基于SAM2的眼动数据跟踪6——SAM2跟踪
目录
一、SAM2跟踪关键文件
二、segment-anything-2/sam2/modeling/sam2_base.py
(2.1)<重点> class SAM2Base(torch.nn.Module)中的track_step函数
(2.1.1)<重点> class SAM2Base(torch.nn.Module)中的_prepare_memory_conditioned_features函数
(2.1.1.1)<重点> memory_attention函数——segment-anything-2/sam2/modeling/memory_attention.py
(2.1.2)class SAM2Base(torch.nn.Module)中的_use_multimask函数
(2.1.3)<重点> class SAM2Base(torch.nn.Module)中的_forward_sam_heads函数
(2.1.3.1)<重点> class SAM2Base(torch.nn.Module)中的_build_sam_heads函数
(2.1.3.1.1)<重点> PromptEncoder——segment-anything-2/sam2/modeling/sam/prompt_encoder.py
(2.1.3.1.2)<重点> MaskDecoder——segment-anything-2/sam2/modeling/sam/prompt_encoder.py
(2.1.4)class SAM2Base(torch.nn.Module)中的_encode_new_memory函数
问题:maskmem_out = self.memory_encoder( pix_feat, mask_for_mem, skip_mask_sigmoid=True ) 这是个函数吗?这个函数在哪呢?
(2.1.4.1)<重点> memory_encoder函数——segment-anything-2/sam2/modeling/memory_encoder.py
四、总结
一、SAM2跟踪关键文件
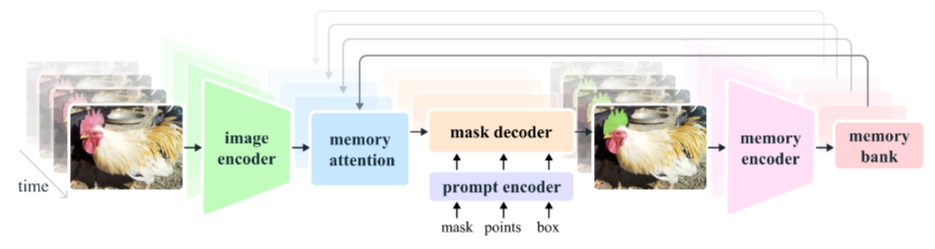
《基于SAM2的眼动数据跟踪5》我们是看到了大概到它调用完“image encoder”的位置,这一篇我们会基本上全部看完。
segment-anything-2/ # 仓库根目录
├─ sam2/ # 核心包
│ ├─ __init__.py # 包入口,一般只 import 主要类
│ ├─ automatic_mask_generator.py # 图像“全自动”模式:网格点+ NMS 产全图 mask
│ ├─ build_sam.py # 统一工厂函数:build_sam2* 系列
│ ├─ sam2_camera_predictor.py # 实时摄像头/视频流推理(官方示例)
│ ├─ sam2_image_predictor.py # 单图交互式推理(等价 SAM1 体验)
│ ├─ sam2_video_predictor.py # 视频跟踪主入口(Memory+Attention)
│ │
│ ├─ modeling/ # 网络骨架与子模块
│ │ ├─ __init__.py
│ │ ├─ sam2_base.py # 图像/视频通用基类(encoder + decoder 拼装)
│ │ ├─ sam2_utils.py # 通用小工具(正余弦位置编码、mask 上/下采样等)
│ │ ├─ memory_attention.py # Memory-Attention 核心实现(Cross-Attention + FFN)
│ │ ├─ memory_encoder.py # 把“历史 mask”编码成 value/mask 特征
│ │ ├─ position_encoding.py # 2D 正余弦位置编码(支持逐像素/逐 token)
│ │ │
│ │ ├─ backbones/ # 图像编码器
│ │ │ ├─ __init__.py
│ │ │ ├─ image_encoder.py # 通用接口:Hiera | ViT | 任意 backbone
│ │ │ ├─ hieradet.py # Hiera 具体实现(多阶段下采样 + 通道阶梯)
│ │ │ └─ utils.py # block 构建、下采样、weight init 辅助
│ │ │
│ │ └─ sam/ # SAM 原始模块(可单独复用)
│ │ ├─ __init__.py
│ │ ├─ prompt_encoder.py # 点/框/ mask → 稀疏/稠密 prompt embedding
│ │ ├─ mask_decoder.py # 两流 Transformer + 动态卷积 → mask & IoU
│ │ └─ transformer.py # Prompt↔Image Cross-Attention 底层算子
│ │
│ └─ checkpoints/ # *.pt 预训练权重(hiera_base / hiera_large …)
├─ sam2_configs/
│ ├─ __init__.py
│ ├─ sam2_hiera_l.yaml
│ └─ sam2_hiera_t.yaml
└─ README.md二、segment-anything-2/sam2/modeling/sam2_base.py
(2.1)<重点> class SAM2Base(torch.nn.Module)中的track_step函数
@torch.inference_mode()
def track_step(self,frame_idx,is_init_cond_frame,current_vision_feats,current_vision_pos_embeds,feat_sizes,point_inputs,mask_inputs,output_dict,num_frames,track_in_reverse=False,run_mem_encoder=True,prev_sam_mask_logits=None,
):"""SAM2 单帧推理核心:把“图像特征 + 用户提示(可选)+ 记忆特征”喂给 SAM 头,得到当前帧掩膜与对象指针,并视情况编码成新记忆供后续帧使用。逻辑分支:1. 若给外部 GT mask 且开关打开 → 直接返回该 mask(跳过头);2. 否则先做“记忆条件特征融合” → 再送 SAM 头 → 得到高分/低分掩膜;3. 若允许编码记忆 → 把高分辨率掩膜再压进记忆库。参数:frame_idx (int):当前帧编号。is_init_cond_frame (bool):True → 初始条件帧,不会读记忆,纯 SAM 推理。current_vision_feats (list[Tensor]):backbone 输出的多尺度特征(已 expand 到 B 份)。current_vision_pos_embeds (list[Tensor]):对应位置编码。feat_sizes (list[(H, W)]):各层特征尺寸,用于 reshape。point_inputs (dict | None):点提示 {"point_coords": (B,N,2), "point_labels": (B,N)}。mask_inputs (Tensor | None):低分辨率掩膜提示 (B,1,H',W');与 point_inputs 互斥。output_dict (dict):全局输出仓库,用于读旧记忆/写新结果。num_frames (int):视频总帧数(用于计算时间位置编码)。track_in_reverse (bool):True → 反向跟踪(时间倒流),影响记忆读写方向。run_mem_encoder (bool):True → 把新掩膜编码进记忆;False → 只出掩膜不写记忆。prev_sam_mask_logits (Tensor | None):上一轮在同帧的掩膜 logits,可作为 mask_inputs 的替代品(迭代 refinement)。返回:dict:{"pred_masks" : (B,1,H/4,W/4) 低分辨率掩膜 logits,"pred_masks_high_res": (B,1,H,W) 高分辨率掩膜 logits,"obj_ptr" : (B,hidden_dim) 对象指针(记忆 key/query),"maskmem_features" : Tensor | None,"maskmem_pos_enc" : Tensor | None,}"""# 1. 先把输入提示存进输出字典(供后续可视化或 debug)current_out = {"point_inputs": point_inputs, "mask_inputs": mask_inputs}# 2. 取出 backbone 最高分辨率特征,reshape 成 BCHW 供 SAM 头使用# 低一层特征作为 "high_res_features" 直接喂给 SAM 的 mask decoderif len(current_vision_feats) > 1:high_res_features = [x.permute(1, 2, 0).view(x.size(1), x.size(2), *s)for x, s in zip(current_vision_feats[:-1], feat_sizes[:-1])]else:high_res_features = None# 3. 若外部直接给 GT mask 且配置要求“跳过 SAM 头”,则直接返回该 maskif mask_inputs is not None and self.use_mask_input_as_output_without_sam:# 3-a 取最后一层像素特征作为空 backbone(仅做尺寸对齐)pix_feat = current_vision_feats[-1].permute(1, 2, 0)pix_feat = pix_feat.view(-1, self.hidden_dim, *feat_sizes[-1])sam_outputs = self._use_mask_as_output(pix_feat, high_res_features, mask_inputs)else:# 4. 标准路径:先把视觉特征与**记忆特征**融合,得到“记忆条件特征”# [这里进去]pix_feat_with_mem = self._prepare_memory_conditioned_features(frame_idx=frame_idx,is_init_cond_frame=is_init_cond_frame,current_vision_feats=current_vision_feats[-1:], # 只用最高层current_vision_pos_embeds=current_vision_pos_embeds[-1:],feat_sizes=feat_sizes[-1:],output_dict=output_dict,num_frames=num_frames,track_in_reverse=track_in_reverse,)# 5. 若上一轮在同帧已有掩膜 logits,把它作为 mask_inputs 喂给 decoder 做 refinementif prev_sam_mask_logits is not None:assert point_inputs is not None and mask_inputs is Nonemask_inputs = prev_sam_mask_logits# 6. 决定是否需要多掩膜输出(初始帧或单点提示默认 True)# [这里进去]multimask_output = self._use_multimask(is_init_cond_frame, point_inputs)# 7. 喂给 SAM 头:prompt encoder + mask decoder# [这里进去]sam_outputs = self._forward_sam_heads(backbone_features=pix_feat_with_mem,point_inputs=point_inputs,mask_inputs=mask_inputs,high_res_features=high_res_features,multimask_output=multimask_output,)# 8. 解压 SAM 头返回的元组(_,_,_,low_res_masks, # (B,1,H/4,W/4) 低分辨率 logitshigh_res_masks, # (B,1,H,W) 高分辨率 logitsobj_ptr, # (B,hidden_dim) 对象指针(记忆 key/query)_,) = sam_outputs# 9. 把结果写进当前输出字典current_out["pred_masks"] = low_res_maskscurrent_out["pred_masks_high_res"] = high_res_maskscurrent_out["obj_ptr"] = obj_ptr# 10. 若需要,把高分辨率掩膜编码成新记忆特征(供下一帧使用)if run_mem_encoder and self.num_maskmem > 0:high_res_masks_for_mem_enc = high_res_masks# [这里进去]maskmem_features, maskmem_pos_enc = self._encode_new_memory(current_vision_feats=current_vision_feats,feat_sizes=feat_sizes,pred_masks_high_res=high_res_masks_for_mem_enc,is_mask_from_pts=(point_inputs is not None), # True 表示来自用户交互)current_out["maskmem_features"] = maskmem_featurescurrent_out["maskmem_pos_enc"] = maskmem_pos_encelse:current_out["maskmem_features"] = Nonecurrent_out["maskmem_pos_enc"] = Nonereturn current_out(2.1.1)<重点> class SAM2Base(torch.nn.Module)中的_prepare_memory_conditioned_features函数
def _prepare_memory_conditioned_features(self,frame_idx,is_init_cond_frame,current_vision_feats,current_vision_pos_embeds,feat_sizes,output_dict,num_frames,track_in_reverse=False,
):"""把当前帧的 backbone 特征与“历史记忆”做 cross-attention 融合,输出一张“既看过过去、又关注当前”的混合特征图,供后续 SAM mask-decoder 使用。记忆来源(按优先级):1. 被选中的条件帧(用户点过提示的帧)2. 最近 num_maskmem-1 帧的非条件输出(可跳 stride)3. 这些帧对应的 object-pointer 序列(用于长程时序建模)参数:frame_idx (int):当前帧编号。is_init_cond_frame (bool):True → 这是第一帧或用户重新初始化,不读记忆,直接返回纯视觉特征。current_vision_feats (list[Tensor]):当前帧 backbone 输出,每层形状 (HW, B, C)。current_vision_pos_embeds (list[Tensor]):对应空间位置编码。feat_sizes (list[(H, W)]):每层特征尺寸,用于 reshape。output_dict (dict):全局输出仓库,含 cond/non_cond 帧的记忆特征、指针等。num_frames (int):视频总帧数,用于计算时间位置编码。track_in_reverse (bool):True → 反向跟踪(时间倒流),影响“上一帧”索引计算。返回:torch.Tensor:融合后的特征图,形状 (B, C, H, W),可直接送 SAM 头。"""# 0. 基本维度B = current_vision_feats[-1].size(1) # batch sizeC = self.hidden_dimH, W = feat_sizes[-1] # 最低分辨率特征尺寸device = current_vision_feats[-1].device# 1. 特殊情况:禁用记忆(复现 SAM 静态图训练/推理)if self.num_maskmem == 0:# 直接返回最高层视觉特征,不做任何融合pix_feat = current_vision_feats[-1].permute(1, 2, 0).view(B, C, H, W)return pix_feat# 2. 初始化要拼接的记忆列表to_cat_memory, to_cat_memory_pos_embed = [], []# 3. 选中最接近当前帧的若干条件帧(用户点过提示的帧)# 这些帧的时间位置编码 t_pos=0(基准帧)assert len(output_dict["cond_frame_outputs"]) > 0selected_cond_outputs, unselected_cond_outputs = select_closest_cond_frames(frame_idx, output_dict["cond_frame_outputs"], self.max_cond_frames_in_attn)# 3-a 把选中的条件帧记忆加入拼接列表t_pos_and_prevs = [(0, out) for out in selected_cond_outputs.values()]# 4. 再补充最近 (self.num_maskmem - 1) 个非条件帧# 允许跳 stride(r)采样,以节省显存;反向跟踪时索引方向相反r = self.memory_temporal_stride_for_evalfor t_pos in range(1, self.num_maskmem):t_rel = self.num_maskmem - t_pos # 距离当前帧的帧数if t_rel == 1:# 最近邻:直接取 frame_idx ± 1if not track_in_reverse:prev_frame_idx = frame_idx - t_relelse:prev_frame_idx = frame_idx + t_relelse:# 跳 stride 采样:保证至少间隔 r 帧if not track_in_reverse:prev_frame_idx = ((frame_idx - 2) // r) * r - (t_rel - 2) * relse:prev_frame_idx = -(-(frame_idx + 2) // r) * r + (t_rel - 2) * r# 4-a 从 non_cond 区拿输出;若未命中,再试 unselected cond 区out = output_dict["non_cond_frame_outputs"].get(prev_frame_idx, None)if out is None:out = unselected_cond_outputs.get(prev_frame_idx, None)# 4-b 只要拿到有效记忆就记录 (t_pos, out) 对t_pos_and_prevs.append((t_pos, out))# 5. 把第 3+4 步收集的记忆全部拼成序列for t_pos, prev in t_pos_and_prevs:if prev is None:continue # 该 slot 为空(padding),跳过# 5-a 记忆特征可能曾被 offload 到 CPU,先搬回 GPUfeats = prev["maskmem_features"].to(device, non_blocking=True)# 展平空间维度:(C, H, W) -> (C, HW) -> (HW, B, C)to_cat_memory.append(feats.flatten(2).permute(2, 0, 1))# 5-b 空间位置编码同样展平maskmem_enc = prev["maskmem_pos_enc"][-1].to(device)maskmem_enc = maskmem_enc.flatten(2).permute(2, 0, 1)# 5-c 再加上**时间**位置编码(sine 嵌入,t_pos 越大离当前越远)maskmem_enc = maskmem_enc + self.maskmem_tpos_enc[self.num_maskmem - t_pos - 1]to_cat_memory_pos_embed.append(maskmem_enc)# 6. 收集 object-pointer 序列(长程时序记忆)num_obj_ptr_tokens = 0if self.use_obj_ptrs_in_encoder:max_obj_ptrs_in_encoder = min(num_frames, self.max_obj_ptrs_in_encoder)# 6-a 先加选中的条件帧指针if not self.training and self.only_obj_ptrs_in_the_past_for_eval:# 评估模式下只拿“过去”的指针(避免信息泄露)ptr_cond_outputs = {t: outfor t, out in selected_cond_outputs.items()if (t >= frame_idx if track_in_reverse else t <= frame_idx)}else:ptr_cond_outputs = selected_cond_outputspos_and_ptrs = [(abs(frame_idx - t), out["obj_ptr"]) # (时间距离, 指针tensor)for t, out in ptr_cond_outputs.items()]# 6-b 再加最多 (max_obj_ptrs_in_encoder - 1) 个非条件帧指针for t_diff in range(1, max_obj_ptrs_in_encoder):t = frame_idx + t_diff if track_in_reverse else frame_idx - t_diffif t < 0 or (num_frames is not None and t >= num_frames):breakout = output_dict["non_cond_frame_outputs"].get(t, unselected_cond_outputs.get(t, None))if out is not None:pos_and_ptrs.append((t_diff, out["obj_ptr"]))# 6-c 若至少有一个指针,就拼成序列if len(pos_and_ptrs) > 0:pos_list, ptrs_list = zip(*pos_and_ptrs)obj_ptrs = torch.stack(ptrs_list, dim=0) # (ptr_len, B, C)# 可选:给指针加 1D sine 时间位置编码if self.add_tpos_enc_to_obj_ptrs:t_diff_max = max_obj_ptrs_in_encoder - 1tpos_dim = C if self.proj_tpos_enc_in_obj_ptrs else self.mem_dimobj_pos = torch.tensor(pos_list, device=device)obj_pos = get_1d_sine_pe(obj_pos / t_diff_max, dim=tpos_dim)obj_pos = self.obj_ptr_tpos_proj(obj_pos)obj_pos = obj_pos.unsqueeze(1).expand(-1, B, self.mem_dim)else:obj_pos = obj_ptrs.new_zeros(len(pos_list), B, self.mem_dim)# 若 mem_dim < C,把一个指针拆成 C//mem_dim 个 tokenif self.mem_dim < C:obj_ptrs = obj_ptrs.reshape(-1, B, C // self.mem_dim, self.mem_dim)obj_ptrs = obj_ptrs.permute(0, 2, 1, 3).flatten(0, 1) # (ptr_len*split, B, mem_dim)obj_pos = obj_pos.repeat_interleave(C // self.mem_dim, dim=0)to_cat_memory.append(obj_ptrs)to_cat_memory_pos_embed.append(obj_pos)num_obj_ptr_tokens = obj_ptrs.shape[0]else:num_obj_ptr_tokens = 0else:# 7. 初始条件帧且不使用指针时,直接给“无记忆”占位符if self.directly_add_no_mem_embed:# 不走 transformer,直接加向量pix_feat_with_mem = current_vision_feats[-1] + self.no_mem_embedpix_feat_with_mem = pix_feat_with_mem.permute(1, 2, 0).view(B, C, H, W)return pix_feat_with_mem# 8. 给 transformer 一个“空记忆”占位 token,避免空输入to_cat_memory = [self.no_mem_embed.expand(1, B, self.mem_dim)]to_cat_memory_pos_embed = [self.no_mem_pos_enc.expand(1, B, self.mem_dim)]num_obj_ptr_tokens = 0# 9. 把所有记忆拼成一条长序列memory = torch.cat(to_cat_memory, dim=0) # (mem_len, B, C)memory_pos_embed = torch.cat(to_cat_memory_pos_embed, dim=0)# 10. 记忆注意力:当前特征作为 Query,记忆序列作为 Key/Value# [这里进去]pix_feat_with_mem = self.memory_attention(curr=current_vision_feats,curr_pos=current_vision_pos_embeds,memory=memory,memory_pos=memory_pos_embed,num_obj_ptr_tokens=num_obj_ptr_tokens, # 告诉注意力层前面多少 token 是指针)# 11. 把输出 reshape 回空间图 (B, C, H, W) 并返回pix_feat_with_mem = pix_feat_with_mem.permute(1, 2, 0).view(B, C, H, W)return pix_feat_with_mem(2.1.1.1)<重点> memory_attention函数——segment-anything-2/sam2/modeling/memory_attention.py
class MemoryAttention(nn.Module):"""记忆注意力模块:把**当前帧特征**(Query)与**历史记忆**(Key/Value)做**多层 cross-attention + self-attention** 融合,输出一张“既看过过去、又关注当前”的混合特征图,供 SAM mask-decoder 使用。结构:- 多层 Transformer 解码器(layer 由外部注入,通常是 `MemoryAttentionLayer`)- 每层:self-attention(当前帧内部)+ cross-attention(当前↔记忆)- 可选 RoPE(旋转位置编码)用于对象指针 token- 支持 batch-first / seq-first 两种格式,内部自动转换"""def __init__(self,d_model: int, # 通道维度 Cpos_enc_at_input: bool, # 是否在输入端就加位置编码(True=SAM2 默认)layer: nn.Module, # 单层模块(MemoryAttentionLayer)num_layers: int, # 堆叠层数batch_first: bool = True, # 外部期望 batch 维在前还是 seq 维在前):super().__init__()self.d_model = d_modelself.layers = get_clones(layer, num_layers) # 深拷贝 num_layers 份self.num_layers = num_layersself.norm = nn.LayerNorm(d_model) # 最后统一 LayerNormself.pos_enc_at_input = pos_enc_at_inputself.batch_first = batch_firstdef forward(self,curr: torch.Tensor, # 当前帧特征 (HW, B, C) 或 [(HW, B, C)]memory: torch.Tensor, # 记忆序列 (L, B, C)curr_pos: Optional[Tensor] = None, # 当前位置编码 (HW, B, C) 或 Nonememory_pos: Optional[Tensor] = None, # 记忆位置编码 (L, B, C) 或 Nonenum_obj_ptr_tokens: int = 0, # 前多少个 token 是对象指针(用于 RoPE)):"""前向:多层 self + cross attention,返回融合后的特征(seq-first 格式)。参数:curr: 当前帧特征,列表长度=1 或单 Tensor,形状 (HW, B, C)memory: 历史记忆,(L, B, C)curr_pos: 当前 2D 位置编码,与 curr 同形状memory_pos: 记忆时间+空间位置编码,与 memory 同形状num_obj_ptr_tokens: 对象指针 token 数(仅 RoPE 层需要)返回:normed_output: (HW, B, C) 融合后的特征,seq-first 格式"""# 1. 若外部给的是列表(多尺度),只拿最高层;必须同步给位置编码if isinstance(curr, list):assert isinstance(curr_pos, list)assert len(curr) == len(curr_pos) == 1curr, curr_pos = curr[0], curr_pos[0]# 2. 基础校验:batch 维必须一致assert curr.shape[1] == memory.shape[1], "Batch size must be the same for curr and memory"# 3. 初始输出 = 当前特征output = curr# 4. 可选:在输入端就加位置编码(系数 0.1 防止数值爆炸)if self.pos_enc_at_input and curr_pos is not None:output = output + 0.1 * curr_pos# 5. 若外部要求 batch_first,内部先转成 seq-first(Transformer 惯例)if self.batch_first:output = output.transpose(0, 1) # (B, HW, C) -> (HW, B, C)curr_pos = curr_pos.transpose(0, 1) # 位置编码同步转memory = memory.transpose(0, 1) # (B, L, C) -> (L, B, C)memory_pos = memory_pos.transpose(0, 1)# 6. 逐层 forwardfor layer in self.layers:# 6-a RoPE 层需要告诉它“前多少个 token 是指针”kwds = {}if isinstance(layer.cross_attn_image, RoPEAttention):kwds = {"num_k_exclude_rope": num_obj_ptr_tokens}# 6-b 单层:self-attention + cross-attention + FFNoutput = layer(tgt=output, # Query = 当前帧memory=memory, # Key/Value = 记忆pos=memory_pos, # 记忆位置编码query_pos=curr_pos, # Query 位置编码**kwds,)# 7. 最后统一 LayerNormnormed_output = self.norm(output)# 8. 若外部要 batch_first,再转回去if self.batch_first:normed_output = normed_output.transpose(0, 1) # (HW, B, C) -> (B, HW, C)curr_pos = curr_pos.transpose(0, 1)# 9. 返回融合后的特征(seq-first 格式)return normed_output(2.1.2)class SAM2Base(torch.nn.Module)中的_use_multimask函数
def _use_multimask(self, is_init_cond_frame, point_inputs):"""根据当前帧类型和提示点数量,决定 SAM mask-decoder 是否输出**多掩膜**(multimask)。背景:SAM 默认对**模糊提示**(单点/粗框)同时给出 3 个候选掩膜,让用户或后续模块挑选;对**清晰提示**(多点、已有较好 mask)则只输出 1 个精炼掩膜,节省计算与显存。本函数即实现这一策略开关。参数:is_init_cond_frame (bool):True → 当前帧是初始条件帧(用户首次点击或重新初始化)。point_inputs (dict | None):点提示字典,含 "point_labels" (B, N) 和 "point_coords" (B, N, 2)。若为 None,表示无点提示。返回:bool:True → 使用 multimask 输出(3 个候选);False → 只输出单掩膜。"""# 1. 计算当前提示点数量(不含背景点)num_pts = 0 if point_inputs is None else point_inputs["point_labels"].size(1)# 2. 同时满足以下 4 个条件才开启 multimask:# a) 全局开关打开;# b) 当前是初始条件帧,**或**配置允许跟踪阶段也 multimask;# c) 点数量在 [min, max] 区间内;# d) 实际上只要有提示点就会触发,没点时 num_pts=0 自动不满足。multimask_output = (self.multimask_output_in_sam # 全局超参:是否启用 multimask 功能and (is_init_cond_frame or self.multimask_output_for_tracking) # 帧类型限制and (self.multimask_min_pt_num <= num_pts <= self.multimask_max_pt_num) # 点数限制)return multimask_output(2.1.3)<重点> class SAM2Base(torch.nn.Module)中的_forward_sam_heads函数
@torch.inference_mode()
def _forward_sam_heads(self,backbone_features,point_inputs=None,mask_inputs=None,high_res_features=None,multimask_output=False,
):"""完整的 SAM 风格「提示编码 + 掩膜解码」一条龙:把 backbone 特征与用户提示(点/框/mask)一起送 SAM,输出多组或单组掩膜 logits、IoU 估计、对象指针等。参数:backbone_features (Tensor):已融合记忆的图像嵌入,形状 (B, C, H, W),其中 H=W=sam_image_embedding_size(默认 64)。point_inputs (dict | None):{"point_coords": (B, P, 2), "point_labels": (B, P)}坐标为**绝对像素**(会在内部归一化),label: 1=前, 0=背, -1=pad。mask_inputs (Tensor | None):低分辨率掩膜提示 (B,1,H',W'),与点提示互斥。high_res_features (list[Tensor] | None):额外两层更高分辨率特征 [4H,4W] 与 [2H,2W],供 decoder refine 边缘。multimask_output (bool):True → 输出 3 候选掩膜 + 3 IoU;False → 1 掩膜 + 1 IoU。返回:tuple:0. low_res_multimasks – (B,M,H/4,W/4) 低分多掩膜 logits1. high_res_multimasks – (B,M,H,W) 高分多掩膜 logits2. ious – (B,M) 各掩膜 IoU 估计3. low_res_masks – (B,1,H/4,W/4) **最佳**低分掩膜4. high_res_masks – (B,1,H,W) **最佳**高分掩膜5. obj_ptr – (B,C) 对象指针(用于记忆)6. object_score_logits – (B,) 对象出现置信度(可软可硬)"""B = backbone_features.size(0)device = backbone_features.device# --- 1. 输入断言:尺寸必须匹配 SAM 预设 ---assert backbone_features.size(1) == self.sam_prompt_embed_dimassert backbone_features.size(2) == self.sam_image_embedding_sizeassert backbone_features.size(3) == self.sam_image_embedding_size# --- 2. 构造点提示 ---if point_inputs is not None:sam_point_coords = point_inputs["point_coords"] # (B, P, 2)sam_point_labels = point_inputs["point_labels"] # (B, P)assert sam_point_coords.size(0) == B and sam_point_labels.size(0) == Belse:# 无点提示时,用 1 个 pad 点(label=-1)占位,保证 prompt encoder 正常 forwardsam_point_coords = torch.zeros(B, 1, 2, device=device)sam_point_labels = -torch.ones(B, 1, dtype=torch.int32, device=device)# --- 3. 构造掩膜提示 ---if mask_inputs is not None:# 若外部 mask 分辨率不符,先双线性下采样到 prompt encoder 期望尺寸assert len(mask_inputs.shape) == 4 and mask_inputs.shape[:2] == (B, 1)if mask_inputs.shape[-2:] != self.sam_prompt_encoder.mask_input_size:sam_mask_prompt = F.interpolate(mask_inputs.float(),size=self.sam_prompt_encoder.mask_input_size,align_corners=False,mode="bilinear",antialias=True, # 抗锯齿,减少下采样 aliasing)else:sam_mask_prompt = mask_inputselse:# 无 mask 时,prompt encoder 内部会加 learned `no_mask_embed`sam_mask_prompt = None# --- 4. 送进 SAM 提示编码器 ---# [这里进去]sparse_embeddings, dense_embeddings = self.sam_prompt_encoder(points=(sam_point_coords, sam_point_labels),boxes=None, # 框提示在外部已转成 2 点,不再走这里masks=sam_mask_prompt,)# --- 5. 送进 SAM mask 解码器 ---# [这里进去](low_res_multimasks, # (B, M, H/4, W/4) M=3 or 1ious, # (B, M) IoU 估计sam_output_tokens, # (B, M, C) 解码器输出 tokenobject_score_logits, # (B,) 对象出现/消失 logits) = self.sam_mask_decoder(image_embeddings=backbone_features,image_pe=self.sam_prompt_encoder.get_dense_pe(), # 固定 2D 位置编码sparse_prompt_embeddings=sparse_embeddings,dense_prompt_embeddings=dense_embeddings,multimask_output=multimask_output,repeat_image=False, # image 已 batch,无需再 repeathigh_res_features=high_res_features, # 高分特征供 refine 边缘)# --- 6. 对象 score 后处理:若模型预测“无对象”,把掩膜 logits 置为 NO_OBJ_SCORE ---if self.pred_obj_scores:is_obj_appearing = object_score_logits > 0 # 硬阈值# 记忆用掩膜必须**硬**选择:有对象才保留,否则置极大负值low_res_multimasks = torch.where(is_obj_appearing[:, None, None],low_res_multimasks,NO_OBJ_SCORE,)# --- 7. 数据类型转换:bf16/fp16 -> fp32(老版本 PyTorch interpolate 不支持 bf16)---low_res_multimasks = low_res_multimasks.float()# 上采样到图像原分辨率(stride=1)high_res_multimasks = F.interpolate(low_res_multimasks,size=(self.image_size, self.image_size),mode="bilinear",align_corners=False,)# --- 8. 选取最佳掩膜 ---sam_output_token = sam_output_tokens[:, 0] # 默认取第 1 个 token(单掩膜时即自身)if multimask_output:# 多掩膜时,选 IoU 估计最高的那个best_iou_inds = torch.argmax(ious, dim=-1) # (B,)batch_inds = torch.arange(B, device=device)low_res_masks = low_res_multimasks[batch_inds, best_iou_inds].unsqueeze(1)high_res_masks = high_res_multimasks[batch_inds, best_iou_inds].unsqueeze(1)# 若解码器输出了多个 token,同样要选最佳if sam_output_tokens.size(1) > 1:sam_output_token = sam_output_tokens[batch_inds, best_iou_inds]else:# 单掩膜时,最佳即唯一low_res_masks, high_res_masks = low_res_multimasks, high_res_multimasks# --- 9. 从最佳 token 提取对象指针(用于记忆)---obj_ptr = self.obj_ptr_proj(sam_output_token) # (B, C)# --- 10. 对象指针后处理:若模型认为“无对象”,指针也被削弱或替换 ---if self.pred_obj_scores:if self.soft_no_obj_ptr:# 软削弱:用 sigmoid 概率加权assert not self.teacher_force_obj_scores_for_memlambda_is_obj_appearing = object_score_logits.sigmoid()else:# 硬削弱:0/1 加权lambda_is_obj_appearing = is_obj_appearing.float()if self.fixed_no_obj_ptr:obj_ptr = lambda_is_obj_appearing * obj_ptr# 剩余权重用“无对象指针”补齐,保证指针和为 1obj_ptr = obj_ptr + (1 - lambda_is_obj_appearing) * self.no_obj_ptr# --- 11. 返回打包结果 ---return (low_res_multimasks, # 0 低分多掩膜high_res_multimasks, # 1 高分多掩膜ious, # 2 各掩膜 IoU 估计low_res_masks, # 3 最佳低分掩膜high_res_masks, # 4 最佳高分掩膜obj_ptr, # 5 对象指针(记忆 key/query)object_score_logits, # 6 对象出现置信度 logits)(2.1.3.1)<重点> class SAM2Base(torch.nn.Module)中的_build_sam_heads函数
在SAM2Base类初始化中调用了self._build_sam_heads()
def _build_sam_heads(self):"""实例化 SAM 风格的两大核心子模块:1. PromptEncoder - 把用户提示(点/框/mask)转成与图像同维度的查询向量2. MaskDecoder - 将「图像嵌入 + 查询向量」解码成掩膜 logits、IoU、对象指针同时根据配置生成:- 对象指针线性/MLP 投影器- 时间位置编码投影器(避免与空间位置编码冲突)所有超参数(如 mask_in_chans=16、depth=2 等)直接沿用 SAM 官方设置,保证与原始 SAM 权重兼容。"""# 1. 计算 SAM 内部网格尺寸 = 图像尺寸 // backbone 下采样倍数(默认 16)self.sam_prompt_embed_dim = self.hidden_dim # 256self.sam_image_embedding_size = self.image_size // self.backbone_stride # 1024//16 = 64# 2. 构建 PromptEncoder# - embed_dim: 与图像嵌入通道对齐# - image_embedding_size: (64,64) 网格# - input_image_size: 预处理后的正方形 1024×1024# - mask_in_chans: 16 通道,用于把外部 mask prompt 先卷积再进 transformer# [这里进去]self.sam_prompt_encoder = PromptEncoder(embed_dim=self.sam_prompt_embed_dim,image_embedding_size=(self.sam_image_embedding_size,self.sam_image_embedding_size,),input_image_size=(self.image_size, self.image_size),mask_in_chans=16,)# 3. 构建 MaskDecoder# - num_multimask_outputs=3: 模糊提示时输出 3 候选掩膜 + 3 个 IoU# - TwoWayTransformer: 2 层双向 cross/self attention,8 头,MLP 2048 隐维# - iou_head: 3 层 MLP 预测掩膜质量(IoU)# - use_high_res_features: 是否把 backbone 高分 skip 接入 decoder refine 边缘# - pred_obj_scores: 是否额外预测「对象出现/消失」logits(用于软/硬 no-object 指针)# - 其余 **kwargs 来自 Hydra 配置,可在 yaml 里覆盖# [这里进去]self.sam_mask_decoder = MaskDecoder(num_multimask_outputs=3,transformer=TwoWayTransformer(depth=2,embedding_dim=self.sam_prompt_embed_dim,mlp_dim=2048,num_heads=8,),transformer_dim=self.sam_prompt_embed_dim,iou_head_depth=3,iou_head_hidden_dim=256,use_high_res_features=self.use_high_res_features_in_sam,iou_prediction_use_sigmoid=self.iou_prediction_use_sigmoid,pred_obj_scores=self.pred_obj_scores,pred_obj_scores_mlp=self.pred_obj_scores_mlp,use_multimask_token_for_obj_ptr=self.use_multimask_token_for_obj_ptr,**(self.sam_mask_decoder_extra_args or {}),)# 4. 对象指针投影器# SAM decoder 输出 token (256-d) → 线性/MLP → 对象指针 (256-d)# 用于后续帧的 cross-attention key/valueif self.use_obj_ptrs_in_encoder:self.obj_ptr_proj = torch.nn.Linear(self.hidden_dim, self.hidden_dim)if self.use_mlp_for_obj_ptr_proj:self.obj_ptr_proj = MLP(self.hidden_dim, self.hidden_dim, self.hidden_dim, 3)else:self.obj_ptr_proj = torch.nn.Identity()# 5. 时间位置编码投影器(可选)# 避免「时间 sin-embedding」与「空间 sin-embedding」直接相加产生干扰if self.proj_tpos_enc_in_obj_ptrs:self.obj_ptr_tpos_proj = torch.nn.Linear(self.hidden_dim, self.mem_dim)else:self.obj_ptr_tpos_proj = torch.nn.Identity()(2.1.3.1.1)<重点> PromptEncoder——segment-anything-2/sam2/modeling/sam/prompt_encoder.py
class PromptEncoder(nn.Module):"""SAM / SAM2 的提示编码器。将用户输入的「点、框、mask」三种提示统一编码成:1. sparse embeddings (B, N, 256) —— 点/框用2. dense embeddings (B, 256, H, W) —— mask 用与图像嵌入同维度,可直接送进 SAM mask-decoder 的 cross-attention。"""# ---------- 初始化 ----------def __init__(self,embed_dim: int, # 256image_embedding_size: Tuple[int, int], # (64, 64) 网格大小input_image_size: Tuple[int, int], # (1024,1024) 输入像素mask_in_chans: int, # 16activation: Type[nn.Module] = nn.GELU,) -> None:super().__init__()self.embed_dim = embed_dimself.input_image_size = input_image_sizeself.image_embedding_size = image_embedding_size# 1. 2D 位置编码生成器(sin-cos + 可学习)self.pe_layer = PositionEmbeddingRandom(embed_dim // 2) # 128 维 sin-cos# 2. 点/框提示嵌入self.num_point_embeddings = 4 # 4 类 token:正点/负点/框左上/框右下self.point_embeddings = nn.ModuleList([nn.Embedding(1, embed_dim) for _ in range(self.num_point_embeddings)])self.not_a_point_embed = nn.Embedding(1, embed_dim) # label=-1 的 padding 点# 3. mask 提示嵌入# 先把外部 mask 下采样到 4× 网格 = (256,256) 再卷积到 64×64self.mask_input_size = (4 * image_embedding_size[0], # 2564 * image_embedding_size[1], # 256)self.mask_downscaling = nn.Sequential(nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2), # 128->128LayerNorm2d(mask_in_chans // 4),activation(),nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2), # 128->64LayerNorm2d(mask_in_chans),activation(),nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1), # 64->256)self.no_mask_embed = nn.Embedding(1, embed_dim) # 无 mask 时用的可学习向量# ---------- 工具函数 ----------def get_dense_pe(self) -> torch.Tensor:"""返回固定网格的 2D 位置编码,形状 (1, 256, 64, 64),供 SAM mask-decoder 的图像位置编码使用。"""return self.pe_layer(self.image_embedding_size).unsqueeze(0)def _embed_points(self,points: torch.Tensor, # (B, N, 2) 绝对像素坐标labels: torch.Tensor, # (B, N) 0=负 1=正 2=框左上 3=框右下 -1=padpad: bool, # 是否补一个 padding 点(当无框时)) -> torch.Tensor:"""把点/框角点转成 256-d 嵌入向量。"""points = points + 0.5 # 移到像素中心if pad:padding_point = torch.zeros((points.shape[0], 1, 2), device=points.device)padding_label = -torch.ones((labels.shape[0], 1), device=labels.device)points = torch.cat([points, padding_point], dim=1)labels = torch.cat([labels, padding_label], dim=1)# 1. 先拿 2D sin-cos 位置编码(归一化到 0~1)point_embedding = self.pe_layer.forward_with_coords(points, self.input_image_size)# 2. 根据 label 加上对应可学习向量(正点/负点/框角)# 用 where 实现“逐元素选择”point_embedding = torch.where((labels == -1).unsqueeze(-1),torch.zeros_like(point_embedding) + self.not_a_point_embed.weight,point_embedding,)# 正点point_embedding = torch.where((labels == 0).unsqueeze(-1),point_embedding + self.point_embeddings[0].weight,point_embedding,)# 负点point_embedding = torch.where((labels == 1).unsqueeze(-1),point_embedding + self.point_embeddings[1].weight,point_embedding,)# 框左上point_embedding = torch.where((labels == 2).unsqueeze(-1),point_embedding + self.point_embeddings[2].weight,point_embedding,)# 框右下point_embedding = torch.where((labels == 3).unsqueeze(-1),point_embedding + self.point_embeddings[3].weight,point_embedding,)return point_embeddingdef _embed_boxes(self, boxes: torch.Tensor) -> torch.Tensor:"""把框 [x1,y1,x2,y2] 转成两个角点嵌入。"""boxes = boxes + 0.5coords = boxes.reshape(-1, 2, 2) # (B, 2, 2)corner_embedding = self.pe_layer.forward_with_coords(coords, self.input_image_size) # (B, 2, 256)# 左上角加 token-2,右下角加 token-3corner_embedding[:, 0, :] += self.point_embeddings[2].weightcorner_embedding[:, 1, :] += self.point_embeddings[3].weightreturn corner_embedding # (B, 2, 256)def _embed_masks(self, masks: torch.Tensor) -> torch.Tensor:"""把外部 mask 先下采样到 256×256 再卷积到 64×64。"""mask_embedding = self.mask_downscaling(masks) # (B, 256, 64, 64)return mask_embedding# ---------- 前向入口 ----------def forward(self,points: Optional[Tuple[torch.Tensor, torch.Tensor]]], # (coord, label)boxes: Optional[torch.Tensor], # (B, 4)masks: Optional[torch.Tensor], # (B, 1, H, W)) -> Tuple[torch.Tensor, torch.Tensor]:"""统一入口:返回sparse_embeddings: (B, N, 256) 点+框dense_embeddings: (B, 256, 64, 64) mask"""# 1. 自动推导 batch 大小bs = self._get_batch_size(points, boxes, masks)# 2. 初始化空 sparse 向量sparse_embeddings = torch.empty((bs, 0, self.embed_dim), device=self._get_device())# 3. 点提示if points is not None:coords, labels = pointspoint_embeddings = self._embed_points(coords, labels, pad=(boxes is None))sparse_embeddings = torch.cat([sparse_embeddings, point_embeddings], dim=1)# 4. 框提示(转成 2 个角点)if boxes is not None:box_embeddings = self._embed_boxes(boxes)sparse_embeddings = torch.cat([sparse_embeddings, box_embeddings], dim=1)# 5. mask 提示if masks is not None:dense_embeddings = self._embed_masks(masks)else:# 无 mask → 用可学习的 no_mask_embed 广播成 64×64dense_embeddings = self.no_mask_embed.weight.reshape(1, -1, 1, 1).expand(bs, -1, self.image_embedding_size[0], self.image_embedding_size[1])return sparse_embeddings, dense_embeddings(2.1.3.1.2)<重点> MaskDecoder——segment-anything-2/sam2/modeling/sam/prompt_encoder.py
class MaskDecoder(nn.Module):"""SAM / SAM2 的掩膜解码器。输入:图像嵌入 + 提示嵌入(稀疏/稠密)输出:掩膜 logits、IoU 估计、对象指针 token(供记忆用)核心路线:1. 把「IoU token + mask token + 提示」拼成 Query2. 与图像嵌入做双向 cross-attention(TwoWayTransformer)3. 用 hyper-network 把每个 mask token 转成 1×1 卷积核,与上采样图像特征做内积 → 掩膜4. 额外分支:IoU 头、对象出现头(可选)5. 单掩膜/多掩膜动态选择"""# -------------------- 初始化 --------------------def __init__(self,*,transformer_dim: int, # 256transformer: nn.Module, # TwoWayTransformernum_multimask_outputs: int = 3, # 3 候选掩膜activation: Type[nn.Module] = nn.GELU,iou_head_depth: int = 3, # IoU MLP 层数iou_head_hidden_dim: int = 256, # IoU MLP 隐维use_high_res_features: bool = False, # 是否用高分 skip 特征iou_prediction_use_sigmoid: bool = False, # IoU 是否 sigmoid 输出dynamic_multimask_via_stability: bool = False, # 低稳定性时回退到多掩膜dynamic_multimask_stability_delta: float = 0.05,dynamic_multimask_stability_thresh: float = 0.98,pred_obj_scores: bool = False, # 是否预测「对象出现」logitspred_obj_scores_mlp: bool = False, # 用 MLP 还是线性use_multimask_token_for_obj_ptr: bool = False, # 多掩膜时取哪个 token 做指针) -> None:super().__init__()self.transformer_dim = transformer_dimself.transformer = transformerself.num_multimask_outputs = num_multimask_outputs# 1. 可学习 token 定义self.iou_token = nn.Embedding(1, transformer_dim) # IoU 预测专用self.num_mask_tokens = num_multimask_outputs + 1 # 3 候选 + 1 单掩膜self.mask_tokens = nn.Embedding(self.num_mask_tokens, transformer_dim)# 2. 对象出现 token(可选)self.pred_obj_scores = pred_obj_scoresif self.pred_obj_scores:self.obj_score_token = nn.Embedding(1, transformer_dim)self.use_multimask_token_for_obj_ptr = use_multimask_token_for_obj_ptr# 3. 图像特征上采样器:64×64 → 256×256(2 层反卷积)self.output_upscaling = nn.Sequential(nn.ConvTranspose2d(transformer_dim, transformer_dim // 4, kernel_size=2, stride=2),LayerNorm2d(transformer_dim // 4),activation(),nn.ConvTranspose2d(transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2),activation(),)self.use_high_res_features = use_high_res_featuresif use_high_res_features:# 1×1 卷积把 backbone 高分 skip 映射到上采样相同通道,方便残差相加self.conv_s0 = nn.Conv2d(transformer_dim, transformer_dim // 8, kernel_size=1, stride=1)self.conv_s1 = nn.Conv2d(transformer_dim, transformer_dim // 4, kernel_size=1, stride=1)# 4. Hyper-network:把每个 mask token 转成 1×1 卷积核,与上采样图做内积 → 掩膜self.output_hypernetworks_mlps = nn.ModuleList([MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3)for _ in range(self.num_mask_tokens)])# 5. IoU 预测头self.iou_prediction_head = MLP(transformer_dim,iou_head_hidden_dim,self.num_mask_tokens, # 输出 3 或 1 个 IoUiou_head_depth,sigmoid_output=iou_prediction_use_sigmoid,)# 6. 对象出现头(可选)if self.pred_obj_scores:self.pred_obj_score_head = nn.Linear(transformer_dim, 1)if pred_obj_scores_mlp:self.pred_obj_score_head = MLP(transformer_dim, transformer_dim, 1, 3)# 7. 动态多掩膜稳定性开关self.dynamic_multimask_via_stability = dynamic_multimask_via_stabilityself.dynamic_multimask_stability_delta = dynamic_multimask_stability_deltaself.dynamic_multimask_stability_thresh = dynamic_multimask_stability_thresh# -------------------- 前向入口 --------------------def forward(self,image_embeddings: torch.Tensor, # (B, 256, 64, 64) 图像嵌入image_pe: torch.Tensor, # (B, 256, 64, 64) 2D 位置编码sparse_prompt_embeddings: torch.Tensor, # (B, N, 256) 点/框提示dense_prompt_embeddings: torch.Tensor, # (B, 256, 64, 64) mask 提示multimask_output: bool, # True=返回 3 候选repeat_image: bool, # 是否把图像复制 B 份(batch>1 时)high_res_features: Optional[List[torch.Tensor]] = None, # 高分 skip 特征 [4×, 2×]) -> Tuple[torch.Tensor, torch.Tensor]:"""返回:masks: (B, M, 256, 256) 掩膜 logits,M=3 或 1iou_pred: (B, M) IoU 估计sam_tokens_out: (B, M, 256) 对应掩膜 token(用于对象指针)object_score_logits: (B, 1) 对象出现置信度(可选)"""# 1. 统一调用内部 predict_masks 拿到 **所有** 掩膜 & tokenmasks, iou_pred, mask_tokens_out, object_score_logits = self.predict_masks(image_embeddings=image_embeddings,image_pe=image_pe,sparse_prompt_embeddings=sparse_prompt_embeddings,dense_prompt_embeddings=dense_prompt_embeddings,repeat_image=repeat_image,high_res_features=high_res_features,)# 2. 根据 multimask_output 或动态稳定性选择最终掩膜if multimask_output:masks = masks[:, 1:, :, :] # 去掉单掩膜 token-0,留 1~3iou_pred = iou_pred[:, 1:]elif self.dynamic_multimask_via_stability and not self.training:masks, iou_pred = self._dynamic_multimask_via_stability(masks, iou_pred)else:masks = masks[:, 0:1, :, :] # 只拿 token-0 单掩膜iou_pred = iou_pred[:, 0:1]# 3. 选择对象指针 tokenif multimask_output and self.use_multimask_token_for_obj_ptr:sam_tokens_out = mask_tokens_out[:, 1:] # [B, 3, 256]else:# 默认 **永远** 用单掩膜 token 作为对象指针(与训练阶段一致)sam_tokens_out = mask_tokens_out[:, 0:1] # [B, 1, 256]return masks, iou_pred, sam_tokens_out, object_score_logits# -------------------- 核心推理 --------------------def predict_masks(self,image_embeddings: torch.Tensor,image_pe: torch.Tensor,sparse_prompt_embeddings: torch.Tensor,dense_prompt_embeddings: torch.Tensor,repeat_image: bool,high_res_features: Optional[List[torch.Tensor]] = None,) -> Tuple[torch.Tensor, torch.Tensor]:""""""# 1. 拼接输出 token:[obj_score(可选) + iou + mask_tokens] + 用户提示s = 0if self.pred_obj_scores:output_tokens = torch.cat([self.obj_score_token.weight,self.iou_token.weight,self.mask_tokens.weight,],dim=0,)s = 1else:output_tokens = torch.cat([self.iou_token.weight, self.mask_tokens.weight], dim=0)output_tokens = output_tokens.unsqueeze(0).expand(sparse_prompt_embeddings.size(0), -1, -1)tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1) # (B, 1+N+4, 256)# 2. 图像侧准备if repeat_image:src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0)else:src = image_embeddingssrc = src + dense_prompt_embeddings # 加上 mask 提示pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)b, c, h, w = src.shape# 3. TwoWayTransformer:双向 cross/self attentionhs, src = self.transformer(src, pos_src, tokens)iou_token_out = hs[:, s, :] # IoU tokenmask_tokens_out = hs[:, s + 1: s + 1 + self.num_mask_tokens, :] # 所有 mask token# 4. 上采样图像特征 64×64 → 256×256src = src.transpose(1, 2).view(b, c, h, w)if not self.use_high_res_features:upscaled_embedding = self.output_upscaling(src)else:# 残差连接高分 skip 特征,边缘更锐利dc1, ln1, act1, dc2, act2 = self.output_upscalingfeat_s0, feat_s1 = high_res_featuresupscaled_embedding = act1(ln1(dc1(src) + feat_s1))upscaled_embedding = act2(dc2(upscaled_embedding) + feat_s0)# 5. Hyper-network:每个 mask token → 1×1 卷积核,与上采样图内积 → 掩膜hyper_in_list: List[torch.Tensor] = []for i in range(self.num_mask_tokens):hyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :]))hyper_in = torch.stack(hyper_in_list, dim=1) # (B, 4, 256//8)b, c, h, w = upscaled_embedding.shapemasks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w) # (B, 4, 256, 256)# 6. IoU 预测头iou_pred = self.iou_prediction_head(iou_token_out) # (B, 4)# 7. 对象出现头(可选)if self.pred_obj_scores:object_score_logits = self.pred_obj_score_head(hs[:, 0, :]) # (B, 1)else:object_score_logits = 10.0 * iou_pred.new_ones(iou_pred.shape[0], 1) # 默认出现return masks, iou_pred, mask_tokens_out, object_score_logits# -------------------- 辅助函数 --------------------def _get_stability_scores(self, mask_logits):"""计算掩膜稳定性分数 = IoU(upper, lower) 用于动态回退多掩膜。"""mask_logits = mask_logits.flatten(-2)stability_delta = self.dynamic_multimask_stability_deltaarea_i = torch.sum(mask_logits > stability_delta, dim=-1).float()area_u = torch.sum(mask_logits > -stability_delta, dim=-1).float()stability_scores = torch.where(area_u > 0, area_i / area_u, 1.0)return stability_scoresdef _dynamic_multimask_via_stability(self, all_mask_logits, all_iou_scores):"""单掩膜 token 稳定性低时,自动回退到多掩膜中 IoU 最高的那个。"""multimask_logits = all_mask_logits[:, 1:, :, :]multimask_iou_scores = all_iou_scores[:, 1:]best_scores_inds = torch.argmax(multimask_iou_scores, dim=-1)batch_inds = torch.arange(multimask_iou_scores.size(0), device=all_iou_scores.device)best_multimask_logits = multimask_logits[batch_inds, best_scores_inds].unsqueeze(1)best_multimask_iou_scores = multimask_iou_scores[batch_inds, best_scores_inds].unsqueeze(1)singlemask_logits = all_mask_logits[:, 0:1, :, :]singlemask_iou_scores = all_iou_scores[:, 0:1]stability_scores = self._get_stability_scores(singlemask_logits)is_stable = stability_scores >= self.dynamic_multimask_stability_threshmask_logits_out = torch.where(is_stable[..., None, None].expand_as(singlemask_logits),singlemask_logits,best_multimask_logits,)iou_scores_out = torch.where(is_stable.expand_as(singlemask_iou_scores),singlemask_iou_scores,best_multimask_iou_scores,)return mask_logits_out, iou_scores_out(2.1.4)class SAM2Base(torch.nn.Module)中的_encode_new_memory函数
def _encode_new_memory(self,current_vision_feats,feat_sizes,pred_masks_high_res,is_mask_from_pts,
):"""把「当前帧图像特征 + 预测掩膜」编码成**记忆特征**(vision + mask),供后续帧 cross-attention 时读取。主要流程:1. 提取最高层视觉特征并 reshape → BCHW2. 对掩膜 logits 做温度缩放 / 二值化(可选)→ (0,1) 概率图3. 视觉 & 掩膜一起送进 self.memory_encoder → 输出记忆特征与位置编码4. 返回结果,将被缓存到 output_dict 中参数:current_vision_feats (list[Tensor]):backbone 多尺度特征,这里只用最后一层 (HW, B, C)。feat_sizes (list[(H, W)]):对应空间尺寸,用于 reshape。pred_masks_high_res (Tensor):当前帧高分辨率掩膜 logits (B, 1, H_img, W_img)。is_mask_from_pts (bool):True → 这些掩膜来自用户点击(需要更“硬”的边界);False → 跟踪自动生成,保持 soft。返回:tuple(Tensor, list[Tensor]):1. maskmem_features – 记忆视觉特征 (B, C, H/16, W/16)2. maskmem_pos_enc – 对应 2D 位置编码列表(每层一个)"""# 1. 基本维度B = current_vision_feats[-1].size(1) # batch sizeC = self.hidden_dimH, W = feat_sizes[-1] # 最低分辨率特征尺寸(默认 64×64)# 2. 取出最高层视觉特征并 reshape → (B, C, H, W)pix_feat = current_vision_feats[-1].permute(1, 2, 0).view(B, C, H, W)# 3. 非重叠约束(仅 eval 且 batch=1 时启用,防止同一像素被多个对象抢占)if self.non_overlap_masks_for_mem_enc and not self.training:pred_masks_high_res = self._apply_non_overlapping_constraints(pred_masks_high_res)# 4. 温度缩放 + 二值化策略# binarize=True 且来自用户点击 → 直接 >0 截断,保持硬边界# 否则 → sigmoid 成 soft 概率,再可选调 scale/biasbinarize = self.binarize_mask_from_pts_for_mem_enc and is_mask_from_ptsif binarize and not self.training:mask_for_mem = (pred_masks_high_res > 0).float()else:mask_for_mem = torch.sigmoid(pred_masks_high_res)# 5. 可选的 scale & bias 微调(让 soft 掩膜更激进 or 更保守)if self.sigmoid_scale_for_mem_enc != 1.0:mask_for_mem = mask_for_mem * self.sigmoid_scale_for_mem_encif self.sigmoid_bias_for_mem_enc != 0.0:mask_for_mem = mask_for_mem + self.sigmoid_bias_for_mem_enc# 6. 送进记忆编码器# 内部:pix_feat 过 CNN → 与 mask 逐像素乘 → 再出特征 + 位置编码maskmem_out = self.memory_encoder(pix_feat,mask_for_mem,skip_mask_sigmoid=True # 前面已 sigmoid/二值化,不再重复)# 7. 取出结果maskmem_features = maskmem_out["vision_features"] # (B, C, H/16, W/16)maskmem_pos_enc = maskmem_out["vision_pos_enc"] # 列表,每层一个 Tensorreturn maskmem_features, maskmem_pos_enc问题:maskmem_out = self.memory_encoder( pix_feat, mask_for_mem, skip_mask_sigmoid=True ) 这是个函数吗?这个函数在哪呢?
self.memory_encoder(...)并不是一段「独立函数」,而是 SAM2 模型内部的一个子模块(nn.Module)。
在类初始化阶段(__init__或build_sam2_*系列工厂函数里)已经被挂到当前实例上:self.memory_encoder = instantiate(cfg.model.memory_encoder, ...)对应配置文件(例如
sam2_hiera_b+.yaml)里会写明它的实际类名:yaml
memory_encoder:_target_: sam2.modeling.memory_encoder.MemoryEncoder # ← 真正实现的类# 下面还有各种超参:dim、kernel、stride、num_layers ...因此:
代码位置
真正的实现位于
sam2/modeling/memory_encoder.py
里面的MemoryEncoder类。调用关系
你在_encode_new_memory里看到maskmem_out = self.memory_encoder(pix_feat, mask_for_mem, skip_mask_sigmoid=True)等同于
memory_encoder = MemoryEncoder(...) maskmem_out = memory_encoder(pix_feat, mask_for_mem, skip_mask_sigmoid=True)MemoryEncoder 做了什么(简明版)
对
pix_feat做若干卷积 → 得到视觉特征对
mask_for_mem也做若干卷积 → 得到掩膜特征两者逐像素相加 / 拼接 → 再卷积 → 输出
vision_features:用于 cross-attention 的「记忆值」
vision_pos_enc:对应 2D 位置编码(sin-cos + learnable)为什么看不到函数定义
Hydra 的instantiate会根据配置文件里的_target_字符串动态 import 并实例化类,
因此源码里不会直接出现def memory_encoder(...),而是挂在self上的一个 nn.Module 子实例。总结:
self.memory_encoder是一个 nn.Module 对象,真正的类在sam2/modeling/memory_encoder.py,
通过 Hydra 配置动态实例化后供这里调用。
(2.1.4.1)<重点> memory_encoder函数——segment-anything-2/sam2/modeling/memory_encoder.py
class MemoryEncoder(nn.Module):"""记忆编码器:把「当前帧视觉特征」与「预测掩膜」融合成供后续 cross-attention 使用的「记忆特征 + 位置编码」。步骤:1. 掩膜先 sigmoid(若未提前做)→ 下采样到与视觉特征同空间分辨率;2. 视觉特征过 1×1 投影;3. 掩膜与视觉特征逐像素相加;4. 再过「融合器」(若干卷积或 Transformer 层)增强;5. 输出投影(若通道数不一致);6. 生成对应 2D 位置编码(sin-cos + learnable);7. 返回字典 {"vision_features": tensor, "vision_pos_enc": [pos]}。"""def __init__(self,out_dim: int,mask_downsampler: nn.Module, # 把掩膜下采样的模块(通常 2 层卷积)fuser: nn.Module, # 融合器(卷积或 Transformer)position_encoding: nn.Module, # 2D 位置编码器in_dim: int = 256, # 输入视觉特征通道数):super().__init__()# 子模块全部通过 Hydra 配置注入,保持模块化self.mask_downsampler = mask_downsampler# 视觉特征先过 1×1 卷积,与掩膜通道对齐并增加表达能力self.pix_feat_proj = nn.Conv2d(in_dim, in_dim, kernel_size=1)# 融合器:相加后再做若干卷积 / Transformer,让视觉+掩膜信息充分交互self.fuser = fuser# 2D 位置编码器:生成与输出同分辨率的 sin-cos + learnable 位置向量self.position_encoding = position_encoding# 输出维度调整:若 out_dim 与 in_dim 不同,用 1×1 卷积对齐;否则 Identityself.out_proj = nn.Identity()if out_dim != in_dim:self.out_proj = nn.Conv2d(in_dim, out_dim, kernel_size=1)def forward(self,pix_feat: torch.Tensor, # (B, in_dim, H, W) 视觉特征masks: torch.Tensor, # (B, 1, H_img, W_img) 掩膜 logitsskip_mask_sigmoid: bool = False, # True → 外部已 sigmoid/二值化,跳过) -> Tuple[torch.Tensor, torch.Tensor]:"""前向流程:掩膜 → 下采样 → 与视觉特征相加 → 融合 → 输出投影 → 位置编码返回:dict{"vision_features": (B, out_dim, H, W), # 记忆特征"vision_pos_enc": [(B, out_dim, H, W)], # 对应 2D 位置编码(列表包一层)}"""# ========== 1. 掩膜预处理 ==========# 若外部未做 sigmoid,先压缩到 0~1(减少与 GT bool 掩膜的域差异)if not skip_mask_sigmoid:masks = F.sigmoid(masks)# 下采样到与视觉特征相同空间分辨率(默认 1/4 图像大小)masks = self.mask_downsampler(masks) # (B, 1, H, W)# ========== 2. 视觉特征投影 ==========# 若视觉特征在 CPU,先搬到 CUDA(与掩膜同设备)pix_feat = pix_feat.to(masks.device)x = self.pix_feat_proj(pix_feat) # (B, in_dim, H, W)# ========== 3. 逐像素相加(融合入口) ==========x = x + masks # 掩膜作为软注意力权重# ========== 4. 融合器增强 ==========x = self.fuser(x) # 形状不变,通道仍 in_dim# ========== 5. 输出通道调整 ==========x = self.out_proj(x) # -> (B, out_dim, H, W)# ========== 6. 生成 2D 位置编码 ==========pos = self.position_encoding(x).to(x.dtype) # -> (B, out_dim, H, W)# 用列表包一层,与下游接口保持一致(可支持多尺度)# ========== 7. 返回字典 ==========return {"vision_features": x, "vision_pos_enc": [pos]}四、总结
现在我们差不多看完了,这个memory bank是指什么东西?代码里好像没有啊,应该是指memory encoder之后的一些输出?在下一篇中我们先理清一些细节,尤其是输入输出维度。