YOLOv4 全面解析:核心改进、数据增强与网络架构
一、关于 YOLOv4
1、什么是 YOLOv4
YOLO v4(You Only Look Once version 4)是计算机视觉领域中经典的实时目标检测算法,由 Alexey Bochkovskiy 等人于 2020 年提出。其核心目标是在保证检测速度的同时显著提升检测精度,实现 "速度与精度的平衡",能够快速准确地识别图像或视频帧中多个目标的位置和类别,广泛应用于自动驾驶、安防监控、智能交通等实际场景。
2、相较于 YOLOv3 的核心优势
YOLOv4 在 YOLOv3 的基础上进行了全方位优化,关键提升包括:
- 主干网络升级:采用 CSPDarknet53,增强特征提取能力并降低计算成本
- 特征融合优化:引入 SPP 模块和 PANet 路径聚合网络,提升多尺度特征表达
- 损失函数改进:使用 CIOU Loss 替代传统 IOU Loss,优化边界框回归精度
- 数据增强升级:新增 Mosaic、CutMix 等强数据增强策略,提升模型泛化能力
- 工程优化:支持多 GPU 训练、混合精度训练(Apex),推理速度提升显著(YOLOv4-tiny 每秒可处理 120 帧)
二、YOLOv4 数据增强的创新做法
1、Bag of Freebies(无成本提升策略)
数据增强是 YOLOv4 中 "Bag of Freebies" 的核心组成 —— 指不增加模型复杂度和推理计算量,仅通过优化训练数据预处理,就能显著提升模型精度的技术手段。这类方法只增加训练阶段的计算成本,对推理速度完全无影响。
2、数据增强基础认知
(1)核心概念
通过对训练图像进行多样化变换,人为扩充数据集规模,让模型学习到更鲁棒的特征,从而缓解过拟合,提升在真实场景中的泛化能力。
(2)传统数据增强种类
基础变换包括:亮度 / 对比度 / 色调调整、图像缩放、随机裁剪、水平翻转、旋转等,YOLOv4 在这些基础上新增了 4 种关键增强策略。
3、YOLOv4 关键数据增强方法
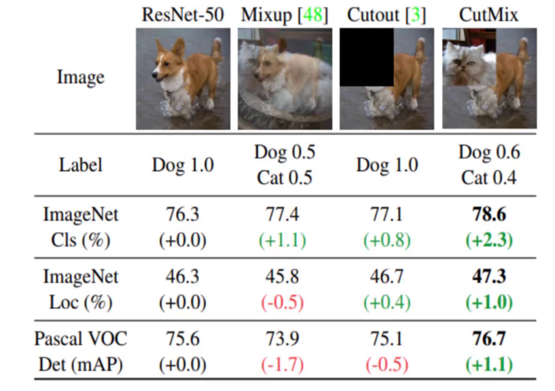
(1)马赛克数据增强(Mosaic)
这是 YOLOv4 最具代表性的数据增强手段,核心思想是将 4 张不同图像拼接成 1 张新图像进行训练,让模型同时学习多个场景、多个目标的特征。
-
技术由来:借鉴了 ResNet-50 的单图训练→Mixup(双图权重融合)→Cutout(随机遮挡)→CutMix(区域替换)的演进路线,最终通过 4 图拼接实现性能突破
-

-
实现逻辑:
- 采用 CutMix 技术,对 4 张原始图像进行随机裁剪(保留目标关键区域)
- 将裁剪后的 4 个图像块按 2×2 网格拼接,形成新图像
- 自动调整标签坐标,确保拼接后目标位置标注准确
-
核心优势:单张图像包含多个类别目标,迫使模型学习更通用的特征,同时减少对小批量数据的依赖,提升训练稳定性
-
关于 CutMix:作为 Mosaic 的基础,CutMix 的核心是在两个训练样本间随机切割矩形区域,用一个样本的区域替换另一个样本的对应区域,并按替换区域大小分配标签权重(例如:替换 30% 区域,则两个样本的标签权重分别为 0.7 和 0.3)。
(2)Random Erase(随机擦除)
在训练图像中随机选择一个矩形区域,用随机像素值或训练集的平均像素值填充该区域,模拟目标部分被遮挡的场景,迫使模型学习目标的全局特征而非局部细节。

(3)Hide and Seek(隐藏 - 寻找)
按预设概率随机选择图像中的多个小补丁区域并隐藏(填充为统一值),模拟目标被碎片化遮挡的情况,增强模型对部分遮挡目标的检测能力。

(4)SAT(自对抗训练)
通过在训练图像中引入随机噪点或微小扰动,人为增加训练难度,让模型学习对噪声的鲁棒性,提升在复杂真实场景中的检测稳定性。

三、YOLOv4 的核心改进技术
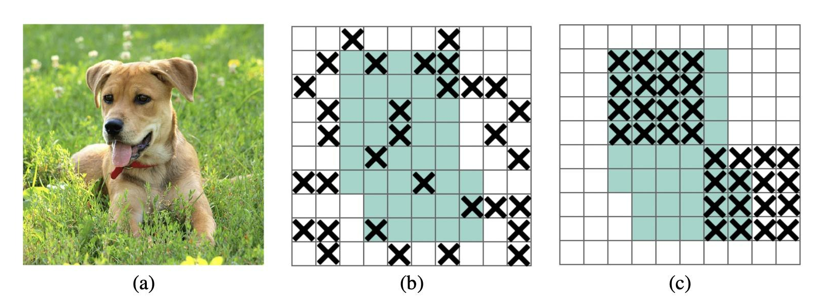
1、DropBlock:正则化优化(缓解过拟合)
DropBlock 是针对 CNN 的正则化技术,专门解决传统 Dropout 的局限性:
- 传统 Dropout:随机屏蔽特征图中的孤立像素,无法有效抑制冗余连接
- DropBlock 改进:随机屏蔽特征图中连续的区域块,强制模型学习分散的特征表示,减少对局部特征的依赖
- 核心作用:提升模型泛化能力,避免在训练集上过拟合,同时不影响推理速度
2、标签平滑(Label Smoothing)
解决传统独热标签的 "绝对化" 问题:
- 传统标签:目标类别为 1,非目标类别为 0,过于绝对化导致模型泛化能力差
- 标签平滑逻辑:对标签进行软化处理,例如原始标签 [0,1](狗),处理后为 [0.05, 0.95],表示 "是狗的概率 95%,同时包含 5% 其他类别的可能性"
- 核心优势:缓解模型过度自信,增强对相似类别目标的区分能力
3、损失函数改进:从 IOU 到 CIOU 的演进
边界框回归损失是目标检测的核心,YOLOv4 通过三次改进实现精度飞跃:
(1)传统 IOU Loss 的局限性
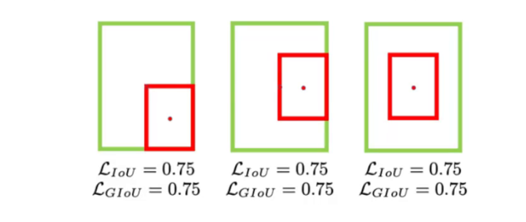
IOU(交并比)是边界框重叠度的度量,损失函数为1-IOU。但存在两个关键问题:
- 当预测框与真实框无重叠时,IOU=0,损失无法提供梯度引导
- 当多个预测框与真实框 IOU 相同,无法区分位置优劣(如中心偏移、长宽比不符)
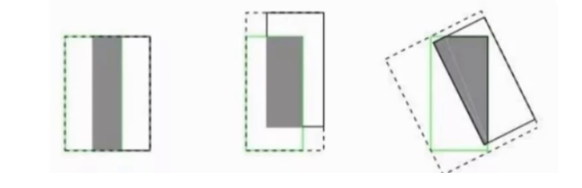
(2)改进 1:GIOU Loss(广义 IOU)
- 核心创新:引入最小封闭矩形 C(能同时包含预测框 A 和真实框 B)
- 公式:\(GIOU = IOU - \frac{|C - (A \cup B)|}{|C|}\)
- 损失函数:\(Loss = 1 - GIOU\)
- 优势:即使无重叠,也能通过封闭矩形提供梯度,引导预测框向真实框移动

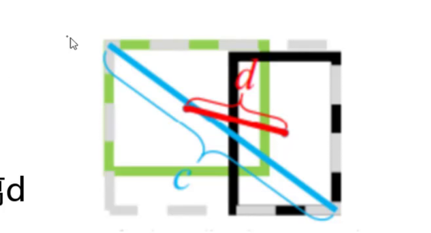
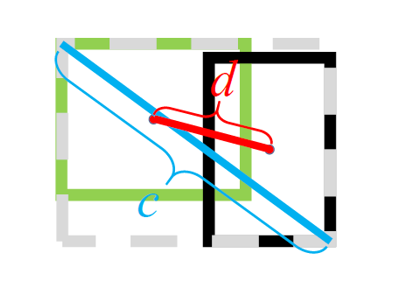
(3)改进 2:DIOU Loss(距离 IOU)
- 核心创新:在 IOU 基础上增加中心点距离约束
- 公式:\(DIOU = IOU - \frac{d^2}{c^2}\)(d 为两框中心点欧氏距离,c 为封闭矩形对角线长度)
- 优势:解决 GIOU 收敛慢的问题,直接优化边界框中心位置,回归更精准
-
(4)最终改进 3:CIOU Loss(完整 IOU)
- 核心创新:融合三大几何因素 —— 重叠面积(IOU)、中心点距离(d)、长宽比一致性(av)
- 公式:\(CIOU = IOU - \frac{d^2}{c^2} - \alpha v\)(α 为权重参数,\(v = \frac{4}{\pi^2}(arctan\frac{w^gt}{h^gt} - arctan\frac{w}{h})^2\))
- 优势:全面优化边界框的位置、大小和形状,成为 YOLOv4 的最终边界框回归损失
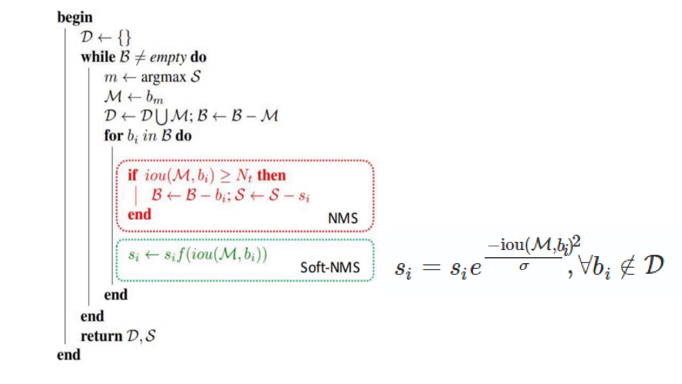
4、非极大值抑制(NMS)改进
NMS 的作用是过滤冗余检测框,保留最优结果,YOLOv4 对传统 NMS 进行了两项关键改进:
(1)传统 NMS 的缺陷
按置信度排序后,删除与基准框 IOU 超过阈值的所有框,容易导致近距离目标漏检(如密集人群、多车辆场景)。
(2)改进 1:DIOU-NMS
- 核心创新:除 IOU 外,引入中心点距离因素
- 筛选逻辑:不仅考虑重叠度,还根据两框中心点距离调整置信度衰减,避免误删近距离目标
- 优势:在密集目标场景中,漏检率显著降低
(3)改进 2:Soft-NMS
- 核心创新:不直接删除高重叠框,而是按重叠度衰减置信度
- 实现逻辑:使用高斯函数\(S_i = S_i \times e^{-\frac{IOU_{i,M}^2}{\sigma}}\)(σ=0.3),重叠度越高,置信度衰减越严重
- 优势:解决传统 NMS 中 "重叠框必删" 的问题,提升密集目标检测准确率
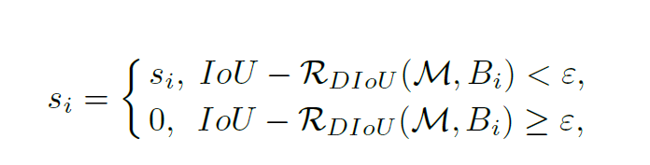
5、网络结构改进:从特征提取到特征融合
YOLOv4 的网络结构可分为 "主干网络→特征增强→特征融合→检测头" 四部分,核心改进如下:
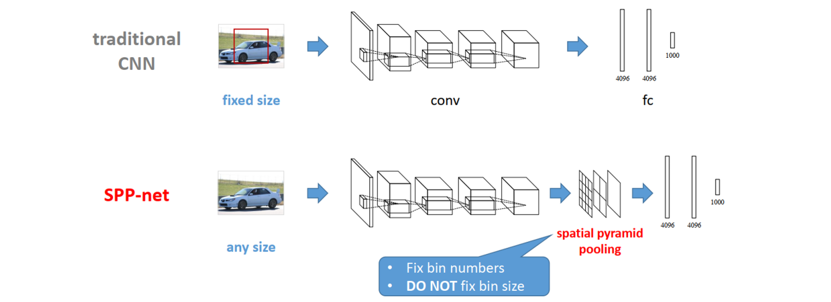
(1)改进 1:SPP-Net(空间金字塔池化)
- 核心问题:传统 CNN 要求输入图像尺寸固定,限制了多尺度特征学习
- 创新方案:在最后一个卷积层后接入 SPP 模块,对特征图进行多尺度池化(如 5×5、9×9、13×13),输出固定长度的特征向量
- 优势:支持任意尺寸图像输入,增强模型对不同尺度目标的适应能力,同时提升特征表达的丰富性

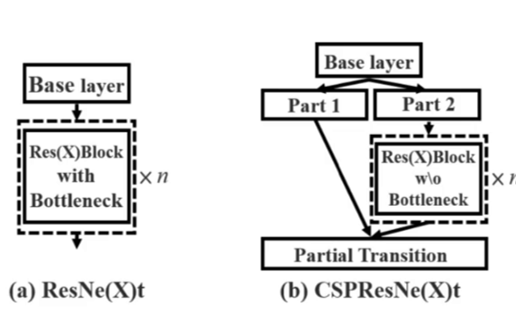
(2)改进 2:CSP-Net(跨阶段局部网络)
- 设计思路:将每个卷积块的特征图按通道维度拆分为两部分:
- 一部分经过残差网络进行特征变换
- 另一部分直接与变换后的特征图拼接(concat)
- 核心优势:
- 增强梯度流动,提升特征提取能力
- 减少计算量和内存占用(比 Darknet53 减少 20% 计算量)
- 可与多种主干网络结合(如 CSPDarknet53、CSPResNet)
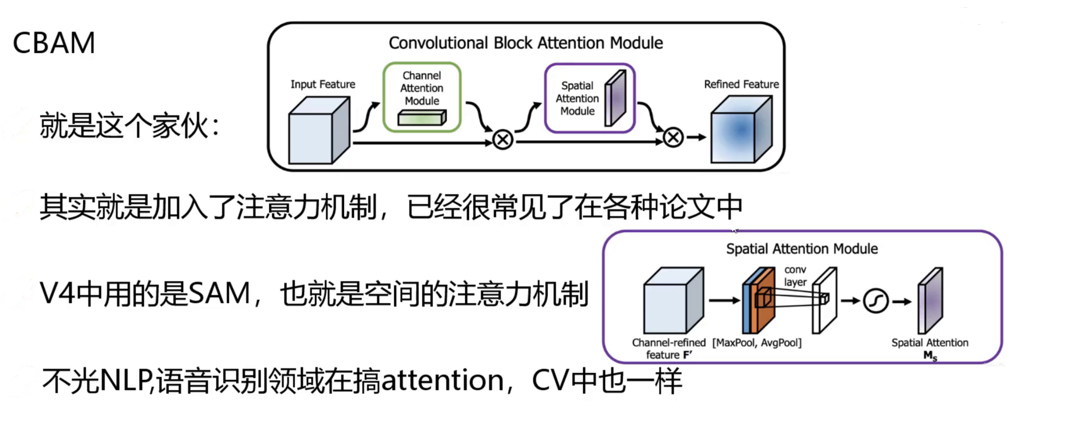
(3)注意力机制:SAM(空间注意力模块)
YOLOv4 采用 CBAM(卷积块注意力模块)中的空间注意力机制:
- 核心作用:通过学习特征图的空间权重,让模型聚焦于目标区域,抑制背景噪声
- 实现逻辑:对特征图进行全局平均池化和最大池化,融合后通过 sigmoid 生成空间注意力图,与原特征图加权融合
- 优势:仅增加少量计算量,显著提升目标区域的特征响应.
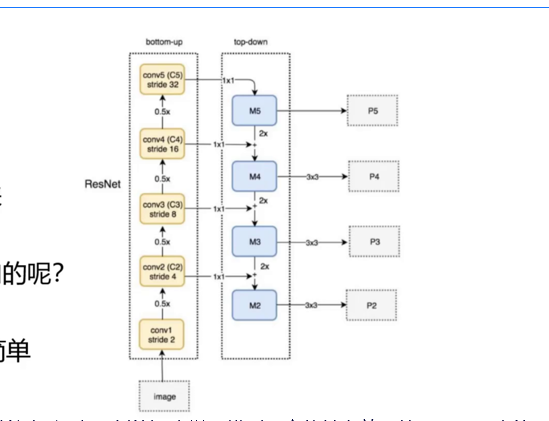
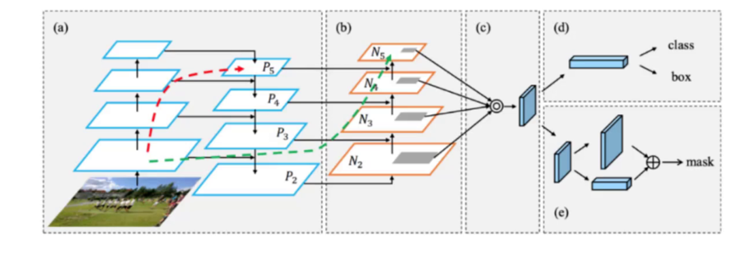
(4)PAN 路径聚合网络(Path Aggregation Network)
- 传统问题:自顶向下的特征金字塔(FPN)中,底层细节特征难以传递到顶层
- 创新方案:在 FPN 基础上增加自底向上的路径,形成双向特征融合
- 优势:底层特征(高分辨率、细节信息)与顶层特征(低分辨率、语义信息)充分融合,提升小目标检测精度
(5)激活函数与网格敏感性优化
① Mish 激活函数
- 公式:\(Mish = x \times tanh(softplus(x))\)
- 核心优势:在负区间保留微小梯度(不同于 ReLU 的硬截断),避免权重初始化时梯度消失,增强深层网络的特征传播
② 消除网格敏感性
- 传统问题:YOLO 系列通过网格预测目标中心,当目标中心接近网格边界时,sigmoid 函数难以输出极端值(0 或 1),导致预测不准确
- 优化方案:对 sigmoid 输出进行缩放和平移,公式为:\(b_x = \sigma(t_x) \times 2 - 0.5 + c_x\)(\(c_x\)为网格左上角 x 坐标)
- 优势:扩大中心坐标的预测范围,消除边界附近的预测偏差
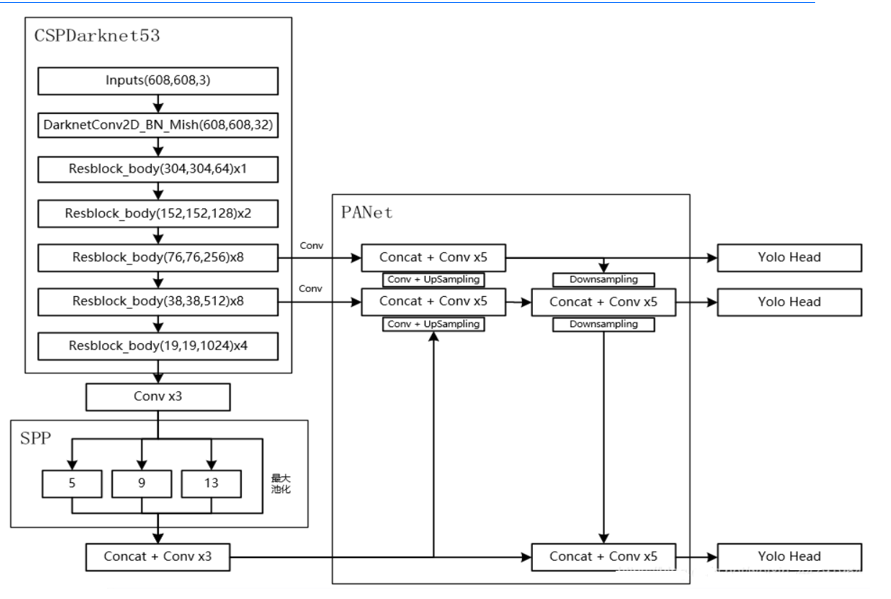
四、YOLOv4 整体网络架构
YOLOv4 的网络架构可概括为 "5 个核心模块" 的串联:
- 输入层:支持任意尺寸图像,经过 Mosaic、CutMix 等数据增强处理
- 主干网络(CSPDarknet53):负责基础特征提取,输出 3 种不同尺度的特征图
- 增强模块(SPP):对主干网络输出的最大尺度特征图进行多尺度池化,增强特征表达
- 特征融合(PANet):通过自顶向下 + 自底向上的双向融合,整合多尺度特征
- 检测头:采用 YOLOv3 的检测头结构,结合 CIOU Loss 和 DIOU-NMS,输出目标类别、置信度和边界框坐标