拥塞控制原理
目录
拥塞原因与代价
拥塞控制方法
端到端拥塞控制
网络辅助的拥塞控制
TCP拥塞控制
拥塞感知
速率控制方法
联合控制
策略概述
慢启动
AIMD
总结
吞吐量
公平性
小结
网络拥塞本质是网络资源的供给无法满足流量需求,例如带宽资源不足,路由器缓存容量有限,路由策略低效,流量突发性等问题导致的分组延迟急剧增加(数据在网络中排队时间过长)、丢包率显著上升(路由器缓存溢出,被迫丢弃分组)、网络吞吐量不升反降(大量丢包导致重传,无效流量占用带宽)等一系列问题。
拥塞控制是一套传输层机制(TCP 是典型代表),核心目标是:
- 让发送方的发送速率适配网络的承载能力,避免过多源以过高速率发送数据引发或加剧拥塞;
- 拥塞发生时快速收敛,恢复网络稳定性;
- 兼顾资源利用率和公平性(不同数据流公平分配网络资源)。
其与流量控制不同:流量控制是端到端的(防止接收方缓冲区过载),依赖接收方的窗口通告;拥塞控制是全网维度的(防止网络链路、路由器拥塞),依赖网络丢包、延迟等全局状态反馈。
拥塞原因与代价
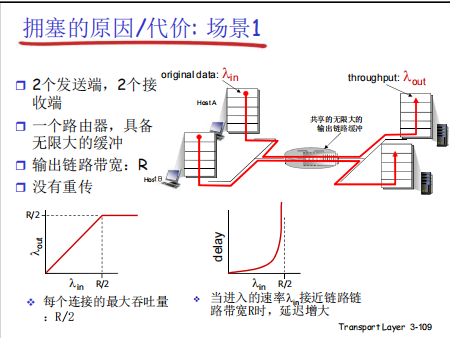
吞吐量受限:链路带宽的上限会让吞吐量 “触顶”,无法随发送速率无限增长;
延迟剧增:输入速率接近链路带宽时,延迟会因排队而急剧恶化。
即使在缓存无限大、无丢包的理想条件下,链路带宽的有限性也会导致拥塞,进而引发吞吐量和延迟的双重问题。
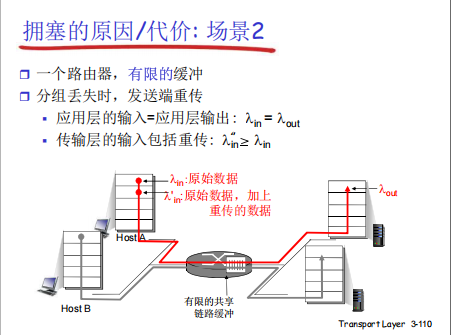
这个场景的核心是:有限缓存→丢包→重传→额外流量→更拥塞的恶性循环:
-
缓存溢出导致丢包:由于路由器缓存有限,当传输层总输入速率
λ'_in超过链路带宽时,缓存会溢出,导致分组丢失。 -
重传引入额外流量:丢包触发发送端重传,重传的分组会加入传输层的输入流,使
λ'_in进一步增大。 -
恶性循环加剧拥塞:重传流量挤占了更多带宽和缓存,导致更多分组丢失、更多重传…… 最终使网络进入拥塞崩溃状态—— 有效吞吐量急剧下降,延迟剧增,网络几乎无法传输有效数据。
有限缓存和重传机制的组合是拥塞恶化的关键推手:有限缓存必然导致丢包,而重传又会引入额外流量,形成恶性循环,最终使网络吞吐量暴跌、延迟失控。这也解释了为何 TCP 拥塞控制需要在 重传时机和速率调整之间做精细平衡,避免陷入这种恶性循环。
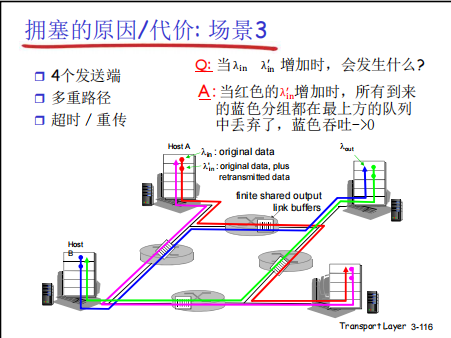
这张图展示了多流竞争、多重路径场景下,恶性循环拥塞导致的资源抢占与吞吐量崩溃问题:
- 资源抢占:当某条流(红色)的输入速率
λ_in大幅增加,会抢占共享链路的带宽和缓存资源。 - 队列溢出丢包:由于共享缓存有限,其他流(蓝色)的分组会因队列满被丢弃。
- 重传加剧竞争:丢包触发蓝色流的超时重传,重传流量进一步挤占资源,导致更多蓝色分组被丢弃。
- 吞吐量崩溃:最终蓝色流的有效数据几乎无法传输,吞吐量
λ_out趋近于 0—— 这体现了拥塞的不公平性(某条流的过度发送会 “饿死” 其他流),以及重传 - 拥塞 - 更重传的恶性循环。
该场景揭示了多流竞争下拥塞的极端代价:单一流的过度发送会通过资源抢占,导致其他流的吞吐量彻底崩溃。这也说明拥塞控制不仅要避免全网拥塞,还要保障流之间的公平性,防止某条流垄断网络资源。
拥塞控制方法
端到端拥塞控制
- 核心逻辑:网络层不向运输层提供显式的拥塞反馈,端系统需通过观察网络行为(如分组丢失、时延变化)间接推断拥塞。
- 典型实现(TCP):
- TCP 无法从 IP 层获取拥塞的直接通知,而是通过报文段丢失(超时或 3 次重复确认)判断网络拥塞,进而减小发送窗口;
- 还可通过往返时延(RTT)增加推断拥塞程度,动态调整发送速率。
网络辅助的拥塞控制
- 核心逻辑:路由器主动向发送方提供显式的拥塞反馈信息,让发送方直接知晓网络状态。
- 反馈方式:
- 简单比特标记:用一个比特(如 SNA、DECbit、TCP/IP 的 ECN、ATM 机制)指示链路是否拥塞;
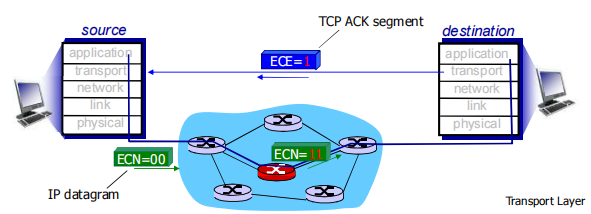
-
- 显式速率建议:路由器直接告知发送方可支持的最大发送速率(如 ATM 的可用比特率 ABR 拥塞控制)。
- 通知机制:
- 「阻塞分组(choke packet)」:路由器直接发分组告知发送方已拥塞;
- 「分组字段标记」:路由器标记数据分组中的字段,接收方收到后通知发送方。
TCP拥塞控制
拥塞感知
TCP 通过分级检测区分轻微拥塞和严重拥塞:

速率控制方法
TCP 针对拥塞发生时和拥塞缓解时设计了不同的速率调整逻辑:
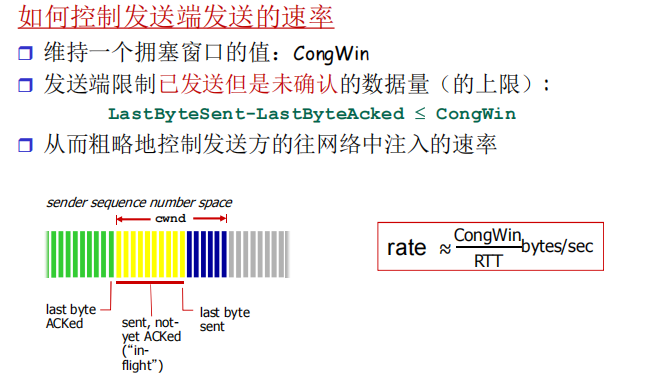
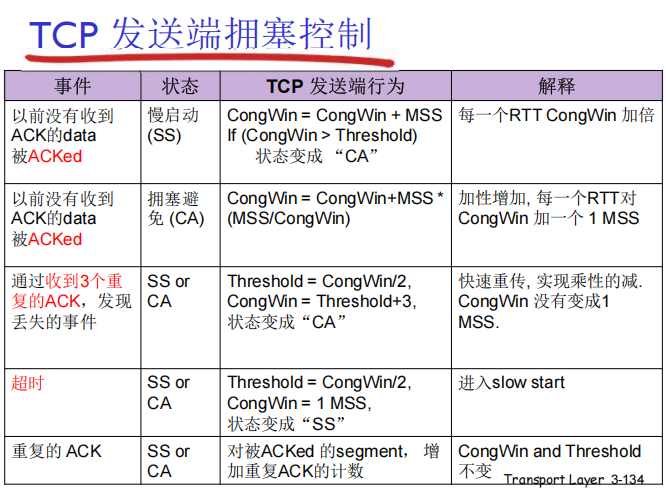
1. 拥塞时:CongWin 减小(应对网络拥塞)
拥塞窗口的缩小策略与拥塞严重程度挂钩:
- 超时丢包(严重拥塞):CongWin 直接降至
1 MSS,进入慢启动(SS)阶段;之后每个 RTT倍增,直到增长到 超时前 CongWin 的一半,再进入拥塞避免(CA)阶段。 - 3 次重复 ACK(轻微拥塞):CongWin 直接降至 原窗口的一半,直接进入拥塞避免(CA)阶段。
2. 正常时:CongWin 增大(利用网络资源)
当未检测到拥塞(正常收到 ACK)时,CongWin 分阶段增长:
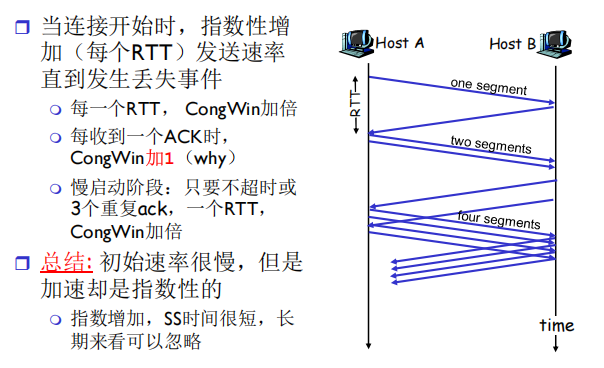
- 慢启动(SS)阶段:每个 RTT,CongWin 指数级倍增,快速探测网络的承载上限。
- 拥塞避免(CA)阶段:每个 RTT,CongWin 线性增长,稳定速率以避免过度拥塞。
联合控制
TCP 最终的发送速率是拥塞控制(网络视角)和 流量控制(接收方视角) 的协同结果,通过取两者最小值,确保发送行为既不压垮网络,也不溢出接收方缓冲区:
发送端最终的发送速率,需同时满足:
- 拥塞控制要求:不能因发送过快导致网络拥塞(由 CongWin 限制);
- 流量控制要求:不能因发送过快导致接收方缓冲区溢出(由 RecvWin 限制)。
实际发送窗口 SendWin 取 拥塞窗口 和 接收窗口 的最小值,即:SendWin = min{CongWin, RecvWin}
- 若
CongWin < RecvWin:发送速率由拥塞控制主导(网络是瓶颈); - 若
RecvWin < CongWin:发送速率由流量控制主导(接收方是瓶颈)。
策略概述
慢启动
原理:TCP 连接建立初期,通过拥塞窗口(CongWin)的指数级增长,在不引发网络拥塞的前提下,快速探测网络的可用带宽。
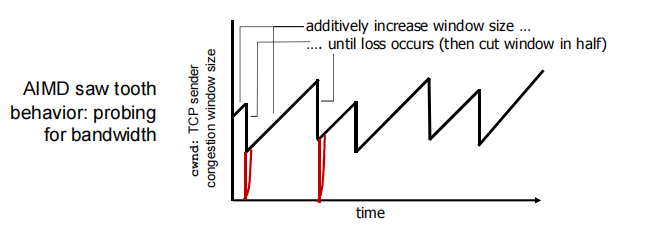
AIMD
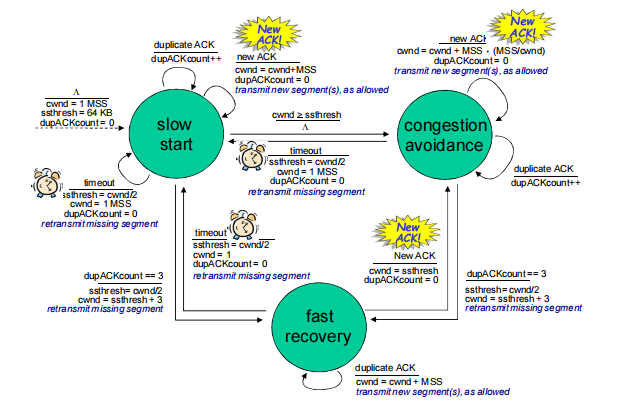
AIMD是 TCP 拥塞控制的核心算法框架,包含 拥塞避免 和 拥塞恢复 两个维度:
1. 加性增(Additive Increase)—— 稳定时缓慢扩窗
- 当网络无丢包时,
CongWin每经过一个 RTT线性增加 1 MSS,缓慢提升发送速率,避免过度拥塞。 - 行为特征:呈现 锯齿状—— 丢包时窗口骤减(乘性减),稳定时窗口缓增(加性增),持续探测网络可用带宽。
2. 乘性减(Multiplicative Decrease)—— 拥塞时快速缩窗
- 场景 1:收到 3 个重复 ACK(轻微拥塞)
- 处理:拥塞窗口(
CongWin)直接减半,之后进入线性增长阶段。 - 逻辑:3 个重复 ACK 说明 某报文段丢失,但后续段已到达,网络仍有传输能力,属于 拥塞警报,因此温和缩窗。
- 处理:拥塞窗口(
- 场景 2:超时事件(严重拥塞)
- 处理:
CongWin重置为1 MSS,进入慢启动(SS)阶段(指数级增长),直到窗口增长到 上次拥塞窗口的一半 后,切换为线性增长。 - 逻辑:超时说明网络拥塞严重,需从极低速率重新探测,避免再次引发拥塞。
- 处理:
总结

吞吐量
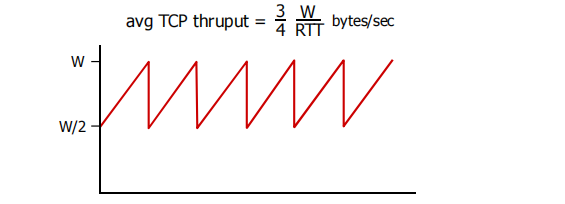
针对长存活期的 TCP 连接,忽略 超时事件后的慢启动阶段。假设在连接持续期间,往返时间(RTT) 和丢包时的拥塞窗口大小(W) 几乎不变。
丢包后,TCP 拥塞窗口会减半,随后再次线性增长,形成 锯齿状 的速率循环 :

公平性
TCP 公平性是指多个 TCP 流在共享网络资源时,能够相对均衡地分配带宽,避免某一或少数流垄断资源的特性。当多个 TCP 连接竞争同一网络链路时,公平性要求每个连接获得的带宽份额与其 需求或 行为相匹配。
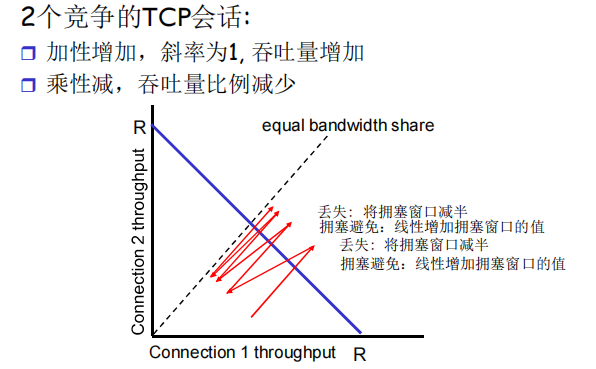
- 当两个连接的总吞吐量小于链路带宽 R 时,触发拥塞避免的 加性增,两个连接的拥塞窗口以相同的线性斜率增长,总吞吐量沿 45度线增长,直到总吞吐量超过 R,引发丢包。
- 丢包后,两个连接执行 乘性减 ,拥塞窗口按比例减半,此时总吞吐量再次小于 R,进入下一轮加性增。
- 每一轮 加性增→丢包→乘性减 的迭代中,两个连接的吞吐量差值会持续缩小。数学上,加性增的线性增长 和 乘性减的比例收缩 组合,具有 偏差修正特性—— 任何偏离 平等带宽共享线 的状态,都会在迭代中被逐步拉回,最终收敛到该线。
小结
UDP 和 TCP 作为因特网运输层两大主力协议,已不完全适配当前环境,运输层功能仍在持续演化。

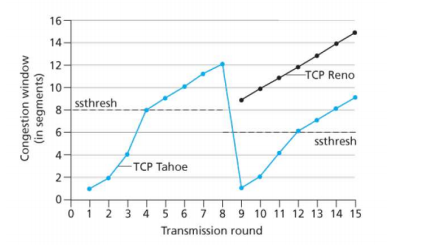
过去十年,TCP 的使用出现诸多变化,除 TCP Tahoe、Reno 等经典版本外,CUBIC、DCTCP、CTCP、BBR 等新版本被研究、实现并大量部署,其中 CUBIC、CTCP 在 Web 服务器的部署广度已超过经典的 TCP Reno,BBR 也在谷歌网络中应用。此外,还存在多种针对无线链路、大 RTT 高带宽路径、数据中心等不同场景设计的 TCP 变种,这些变种虽功能各异,但均采用 TCP 报文段格式,且在网络拥塞时会 公平 竞争。
🦆🦆🦆.