【完整源码+数据集+部署教程】【文件&发票】发票信息提取系统源码&数据集全套:改进yolo11-ContextGuided
背景意义
随着电子商务的迅猛发展,发票作为商业交易的重要凭证,其信息的自动提取与处理变得愈发重要。传统的发票信息提取方法多依赖人工输入,效率低下且易出错,无法满足现代企业对数据处理速度和准确性的高要求。因此,开发一种高效、准确的发票信息提取系统显得尤为必要。近年来,深度学习技术的飞速发展为图像识别和信息提取提供了新的解决方案,其中YOLO(You Only Look Once)系列模型因其实时性和高精度而备受关注。
本研究旨在基于改进的YOLOv11模型,构建一个高效的发票信息提取系统。我们所使用的数据集包含756张发票图像,涵盖了多个重要信息类别,如地址、商品、日期、价格、税务信息等。这些类别不仅是发票信息提取的核心内容,也是后续财务分析和数据挖掘的基础。通过对这些类别的准确识别与提取,企业能够实现自动化的财务管理,提升工作效率,降低人工成本。
在技术实现上,YOLOv11模型通过其创新的网络结构和训练方法,能够在保证高精度的同时,提升信息提取的速度。针对发票图像的特性,我们将对模型进行针对性的改进,以适应不同发票格式和排版的多样性。此外,结合数据增强技术和迁移学习策略,我们期望进一步提升模型的泛化能力,使其在实际应用中能够有效应对各种复杂场景。
综上所述,本研究不仅具有重要的理论意义,推动了深度学习在信息提取领域的应用,也具备广泛的实际应用价值,能够为企业的财务管理提供有力支持,助力数字化转型的进程。
图片效果
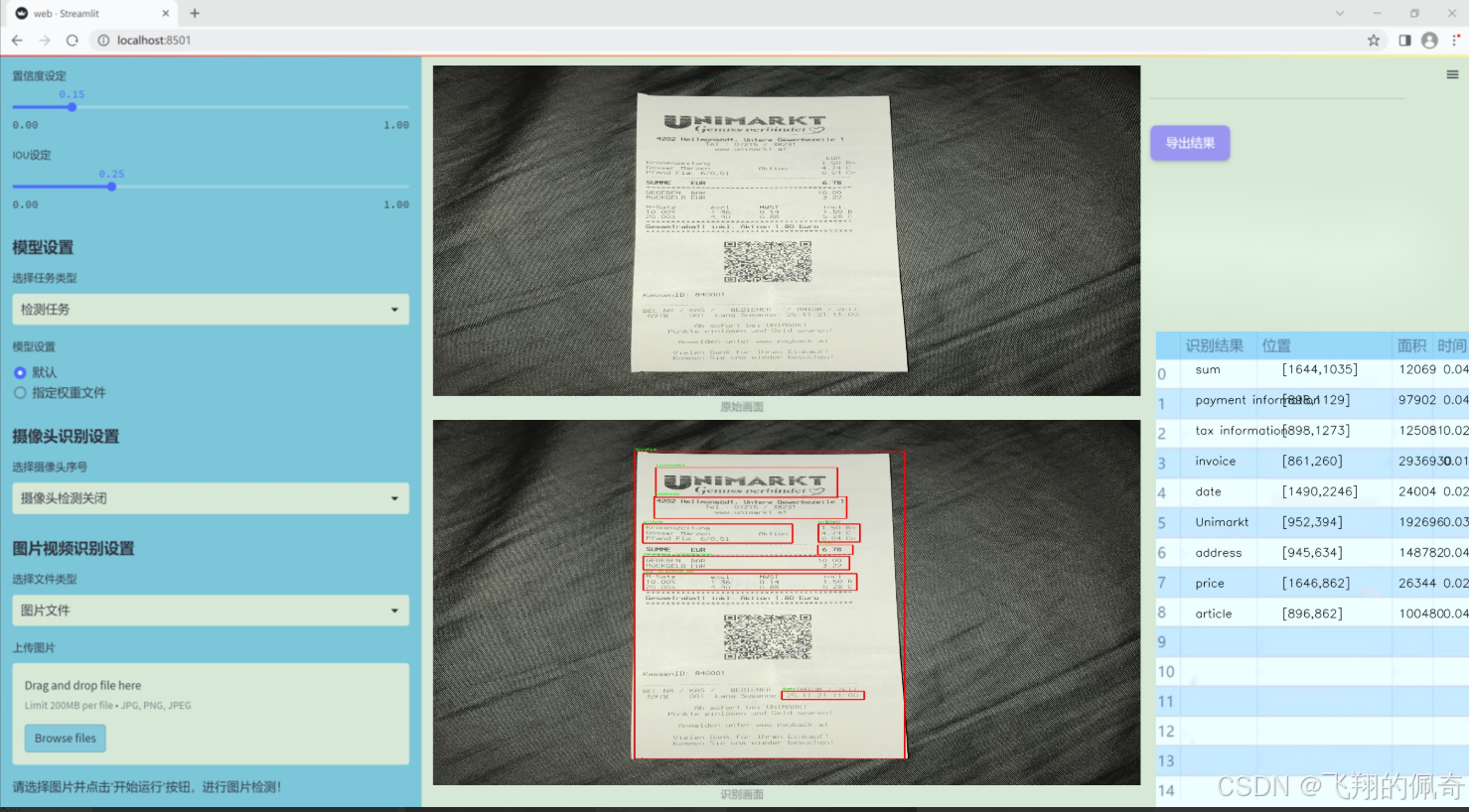
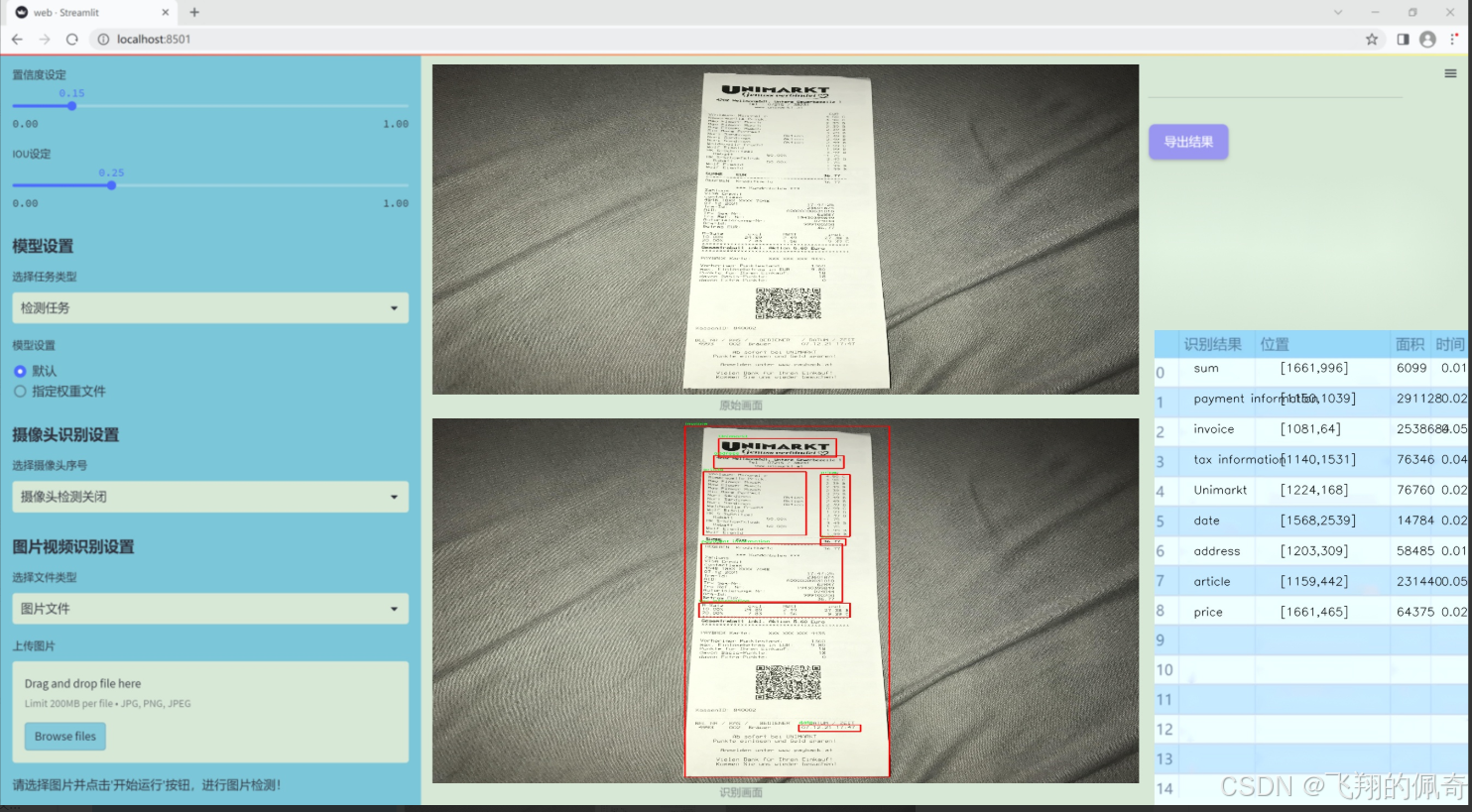
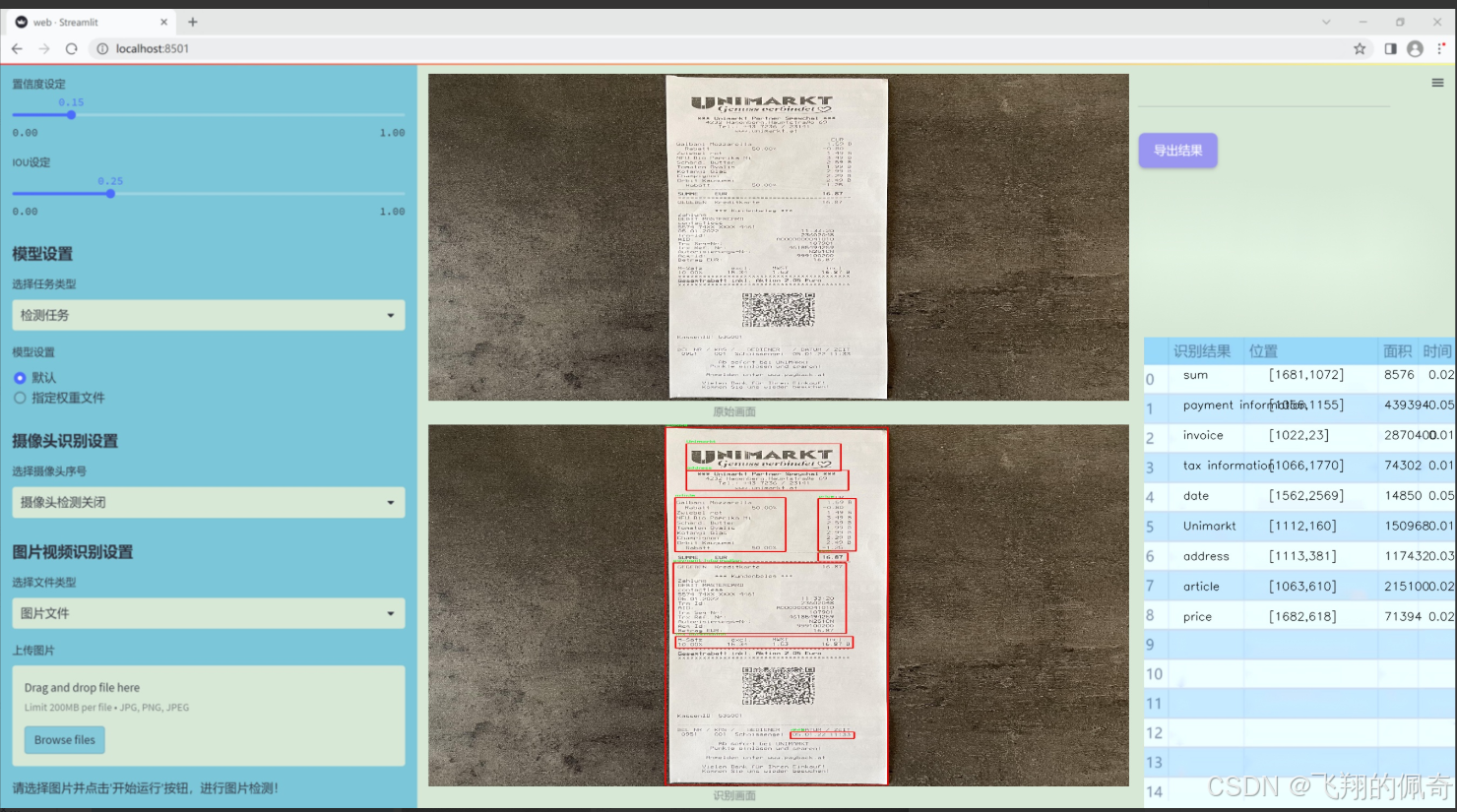
数据集信息
本项目所使用的数据集名为“Invoice Detection”,旨在为改进YOLOv11的发票信息提取系统提供支持。该数据集包含12个类别,涵盖了发票中常见的关键信息,具体类别包括:Billa、Hofer、Spar、Unimarkt、地址、商品、日期、发票、支付信息、价格、总计以及税务信息。这些类别的设计充分考虑了发票的实际应用场景,确保系统能够准确提取并识别各种重要信息。
在数据集的构建过程中,我们采集了多种类型的发票样本,确保数据的多样性和代表性。这些样本来自不同的商家和服务提供商,涵盖了多种格式和布局,以模拟真实世界中可能遇到的各种情况。通过这种方式,我们的目标是提高YOLOv11在处理不同发票时的鲁棒性和准确性,进而提升信息提取的效率。
数据集中的每个类别都经过精心标注,以确保训练过程中模型能够学习到每种信息的特征。例如,商品类别不仅包括商品名称,还涵盖了数量和单价等信息,而支付信息则涉及到支付方式和交易编号等细节。这种细致的标注使得模型在训练时能够更好地理解和区分不同类别之间的关系,从而提高提取的准确性。
此外,为了确保模型的泛化能力,我们还进行了数据增强处理,包括旋转、缩放和颜色调整等。这些技术手段不仅丰富了训练数据的多样性,还有效降低了模型对特定样本的过拟合风险。通过这样的数据集构建和处理策略,我们期望能够显著提升YOLOv11在发票信息提取任务中的表现,为实际应用提供更加高效和可靠的解决方案。





核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
from einops import rearrange
定义一个h_sigmoid激活函数
class h_sigmoid(nn.Module):
def init(self, inplace=True):
super(h_sigmoid, self).init()
self.relu = nn.ReLU6(inplace=inplace) # 使用ReLU6作为基础
def forward(self, x):return self.relu(x + 3) / 6 # 计算h_sigmoid
定义一个h_swish激活函数
class h_swish(nn.Module):
def init(self, inplace=True):
super(h_swish, self).init()
self.sigmoid = h_sigmoid(inplace=inplace) # 使用h_sigmoid作为基础
def forward(self, x):return x * self.sigmoid(x) # 计算h_swish
定义RFAConv模块
class RFAConv(nn.Module):
def init(self, in_channel, out_channel, kernel_size, stride=1):
super().init()
self.kernel_size = kernel_size
# 生成权重的卷积操作self.get_weight = nn.Sequential(nn.AvgPool2d(kernel_size=kernel_size, padding=kernel_size // 2, stride=stride),nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=1, groups=in_channel, bias=False))# 生成特征的卷积操作self.generate_feature = nn.Sequential(nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size=kernel_size, padding=kernel_size // 2, stride=stride, groups=in_channel, bias=False),nn.BatchNorm2d(in_channel * (kernel_size ** 2)),nn.ReLU())# 最终的卷积操作self.conv = nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride=kernel_size)def forward(self, x):b, c = x.shape[0:2] # 获取输入的batch size和通道数weight = self.get_weight(x) # 计算权重h, w = weight.shape[2:] # 获取特征图的高和宽# 对权重进行softmax归一化weighted = weight.view(b, c, self.kernel_size ** 2, h, w).softmax(2)feature = self.generate_feature(x).view(b, c, self.kernel_size ** 2, h, w) # 生成特征# 权重与特征相乘weighted_data = feature * weightedconv_data = rearrange(weighted_data, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size, n2=self.kernel_size) # 重排数据return self.conv(conv_data) # 返回卷积结果
定义SE模块(Squeeze-and-Excitation)
class SE(nn.Module):
def init(self, in_channel, ratio=16):
super(SE, self).init()
self.gap = nn.AdaptiveAvgPool2d((1, 1)) # 全局平均池化
self.fc = nn.Sequential(
nn.Linear(in_channel, ratio, bias=False), # 从c到c/r
nn.ReLU(),
nn.Linear(ratio, in_channel, bias=False), # 从c/r到c
nn.Sigmoid()
)
def forward(self, x):b, c = x.shape[0:2] # 获取输入的batch size和通道数y = self.gap(x).view(b, c) # 进行全局平均池化y = self.fc(y).view(b, c, 1, 1) # 通过全连接层return y # 返回通道注意力
定义RFCBAMConv模块
class RFCBAMConv(nn.Module):
def init(self, in_channel, out_channel, kernel_size=3, stride=1):
super().init()
self.kernel_size = kernel_size
# 生成特征的卷积操作self.generate = nn.Sequential(nn.Conv2d(in_channel, in_channel * (kernel_size ** 2), kernel_size, padding=kernel_size // 2, stride=stride, groups=in_channel, bias=False),nn.BatchNorm2d(in_channel * (kernel_size ** 2)),nn.ReLU())# 获取权重的卷积操作self.get_weight = nn.Sequential(nn.Conv2d(2, 1, kernel_size=3, padding=1, bias=False), nn.Sigmoid())self.se = SE(in_channel) # 初始化SE模块# 最终的卷积操作self.conv = nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride=kernel_size)def forward(self, x):b, c = x.shape[0:2] # 获取输入的batch size和通道数channel_attention = self.se(x) # 计算通道注意力generate_feature = self.generate(x) # 生成特征h, w = generate_feature.shape[2:] # 获取特征图的高和宽generate_feature = generate_feature.view(b, c, self.kernel_size ** 2, h, w) # 重排特征generate_feature = rearrange(generate_feature, 'b c (n1 n2) h w -> b c (h n1) (w n2)', n1=self.kernel_size, n2=self.kernel_size) # 重排数据unfold_feature = generate_feature * channel_attention # 应用通道注意力max_feature, _ = torch.max(generate_feature, dim=1, keepdim=True) # 最大特征mean_feature = torch.mean(generate_feature, dim=1, keepdim=True) # 平均特征# 计算接收场注意力receptive_field_attention = self.get_weight(torch.cat((max_feature, mean_feature), dim=1))conv_data = unfold_feature * receptive_field_attention # 应用接收场注意力return self.conv(conv_data) # 返回卷积结果
代码分析:
激活函数:
h_sigmoid 和 h_swish 是自定义的激活函数,分别实现了h-sigmoid和h-swish的功能,主要用于网络中的非线性变换。
RFAConv:
该模块实现了一种基于注意力机制的卷积操作,首先通过平均池化和卷积生成权重,然后生成特征,最后将特征与权重相乘,经过重排后进行卷积。
SE模块:
Squeeze-and-Excitation模块通过全局平均池化和全连接层生成通道注意力,用于增强网络对重要特征的关注。
RFCBAMConv:
该模块结合了特征生成、通道注意力和接收场注意力,通过多个卷积操作和特征重排,增强了特征的表达能力。
这些模块的设计旨在提高卷积神经网络的性能,特别是在处理复杂图像任务时。
这个程序文件 RFAConv.py 定义了一些用于深度学习卷积操作的模块,主要包括 RFAConv、RFCBAMConv 和 RFCAConv。这些模块利用了深度学习中的一些新技术,比如注意力机制和非线性激活函数,来增强卷积神经网络的性能。
首先,文件中导入了必要的库,包括 PyTorch 和 einops。PyTorch 是一个流行的深度学习框架,而 einops 是一个用于重排张量的库。接着,定义了两个自定义的激活函数:h_sigmoid 和 h_swish。h_sigmoid 是一种改进的 sigmoid 函数,h_swish 则是基于 h_sigmoid 的一种新型激活函数,它结合了 ReLU 和 sigmoid 的特性。
接下来是 RFAConv 类的定义。这个类实现了一种新的卷积操作,称为 RFA(Receptive Field Attention)卷积。构造函数中,get_weight 用于生成权重,generate_feature 用于生成特征。forward 方法中,输入数据经过处理后生成加权特征,并通过重排操作将其格式化为适合卷积的形状,最后通过 self.conv 进行卷积操作。
然后是 SE 类的定义,它实现了 Squeeze-and-Excitation(SE)模块。该模块通过全局平均池化和全连接层来生成通道注意力,增强特征表示。forward 方法中,输入数据经过池化和全连接层处理后生成通道注意力。
接着是 RFCBAMConv 类的定义,它结合了 RFA 和 SE 模块。构造函数中,generate 用于生成特征,get_weight 用于生成注意力权重。forward 方法中,首先计算通道注意力,然后生成特征并进行重排,最后通过注意力机制和卷积操作生成输出。
最后是 RFCAConv 类的定义,它结合了 RFA 和通道注意力机制。构造函数中,generate 用于生成特征,pool_h 和 pool_w 用于对特征进行池化。forward 方法中,生成特征后分别进行水平和垂直池化,生成通道注意力,并最终通过卷积操作生成输出。
总体来说,这个文件实现了一些复杂的卷积操作和注意力机制,旨在提高卷积神经网络在图像处理任务中的表现。通过这些模块,用户可以构建更为高效和强大的深度学习模型。
10.2 rmt.py
以下是经过简化并添加详细中文注释的核心代码部分:
import torch
import torch.nn as nn
import torch.nn.functional as F
class DWConv2d(nn.Module):
“”" 深度可分离卷积层 “”"
def init(self, dim, kernel_size, stride, padding):
super().init()
# 使用深度可分离卷积,groups=dim表示每个输入通道独立卷积
self.conv = nn.Conv2d(dim, dim, kernel_size, stride, padding, groups=dim)
def forward(self, x: torch.Tensor):'''x: 输入张量,形状为 (b, h, w, c)'''x = x.permute(0, 3, 1, 2) # 转换为 (b, c, h, w)x = self.conv(x) # 进行卷积操作x = x.permute(0, 2, 3, 1) # 转换回 (b, h, w, c)return x
class MaSA(nn.Module):
“”" 多头自注意力机制 “”"
def init(self, embed_dim, num_heads, value_factor=1):
super().init()
self.factor = value_factor
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = self.embed_dim * self.factor // num_heads
self.key_dim = self.embed_dim // num_heads
self.scaling = self.key_dim ** -0.5
# 线性变换层self.q_proj = nn.Linear(embed_dim, embed_dim, bias=True)self.k_proj = nn.Linear(embed_dim, embed_dim, bias=True)self.v_proj = nn.Linear(embed_dim, embed_dim * self.factor, bias=True)self.out_proj = nn.Linear(embed_dim * self.factor, embed_dim, bias=True)def forward(self, x: torch.Tensor, rel_pos):'''x: 输入张量,形状为 (b, h, w, c)rel_pos: 位置关系的掩码'''bsz, h, w, _ = x.size()q = self.q_proj(x) # 计算查询k = self.k_proj(x) # 计算键v = self.v_proj(x) # 计算值# 计算注意力权重qk_mat = (q @ k.transpose(-1, -2)) * self.scaling + rel_pos # 加入位置关系qk_mat = torch.softmax(qk_mat, dim=-1) # 归一化# 计算输出output = (qk_mat @ v) # 注意力加权output = self.out_proj(output) # 最终线性变换return output
class FeedForwardNetwork(nn.Module):
“”" 前馈神经网络 “”"
def init(self, embed_dim, ffn_dim, activation_fn=F.gelu, dropout=0.0):
super().init()
self.fc1 = nn.Linear(embed_dim, ffn_dim) # 第一层线性变换
self.fc2 = nn.Linear(ffn_dim, embed_dim) # 第二层线性变换
self.dropout = nn.Dropout(dropout) # Dropout层
self.activation_fn = activation_fn # 激活函数
def forward(self, x: torch.Tensor):'''x: 输入张量,形状为 (b, h, w, c)'''x = self.fc1(x) # 第一层x = self.activation_fn(x) # 激活x = self.dropout(x) # Dropoutx = self.fc2(x) # 第二层return x
class VisRetNet(nn.Module):
“”" 可视化恢复网络 “”"
def init(self, in_chans=3, num_classes=1000, embed_dims=[96, 192, 384, 768], depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24]):
super().init()
self.patch_embed = PatchEmbed(in_chans=in_chans, embed_dim=embed_dims[0]) # 图像分块嵌入
self.layers = nn.ModuleList() # 存储各层
# 构建网络层for i_layer in range(len(depths)):layer = BasicLayer(embed_dim=embed_dims[i_layer], depth=depths[i_layer], num_heads=num_heads[i_layer])self.layers.append(layer)def forward(self, x):x = self.patch_embed(x) # 图像嵌入for layer in self.layers:x = layer(x) # 逐层传递return x
这里省略了 PatchEmbed 和 BasicLayer 的实现,假设它们已定义
模型实例化示例
if name == ‘main’:
model = VisRetNet()
inputs = torch.randn((1, 3, 640, 640)) # 随机输入
res = model(inputs) # 前向传播
print(res.size()) # 输出结果的形状
代码说明:
DWConv2d: 实现了深度可分离卷积,适用于图像特征提取。
MaSA: 实现了多头自注意力机制,能够捕捉输入特征之间的关系。
FeedForwardNetwork: 实现了前馈神经网络,包含两层线性变换和激活函数。
VisRetNet: 主要网络结构,包含图像嵌入和多个基本层的堆叠。
这个程序文件 rmt.py 实现了一个视觉变换器(Vision Transformer)模型,名为 VisRetNet,并提供了不同规模的模型构造函数(如 RMT_T, RMT_S, RMT_B, RMT_L)。该模型主要用于图像处理任务,尤其是在计算机视觉领域。
文件首先导入了必要的库,包括 PyTorch 和一些特定的模块。接下来定义了一些基础组件,如 DWConv2d(深度可分离卷积)、RelPos2d(二维相对位置编码)、MaSAd 和 MaSA(不同类型的注意力机制),以及 FeedForwardNetwork(前馈神经网络)等。这些组件构成了模型的基础。
DWConv2d 类实现了深度可分离卷积,它在输入的通道维度上进行卷积操作,适用于处理图像数据。RelPos2d 类用于生成相对位置编码,支持在二维空间中计算位置关系,帮助模型理解输入数据的空间结构。
MaSAd 和 MaSA 类实现了多头自注意力机制,分别支持不同的注意力计算方式。它们通过查询(Q)、键(K)和值(V)的线性变换来计算注意力权重,并结合相对位置编码来增强模型的上下文理解能力。
FeedForwardNetwork 类实现了一个简单的前馈网络,包含两个线性层和激活函数,常用于 transformer 模型中的每个层。
RetBlock 类是一个包含注意力机制和前馈网络的基本模块,它通过残差连接和层归一化来增强模型的稳定性。PatchMerging 类则用于将输入特征图进行下采样,合并成更小的特征图。
BasicLayer 类构建了一个基本的 transformer 层,包含多个 RetBlock 组成的堆叠,并在最后可选择性地进行下采样。
LayerNorm2d 和 PatchEmbed 类分别实现了二维层归一化和图像到补丁的嵌入,将输入图像转换为适合 transformer 处理的格式。
VisRetNet 类是整个模型的核心,负责将所有层和模块组合在一起。它支持不同的输入通道、嵌入维度、层数、头数等超参数,并通过 forward 方法实现前向传播。
最后,文件提供了四个函数(RMT_T, RMT_S, RMT_B, RMT_L)用于创建不同规模的 VisRetNet 模型。这些函数根据预设的参数配置模型的各个部分。
在 main 部分,代码示例展示了如何创建一个小型模型并进行一次前向传播,输出每个特征图的尺寸。
总体而言,这个文件实现了一个灵活且可扩展的视觉变换器模型,适用于各种计算机视觉任务。
10.3 VanillaNet.py
以下是经过简化并添加详细中文注释的核心代码部分:
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.layers import weight_init
定义激活函数类
class Activation(nn.ReLU):
def init(self, dim, act_num=3, deploy=False):
super(Activation, self).init()
self.deploy = deploy # 是否处于部署模式
# 权重参数初始化
self.weight = torch.nn.Parameter(torch.randn(dim, 1, act_num * 2 + 1, act_num * 2 + 1))
self.bias = None
self.bn = nn.BatchNorm2d(dim, eps=1e-6) # 批归一化
self.dim = dim
self.act_num = act_num
weight_init.trunc_normal_(self.weight, std=.02) # 权重初始化
def forward(self, x):# 前向传播if self.deploy:# 在部署模式下,使用卷积层处理输入return torch.nn.functional.conv2d(super(Activation, self).forward(x), self.weight, self.bias, padding=(self.act_num * 2 + 1) // 2, groups=self.dim)else:# 否则,先进行批归一化再卷积return self.bn(torch.nn.functional.conv2d(super(Activation, self).forward(x),self.weight, padding=self.act_num, groups=self.dim))def switch_to_deploy(self):# 切换到部署模式,融合批归一化if not self.deploy:kernel, bias = self._fuse_bn_tensor(self.weight, self.bn)self.weight.data = kernelself.bias = torch.nn.Parameter(torch.zeros(self.dim))self.bias.data = biasself.__delattr__('bn') # 删除bn属性self.deploy = Truedef _fuse_bn_tensor(self, weight, bn):# 融合权重和批归一化的参数kernel = weightrunning_mean = bn.running_meanrunning_var = bn.running_vargamma = bn.weightbeta = bn.biaseps = bn.epsstd = (running_var + eps).sqrt()t = (gamma / std).reshape(-1, 1, 1, 1)return kernel * t, beta + (0 - running_mean) * gamma / std
定义基本块
class Block(nn.Module):
def init(self, dim, dim_out, act_num=3, stride=2, deploy=False):
super().init()
self.deploy = deploy
# 根据是否部署选择不同的卷积结构
if self.deploy:
self.conv = nn.Conv2d(dim, dim_out, kernel_size=1)
else:
self.conv1 = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=1),
nn.BatchNorm2d(dim, eps=1e-6),
)
self.conv2 = nn.Sequential(
nn.Conv2d(dim, dim_out, kernel_size=1),
nn.BatchNorm2d(dim_out, eps=1e-6)
)
# 池化层
self.pool = nn.MaxPool2d(stride) if stride != 1 else nn.Identity()
self.act = Activation(dim_out, act_num) # 激活函数
def forward(self, x):# 前向传播if self.deploy:x = self.conv(x)else:x = self.conv1(x)x = F.leaky_relu(x, negative_slope=1) # 使用Leaky ReLU激活x = self.conv2(x)x = self.pool(x) # 池化x = self.act(x) # 激活return x
定义VanillaNet模型
class VanillaNet(nn.Module):
def init(self, in_chans=3, num_classes=1000, dims=[96, 192, 384, 768],
drop_rate=0, act_num=3, strides=[2, 2, 2, 1], deploy=False):
super().init()
self.deploy = deploy
# 定义网络的stem部分
if self.deploy:
self.stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
Activation(dims[0], act_num)
)
else:
self.stem1 = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
nn.BatchNorm2d(dims[0], eps=1e-6),
)
self.stem2 = nn.Sequential(
nn.Conv2d(dims[0], dims[0], kernel_size=1, stride=1),
nn.BatchNorm2d(dims[0], eps=1e-6),
Activation(dims[0], act_num)
)
self.stages = nn.ModuleList()for i in range(len(strides)):stage = Block(dim=dims[i], dim_out=dims[i + 1], act_num=act_num, stride=strides[i], deploy=deploy)self.stages.append(stage) # 添加每个Block到模型中def forward(self, x):# 前向传播if self.deploy:x = self.stem(x)else:x = self.stem1(x)x = F.leaky_relu(x, negative_slope=1)x = self.stem2(x)for stage in self.stages:x = stage(x) # 通过每个Block进行前向传播return x
示例用法
if name == ‘main’:
inputs = torch.randn((1, 3, 640, 640)) # 输入张量
model = VanillaNet() # 创建模型实例
pred = model(inputs) # 进行前向传播
print(pred.size()) # 输出预测结果的尺寸
代码说明:
Activation类:自定义的激活函数类,包含了卷积和批归一化的融合操作。
Block类:网络的基本构建块,包含卷积、池化和激活操作。
VanillaNet类:主网络结构,包含stem部分和多个Block的组合。
前向传播:每个类都有forward方法,定义了数据如何通过网络流动。
示例用法:在主程序中创建一个输入张量并通过模型进行前向传播,输出结果的尺寸。
这个程序文件 VanillaNet.py 实现了一个名为 VanillaNet 的深度学习模型,主要用于图像处理任务。代码中使用了 PyTorch 框架,并且包含了一些自定义的层和模块,以增强模型的功能和灵活性。
首先,文件开头包含版权声明和许可证信息,表明该程序是开源的,并且可以在 MIT 许可证下进行修改和分发。
接下来,程序导入了必要的库,包括 PyTorch 的核心模块和一些辅助功能模块。timm.layers 中的 weight_init 和 DropPath 用于权重初始化和路径丢弃操作。
文件中定义了多个类和函数。activation 类是一个自定义的激活函数层,继承自 ReLU。它的构造函数中初始化了权重和偏置,并使用批量归一化。前向传播方法根据是否处于部署模式(deploy)来选择不同的计算方式。
Block 类表示网络中的一个基本构建块,包含两个卷积层和一个激活层。根据是否处于部署模式,Block 的构造函数会选择不同的实现方式。它还包含一个池化层,能够根据步幅的不同选择最大池化或自适应池化。前向传播方法在执行卷积和激活操作后,进行池化处理。
VanillaNet 类是整个网络的主体,构造函数中定义了网络的输入通道、类别数、各层的维度、丢弃率等参数。它根据给定的步幅和维度创建多个 Block 实例,并将它们添加到一个模块列表中。forward 方法实现了网络的前向传播,返回不同尺度的特征图。
此外,文件中还定义了一些辅助函数,例如 update_weight 用于更新模型的权重,vanillanet_5 到 vanillanet_13_x1_5_ada_pool 函数用于创建不同配置的 VanillaNet 模型,并支持加载预训练权重。
最后,在 main 块中,创建了一个输入张量并实例化了 vanillanet_10 模型,随后进行前向传播并打印输出特征图的尺寸。
总体而言,这个程序文件实现了一个灵活且可扩展的深度学习模型,适用于各种图像处理任务,并提供了多种模型配置以满足不同需求。
10.4 CSwomTramsformer.py
以下是提取后的核心代码部分,并添加了详细的中文注释:
import torch
import torch.nn as nn
import numpy as np
class Mlp(nn.Module):
“”“多层感知机(MLP)模块”“”
def init(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().init()
out_features = out_features or in_features # 输出特征数
hidden_features = hidden_features or in_features # 隐藏层特征数
self.fc1 = nn.Linear(in_features, hidden_features) # 第一层线性变换
self.act = act_layer() # 激活函数
self.fc2 = nn.Linear(hidden_features, out_features) # 第二层线性变换
self.drop = nn.Dropout(drop) # Dropout层
def forward(self, x):"""前向传播"""x = self.fc1(x) # 线性变换x = self.act(x) # 激活x = self.drop(x) # Dropoutx = self.fc2(x) # 线性变换x = self.drop(x) # Dropoutreturn x
class CSWinBlock(nn.Module):
“”“CSWin Transformer的基本块”“”
def init(self, dim, num_heads, mlp_ratio=4., drop=0., attn_drop=0., norm_layer=nn.LayerNorm):
super().init()
self.dim = dim # 输入特征维度
self.num_heads = num_heads # 注意力头数
self.mlp_ratio = mlp_ratio # MLP的扩展比例
self.qkv = nn.Linear(dim, dim * 3) # 线性变换生成Q、K、V
self.norm1 = norm_layer(dim) # 第一层归一化
self.attn = LePEAttention(dim, num_heads=num_heads, attn_drop=attn_drop) # 注意力模块
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), out_features=dim) # MLP模块
self.norm2 = norm_layer(dim) # 第二层归一化
def forward(self, x):"""前向传播"""x = self.norm1(x) # 归一化qkv = self.qkv(x).reshape(x.shape[0], -1, 3, self.dim).permute(2, 0, 1, 3) # 生成Q、K、Vx = self.attn(qkv) # 注意力计算x = x + self.mlp(self.norm2(x)) # MLP计算return x
class CSWinTransformer(nn.Module):
“”“CSWin Transformer模型”“”
def init(self, img_size=640, in_chans=3, num_classes=1000, embed_dim=96, depth=[2,2,6,2], num_heads=12):
super().init()
self.num_classes = num_classes # 类别数
self.embed_dim = embed_dim # 嵌入维度
self.stage1_conv_embed = nn.Sequential(
nn.Conv2d(in_chans, embed_dim, 7, 4, 2), # 卷积层
nn.LayerNorm(embed_dim) # 归一化层
)
self.stage1 = nn.ModuleList([
CSWinBlock(dim=embed_dim, num_heads=num_heads) for _ in range(depth[0]) # 第一阶段的多个CSWinBlock
])
# 后续阶段的定义略去…
def forward(self, x):"""前向传播"""x = self.stage1_conv_embed(x) # 输入经过卷积和归一化for blk in self.stage1:x = blk(x) # 通过每个CSWinBlockreturn x
定义模型的实例化函数
def CSWin_tiny(pretrained=False, **kwargs):
model = CSWinTransformer(embed_dim=64, depth=[1,2,21,1], num_heads=2, **kwargs)
return model
主程序入口
if name == ‘main’:
inputs = torch.randn((1, 3, 640, 640)) # 输入数据
model = CSWin_tiny() # 创建模型实例
res = model(inputs) # 前向传播
print(res.size()) # 输出结果的尺寸
代码说明:
Mlp类:实现了一个多层感知机,包含两层线性变换和激活函数,使用Dropout来防止过拟合。
CSWinBlock类:实现了CSWin Transformer的基本块,包含注意力机制和MLP模块。
CSWinTransformer类:定义了整个CSWin Transformer模型的结构,包括输入层和多个CSWinBlock。
CSWin_tiny函数:用于创建一个小型的CSWin Transformer模型实例。
主程序:用于测试模型的前向传播,输出结果的尺寸。
这个程序文件实现了一个名为CSWin Transformer的视觉变换器模型,主要用于图像分类等计算机视觉任务。文件中包含了多个类和函数,下面是对代码的详细说明。
首先,文件引入了必要的库,包括PyTorch、timm库以及一些功能性模块。接着,定义了几个全局变量,表示不同规模的CSWin Transformer模型。
接下来,定义了一个名为Mlp的类,它是一个多层感知机(MLP),包含两个线性层和一个激活函数(默认为GELU)。这个类的主要功能是对输入进行前向传播,通过两个线性层和激活函数的组合来实现特征变换。
然后,定义了LePEAttention类,它实现了一种特殊的注意力机制,称为局部增强位置编码(LePE)。该类的构造函数接收多个参数,包括输入维度、分辨率、头数等。forward方法实现了注意力计算,包括将输入分割成窗口、计算注意力权重以及将结果重新组合成图像。
接着,定义了CSWinBlock类,它是CSWin Transformer的基本构建块。每个块包含一个注意力层和一个MLP层,使用层归一化进行规范化。forward方法实现了块的前向传播,首先对输入进行归一化,然后计算注意力,最后通过MLP进行特征变换。
img2windows和windows2img是两个辅助函数,用于将图像从常规格式转换为窗口格式,反之亦然。这对于注意力机制的实现至关重要,因为它允许模型在局部窗口内进行计算。
Merge_Block类用于在不同阶段之间合并特征,使用卷积层来减少特征图的分辨率,并进行层归一化。
CSWinTransformer类是整个模型的核心,包含多个阶段,每个阶段由多个CSWinBlock组成。构造函数中定义了输入层、多个阶段和合并层,并根据给定的参数初始化模型的权重。forward_features方法实现了模型的前向传播,提取特征并在不同阶段之间传递。
此外,文件中还定义了一些辅助函数,如_conv_filter和update_weight,用于处理模型权重的加载和转换。
最后,文件提供了四个函数(CSWin_tiny、CSWin_small、CSWin_base、CSWin_large),用于创建不同规模的CSWin Transformer模型,并可选择加载预训练权重。在__main__部分,创建了不同规模的模型实例,并对随机输入进行前向传播,输出每个模型的特征图大小。
整体而言,这个程序文件实现了一个复杂的视觉变换器模型,结合了局部增强位置编码和多层感知机,适用于各种计算机视觉任务。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式