肾脏癌症图像分类数据集
本数据集包含两类肾脏影像样本:肾脏正常与肾脏癌症。旨在构建高精度的图像分类模型,实现对肾脏肿瘤状态的自动识别与判定。通过对大量标注清晰的医学影像进行深度学习训练,模型能够自动提取肾脏组织的关键特征,区分正常与癌变组织,从而为临床提供辅助诊断依据。该数据集的建立旨在推动深度学习与人工智能技术在肾脏癌症早期筛查与智能诊断中的应用,助力实现医疗影像分析的标准化与智能化。
数据集概览
数据图像:

图1 医疗影像样本图像
数据类型:

表1 数据类型与格式
数据规模:
(1)数据集划分饼图

图3 数据集划分饼图
(2)数据集划分和规模
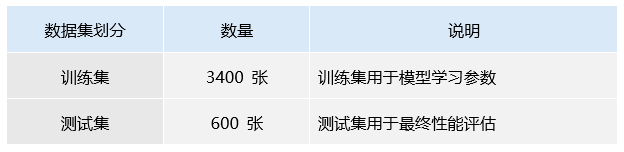
表2 数据集划分和规模
数据集类别
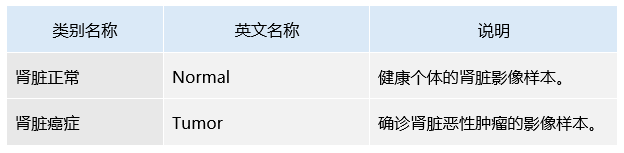
表3 类别定义
数据集来源

表4 数据集来源与说明
数据集用途
本数据集用于肾脏肿瘤影像的分类模型训练与验证,包含两类样本:肾脏正常(Normal)与肾脏癌症(Tumor)。可应用于以下研究与开发方向:
(1)模型训练:支持基于深度学习的图像分类模型(如ResNet50、VGG16、Swin Transformer)进行肾脏影像特征学习。
(2)性能评估:用于测试模型在肾脏肿瘤分类任务中的准确率、召回率、F1值等性能指标。
(3)特征分析:研究肾脏正常与癌变影像在纹理、形态及组织结构等方面的特征差异。
(4)系统开发:为肾脏肿瘤智能诊断系统、医学影像辅助诊断平台及健康筛查系统提供数据支持。
数据集须知
(1)数据来源:基于公开医学影像数据集,仅限科研与教学用途。
(2)数据结构:包含训练集与测试集,分为两类样本(肾脏正常与肾脏癌症)。
(3)文件格式:图像文件为.jpg格式,文件命名与类别严格对应。
(4)使用要求:需遵守医学影像数据隐私与伦理保护相关规定,引用时须注明数据来源。
(5)适用范围:适用于肾脏肿瘤影像识别、分类、特征提取及智能诊断系统研究。
数据集性能
训练与验证准确率和损失曲线:
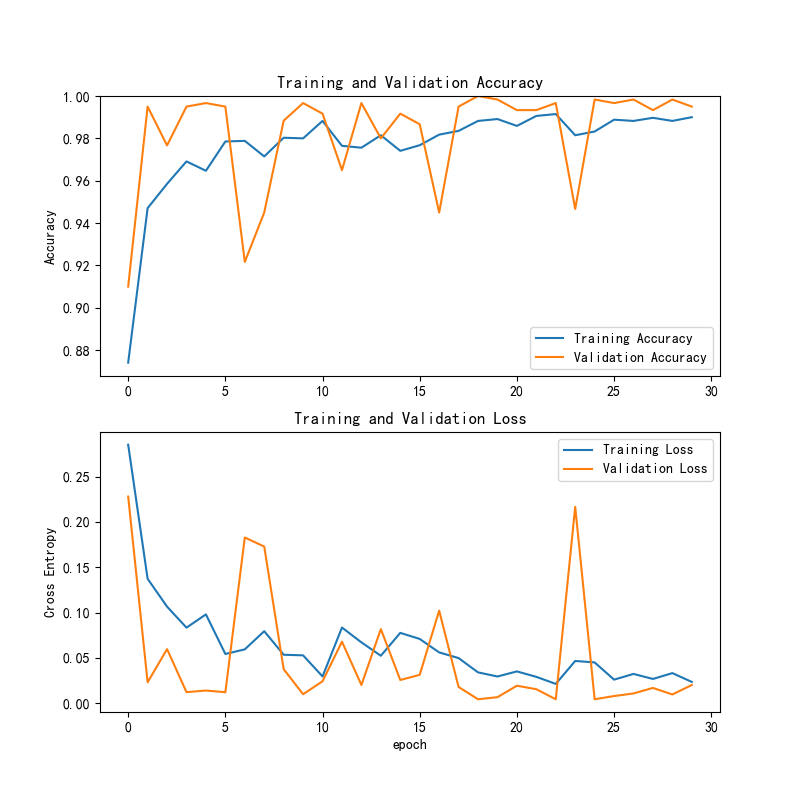
图4 VGG16训练与验证准确率和损失曲线线
该图分为两部分,分别展示了训练过程中的准确率和损失。上方的训练准确率曲线显示,随着训练的进行,准确率逐步提高,并在训练的后期趋于稳定,验证准确率的变化也基本保持一致。下方的交叉熵损失曲线显示,训练损失和验证损失都有明显下降,并在后期趋于平稳,表明模型在优化过程中逐渐减少了误差,未出现明显的过拟合现象。
混淆矩阵热力图:
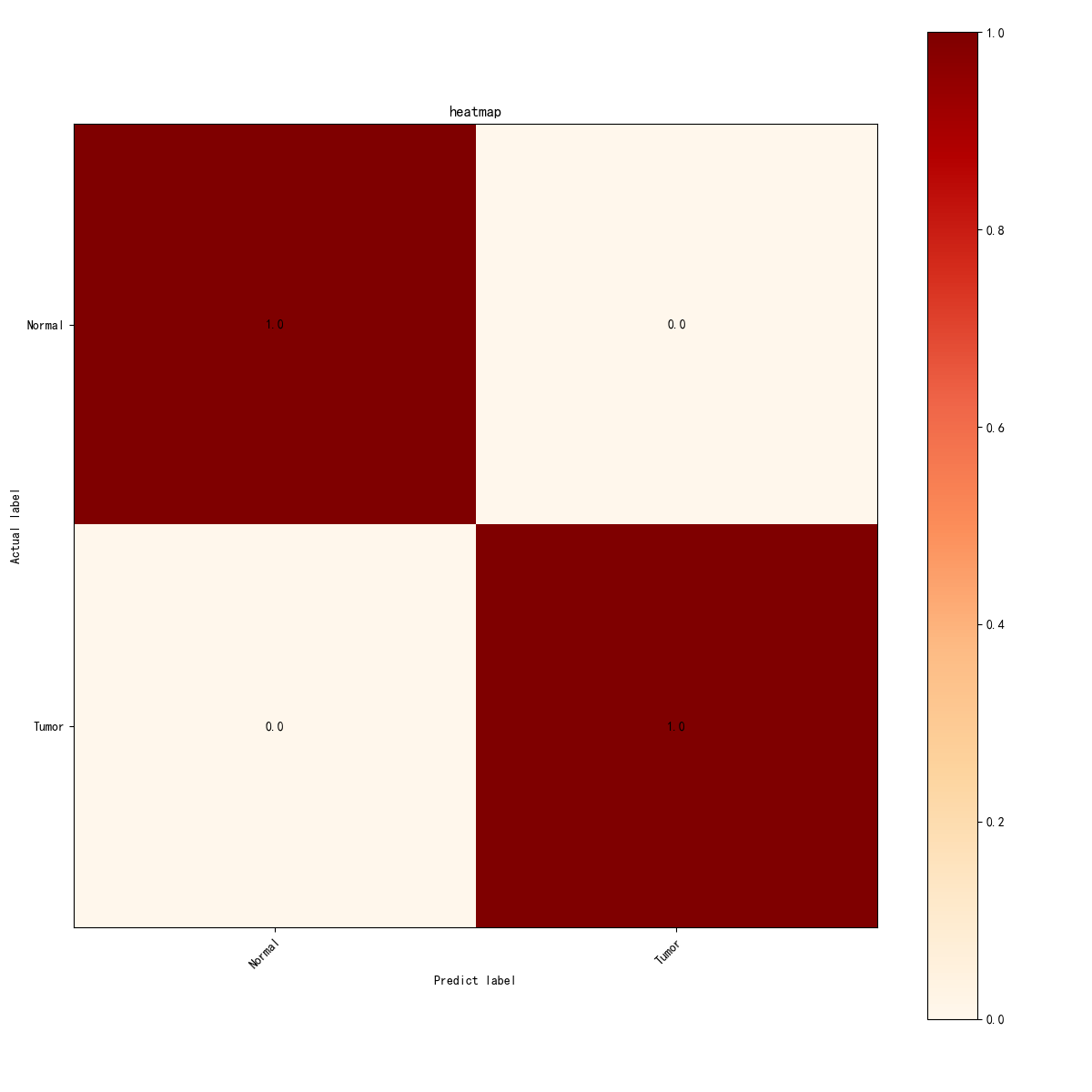
图5 VGG16混淆矩阵热力图
该热图展示了模型在测试数据集上的分类效果。通过混淆矩阵可以看到,所有的预测都完全正确,所有的“正常”和“肿瘤”样本都被准确分类,矩阵中的数值为1.0,表示模型在这两个类别的分类中没有出现任何错误的预测(假阳性或假阴性)。该图进一步验证了模型的高精度和稳定性。
各类认知障碍的分类性能评估:准确率、精确率、召回率与F1分数图
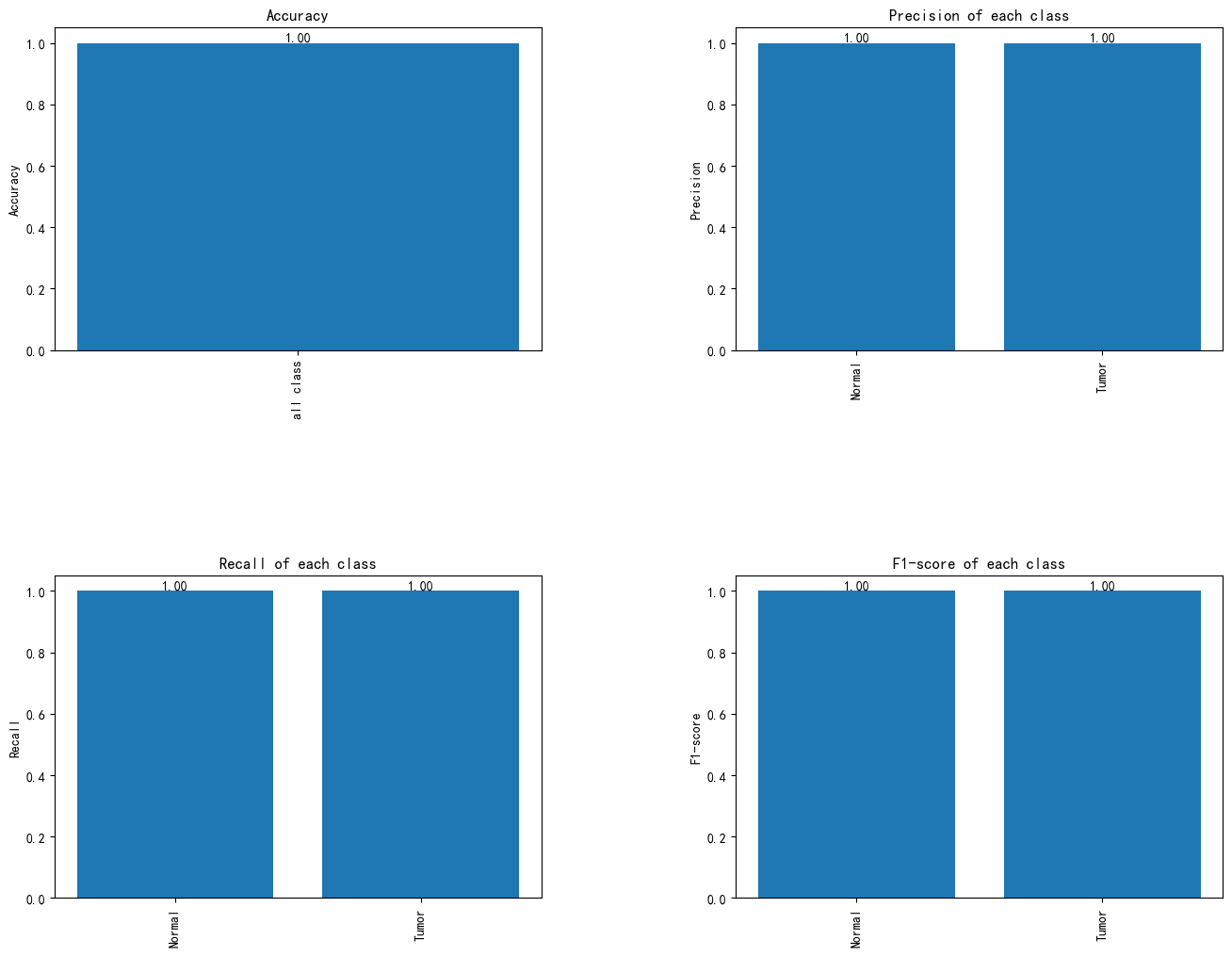
图6 各类认知障碍的分类性能评估:准确率、精确率、召回率与F1分数图
该图分为两部分,分别展示了训练过程中的准确率和损失。上方的训练准确率曲线显示,随着训练的进行,准确率逐步提高,并在训练的后期趋于稳定,验证准确率的变化也基本保持一致。下方的交叉熵损失曲线显示,训练损失和验证损失都有明显下降,并在后期趋于平稳,表明模型在优化过程中逐渐减少了误差,未出现明显的过拟合现象。