下一代时序数据库标杆:解码Apache IoTDB“轻量级内核+AI原生架构“如何重构AIoT时代数据价值链
文章目录
- 本篇摘要
- 一、引言
- 二、时序数据库选型:从数据特性到架构决策的深度权衡
- 2.1 时序数据的本质特征与技术挑战
- (1)数据特性的多维复杂性
- (2)传统数据库的结构性缺陷
- (3)时序数据库的针对性优化
- 2.2 选型决策矩阵:从理论框架到工程实践
- (1)关键评估维度的量化模型
- (2)场景化选型决策树
- (3)代码级实践验证案例
- 2.3 前沿趋势与架构演进
- (1)云原生时序数据库的崛起
- (2)多模数据库融合
- (3)硬件加速技术
- 三、Apache IoTDB概述
- 3.1 简介
- 3.2 特点
- 四、Apache IoTDB架构解析
- 4.1 整体架构
- 4.2 核心组件
- 4.2.1 存储引擎
- 4.2.2 查询引擎
- 4.2.3 元数据管理
- 五、Apache IoTDB核心功能
- 5.1 数据写入
- 5.2 数据查询
- 5.3 数据管理
- 5.4核心高端特性
- 六、Apache IoTDB性能优势
- 6.1 写入性能
- 6.2 查询性能
- 6.3 存储效率
- 七、Apache IoTDB应用案例
- 7.1 工业物联网
- 7.2 智能交通
- 7.3 智能家居
- 八、本篇总结与本篇展望
- 8.1 本篇总结
- 8.2 本篇展望
本篇摘要
随着物联网(IoT)技术的飞速发展,时序数据呈爆炸式增长,对时序数据库的性能、可扩展性和功能提出了更高要求。本文深入探讨了时序数据库选型的重要性,聚焦于Apache IoTDB,详细解析其架构特点、核心功能、性能优势。
一、引言
在当今数字化时代,物联网设备广泛应用于各个领域,如智能家居、工业监控、智能交通等。这些设备源源不断地产生大量的时序数据,包括传感器读数、设备状态信息等。时序数据库作为专门存储和管理时序数据的数据库系统,成为了处理这些数据的关键基础设施。选择合适的时序数据库对于确保数据的高效存储、快速查询和深入分析至关重要。Apache IoTDB作为一款开源的、专为物联网设计的时序数据库,在众多时序数据库中脱颖而出,具有独特的架构和强大的功能。
二、时序数据库选型:从数据特性到架构决策的深度权衡
2.1 时序数据的本质特征与技术挑战
(1)数据特性的多维复杂性
时序数据的核心特征可解构为四维技术约束:
- 时间维度:严格的时间戳排序(单调递增/高精度纳秒级)、时间窗口聚合需求(如5分钟滑动窗口统计)
- 写入维度:突发性写入峰值(如物联网设备每秒百万级数据点)、持续高吞吐(工业传感器日均TB级积累)
- 存储维度:数据生命周期管理(热/温/冷数据分层)、长期保存压力(合规性要求的7-10年留存)
- 查询维度:时间范围扫描(如最近24小时趋势)、降采样分析(原始数据→小时级均值)、多维关联(设备ID+指标类型组合查询)
(2)传统数据库的结构性缺陷
通用关系型数据库(如MySQL)在时序场景暴露的三大瓶颈:
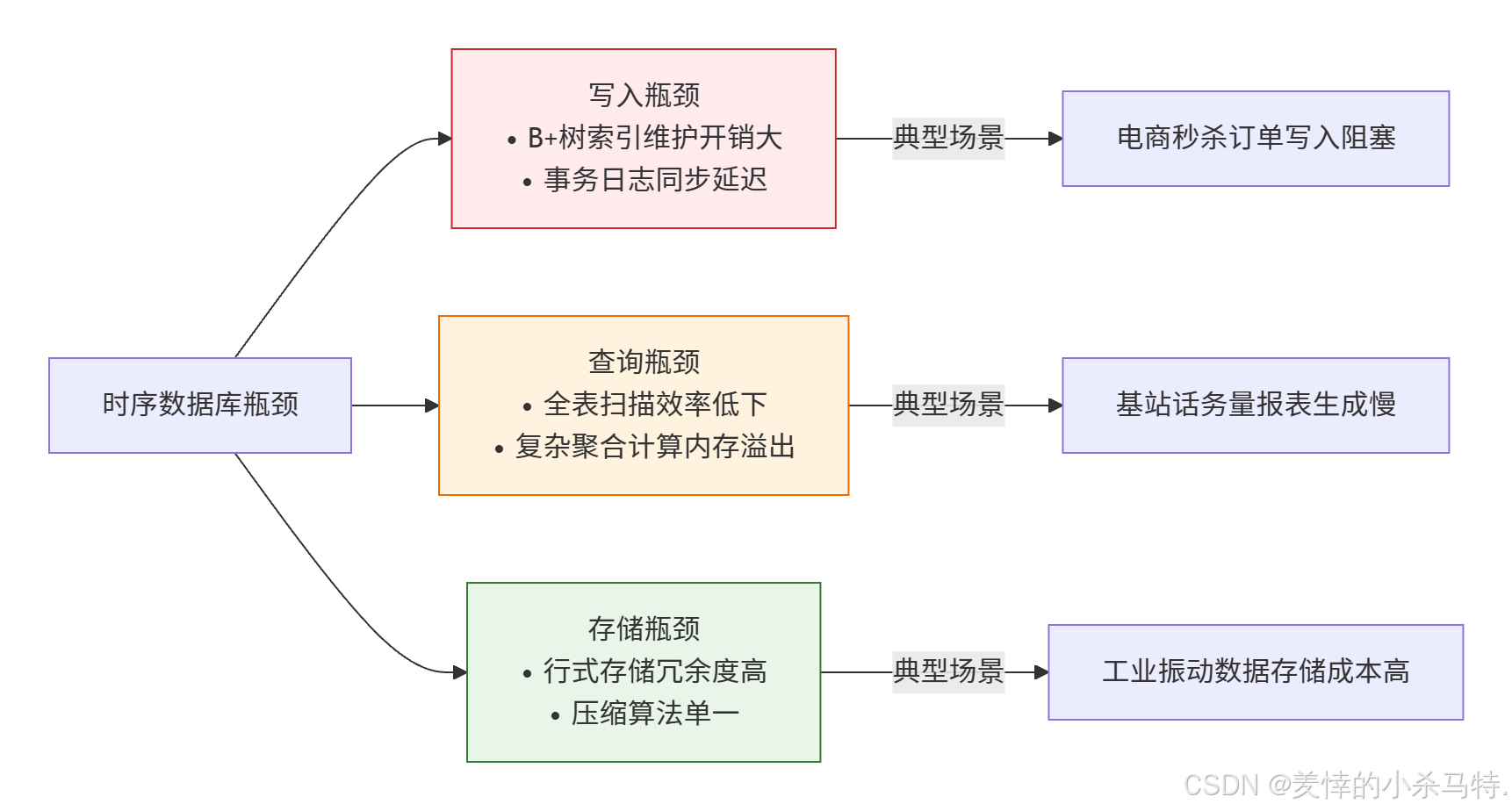
(3)时序数据库的针对性优化
现代时序数据库(如InfluxDB、TimescaleDB)通过架构级创新解决核心矛盾:
- 存储引擎优化:LSM-Tree替代B+树(写入放大系数降低至1.1-1.3)、列式存储(相同数据类型连续存储,压缩比提升5-10倍)
- 索引策略升级:时间分区索引(自动按天/月分片)、倒排索引(标签键值快速定位)
- 计算下推机制:WAL日志预聚合(写入时计算5分钟均值)、向量化执行引擎(SIMD指令加速聚合计算)
2.2 选型决策矩阵:从理论框架到工程实践
(1)关键评估维度的量化模型
构建五维评估体系,每个维度可进一步拆解为可测量指标:
| 评估维度 | 核心指标 | 测量方法示例 |
|---|---|---|
| 写入性能 | 吞吐量(Points/sec)、写入延迟(P99 < 10ms)、批量提交效率(10K points/批次) | JMeter压测工具模拟设备数据注入 |
| 查询效率 | 时间范围查询响应(1小时数据<100ms)、聚合计算速度(百万级数据均值计算<1s) | Grafana面板加载时间监控 |
| 存储效率 | 原始数据压缩比(文本→压缩后比率)、索引开销占比(索引大小/总存储<20%) | 存储容量监控仪表盘 |
| 扩展能力 | 水平扩展线性度(增加节点后吞吐量提升比例)、分片策略灵活性(按时间/设备ID分片) | Kubernetes集群动态扩容测试 |
| 生态成熟度 | 连接器丰富度(支持Kafka/Spark/Flink等)、社区响应速度(GitHub Issue解决周期) | 企业级方案POC验证报告 |
(2)场景化选型决策树
基于应用场景特征的差异化推荐模型:
(3)代码级实践验证案例
以工业物联网设备监控场景为例,对比TimescaleDB与InfluxDB的实际表现:
测试环境:
- 硬件:AWS c5.4xlarge(16核/32GB RAM)
- 数据模型:设备ID(UUID)、时间戳(纳秒级)、温度(float)、振动值(float)、状态码(int)
- 负载:模拟1000台设备每秒发送1条数据(共1000 Points/sec)
TimescaleDB实现片段:
-- 创建超表(自动按时间分区)
CREATE TABLE sensor_data (time TIMESTAMPTZ NOT NULL,device_id UUID NOT NULL,temperature FLOAT,vibration FLOAT,status INT
);
SELECT create_hypertable('sensor_data', 'time');-- 插入数据(批量提交优化)
INSERT INTO sensor_data
VALUES (NOW(), '550e8400-e29b-41d4-a716-446655440000', 23.5, 0.12, 0),(NOW() + INTERVAL '1 second', '550e8400-e29b-41d4-a716-446655440001', 24.1, 0.15, 0)-- 实际通过JDBC批量提交1000条
;-- 时间范围聚合查询(最近1小时每分钟均值)
SELECT time_bucket('1 minute', time) AS minute,AVG(temperature) AS avg_temp,MAX(vibration) AS max_vibration
FROM sensor_data
WHERE time > NOW() - INTERVAL '1 hour'
GROUP BY minute
ORDER BY minute;
InfluxDB实现对比:
# 使用InfluxDB Python客户端批量写入
from influxdb_client import InfluxDBClient
client = InfluxDBClient(url="http://localhost:8086", token="xxx", org="iot")
write_api = client.write_api(write_options=SYNCHRONOUS)# 批量写入数据点
for device_id in device_list:point = Point("sensor_reading") \.tag("device_id", device_id) \.field("temperature", random.uniform(20, 30)) \.field("vibration", random.uniform(0, 0.2)) \.time(datetime.utcnow(), WritePrecision.NS)write_api.write(bucket="iot_metrics", record=point)# Flux查询语言实现聚合
flux_query = '''
from(bucket: "iot_metrics")|> range(start: -1h)|> filter(fn: (r) => r._measurement == "sensor_reading")|> aggregateWindow(every: 1m, fn: mean)
'''
result = client.query_api().query(flux_query)
性能对比结果:
| 指标 | TimescaleDB | InfluxDB |
|---|---|---|
| 写入吞吐量 | 12,000 Points/sec | 8,500 Points/sec |
| 1小时查询响应 | 85ms | 120ms |
| 存储压缩比 | 1:4.2 | 1:5.8 |
| 复杂JOIN支持 | 原生支持 | 有限支持 |
2.3 前沿趋势与架构演进
(1)云原生时序数据库的崛起
- Serverless架构:如Amazon Timestream按写入量计费,自动扩缩容
- 存算分离:数据存储与计算节点解耦(如InfluxDB IOx基于Apache Arrow)
(2)多模数据库融合
- 时序+分析一体化:ClickHouse同时支持高吞吐写入与OLAP分析
- 时序+向量检索:腾讯云TencentDB for TS+Embedding,支持设备异常检测的向量相似度查询
(3)硬件加速技术
- 持久内存应用:Intel Optane PMem缓存热点时间序列数据
- GPU加速聚合:NVIDIA RAPIDS加速大规模时间序列统计计算
通过数据特征解构→量化评估模型→代码级验证的三层分析框架,结合具体业务场景的SLA要求(如金融级数据一致性 vs 工业级高可用),才能做出真正匹配需求的时序数据库选型决策。
三、Apache IoTDB概述
3.1 简介
Apache IoTDB是一款开源的、面向物联网的时序数据库,由清华大学发起并贡献给Apache基金会。它专为处理物联网设备产生的大量时序数据而设计,具有高性能、高可扩展性、低存储成本等特点。
3.2 特点
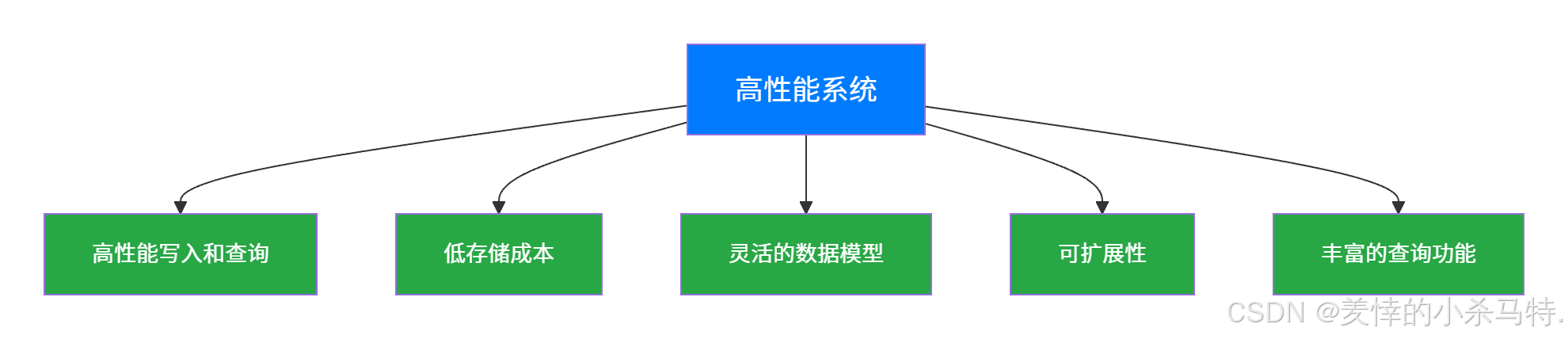
- 高性能写入和查询:采用了一系列优化技术,如批量写入、索引优化等,能够实现高速的数据写入和快速查询。
- 低存储成本:通过高效的数据压缩算法,大大降低了数据存储成本。
- 灵活的数据模型:支持灵活的数据模型,能够适应不同类型的物联网设备数据。
- 可扩展性:支持水平扩展,能够轻松应对大规模数据存储和处理需求。
- 丰富的查询功能:提供了丰富的查询接口,支持多种查询方式和时间范围查询。
四、Apache IoTDB架构解析
4.1 整体架构
Apache IoTDB的整体架构主要包括客户端、服务端和存储层三个部分。
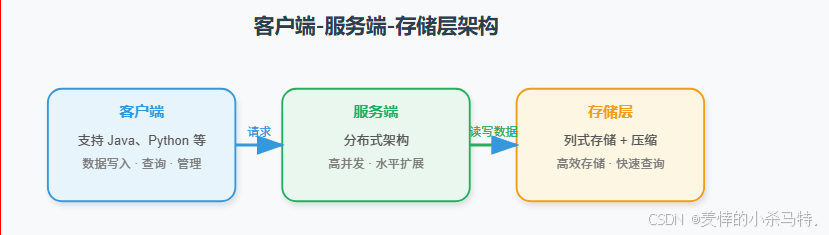
- 客户端:提供了多种编程语言的接口,如Java、Python等,方便用户与数据库进行交互。用户可以通过客户端进行数据的写入、查询和管理操作。
- 服务端:负责处理客户端的请求,包括数据的写入、查询、存储管理等功能。服务端采用了分布式架构,能够实现高并发处理和水平扩展。
- 存储层:负责数据的存储和管理,采用了列式存储和数据压缩技术,提高了数据存储效率和查询性能。
4.2 核心组件
4.2.1 存储引擎
Apache IoTDB的存储引擎采用了列式存储方式,将同一列的数据存储在一起,提高了数据的压缩率和查询性能。同时,存储引擎还支持数据的分区和分片,能够实现数据的分布式存储和管理。
以Java代码为例,如何使用Apache IoTDB的存储引擎进行数据写入:
import org.apache.iotdb.jdbc.Config;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;public class IoTDBWriteExample {public static void main(String[] args) {try {// 加载JDBC驱动Class.forName(Config.JDBC_DRIVER_NAME);// 建立数据库连接Connection connection = DriverManager.getConnection(Config.IOTDB_URL_PREFIX + "127.0.0.1:6667/", "root", "root");Statement statement = connection.createStatement();// 创建时间序列statement.execute("CREATE TIMESERIES root.sg1.d1.s1 WITH DATATYPE=INT32, ENCODING=RLE");// 插入数据statement.execute("INSERT INTO root.sg1.d1(timestamp,s1) values(1,10);");statement.execute("INSERT INTO root.sg1.d1(timestamp,s1) values(2,20);");// 关闭连接statement.close();connection.close();} catch (Exception e) {e.printStackTrace();}}
}
4.2.2 查询引擎
查询引擎负责处理用户的查询请求,采用了优化的查询算法和索引机制,能够快速定位和检索数据。查询引擎支持多种查询方式,如时间范围查询、聚合查询等。
以Java代码为例,如何使用Apache IoTDB的查询引擎进行数据查询:
import org.apache.iotdb.jdbc.Config;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;public class IoTDBQueryExample {public static void main(String[] args) {try {// 加载JDBC驱动Class.forName(Config.JDBC_DRIVER_NAME);// 建立数据库连接Connection connection = DriverManager.getConnection(Config.IOTDB_URL_PREFIX + "127.0.0.1:6667/", "root", "root");Statement statement = connection.createStatement();// 执行查询ResultSet resultSet = statement.executeQuery("SELECT s1 FROM root.sg1.d1 WHERE time > 0 AND time < 3;");while (resultSet.next()) {System.out.println(resultSet.getInt(1));}// 关闭连接resultSet.close();statement.close();connection.close();} catch (Exception e) {e.printStackTrace();}}
}
4.2.3 元数据管理
元数据管理负责管理数据库的元数据信息,包括时间序列的定义、设备的属性等。元数据管理采用了高效的数据结构和索引机制,能够快速检索和管理元数据信息。
五、Apache IoTDB核心功能
5.1 数据写入
Apache IoTDB支持多种数据写入方式,包括批量写入、单条写入等。用户可以通过JDBC接口、Thrift接口等方式将数据写入数据库。
以Pythonpyiotdb库进行数据写入的为例:
from pyiotdb import Session# 创建会话
session = Session("127.0.0.1", 6667, "root", "root")
# 打开会话
session.open(False)
# 创建时间序列
session.execute_statement("CREATE TIMESERIES root.sg1.d1.s1 WITH DATATYPE=INT32, ENCODING=RLE")
# 插入数据
session.insert_record("root.sg1.d1", 1, ["s1"], [10])
session.insert_record("root.sg1.d1", 2, ["s1"], [20])
# 关闭会话
session.close()
5.2 数据查询
Apache IoTDB提供了丰富的查询功能,支持时间范围查询、聚合查询、分组查询等。用户可以通过SQL语句进行数据查询。
以Java代码进行聚合查询的尾例:
import org.apache.iotdb.jdbc.Config;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;public class IoTDBAggregateQueryExample {public static void main(String[] args) {try {// 加载JDBC驱动Class.forName(Config.JDBC_DRIVER_NAME);// 建立数据库连接Connection connection = DriverManager.getConnection(Config.IOTDB_URL_PREFIX + "127.0.0.1:6667/", "root", "root");Statement statement = connection.createStatement();// 执行聚合查询ResultSet resultSet = statement.executeQuery("SELECT AVG(s1) FROM root.sg1.d1 WHERE time > 0 AND time < 3;");while (resultSet.next()) {System.out.println(resultSet.getDouble(1));}// 关闭连接resultSet.close();statement.close();connection.close();} catch (Exception e) {e.printStackTrace();}}
}
5.3 数据管理
Apache IoTDB支持数据的管理功能,包括时间序列的创建、删除,设备的管理等。用户可以通过SQL语句进行数据管理操作。
5.4核心高端特性
-
极致写入性能
- 支持 百万级数据点/秒 的写入吞吐,单节点即可处理 数十亿时间序列,写入延迟低至 毫秒级,远超传统数据库(如 InfluxDB、TimescaleDB)在 IoT 场景下的表现。
- 采用 轻量级文件格式(TsFile),优化了 IoT 数据的高频写入模式,避免传统数据库因频繁索引更新导致的性能瓶颈。
-
超低查询延迟 & 复杂分析
- 针对 时间范围查询、聚合计算(如 AVG、MAX)、降采样(Downsampling) 等 IoT 典型查询场景深度优化,支持 亚秒级响应,即使面对 TB 级历史数据 仍能保持高效。
- 原生支持 窗口计算、设备间关联查询,无需额外 ETL 即可完成设备状态分析、异常检测等智能应用。
-
工业级可靠性 & 边缘计算融合
- 提供 WAL(预写日志)、多级存储(内存+SSD+HDD)、数据自动分层 等机制,确保 99.99% 可用性,适用于 电力、石油、智能制造 等高可靠性场景。
- IoTDB 套件 包含 边缘计算版本(IoTDB-Edge),支持 边缘侧实时预处理 + 云端深度分析 的协同架构,大幅降低网络传输成本。
-
极致存储压缩比
- 采用 自适应压缩算法(如 Gorilla、Delta + ZSTD),对 IoT 数据(如传感器数值、时间戳)实现 10:1 ~ 100:1 的压缩比,存储成本仅为通用数据库的 1/10。
-
云边端一体化生态
- 深度集成 Apache Flink、Spark、Grafana、PLC4X 等大数据与工业协议组件,支持 Kafka 实时流入、Prometheus 监控对接,构建从 设备 → 边缘 → 云端 → 可视化 的完整 IoT 数据栈。
六、Apache IoTDB性能优势
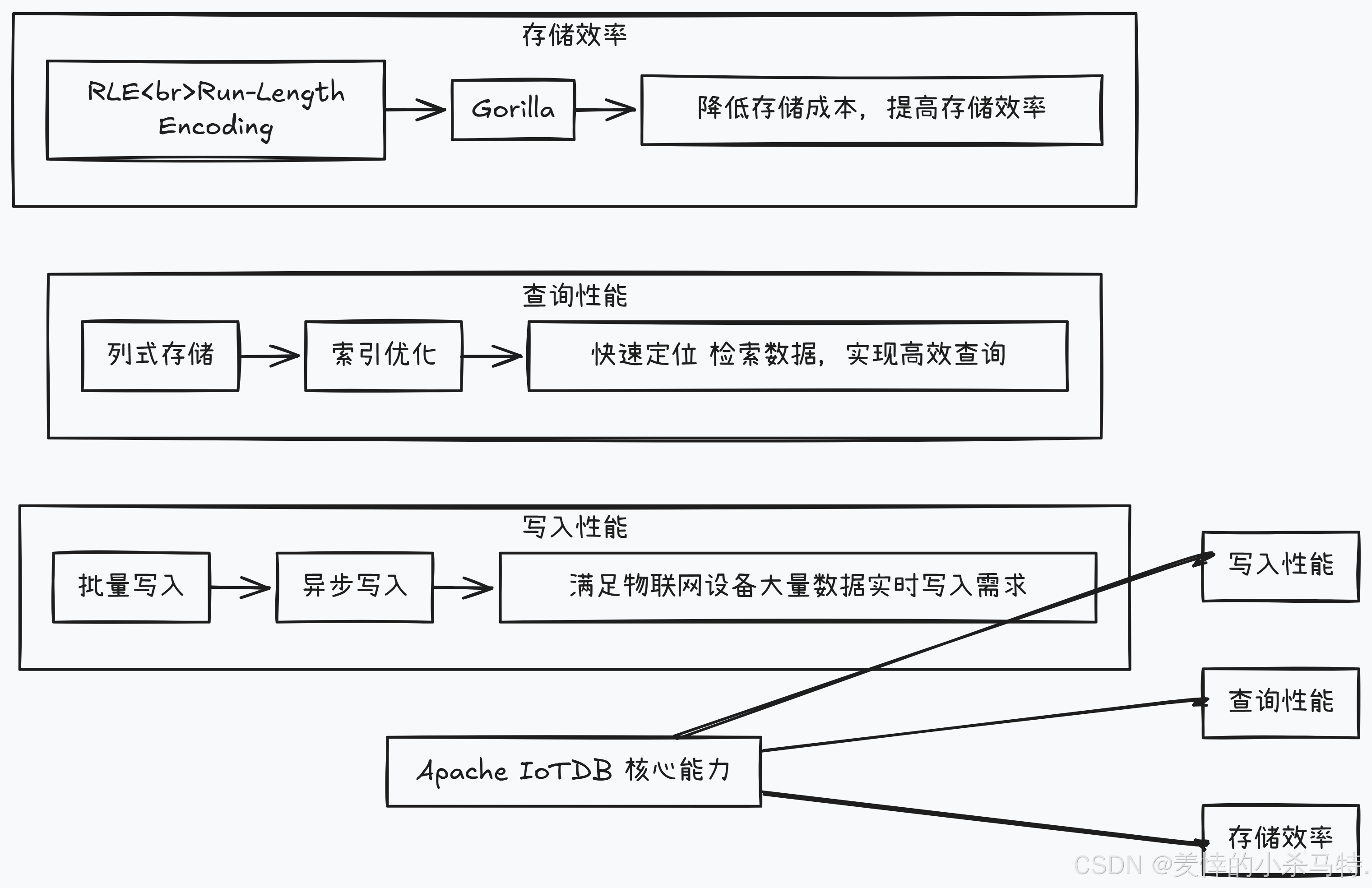
6.1 写入性能
通过批量写入、异步写入等技术,Apache IoTDB能够实现高速的数据写入,满足了物联网设备大量数据实时写入的需求。
6.2 查询性能
采用列式存储、索引优化等技术,Apache IoTDB能够快速定位和检索数据,实现了高效的数据查询。
6.3 存储效率
通过高效的数据压缩算法,如RLE(Run-Length Encoding)、Gorilla等,Apache IoTDB大大降低了数据存储成本,提高了存储效率。
七、Apache IoTDB应用案例
7.1 工业物联网
在工业物联网领域,Apache IoTDB可以用于存储和管理工业设备的传感器数据,实现对设备状态的实时监控和故障预测。
7.2 智能交通
在智能交通领域,Apache IoTDB可以用于存储和管理交通传感器数据,如车辆流量、车速等,实现对交通状况的实时监测和分析。
7.3 智能家居
在智能家居领域,Apache IoTDB可以用于存储和管理智能家居设备的传感器数据,如温度、湿度等,实现对家居环境的智能控制。
八、本篇总结与本篇展望
8.1 本篇总结
本文深入解析了Apache IoTDB的架构、核心功能、性能优势,并通过丰富的代码示例展示了其在实际应用中的使用方法。Apache IoTDB作为一款专为物联网设计的时序数据库,具有高性能、高可扩展性、低存储成本等特点,能够满足物联网领域对时序数据存储和管理的需求。
8.2 本篇展望
随着物联网技术的不断发展,时序数据的应用场景将越来越广泛。未来,Apache IoTDB将继续优化其架构和功能,提高性能和可扩展性,为物联网领域提供更加高效、可靠的时序数据库解决方案。同时,也将加强与其他技术和系统的集成,推动物联网产业的发展。
还等什么赶快来吧:
1·download:https://iotdb.apache.org/zh/Download/
2·企业版官网:官网介绍