贝叶斯统计结合机器学习在术后院内感染危险因素分析中的应用
贝叶斯统计结合机器学习在术后院内感染危险因素分析中的应用
疾病及预后危险因素鉴定是临床研究的核心形式之一,其核心价值在于从繁杂的临床指标中筛选出与结局事件相关的关键因素,并量化其关联强度,为临床干预策略的制定提供坚实的数据支撑。传统研究多采用多因素回归方法,通过报告变量的比值比(OR值)及概率值(P值)明确关联因素。近年来,随着数据分析技术的迭代,危险因素鉴定领域涌现出两类创新方法:其一为机器学习法,通过LightGBM等非线性树形算法结合SHAP(Shapley Additive exPlanations)模型解释技术,可精准呈现变量间的曲线关系并开展阈值分析;其二为贝叶斯分析法,以区间关联概率替代传统P值,更科学地阐释变量间的关联性。上述方法单独或联合应用于医学危险因素分析,可显著提升研究的创新性与说服力。
本文以术后院内感染危险因素分析为实例,系统展示贝叶斯统计与机器学习联合应用的技术路径及实践价值。
术后院内感染是临床诊疗中亟待解决的关键问题,不仅延长患者住院周期、增加医疗负担,更严重影响患者预后质量。精准识别院内感染的危险因素,是开展针对性预防干预、降低感染发生率的核心前提。然而,传统统计方法在处理多指标关联、挖掘非线性关系时存在明显局限,难以适配复杂医疗数据的分析需求。本研究基于82例择期手术患者(涵盖胃肠外科、神经外科及直肠外科手术类型)的前瞻性队列数据,创新性构建“贝叶斯统计+机器学习”融合分析框架,成功突破传统方法瓶颈,清晰揭示住院时长(LOS)、上臂肌肉面积(AMA)等关键指标与术后院内感染的关联规律,为临床实践提供科学依据。该研究构建的“数据采集-指标筛选-关联量化-阈值验证”完整分析体系,可为同类术后并发症危险因素研究提供可复用的技术范式,以下详细阐述其核心流程与技术细节。
本研究遵循“数据采集-指标筛选-关联量化-阈值验证”的逻辑主线,整合多种前沿算法构建分析流程,确保研究结果的精准性与可靠性,具体实施路径如下:
1. 数据基础:多维度指标体系构建与采集
本研究采用“主题导向”的数据采集策略,围绕“营养状态与术后院内感染关联”核心科学问题,系统收集82例择期手术患者的多维度数据,为后续分析提供全面支撑,其数据设计思路可为同类研究提供借鉴。
• 结局指标:以术后30天内院内感染发生情况为核心结局,涵盖手术切口感染、尿路感染、呼吸道感染、血管导管插入部位感染及败血症5类常见感染类型,最终确认12例患者发生院内感染;
• 潜在危险因素:构建“一般情况-营养状态-诊疗特征”三维指标体系,包括一般资料(年龄、2型糖尿病史、高血压史、吸烟饮酒史、ASA-PS评分)、营养指标(体质量指数BMI、上臂肌肉面积AMA、上臂脂肪面积AFA,其中AMA通过上臂围、皮褶厚度测量结合性别校正公式计算,AFA由上臂围与AMA推导得出)及住院时长(LOS)等共计15项指标。
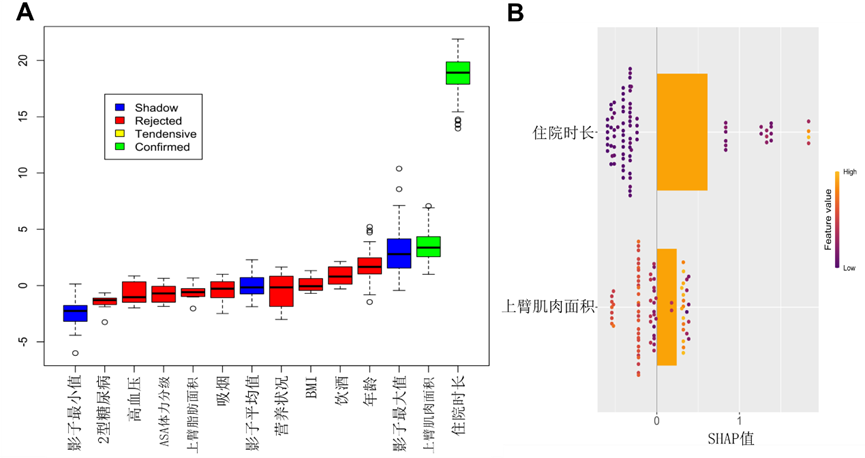
2. 指标初筛:Boruta算法精准锁定核心关联因素
传统特征选择方法常以模型拟合优度为导向,易遗漏潜在关联指标。本研究采用基于随机森林的Boruta算法,以“全面筛选与因变量相关特征”为核心目标,通过构建“真实特征+随机影子特征”的双重验证体系,有效规避过拟合风险。经算法迭代筛选,最终从15项潜在危险因素中精准锁定住院时长(LOS)、上臂肌肉面积(AMA)为与术后院内感染显著关联的核心因素,BMI、AFA、年龄等指标因关联性较弱被排除,为后续深度分析聚焦研究重点。
3. 关联量化:贝叶斯逻辑回归与SHAP分析双重验证
(1)贝叶斯逻辑回归:突破频率派局限,精准量化关联强度
针对临床研究中常见的“样本量较小、先验信息不足”问题,本研究摒弃传统频率派多因素回归方法的局限,采用无信息先验贝叶斯逻辑回归模型进行关联量化。通过哈密顿蒙特卡洛(MCMC)算法进行抽样模拟(设置4条独立链,每条链含1000次预热迭代及20000次抽样迭代),经Rhat值(均为1.00)及有效样本量检验确认模型收敛稳定后,以OR值及95%可信区间(95%CI)量化指标与感染结局的关联强度,结果如下:
• 住院时长(LOS):OR=1.42(95%CI:1.19~1.77),区间关联概率100%(95%CI完全位于>0区间),提示住院时间每增加1单位,术后院内感染风险显著升高42%,为明确的独立危险因素;
表2 贝叶斯逻辑回归分析
OR 95% CI 区间关联概率 Rhat Bulk_ESS Tail_ESS
AMA 0.95 0.84~1.05 0.83(<0区间) 1.00 1970 2100
AFA 1.04 0.91~1.18 0.73(>0区间) 1.00 1639 1877
BMI 0.92 0.63~1.32 0.69(<0区间) 1.00 1593 2038
Length_of_stay 1.42 1.19~1.77 100(>0区间) 1.00 2359 1734
(2)SHAP分析:可视化指标贡献,解释非线性关系
采用Lightgbm算法构建二分类模型,通过SHAP(Shapley Additive exPlanations)分析,将各指标对感染结局的贡献转化为可解释的SHAP值,结合散点图直观展示指标变化对感染风险的影响:
• 贡献度对比:LOS平均SHAP值为0.614,AMA平均SHAP值为0.241,明确LOS对感染的贡献远高于AMA;
• 关系可视化:SHAP散点图清晰显示,LOS与感染风险并非简单线性关系,AMA与感染更呈现复杂非线性关联,为后续阈值分析提供依据。
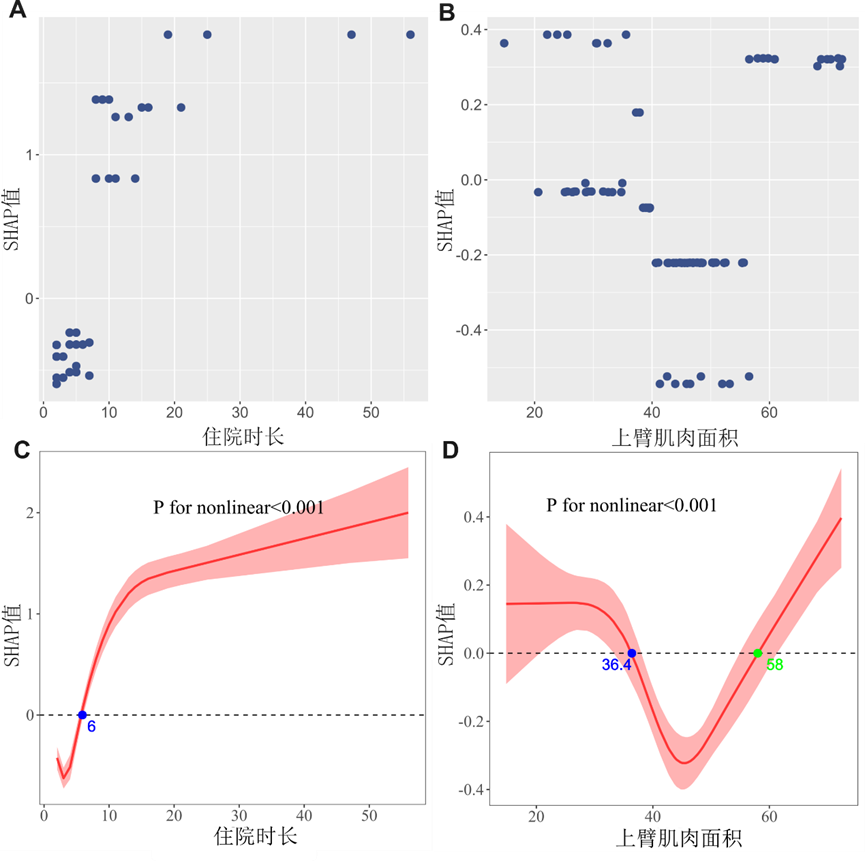
4. 阈值验证:立方样条回归锁定风险临界点
为明确指标“何时开始显著影响感染风险”,采用立方样条回归拟合LOS、AMA与SHAP值的曲线关系,以SHAP值=0为阈值节点,结合逻辑回归验证分组有效性:
• 住院时长(LOS):曲线显示LOS超过6天后,SHAP值急剧上升,感染可能性大幅升高;随后按“LOS≤6天”“LOS>6天”分组,OR=47.3(95%CI:5.4~411.6,P<0.001),验证6天为感染风险临界值;
• 上臂肌肉面积(AMA):曲线提示AMA在36.4-58cm²区间时,SHAP值接近0,感染风险最低;当AMA<36.4cm²(肌肉减少)或AMA>58cm²时,感染风险均上升,按此区间分组后OR=3.53(95%CI:0.72-17.3),与AMA本身弱关联特征一致。
本研究所有分析均通过R语言4.3.2实现,核心依赖R包包括boruta(特征筛选)、brms(贝叶斯回归)、shapviz(SHAP分析)、splines(立方样条回归)等。提供医学数据分析、生信分析、深度学习数据分析,欢迎咨询。