# 高并发内存池开发记录 - 04
高并发内存池 - 开发记录04

📑 目录
- 一、PageCache设计思路
- 二、NewSpan实现过程
- 三、并发安全:加锁的坑
- 四、编译错误排查
- 五、核心代码统计
- 六、今日收获
- 七、遗留问题
- 八、思考题
- 九、三层架构连通
- 十、Bug发现与修复
- 十一、测试设计与结果
- 十二、今日总结
- 十三、思考与展望
今日目标
实现PageCache(第三层架构),完成三层内存池的核心框架
一、PageCache设计思路
1.1 为什么需要PageCache?
Day3实现的CentralCache在没有Span时用的是malloc模拟,这显然不是最终方案。PageCache的作用是:
ThreadCache(线程级) ↓ 没内存了
CentralCache(全局级)↓ 没Span了
PageCache(全局级)← 今天实现这里↓ 还没有?
操作系统(VirtualAlloc/mmap)
PageCache的职责:
- 管理大块内存(以页为单位,1页=8KB)
- 为CentralCache提供Span
- 页合并:回收时尝试合并相邻空闲页,减少外部碎片
- 页切分:大Span切分成小Span,提高内存利用率
三层架构完整流程:
1.2 核心数据结构设计
class PageCache {
private:SpanList _spanLists[NPAGES]; // 管理1~128页的Spanstd::unordered_map<PAGE_ID, Span*> _pageToSpan; // 页号→Span快速查找std::mutex _pageMtx; // 全局锁
};
为什么是128页?
- ThreadCache最大管理256KB
- 256KB / 8KB = 32页
- 留一些余量,设置为128页(1MB)
- 超过128页的大对象直接找OS,不走PageCache缓存
为什么需要_pageToSpan映射?
一开始我不理解为什么要这个映射,后来想到页合并的场景就明白了:
场景:释放一个Span(假设页号100,1页)
问题:如何知道页号101是不是也是空闲的?能不能合并?
答案:通过_pageToSpan[101]快速找到对应的Span,判断是否空闲
二、NewSpan实现过程
2.1 函数签名设计
Span* NewSpan(size_t k); // k表示需要多少页
关键问题1:如果需要3页,但只有5页的Span怎么办?
我的第一反应是直接返回5页的Span,但这样会浪费2页。正确做法是:
- 切分:5页Span → 3页(返回) + 2页(放回链表)
关键问题2:如果所有链表都空了怎么办?
选项A:向OS申请k页(刚好够用)
选项B:向OS申请128页(最大),然后切分
我选的是B,原因是:
系统调用成本:
VirtualAlloc(3页) → 1次系统调用 → 得到3页
VirtualAlloc(128页) → 1次系统调用 → 得到128页成本一样,但128页可以切分后留着后用,减少后续系统调用!
这是一种批量预取的优化思想。
NewSpan决策流程:
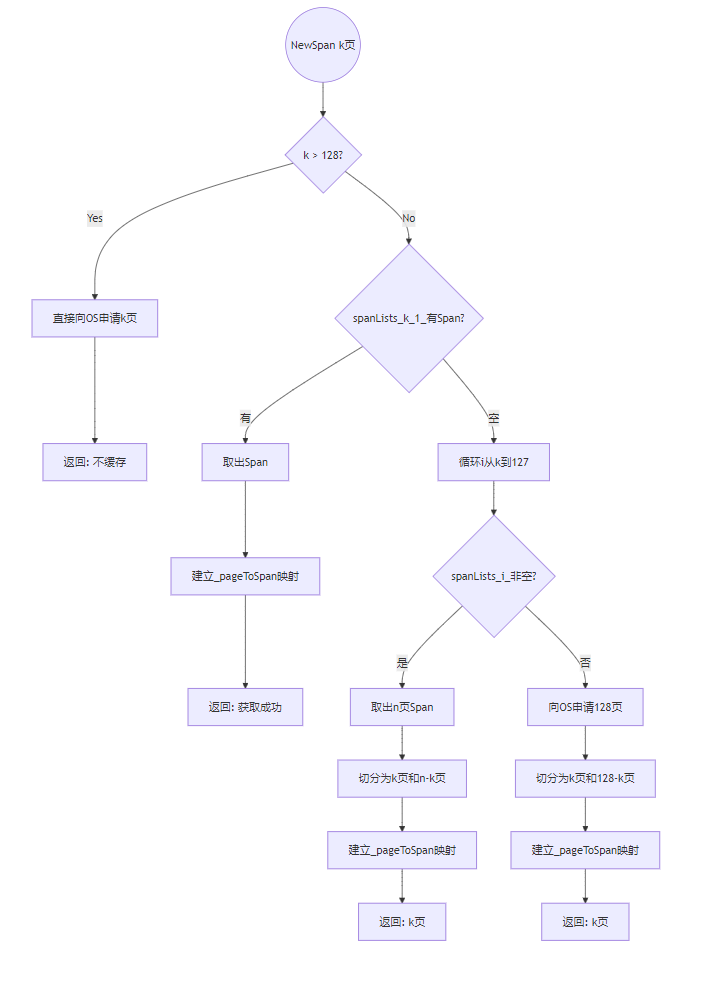
2.2 实现的四个分支
分支1:超大对象(k > 128)
if(k > 128){void* ptr = SystemAlloc(k);Span* span = new Span;span->_pageId = ((PAGE_ID)ptr) >> PAGE_SHIFT;span->_n = k;_pageMtx.unlock();return span; // 直接返回,不放入_spanLists
}
为什么不放入_spanLists?
- _spanLists只有128个位置,放不下更大的
- 超大对象很少被重复使用,缓存意义不大
- 直接申请、直接使用、直接释放回OS
分支2:有现成的k页Span
if(!_spanLists[k-1].Empty()){Span* kSpan = _spanLists[k-1].PopFront();// 建立页号到Span的映射(用于后续页合并)for(size_t i = 0; i < kSpan->_n; ++i){_pageToSpan[kSpan->_pageId + i] = kSpan;}_pageMtx.unlock();return kSpan;
}
为什么要建立_pageToSpan映射?
起初我直接返回了kSpan,结果被提醒:将来ReleaseSpanToPageCache需要页合并时,要根据页号快速找到Span。
映射建立的细节:
- 一个Span有n页,需要为每一页都建立映射
- 例如:3页的Span(页号100-102)需要建立3个映射
分支3:查找更大的Span并切分
for(size_t i = k; i < 128; ++i){if(!_spanLists[i].Empty()){Span* nSpan = _spanLists[i].PopFront();Span* kSpan = new Span;// 切分操作kSpan->_pageId = nSpan->_pageId;kSpan->_n = k;nSpan->_pageId += k; // 剩余部分的起始页号后移nSpan->_n -= k;_spanLists[nSpan->_n - 1].PushFront(nSpan);// 建立映射for(size_t j = 0; j < kSpan->_n; ++j){_pageToSpan[kSpan->_pageId + j] = kSpan;}_pageMtx.unlock();return kSpan;}
}
我犯的错误1:直接返回大Span
最开始我写的是:
Span* nSpan = _spanLists[i].PopFront();
return nSpan; // ❌ 需要3页却返回了5页
这会造成内存浪费。正确做法是切分。
我犯的错误2:在循环内申请OS内存
for(...){if(!_spanLists[i].Empty()){...}else{ // ❌ 每次循环都会进这里SystemAlloc(128); // 会被调用多次!}
}
这个逻辑错误很隐蔽:循环是为了查找,不是为了申请。申请应该放在循环外。
切分的数学推导:
假设有5页的Span(页号100),切分成3页 + 2页:
原Span: _pageId = 100_n = 5切分后:kSpan: _pageId = 100, _n = 3 ← 返回nSpan: _pageId = 103, _n = 2 ← 放回_spanLists[1]为什么页号是103?100(起始) + 3(用掉的) = 103(剩余的起始)
我犯的错误3:数组索引错误
最开始我写的是:
_spanLists[nSpan->_n].PushFront(nSpan); // ❌ 2页应该放哪里?
回忆索引映射:
_spanLists[0] → 存1页
_spanLists[1] → 存2页
所以剩余2页应该放到_spanLists[nSpan->_n - 1]。
分支4:所有链表都空,向OS申请128页
void* ptr = SystemAlloc(128);
Span* nspan = new Span;
nspan->_pageId = ((PAGE_ID)ptr) >> PAGE_SHIFT;
nspan->_n = 128;// 和分支3一样的切分逻辑
Span* kSpan = new Span;
kSpan->_pageId = nspan->_pageId;
kSpan->_n = k;nspan->_pageId += k;
nspan->_n -= k;_spanLists[nspan->_n - 1].PushFront(nspan);for(size_t j = 0; j < kSpan->_n; ++j){_pageToSpan[kSpan->_pageId + j] = kSpan;
}_pageMtx.unlock();
return kSpan;
我犯的错误4:创建了3个Span对象
最开始我写的是:
Span* nspan = new Span; // 128页
Span* kSpan = new Span; // k页
Span* remainSpan = new Span; // ❌ 多余!剩余的(128-k)页
其实修改nspan后,它就是剩余部分,不需要再new一个。
三、并发安全:加锁的坑
3.1 为什么每个return前都要解锁?
PageCache是全局单例,会被多个线程同时访问:
Span* NewSpan(size_t k) {_pageMtx.lock(); // 加锁if (k > 128) {...return span; // ❌ 如果不解锁,锁永远不会释放!}
}
死锁场景:
线程1调用NewSpan → 加锁 → 返回(忘记解锁)
线程2调用NewSpan → 尝试加锁 → 永远等待 ← 死锁!
正确做法:
if (k > 128) {..._pageMtx.unlock(); // ✅ 返回前必须解锁return span;
}
我数了数,NewSpan有4个return分支,每个都要记得解锁。
3.2 为什么不用RAII?
为什么不用std::lock_guard自动管理锁?
Span* NewSpan(size_t k) {std::lock_guard<std::mutex> lock(_pageMtx); // RAII// 不用手动unlock,离开作用域自动解锁
}
这确实是更好的做法,但目前为了清晰理解锁的机制,我们先手动管理。后续优化可以改成RAII。
四、编译错误排查
4.1 错误现象
g++ -c src/PageCache.cpp -o src/PageCache.o -std=c++11error: 'Span' does not name a type
error: 'PageCache' has not been declared
error: '_pageMtx' was not declared in this scope
4.2 排查过程
第一反应: 是不是没包含头文件?
检查PageCache.cpp:
#include "PageCache.h" // ✅ 有包含
检查PageCache.h:
#include "Common.h" // ✅ 有包含(Span定义在这里)
第二反应: 头文件保护有问题?
PageCache.h使用的是:
#ifndef _PAGE_CACHE_H_ // ← 下划线开头是保留标识符
#define _PAGE_CACHE_H_
...
#endif
C++标准规定:以下划线+大写字母开头的标识符是保留的,可能导致未定义行为。
解决方案: 改成#pragma once
#pragma once // ✅ 现代C++推荐#include "Common.h"
#include <unordered_map>
#include <mutex>
编译通过!
4.3 学到的知识点
-
头文件保护规范:
- ❌
#ifndef _NAME_H_(下划线开头) - ✅
#ifndef PROJECT_NAME_H(项目名开头) - ✅
#pragma once(最简洁,编译器支持)
- ❌
-
C++保留标识符:
- 以下划线+大写字母开头:
_Name - 包含双下划线:
__name - 全局命名空间中以下划线开头:
_name
- 以下划线+大写字母开头:
五、核心代码统计
5.1 PageCache.h(24行)
#pragma once#include "Common.h"
#include <unordered_map>
#include <mutex>class PageCache{
public:static PageCache* GetInstance(){static PageCache _sInst;return &_sInst;}Span* NewSpan(size_t k);void ReleaseSpanToPageCache(Span* span);private:PageCache(){}PageCache(const PageCache&)=delete;PageCache& operator=(const PageCache&)=delete;SpanList _spanLists[NPAGES];std::mutex _pageMtx;std::unordered_map<PAGE_ID, Span*> _pageToSpan;
};
5.2 PageCache.cpp NewSpan(104行)
核心逻辑:
- 超大对象处理(6行)
- 查找现成Span(8行)
- 切分大Span(20行)
- 申请OS内存并切分(15行)
六、今日收获
6.1 设计思想
- 批量预取策略: 一次申请128页,减少系统调用
- 页切分算法: 大Span切小Span,提高内存利用率
- 特殊对象处理: 超大对象不缓存,直接走OS
6.2 工程技巧
- 锁的正确使用: 每个return前必须解锁,避免死锁
- 映射建立时机: 分配Span时立即建立_pageToSpan映射
- 数组索引计算: n页的Span放在
_spanLists[n-1]
6.3 调试经验
- 编译错误排查: 头文件保护规范问题
- 逻辑错误定位: 切分算法的边界条件
- 内存管理: 避免创建多余的Span对象
七、遗留问题(TODO)
// PageCache.cpp
void PageCache::ReleaseSpanToPageCache(Span* span){// TODO: 实现页合并算法
}
八、思考题
- 为什么一次申请128页而不是更多(256页、512页)?
- 页合并的算法难点在哪里?
- 如果两个线程同时申请3页,会发生什么?
我的思考:
问题1:128页=1MB是一个平衡点
- 太小:频繁系统调用
- 太大:浪费内存(可能用不完)
- 1MB是经验值,适合大多数场景
问题2:页合并需要判断相邻页是否空闲
- 如何知道相邻页的页号?(前一页、后一页)
- 如何判断相邻页是否属于空闲Span?(用_pageToSpan查找)
- 如何合并?(修改Span的_n和_pageId,调整链表)
问题3:有锁保护,不会冲突
- 线程1先拿锁 → 获取3页Span → 解锁
- 线程2等待锁 → 获取另一个3页Span → 解锁
- 如果只剩一个3页Span,第二个线程会走切分或申请OS的逻辑
九、三层架构连通
NewSpan实现完成后,需要把三层真正连通起来,替换掉Day3的malloc模拟。
9.1 实现NumMovePage
这个函数用来计算:申请size大小的对象时,应该向PageCache申请几页。
设计思路:
小对象(如32字节):1页能切很多个,申请1页就够
大对象(如256KB):1页只有8KB,需要256/8=32页
简单实现(Common.h):
static inline size_t NumMovePage(size_t size) {// 简单策略:size小于8KB申请1页,否则向上取整size_t num = size / (1 << PAGE_SHIFT); // 除以8KBif (num == 0) num = 1; // 至少1页return num;// TODO: 后续优化可以考虑对象数量
}
为什么这么简单?
采用迭代开发思想:先用最简单的策略跑通,后续测试发现问题再优化。复杂的慢增长算法留到后面实现。
9.2 修改CentralCache调用PageCache
之前(Day3):
// TODO: 向PageCache申请Span(暂时用malloc模拟)
span = new Span;
span->_pageId = (PAGE_ID)malloc(8 * 1024) >> PAGE_SHIFT; // 固定1页
span->_n = 1;
现在(Day4):
// 向PageCache申请Span
size_t numPages = SizeClass::NumMovePage(size);
span = PageCache::GetInstance()->NewSpan(numPages);
关键改动:
- 计算需要几页:
NumMovePage(size) - 调用真实的PageCache:
PageCache::GetInstance()->NewSpan()
但这里有个隐藏的bug!
之前固定1页,切分时是这样写的:
size_t blockCount = (8 * 1024) / size; // 硬编码1页=8KB
现在可能是多页,需要修正:
size_t spanBytes = span->_n << PAGE_SHIFT; // 动态计算总字节数
size_t blockCount = spanBytes / size; // 能切多少块
例子:
- size=256KB,申请32页
- spanBytes = 32 << 13 = 262144字节
- blockCount = 262144 / 262144 = 1块 ✅
9.3 修改ThreadCache调用CentralCache
之前(Day2):
// TODO: 调用真正的CentralCache,当前用malloc模拟
for (int i = 0; i < 7; ++i) {void* obj = malloc(size);_freeLists[index].Push(obj);
}
void* returnObj = malloc(size);
return returnObj;
现在(Day4):
void* start = nullptr;
void* end = nullptr;// 从CentralCache批量获取8个对象
CentralCache::GetInstance()->FetchRangeObj(start, end, size, 8);// 把前7个Push到FreeList缓存
void* cur = start;
for (int i = 0; i < 7; ++i) {void* next = NextObj(cur);_freeLists[index].Push(cur);cur = next;
}// 返回第8个对象
return cur;
学到的知识点:
FetchRangeObj的参数void*& start是引用,可以修改调用者的变量- 返回链表用
start和end两个指针,O(1)时间复杂度 - 遍历链表用
NextObj辅助函数
三层调用时序图:
十、Bug发现与修复
10.1 第一次测试:大对象崩溃
编写了三层架构联调测试:
// 测试1:小对象(32字节)
void* ptr1 = GetTLSThreadCache()->Allocate(32); // ✅ 通过// 测试2:大对象(128KB)
void* bigPtr = GetTLSThreadCache()->Allocate(128 * 1024); // ❌ 崩溃
现象: 程序在分配128KB时卡住或崩溃
10.2 调试过程
步骤1:添加输出定位问题
void* FetchFromCentralCache(...) {cout << "调用FetchRangeObj" << endl;CentralCache::GetInstance()->FetchRangeObj(start, end, size, 8);cout << "开始遍历对象" << endl;for (int i = 0; i < 7; ++i) { // ← 崩溃在这里...}
}
步骤2:分析原因
128KB对象,申请16页Span:
spanBytes = 16 * 8KB = 128KB
blockCount = 128KB / 128KB = 1 ← 只能切1个对象!但ThreadCache期望拿7个:
for (int i = 0; i < 7; ++i) { ← 循环7次void* next = NextObj(cur); // 第2次:cur已经是nullptr,崩溃!
}
问题根源: 固定循环7次,但实际对象数量是动态的!
Bug前后对比:
10.3 解决方案
FetchRangeObj有返回值:实际获取的对象数量
size_t FetchRangeObj(void*& start, void*& end, size_t size, int num);
//^^^^^
//返回actualNum
修正代码:
// 获取实际数量
size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, size, 8);// 根据实际数量循环(actualNum-1个缓存,1个返回)
void* cur = start;
for (size_t i = 0; i < actualNum - 1; ++i) {void* next = NextObj(cur);_freeLists[index].Push(cur);cur = next;
}return cur; // 返回最后一个
测试结果:
测试2:分配大对象(128KB)
大对象分配成功 ✅bigPtr = 0x253d1412000
十一、测试设计与结果
11.1 测试设计思路
采用分层测试策略,从简单到复杂:
Level 1:单元测试(已完成)├─ test_common.cpp → SizeClass功能└─ test_threadcache.cpp → ThreadCache单独工作Level 2:集成测试(今天)└─ test_three_layers.cpp → 三层协作Level 3:压力测试(后续)└─ 多线程并发测试
为什么这样设计?
如果直接测三层,出问题很难定位。分层测试可以快速定位到是哪一层的问题。
测试流程图:
+---------------------+
| 开始测试 |
+---------------------+|v
+---------------------+
| 测试1:小对象32字节×3|
+---------------------+|+---> 分配成功? --否--> +---------------------+| | 失败:批量申请有问题 || +---------------------+|是|v
+---------------------+
| 测试2:大对象128KB |
+---------------------+|+---> 分配成功? --否--> +-----------------------------+| | 失败:NumMovePage或切分有问题 || +-----------------------------+|是|v
+---------------------+
| 测试3:释放全部对象 |
+---------------------+|+---> 释放成功? --否--> +---------------------+| | 失败:Deallocate有问题|| +---------------------+|是|v
+---------------------+
| 测试4:再次分配32字节|
+---------------------+|+---> 地址复用? --否--> +---------------------+| 警告:FreeList可能有问题|+---------------------+|是|v
+---------------------+
| 全部通过! |
+---------------------+
11.2 测试用例设计
// 测试1:小对象分配
void* ptr1 = GetTLSThreadCache()->Allocate(32);
void* ptr2 = GetTLSThreadCache()->Allocate(32);
void* ptr3 = GetTLSThreadCache()->Allocate(32);
验证点:
- 第1次:ThreadCache空 → CentralCache → PageCache → OS(申请1页)
- 第2次:从ThreadCache缓存拿(无锁)
- 第3次:从ThreadCache缓存拿(无锁)
预期: 3个不同地址
实际: ✅ ptr1/2/3都非空
// 测试2:大对象分配
void* bigPtr = GetTLSThreadCache()->Allocate(128 * 1024);
验证点:
- NumMovePage计算:128KB / 8KB = 16页
- PageCache::NewSpan(16)
- CentralCache切分:只能切1个对象
- ThreadCache只缓存0个,返回1个
预期: 返回有效地址
实际: ✅ bigPtr = 0x253d1412000
// 测试3:释放对象
GetTLSThreadCache()->Deallocate(ptr1, 32);
GetTLSThreadCache()->Deallocate(ptr2, 32);
GetTLSThreadCache()->Deallocate(ptr3, 32);
验证点: 内存回到ThreadCache的FreeList
FreeList状态(栈结构):
释放ptr1 → FreeList: ptr1
释放ptr2 → FreeList: ptr2 → ptr1
释放ptr3 → FreeList: ptr3 → ptr2 → ptr1
// 测试4:内存复用
void* ptr4 = GetTLSThreadCache()->Allocate(32);
if (ptr4 == ptr3) {cout << "成功复用!" << endl;
}
验证点: Pop栈顶元素,应该是ptr3
预期: ptr4 == ptr3
实际: ✅ 0x253d14100a0 == 0x253d14100a0
11.3 测试结果表格
| 测试项 | 输入 | 预期输出 | 实际输出 | 状态 | 验证功能 |
|---|---|---|---|---|---|
| 小对象分配 | Allocate(32)×3 | 3个不同地址 | ptr1/2/3非空 | ✅ | 批量申请机制 |
| 大对象分配 | Allocate(128KB) | 有效地址 | 0x253d1412000 | ✅ | 多页申请+动态切分 |
| 内存释放 | Deallocate×4 | 无异常 | 正常完成 | ✅ | FreeList Push |
| 内存复用 | 再次Allocate(32) | ptr4==ptr3 | 地址相同 | ✅ | FreeList Pop |
11.4 调试技巧总结
当集成测试失败时:
-
分层定位
cout << "进入Allocate" << endl; cout << "调用FetchFromCentralCache" << endl; cout << "调用FetchRangeObj" << endl; -
查看中间值
cout << "actualNum = " << actualNum << endl; cout << "blockCount = " << blockCount << endl; -
断言验证假设
assert(blockCount > 0); assert(actualNum > 0); -
分离测试
- 先单独测PageCache
- 再测CentralCache+PageCache
- 最后测完整三层
十二、今天的收获
完成的功能:
PageCache基本实现完了,NewSpan可以正常工作,能够切分大页、批量申请内存。NumMovePage虽然现在实现得比较简单,但先这样跑通了再说,后面有问题再优化。
三层架构终于连起来了!之前Day3用的malloc模拟,现在替换成真正调用PageCache了。ThreadCache也改成调用真实的CentralCache。测试都通过了,小对象和大对象都能正常分配。
踩过的坑:
循环那里栽了,一开始写死循环7次,结果大对象时只返回1个就崩了。后来才想起来应该用actualNum这个返回值。还有blockCount那里也是,硬编码8KB导致多页时计算错了。这些都是不够细心导致的。
学到的东西:
单例模式用得比较熟练了,PageCache和CentralCache都是这个模式。批量预取这个思想挺好的,一次申请128页虽然看起来多,但系统调用成本一样,还能减少后续申请次数。
分层测试确实有用,一开始直接测三层出问题很难定位,现在知道要先单独测每一层。还有就是用返回值控制循环比硬编码靠谱多了。
调试的时候加cout输出定位问题很管用,虽然有点笨但很有效。看到中间值就能分析出哪里错了。
还没做的事:
- NumMovePage现在太简单了,后面要加慢增长算法
- ThreadCache释放太多时要批量还给CentralCache,这个还没实现
- PageCache的页合并算法,这个留到后面做
- 多线程测试还没做
- 性能对比测试也得做
Git提交:
commit b5581ae: 实现PageCache的NewSpan功能
commit 2dc853a: 三层架构连通,实现NumMovePage函数
commit 19c0caf: 修复大对象分配崩溃问题
十三、一些思考
今天花了大概4个小时,设计和编码2小时左右,调试测试1小时,写文档1小时。
迭代开发这个思路确实好用,一开始想把NumMovePage写得很完美,后来想想先简单实现跑通再说,果然快很多。调试时也是,分层定位问题比一股脑全测要高效。
下一步打算实现页合并算法,还有ThreadCache批量归还。页合并感觉会比较难,要判断相邻页是否空闲,还要处理合并后的链表。先研究一下再说吧。
项目地址: https://github.com/Guojin06/HighConcurrencyMemoryPool