AI研究-110 DeepSeek-OCR 原理剖析|上下文光学压缩、Gundam 动态分辨率与并发预期 附代码
TL;DR
- 核心:DeepSeek-OCR 走 LLM-centric 的“上下文光学压缩”,把整页图像压成少量视觉 token;支持四档原生分辨率(Tiny/Small/Base/Large)与 Gundam 动态分辨率(局部+全局)。〔来源:官方 README/模型卡〕
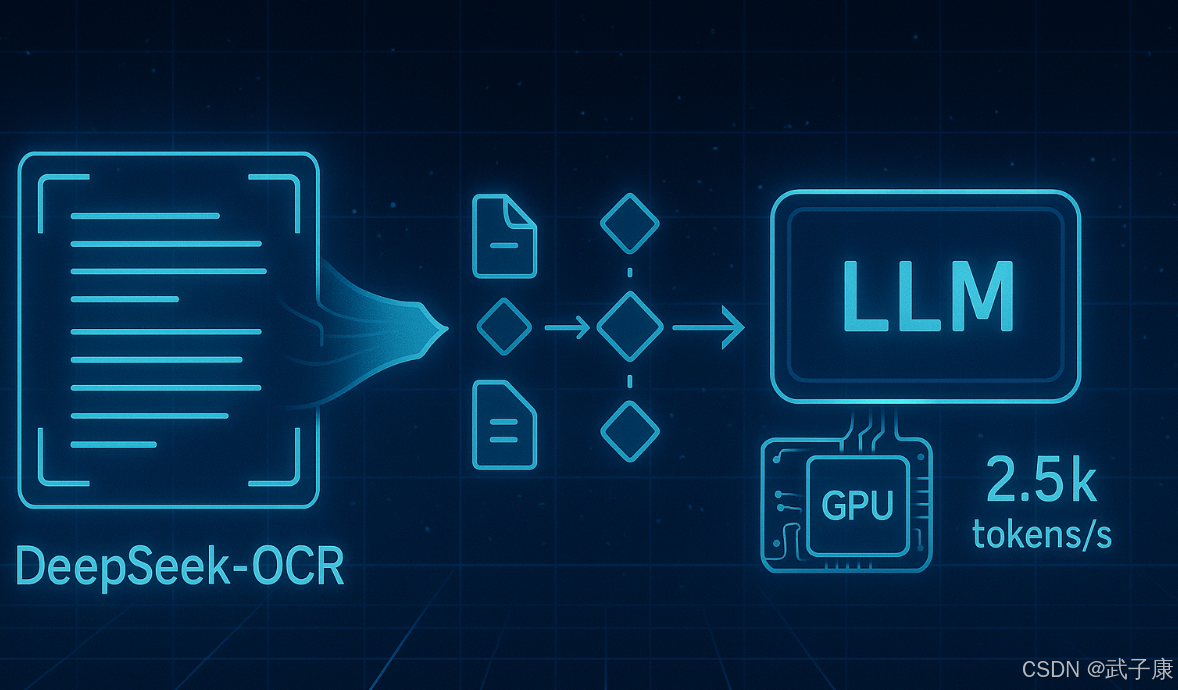
- 工程含义:更少视觉 token ⇒ 同显存下可放入更多页/更长上下文、并发更友好;不同模式在结构正确率 ↔ 速度之间需场景化取舍。〔官方文档强调模式差异与参数影响〕
- 参考值:vLLM 跑 PDF 的并发≈2.5k tokens/s(A100-40G)为 README 给出的参考,非你本机承诺。〔vLLM 小节原文注释〕
版本矩阵与环境
| 组件 | 已验证/建议 | 备注 |
|---|---|---|
| Python | 3.12.9 | 官方示例环境 |
| CUDA | 11.8 | 与 PyTorch 2.6.0 搭配 |
| PyTorch | 2.6.0 | HF 路线示例 |
| Transformers | 4.46.3(HF 路线) | vLLM 路线参考 README |
| Flash-Attn | 2.7.3 | 官方示例建议,可关但吞吐会降 |
| vLLM | 0.8.5(cu118 whl) | README 指向 whl;Release 说明 Bump 到 4.51.x |
| 模型规模 | 3B / BF16 | HF 模型卡标注 |
| 许可 | MIT | 仓库/模型卡一致 |
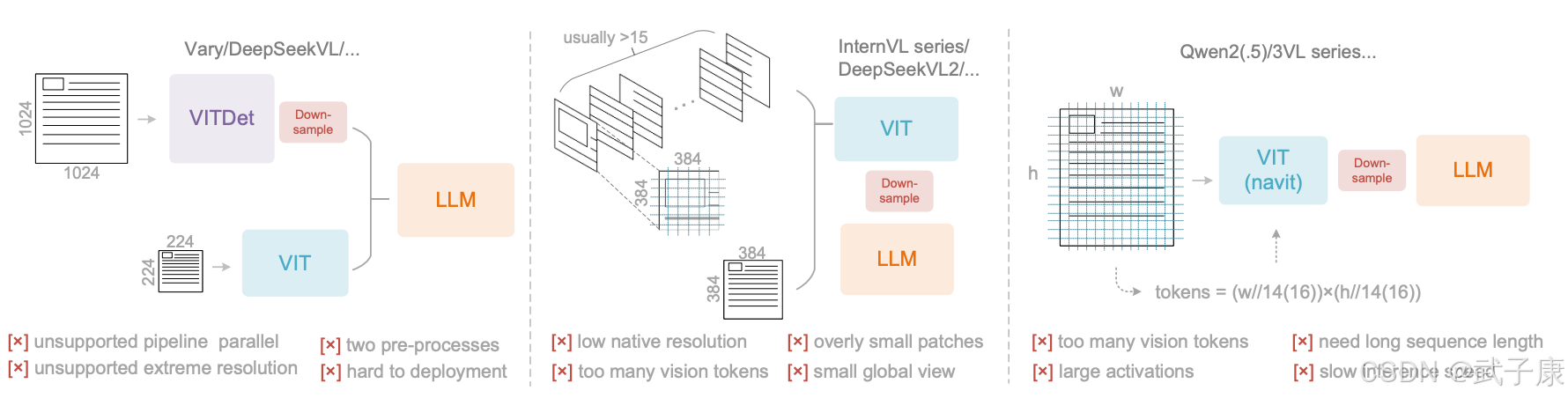
它到底在解决什么?
传统 OCR 多为检测→识别→版面还原三段式,遇到长文档/复杂版面时,上下文受限、结构恢复脆弱。DeepSeek-OCR 的切入点是先把页面压到少量视觉 token,再用 LLM 做生成式理解(Markdown、图表描述、定位等),把“结构化还原”并入语言模型的生成。
官方术语叫 Contexts Optical Compression。
视觉 token 与分辨率模式
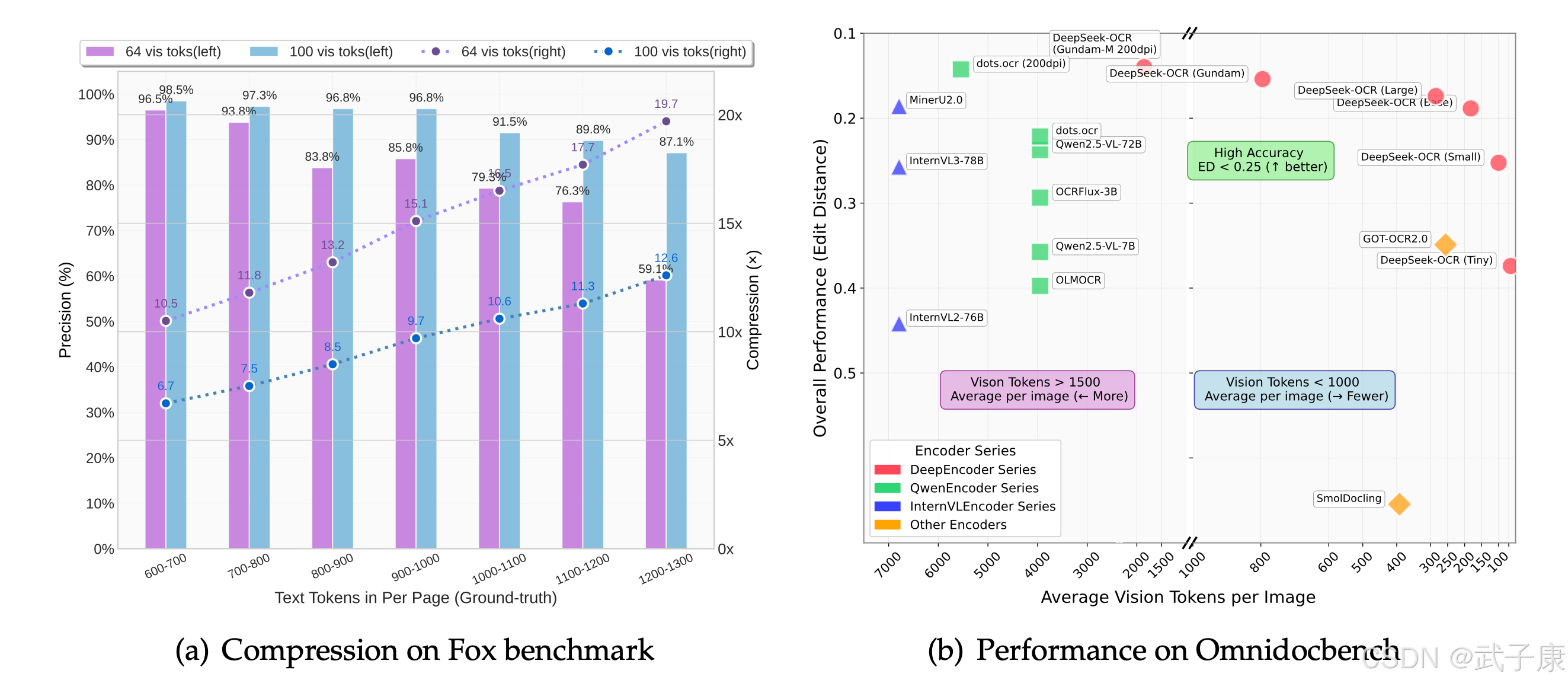
原生(Native) 四档与 动态(Gundam) 是它的关键设计点:
- Native(视觉 token 固定规模):
- Tiny:512×512(64 视觉 token)
- Small:640×640(100)
- Base:1024×1024(256)
- Large:1280×1280(400)
- Gundam 动态分辨率:n×640×640 + 1×1024×1024 的局部+全局拼接,适配报刊/多栏/表格/混排。
实操建议:纯文本扫描多用 Small/Base;复杂版面优先 Gundam。以上模式/数值以官方文档为准。
DeepSeek-OCR的核心创新在于提出“上下文光学压缩”这一理念 。
简单来说,就是利用视觉模式来高效编码文本信息:将长文本渲染成图像,由模型“阅读”该图像来重构文本。这听起来有悖常规——毕竟传统观点里,图像输入文本会引入额外噪声和开销。然而DeepSeek团队发现,对于超长文本,视觉表示反而更划算 。
原因在于:图像天然包含文字的空间布局和形状信息,能够以更少的编码单元承载大量字符 。例如,一整页2000字的文本可能需要数千个字词token表示,但渲染成清晰图片后,用视觉patch表示可能只需几百个token 。这相当于把线性的文本序列“打包”进二维像素阵列中,用图像压缩的方式存储。有点类似人类快速浏览书页:大脑形成页面视觉记忆,再从中提取文字,而非逐字阅读。
DeepSeek-OCR正是基于此逆向思维,探索视觉-文本压缩范式的可行性 。通过特殊设计的模型结构,它成功证明了视觉token可以比文本token更高效地存储长文本上下文 。
值得一提的是,DeepEncoder支持多种分辨率/压缩模式,以适应不同应用需求 。从“Tiny”(输入512×512像素,输出仅64个token)到“Base”(1024×1024,256 token)再到“Gundam”模式(对超大页面动态分块,输出接近800 token) ——同一模型可以灵活调整“压缩强度”。
这意味着对于文字稀疏的小页面,可以使用极强的压缩以提升速度;而对于特别复杂的大版面,则可以选择适当降低压缩、分块处理以保留细节。这种多分辨率设计在业界尚属首次,为视觉模型处理各种尺寸文档提供了便利 。开发者在推理时只需设置相应参数(如base_size和crop_mode等 ),即可切换模式,非常实用。
推理栈与接口
把页面压成少量视觉 token 后,单位显存可承载更多样本/更长上下文,所以在批/并发上更友好;但单样本的绝对 tokens/s还受模型规模、Flash-Attn、I/O、分辨率模式影响。官方示例里提到 A100-40G PDF 并发约 ~2500 tokens/s,可做对齐参考,不是各机型的承诺值。
数据来源自官方论文

Hugging Face Transformers(GPU 建议)
-
环境:PyTorch 2.6.0、Transformers 4.46.3、Flash-Attn 2.7.3(BF16)。
-
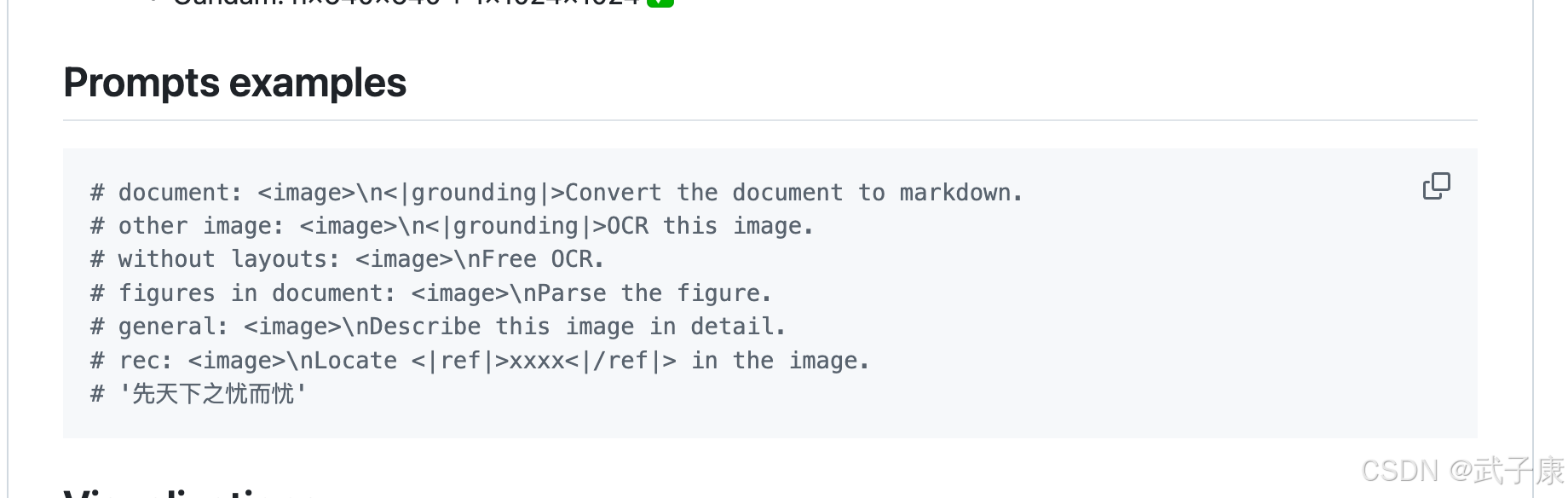
常用 Prompt:
document: <image>\n<|grounding|>Convert the document to markdown.
free OCR: <image>\nFree OCR.
figures: <image>\nParse the figure. -
模式与参数(视觉 token 固定规模):
Tiny 512×512(64)|Small 640×640(100)|Base 1024×1024(256)|Large 1280×1280(400)
Gundam:base_size=1024, image_size=640, crop_mode=True(局部+全局,复杂版式优先) -
最小示例(与你现有一致,略)
vLLM(并发/PDF 处理)
- 步骤:进入
DeepSeek-OCR-master/DeepSeek-OCR-vllm/,按需修改config.py的输入/输出路径,然后:
python run_dpsk_ocr_image.py(图片流式)|python run_dpsk_ocr_pdf.py(PDF 并发) - README 原文提示:如果你希望 vLLM 和 Transformers 代码在同一环境跑,看到
vllm 0.8.5+cu118 requires transformers>=4.51.1这样的安装报错不必紧张(可共存运行)。
Transformers 路线
(建议 GPU):模型卡给出环境与最小用法(PyTorch 2.6.0、Transformers 4.46.3、Flash-Attn 2.7.3,BF16);Prompt 示例包含“文档转 Markdown”“Free OCR”“Parse the figure”等。
from transformers import AutoModel, AutoTokenizer
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
model_name = 'deepseek-ai/DeepSeek-OCR'tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, _attn_implementation='flash_attention_2', trust_remote_code=True, use_safetensors=True)
model = model.eval().cuda().to(torch.bfloat16)# prompt = "<image>\nFree OCR. "
prompt = "<image>\n<|grounding|>Convert the document to markdown. "
image_file = 'your_image.jpg'
output_path = 'your/output/dir'res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results = True, test_compress = True)
vLLM 路线
仓库内置图片/ PDF 并发脚本与参数位,官方 README 注明了并发参考值。
注意官方做了提示:(if you want vLLM and transformers codes to run in the same environment, you don’t need to worry about this installation error like: vllm 0.8.5+cu118 requires transformers>=4.51.1)
如果你希望 vLLM 和 transformers 的代码在同一个环境中运行,那么你不需要担心类似下面的安装错误:
vllm 0.8.5+cu118 requires transformers>=4.51.1
意思是:只要它们能共存并正常运行,这个安装提示不是严重问题,可以忽略。
cd DeepSeek-OCR-master/DeepSeek-OCR-vllm
图片输入:
python run_dpsk_ocr_image.py
PDF输入:
python run_dpsk_ocr_pdf.py
benchmark:
python run_dpsk_ocr_eval_batch.py
局限与开放问题
- Gundam 的裁剪/拼接策略带来调参成本(窗口大小、全局帧的放置等)。
- 不同模板(发票、论文、试卷)误差分布不同:表格单元合并、脚注/公式旁注易出错。
- 训练/数据细节尚未完整公开(模型卡显示“Citation/论文 coming soon”)。
数据来源

实操提示
Prompt 模式
PS:(来自官方示例)
document: <image>\n<|grounding|>Convert the document to markdown.
free OCR: <image>\nFree OCR.
figures: <image>\nParse the figure.
- 环境组合:Python 3.12.9 / CUDA 11.8 / PyTorch 2.6.0 / Transformers 4.46.3 / Flash-Attn 2.7.3;模型以 BF16 / 3B 公开。
数据来源 依赖版本
选型建议
- 只做纯文本 OCR:Small/Base,追求速度与稳定。
- 版面/表格密集:Gundam,追求结构正确率,吞吐次之。
- 并发优先:优先调批/并发与 I/O,而非一味加大分辨率。
复现实验
克隆项目
git clone https://github.com/deepseek-ai/DeepSeek-OCR
cd DeepSeek-OCR
虚拟环境
可以选择conda
conda create -n deepseek-ocr python=3.12.9 -y
conda activate deepseek-ocr
可以选择 pyenv
python3 -m venv env
source env/bin/activate
安装依赖
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118
pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl
pip install -r requirements.txt
pip install flash-attn==2.7.3 --no-build-isolation
这里注意,安装 vllm 的时候,需要下载对应的 whl:
https://github.com/vllm-project/vllm/releases/tag/v0.8.5
用wget可以直接下载:
wget https://github.com/vllm-project/vllm/releases/download/v0.8.5/vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl
下载完成后,安装是:
pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl
将其他的依赖都安装完:
测试图片
查看目录
我目前在 autodl 的目录下,你也应该注意自己的目录:
pwd
/root/autodl-tmp/wzk/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm
修改配置
目录是:DeepSeek-OCR-master/DeepSeek-OCR-vllm/config.py
vim config.py
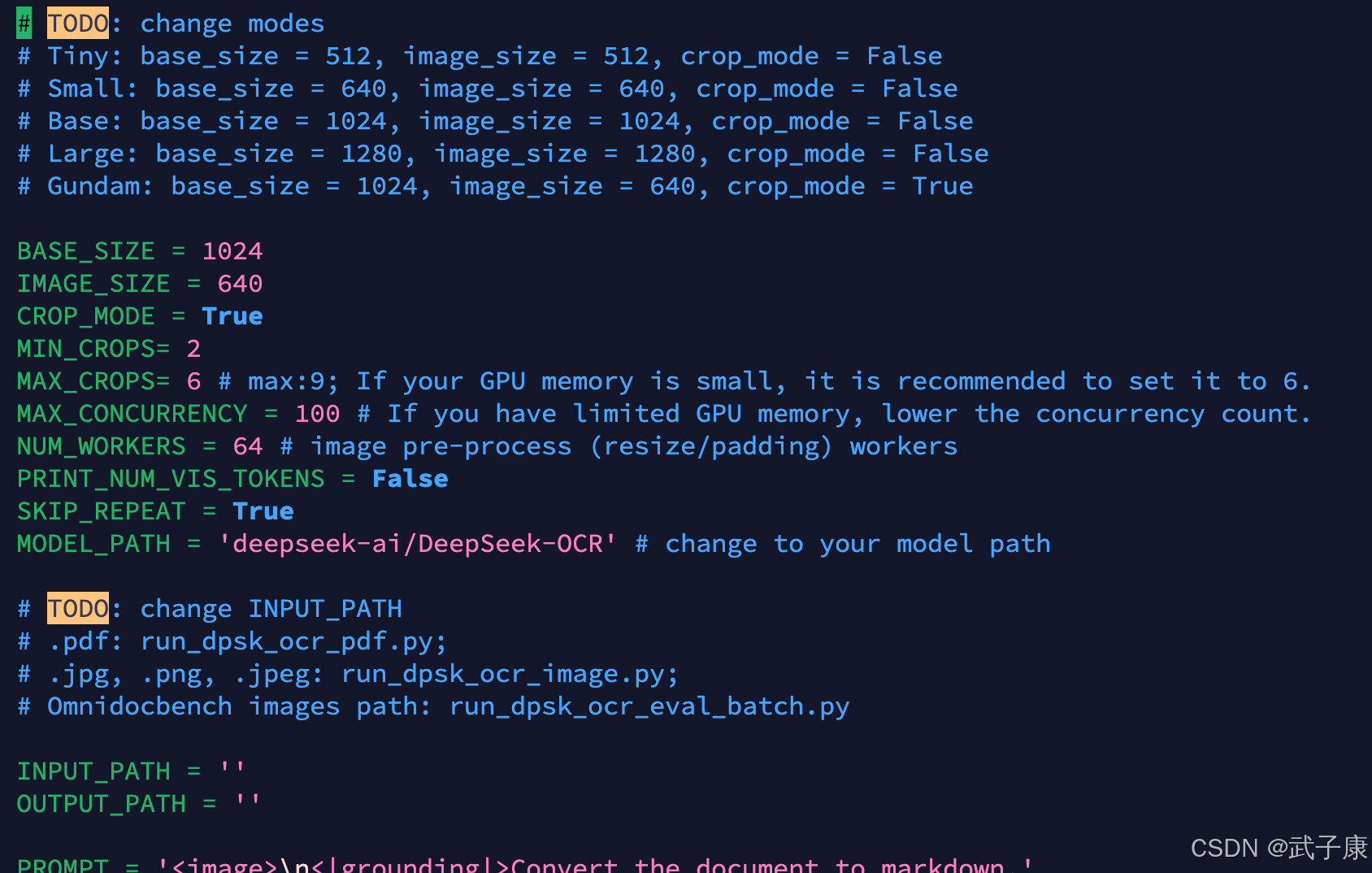
我们修改这两行:
INPUT_PATH = './1.png'
OUTPUT_PATH = './outputs'
然后对应的目录准备好目录和图片。
运行脚本
python run_dpsk_ocr_image.py
DeepSeek-OCR Q & A
多 GPU 会线性提速吗?
价值主要在容量/并发稳定性,单次提速有限;先用并发/批处理衡量收益。
能否输出 Markdown/定位?
可以,官方给了对应 Prompt 片段。
数据来源
参数规模/数值类型?
模型卡显示 3B / BF16。
数据来源
必须用 Flash-Attn 吗?
官方示例使用并建议;不满足也能跑,吞吐会受影响。
vLLM 的 ~2500 tokens/s 是不是我的机器也能到?
不是,这是官方在 A100-40G 的参考。

数据来源:DeepSeek-OCR 官方论文
是否使用大语言模型进行协同?
虽然DeepSeek-OCR本质上自己就包含一个语言模型作为解码器,但一个有趣的问题是:它能否与外部的大语言模型协同工作?从设计上看,DeepSeek-OCR已经集成视觉和语言于一体(即所谓Visual-Language模型),因此并不需要再额外对接GPT这类模型来完成OCR任务。然而,它的确可以作为其它LLM的“前端模块”使用:例如我们可以用DeepSeek-OCR将超长文档压缩成少量视觉token,然后把这些token对应的文本摘要交给另一个更大的LLM继续推理。这其实就是上下文光学压缩的应用场景之一 。
因此可以说,DeepSeek-OCR不是简单调用某个现有LLM,而是自带一个定制的小型LLM(3B-MoE)专门用于OCR。
当然,社区中也有人尝试将DeepSeek-OCR与其他模型结合,例如使用DeepSeek-OCR读取文档后,把结果传入Claude等问答模型以实现文档问答 。这种模块化协同属于应用层集成,而非模型内部直接使用了别的LLM。
其他系列
Ollama 本地部署实战 | 3 分钟安装 & 多卡GPU部署 & 运行实战 【2025版】
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究,持续打造实用AI工具指南!
AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接