MOTR: End-to-End Multiple-Object Tracking with TRansformer推理学习
1.连接服务器
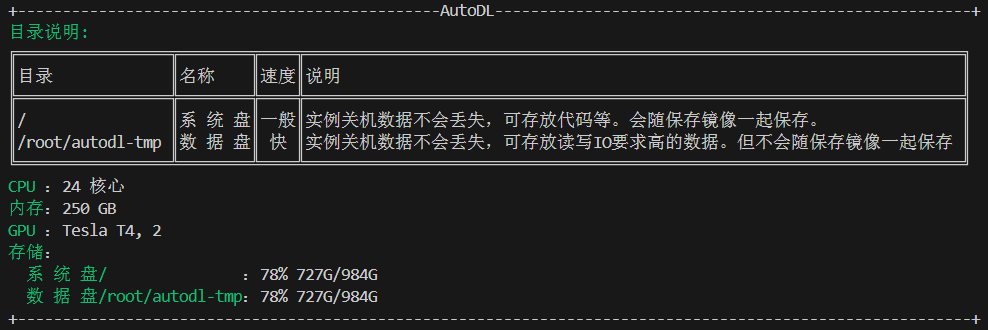
我个人使用的是autodl的Tesla T4 * 2进行推理学习,显存16GB,我将其用vscode进行连接,而不是jupyterlab,看个人习惯。
在vscode中,使用快捷键“Fn+F1”打开“remote-ssh”,然后选择添加新主机,输入你的ssh命令然后选择linux,输入密码,正常来说就可以连接成功。但是这个过程也许会连接失败,个人遇到三个情况,希望对您有帮助:
- 网络问题
- vscode配置问题
- autodl这个卡有问题
这三个问题也就第二个“vscode的配置”有必要去研究一下,大部分就是vscode的安装问题,VSCode的安装路径要已添加到系统的PATH环境变量以及Remote-ssh的插件安装等,希望读者自行查阅资料去学习如何解决,本文不作解释。
2.环境配置
项目在 root/antodl-tmp 下创建项目:git clone https://github.com/megvii-research/MOTR.git
那么现在你就可以进入: root/autodl-tmp/MOTR
但是在开始之前,你需要确保:Linux、CUDA>=9.2、GCC>=5.4,必须有GPU哦,低配服务器就别跑这个了。
2.1使用 Anaconda 创建 conda 环境
conda create -n deformable_detr python=3.7 pipconda环境是一个独立的python运行环境,这样不同的项目就可以在各自的环境中使用不同版本的包而不会相互干扰。
2.2 conda初始化
正常来说,其实有四种初始化方法:
- conda init:conda自动检测当前的shell类型
- conda init bash:大部分ubuntu和centOS
- conda init zsh:macOS
- conda init fish:用户友好,语法简介,会高亮
你首先要检查一下你自己当前使用的shell:
echo $SHELL-
如果显示
/bin/bash→ 用conda init bash -
如果显示
/bin/zsh→ 用conda init zsh -
如果显示
/bin/fish→ 用conda init fish
如果你是bash,在你初始化后,建议:(如果不是,请去查一下命令)
source ~/.bashrc因为你在conda初始化后,他会在shell的配置文件里面添加一些内容,重启后生效。
2.3 conda激活环境
conda activate deformable_detr2.4 pytorch和torchvision
如果您的 CUDA 版本是 9.2,您可以按如下方式安装 pytorch 和 torchvision:
conda install pytorch=1.5.1 torchvision=0.6.1 cudatoolkit=9.2 -c pytorch2.5 安装其他依赖
pip install -r requirements.txt2.6 构建 MultiScaleDeformableAttention
cd ./models/ops
sh ./make.sh3.模型推理
在github上找到main result部分,我们来推理MOT17,我们首先下载一下model预训练模型,我是在autodl的jupyterlab页面手动添加进去的到exps/e2e_motr_r50_joint(自己在MOTR下创建一下)。最后形成:MOTR/exps/e2e_motr_r50_joint/motr_final.pth
因为我们是进行推理,而不是训练,所以也就不用下载dataset了。
创建一个shell脚本 run_demo.py
#!/bin/bash
python3 demo.py \--meta_arch motr \--dataset_file e2e_joint \--epoch 200 \--with_box_refine \--lr_drop 100 \--pretrained exps/e2e_motr_r50_joint/motr_final.pth \--output_dir exps/e2e_motr_r50_joint \--batch_size 1 \--sample_mode 'random_interval' \--sample_interval 10 \--sampler_lengths 2 3 4 5 \--sampler_steps 50 90 120 \--update_query_pos \--query_interaction_layer 'QIM' \--extra_track_attn \--resume exps/e2e_motr_r50_joint/motr_final.pth \--input_video figs/demo.avi然后运行sh run_demo.py就可以了。

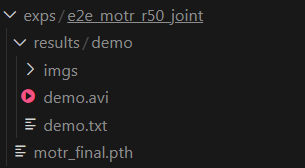
可以看到最后有一个results输出。成功!
3.1参数分析
3.1.1模型架构参数
- --meta_arch motr:指定模型架构为MOTR
- --dataset_file e2e_joint:指定数据集格式为端到端联合训练
3.1.2训练相关参数
- --epoch 200:训练周期
- --lr_drop 100:学习率下降点
来自训练配置,不影响推理
3.1.3模型优化参数
- --with_box_refine:启用边界框细化,这是 Deformable DETR 的关键技术,通过迭代优化提高检测框精度。
- --update_query_pos:启用查询位置更新,这是 MOTR 的核心机制,允许查询根据前一帧的跟踪结果更新位置,实现时间一致性。
- --query_interaction_layer 'QIM':使用查询交互模块,处理查询之间的冲突和交互,减少ID切换。
- --extra_track_attn:额外的跟踪注意力层,增强模型对跟踪目标的关注。
这些参数都应保持启用,因为它们实现了 MOTR 论文中的关键创新。
3.1.4采样策略参数
- --sample_mode 'random_interval':在训练时使用随机间隔采样,增加数据多样性。但在推理时,随机采样可能不适合。
- --sample_interval 10:每10帧采样一帧,这是为了平衡计算效率和跟踪精度。论文中提到,较长的间隔可能丢失快速移动目标。
- --sampler_lengths 2 3 4 5:定义每个视频片段的帧数,MOTR 处理的是视频片段而非单帧。这些值表示模型同时处理2-5帧来跟踪目标。
- --sampler_steps 50 90 120:训练时调整采样长度的步骤,推理时不起作用。
修改sample_mode,对于推理,建议改为 'uniform' 或 'sequential' 以获得更稳定的结果。
修改sample_interval,采样间隔直接影响轨迹连续性。较小的间隔减少ID切换,但增加计算量。
修改sampler_lengths,更长的序列能更好地建模时间上下文,但需要更多GPU内存。
3.1.5模型参数文件
- --pretrained exps/e2e_motr_r50_joint/motr_final.pth
- --resume exps/e2e_motr_r50_joint/motr_final.pth
指定预训练模型的路径。
3.1.6输入输出参数
- --input_video figs/demo.avi
- --output_dir exps/e2e_motr_r50_joint
3.1.7批处理参数
- --batch_size 1
4.结果分析
4.1基础分析脚本
在MOTR/exps/e2e_motr_r50_joint/results下创建basic_analysis.py
# basic_analysis.py - 基础分析脚本
import pandas as pd
import os
import jsondef basic_analysis():"""基础分析函数"""print("=== MOTR 跟踪结果基础分析 ===\n")# 读取跟踪数据txt_path = "demo/demo.txt"if not os.path.exists(txt_path):print(f"错误: 找不到文件 {txt_path}")returndf = pd.read_csv(txt_path, header=None, names=['frame', 'id', 'bb_left', 'bb_top', 'bb_width', 'bb_height', 'conf', 'x', 'y', 'z'])print("📊 基础统计:")print(f"总检测数: {len(df):,}")print(f"总帧数: {df['frame'].nunique()}")print(f"跟踪目标数: {df['id'].nunique()}")print(f"平均置信度: {df['conf'].mean():.3f}")# 轨迹统计track_lengths = df.groupby('id').size()print(f"\n🎯 轨迹统计:")print(f"平均轨迹长度: {track_lengths.mean():.1f} 帧")print(f"最长轨迹: {track_lengths.max()} 帧")print(f"最短轨迹: {track_lengths.min()} 帧")# 边界框统计print(f"\n📏 边界框统计:")print(f"平均宽度: {df['bb_width'].mean():.1f} 像素")print(f"平均高度: {df['bb_height'].mean():.1f} 像素")# 文件信息print(f"\n📁 文件信息:")img_count = len([f for f in os.listdir("demo/imgs") if f.endswith('.jpg')])print(f"图片序列数量: {img_count} 张")if os.path.exists("demo/demo.avi"):file_size = os.path.getsize("demo/demo.avi") / (1024*1024)print(f"输出视频大小: {file_size:.1f} MB")# 保存基础统计stats = {"total_detections": len(df),"total_frames": df['frame'].nunique(),"total_tracks": df['id'].nunique(),"avg_confidence": float(df['conf'].mean()),"avg_track_length": float(track_lengths.mean()),"image_count": img_count}with open('basic_stats.json', 'w') as f:json.dump(stats, f, indent=2)print(f"\n✅ 基础统计已保存: basic_stats.json")if __name__ == "__main__":basic_analysis()最后运行一下这个脚本:
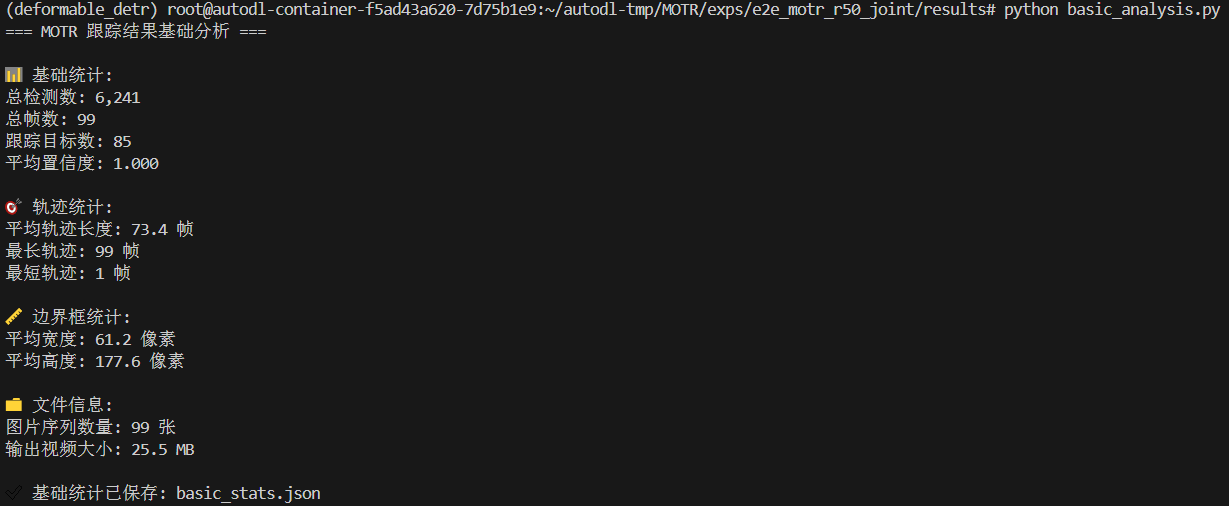
- basic_stats.json:基础统计信息,包括总检测数、总帧数、跟踪目标数、平均置信度、平均轨迹长度和图片数量等
4.2可视化分析脚本
在MOTR/exps/e2e_motr_r50_joint/results下创建visual_analysis.py
# visual_analysis.py - 可视化分析脚本
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import os# 设置中文字体(可选)
plt.rcParams['font.sans-serif'] = ['DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = Falsedef create_visualizations():"""创建可视化图表"""print("📈 创建可视化分析图表...")# 读取数据txt_path = "demo/demo.txt"if not os.path.exists(txt_path):print(f"错误: 找不到文件 {txt_path}")returndf = pd.read_csv(txt_path, header=None, names=['frame', 'id', 'bb_left', 'bb_top', 'bb_width', 'bb_height', 'conf', 'x', 'y', 'z'])# 创建多个子图fig, axes = plt.subplots(2, 2, figsize=(15, 10))fig.suptitle('MOTR 跟踪结果分析', fontsize=16, fontweight='bold')# 1. 每帧目标数量detections_per_frame = df.groupby('frame').size()axes[0,0].plot(detections_per_frame.index, detections_per_frame.values, color='blue', linewidth=2)axes[0,0].set_title('每帧目标数量变化', fontweight='bold')axes[0,0].set_xlabel('帧号')axes[0,0].set_ylabel('目标数量')axes[0,0].grid(True, alpha=0.3)# 2. 置信度分布axes[0,1].hist(df['conf'], bins=30, alpha=0.7, color='green', edgecolor='black')axes[0,1].set_title('检测置信度分布', fontweight='bold')axes[0,1].set_xlabel('置信度')axes[0,1].set_ylabel('频次')axes[0,1].grid(True, alpha=0.3)# 3. 轨迹长度分布track_lengths = df.groupby('id').size()axes[1,0].hist(track_lengths, bins=20, alpha=0.7, color='orange', edgecolor='black')axes[1,0].set_title('轨迹长度分布', fontweight='bold')axes[1,0].set_xlabel('轨迹长度(帧数)')axes[1,0].set_ylabel('目标数量')axes[1,0].grid(True, alpha=0.3)# 4. 边界框大小分布bbox_areas = df['bb_width'] * df['bb_height']axes[1,1].hist(bbox_areas, bins=30, alpha=0.7, color='red', edgecolor='black')axes[1,1].set_title('边界框面积分布', fontweight='bold')axes[1,1].set_xlabel('边界框面积(像素²)')axes[1,1].set_ylabel('频次')axes[1,1].grid(True, alpha=0.3)plt.tight_layout()plt.savefig('tracking_analysis.png', dpi=150, bbox_inches='tight')plt.close()print("✅ 可视化图表已保存: tracking_analysis.png")def create_track_visualization():"""创建轨迹可视化"""print("🔄 创建轨迹可视化...")txt_path = "demo/demo.txt"df = pd.read_csv(txt_path, header=None, names=['frame', 'id', 'bb_left', 'bb_top', 'bb_width', 'bb_height', 'conf', 'x', 'y', 'z'])# 计算边界框中心点df['center_x'] = df['bb_left'] + df['bb_width'] / 2df['center_y'] = df['bb_top'] + df['bb_height'] / 2# 选择前10个最长的轨迹进行可视化track_lengths = df.groupby('id').size()top_tracks = track_lengths.nlargest(10).indexplt.figure(figsize=(12, 8))for track_id in top_tracks:track_data = df[df['id'] == track_id]plt.plot(track_data['center_x'], track_data['center_y'], marker='o', markersize=3, linewidth=2, label=f'ID {track_id}')plt.title('目标轨迹可视化(前10个最长轨迹)', fontweight='bold')plt.xlabel('X 坐标(像素)')plt.ylabel('Y 坐标(像素)')plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')plt.grid(True, alpha=0.3)plt.tight_layout()plt.savefig('track_visualization.png', dpi=150, bbox_inches='tight')plt.close()print("✅ 轨迹可视化已保存: track_visualization.png")def analyze_image_sequence():"""分析图片序列"""print("🖼️ 分析图片序列...")img_dir = "demo/imgs"if not os.path.exists(img_dir):print(f"警告: 图片目录 {img_dir} 不存在")returnimg_files = [f for f in os.listdir(img_dir) if f.endswith(('.jpg', '.png'))]if not img_files:print("警告: 未找到图片文件")returnprint(f"找到 {len(img_files)} 张图片")# 分析图片命名模式img_files.sort()print(f"第一张图片: {img_files[0]}")print(f"最后一张图片: {img_files[-1]}")# 保存图片序列信息with open('image_sequence_info.txt', 'w') as f:f.write(f"图片总数: {len(img_files)}\n")f.write(f"图片目录: {img_dir}\n")f.write(f"第一帧: {img_files[0]}\n")f.write(f"最后一帧: {img_files[-1]}\n")print("✅ 图片序列信息已保存: image_sequence_info.txt")if __name__ == "__main__":create_visualizations()create_track_visualization()analyze_image_sequence()运行visual_analysis.py脚本,出现:

- tracking_analysis.png:包含四个子图,分别展示每帧目标数量变化、置信度分布、轨迹长度分布和边界框面积分布。
- track_visualization.png:展示前10个最长轨迹的中心点运动路径。
- image_sequence_info.txt:图片序列的信息,如图片数量、第一帧和最后一帧的文件名。
通过可视化图表直观地展示跟踪结果的各个方面,帮助分析模型性能和数据分布。
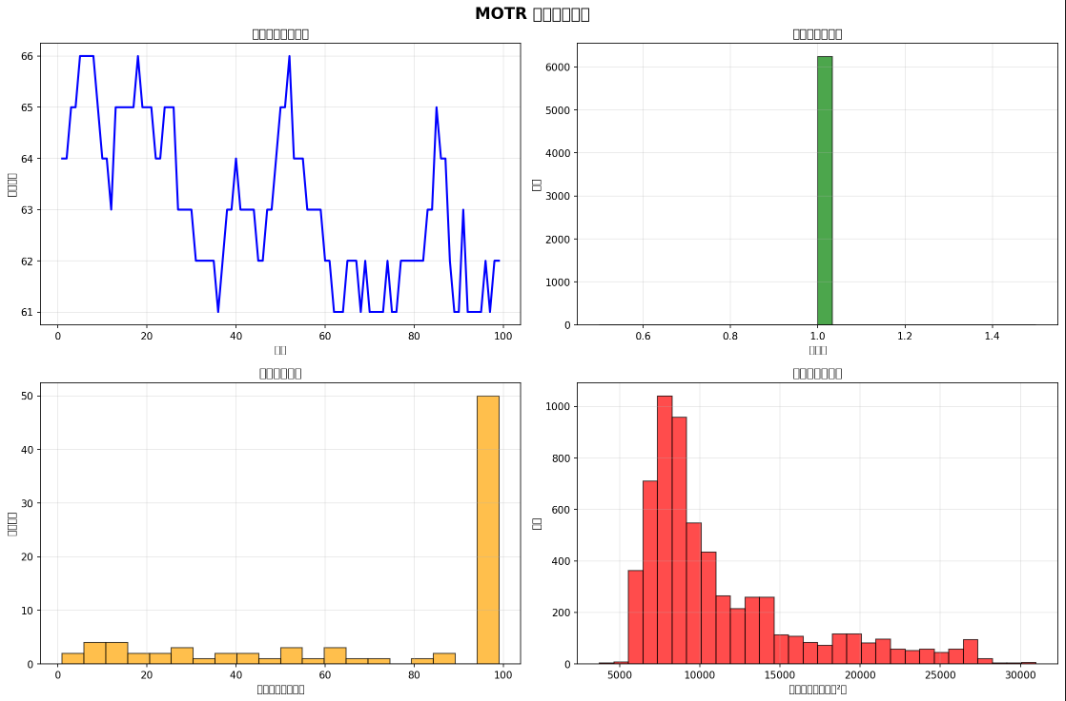
每帧的目标数量,置信度分布
边界框面积,边界框面积
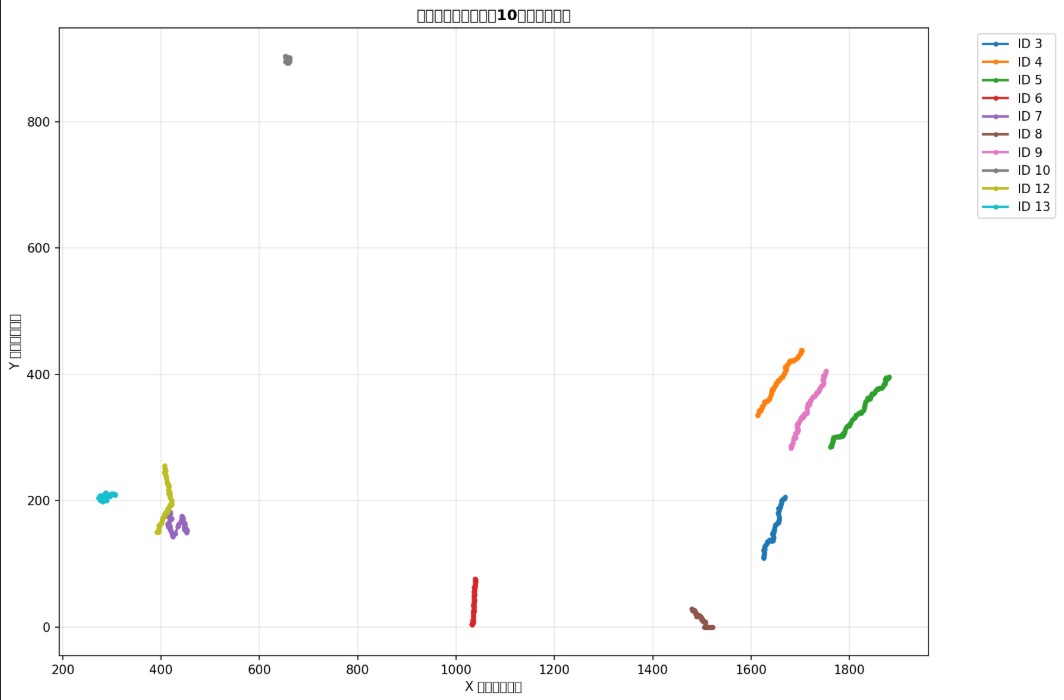
不同目标的运动轨迹
4.3详细报告脚本
在MOTR/exps/e2e_motr_r50_joint/results下创建detailed_report.py
# detailed_report.py - 详细报告脚本
import pandas as pd
import os
import json
from datetime import datetimedef generate_detailed_report():"""生成详细分析报告"""print("📋 生成详细分析报告...")# 读取数据txt_path = "demo/demo.txt"if not os.path.exists(txt_path):print(f"错误: 找不到文件 {txt_path}")returndf = pd.read_csv(txt_path, header=None, names=['frame', 'id', 'bb_left', 'bb_top', 'bb_width', 'bb_height', 'conf', 'x', 'y', 'z'])# 生成报告report_lines = []report_lines.append("=" * 60)report_lines.append(" MOTR 多目标跟踪详细分析报告")report_lines.append("=" * 60)report_lines.append(f"生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")report_lines.append(f"数据文件: {txt_path}")report_lines.append("")# 基础统计report_lines.append("1. 基础统计")report_lines.append("-" * 40)report_lines.append(f"总检测数: {len(df):,}")report_lines.append(f"总帧数: {df['frame'].nunique()}")report_lines.append(f"跟踪目标数: {df['id'].nunique()}")report_lines.append(f"平均置信度: {df['conf'].mean():.3f}")report_lines.append(f"置信度标准差: {df['conf'].std():.3f}")report_lines.append("")# 轨迹分析track_lengths = df.groupby('id').size()report_lines.append("2. 轨迹分析")report_lines.append("-" * 40)report_lines.append(f"平均轨迹长度: {track_lengths.mean():.1f} 帧")report_lines.append(f"轨迹长度标准差: {track_lengths.std():.1f} 帧")report_lines.append(f"最长轨迹: {track_lengths.max()} 帧")report_lines.append(f"最短轨迹: {track_lengths.min()} 帧")report_lines.append("")# 边界框分析report_lines.append("3. 边界框分析")report_lines.append("-" * 40)report_lines.append(f"平均宽度: {df['bb_width'].mean():.1f} 像素")report_lines.append(f"平均高度: {df['bb_height'].mean():.1f} 像素")report_lines.append(f"最大宽度: {df['bb_width'].max():.1f} 像素")report_lines.append(f"最大高度: {df['bb_height'].max():.1f} 像素")report_lines.append("")# 帧级统计detections_per_frame = df.groupby('frame').size()report_lines.append("4. 帧级统计")report_lines.append("-" * 40)report_lines.append(f"平均每帧目标数: {detections_per_frame.mean():.1f}")report_lines.append(f"最多目标帧: {detections_per_frame.max()} 个目标")report_lines.append(f"最少目标帧: {detections_per_frame.min()} 个目标")report_lines.append("")# 前10个最长轨迹report_lines.append("5. 前10个最长轨迹")report_lines.append("-" * 40)top_tracks = track_lengths.nlargest(10)for i, (track_id, length) in enumerate(top_tracks.items(), 1):track_data = df[df['id'] == track_id]avg_conf = track_data['conf'].mean()report_lines.append(f"{i:2d}. 目标 ID {track_id:3d}: {length:3d} 帧, 平均置信度: {avg_conf:.3f}")report_lines.append("")# 文件信息report_lines.append("6. 输出文件信息")report_lines.append("-" * 40)# 图片序列信息img_dir = "demo/imgs"if os.path.exists(img_dir):img_count = len([f for f in os.listdir(img_dir) if f.endswith(('.jpg', '.png'))])report_lines.append(f"图片序列: {img_count} 张图片")else:report_lines.append("图片序列: 目录不存在")# 视频文件信息video_path = "demo/demo.avi"if os.path.exists(video_path):video_size = os.path.getsize(video_path) / (1024*1024)report_lines.append(f"输出视频: {video_size:.1f} MB")else:report_lines.append("输出视频: 文件不存在")report_lines.append(f"跟踪数据: {os.path.getsize(txt_path) / 1024:.1f} KB")report_lines.append("")# 输出报告report_text = "\n".join(report_lines)print(report_text)# 保存报告with open('detailed_report.txt', 'w', encoding='utf-8') as f:f.write(report_text)print(f"\n✅ 详细报告已保存: detailed_report.txt")if __name__ == "__main__":generate_detailed_report()运行detailed_report.py出现:
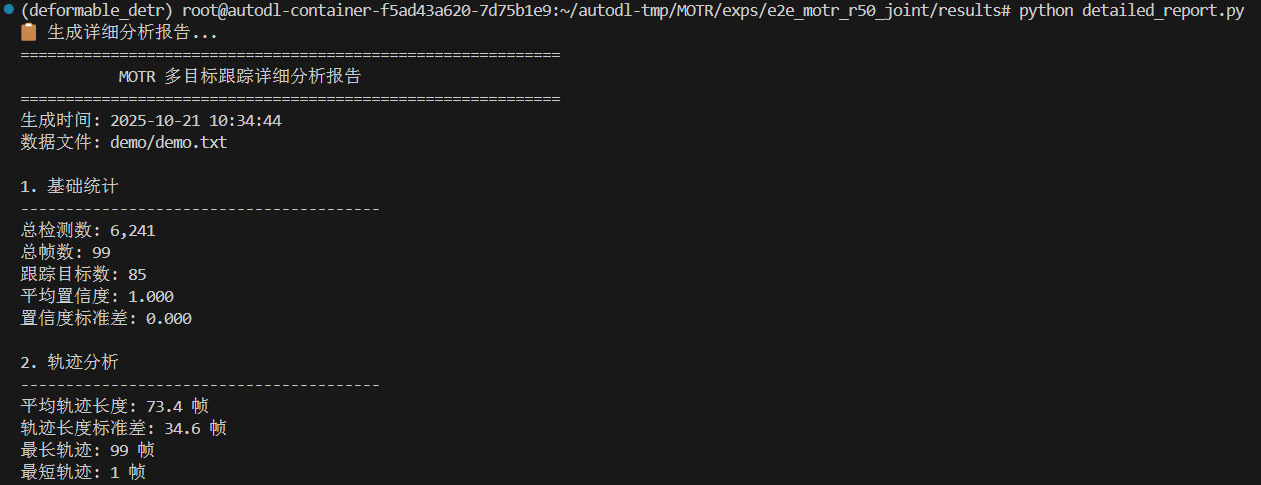


- detailed_report.txt:详细的文本报告,包括基础统计、轨迹分析、边界框分析、帧级统计、前10个最长轨迹和输出文件信息等。
4.4一键分析脚本
在MOTR/exps/e2e_motr_r50_joint/results下创建run_all_analysis.py
# run_all_analysis.py - 一键运行所有分析
import os
import subprocess
import sys
from datetime import datetimedef run_analysis():"""运行所有分析脚本"""print("🚀 开始运行 MOTR 结果分析...")print(f"时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")print("=" * 60)# 检查目录结构print("📁 检查目录结构...")required_paths = ["demo/demo.txt","demo/demo.avi", "demo/imgs"]for path in required_paths:if os.path.exists(path):print(f" ✅ {path}")else:print(f" ❌ {path} (缺失)")# 检查必要文件if not os.path.exists("demo/demo.txt"):print("❌ 错误: 找不到 demo/demo.txt 文件")returnscripts = ['basic_analysis.py', 'visual_analysis.py', 'detailed_report.py']for script in scripts:if os.path.exists(script):print(f"\n▶️ 运行 {script}...")try:result = subprocess.run([sys.executable, script], capture_output=True, text=True)print(result.stdout)if result.stderr:print(f"警告: {result.stderr}")except Exception as e:print(f"❌ 运行 {script} 时出错: {e}")else:print(f"❌ 找不到脚本: {script}")print("\n" + "=" * 60)print("✅ 所有分析完成!生成的文件:")# 列出生成的文件output_files = ['basic_stats.json', 'tracking_analysis.png', 'track_visualization.png','image_sequence_info.txt','detailed_report.txt']for file in output_files:if os.path.exists(file):size = os.path.getsize(file)if file.endswith('.png'):size_str = f"{size/1024:.1f} KB"else:size_str = f"{size/1024:.1f} KB"print(f" 📄 {file} ({size_str})")else:print(f" ❌ {file} (未生成)")print("\n📊 分析总结:")print(" 1. basic_stats.json - 基础统计信息 (JSON格式)")print(" 2. tracking_analysis.png - 综合可视化图表")print(" 3. track_visualization.png - 轨迹可视化")print(" 4. image_sequence_info.txt - 图片序列信息")print(" 5. detailed_report.txt - 详细分析报告")print("\n🎯 下一步建议:")print(" - 查看生成的PNG图片了解数据分布")print(" - 阅读详细报告了解跟踪性能")print(" - 可以尝试不同的视频进行对比分析")if __name__ == "__main__":run_analysis()5.总结
本地vscode连接antodl的服务器,然后搭建项目所需的环境,根据readme的说明进行预训练的推理,自己尝试分析推理的txt文件,最后可以通过图表可视化以及txt文本查看推理内容。