TPAMI 2025 | 从分离到融合:新一代3D场景技术实现双重能力提升!
本文提出了一种名为 OccScene 的新型相互学习 (mutual learning) 范式,旨在统一精细化的 3D 场景感知与高质量的生成任务。当前方法通常将生成与感知分离,生成模型仅作为数据增强器,这导致了灵活性受限、约束不足和目标不明确等挑战。OccScene 创新地将语义占据预测 (semantic occupancy prediction) 和文本驱动的场景生成整合到一个联合训练的扩散模型 (diffusion models) 框架中。
该框架通过一个基于 Mamba 的双重对齐模块,将语义占据信息作为先验知识,有效引导扩散过程,从而生成仅依赖文本提示的高保真、多视角一致的3D场景(包括图像/视频及其对应的语义占据栅格)。通过这种跨任务协同,感知模块可以利用生成的多样化场景得到增强,而增强的感知能力反过来又提升了生成质量,实现了“双赢”效果。实验证明,OccScene 不仅能生成逼真的室内外3D场景,还能显著提升下游3D语义占据预测任务的性能。
另外我整理了TPAMI 2025 CV相关论文合集,感兴趣的dd!
原文 资料 这里!

一、论文基本信息

基本信息
- 论文标题:OccScene: Semantic Occupancy-based Cross-task Mutual Learning for 3D Scene Generation
- 作者:Bohan Li, Xin Jin, Jianan Wang, Yukai Shi, Yasheng Sun, Xiaofeng Wang, Zhuang Ma, Baao Xie, Chao Ma, Xiaokang Yang, Wenjun Zeng
- 作者单位:上海交通大学, 宁波东方理工大学,Astribot, PhiGent Robotics
- 论文链接:https://arxiv.org/abs/2412.11183
摘要精炼
该研究旨在解决现有3D场景生成方法与下游感知任务分离、依赖真值标签、缺乏灵活性和精细约束的问题。核心贡献是提出了 OccScene,一个统一了3D场景感知与生成的相互学习框架。该框架在一个联合扩散过程中,利用感知模型预测的语义占据作为先验,指导文本驱动的场景生成,同时,生成的多样化数据也反哺感知模型的训练。
关键技术是一种名为Mamba的模块,它高效地对齐了语义占据信息和扩散模型的潜在特征,确保了跨视角生成的一致性和精细的几何语义引导。最终,论文证明了该方法不仅能生成高质量的3D场景,还能作为一个即插即用的训练策略,显著提升语义占据预测任务的性能,例如在 SemanticKITTI 数据集上实现了 113.28 的 FVD 和 19.86 的 FID,同时将多个基线感知模型的 mIoU 提升了高达 4.38%。
二、研究背景与相关工作
研究背景
3D感知模型的性能高度依赖于大规模、精细标注的数据集,但这类数据的获取成本高昂。尽管生成扩散模型在2D图像合成方面取得了巨大成功,并被用于为下游任务生成合成数据,但在生成具有真实布局和几何结构的场景级3D数据方面仍面临巨大挑战。
现有方法通常依赖于3D真值标签(如3D边界框)来辅助生成,这限制了生成场景的多样性和灵活性,特别是难以生成罕见的“角落案例”。此外,这些粗粒度的先验信息(如边界框)不足以为复杂的真实世界场景生成提供像素级的精细语义与几何约束。因此,迫切需要一种不依赖真值标签、能生成多样化且对下游感知任务有价值的3D场景生成新范式。
相关工作
相关工作主要分为两大类。
第一类是用于场景生成的扩散模型,如 DriveDreamer、MagicDrive 等,它们尝试生成逼真的驾驶场景。然而,这些方法大多在推理过程中依赖地面真实(GT)标签进行几何约束,限制了其灵活性,并且通常将生成与感知视为独立过程,降低了生成数据对感知任务的针对性。
第二类是语义占据预测(SOP),这是一个统一了场景补全与语义分割的3D感知任务。从早期的 SSCNet 到近期的 MonoScene、TPVFormer等,这些方法在从单目或多视角图像进行3D场景理解方面取得了显著进展。然而,它们都依赖于现有的数据集进行监督训练,如何利用强大的生成模型来创造高质量的训练数据对以提升感知性能,仍然是一个未被深入探索的问题。现有工作普遍缺乏一个将生成与感知进行联合优化以实现相互促进的框架。
三、主要贡献与创新
-
提出新型相互学习范式:首次提出了一个将3D场景感知与生成深度融合的生成范式,通过在联合扩散过程中协同优化,实现了两个任务的相互增益。
-
提出Mamba模块:设计了一个高效的MDA模块,利用摄像机轨迹感知来保证跨视角的生成一致性,并通过对齐的上下文信息,将精细的几何与语义先验(来自语义占据)融入扩散模型,提升了生成质量。
-
实现感知驱动的生成与数据增强:将感知模型集成到生成流程中,不仅通过感知的先验知识提升了生成效果,还利用文本驱动生成了多样化和定制化的场景数据,作为一种有效的数据增强手段,显著提升了下游感知模型的性能。
四、研究方法与原理
总体框架与核心思想
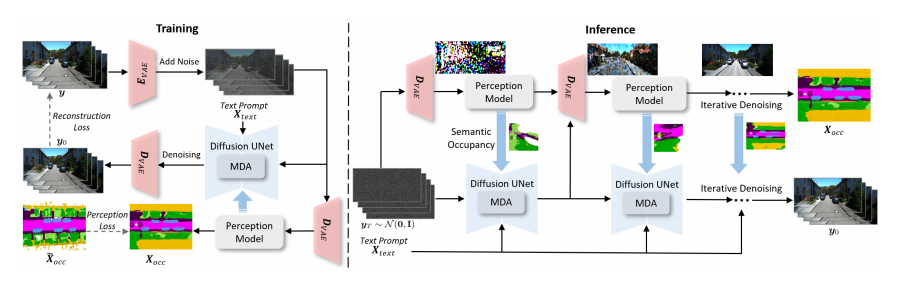
OccScene 的核心思想是跨任务协同与联合优化。它将通常独立的3D场景生成和语义占据感知两个任务耦合在一个统一的扩散学习框架中。其设计哲学可以概括为“生成引导感知,感知约束生成”。
具体来说,框架包含一个生成式的扩散U-Net和一个感知模型。在训练的每一步,输入的带噪图像不仅被送入扩散模型进行去噪,还被送入感知模型预测其语义占据栅格 (semantic occupancy grids)。这个预测出的占据栅格随后作为额外的、精细的条件,输入到扩散U-Net中,以几何和语义的方式引导生成过程。这种设计使得生成过程不再是盲目的,而是有明确的3D结构感知的,从而提升了生成图像的真实性和一致性。
关键实现与评估原理
关键实现细节:
- 联合扩散方案:框架采用两阶段训练策略。第一阶段,固定预训练的感知模型,仅训练扩散U-Net以适应特定数据。第二阶段,联合训练扩散U-Net和感知模型,实现相互促进。损失函数结合了潜在扩散模型 (Latent Diffusion Model, LDM) 的重构损失和感知损失:
L = L LDM + α ˉ t L p L = L_{\text{LDM}} + \sqrt{\bar{\alpha}_t} L_p L=LLDM+αˉtLp
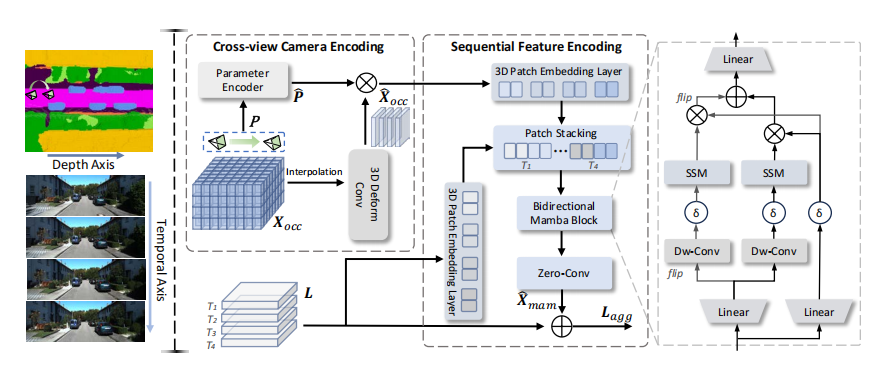
其中,感知损失 L p L_p Lp 包含语义、几何和类别加权损失,而 α ˉ t \sqrt{\bar{\alpha}_t} αˉt 因子根据噪声水平动态调整监督强度,确保训练稳定。 - Mamba模块:这是实现高效约束的关键。该模块首先通过“跨视角相机编码”将相机参数融入语义占据特征,实现轨迹感知和视角一致性。然后,利用一个双向的 Mamba 模块(一种状态空间模型 (State Space Models, SSMs)),沿着深度轴和时间轴顺序扫描占据特征和潜在特征,实现上下文对齐和高效特征融合。
- 推理过程:推理时,从高斯噪声开始,在每个去噪步骤中,感知模型都会根据当前生成的(带噪)图像预测出语义占据,并将其作为条件送入下一轮的扩散U-Net中,形成一个迭代优化的闭环。
核心评估原理与指标:
- 生成质量评估:
- 弗雷彻初始距离(Frechet Inception Distance, FID):衡量生成图像与真实图像在特征空间的分布相似度,分值越低越好。
- 弗雷彻视频距离 (Frechet Video Distance, FVD):专为视频生成设计,评估生成视频的质量和时序一致性,分值越低越好。
- 感知性能评估:
- 平均交并比 (Mean Intersection over Union, mIoU):语义占据预测任务的核心指标,用于评估预测体素类别与真值体素类别的重合度,分值越高越好。
五、实验结果与分析
实验设置
- 数据集:
- 室内场景: NYUv2
- 室外驾驶场景: SemanticKITTI, NuScenes-Occupancy
- 评估指标:
- 生成任务: FID, FVD
- 感知任务: mIoU
- 对比基线:
- 生成模型: Stable Diffusion (Finetune), ControlNet, Tune-a-video, MagicDrive 等
- 感知模型: MonoScene, TPVFormer, OccFormer, NDC-Scene 等
- 关键超参: 采用 50 个采样步数作为效率与效果的最佳平衡点。
核心实验与结论
【一项最能体现本文贡献的核心实验】
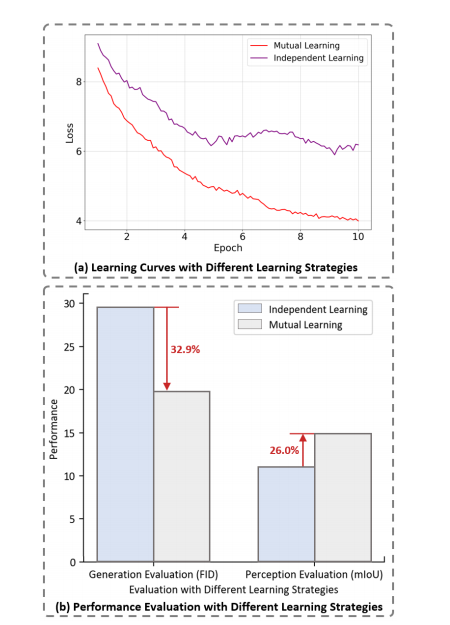
- 实验目的: 验证“联合扩散方案(JDS)”相较于传统“分离式”方案(即离线生成数据再训练感知模型)的优越性,证明相互学习机制的有效性。
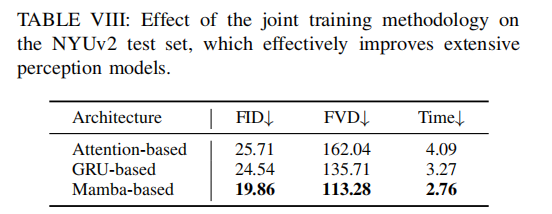
-
关键结果: 在 SemanticKITTI 验证集上的消融实验(见表 VII)显示:
- 不使用JDS(w/o JDS)时,FID 为 28.52,FVD 为 187.21,mIoU 为 12.94%。
- 使用JDS(完整OccScene模型)时,FID 降至 19.86,FVD 降至 113.28,mIoU 提升至 14.98%。
此外,图 5 的学习曲线表明,相互学习策略能够引导模型找到更优的损失最小值,避免了独立学习中途可能出现的停滞。
-
作者结论: 结果明确表明,联合扩散方案(相互学习)对生成和感知任务均有显著益处。对于生成任务,实时的感知反馈提供了更强的约束,使 FID 和 FVD 分别降低了约 30% 和 39%。对于感知任务,通过在生成过程中利用不同噪声水平的图像进行训练,感知模型获得了更强的鲁棒性,mIoU 提升了 2.04 个百分点。这证明了 OccScene 的核心机制——跨任务协同——是成功的。
六、论文结论与启示
总结
本文成功提出了 OccScene,一个创新性地将3D场景感知与生成统一在相互学习框架下的方法。通过设计一个联合扩散方案,并引入新颖的Mamba模块,OccScene 实现了仅通过文本提示便能生成高质量、多视角一致的3D场景及其语义占据。该框架的核心优势在于打破了生成与感知的壁垒,感知模型为生成提供精细的3D结构先验,而生成过程中的多样化数据又反过来增强了感知模型的性能和鲁棒性,形成了良性循环。大量的室内与室外场景实验结果不仅展示了其卓越的场景生成能力,也证明了其作为一种即插即用的训练策略,能显著提升现有3D语义占据预测模型的SOTA性能。
展望
尽管论文未明确阐述未来工作,但其研究为后续探索开辟了几个潜在方向:
- 扩展到更多模态与任务:可以将此相互学习框架扩展到包含LiDAR点云、音频等多模态数据的生成与感知任务,或应用于更复杂的下游任务,如3D实例分割或交互式场景编辑。
- 模型效率优化:虽然 Mamba 提升了效率,但在高分辨率、长时序视频生成方面仍有计算压力。未来可以研究更轻量级的对齐与生成架构。
- 探索更深层次的协同机制:目前是感知结果指导生成,未来可以探索更深层次的特征级交互,让两个任务的网络层之间进行更紧密的知识交换,可能进一步激发性能潜力。