Linux网络之----序列化和反序列化
1.序列化和反序列化
序列化是指将数据结构或对象转换为一种可以存储或传输的格式的过程。这个过程通常将数据转换为字节流、字符串或其他通用格式,以便可以将其写入文件、存储到数据库或通过网络传输。
反序列化是序列化的逆过程,即将存储或传输的格式还原为原始数据结构或对象的过程。这个过程将字节流、字符串或其他通用格式的数据解析为原始的数据结构或对象。
一张图简明的说明一下:
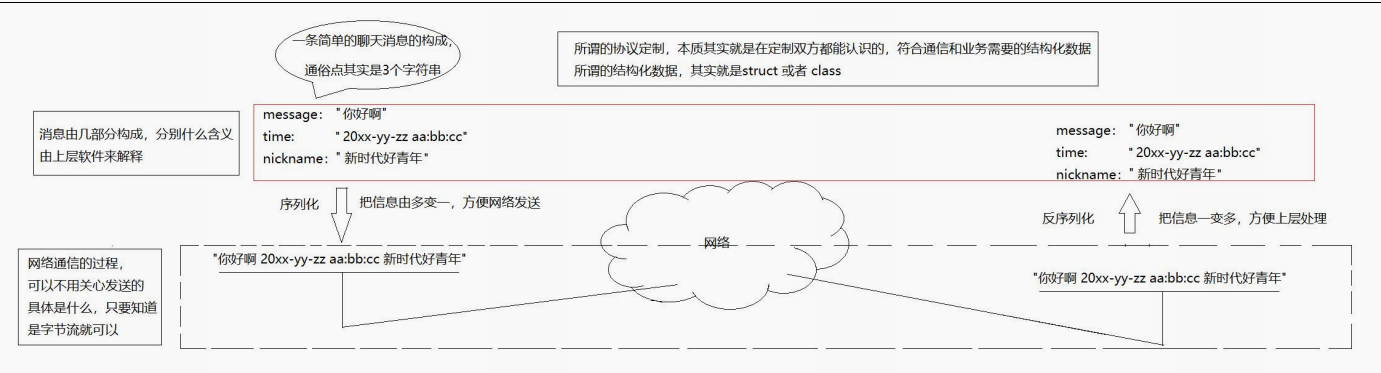
就好比我们要实现一个网络版的计算器,之后我们定义了这样一个结构体:
struct cal
{int x;int y;char oper;
};你怎么保证将这个结构体(假设是在A主机上)传递到B主机上呢?而且还要保证这两台主机都能认识你写的这玩意,要不也没办法实现计算功能啊,好,这就是我们本篇博客要讨论的问题!
2. Jsoncpp
2.1 简介
JSONCPP 是一个用于处理 JSON 数据的 C++ 库。它提供了方便的 API,用于解析、生成和操作 JSON 数据。它提供了将 JSON 数据序列化为字符串以及从字符串反序列化为 C++ 数据结构的功能。Jsoncpp 是开源的,广泛用于各种需要处理 JSON 数据的 C++ 项目中。
2.2 安装
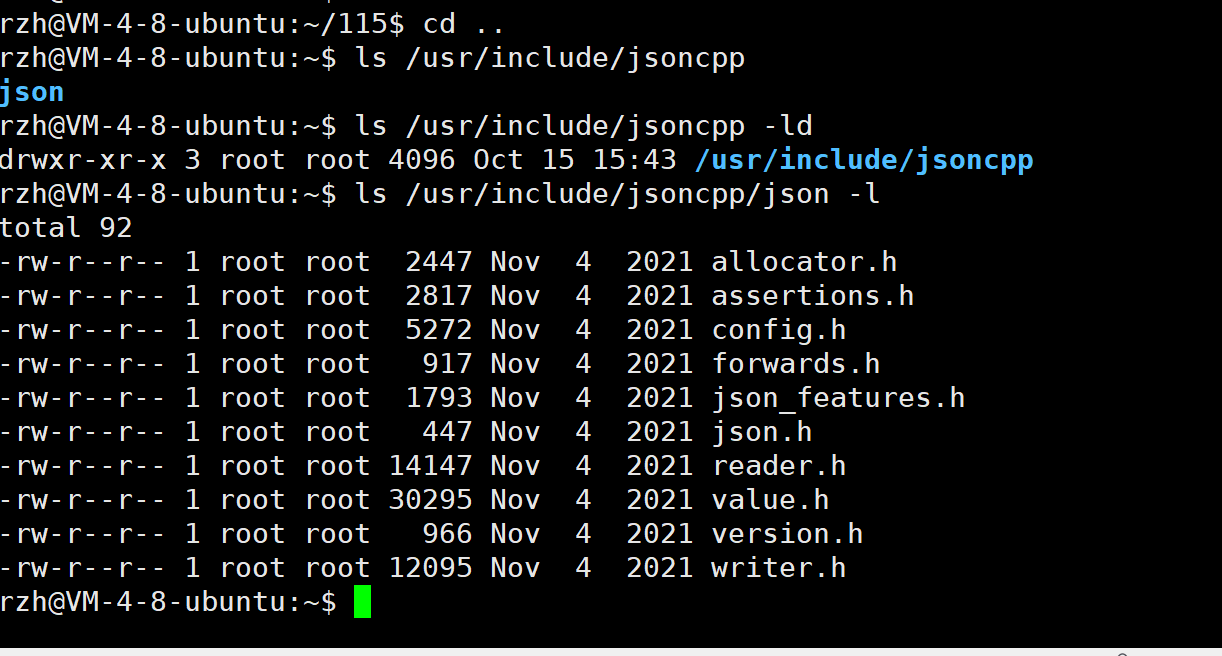
安装好了我们看一下,这里我们只用json.h文件,但是其不在include路径下,所以我们在#include时,要注意把其路径带上~
2.3 序列化
首先我们要知道jsoncpp里面的数据是通过“键值对”来存储的,这也说明了为什么它能进行序列化和反序列化这一互逆的操作。
2.3.1 toStyledString()
我们先来简单体验一下:
#include <iostream>
#include<string>
#include<jsoncpp/json/json.h> //这里我们要注意一下,大多数默认都是include目录下的//但是json.h不是这个路径,需要我们指明路径
using namespace std;
int main()
{Json::Value root;root["name"]="zs";root["age"]=17;root["sex"]="男";string s=root.toStyledString();cout<<s<<endl;return 0;
} 在写makefile时要注意,这里是要外部链接库的,应该加上-l库名,我第一次编译的时候没有加导致出现了这个问题
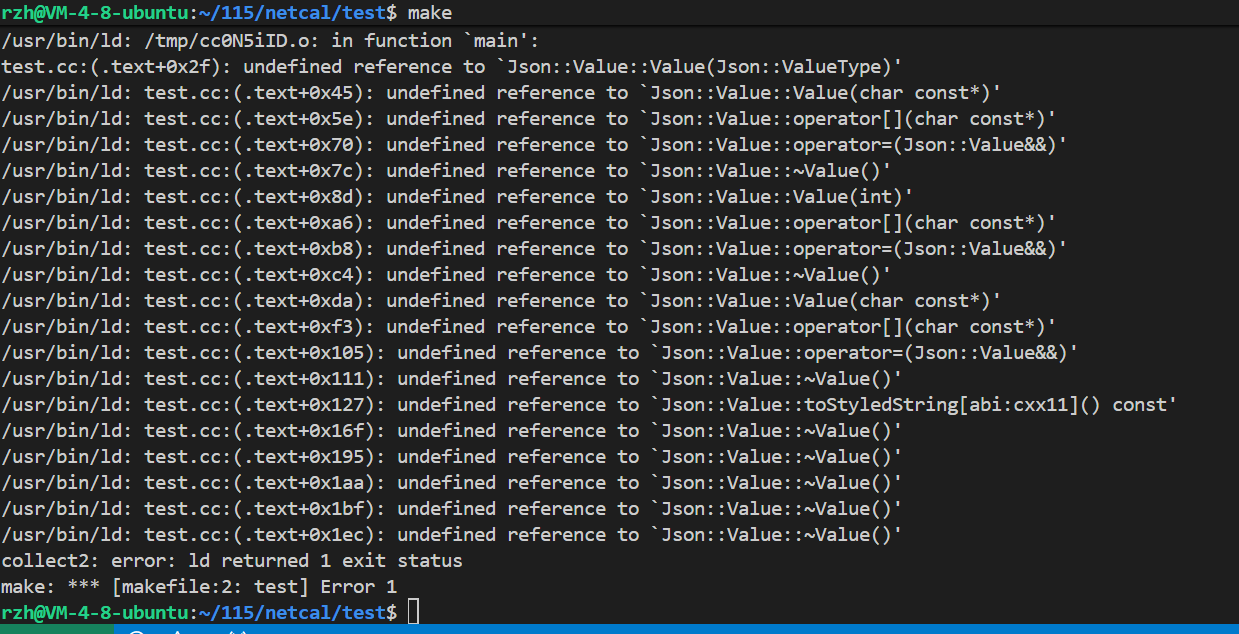
makefile文件应该这样写:
test:test.ccg++ -o $@ $^ -ljsoncpp
.PHONY:clean
clean:rm -f test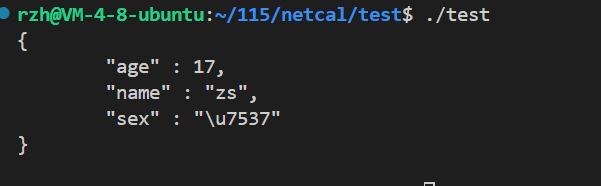
输出这种结构的结果是因为我们用了toStyledString()函数,
2.3.2 StreamWriter
#include<iostream>
#include<string>
#include<sstream>
#include<memory>
#include<jsoncpp/json/json.h>
using namespace std;
int main()
{Json::Value root;root["name"]="zs";root["age"]=17;root["sex"]="man";Json::StreamWriterBuilder wbuilder; //StreamWriter的工厂unique_ptr<Json::StreamWriter> writer(wbuilder.newStreamWriter());stringstream ss;writer->write(root,&ss);cout<<ss.str()<<endl;return 0;
}运行结果:
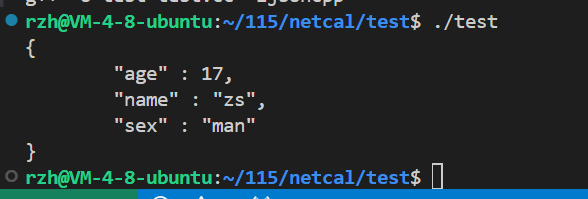
2.3.3 FastWriter
#include<iostream>
#include<string>
#include<sstream>
#include<jsoncpp/json/json.h>
using namespace std;
int main()
{Json::Value root;root["name"]="john";root["age"]=17;root["sex"]="man";Json::FastWriter writer;string s=writer.write(root);cout<<s<<endl;return 0;
}运行结果:

我们惊奇的发现没有那个结构了,但是把fastwriter改成styledwriter在看看呢?其余不变
运行结果:
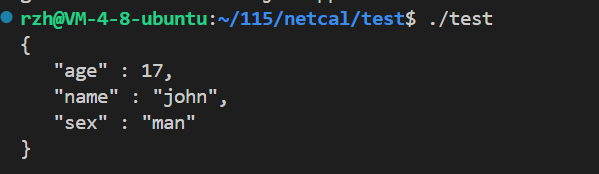
2.3.4 对比
2.4 反序列化
#include <iostream>
#include <string>
#include <sstream>
#include <memory>
#include <jsoncpp/json/json.h>
using namespace std;
int main()
{// 序列化Json::Value root;root["name"] = "zs";root["high"] = 1.78f;root["sex"] = "男";Json::StyledWriter writer;string s=writer.write(root);cout<<s;//反序列化Json::Value droot;Json::Reader reader;reader.parse(s,droot);//将JSON格式的字符串解析(反序列化)成Json::Value 对象//从 droot 对象中提取键为 "name" 的值,并将其转换为 std::string 类型string name=droot["name"].asString();float high=droot["high"].asFloat();string sex=droot["sex"].asString();cout<<name<<endl;cout<<high<<endl;cout<<sex<<endl;return 0;
}运行结果:
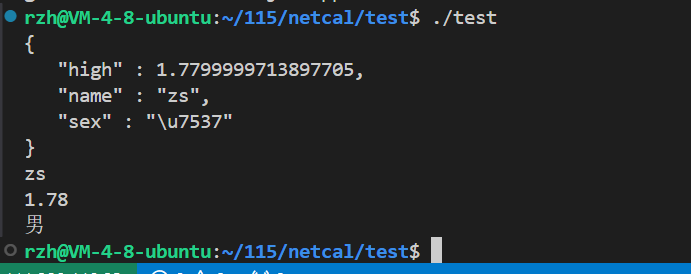
3.前台进程和后台进程
3.1 前台进程
前台进程通常与用户直接交互,它们在终端或控制台上运行,并且可以接收用户的输入和向用户显示输出。如下图的命令就是前台进程

3.2 后台进程
后台进程是指那些不需要与用户直接交互的进程。它们在后台运行,执行任务而不需要用户的即时输入。后台进程,不影响bash,用户可以在进程运行期间,继续访问Linux
3.3 查看进程状态
1)jobs
这个是正在运行中的后台程序

这个是运行完的后台程序

我们在多加几个,Jobs一下看看
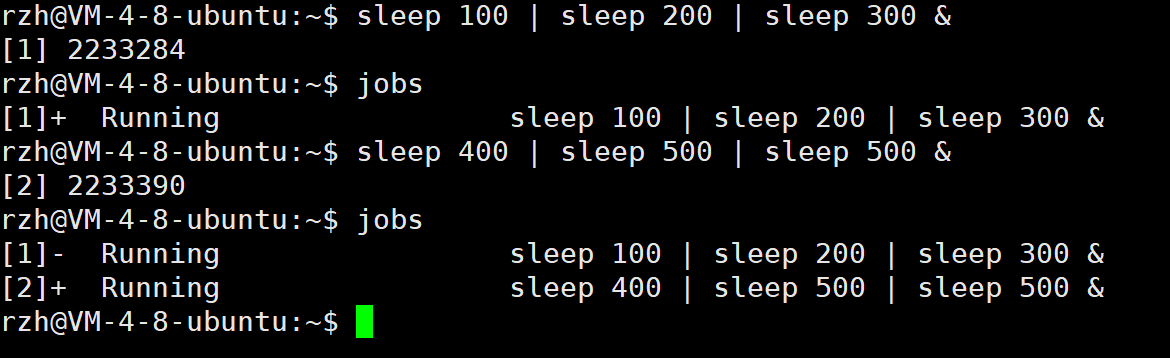
接下来,我们换一个方式再查看一下
2)ps axj
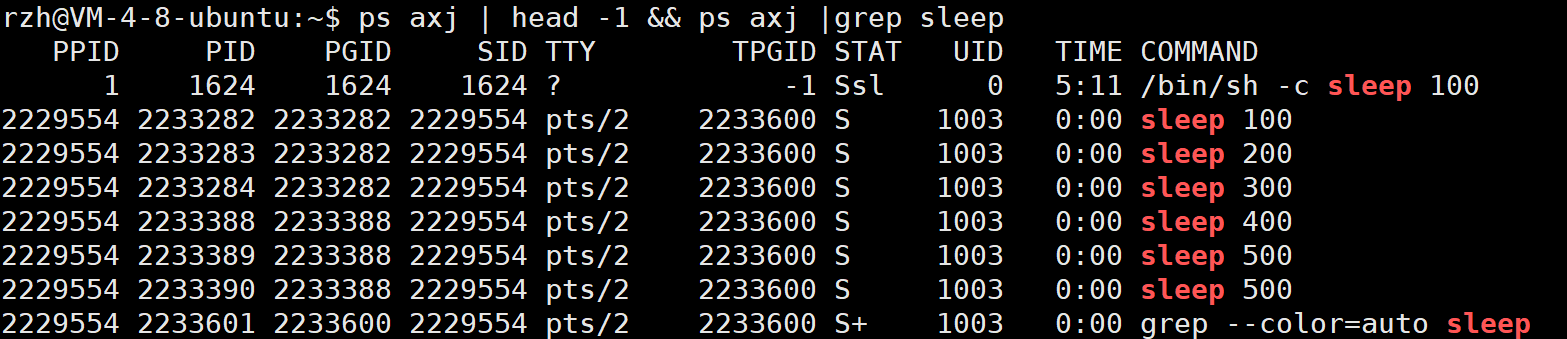
仔细观察这个表,我们将介绍一个新的概念,叫做进程组
3)后台切换前台
使用fg命令可以将最近的后台进程切换到前台
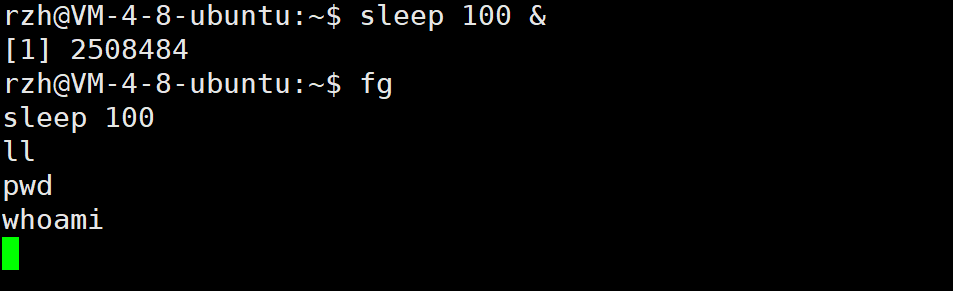
4)前台切换后台
在前台进程正在运行时,可以按下Ctrl+Z组合键将其挂起(暂停),然后使用bg命令将其移至后台继续运行
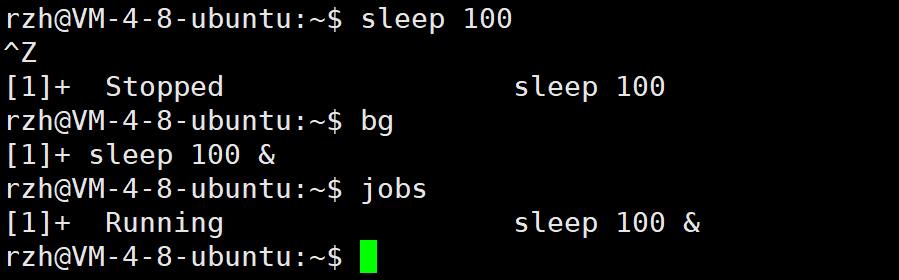
3.4 进程组
我们还是看上面那个图,会发现有个PGID,那个就是进程组,发现其有两组,一组编号为2233282,另一组编号为2233388,而且每组的PGID都与该组的第一个PID值相同,这个就是我们在数值上先了解一下进程组!
3.4.1 进程组的定义
进程组是操作系统中用于管理多个相关进程的一种机制。它是由一个或多个进程组成的集合。在操作系统中,进程是程序执行的实例,而进程组则是将这些进程按照一定的逻辑关系组织起来,方便操作系统进行统一的管理和调度。
3.4.2 进程组标识符(PGID)
每个进程组都有一个唯一的标识符,称为进程组标识符(PGID)。PGID是一个非负整数。在很多操作系统中,进程组的创建者(创建进程组的第一个进程)的进程标识符(PID)会被用作该进程组的PGID。例如,如果进程A创建了一个新的进程组,并且它的PID是1234,那么这个新进程组的PGID可能就是1234。
3.4.3 前后台进程组的特点
我们先输出一个结论:一个会话中,只允许有一个前台进程组(任务),可以同时存在多个进程组任务
下面我们来讨论一个问题:
1)Q:我们知道在linux中,bash 作为一个命令行解释器,是一种常用的 shell,那他是不是前台进程组呢?
A:在 Linux 系统中,默认情况下,bash 并不是作为前台进程组,而是作为前台进程组中的一个进程。也就是说,当你登录到一个 Linux 系统时,bash 通常会被启动作为一个交互式的 shell。bash 本身是一个进程,它会创建一个进程组,并且 bash 进程通常是这个进程组的组长,并且这个进程组会成为前台进程组。在这个 bash 会话中,你也可以运行其他命令,这些命令会作为子进程运行在同一个进程组中。例如,当你在 bash 中运行 ls 命令时,ls 命令会作为子进程运行在 bash 所在的进程组中。
那么我下一个问题就是,前面既然说了一个会话中只能有一个前台进程组,那是不是就是说bash变为后台进程了呢?抽象总结一下就是:
Q:假如我现在输入ls命令,那现在的前台进程是bash还是ls
A:首先给出答案!bash 并没有变成后台进程。它仍然是前台进程组的一部分,只是在 ls 命令执行期间,ls 进程是当前与终端交互的前台进程。下面可以详细解释一下:当你在 bash 中输入 ls 命令并按下回车时,bash 会执行以下操作:
1)创建子进程:bash 会调用 fork() 系统调用创建一个子进程。
2)执行 ls:子进程会调用 exec() 系统调用,将子进程的代码替换为 ls 程序的代码。
3)进程组管理:子进程会继承父进程的进程组(即 bash 所在的进程组)。因此,ls 进程会属于 bash 所在的进程组。
在 ls 命令执行期间,ls 进程会成为前台进程。这是因为 ls 进程是当前与终端交互的进程,它会读取终端的输入(虽然 ls 通常不需要输入)并将输出写入终端。但是,bash 进程并没有变成后台进程。bash 进程仍然在前台进程组中,只是它暂时让出了对终端的控制权,让 ls 进程可以与终端交互。当 ls 命令执行完毕后,ls 进程会退出。bash 进程会接收到子进程退出的信号(如 SIGCHLD),并恢复对终端的控制,继续等待用户输入。
说人话就是我们可以把这个会话看作一个团体,其里面有很多小团体,但是这个大团体只能有一个小团体来控制(可以类比为专政),但是在这个小团体里面还有老大,老二,老三等等,在ls命令输入后,就相当于原来的老大宣布暂时退位了,由组内的其他人来上位,之后等这个事情执行完之后,原来的老大就又回来了!恢复对原来的小团体的控制!可以简单的这样理解~
3.4.4 对上述结论的理解
我们再来详细说一下上面那个红色字的理解,其表明前台进行组是具有唯一性的,即在任何给定时刻,一个终端只能有一个前台进程组。这个进程组可以包含多个进程,但只有一个进程可以与终端直接交互。当你运行 ls 命令时,ls 进程会成为前台进程,但 bash 进程仍然在前台进程组中。bash 进程并没有变成后台进程,它只是暂时让出了对终端的控制权。bash 进程在运行 ls 命令期间仍然是前台进程组的一部分,但它不会与终端交互。bash 进程会等待 ls 进程完成,然后恢复对终端的控制。
那么我再来解释一下为什么一个会话中,只允许有一个前台进程组,原因就是不管是前台还是后台,都可以向终端文件进行写入的,但是只有前台进程,能够从标准输入(终端文件)中获取数据!而前台进程的一个主要职责就是和用户进行交互,需要获取用户的标准输入,而标准输入只有一个,所以前台进程也必须只能有一个,这也解释了为什么我们的ctrl+c只能终止我们的前台进程
3.5 会话
会话是比进程组更高一级的进程组织结构。一个会话可以包含一个或多个进程组。会话的创建通常与用户登录有关。例如,当用户登录到一个Unix系统时,会创建一个新的会话,这个会话会包含用户启动的所有进程组。
3.6 守护进程
3.6.1 定义
守护进程是一种在后台运行的进程,通常用于执行特定的任务,如系统服务、网络服务等。它们不会直接与用户交互,而是在后台持续运行,提供各种服务。守护进程通常在系统启动时启动,并在系统关闭时停止。
3.6.2 创建
守护进程通过调用 fork() 创建一个子进程,然后父进程退出,留下子进程继续执行。换句话说,守护进程不就是孤儿进程吗!!!接着,子进程调用 setsid() 创建一个新的会话,这样守护进程就成为了这个新会话的会话首进程,同时也是这个新进程组的组长。
之后守护进程通过 setsid() 创建一个新的会话,这样它就不再与任何控制终端关联,从而可以在后台运行,不受用户登录和注销的影响。
所以从另外的角度讲,自成进程组,自成会话的进程组,或者作业叫做守护进程
而守护进程在创建的时候,需要通过chdir("/") 将工作目录改变为根目录,防止守护进程占用某个特定的文件系统。
3.6.3 相关函数
1)setsid()函数
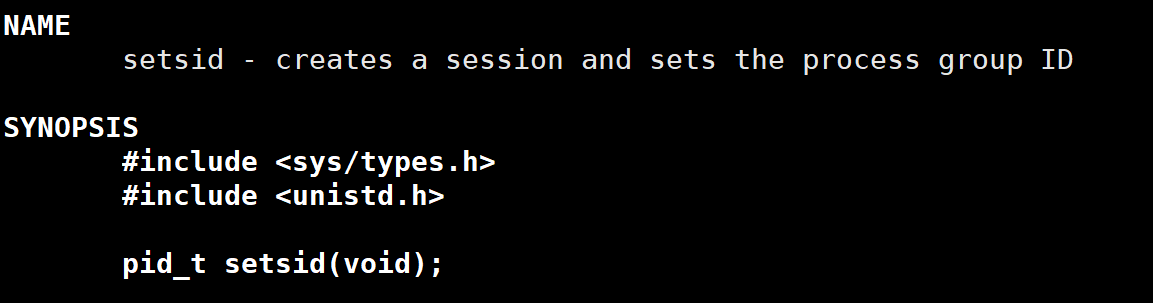
描述

返回值

网络版计算器任务
现在,我们有一个任务,要求我们设计一个计算器,网络版的,我们先来构思一下,既然是网络版,就说明我们要进行传输,所以我们介绍的Json字符串就有大用了,之后我们还要写一个网络传输的协议,因为我们要保证两台主机之间都能看得懂我们传递的数据,这样才能计算,那我们就先写一个协议的代码文件吧!
在网络中,我们是有请求和应答的,所以我们可以设计两个类,Request类和Respond类,在这两个类里面都要进行数据的序列化和反序列化,其中序列化的参数要都是输出型参数,因为我们序列化之后要将数据发出,那么反序列化的参数就是输入性参数,获取网络中来的数据
之后就可以进行设计我们的协议类了,中心思想是提供用于打包和解包JSON字符串的静态方法,其中每个JSON字符串都以它的长度作为前缀,长度和JSON字符串之间用特定的分隔符(sep)隔开。
首先是打包函数,设计方法如下:
1)Package 方法接收一个JSON字符串,如果字符串为空,则返回空字符串。
2)如果字符串不为空,方法会计算字符串的长度,并将长度转换为字符串格式。
3)然后,它将长度字符串、分隔符、原始JSON字符串和另一个分隔符连接起来,形成一个新的打包字符串。
之后是解包函数,设计方法如下:
1)Unpack 方法接收一个从网络中读取的原始字符串和一个指向字符串的指针,用于输出解包后的JSON字符串。
2)方法首先检查输出参数是否为空,如果为空则返回0。
3)然后,它在原始字符串中查找分隔符的位置,如果找不到,说明没有完整的报文,返回0。找到分隔符后,它提取出报文长度的字符串,并使用 DigitSafeCheck 方法检查这个长度字符串是否只包含数字。
4)如果长度字符串不安全(包含非数字字符),方法返回-1,表示错误。如果长度字符串安全,它将长度字符串转换为整数,并计算出完整报文的预期长度。如果原始字符串的长度小于预期长度,说明报文不完整,返回0。
5)如果原始字符串包含完整的报文,方法提取出JSON字符串,并从原始字符串中移除这个报文。最后,方法返回解包后的JSON字符串的大小。
protocol.hpp
#pragma once#include <iostream>
#include <string>
#include <jsoncpp/json/json.h>using namespace std;class Request
{
public:Request(){_x = _y = _oper = 0;}// 序列化对象bool Serialize(string *out){// 1. 手写 "_x" "_oper" "_y" --- 字符串拼接转换// 2. 现成工具Json::Value root;root["x"] = _x;root["y"] = _y;root["oper"] = _oper;Json::StyledWriter writer;*out = writer.write(root);if (out->empty())return false;return true;}// 反序列化对象bool Deserialize(string &in){Json::Reader reader;Json::Value root;bool ret = reader.parse(in, root);if (!ret)return false;_x = root["x"].asInt();_y = root["y"].asInt();_oper = root["oper"].asInt(); // ASCII码对应的return true;}int X(){return _x;}int Y(){return _y;}char Oper(){return _oper;}~Request(){}public:int _x;int _y;char _oper;
};class Response
{
public:Response(): _result(0), _code(0){}// 序列化对象bool Serialize(string *out) //参数是一个输出流{Json::Value root;root["result"] = _result;root["code"] = _code;Json::StyledWriter writer;*out = writer.write(root);if (out->empty())return false;return true;}// 反序列化对象 bool Deserialize(string &in) //参数是一个输入流{Json::Reader reader;Json::Value root;bool ret = reader.parse(in, root);if (!ret)return false;_result = root["result"].asInt();_code = root["code"].asInt();return true;}void SetResult(int r){_result = r;}void SetCode(int c){_code = c;}void Print(){cout << _result << "[" << _code << "]" << endl;}~Response(){}private:int _result; // 计算结果int _code; // 可信度码,防止除0时候结果错误但是还输出了
};static const string sep = "\r\n";
// 基本的请求与应答写完了,现在可以写协议了
class Protocol
{
public:static string Package(const string &jsonstr) // 打包{// jsonstr -> len\r\njsonstr\r\nif (jsonstr.empty())return string(); // 返回一个空的 string 对象string json_length = to_string(jsonstr.size());return json_length + sep + jsonstr + sep;}static bool DigitSafeCheck(const string str){for (int i = 0; i < str.size(); i++){if (!(str[i] >= '0' && str[i] <= '9'))return false;}return true;}// len\r\njsonstr\r\n// len\r\njsonstr\r\nlen\r\njsonstr\r\n// len\r\njsonstr\r\nlen\r// len\r\n// len\r\njs// len\r// len// origin_str: 从网络中读取上来的字符串,输入输出// package: 输出参数,如果有完整的json报文,就返回static int Unpack(string &origin_str, string *package) //第二个参数为输出型参数{//要解包的每个JSON字符串都以它的长度作为前缀,//长度和JSON字符串之间用特定的分隔符(sep)隔开。//由于传输可能有只传了一半或者没传的情况,所以要讨论一下if (!package)return 0;auto pos = origin_str.find(sep);if (pos == string::npos)return 0;// 至少说明,我们收到了一个报文的长度string len_str = origin_str.substr(0, pos); //获取长度字符串(数字组成的字符串)if (!DigitSafeCheck(len_str)){return -1;}int digit_len = stoi(len_str); //len_str为长度字符串,// 如果我得到了当前报文的长度// 根据协议,我可以推测出,一个完整报文的长度是多少int target_len = len_str.size() + digit_len + 2 * sep.size();//预期收到的报文串长度if (origin_str.size() < target_len)return 0;///////////////上面的逻辑,我们对origin_string都没做/////////////////// 我保证,origin_str内部,一定有一个完整的报文请求!*package=origin_str.substr(pos+sep.size(),digit_len);origin_str.erase(0,target_len);return package->size();}
};之后我们还要设置一个文件,用于解析我们从网络上收获到的报文,我们的解析工作主要分为以下几个步骤来进行:
1. 解析报文2. 反序列化3. 根据req->response, 具体的业务(这里可以使用回调函数)4. 对resp在进行序列化5. 打包
总结起来就是从输入缓冲区中解析报文,反序列化请求,调用业务处理函数生成响应,序列化响应,并将响应报文打包返回。它通过循环处理输入缓冲区中的所有完整报文,确保每个报文都能被正确解析和处理。
Parser.hpp
#pragma once
#include "Protocol.hpp"
#include "Logger.hpp"
#include <string>
#include <functional>using namespace std;
using handler_t = function<Response(Request &req)>;
// 只负责对报文进行各种解析工作
// 对解析出来的请求和应答,Parser不归你处理
class Parser
{
public : Parser(handler_t handler):_handler(handler){}string Parse(string& inbuffer) //进行解析工作{LOG(LogLevel::DEBUG)<< "inbuffer: \r\n" << inbuffer;string send_str;while(true){string jsonstr;// 1. 解析报文int n=Protocol::Unpack(inbuffer,&jsonstr);if(n<0)exit(0);else if(n==0)break;// 我已经将inbuffer所有完整报文处理完毕else{LOG(LogLevel::DEBUG)<<"jsonstr: \r\n" << jsonstr;Request req;// 2. 反序列化if(!req.Deserialize(jsonstr)){return string();}// 3. 根据req->response, 具体的业务Response resp=_handler(req);// 4. 对resp在进行序列化string resp_json;if(!resp.Serialize(&resp_json)){return string();}// 5. 打包send_str+=Protocol::Package(resp_json);}}return send_str;}~Parser(){}
private:handler_t _handler;
};之后是计算器类,这里我们要实现几种运算方法,这里我们直接给出代码
Calculator.hpp
#pragma once
#include <iostream>
#include <string>
#include "Protocol.hpp"class Calculator
{
public:Calculator() {}Response exec(Request &req){Response resp;switch (req.Oper()){case '+':resp.SetResult(req.X()+req.Y());break;case '-':resp.SetResult(req.X()-req.Y());break;case '/':if(req.Y()==0)resp.SetCode(1); //1:除0错误resp.SetResult(req.X()/req.Y());break;case '*':resp.SetResult(req.X()*req.Y());break;case '%':if(req.Y()==0)resp.SetCode(2);// 2: 模0错误resp.SetResult(req.X()%req.Y());default:resp.SetCode(3);// 3: 非法操作break;}return resp;}~Calculator(){}
};之后是套接字文件,这里我们可以设置为基类和子类的方式,这样只要我们需要的话,也可以实现UDP的代码,但是这里还是写TCP了!!
我们可以在抽象基类Socket中定义一系列纯虚函数,用于实现Socket的基本操作:创建套接字、
绑定套接字到指定端口、监听套接字、接受客户端连接、获取套接字文件描述符、关闭套接字、接收数据、发送数据、连接到服务器。
之后再派生类TCPTcpSocket中进行虚函数的重写,代码如下:
socket.hpp
#ifndef __SOCKET_HPP__
#define __SOCKET_HPP__#include <iostream>
#include <string>
#include <unistd.h>
#include <cstdlib>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <memory>
#include "InetAddr.hpp"
#include "Logger.hpp"enum
{OK,CREATE_ERROR,BIND_ERROR,LISTEN_ERROR
};
static int gbacklog = 16;
static const int gsockfd = -1;class Socket
{
public:virtual ~Socket() {}virtual void CreateSockOrDie() = 0;virtual void BindSocketOrDie(int port) = 0;virtual void ListenSocketOrDie(int backlog) = 0;virtual shared_ptr<Socket> Accept(InetAddr *clientaddr) = 0;virtual int SockFd() = 0;virtual void Close() = 0;virtual ssize_t Recv(string *out) = 0;virtual ssize_t Send(const string &in) = 0;virtual bool Connect(InetAddr &peer) = 0;// 其他接口
public:void BuildListenSocketMethod(int _port){CreateSockOrDie();BindSocketOrDie(_port);ListenSocketOrDie(gbacklog);}void BuildClientSocketMethod(){CreateSockOrDie();}
};class TcpSocket : public Socket
{
public:TcpSocket(int sockfd=gsockfd):_sockfd(sockfd){}void CreateSockOrDie() override{_sockfd=socket(AF_INET,SOCK_STREAM,0);if(_sockfd<0){LOG(LogLevel::FATAL) << "create socket error!";exit(CREATE_ERROR);}LOG(LogLevel::INFO) << "create socket success!";}void BindSocketOrDie(int port) override{InetAddr local(port);if(bind(_sockfd,local.Addr(),local.Length())!=0){LOG(LogLevel::FATAL) << "bind socket error!";exit(BIND_ERROR);}LOG(LogLevel::INFO)<<"bind socket success!";}void ListenSocketOrDie(int backlog) override{if(listen(_sockfd,backlog)!=0){LOG(LogLevel::FATAL) << "listen socket error!";exit(LISTEN_ERROR);}LOG(LogLevel::INFO) << "listen socket success!";}shared_ptr<Socket> Accept(InetAddr *clientaddr) override{struct sockaddr_in peer;socklen_t len=sizeof(peer);int fd =accept(_sockfd,(struct sockaddr*)&peer,&len);if(fd<0){LOG(LogLevel::WARNING) << "accept socket error!";return nullptr;}LOG(LogLevel::INFO) << "accept socket success!";clientaddr->Init(peer);return make_shared<TcpSocket>(fd);}int SockFd() override{return _sockfd;}void Close() override{if(_sockfd>=0)close(_sockfd);}// 今天重点放在读,通过读,理解序列和反序列和自定义协议的过程ssize_t Recv(string *out) override{// 只读一次char buffer[1024];ssize_t n=recv(_sockfd,buffer,sizeof(buffer)-1,0);if(n>0){buffer[n]=0;*out+=buffer;}return n;}ssize_t Send(const string &in){//也有问题return send(_sockfd,in.c_str(),in.size(),0);}bool Connect(InetAddr &peer)override{int n=connect(_sockfd,peer.Addr(),peer.Length());if(n>=0)return true;elsereturn false;}~TcpSocket(){}
private:int _sockfd;
};
#endif随后就是TCP的服务端文件了,用于处理请求,我们可以这样,创建一个字符串inbuffer用于存储接收到的数据。使用while(true)循环不断接收数据,直到客户端关闭连接或发生错误。调用sockfd->Recv(&inbuffer)接收数据,根据返回值n处理不同情况:n > 0:成功接收到数据,调用回调函数_cb(inbuffer)处理数据,生成响应字符串send_str,并发送响应。n == 0:客户端关闭连接,退出循环。n < 0:读取错误,退出循环。最后关闭套接字。
TcpServer.hpp
#pragma once#include <memory>
#include <unistd.h>
#include <signal.h>
#include <functional>
#include "Socket.hpp"
#include "InetAddr.hpp"using namespace std;
using callback_t = function<string(string &)>; //&输入输出// TcpServer : 只负责进行IO
class TcpServer
{
public:TcpServer(int port, callback_t cb): _port(port), _cb(cb),_listensocket(make_unique<TcpSocket>()){_listensocket->BuildListenSocketMethod(_port);}void HandlerRequest(shared_ptr<Socket> sockfd, InetAddr addr){// 长服务string inbuffer; // 字节流式的队列while (true){ssize_t n = sockfd->Recv(&inbuffer);if (n > 0){// 都必须和协议有关!!!// 1. 你怎么知道inbuffer里面有至少一个完整的报文呢?// 2. 如何把这个完整的报文,交给上层呢?// 3. 上层拿到了一个报文,该如何处理呢??LOG(LogLevel::DEBUG) << addr.ToString() << "# " << inbuffer;// 如何处理(检测? 解包? 序列..)收到的数据,和底层tcpserver没有关系string send_str = _cb(inbuffer);if (send_str.empty())continue;sockfd->Send(send_str);}else if (n == 0){LOG(LogLevel::DEBUG) << addr.ToString() << " quit, me too!";break;}else{LOG(LogLevel::DEBUG) << addr.ToString() << " read error, quit!";break;}}sockfd->Close();}void Run(){while(true){// 你要得到一个sockfd, client addrInetAddr addr;auto sockfd=_listensocket->Accept(&addr);if(sockfd==nullptr)continue;LOG(LogLevel::DEBUG) << "获取一个新连接: " <<addr.ToString()<<",sockfd:"<<sockfd->SockFd();if(fork()==0){_listensocket->Close();HandlerRequest(sockfd,addr);exit(0);}sockfd->Close();}}~TcpServer() {}private:int _port;unique_ptr<Socket> _listensocket;callback_t _cb;
};随后是客户端的主文件,实现思路为构建请求、序列化、打包、发送、接收、报文解析、反序列化,就是调用前面的函数就行了
Client.cc
#include<iostream>
#include<string>
#include<memory>
#include"Socket.hpp"
#include"InetAddr.hpp"
#include"Protocol.hpp"using namespace std;
void Usage(std::string proc)
{cerr << "Usage: " << proc << " serverip serverport" << endl;
}// ./Client serverip serverport
int main(int argc,char *argv[])
{if(argc!=3){Usage(argv[0]);exit(0);}string serverip=argv[1];uint16_t serverport =stoi(argv[2]);unique_ptr<Socket> sockptr=make_unique<TcpSocket>();sockptr->BuildClientSocketMethod();InetAddr server(serverport,serverip);if(sockptr->Connect(server)){string inbuffer;while(true){// 1. 构建请求Request req;cout<<"Please Enter X: ";cin>>req._x;cout << "Please Enter Y: ";cin>>req._y;cout<<"Please Enter Operator: ";cin>>req._oper;// 2. 序列化string jsonstr;req.Serialize(&jsonstr);cout<<"jsonstr: \r\n" << jsonstr << endl;// 3. 打包// len\r\njsonstr\r\nstring sendstr=Protocol::Package(jsonstr);cout<<"sendstr:\r\n" << sendstr << std::endl;// 4. 发送sockptr->Send(sendstr);// 5. 接收sockptr->Recv(&inbuffer);// 6. 报文解析string package;int n=Protocol::Unpack(inbuffer,&package);if(n>0){Response resp;// 7. 反序列化bool r=resp.Deserialize(package);if(r){resp.Print();}}}}return 0;
}最后是server主程序的代码
main.cc
#include"Calculator.hpp"// 业务 // 应用层
#include"Parser.hpp" // 报文解析,序列反序列化等 // 表示层
#include"TcpServer.hpp" // 网络通信开断连接 //会话层
#include"Daemon.hpp"
#include<memory>
void Usage(string proc)
{cerr<<"Usage:"<<proc<<"localport"<<endl;
}int main(int argc,char*argv[])
{if(argc!=2){Usage(argv[0]);exit(0);}// Daemon();//EnableFileLogStrategy();EnableConsoleLogStrategy();// 计算机对象unique_ptr<Calculator> cal=make_unique<Calculator>();// 协议解析的模块unique_ptr<Parser> parser=make_unique<Parser>([&cal](Request &req)->Response{return cal->exec(req);});// 网络通信模块uint16_t serverport=stoi(argv[1]);unique_ptr<TcpServer> tsock=make_unique<TcpServer>(serverport,[&parser](string &inbuffer)->string{return parser->Parse(inbuffer);});tsock->Run();return 0;
}makefile
.PHONY:all
all: Main ClientMain:Main.ccg++ -o $@ $^ -std=c++17 -ljsoncpp -gClient:Client.ccg++ -o $@ $^ -std=c++17 -ljsoncpp -g.PHONY:clean
clean:rm -f Main ClientDeamon.hpp
#pragma once#include<iostream>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
#include<signal.h>void Daemon()
{// 1. 忽略可能导致进程退出的信号signal(SIGCHLD,SIG_IGN);signal(SIGPIPE,SIG_IGN);// 2. 让进程不要是组长if(fork()>0){exit(0);}//3. 更改守护进程的工作路径,建议/chdir("/");//4. 将自己设计成为新的会话setsid();// 5. 看待标准输入,标准输出,表示准错误// a. 关闭 2. 标准输入,标准输出,标准错误 -> 重定向 -> /dev/null(最佳实践)int fd=open("dev/null",O_RDWR);if(fd>=0){dup2(fd,0);dup2(fd,1);dup2(fd,3);}
}之后,InetAddr.hpp,Mutex.hpp,Logger.hpp,跟前面一样的,不写了
下面我们运行一下:
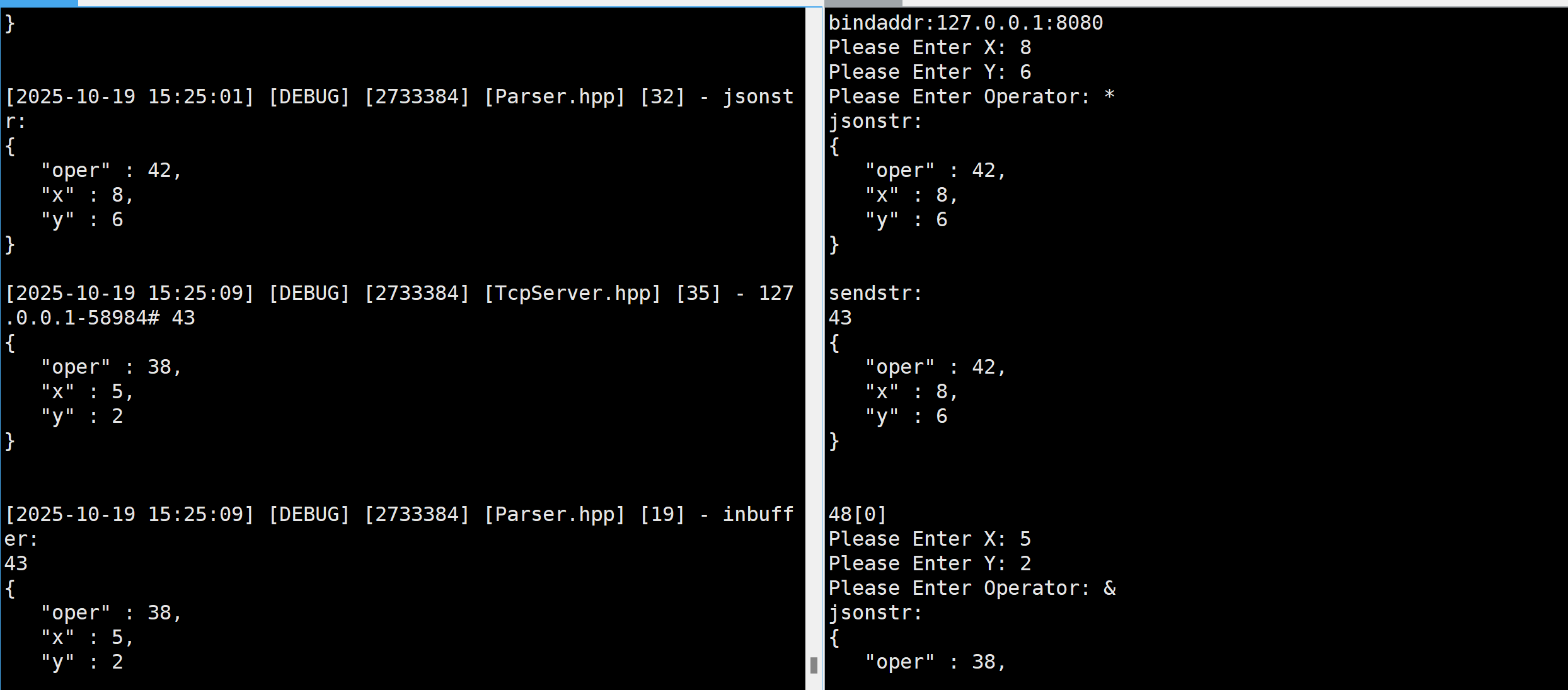
任务完成!!