flash-attention连环问答--softmax 、safe softmax 、online softmax
1 Self Attention是怎么计算的,写出对应的公式
其中 Q,K,V 都是 N * dk 的 2D 矩阵,N 为序列长度,dk 为头的维度。
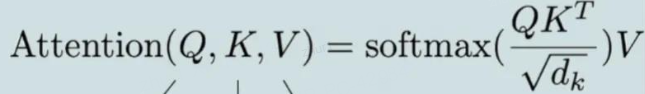
2 softmax 公式的计算有什么问题,在工程实现的时候怎么做的?
因为包含了幂指数计算,所以它有一个明显的问题:数值溢出。
对于大模型常用的半精度 fp16 来说,最大值也才 65536,所以当 xi 大于 11 的时候,e 的 12 次方等于 162754.7914 ,大于 65536。所以实际工程实现相对于原生的 softmax,它先要减去一个 max 的值,确保计算过程中不会导致数值溢出,
如下图:由于 xi-m ≤0 所以不会出现溢出,这种实现方案也叫 safe-softmax。
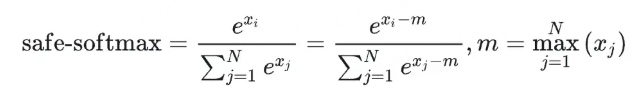
所以总结一下,对于这个问题,我们要沿着面试官的心理,首先答出标准 softmax 公式导致的问题:数值溢出。再回答实际工程的解决方案:safe-softmax,并结合相应的公式进行回答。
此外对于标准的 softmax 计算,需要 3 步,计算最大值 m,计算分母,最后再依此计算分子。
如果不做任何优化的话,它至少要和 GPU 进行 6 次通信(3 次写入,3 次写出)。
数值不稳定性:如果 x很大,ex会变得非常大,可能导致溢出。
计算效率:需要两次遍历数据——一次找最大值(为了数值稳定),一次计算概率。
内存需求:对于大数据集,需要存储所有中间结果。
所以这里我们自然就引出了下一个问题:那你能够降低 softmax 的 GPU 访存复杂度吗?如果可以,怎么做?
3 你能够降低 softmax 的 GPU 访存复杂度吗?如果可以,怎么做?
这个问题希望你回答什么呢?其实就两点,
第一,你知不知道 softmax 可以通过流式计算降低 GPU 访存复杂度。
第二,能否阐述一下流式计算的核心思想。
首先我们明确一点,就是 softmax 是可以做成流式计算的,18 年 NVIDIA 发表的一篇论文,就提出了 online-softmax 算法,下图展示了其核心计算过程。
Online Softmax 的目标是:
- 单次遍历:只看一遍数据,边看边算。
- 流式处理:数据一块一块来,随时更新结果。
- 内存高效:不用把所有数据都存下来。
Online Softmax 的核心思想
Online Softmax 的核心在于增量更新。我们不一次性处理所有数据,而是每次来一个新数据点,就更新两个关键统计量:
- 当前最大值m:记录目前见过的最大输入值。
- 分母的累加和d:Softmax 分母是所有 e x i 的和,我们动态维护它。
当新数据到来时,我们只需要用已有的统计量和新数据点,更新这两个值,就能保证结果正确。这就像在流水线上加工零件,每来一个零件就更新一下生产线上的状态,不用等所有零件都到齐。
所以最终我们可以借助 GPU 的 share memory 来存储中间结果,将上面的两步只用一个 kernel 实现,这样就只需要与 global memory 通信两次,一次写入数据,一次读取结果。
不过这里要注意,就是由于第二步的计算仍然需要依赖第一步计算的分母 dN,所以还是需要两步,换句话说,不能做成 one pass。
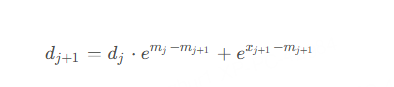
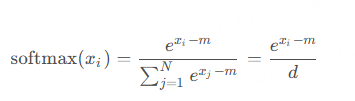
4 既然 softmax 不能做到 one-pass,为什么 Flash Attention 可以,解释一下背后的核心思想?
首先 Flash Attention 能做到 one-pass 计算,其核心思想是 Flash Attention 让 Attention 的所有计算都符合加法结合律,这样就可以充分利用 GPU 的并行优势,这是希望我们答出的第一个点。
虽然单独的 softmax 运算不能做到 one-pass,但是 self-Attention 中的 softmax 求完之后,它的每一项的值会与 V 中向量相乘,然后累加。这里的累加很关键,有了这个累加的操作,所有的计算又符合结合律了,这就是 FlashAttention 并行加速的的理论核心思想。如果没有这个累加,比如单纯的计算 softmax,反而没有办法并行。
所以用类似 Online Softmax 的方法,就可以将 Attention 所有的操作,都放到一个 for 循环里(一个 Kernel 就可以实现)。我们可以推导一下输出的关系:
从上面式子可以看到,oi 只依赖 oi-1, mi, mi-1,所以可以实现递归计算。
更进一步,分析 Flash Attention 计算过程可以发现,Flash Attention 其实并没有减少 Attention 的计算量,也不影响精度,但是却比标准的 Attention 运算快 2-4 倍的运行速度,同时减少了 5~20 倍的内存使用量。
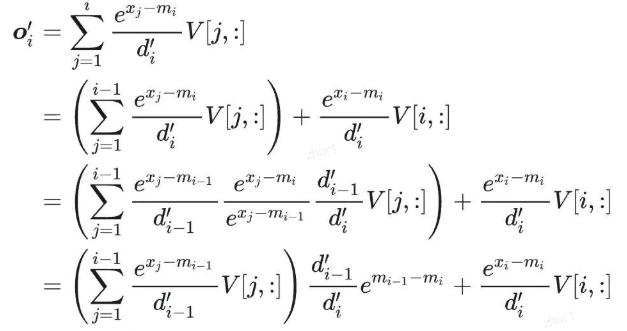
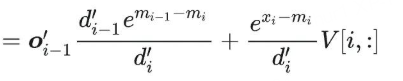
5 详细解释一下 Flash Attention 中的 tiling 策略?
问这个问题,首先是想考察你,
知不知道什么是 tiling,为什么要使用它?
以及使用之后有什么作用?
其次在 Flash Attention 中的 tiling 策略是如何做的,能否说一下它的整个流程以及具体的效果?
tiling 说白了就是对矩阵分块,
分块策略的主要动机,是通过将大矩阵分解为更小的块,以此来减少内存访问的开销,同时提高计算效率。分块策略允许我们在处理大矩阵时,只加载和处理一部分数据,而不是一次性加载整个矩阵,这样可以减少内存带宽的压力。
而具体到 Flash Attention 中,就是将 Q,K,V 分成更多个小块,其中 K,V 在外循环,Q 在内循环。
在计算注意力分数的时候,通常需要进行 softmax 操作。为了避免一次性计算整个 softmax,Flash Attention 会采用局部归一化策略。
对于每个块,我们只计算这个块内部的 softmax,并在累加结果的时候进行适当的归一化。
所以通过逐块计算,减少了全局内存的访问次数,这样就降低了内存带宽的压力。
这种策略特别适用于处理长序列的注意力机制,能够显著加速计算过程。
6 FlashAttention 对 MQA 和 GQA 是怎么处理的?
想考察的,首先是你是否知道 MQA 和 GQA,如果你都不知道这两个概念,这道题目也就无从答起。我们来看这张图。
之前我们讲过,MQA 只保留了一个 KV Head,多个 Query Heads 共享相同的 KV Head。
而 GQA 与 MQA 不同,它采取了折中的做法,GQA 把 Query Heads 进行分组,每组 Query Heads 对应一个 KV Head。
7 那在 Flash Attention 中对 MQA/GQA 是如何处理呢?
这里要听到的一个关键词,就是 Indexing 思想。
对于 MQA 和 GQA,FlashAttention 采用了 Indexing 的方式,而不是直接复制多份 KV Head 的内容到显存然后再进行计算。
Indexing 的思想,就是通过传入 KV Head 索引到 GPU Kernel 中,然后根据内存地址,直接从内存中读取 KV。