A Survey of Camouflaged Object Detection and Beyond论文阅读笔记
A Survey of Camouflaged Object Detection and Beyond论文阅读笔记
1. 基本信息
- 标题: A Survey of Camouflaged Object Detection and Beyond
- 作者: Fengyang Xiao, Sujie Hu, Yuqi Shen, et al.
- 关键词: Camouflaged Object Detection (COD), Camouflaged Scenario Understanding, Deep Learning, Artificial Intelligence
- 资源库: GitHub链接
2. 摘要与核心贡献
本文旨在对伪装目标检测(COD) 领域进行迄今为止最全面的综述。与传统目标检测(GOD)和显著目标检测(SOD)不同,COD专注于检测那些与背景高度融合、难以察觉的目标,极具挑战性。
核心贡献:
- 全面性: 涵盖了约180篇前沿研究,包括图像和视频级别的COD,并延伸至相关的伪装场景理解任务。
- 系统性基准测试: 对40个图像模型和8个视频模型在6个数据集和6个评估指标上进行了定量和定性分析。
- 前瞻性指导: 系统性地指出了当前方法的局限性,并提出了9个有前景的未来研究方向。
- 资源整合: 创建并维护一个GitHub仓库,持续收集COD相关的技术、数据集和资源。
3. 引言:什么是COD?
- COD定义: 在图像或视频中识别和分割那些因伪装而“消失”在背景中的物体。
- 挑战性: 目标的表观特征(纹理、颜色、轮廓)被刻意设计或自然演化以匹配背景,使得区分前景与背景极其困难。
- 应用价值:
- 工业: 隐蔽缺陷检测。
- 农业: 害虫监测。
- 医学: 病灶分割。
- 生态学: 野生动物研究与保护。
- 艺术与娱乐: 照片级真实感融合、艺术创作。
4. 图像级COD方法详解
这是综述的核心部分,详细梳理了从传统方法到现代深度学习的演进。
4.1 传统方法(基于手工特征)
- 依赖特征: 纹理、强度(亮度)、颜色。
- 局限性: 在简单、均匀背景下有效,但无法处理复杂场景、低分辨率或前景背景高度相似的情况。这凸显了深度学习方法的必要性。
4.2 深度学习方法
作者从多个维度对深度学习方法进行了分类,并提炼出六大核心策略,这是理解现代COD技术的关键。
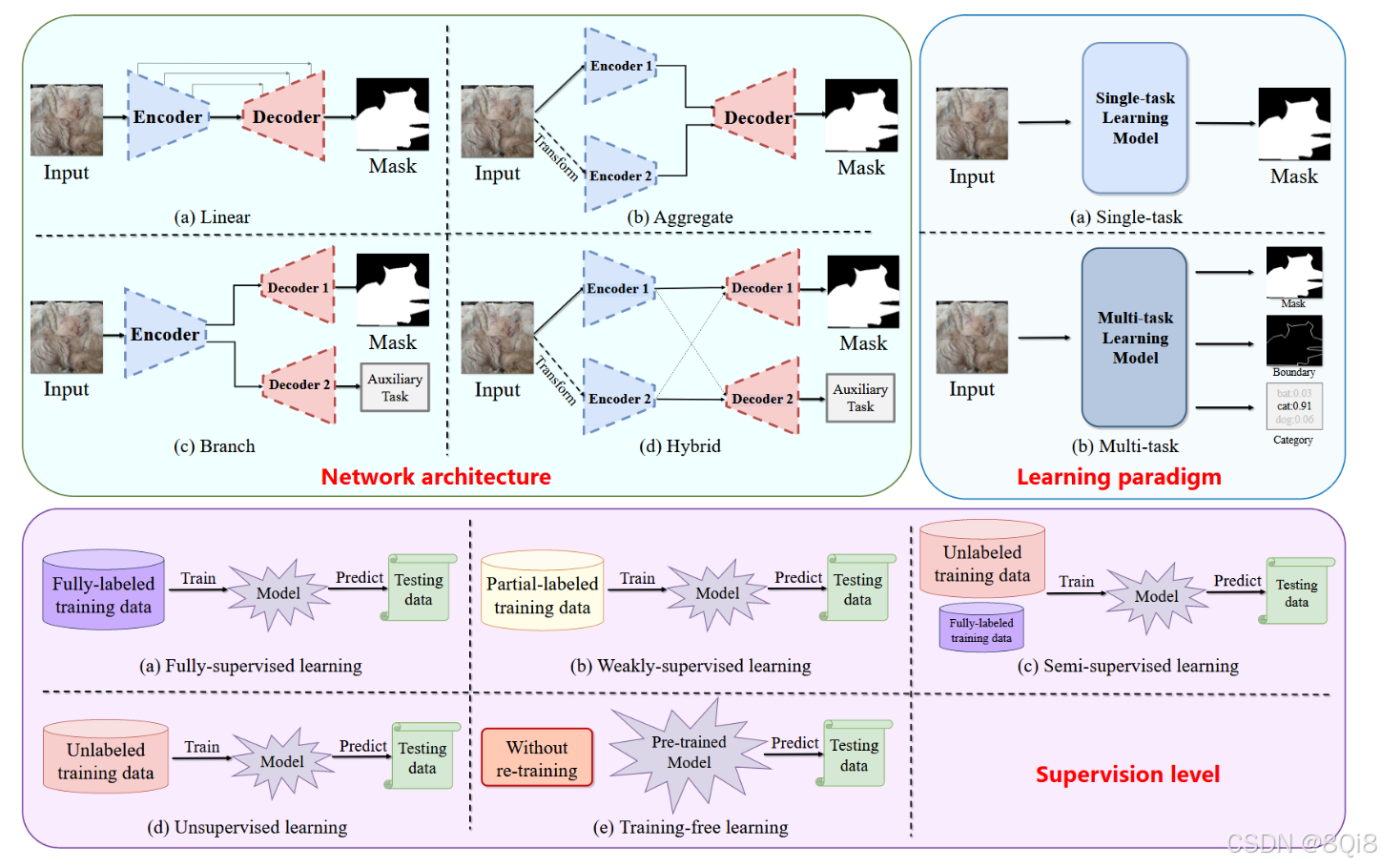
维度一:基本架构
- 网络架构: 线性、聚合、分支、混合。
- 学习范式: 单任务学习、多任务学习。
- 监督水平: 全监督、弱监督、半监督、无监督、训练无关。
维度二:六大核心策略(重点)
- 多尺度特征聚合
- 动机: 伪装目标尺寸多变,需要模型感知不同尺度的信息。
- 方法: 通过特征金字塔、多分支输入等方式融合不同层级的特征。
- 机制模拟
- 动机: 模仿自然界捕食者(或人类)的搜索和识别过程。
- 典型方法:
- SINet系列: 模拟“搜索”和“识别”两个阶段。
- ZoomNet: 模拟人类“放大缩小”观察模糊图像的行为。
- MirrorNet: 使用镜像流扰乱伪装模式。
- PreyNet & Camouflageator: 模拟捕食者-猎物的对抗动态进行对抗训练。
- 多源信息融合
- 动机: 利用RGB图像以外的信息来提供额外线索,打破伪装。
- 融合模态:
- 频率域: 伪装可能在频域中表现出异常(如FEMNet, FEDER)。
- 深度信息: 提供3D空间线索,帮助物体“弹出”(如PopNet, RISNet)。
- 提示学习: 利用文本或视觉提示引导大模型进行检测,实现零样本或训练无关的COD(如CoVP, GenSAM)。
- 多任务学习
- 动机: 通过引入相关辅助任务,为模型提供额外的监督信号,提升主任务性能。
- 辅助任务类型:
- 边界检测: 强制模型关注物体轮廓(如MGL, BSA-Net)。
- 分类: 判断图像中是否存在伪装物体(如ANet)。
- 定位/排序: 定位最易识别的区域或对实例的伪装难度进行排序(如LSR)。
- 不确定性估计: 量化模型预测的不确定性,聚焦于难分区域(如URCOD, UGTR)。
- 图像重建/纹理检测: 通过重建或纹理分析来学习更好的特征表示。
- 联合SOD与COD
- 动机: SOD(找最显眼的)和COD(找最隐蔽的)看似对立,但在特征层面有共通之处(都需要从背景中分离物体)。
- 方法: 通过对抗学习、对比学习等方式,让模型同时学习这两个任务,利用其矛盾性相互促进(如UJSCOD)。
- 新任务设定
- 动机: 拓展COD的应用边界,解决更实际、更复杂的场景。
- 新任务:
- UCOS: 无监督伪装分割,解决标注数据稀缺问题。
- CoCOD: 协作COD,通过分析多张相关图像来协同检测同一类伪装物体。
- RefCOD: 参考式COD,根据文本或参考图像检测指定的伪装目标。
- OVCOS: 开放词汇伪装分割,检测训练时未见过的类别的伪装物体。
5. 视频级COD方法
-
核心挑战: 利用时序信息和运动线索来揭示在单帧中难以发现的伪装物体。
-
方法分类:
- 两阶段框架:
- 显式运动: 预先计算光流图作为运动输入。
- 隐式运动: 在网络内部(如通过伪掩码)学习时序对应关系。
- 端到端框架: 成为新趋势,将运动建模和分割集成在一个网络中,避免误差累积,泛化性更好(如ZoomNeXt, TSP-SAM)。
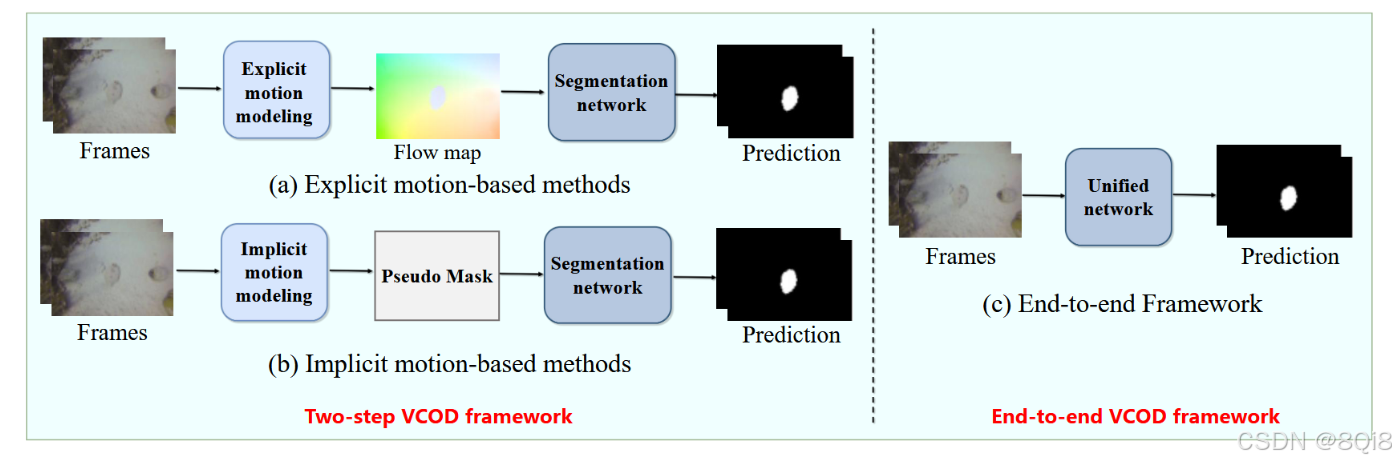
- 两阶段框架:
6. 实验与评估
6.1 常用数据集(摘要)
- 图像:
COD10K(最大最全),CAMO,NC4K(测试泛化性),CHAMELEON。
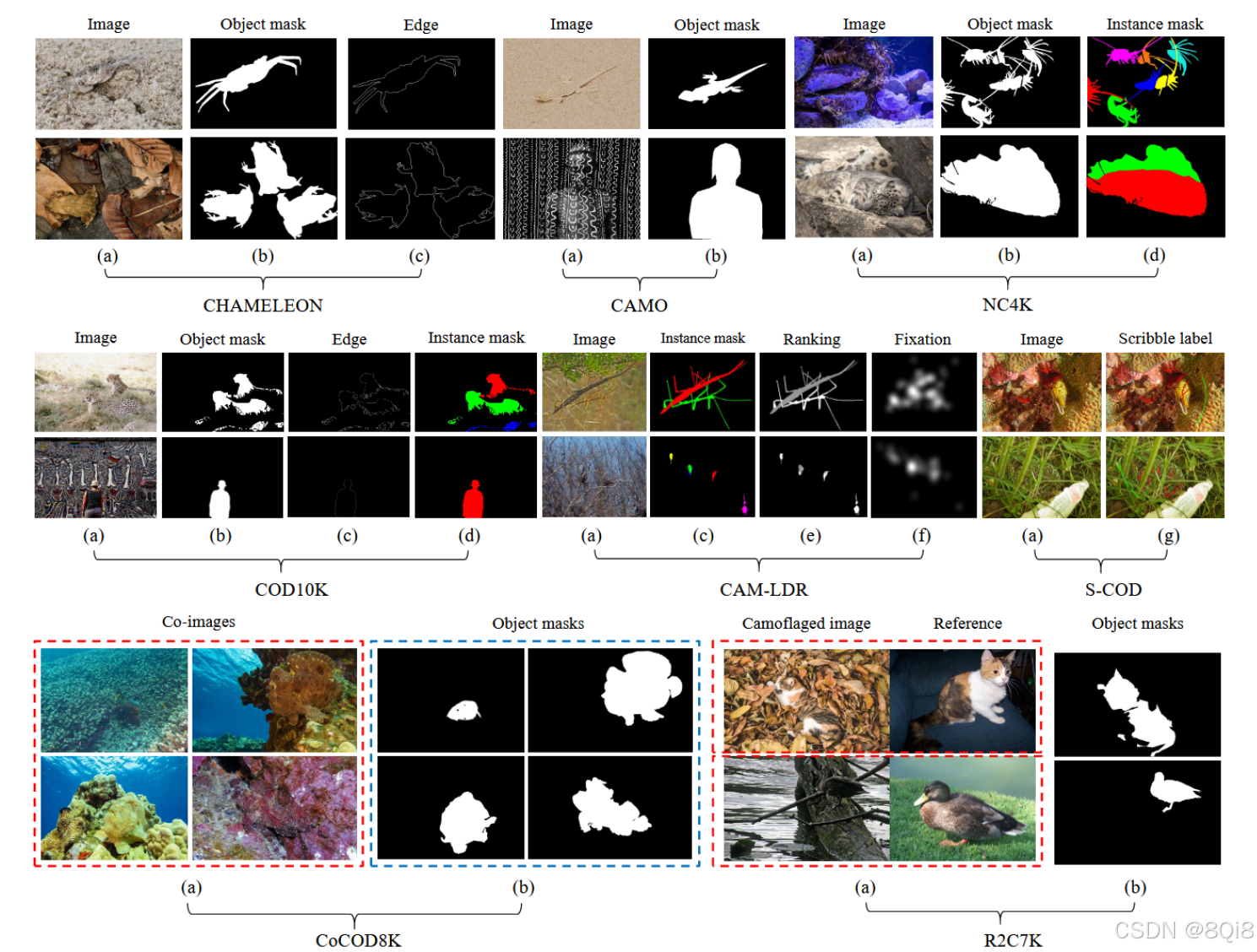
- 视频:
MoCA-Mask,CAD2016。

6.2 评估指标
Sα: 结构相似性。Fβ: 加权精确率-召回率调和平均。Eϕ: 局部和全局对齐度量。M: 平均绝对误差(值越低越好)。- 视频任务额外使用:
mDice,mIoU。
6.3 关键实验结果
- 图像COD: 基于Transformer的模型(如FSNet, HitNet)因其强大的长距离依赖建模能力,总体表现优于CNN模型。PopNet因其创新的深度感知和物体分离策略表现突出。
- 视频COD: 端到端模型(如ZoomNeXt) 性能优于两阶段模型,证明了统一框架的有效性。基于SAM的模型(如TSP-SAM)也显示出巨大潜力。
7. 未来研究方向
作者提出了9个方向,可归纳为两大类:
A. 缓解现有问题
- 利用深度生成模型解决数据稀缺: 使用GAN和扩散模型(如CamDiff)生成多样化的高质量伪装图像,用于数据增强。
- 应对复杂场景与挑战性样本: 专门研究如何处理微小物体、严重遮挡、模糊边界、极端光照(如低光、雾天) 等极端情况。
- 标注高效的学习: 发展弱监督、半监督、零样本和开放世界学习范式,减少对大量精细标注的依赖。
- 设计专用的伪装损失函数: 如SCLoss,通过加强空间一致性来改善对模糊区域的分割。
- 满足实时性能约束: 开发轻量级网络、训练无关方法和绿色学习策略,使COD能部署在资源受限的设备上。
B. 探索扩展潜力
- 拥抱新任务: 继续探索和深化CoCOD, RefCOD等新任务,并设想如交互式COD(I-COD) 等全新方向。
- 区分SOD与COD: 深入研究两者在特征层面的根本差异与联系,设计能鲁棒处理两者并实现相互转换的模型。
- 多模态信息融合: 更深入地融合RGB、热红外、深度、音频、文本等多种模态信息,以应对更复杂的真实环境。
- 效率导向的大规模视觉-语言模型: 探索如何高效地利用SAM、VLMs等基础模型,通过提示工程、适配器微调、知识蒸馏等技术,在保持高性能的同时降低计算成本。
8. 总结
地融合RGB、热红外、深度、音频、文本等多种模态信息,以应对更复杂的真实环境。
4. 效率导向的大规模视觉-语言模型: 探索如何高效地利用SAM、VLMs等基础模型,通过提示工程、适配器微调、知识蒸馏等技术,在保持高性能的同时降低计算成本。
8. 总结
这篇综述是进入COD领域的绝佳指南和路线图。它不仅系统性地梳理了从传统方法到最前沿深度学习模型的技术演进,还通过详尽的实验评估指明了各方法的优缺点。最重要的是,它提出的9个未来方向为研究者(尤其是刚入门的研究者)提供了清晰且有价值的研究课题。文末附带的GitHub资源库更是持续学习和跟踪领域动态的宝贵财富。