1.基于cuda的异构计算
1. 基于cuda 的异构并行计算
1.1 并行计算
目标:提高运算速度
定义:同时使用许多计算资源(核心或计算机)来执行并发运算。
1.1.1 串行编程与并行编程
串行编程:指的是有先后次序的执行。比如后一个依赖前一个的执行结果。
并行编程:指的是其它模块间互不影响,就是运算独立。比如我要计算1-5000的和,我可以拆成五个部分,分别计算,最后相加即可。
1.1.2 并行性
可分为任务并行与数据并行
-
任务并行:当许多任务或者函数可以独立地、大规模地并行执行时,这便是任务并行。任务并行的重点在于利用多核系统对任务进行分配。
-
数据并行:当可以同时处理很多数据时,这就是数据并行。数据并行的重点在于利用多核系统对数据进行分配。
数据并行两种方式:块划分(block partitioning)和周期划分(cyclic partitioning)
2.1 块划分:一组连续的数据被分到一个块内,每个数据块以任意次序被安排给一个线程。线程通常在同一时间只处理一个数据块。
2.2 周期划分:更少的数据被分到一个块内,相邻的线程处理相邻的数据块,每个线程可以处理多个数据块。
1.1.3 计算机架构
广泛分类的方法是弗林分类法,根据指令和数据进入CPU的方式,分为以下四种:
- 单指令单数据(SISD):传统计算机,一种串行结构,只有一个核心,在任意时刻只有一个指令流在处理数据流。
- 单指令多数据(SIMD):并行架构类型。有多个核心,在任何时刻每个核心只有一条执行处理不同的数据流。例如:向量机。 优点:在CPU编写代码时,程序员可以继续按照串行逻辑思考但对并行数据操作实现并行加速,而其他细节由编译器负责。
- 多指令单数据(MISD):并行架构类型。每个核心使用多个指令流处理同一个数据。
- 多指令多数据(MIMD):并行架构。多个核心使用多个指令流来异步处理多个数据流来达到实现空间上的并行。
根据内存组织方式进行进一步划分,一般可以分为以下类型:
- 分布式内存的多节点系统。
- 共享内存的多处理器系统。(众核系统)
1.1.4 gpu核心与cpu核心
gpu核心代表了一种众核结构,几乎包括了:多线程、MIMD、SIMD以及指令级并行。NVDIA 称这个架构未SIMT(单指令多线程)
两种核心的区别:
- cpu核心比较重,侧重于处理非常复杂的控制逻辑,以优化串行程序的进行。
- gpu核心较为轻量 ,用于优化具有简单控制逻辑的数据并行任务,注重并行程序的吞吐量。
1.2 异构计算
gpu设计之初是用于处理并行图形计算问题的。随着时间推移,gpu已然成为了更强大和更广义的处理器,在执行大规模并行计算中有着较为优越的性能和很高的效率。
1.2.1 异构架构
一个异构计算节点包括两个多核cpu插槽和两个或更多个的众核gpu。GPU不是一个独立运行的平台而实CPU的协处理器, GPU必须通过PCLe总线与基于CPU的主机相连来进行操作。
通常我们将CPU的所在位置称为主机端,GPU的所在位置称之为设备端。
具体逻辑图如下:
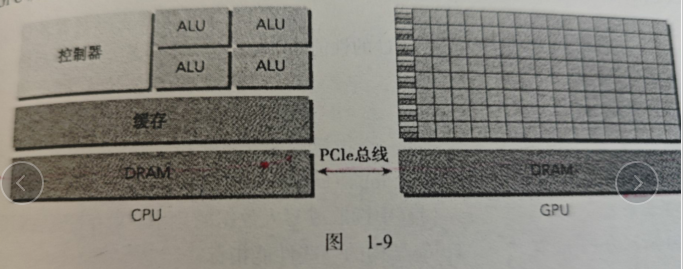
异构应用包含两个部分:
- 主机代码。CPU运行,作用:应用通常由CPU初始化。CPU代码负责管理设备端的环境、代码和数据。
- 设备代码。GPU运行。作用:在计算密集型的应用中,有很多并行数据的程序段。GPU就是最为常见的硬件加速器。
应用NVIDA gpu计算平台的产品:
- Tegra(用于移动和嵌入式设备)
- Geforce(面向图形用户)
- Quadro(专业绘图设计)
- Tesla(用于大规模的并行计算)
描述GPU容量的两个特征:
- CUDA核心数量。
- 内存大小。
描述GPU性能:
- 峰值计算的性能。(是用来评估计算容量的一个指标,通常定义为每秒能处理的单精度或双精度的浮点运算的数量,单位通常是GFlops(每秒十亿次浮点运算)或者TFlops(每秒万亿次浮点运算))
- 内存带宽。(从内存中读取或者写入数据的比率 单位是GB/S)
1.2.2 异构计算的范例
适用范围:
- cpu计算:适合处理控制密集型的任务。
- gpu计算:适合处理包含数据并行的计算密集型任务。处理由计算任务主导且带有简单控制流的工作负载。
1.2.3 GPU线程与CPU线程

1.2.4 CUDA:一种异构计算平台
CUDA是一种通用的并行计算平台与编程模型,它利用NVIDA GPU 中的并行计算引擎可以有效的解决复杂计算问题。可以像在CPU上,通过GPU来进行运算。
适用语言:C、C++、python等。
CUDA提供了两层API 来管理GPU设备和组织线程。
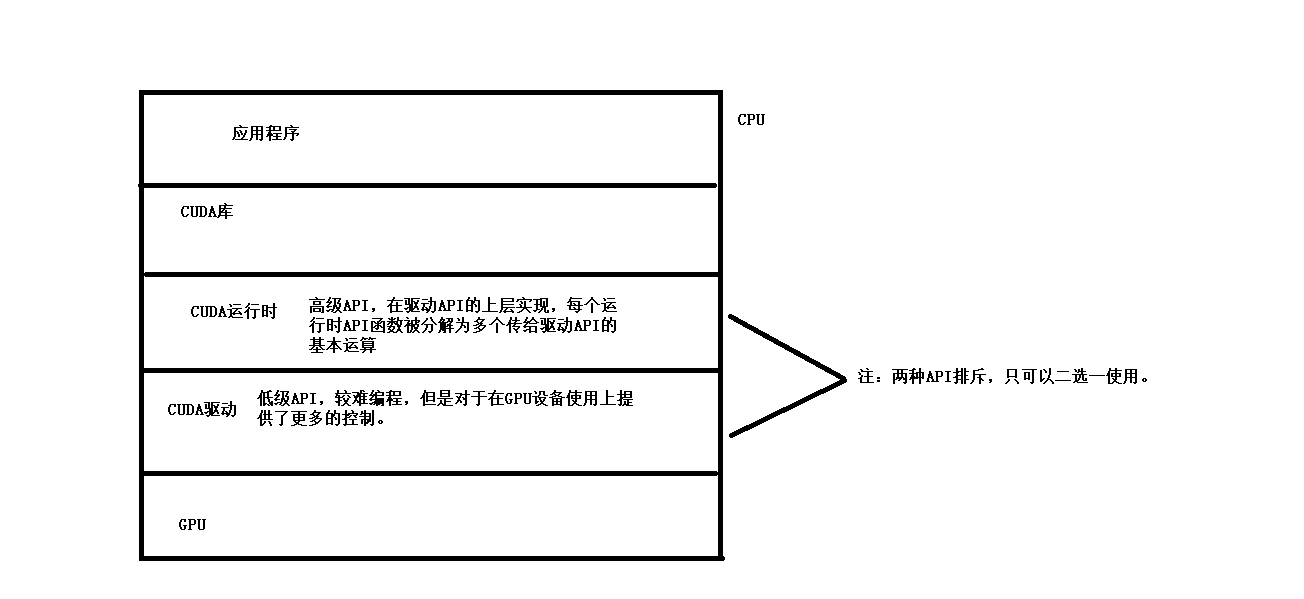
CUDA程序包含了以下两个部分的混合:
- 在CPU上运行的主机代码。 nvcc(cuda 的一个编译,类似于gcc)会将设备代码从主机代码中分离出来。主机代码是标注的C代码,通过C编译器进行编译。
- 在GPU上运行的设备代码。通过nvcc 编译。
在链接阶段,在内核程序调用和显示GPU设备操作中添加CUDA运行时库。

nvcc是以广泛使用的LLVM的开源编译系统为基础的。
1.3 写代码
1.3.1 输出hello world
#include<stdio.h>
int main() {printf("hello world \n");return 0;
}
编译命令:nvcc hello.cu -o hello
1.3.2 编写内核函数
__global__ void print(void) { //__global__ 告诉编译器这个函数会从CPU调用,在gpu运行printf("hello world from gpu\n");
}
int main() {printf("hello world from cpu\n"); print<<<1,10>>>(); //三个尖括号意味着主线程到设备端代码的调用。在这个代码中,意味着有10 个线程被调用。 cudaDeviceReset();//显示的释放和清空当前进程中与当前设备有关的所有资源。return 0;
}
编译命令:nvcc -arch=sm_86 hello.cu -o hello
-arch=sm_86:用于指定目标 GPU 的架构代码(binary 版本)
-arch=sm_86 :如何查看:
#include <cuda_runtime.h>
#include <iostream>int main() {int device_count = 0;cudaGetDeviceCount(&device_count);for (int i = 0; i < device_count; ++i) {cudaDeviceProp prop;cudaGetDeviceProperties(&prop, i);std::cout << "Device " << i << ": " << prop.name << std::endl;std::cout << "Compute Capability: " << prop.major << "." << prop.minor << std::endl;std::cout << "sm_" << prop.major << prop.minor << std::endl;}return 0;
}
1.3.3 CUDA编程结构(步骤)
- 分配CPU内存
- 从CPU内存拷贝数据到GPU内存。
- 调用CUDA内核函数完成程序指定的运算。
- 将数据从GPU拷贝回CPU。
< prop.major << prop.minor << std::endl;
}
return 0;
}
### 1.3.3 CUDA编程结构(步骤)1. 分配CPU内存
2. 从CPU内存拷贝数据到GPU内存。
3. 调用CUDA内核函数完成程序指定的运算。
4. 将数据从GPU拷贝回CPU。
5. 释放GPU内存空间。