clickhouse学习笔记(一)基础概念与架构
目录
- 简介
- 技术关键词
- OLAP
- MPP
- 列式存储
- Clickhouse架构
- 系统架构
- 查询处理层
- 存储层
- 集成层
- 核心特性
- 多主架构
- 列式存储
- 向量化执行引擎
- 多样化表引擎
- 结语
- 参考文献
简介
Clickhouse是Yandex公司在2009年开始开发,2016年开源的一款用于OLAP(Online Analytical Processing,联机分析处理)的基于MPP(Massively Parallel Processing,大规模并行处理)架构的列式存储数据库系统。其主要适用领域为商业智能领域(俗称BI领域),其次在广告流量、Web/APP流量、电信、电子商务等领域中有广泛的应用。
技术关键词
OLAP、MPP、列式存储
OLAP
联机分析处理主要关注在对大规模数据进行多维度复杂查询分析。因此,系统更加注重读性能,不适用于频繁写入操作的场景。相关的数据库有greenplum,Doris
MPP
大规模并行处理是一种分布式数据处理技术,多个节点并行处理数据以提升数据的处理性能。与其他的分布式架构普遍采用的主从架构不同的是,MPP采用的是非共享架构,每个节点都是独立节点,通过专用网络进行连接并提供服务。这种架构具有避免单点故障、易于横向扩展的优点。
列式存储
列式存储是按列组织数据和保存,与传统的按行存储数据不同,列式存储是将每一列的数据按顺序存储在一起,而不是将一行数据存储在一起。这样带来的好处是:
数据压缩:同一列的数据类型一样,可以采用更高效数据压缩算法
快速查询:只需要查询对应列的数据,减少查询的数据量
坏处:
删除困难:删除一行数据需要查询所有列的数据文件,对对应数据进行删除
写入效率低:一行数据需要拆分成多个列数据进行存储,执行的调用次数比行式存储要多
Clickhouse架构
官方文档有非常详细的介绍,这里仅做一些个人归纳理解
https://clickhouse.com/docs/zh/academic_overview#page-9-0
系统架构
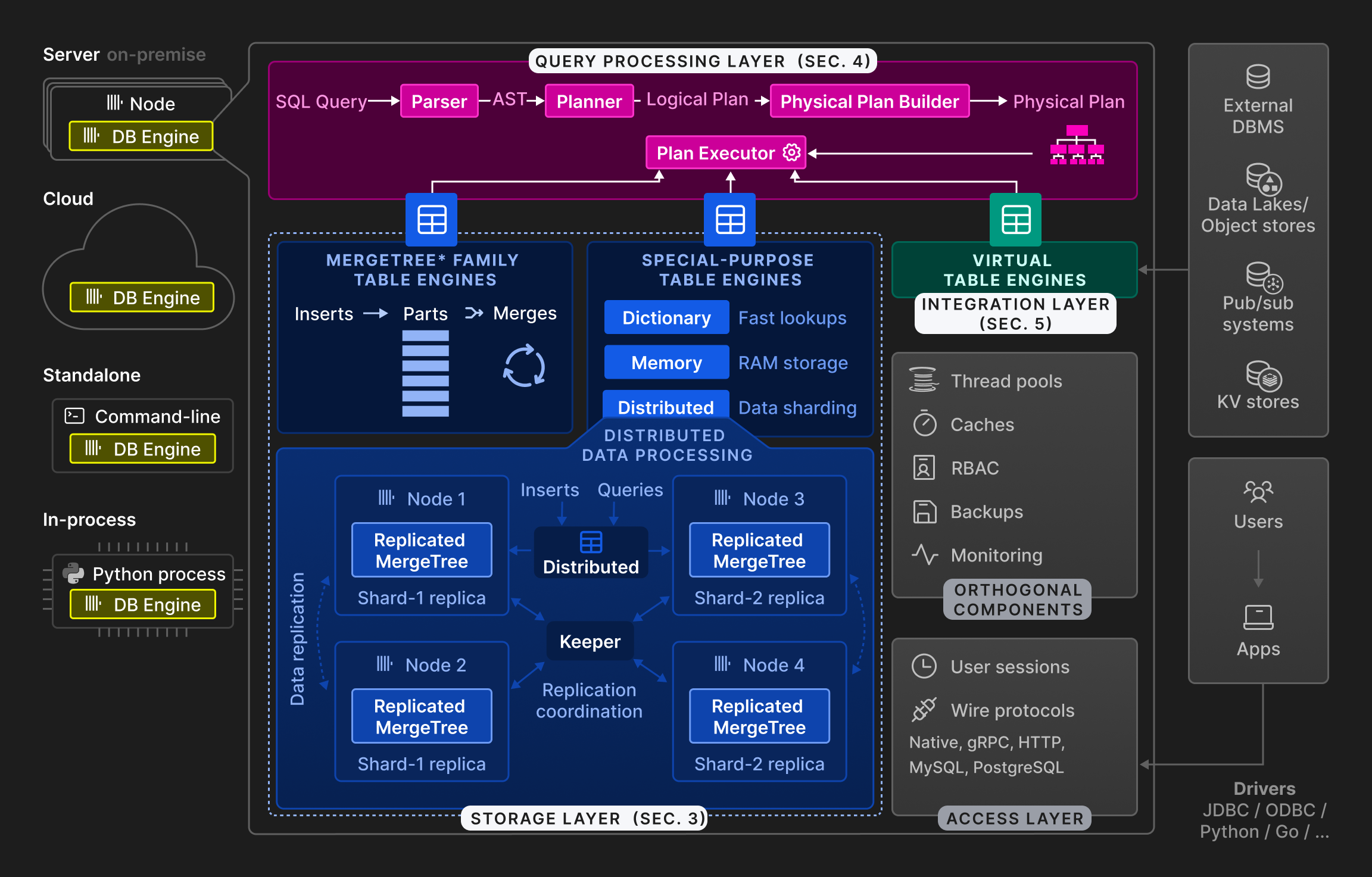
如图所示,Clickhouse引擎分为三层:查询处理层(Query Processing Layer)、存储层(Storage Layer)和集成层(Intergation Layer)。此外,还有访问层(Access Layer)用于用户会话访问和与其他应用程序的通信,以及正交组件(Orthogonal Components)用于系统辅助工作。(详细的描述可以参考官方文档)
查询处理层
查询处理层按照传统的范式,解析输入查询,生成对应的AST树并构建执行计划进行查询。查询的语言支持标准SQL(大小写敏感),易于使用。
存储层
存储层由多种表引擎组成。表引擎可以分为以下三类:
MergeTree系列表引擎:Clickhouse用于主要持久化的表引擎。该系列表引擎是基于 LSM 树的理念,表被拆分成水平有序的parts,并由后台进程持续合并
特殊用途的表引擎:这些表引擎是用于加速或分布查询执行的,如字典、缓存等
虚拟表引擎:用于与外部系统(如关系数据库(例如 PostgreSQL、MySQL)、发布/订阅系统(例如 Kafka、RabbitMQ )或键值存储(例如 Redis))进行双向数据交换
集成层
集成层用于集成外部数据源,通过连接外部数据源,查询外部数据进行数据补充。如果仅用外部数据源的话,该层就类似于一个中间层,可以查询外部数据。如果使用了数据绑定的话,可以将外部数据源的数据同步到本地进行持久化。
核心特性
多主架构
Clickhouse采用了Multi-Master的多主架构。每个节点都是Master,节点间地位对等,不需要通信。客户端访问任意节点都能得到同样的结果。在架构上,天然避免了单点故障的问题和支持灵活的横向伸缩,非常适合多数据中心,异地多活的场景。集群不同节点的数据一致性上,Clickhouse需要使用ClickHouse Keeper和分布式表设置进行不同数据同步。简单描述,ClickHouse Keeper用于提供分布式协调服务,在任意节点上创建库和表时,节点会通过Keeper获取集群中其他节点信息进行副本和数据的同步。
列式存储
列式存储是将数据按列进行保存。这样做的好处在于能有效减少查询时所需要扫描的数据量。假设一个表有50个字段,100行数据,一个查询要求获取前5个字段的数据。按行存储是将这100行的数据全部扫描出来,加载到内存中,取出每行前5个字段。按列存储是直接取出前5个字段的数据。这样按列存储需要扫描的数据量明显小于按行存储,因此查询性能较高。在Clickhouse中,列数据的存储是有序(按照Primary key进行排序)分区(根据Primary key的数据)
另外,同一列的数据类型是一样的,重复项的可能性也更高。因此可以针对相同类型的数据采用效率更高的数据压缩算法,数据的相似性也会使压缩率更高。Clickhouse默认使用LZ4压缩算法。
向量化执行引擎
向量化执行是使用了CPU的SIMD指令(Single Instruction Multiple Data),即单条指令操作多条数据。个人理解,列式存储为向量化执行提供了前提条件。在执行统计操作时,由于采用了列式存储,输入是可以同类多行可以直接运算的数据,并且可以并发计算。如果是按行存储,需要从行数据进行提取再进行运算,并且由于行数据有冗余的数据,导致有效加载的数据量不及按列存储,并发度没那么高,因此向量化执行的收益不大。
多样化表引擎
Clickhouse将存储层进行了抽象,把存储引擎作为一层独立的接口,支持各种各样的表引擎。用户可以根据实际的场景需要选择对应的表引擎。
结语
本文对Clickhouse使用的技术和系统架构进行了一些总结归纳。列式存储 + 向量化执行 + MergeTree 引擎的组合为Clickhouse提供强劲的性能,非常适合实时海量数据分析场景,是目前最佳的OLAP的数据库解决方案之一。
参考文献
1 Robert Schulze, Tom Schreiber, Ilya Yatsishin, Ryadh Dahimene, and Alexey Milovidov. 2024. ClickHouse - Lightning Fast Analytics for Everyone. https://www.vldb.org/pvldb/vol17/p3731-schulze.pdf
2 朱凯.《ClickHouse原理解析与应用实践》