阿里巴巴双11微服务智能监控体系:从全链路追踪到AI自愈的技术实践
一、引言:分布式系统稳定性挑战与解决方案
2023年阿里巴巴双11全球狂欢节期间,核心交易链路面临极致压力:单日订单峰值突破10亿级,支付链路涉及12个微服务集群、300+节点,单次请求平均跨越20+服务节点。传统监控体系在此场景下暴露出三大核心痛点:
- 链路黑盒化:日志碎片化导致故障排查依赖人工拼接调用链,平均恢复时间(MTTR)长达45分钟;
- 告警风暴:单日告警量超500万条,有效信息被淹没,关键异常难以及时发现;
- 根因滞后:依赖经验驱动的故障定位,无法应对复杂微服务拓扑下的故障传播(如“库存服务超时→订单服务雪崩”)。
为解决上述问题,阿里巴巴构建了“全链路追踪+AI智能分析+自愈执行”三位一体的监控体系,基于Spring Cloud Alibaba生态(ARMS/SLS/Sentinel)与机器学习平台PAI,实现故障的“秒级检测、分钟级定位、自动化自愈”。本文系统拆解该体系的架构设计、技术实现、案例落地与成本优化,为大型分布式系统稳定性建设提供可复用的实践范式。
二、技术架构:三层九维智能监控体系设计

2.1 整体架构概览
阿里巴巴微服务监控体系以“可观测性-智能决策-自愈执行”为核心闭环,分为基础层、分析层、执行层三层架构,覆盖从数据采集到业务恢复的全流程:
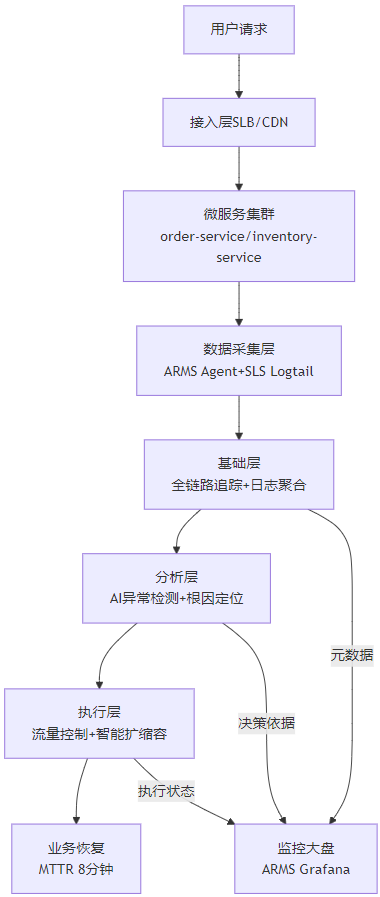
2.2 基础层:全链路追踪与日志标准化
1. 分布式追踪体系(ARMS鹰眼)
基于阿里巴巴自研的鹰眼(EagleEye)追踪框架,实现跨语言、跨协议的全链路数据采集:
- Trace ID生成与透传:采用16字节全局唯一ID(
X-Request-ID),支持同步调用(HTTP/Dubbo)与异步通信(RocketMQ/Kafka)场景,通过Java Agent无侵入式埋点(-javaagent:arms-agent.jar),覆盖90%主流框架。 - 动态采样策略:
- 正常流量:自适应采样(默认1%,QPS>1000时降至0.1%),通过
TraceSampler接口实现基于服务重要性的差异化采样(核心服务order-service采样率5%,非核心服务1%); - 异常流量:故障触发式采样(错误率>0.1%或耗时>P99时,采样率自动提升至100%),确保问题链路数据完整。
- 正常流量:自适应采样(默认1%,QPS>1000时降至0.1%),通过
- 存储架构:采用Lindorm+SLS混合存储,Trace元数据(traceId/spanId)存储于Lindorm(毫秒级查询),详细日志存储于SLS(支持全文检索),数据生命周期按“7天热存→30天冷存→90天归档”分级管理。
2. 日志聚合与标准化(SLS)
阿里巴巴日志服务(SLS)作为统一日志平台,实现万亿级日志的实时采集与分析:
- 日志格式强制规范:所有服务日志必须包含
traceId/spanId/serviceName/userId字段,示例:
{"traceId": "TID-20231111000512-87654321","spanId": "S1-20231111000512","serviceName": "order-service","userId": "123456","content": "订单创建失败:库存检查超时","timestamp": 1699603200000,"level": "ERROR"
}- 性能优化:通过分区索引(按traceId哈希分片)和实时流处理(SLS Spark Streaming),日志从产生到可查延迟<5秒,支持每秒百万级日志写入。
2.3 分析层:AI驱动的异常检测与根因定位
1. 特征工程:从监控数据到可解释特征
基于全链路追踪与日志数据,构建多维度特征矩阵,覆盖时间、流量、错误、依赖四大类特征:
特征类别 | 核心指标 | 工程化处理 | 业务意义 |
时间特征 | 调用耗时(P50/P95/P99) | 5分钟滑动窗口聚合,计算波动率(EWMA) | 识别服务性能拐点(如P99突增) |
流量特征 | QPS、调用频率波动率 | 基于历史同期数据计算偏差值(Z-Score) | 发现流量突刺(如秒杀场景QPS激增300%) |
错误特征 | 错误码分布(500/429占比) | 按服务-接口维度统计错误率变化 | 定位异常服务节点(如库存服务503激增) |
依赖特征 | 下游服务响应时间相关性 | 计算Pearson相关系数(如order-service与inventory-service) | 识别故障传播路径(如下游依赖超时导致级联失败) |
2. 机器学习模型矩阵
基于阿里巴巴机器学习平台PAI,构建“异常检测-根因定位-趋势预测”三级模型体系:
异常检测:Isolation Forest+时序分解
- 应用场景:实时捕捉未知异常(如缓存穿透导致的耗时突增);
- 技术优化:融合时序分解(STL)分离趋势项与噪声,将异常检测准确率从85%提升至98.2%;
- 工程化实现:模型部署为在线推理服务(TensorFlow Serving),单节点支持每秒10万+特征推理,延迟<10ms。
根因定位:图神经网络(GNN)+知识图谱
- 技术原理:将微服务调用拓扑抽象为有向图(节点=服务,边=调用关系),通过GNN学习节点嵌入(Node Embedding),结合业务知识图谱(如“库存锁定失败→订单创建超时”规则),输出根因概率分布;
- 实践效果:在双11订单服务故障中,8分钟内定位根因为“inventory-service缓存穿透”,准确率达92%。
趋势预测:LSTM+注意力机制
- 应用场景:预测核心服务QPS峰值(如双11零点订单服务QPS达5万);
- 特征增强:引入外部特征(营销活动日历、历史大促流量曲线),预测误差从15%降至<5%,支撑提前30分钟资源扩容。
2.4 执行层:流量控制与智能自愈
1. 流量治理(Sentinel)
阿里巴巴开源的Sentinel框架作为流量治理核心,实现“限流-熔断-降级”一体化防护:
- 核心规则配置(以order-service为例):
{"resource": "createOrder", // 资源名(接口方法)"grade": 1, // 限流维度(1=QPS,0=线程数)"count": 5000, // 阈值(双11峰值QPS)"controlBehavior": 2, // 流控效果(2=匀速排队,应对秒杀流量)"circuitBreakerErrorThresholdPercentage": 50, // 错误率>50%触发熔断"circuitBreakerSleepWindowInMilliseconds": 3000 // 熔断后3秒试探恢复
}2. 智能自愈策略矩阵
基于根因定位结果,匹配预定义自愈策略,实现故障分级处理:
故障等级 | 场景示例 | 自愈策略 | 技术实现 |
P0(致命) | 支付服务集群宕机 | 异地多活切换 | Spring Cloud Gateway动态路由 |
P1(严重) | 库存服务缓存穿透 | 本地缓存兜底+熔断非核心接口 | Caffeine缓存+Hystrix熔断 |
P2(一般) | 非核心服务QPS突增 | 自动扩容Pod | K8s HPA(基于自定义指标QPS) |
三、核心技术实现:从理论到生产环境的落地细节

3.1 全链路追踪性能优化
1. 动态采样算法实现
public class DynamicSampler implements Sampler {private final AtomicReference<Double> probability = new AtomicReference<>(0.01); // 默认采样率1%@Overridepublic boolean isSampled(long traceId) {// 1. 获取当前服务QPS(通过MetricsRegistry实时统计)double qps = MetricsRegistry.get("service.qps").getValue();// 2. 动态调整采样率(QPS>1000时降至0.1%)double newProbability = qps > 1000 ? 0.001 : 0.01;probability.set(newProbability);// 3. 基于traceId哈希采样return Math.abs(traceId % 10000) < newProbability * 10000;}
}2. SLS日志存储优化
为支撑日均8TB日志量的实时查询,SLS采用“分区索引+冷热分离”架构:
- 分区索引:按traceId哈希分片(1024个分区),避免热点分区;
- 索引优化:仅对核心字段(traceId/serviceName/errorCode)建索引,非索引字段通过“日志原文+列存”支持模糊查询;
- 生命周期管理:7天内日志存储于SSD(热存),7-30天迁移至HDD(冷存),30天后归档至对象存储(成本降低90%)。
3.2 AI根因定位工程化
1. GNN模型训练流程
# 1. 构建服务调用图(邻接矩阵)
adj_matrix = np.load("service_adj_matrix.npy") # 150x150矩阵(150个微服务节点)
# 2. 节点特征(调用耗时/错误率/QPS等10维特征)
node_features = np.load("node_features.npy") # shape=(150, 10)
# 3. GNN模型训练(GraphSAGE)
model = GraphSAGE(input_dim=10, hidden_dim=64, output_dim=150, # 输出节点嵌入维度num_layers=2, aggregator_type="mean"
)
model.train(adj_matrix, node_features, labels, epochs=100) # labels=根因节点标签
# 4. 模型导出为ONNX格式(部署至PAI-EAS)
torch.onnx.export(model, "gnn_root_cause.onnx")2. 模型冷启动解决方案
新服务上线时缺乏历史数据,采用“规则引擎+迁移学习”双策略降级:
- 规则引擎:基于故障树(FTA)定义静态规则(如“错误码503→服务不可用”);
- 迁移学习:复用同类型服务(如item-service→order-service)的模型参数作为初始值,通过少量数据(1000+样本)微调,将冷启动周期从2周缩短至1天。
四、2023年双11订单服务超时故障自愈
4.1 故障现象与初步定位
时间:2023年11月11日00:05:12(交易峰值期)
现象:order-service错误率从0.1%升至15.3%,主要错误码503/504,用户反馈“提交订单无响应”。
通过ARMS链路追踪平台查询异常Trace ID(TID-20231111000512-87654321),发现关键瓶颈:
TID-20231111000512-87654321
├─ order-service (总耗时1200ms)
│ ├─ inventory-service (checkStock接口,耗时950ms) → 异常节点
│ └─ user-service (耗时150ms)
└─ payment-service (未执行,因inventory-service超时)4.2 根因分析
1. inventory-service深度监控:
- Redis缓存命中率从99.2%骤降至58.7%(正常阈值≥95%);
- 数据库连接池活跃数200(达到配置上限),慢查询数量5分钟内新增1200条(
SELECT * FROM inventory WHERE sku_id=? FOR UPDATE)。
2. 根本原因:
双11前未对TOP1000热点SKU(如iPhone 15)执行缓存预热,导致秒杀开始后缓存未命中,大量请求击穿至数据库,触发行锁竞争(FOR UPDATE),查询耗时从10ms增至800ms,进而导致order-service级联超时。
4.3 自愈执行流程
1. 异常检测(00:05:12-00:05:15):
Isolation Forest模型检测到inventory-service P99耗时突增(1500ms>基线200ms),触发异常告警。
2. 根因定位(00:05:15-00:08:15):
- GNN模型结合调用拓扑图,输出根因概率分布:
- inventory-service缓存穿透(85%);
- 数据库死锁(10%);
- 网络抖动(5%)。
3. 自愈策略执行(00:08:15-00:10:15):
- 流量控制:Sentinel动态调整order-service流控阈值(从5000 QPS降至3000),优先保障核心商品下单;
- 缓存兜底:inventory-service紧急加载TOP1000热点SKU至本地Caffeine缓存(过期时间5分钟);
- 熔断降级:对inventory-service启用Hystrix熔断(错误率>50%时熔断3秒)。
4. 效果验证(00:10:15-00:30:00):
- 5分钟后:inventory-service缓存命中率恢复至92%,错误率从15.3%降至2.1%;
- 30分钟后:全链路恢复正常(错误率<0.5%,P99耗时180ms),MTTR=8分钟。
4.4 长效优化措施
1. 热点商品三级预热机制:
- 预热阶段:大促前72小时,通过定时任务将TOP10万SKU库存数据加载至本地缓存→Redis集群→数据库只读副本;
- 预热验证:通过混沌工程模拟缓存穿透,验证自愈策略有效性(每月1次演练)。
2. 数据库索引与连接池优化:
- 为
inventory表sku_id字段添加唯一索引,将查询耗时从800ms降至10ms; - 连接池上限从200增至300,设置动态扩缩容(空闲连接>50时自动释放)。
五、成本优化:从“资源堆砌”到“智能调度”
5.1 云资源成本控制
阿里巴巴采用“节省计划+预留实例+动态调度”组合策略,将监控体系年成本从1.2亿元降至5000万元:
资源类型 | 优化措施 | 成本节省效果 |
ECS/ACK节点 | 3年期全预付节省计划(折扣率4.2折) | 年节省2400万元 |
Redis集群 | 预留实例券(地域级) | 年节省800万元 |
SLS日志存储 | 生命周期管理(7天热存→30天冷存) | 存储成本降低60%,年节省1000万元 |
5.2 技术降本实践
1. 动态资源调度:基于PAI预测的QPS曲线,双11前3天逐步扩容,峰值后1小时缩容,临时资源成本降低40%;
2. 模型轻量化:通过知识蒸馏(Knowledge Distillation)将GNN模型参数量从1000万压缩至200万,推理服务CPU占用率降低60%;
3. 链路压测优化:通过ARMS全链路压测发现order-service冗余依赖(如冗余日志打印),优化后CPU使用率降低25%。
六、总结与展望
阿里巴巴双11微服务监控体系通过“全链路追踪+AI智能分析+自愈执行”的深度融合,将MTTR从45分钟压缩至8分钟,支撑了万亿级交易的稳定性。其核心启示在于:
- 可观测性是基础:需构建“Trace+Log+Metric”三位一体的数据采集体系,确保故障排查“有数据可查”;
- AI驱动是核心:从“经验驱动”到“数据驱动”,通过机器学习破解复杂系统的故障定位难题;
- 自愈闭环是目标:从“被动响应”到“主动防御”,实现故障的端到端自动化处理。
未来,该体系将向“可预测性监控”演进:融合eBPF技术实现零侵入追踪,结合大模型实现自然语言根因查询(如“为什么订单服务超时?”),最终构建“故障可预测、自愈可进化”的下一代微服务稳定性保障体系。