数据结构——布隆过滤器(介绍、工作原理、详细Java实现)
文章目录
- 布隆过滤器
- 介绍
- 工作原理
- 数据结构
- 操作流程
- 误判原因
- 关键参数与性能
- Java实现
布隆过滤器
介绍
布隆过滤器是一种空间效率极高的概率型数据结构,用于快速判断一个元素是否在集合中。
它的核心特点是:
- 空间效率极高:使用很少的内存空间
- 查询速度快:常数时间复杂度 O(k),k 为哈希函数数量
- 存在误判率:可能误报元素存在(false positive),但不会漏报(false negative)
工作原理
数据结构
布隆过滤器由一个位数组(bit array)和一组哈希函数组成:
- 位数组:初始时所有位都为 0
- 哈希函数:将元素映射到位数组的不同位置
操作流程
- 添加元素:
- 对元素进行 k 次哈希计算,得到 k 个位置
- 将这些位置的值设为 1
- 查询元素:
- 对元素进行 k 次哈希计算,得到 k 个位置
- 如果所有位置的值都为 1,则认为元素可能存在
- 如果有任何一个位置为 0,则元素一定不存在
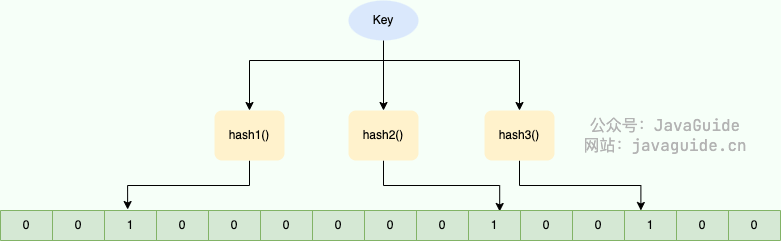
误判原因
当多个元素哈希到相同位置时,可能产生误判(假阳性)。但布隆过滤器不会产生假阴性。可能误报元素存在(false positive),但不会漏报(false negative)
关键参数与性能
- 位数组大小 (m):
-
越大则误判率越低,但占用空间越大
-
计算公式:
m = - (n * ln(p)) / (ln(2))² -
n:预期元素数量
-
p:期望的误判率
- 哈希函数数量 (k):
- 最优值:
k = (m/n) * ln(2) - 哈希函数太少:冲突增加,误判率升高
- 哈希函数太多:位数组快速饱和,误判率升高
- 误判率 §:
- 近似公式:
p ≈ (1 - e^(-k * n / m))^k
Java实现
手搓一个布隆过滤器,项目地址:
https://gitcode.com/Camelazy/java-algorithm/tree/master/src/main/java/cn/camel/algorithm/BloomFilter
import java.util.BitSet;
import java.util.Random;
import java.util.function.ToIntFunction;public class BloomFilter<T> {private final BitSet bitSet;private final int size;private final int numHashFunctions;private final ToIntFunction<T>[] hashFunctions;public BloomFilter(int expectedElements, double falsePositiveRate) {// 计算最优位数组大小this.size = calculateSize(expectedElements, falsePositiveRate);// 计算最优哈希函数数量this.numHashFunctions = calculateNumHashFunctions(expectedElements, size);this.bitSet = new BitSet(size);this.hashFunctions = createHashFunctions(numHashFunctions);}// 添加元素public void add(T item) {for (ToIntFunction<T> hashFunction : hashFunctions) {int index = Math.abs(hashFunction.applyAsInt(item)) % size;bitSet.set(index);}}// 检查元素是否存在public boolean mightContain(T item) {for (ToIntFunction<T> hashFunction : hashFunctions) {int index = Math.abs(hashFunction.applyAsInt(item)) % size;if (!bitSet.get(index)) {return false;}}return true;}// 计算位数组大小private int calculateSize(int n, double p) {return (int) Math.ceil(-(n * Math.log(p)) / (Math.log(2) * Math.log(2)));}// 计算哈希函数数量private int calculateNumHashFunctions(int n, int m) {return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));}// 创建哈希函数(使用不同种子模拟多个哈希函数)@SuppressWarnings("unchecked")private ToIntFunction<T>[] createHashFunctions(int k) {Random random = new Random();ToIntFunction<T>[] functions = new ToIntFunction[k];for (int i = 0; i < k; i++) {int seed = random.nextInt();functions[i] = obj -> (obj.hashCode() ^ seed);}return functions;}// 获取当前误判率(近似值)public double estimateFalsePositiveRate() {double filledBits = (double) bitSet.cardinality() / size;return Math.pow(filledBits, numHashFunctions);}// 测试方法public static void main(String[] args) {// 创建布隆过滤器:预期10000个元素,误判率0.01BloomFilter<String> bloomFilter = new BloomFilter<>(10000, 0.01);// 添加元素bloomFilter.add("apple");bloomFilter.add("banana");bloomFilter.add("orange");// 测试存在元素System.out.println("Contains 'apple': " + bloomFilter.mightContain("apple")); // trueSystem.out.println("Contains 'banana': " + bloomFilter.mightContain("banana")); // true// 测试不存在元素System.out.println("Contains 'grape': " + bloomFilter.mightContain("grape")); // false// 测试误判率int falsePositives = 0;int tests = 10000;for (int i = 0; i < tests; i++) {if (bloomFilter.mightContain("fruit" + i)) {falsePositives++;}}System.out.printf("实际误判率: %.4f%%\n", (falsePositives * 100.0) / tests);System.out.printf("预估误判率: %.4f%%\n", bloomFilter.estimateFalsePositiveRate() * 100);}
}
布隆过滤器是一种空间效率极高的概率型数据结构,特别适合需要快速判断元素是否存在且可以容忍一定误判率的场景。它通过多个哈希函数和位数组的组合,以极小的空间代价实现了高效的成员查询。在实际应用中,需要根据预期元素数量和可接受的误判率合理设置参数,以达到最优效果。