AIDD - 前沿生物科技 虚拟细胞 (Virtual Cells) 的头部公司
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://spike.blog.csdn.net/article/details/153695943
免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。
到 2030 年实现 AI 驱动的虚拟细胞这一愿景,不仅仅代表着一项技术进步,更意味着理解生物学及与之互动的方式将发生根本性的转变。尽管从数据生成到模型验证仍存在重大挑战,但是产业界和学术实验室的先驱们正朝着这个未来迈出重大的步伐。正如 CZI (Chan Zuckerberg Initiative) 科学主管 Steve Quake 在与 Eric Topol 博士的访谈中所指出的:“目前,细胞生物学 90% 是实验性的,10% 是计算性的……我认为在 10 年内,我们可以让生物学变成 90% 是计算性的,10% 是实验性的。”这种翻转不仅将改变药物发现,更将改变我们进行生物研究的整体方法。未来十年将是决定这一愿景能否实现的关键时期。成功不仅需要技术上的突破,还需要建立用于验证、监管以及跨生物尺度整合的新框架。文中提到的这些先驱正在引领潮流,但要完全实现虚拟细胞的潜力,将需要一个横跨学术界、产业界和监管机构的、更广泛的创新生态系统。
行业主要的公司:Arc Institute、BCR (Basecamp Research)、Noetik
Arc Institute (Arc 研究所)
Arc 研究所 (Arc Institute) 是位于 加利福尼亚 - 帕洛阿尔托 的非营利性生物医学研究机构,使命是 ”加速科学进步,理解疾病原因,缩小发现与患者影响之间的差距”。Arc 与斯坦福大学、加州大学伯克利分校和加州大学旧金山分校合作运营。
to accelerate scientific progress, understand the root causes of diseases, and narrow the gap between discoveries and impact on patients.
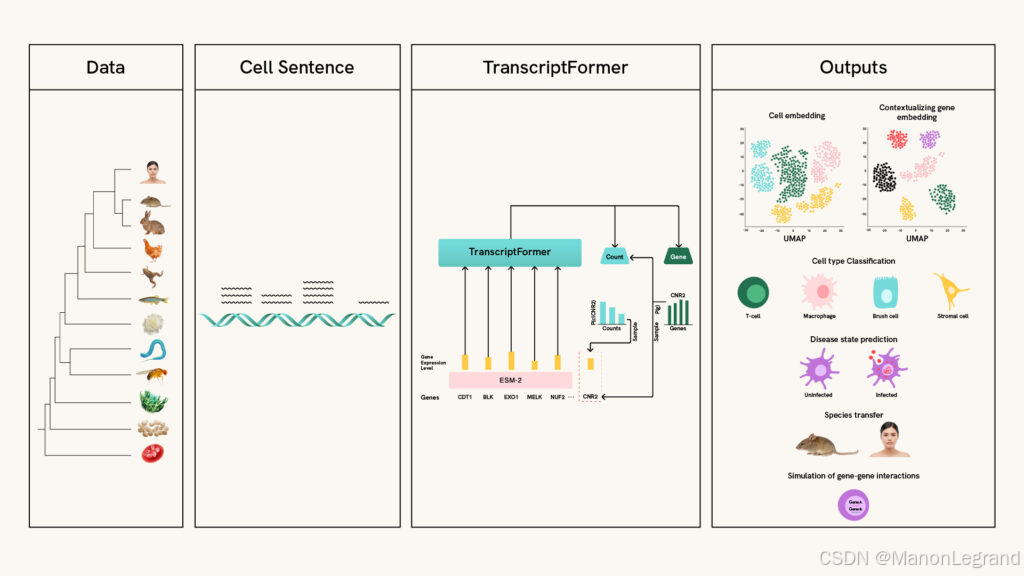
技术方面,Arc 对虚拟细胞生态系统的贡献是于 2025 年 2 月推出的 Arc 虚拟细胞图谱。不断增长的资源汇集了跨越多个物种、组织和实验条件的多样化数据集,用于先进的计算分析。图谱首次亮相时包含两个基础数据集:与 Tahoe Bio 合作生产的 Tahoe-100M,包含 100M 个细胞,映射 50 种癌症细胞系中的 60K 种药物-细胞相互作用;以及 scBaseCount,首个使用 AI 智能体 从公共数据策划和重新处理的单细胞 RNA 测序数据集。
Arc 使用 AI 代理自动从公共存储库中识别和策划单细胞数据集的做法是独一无二的。这改善了不同类型单细胞数据之间的整合,为研究人员提供了用于虚拟细胞模型预训练的优化数据集。2025年4月,Arc宣布与 10x Genomics 和 Ultima Genomics 建立战略合作伙伴关系,以进一步扩展图谱。Arc研究人员将使用 10x 的 Chromium Flex 检测法进行化学和遗传扰动筛选中的单细胞测序,使用 Ultima 的 UG 100 测序系统进行读数。
这些工作促使Arc发布了他们的第一个虚拟细胞模型State。该模型基于数亿个单细胞和扰动观察训练,涵盖约70种人类细胞系,State在检测扰动效应方面比以前的模型提高了约50%,在识别差异表达基因方面的准确性提高了一倍。此外,STATE是开源的,可通过GitHub用于非商业用途。
最近,Arc启动了由NVIDIA、10x Genomics和Ultima Genomics赞助的虚拟细胞挑战。该竞赛邀请参与者构建预测单个基因扰动在细胞中影响的模型。该挑战旨在加速生物学AI建模的进展,并鼓励开发高质量的数据集和虚拟细胞研究的标准化基准。
Tahoe-100M
网址: https://huggingface.co/datasets/tahoebio/Tahoe-100M
Tahoe-100M 是 大规模单细胞扰动图谱(giga-scale single-cell perturbation atlas),包含来自 50 种癌细胞系的超过 100M 个转录组表达谱,这些细胞系暴露于 1100 种小分子扰动。图谱使用 Vevo Therapeutics 公司的 Mosaic 高通量平台生成,以前所未有的规模和分辨率,对基因功能、细胞状态和药物反应进行深入且情境感知的探索。该数据集旨在助力新一代细胞生物学AI模型的开发,为系统生物学、药物发现和精准医学提供广泛的应用。数据集: 429G,核心是 expression_data 数据,有 95.6M 数据。
expression_data 的数据维度:
- genes:基因
- expressions:表达量
- drug:药物,例如,8-Hydroxyquinoline,即8-羟基喹啉是杀菌、抗癌、螯合金属的小分子。
- sample:样本
BARCODE_SUB_LIB_ID:条形码子库编号cell_line_id:细胞系编号moa-fine:作用机制-细分类canonical_smiles:规范 SMILES 表达式pubchem_cid:PubChem CID- plate:培养板编号
scBaseCount
https://github.com/ArcInstitute/arc-virtual-cell-atlas/blob/main/scBaseCount/README.md
scBaseCount (曾用名 “scBaseCamp”) 是持续更新的 单细胞RNA测序 (scRNA-seq) 数据库,使用 AI 驱动分层代理工作流 (AI-driven hierarchical agent workflow),自动对 SRA (Sequence Read Archive, 序列读取档案库) 数据进行发现、元数据提取和标准化预处理。作为目前最大的公共单细胞数据存储库,包含超过 230M 个细胞,持续扩展中,涵盖 21 个物种和 72 种组织。通过持续发现、注释和重新处理原始的单细胞 RNA-seq 数据,scBaseCount 提供一个规模庞大且统一协调的存储库,可作为 AI 驱动建模和综合性 元分析(meta-analyses) 的基础。
BCR (Basecamp Research)
https://basecamp-research.com/
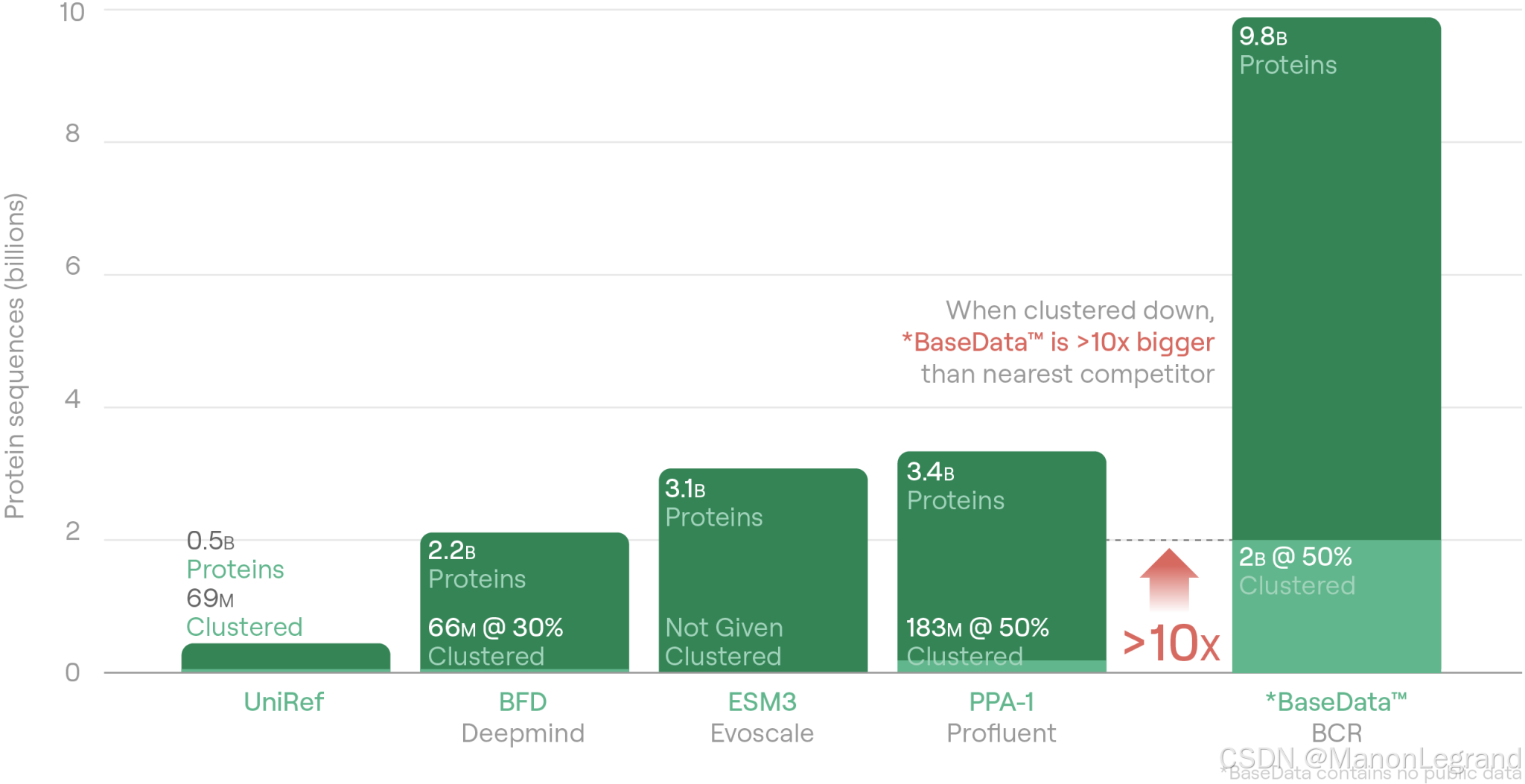
Basecamp Research 使用独特的方法来构建生物基础模型 (biofoundation models),专注于设计能够被精确控制的完整生物系统。Basecamp 并非对孤立的组件进行建模,而是正在构建一个详尽的知识图谱,图谱建立在超过 10B 个,且仍在不断增长的,新型蛋白质序列之上,反映了现实世界生物学的复杂性。该框架实际上充当了自然生态系统的“数字孪生”。
Basecamp 战略的一个关键部分是数据收集。该公司开发了 BaseData,这是一个专有数据集,规模是所有公开可用测序数据总和的10倍。该数据集是通过采集来自广泛地理区域和生态系统的样本汇编而成,重点在于捕获生物多样性,以支持具有通用性的模型。据 Basecamp 称,BaseData 包含了超过 100 万种新发现的微生物物种的基因组数据,这些物种采集自偏远地区,例如二战时期的沉船、火山温泉和南极土壤。
Basecamp 的所有数据正被用于训练一系列模拟细胞分子尺度的生物基础模型 (bioFMs)。2024年,Basecamp 发布了 ZymCTRL (“enzyme control”即“酶控制”的缩写),这是一个蛋白质语言模型,使用公共数据进行训练,使用该公司的专有数据集进行微调。使用模型设计新型乳酸脱氢酶 (lactate dehydrogenases),表明其专有数据集增强,模型对其预测稳定性的信心。实验测试,这些生成的酶中有70%被证明具有活性。Basecamp 计划使用 BaseData 日益增长的基因组序列库,通过内部开发以及合作伙伴关系来构建一系列广泛的 DNA 和蛋白质语言模型。作为开发可编程基因医疗工具的一部分,Basecamp 收购了 Tome Biosciences 的关键 IP (知识产权),正与 NVIDIA 合作构建一系列基础模型。
设计复杂度,最终达到涌现的生物特性,即:
数据优势使得平台处于生物设计领域的前沿。收集的数据越多,AI 对于生物学运作原理的理解就越深入。如今,独特的知识图谱正在驱动突破性的性能表现,远远超越了以往在速度和复杂性上的限制。
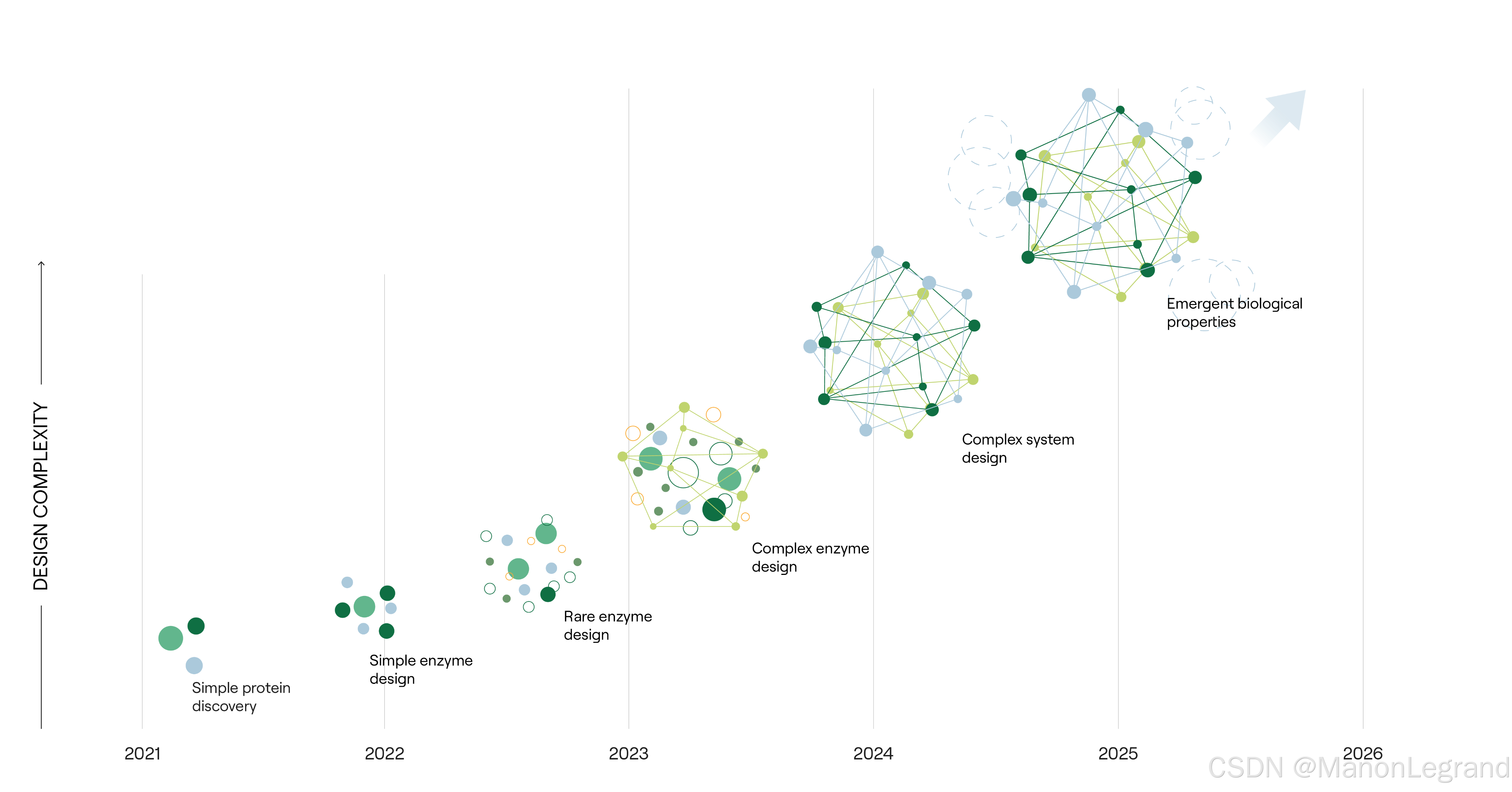
数据规模:
Noetik
https://www.noetik.ai/
Noetik 是一家 AI 原生 (AI-native) 的生物技术公司,使用自监督机器学习和高通量空间数据,研发新一代癌症疗法。Noetik 在虚拟细胞生态系统中的杰出贡献是于2024年12月发布的 OCTO-VirtualCell (OCTO-vc)。这个基础模型能够在完整的或虚拟的患者组织中,模拟空间解析的单细胞基因表达,从而高保真地预测基因表达以响应生物环境 (biological context) 的变化。
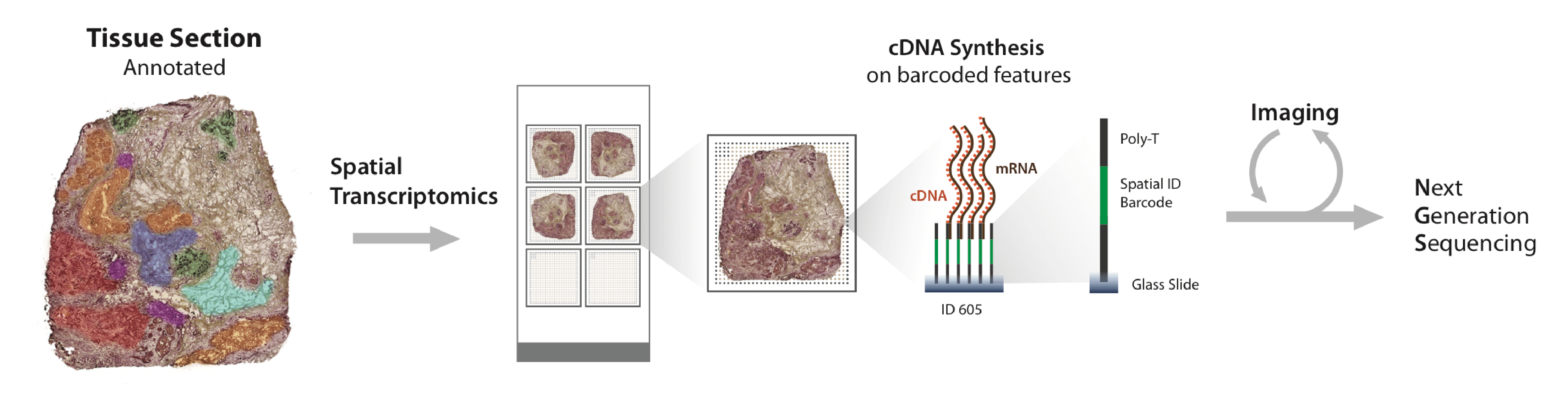
OCTO-vc 的独特之处在于,专注于空间生物学,即理解细胞在其组织环境中的行为,而非孤立状态下的行为。该模型使用了近 77M 个细胞的专有空间转录组数据进行训练,这些数据产生自超过 2500 份患者肿瘤样本,这本身就是一项壮举,因为历史上的其他空间转录组数据集通常采集自不到 100 名患者。
OCTO-vc 能够在真实组织样本的各个区域模拟虚拟细胞。例如,一个虚拟 T 细胞可以被引入到肿瘤的不同区域,以推断是否会被激活,是否能够杀死癌细胞。这种能力使研究人员能够构建出底层生物学的 全景图(holistic picture),而无需进行额外的实验。
空间转录组 (Spatial Transcriptomics) 技术的核心优势在于能够在 保留组织完整空间结构 的前提下,对于组织切片上的基因表达进行定量和定位。