「日拱一码」126 机器学习路线
目录
1. 基础准备
2. 数据处理与可视化
3. 机器学习基础算法
a. 监督学习
b. 无监督学习
4. 模型评估与优化
5. 特征工程
6. 集成学习
7. 深度学习入门
8. 进阶方向
学习路线建议
1. 基础准备
- 数学基础:线性代数、概率论、微积分
- 编程基础:Python + 核心库
## 1. 基础准备
import numpy as np
import pandas as pd# 创建数组和DataFrame
arr = np.array([[1, 2], [3, 4]])
df = pd.DataFrame({'A': [1, 2], 'B': ['X', 'Y']})
print("NumPy数组:\n", arr)
# [[1 2]
# [3 4]]
print("\nPandas DataFrame:\n", df)
# A B
# 0 1 X
# 1 2 Y2. 数据处理与可视化
- 工具:Pandas(数据处理)、Matplotlib/Seaborn(可视化)
## 2. 数据处理与可视化
import seaborn as sns
import matplotlib.pyplot as plt# 加载数据
titanic = sns.load_dataset('titanic')# 数据清洗
titanic_clean = titanic.dropna(subset=['age']).reset_index(drop=True)# 可视化
plt.figure(figsize=(10, 6))
sns.histplot(data=titanic_clean, x='age', hue='survived', kde=True)
plt.title('Age Distribution by Survival')
plt.show()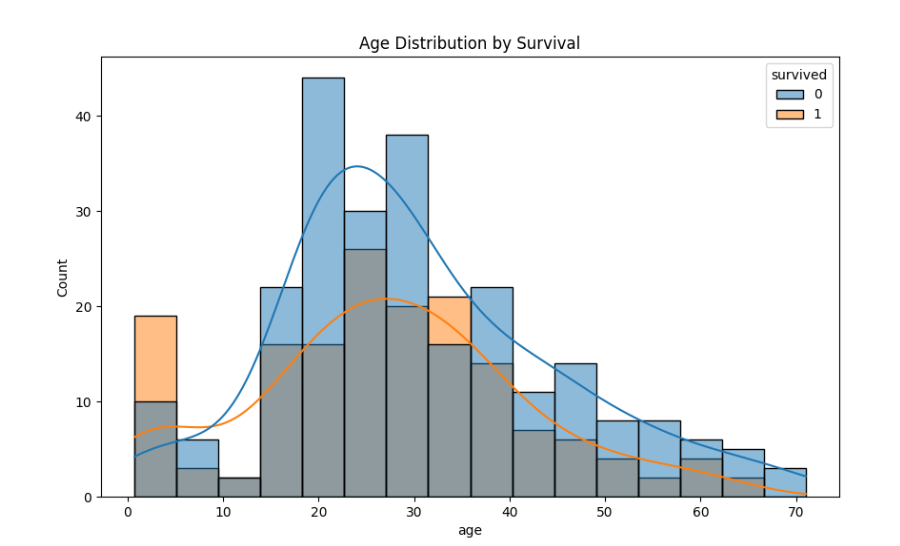
3. 机器学习基础算法
a. 监督学习
- 线性回归
## 3. 机器学习基础算法
# 监督学习——线性回归
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_diabetes# 加载数据
data = load_diabetes()
X, y = data.data[:, :2], data.target # 仅使用前两个特征# 训练模型
model = LinearRegression()
model.fit(X, y)# 预测
print(f"预测: {model.predict([[3.5, 15]])[0]:.2f}") # 1467.09
print(f"系数: {model.coef_}, 截距: {model.intercept_:.2f}")
# 系数: [301.16135996 17.3924542 ], 截距: 152.13- 分类(KNN)
# 分类(KNN)
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split# 加载数据
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3)# 训练模型
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)# 评估
print(f"测试集准确率: {knn.score(X_test, y_test):.2f}") # 0.96b. 无监督学习
- K-Means聚类
## 无监督学习——K-Means聚类
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt# 生成数据
X, _ = make_blobs(n_samples=300, centers=3, random_state=42)# 聚类
kmeans = KMeans(n_clusters=3)
kmeans.fit(X)# 可视化
plt.scatter(X[:, 0], X[:, 1], c=kmeans.labels_, cmap='viridis')
plt.scatter(kmeans.cluster_centers_[:,0], kmeans.cluster_centers_[:,1],marker='X', s=200, c='red')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.title('K-Means聚类结果')
plt.show()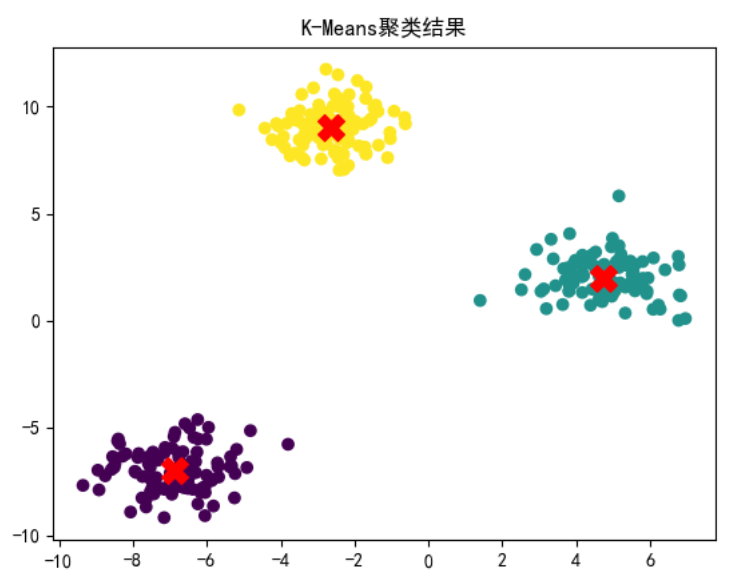
4. 模型评估与优化
- 交叉验证与网格搜索
## 4. 模型评估与优化
# 交叉验证与网格搜索
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV, cross_val_score
from sklearn.datasets import load_iris# 使用鸢尾花数据
X, y = load_iris(return_X_y=True)# 交叉验证
svc = SVC()
scores = cross_val_score(svc, X, y, cv=5)
print(f"交叉验证准确率: {scores.mean():.2f}±{scores.std():.2f}") # 0.97±0.02# 网格搜索
params = {'C': [0.1, 1, 10], 'kernel': ['linear', 'rbf']}
grid = GridSearchCV(SVC(), params, cv=3)
grid.fit(X, y)
print(f"最佳参数: {grid.best_params_}, 最佳得分: {grid.best_score_:.2f}")
# 最佳参数: {'C': 1, 'kernel': 'linear'}, 最佳得分: 0.995. 特征工程
- 特征缩放与编码
## 5. 特征工程
# 特征缩放与编码
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
import pandas as pd# 创建混合类型数据
data = pd.DataFrame({'Age': [25, 30, 35],'Gender': ['M', 'F', 'M'],'Salary': [50000, 80000, 60000]
})# 预处理管道
preprocessor = ColumnTransformer(transformers=[('num', StandardScaler(), ['Age', 'Salary']),('cat', OneHotEncoder(), ['Gender'])])transformed = preprocessor.fit_transform(data)
print("处理后的特征矩阵:\n", transformed[:3])
# [[-1.22474487 - 1.06904497 0. 1.]
# [0. 1.33630621 1. 0.]
# [1.22474487 - 0.26726124 0. 1.]]6. 集成学习
- 随机森林
## 6. 集成学习
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification# 生成分类数据
X, y = make_classification(n_samples=1000, n_features=4, random_state=42)# 训练模型
rf = RandomForestClassifier(n_estimators=100)
rf.fit(X, y)# 特征重要性
print("特征重要性:", rf.feature_importances_) # [0.19187158 0.11089512 0.42058598 0.27664732]7. 深度学习入门
- 神经网络(TensorFlow/Keras)
## 7. 深度学习入门
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense# 创建简单神经网络
model = Sequential([Dense(16, activation='relu', input_shape=(4,)),Dense(8, activation='relu'),Dense(3, activation='softmax') # 三分类输出
])model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])from sklearn.datasets import load_iris# 使用鸢尾花数据
X, y = load_iris(return_X_y=True)
model.fit(X, y, epochs=50, batch_size=8, validation_split=0.2)
# Epoch 1/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 3s 48ms/step - accuracy: 0.4809 - loss: 1.0539 - val_accuracy: 0.0000e+00 - val_loss: 2.2225
# Epoch 2/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 23ms/step - accuracy: 0.3573 - loss: 1.0570 - val_accuracy: 0.0000e+00 - val_loss: 1.9504
# Epoch 3/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 25ms/step - accuracy: 0.4543 - loss: 1.0130 - val_accuracy: 0.0000e+00 - val_loss: 1.7946
# Epoch 4/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 1s 21ms/step - accuracy: 0.3709 - loss: 1.0432 - val_accuracy: 0.0000e+00 - val_loss: 1.6937
# Epoch 5/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 20ms/step - accuracy: 0.4127 - loss: 1.0087 - val_accuracy: 0.0000e+00 - val_loss: 1.6280
# Epoch 6/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 13ms/step - accuracy: 0.3909 - loss: 0.9927 - val_accuracy: 0.0000e+00 - val_loss: 1.5939
# Epoch 7/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 13ms/step - accuracy: 0.4594 - loss: 0.9809 - val_accuracy: 0.0000e+00 - val_loss: 1.5724
# Epoch 8/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - accuracy: 0.4445 - loss: 0.9837 - val_accuracy: 0.0000e+00 - val_loss: 1.5351
# Epoch 9/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 13ms/step - accuracy: 0.3416 - loss: 1.0096 - val_accuracy: 0.0000e+00 - val_loss: 1.4902
# Epoch 10/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step - accuracy: 0.2327 - loss: 1.0088 - val_accuracy: 0.0000e+00 - val_loss: 1.5017
# Epoch 11/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 14ms/step - accuracy: 0.2605 - loss: 1.0100 - val_accuracy: 0.0000e+00 - val_loss: 1.4128
# Epoch 12/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step - accuracy: 0.2959 - loss: 0.9511 - val_accuracy: 0.1667 - val_loss: 1.2437
# Epoch 13/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 10ms/step - accuracy: 0.6964 - loss: 0.9002 - val_accuracy: 0.6667 - val_loss: 0.9072
# Epoch 14/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 9ms/step - accuracy: 0.9348 - loss: 0.8280 - val_accuracy: 0.5667 - val_loss: 0.9211
# Epoch 15/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 8ms/step - accuracy: 0.9814 - loss: 0.7634 - val_accuracy: 0.5667 - val_loss: 0.8991
# Epoch 16/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 8ms/step - accuracy: 0.9636 - loss: 0.7216 - val_accuracy: 0.5333 - val_loss: 0.8739
# Epoch 17/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 0.9425 - loss: 0.6850 - val_accuracy: 0.5333 - val_loss: 0.8628
# Epoch 18/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 0.9761 - loss: 0.6234 - val_accuracy: 0.5000 - val_loss: 0.8575
# Epoch 19/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.9860 - loss: 0.5867 - val_accuracy: 0.5333 - val_loss: 0.8093
# Epoch 20/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 0.9506 - loss: 0.5556 - val_accuracy: 0.5333 - val_loss: 0.7932
# Epoch 21/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.9629 - loss: 0.4919 - val_accuracy: 0.5667 - val_loss: 0.7568
# Epoch 22/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 6ms/step - accuracy: 0.9530 - loss: 0.4680 - val_accuracy: 0.5333 - val_loss: 0.7723
# Epoch 23/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.9620 - loss: 0.4558 - val_accuracy: 0.5000 - val_loss: 0.8096
# Epoch 24/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.9312 - loss: 0.4277 - val_accuracy: 0.5667 - val_loss: 0.7312
# Epoch 25/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - accuracy: 0.9543 - loss: 0.3949 - val_accuracy: 0.5333 - val_loss: 0.7528
# Epoch 26/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 8ms/step - accuracy: 0.9634 - loss: 0.3507 - val_accuracy: 0.5333 - val_loss: 0.7714
# Epoch 27/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 9ms/step - accuracy: 0.9385 - loss: 0.3618 - val_accuracy: 0.5667 - val_loss: 0.6876
# Epoch 28/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.9803 - loss: 0.3215 - val_accuracy: 0.5333 - val_loss: 0.7657
# Epoch 29/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 8ms/step - accuracy: 0.9850 - loss: 0.2792 - val_accuracy: 0.6333 - val_loss: 0.6572
# Epoch 30/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 8ms/step - accuracy: 0.9722 - loss: 0.2874 - val_accuracy: 0.5333 - val_loss: 0.7498
# Epoch 31/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.9879 - loss: 0.2598 - val_accuracy: 0.6000 - val_loss: 0.6697
# Epoch 32/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 8ms/step - accuracy: 0.9795 - loss: 0.2632 - val_accuracy: 0.5333 - val_loss: 0.7364
# Epoch 33/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 8ms/step - accuracy: 0.9696 - loss: 0.2779 - val_accuracy: 0.6667 - val_loss: 0.6080
# Epoch 34/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 8ms/step - accuracy: 0.9707 - loss: 0.2359 - val_accuracy: 0.5333 - val_loss: 0.7535
# Epoch 35/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 14ms/step - accuracy: 0.9738 - loss: 0.2253 - val_accuracy: 0.6333 - val_loss: 0.6399
# Epoch 36/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 9ms/step - accuracy: 0.9880 - loss: 0.2026 - val_accuracy: 0.6000 - val_loss: 0.6927
# Epoch 37/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 8ms/step - accuracy: 0.9518 - loss: 0.2127 - val_accuracy: 0.6667 - val_loss: 0.5798
# Epoch 38/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.9640 - loss: 0.1947 - val_accuracy: 0.5333 - val_loss: 0.7723
# Epoch 39/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.9708 - loss: 0.1861 - val_accuracy: 0.7333 - val_loss: 0.5081
# Epoch 40/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.9921 - loss: 0.1761 - val_accuracy: 0.5333 - val_loss: 0.7666
# Epoch 41/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.9768 - loss: 0.1724 - val_accuracy: 0.6667 - val_loss: 0.5986
# Epoch 42/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 8ms/step - accuracy: 0.9809 - loss: 0.1615 - val_accuracy: 0.6667 - val_loss: 0.6072
# Epoch 43/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.9744 - loss: 0.1619 - val_accuracy: 0.6000 - val_loss: 0.6482
# Epoch 44/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.9788 - loss: 0.1416 - val_accuracy: 0.6667 - val_loss: 0.5704
# Epoch 45/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.9891 - loss: 0.1476 - val_accuracy: 0.6667 - val_loss: 0.5727
# Epoch 46/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.9654 - loss: 0.1449 - val_accuracy: 0.6333 - val_loss: 0.6212
# Epoch 47/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.9842 - loss: 0.1510 - val_accuracy: 0.7000 - val_loss: 0.5006
# Epoch 48/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 8ms/step - accuracy: 0.9725 - loss: 0.1533 - val_accuracy: 0.6667 - val_loss: 0.5911
# Epoch 49/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 8ms/step - accuracy: 0.9793 - loss: 0.1484 - val_accuracy: 0.7000 - val_loss: 0.4937
# Epoch 50/50
# 15/15 ━━━━━━━━━━━━━━━━━━━━ 0s 9ms/step - accuracy: 0.9888 - loss: 0.1366 - val_accuracy: 0.6333 - val_loss: 0.64058. 进阶方向
| 领域 | 关键技术 | 典型应用场景 |
|---|---|---|
| 自然语言处理 | Transformer/BERT | 机器翻译、情感分析 |
| 计算机视觉 | CNN/YOLO | 图像识别、目标检测 |
| 强化学习 | Q-Learning/PPO | 游戏AI、机器人控制 |
| 推荐系统 | 协同过滤/矩阵分解 | 电商推荐、内容推荐 |
学习路线建议
1. 基础阶段(1-2个月):
- Python编程 + NumPy/Pandas
- 统计学基础 + 数据可视化
- Scikit-learn基础模型
2. 中级阶段(2-3个月):
- 特征工程技巧
- 模型调优方法
- 集成学习模型
3. 高级阶段(持续学习):
- 深度学习框架(TensorFlow/PyTorch)
- 领域专项学习(NLP/CV等)
- 部署与优化(ONNX/Docker)