DeepSeek-OCR:把长文本“挤进图片”的新思路
长上下文会让大模型变慢、变贵。DeepSeek-OCR 提出“光学上下文压缩”:先把文本渲染成图片,用极少的视觉标记承载大量信息;需要时再从这些视觉标记解码为文本。这样既能保留关键内容,又能把计算成本显著降下来。
效果到底怎样?
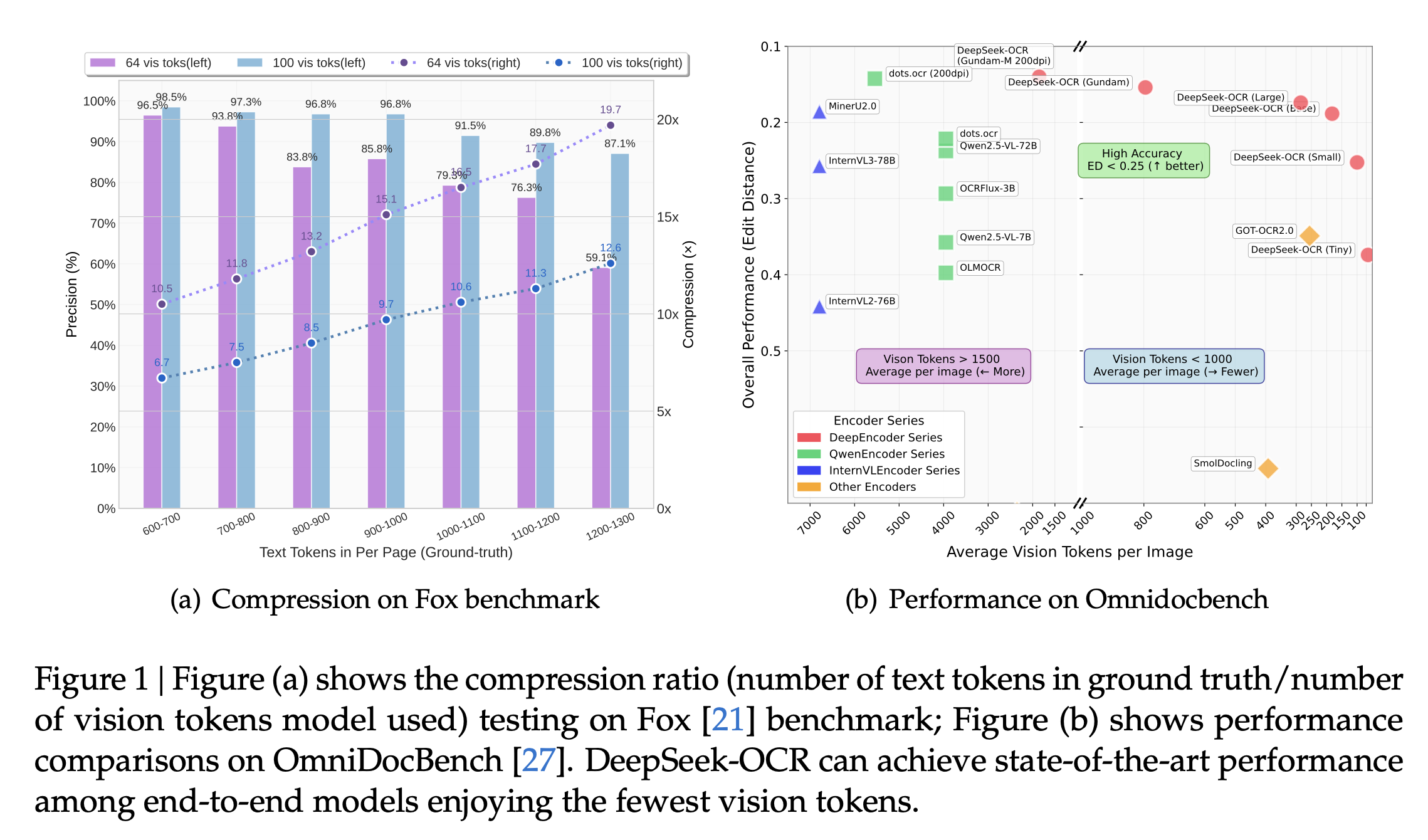
- 在 10 倍压缩比内,OCR 解码准确率约 97%;
- 在 20 倍压缩时,仍有约 60% 的准确率,可用于较旧或次要的上下文;
- 仅用 100 个视觉标记就超越使用 256 标记的 GOT-OCR2.0;不到 800 个标记(Gundam 模式)即可超过平均每页需 6000+ 标记的 MinerU2.0;
- 单张 A100-40G GPU 每天可生成超 20 万页训练数据,工程可落地。
它是怎么做到的?用一个更“聪明”的编码器 DeepEncoder:前半段用窗口注意力细看局部,后半段用密集全局注意力把握整体;中间插入 16 倍卷积下采样,把标记从 4096 压到 256,让内存和计算压力大幅降低。同时支持多分辨率与动态分块(如 Gundam 模式),高分辨率大图不再被过度碎片化,关键区域更清晰。解码器采用 3B 级 MoE,在保证表达力的同时维持小模型级别的推理效率。
能用在哪些场景?
- 长文档解析:报告、书籍、论文等常见场景用 64–100 个视觉标记就够用;
- 对话历史压缩:把旧对话转成图片并逐步降低分辨率,模拟“遗忘曲线”,节省上下文成本;
- 数据生产:为 LLM/VLM 快速生成高质量预训练数据;
- 复杂视觉表达:图表、化学公式、几何图形与自然图像解析。
与常见方案相比,它不追求极端的高分辨率或细碎分块,而是通过“先压再看全局”的折中设计,在效率与效果之间取得平衡。
注意:当压缩比超过 10 倍时,布局复杂或分辨率过低会造成精度下降;使用场景需结合容忍度选择合适压缩比与分辨率。
开源地址:http://github.com/deepseek-ai/DeepSeek-OCR
一句话总结:把长文本“挤进图片”,用更少的标记承载更多信息,在不明显牺牲准确率的前提下,显著降低长上下文的成本,让大模型更省、更稳、更快。