记录一次线上oom问题排查
在这里插入图片描述
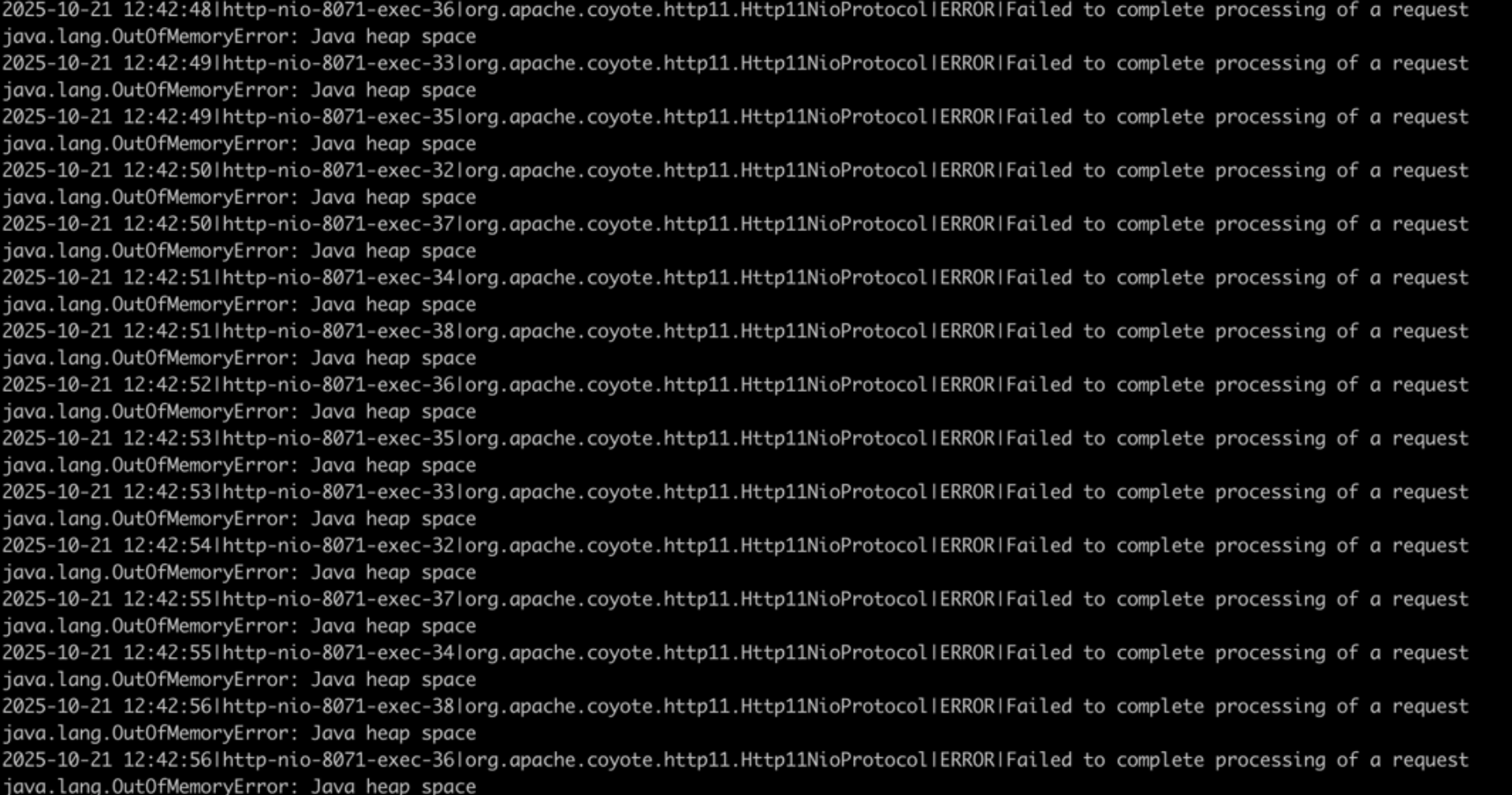
1. 获取 PID:
jps
2. 查看线程状态(是否有死锁、卡顿):
jstack <PID>
3. 通过查看线程状态发现mongoDb阻塞:
```bash
主线程状态:RUNNABLE 在 java.net.SocketInputStream.socketRead0
MongoDB操作:执行 FindOperation 时卡住
4. 查看mogodb发现在建前台索引:
@CompoundIndexes({
@CompoundIndex(def = "{'group_name':1, 'bag_name':1, 'topic_name':1, 'timestamp':1}",unique = true, background = true)})
background = true改为后台索引
5. 分析dump文件:
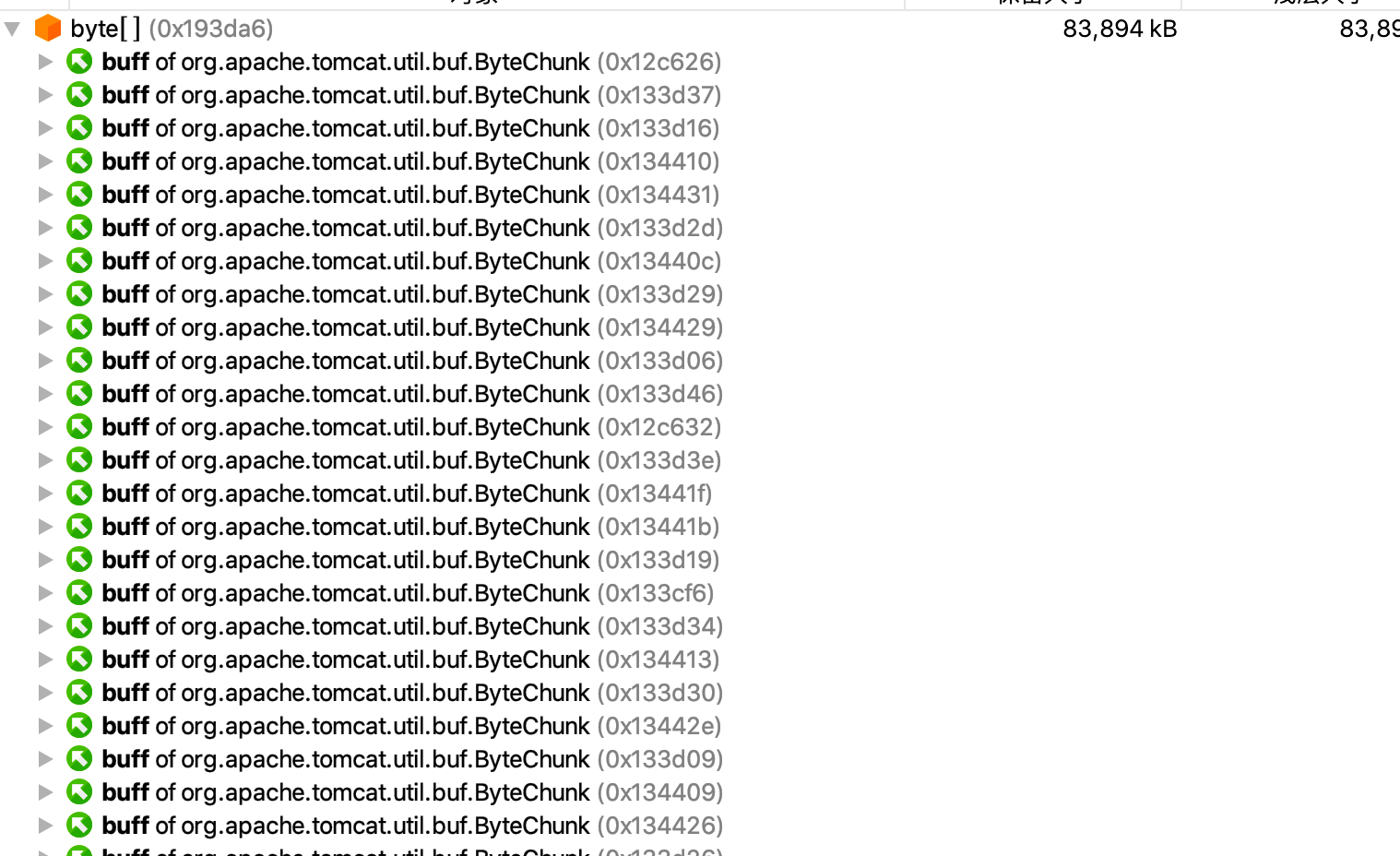
1. 当前对象集:byte[] 的 171,181 个实例
- 实例数量:有 171,181 个
byte[]实例。 - 浅层大小(Shallow Size):总共 4,710 MB。
- 保留大小(Retained Size):未显示具体值,但可以通过进一步分析得到。
2. 传入引用(Incoming references)
截图中列出了多个 byte[] 实例,每个实例的保留大小和浅层大小均为 83,894 kB(约 82 MB)。这些 byte[] 实例被 org.apache.tomcat.util.buf.ByteChunk 类的 buff 字段引用。
3. 内存泄漏的可能原因
3.1 大量的 byte[] 实例
- 数量巨大:171,181 个
byte[]实例占用 4,710 MB 内存,这表明存在大量的字节数组实例。 - 单个实例大小:每个
byte[]实例大小为 83,894 kB,这通常表示每个数组的长度非常大(大约 82 MB)。
3.2 ByteChunk 的引用
ByteChunk类:这是 Tomcat 中用于处理字节数据的类,常见于 HTTP 请求和响应的处理。buff字段:每个ByteChunk实例都有一个buff字段引用一个byte[]实例。
3.3 潜在问题
-
未释放的
ByteChunk实例:- 如果
ByteChunk实例在使用后没有被正确释放,会导致其引用的byte[]实例也无法被垃圾回收,从而造成内存泄漏。
- 如果
-
过度使用
ByteChunk:- 如果应用频繁创建
ByteChunk实例且没有有效管理其生命周期,会导致内存占用不断增加。
- 如果应用频繁创建
-
大数组的频繁创建:
- 每个
byte[]实例大小为 82 MB,如果频繁创建这样的大数组,会导致内存迅速耗尽。
- 每个
4. 解决方案
4.1 检查 ByteChunk 的使用
- 代码审查:检查应用中
ByteChunk实例的创建和释放逻辑,确保在使用完毕后及时释放。 - 复用
ByteChunk:考虑复用ByteChunk实例,而不是每次都需要创建新的实例。
4.2 优化大数组的使用
- 按需分配:根据实际需要分配
byte[]的大小,避免一次性分配过大的数组。 - 分段处理:对于大文件或数据流,可以采用分段处理的方式,每次只处理一小部分数据。
4.3 内存监控和分析
- 定期分析:定期使用内存分析工具(如 MAT)进行内存分析,及时发现和解决问题。
- 性能监控:使用性能监控工具(如 JMX、Prometheus 等)监控应用的内存使用情况,及时发现异常。
5. 总结
截图显示的内存使用情况表明,存在大量的 byte[] 实例被 ByteChunk 引用,且每个实例的大小都非常大。这可能是由于 ByteChunk 实例未被正确释放或过度使用导致的。通过检查 ByteChunk 的使用逻辑、优化大数组的分配和使用、以及定期进行内存分析,可以有效解决该问题。
如果你有更多具体的代码或应用场景信息,可以进一步分析具体原因并提供更详细的解决方案。
在MongoDB中,前台索引和后台索引是两种不同的索引构建方式,它们在性能影响和可用性方面有显著区别。
前台索引 (Foreground Index)
特点:
// 前台索引创建(默认)
db.brakeCollection.createIndex({ "status": 1, "createTime": -1 })// 或者显式指定
db.brakeCollection.createIndex({ "status": 1, "createTime": -1 },{ background: false } // 默认就是false
)
优势:
- 构建速度更快 - 通常比后台索引快2-3倍
- 索引更紧凑 - 索引结构更优化
- 立即生效 - 构建完成后立即可用
劣势:
- 阻塞操作 - 在索引构建期间:
- 集合被锁定,无法执行写操作
- 读操作可能被阻塞
- 可能导致应用超时和连接中断
后台索引 (Background Index)
特点:
// 后台索引创建
db.brakeCollection.createIndex({ "status": 1, "createTime": -1 },{ background: true } // 关键参数
)
优势:
- 非阻塞 - 在索引构建期间:
- 集合可以正常执行读写操作
- 应用不会中断
- 生产环境友好 - 适合7x24运行的系统
劣势:
- 构建速度慢 - 比前台索引慢2-3倍
- 资源消耗大 - 可能影响系统整体性能
- 索引效率稍低 - 索引结构可能不如前台索引紧凑
在您当前情况下的选择建议
1. 紧急情况 - 使用后台索引
// 立即执行 - 不会阻塞您的应用
db.brakeCollection.createIndex({ "status": 1, "createTime": -1 },{ background: true,name: "status_createtime_idx"}
)db.brakeCollection.createIndex({ "status": 1 },{ background: true,name: "status_idx" }
)db.brakeCollection.createIndex({ "createTime": -1 },{ background: true,name: "createtime_idx" }
)
2. 在Spring Data MongoDB中配置
@CompoundIndexes({@CompoundIndex(def = "{'group_name':1, 'bag_name':1, 'topic_name':1, 'timestamp':1}",unique = true),@CompoundIndex(def = "{'status':1, 'createTime':-1}",name = "status_createtime_idx",background = true // 关键配置),@CompoundIndex(def = "{'status':1}",name = "status_idx",background = true)
})
public class Brake {// 实体字段
}
3. 编程方式创建后台索引
@Component
public class MongoIndexCreator {@Autowiredprivate MongoTemplate mongoTemplate;@EventListener(ApplicationReadyEvent.class)public void createBackgroundIndexes() {try {// 创建后台索引 - 不会阻塞应用启动mongoTemplate.indexOps(Brake.class).ensureIndex(new Index().on("status", Sort.Direction.ASC).on("createTime", Sort.Direction.DESC).named("status_createtime_idx").background());mongoTemplate.indexOps(Brake.class).ensureIndex(new Index().on("status", Sort.Direction.ASC).named("status_idx").background());mongoTemplate.indexOps(Brake.class).ensureIndex(new Index().on("createTime", Sort.Direction.DESC).named("createtime_idx").background());logger.info("Background indexes creation initiated");} catch (Exception e) {logger.warn("Background index creation failed, but application continues", e);}}
}
监控索引构建进度
查看正在构建的索引
// 查看当前操作
db.currentOp({ "active": true, "ns": "your_database.brakeCollection","op": "command","command.createIndexes": { "$exists": true }}
)
检查索引状态
// 查看索引构建状态
db.brakeCollection.getIndexes()// 查看索引构建进度
db.brakeCollection.aggregate([{ $indexStats: {} }])// 等待索引构建完成(用于脚本)
while (db.brakeCollection.currentOp().inprog.filter(op => op.ns === 'your_database.brakeCollection' && op.command && op.command.createIndexes).length > 0) {sleep(1000);
}
print("Index build completed");
针对您当前问题的具体建议
立即执行步骤:
- 首先让应用启动 - 临时禁用初始化
- 创建后台索引 - 使用上面的MongoDB命令
- 验证索引生效 - 检查索引状态
- 逐步恢复功能 - 重新启用初始化
推荐的后台索引创建命令:
use your_database_name// 创建查询需要的后台索引
db.brakeCollection.createIndex({ "status": 1, "createTime": -1 },{ background: true,name: "status_createtime_idx" }
)// 创建单字段索引作为备用
db.brakeCollection.createIndex({ "status": 1 },{ background: true,name: "status_idx" }
)db.brakeCollection.createIndex({ "createTime": -1 },{ background: true,name: "createtime_idx" }
)
总结:在您当前的生产环境问题中,强烈建议使用后台索引,因为它不会阻塞您的应用运行,可以让系统在索引构建期间继续提供服务。