Redis的Hash数据结构底层实现
在Redis的五大基本数据类型中,Hash类型因其“键值对嵌套”的特性,成为存储对象类数据的首选——比如存储用户信息、商品属性、配置参数等。但你是否好奇:同样是Hash类型,存储少量字段和大量字段时,Redis的底层实现是否一致?答案是否定的。为了兼顾内存利用率和操作性能,Redis为Hash类型设计了ziplist(压缩列表)和hashtable(哈希表)两种动态切换的编码方式。本文将深入剖析这两种编码的底层逻辑、适用场景及转换规则,带你理解Redis设计背后的“取舍智慧”。
一、核心问题:为何Hash需要两种编码方式?
Redis作为内存数据库,“内存效率”和“操作性能”是永恒的核心诉求。若为Hash类型仅设计一种编码方式,会陷入明显的矛盾:
- 仅用ziplist:虽然内存紧凑,但查询需遍历所有字段,当字段数量达到上千个时,查询性能会急剧下降;
- 仅用hashtable:虽然查询性能优异,但哈希表的数组、链表节点会带来大量指针开销,存储少量字段时内存浪费严重。
因此,Redis采用“按需切换”的策略:小数据场景用ziplist节省内存,大数据场景用hashtable保证性能,完美平衡了内存与性能的矛盾。
二、ziplist编码:小数据场景的“内存王者”
ziplist是Redis专为“小数据紧凑存储”设计的底层结构,并非传统意义上的链表,而是一块连续的内存空间。当Hash类型的字段数量少、字段值小时,Redis会优先选择ziplist编码。
2.1 底层结构:连续内存的紧凑排列
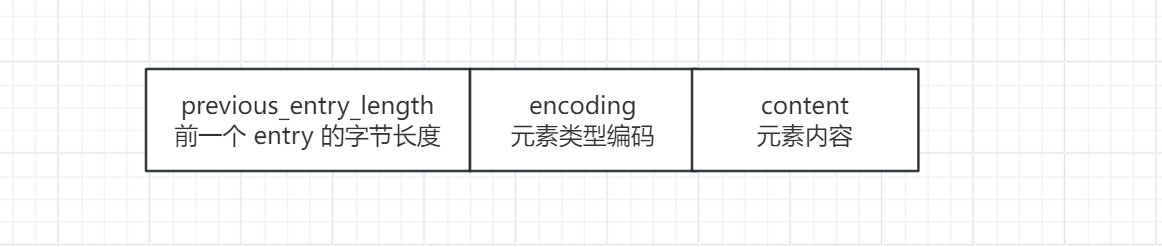
ziplist 是一块连续的内存空间,按以下格式存储数据:

每个 entry 存储一个字段(field)和值(value),格式为:
优势
ziplist的核心特点是“连续存储、无指针开销”,其整体结构由“头部信息+多个entry(字段-值对)+尾部标记”组成。对于Hash类型而言,ziplist中的entry会按照“字段1→值1→字段2→值2→……”的顺序紧凑排列,每个entry包含“长度信息+编码类型+实际数据”三部分。
这种结构的优势在于:所有数据都存储在连续内存中,无需像链表那样用指针连接节点,极大减少了内存冗余;同时,连续的内存布局能提升CPU缓存命中率,读取数据时效率更高。
2.2 核心优势:极致的内存利用率
ziplist编码的核心竞争力在于“内存紧凑”,具体优势可总结为两点:
- 内存开销极低:无指针开销,且通过动态编码(根据数据长度选择不同的长度字段)进一步压缩内存。例如存储“name:张三”这样的短字段值对,ziplist的内存占用仅为hashtable的1/3~1/2;
- 缓存友好:连续内存存储使得CPU在读取数据时,能一次性将多个字段-值对加载到缓存中,减少缓存缺失的概率,提升读取性能。
2.3 致命缺陷:性能随数据量增长而下降
ziplist的连续内存结构也是一把双刃剑,带来了两个无法回避的缺陷:
- 查询性能差:由于没有索引,查询某个字段时必须从ziplist头部开始遍历,直到找到目标字段,时间复杂度为O(n)。当字段数量达到数百个时,查询延迟会明显增加;
- 插入/删除效率低:在中间位置插入或删除字段时,需要移动后续所有数据以保证内存连续性,时间复杂度同样为O(n)。若频繁修改数据,会产生大量内存移动开销。
2.4 触发条件与适用场景
Redis通过两个配置参数控制ziplist编码的触发(默认值适用于大多数场景,可根据业务调整):
hash-max-ziplist-entries:Hash的字段数量≤512个;hash-max-ziplist-value:每个字段的键和值的长度≤64字节。
适用场景:小数据集、低修改频率的对象存储,例如:
- 存储用户基础信息:
HSET user:1001 name "张三" age "25" gender "男"(3个字段,均为短值); - 存储商品精简属性:
HSET goods:100 name "小米耳机" price "99" stock "1000"(字段少且值短)。
三、hashtable编码:大数据场景的“性能王者”
当Hash类型的字段数量过多或字段值过大时,ziplist的性能缺陷会被无限放大。此时Redis会自动切换为hashtable编码,通过“数组+链表”的经典哈希表结构,保证查询和修改的高效性。
3.1 底层结构:数组+链表的经典实现
Redis的hashtable基于“链地址法”解决哈希冲突,核心结构由dict(哈希表整体控制)、dictht(实际哈希表)、dictEntry(链表节点)三级组成,核心结构体定义如下:
// 哈希表整体控制结构
typedef struct dict {dictType *type; // 类型特定函数(如键值复制、释放)void *privdata; // 私有数据dictht ht[2]; // 两个哈希表,用于rehash(扩容/缩容)long rehashidx; // rehash索引(-1表示未进行rehash)unsigned long iterators; // 迭代器数量(防止rehash时迭代出错)
} dict;// 实际的哈希表结构
typedef struct dictht {dictEntry **table; // 哈希表数组(每个元素是链表头指针)unsigned long size; // 哈希表数组大小(总是2的幂次)unsigned long sizemask; // 哈希掩码(size-1,用于计算索引)unsigned long used; // 已存储的节点数量
} dictht;// 哈希表节点(链表节点)
typedef struct dictEntry {void *key; // 字段(field)union { // 值(value)void *val;uint64_t u64; // 整数优化存储int64_t s64;} v;struct dictEntry *next; // 下一个节点指针(解决哈希冲突)
} dictEntry;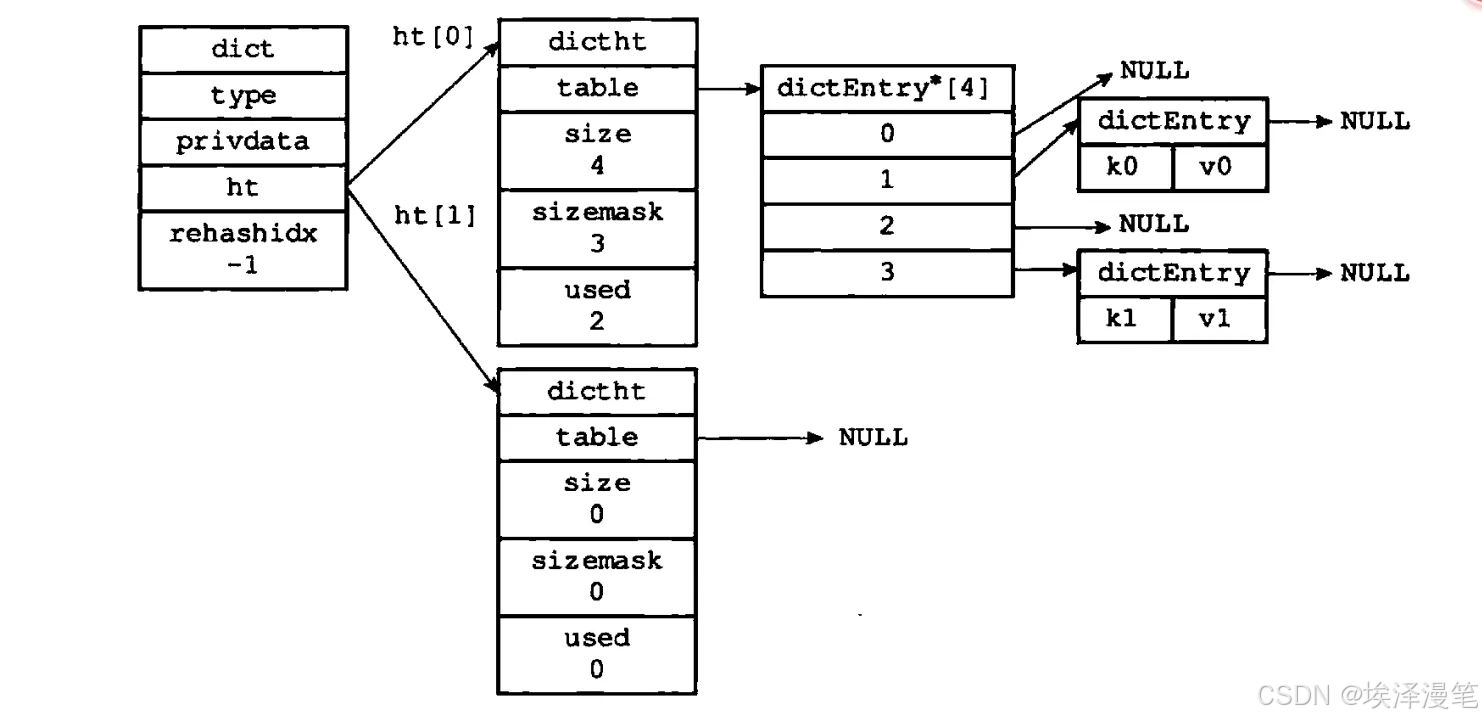 关键设计细节:
关键设计细节:
- 双哈希表设计:
ht[0]用于正常存储,ht[1]用于rehash(扩容/缩容)时临时存储,避免rehash期间性能抖动; - 哈希掩码:通过
sizemask = size - 1计算键的索引(替代取模运算,提升效率),要求size必须是2的幂次; - 整数优化:若值为整数,直接存储在
u64/s64中,无需额外分配内存。
3.2 核心优势:高效的查询与修改
hashtable编码的核心竞争力在于“O(1)级别的平均操作复杂度”,具体优势:
- 查询性能优异:通过键的哈希值计算索引,直接定位到数组位置,再遍历链表(冲突时)找到目标节点,平均时间复杂度为O(1);
- 插入/删除高效:同样通过哈希值定位位置,插入时只需在链表头部添加节点,删除时只需修改链表指针,平均时间复杂度为O(1);
- 扩展性好:支持动态扩容(当负载因子≥1时)和缩容(当负载因子≤0.1时),通过rehash机制保证哈希表的稀疏度,避免链表过长导致性能下降。
3.3 局限性:内存开销较高
hashtable的高效性能是以牺牲内存为代价的,主要内存开销来自两方面:
- 指针开销:哈希表数组的每个元素是链表头指针,每个链表节点也需要存储prev/next指针(64位系统中每个指针占8字节);
- 稀疏存储:为保证哈希表性能,扩容时会预留一定的空闲空间(负载因子控制在1以内),导致部分内存未被利用。
3.4 触发条件与适用场景
当满足以下任一条件时,Redis会自动将Hash的编码从ziplist转为hashtable:
- Hash的字段数量超过
hash-max-ziplist-entries(默认512); - 任意一个字段的键或值长度超过
hash-max-ziplist-value(默认64字节)。
适用场景:大数据集、高频修改或查询的对象存储,例如:
- 存储商品详细属性:
HSET goods:100 name "iPhone 15" price "5999" desc "A17 Pro芯片,6.7英寸屏幕..." 参数 "{"cpu":"A17","screen":"6.7"}"(字段值过长); - 存储用户行为标签:
HSET user:100 tags "篮球" "音乐" "旅游" ...(标签数量超过512个)。
四、编码转换与核心对比
4.1 编码转换规则
Redis的Hash编码转换是“单向不可逆”的,具体规则:
- ziplist → hashtable:当字段数量或字段值超过阈值时,自动触发转换,转换过程是创建新的hashtable,将ziplist中的字段-值对逐个迁移过去;
- hashtable → ziplist:一旦转为hashtable编码,即使后续删除字段使数据量降至阈值以下,也不会自动转回ziplist(需手动删除Hash后重新创建才能触发ziplist编码)。
4.2 两种编码核心对比
为了更清晰地展示两种编码的差异,我们从核心特性、性能、适用场景等维度进行对比:
特性 | ziplist(压缩列表) | hashtable(哈希表) |
内存占用 | 低(连续存储,无指针开销) | 高(指针+稀疏存储) |
查询性能 | O(n)(遍历查找) | O(1)(平均,哈希定位) |
插入/删除性能 | O(n)(需移动数据) | O(1)(平均,链表操作) |
CPU缓存友好性 | 高(连续内存) | 低(节点离散存储) |
适用场景 | 小数据集、低修改频率 | 大数据集、高频操作 |
五、面试考点与实践建议
5.1 面试高频考点总结
Redis Hash的底层实现是面试中的高频考点,核心得分点包括:
- 两种编码的识别:明确ziplist和hashtable的定义及核心结构;
- 转换条件:熟记两个配置参数的默认值(512个字段、64字节值长度)及触发规则;
- 优劣对比:能结合内存和性能分析两种编码的适用场景;
- 设计思想:理解Redis“小数据省内存、大数据保性能”的设计理念。
5.2 实际开发优化建议
基于两种编码的特性,在实际开发中可通过以下方式优化Hash的使用:
- 优先适配ziplist编码:设计Hash结构时,尽量控制字段数量在512以内,字段值长度在64字节以内,充分利用ziplist的内存优势。例如将长文本属性(如商品详情)单独存储为String类型,而非嵌入Hash;
- 避免频繁修改大Hash:若Hash已转为hashtable编码,频繁的插入/删除操作可能触发rehash,导致性能抖动。可将大Hash拆分为多个小Hash(如按用户ID分段存储用户标签);
- 合理调整配置参数:根据业务场景调整
hash-max-ziplist-entries和hash-max-ziplist-value。例如存储短链接映射时,可将值长度阈值调小,确保更多场景使用ziplist; - 版本适配注意:Redis 7.0及以上版本中,ziplist已被listpack替代(解决ziplist的连锁更新问题),但编码转换逻辑和核心思想一致,无需修改业务代码。
六、总结
Redis Hash类型的两种编码实现,是“因地制宜”优化思想的典型体现——ziplist以“紧凑存储”为核心,解决小数据场景的内存浪费问题;hashtable以“高效操作”为核心,解决大数据场景的性能瓶颈问题。两者的动态切换,让Redis在不同场景下都能实现内存与性能的最佳平衡。