INT301 Bio-computation 生物计算(神经网络)Pt.2 监督学习模型:感知器(Perceptron)
文章目录
- 1.机器学习与人工神经网络(ANN)
- 1.机器学习的基础概念
- 1.2 监督学习(Supervised Learning)和无监督学习(Unsupervised Learning)
- 1.2.1 监督学习(Supervised Learning)
- 1.3 ANN的基础概念
- 1.3.1 感知器(Perceptron)的导论
- 1.3.2 人工神经网络(ANN)在模式识别中的应用
- 1.3.3 感知器(Perceptron)
- 1.3.4 感知器在权重更新过程中的步骤
- 1.3.5 示例
- 1.3.6 总结
- 1.3.6.1 感知器收敛定理(Perceptron Convergence Theorem)
- 1.3.7 衡量感知器
- 1.3.7.1 感知器收敛定理(Perceptron Convergence Theorem)
- 1.3.8 感知器作为分类器
- 1.3.8.1 决策边界
- 1.3.9 线性可分问题(Linear Separability Problem)
1.机器学习与人工神经网络(ANN)
1.机器学习的基础概念
计算机通过数据学习,这些数据代表了某个领域的“过去经历”。目标是学习一个函数,这个函数可以根据输入数据预测离散的类别输出,例如“是”或“否”。这种任务被称为监督学习。
在机器学习中,数据通常是一组记录,每个记录都包含一些特征(attributes)和一个标签(label)。这些记录也被称为“示例”“实例”或“案例”。
每个数据记录由k个属性(特征)描述。这些属性可以是数值型的(如年龄、收入)或分类型(如性别、颜色)的。例如,如果你在处理一个客户数据集,属性可能包括客户的年龄(A1)、收入(A2)、职业(A3)等。
在监督学习中,每个数据记录都有一个已知的类别标签。这些标签是预先定义好的,用于表示每个记录所属的类别。例如,在一个垃圾邮件分类任务中,每个邮件都被标记为“垃圾邮件”或“非垃圾邮件”。
监督学习的目标是通过已标记的数据训练一个模型,这个模型能够根据输入的特征预测新数据的类别。例如,如果你训练了一个垃圾邮件分类器,你可以用它来预测新邮件是否为垃圾邮件。
下图给出了一个数据的例子。
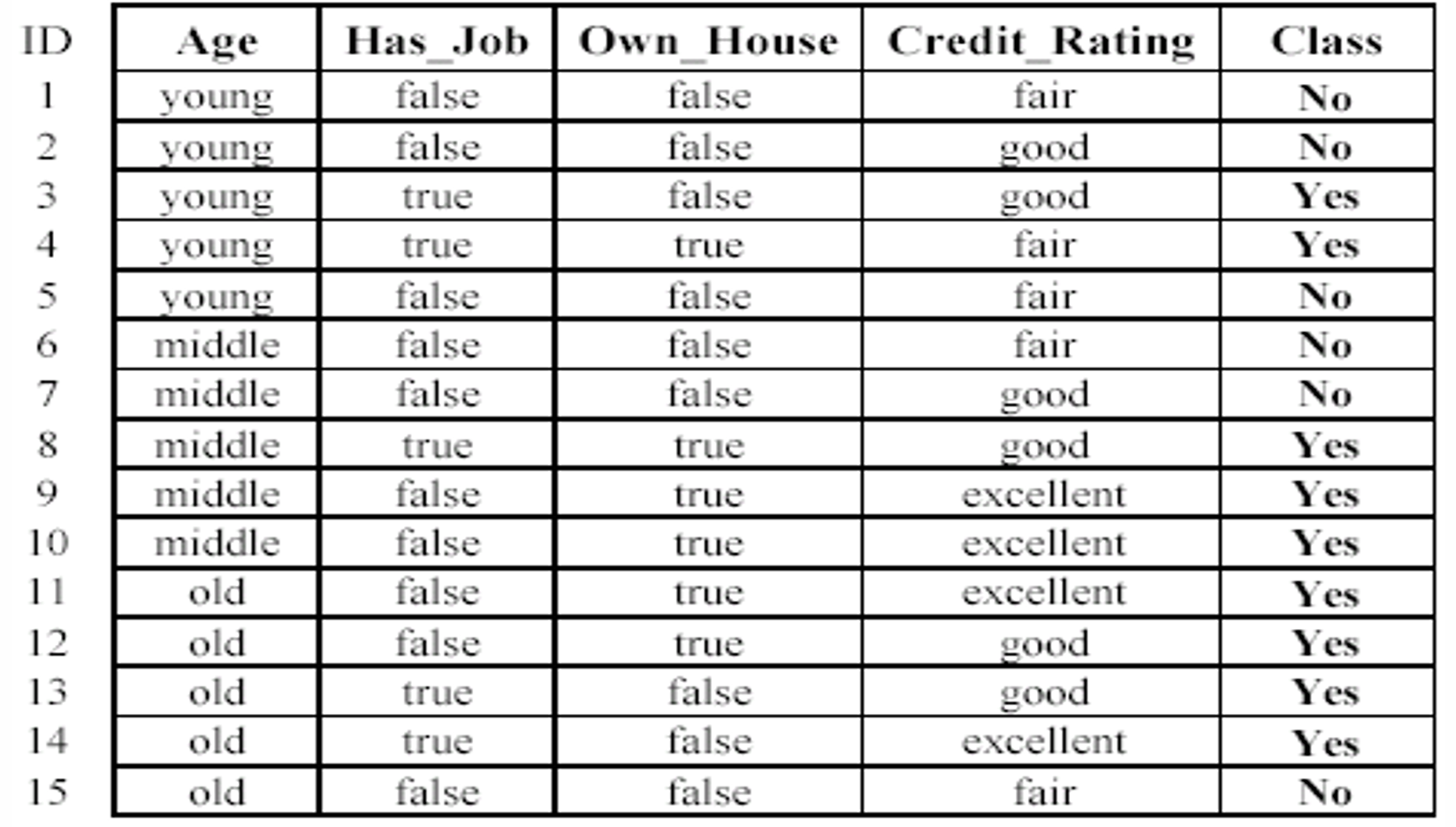
我们现在从数据中学习一个分类模型。这个模型的目标是根据申请者的特征(年龄、是否有工作、是否拥有房产、信用评级)来预测贷款申请的结果。
使用训练好的模型来预测新的贷款申请是否会被批准(Yes/No)。
因此我们对于现在新的一个输入。

根据数据这个新案例可能会被预测为“No”(不批准)。
1.2 监督学习(Supervised Learning)和无监督学习(Unsupervised Learning)
监督学习:数据有标签,模型学习如何根据输入预测这些标签。
无监督学习:数据没有标签,模型试图发现数据中的隐藏结构或模式。
1.2.1 监督学习(Supervised Learning)
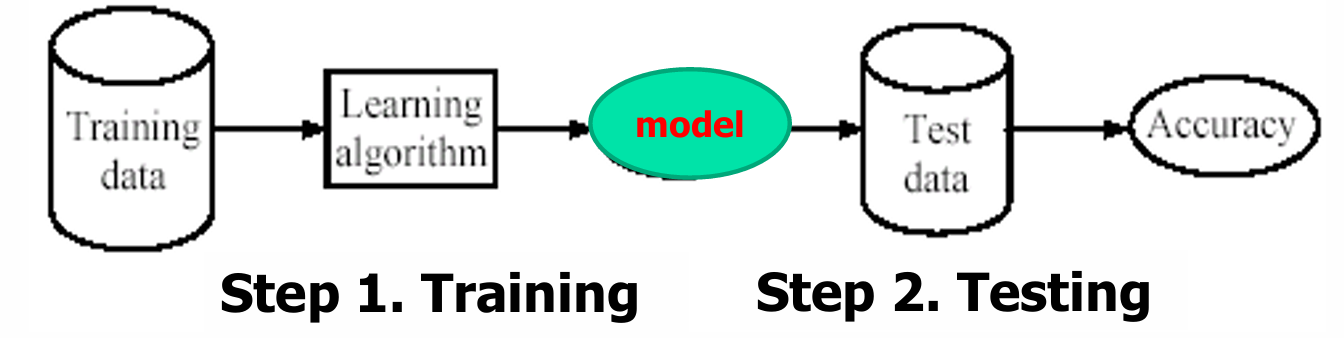
监督学习过程的两个步骤:
- 训练(Training):
在这个阶段,使用标记的训练数据来学习一个模型。训练数据是已经知道输出结果的数据,模型通过这些数据学习如何从输入特征预测输出标签。
训练过程中,模型会尝试找到输入特征和输出标签之间的关系,以便能够对新的、未见过的数据进行预测。 - 测试(Testing):
在这个阶段,使用未见过的测试数据来评估模型的准确性。测试数据是模型在训练过程中没有见过的数据,用于检验模型的泛化能力。
通过比较模型对测试数据的预测结果和实际标签,可以评估模型的性能。
我们可以使用准确性(Accuracy)来衡量模型性能。其计算公式如下:Accuracy = 模型预测正确的样本数量/模型做出的总预测样本数量。
我们回顾一下及其学习的定义:一个计算机系统通过从数据集中学习,提高了在特定任务上的性能,这种性能的提升是通过某种性能度量来评估的。学习使得系统在执行任务时比没有学习时表现得更好。
我们这里再提出一个有关机器学习的假设:训练数据和测试数据的分布应该是相同的。
然而,在实际应用中,这个假设往往难以完全满足,因为训练和测试数据可能来自不同的分布。
如果这种分布差异很大,模型的泛化能力会受到影响,导致在测试数据上的准确性下降。
因此,为了提高模型在测试数据上的表现,需要确保训练数据能够充分代表测试数据的分布。
1.3 ANN的基础概念
1.3.1 感知器(Perceptron)的导论
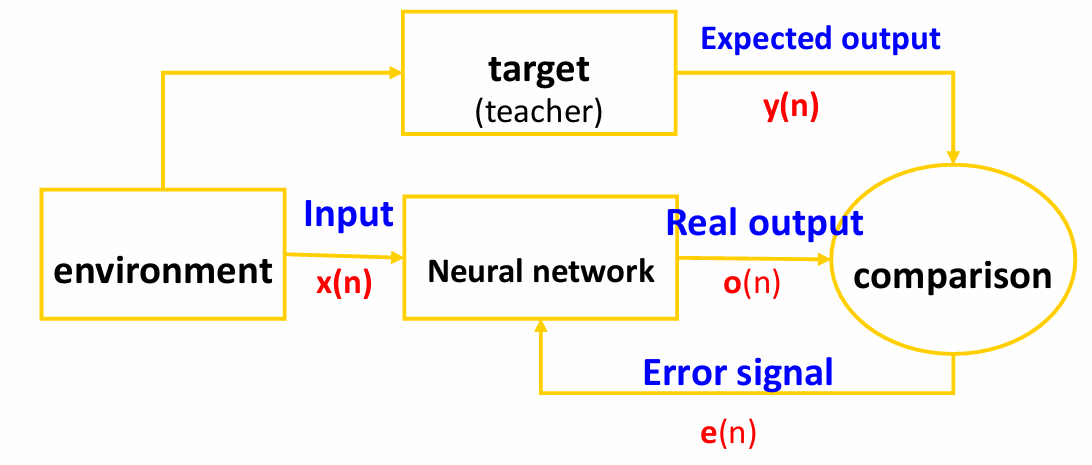
Rosenblatt在1958年明确考虑了模式识别问题,在这个问题中,“教师”是必不可少的。这里“教师”来提供正确的输出,以便网络能够学习并调整其权重。
在感知器中,每个神经元(或称为响应单元)都有一个权重。当网络接收到输入并给出预测时,如果预测结果与“教师”提供的正确结果不一致,那么网络就会调整相关神经元的权重。这种调整是基于一个简单的规则,目的是减少预测错误,使网络在未来能够更准确地响应类似的刺激。
因此感知器是一种简单的神经网络,它可以通过学习来改变其内部权重。这种学习是通过一个错误纠正规则来实现的,即网络会根据其预测与实际结果之间的差异来调整权重。
1.3.2 人工神经网络(ANN)在模式识别中的应用
人工神经网络是一种模拟人脑神经元网络结构和功能的计算模型,常用于识别和分类数据模式。
训练数据由输入特征 x x x和对应的期望输出 y y y组成。
网络(模型,分类器)根据目标和网络输出之间的错误调整其连接权重。
1.3.3 感知器(Perceptron)
感知器是一种早期的神经网络模型,用于模式识别和分类任务。
感知器的最简单结构由两层理想化的“神经元(neurons)”组成,我们将称之为网络的“单元(units)”。
感知器的结构非常简单,只有输入层(one layer of input units)和输出层(one layer of output units),没有隐藏层。如下图所示。
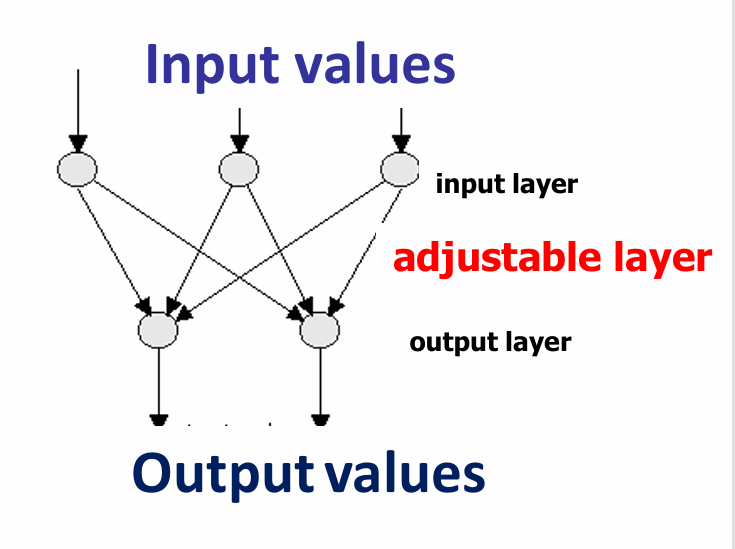
这两层是完全互相连接的,即每个输入单元都与每个输出单元相连。
因此,感知器的处理元素是抽象的神经元。
每个处理元素都有相同的输入,包括整个输入层,但具有不同的输出,不同的连接方式,因此连接的权重也不同。这里指的便是输出层的单元。
输出单元 j j j的总输入是 S j = ∑ i = 0 n w j i a i S_j = \sum_{i=0}^{n} w_{ji} a_i Sj=∑i=0nwjiai,计算方法是将所有输入单元 a i a_i ai与对应的权重 w j i w_{ji} wji相乘后求和。
需要注意的是在输入层中有一个特殊的偏置输入单元编号0。偏置单元(bias unit)是一个常数 a 0 a_0 a0输入(通常为1),它不接收外部输入,但与每个输出单元相连,帮助模型更好地拟合数据。因此求和是对所有连接到输出单元 j j j的 n + 1 n+1 n+1个输入单元进行的。而偏置单元连接到输出单元 j j j的权重 w j 0 w_{j0} wj0会像其他权重一样进行调整。
输出单元 j j j的输出值 X j X_j Xj取决于加权和是否超过该单元的阈值。
也就是说 X j X_j Xj是由单元的阈值激活函数定义的,定义如下:
X j = f ( S j ) = { 1 , if S j ≥ θ j 0 , if S j < θ j X_j = f(S_j) = \begin{cases} 1, & \text{if } S_j \geq \theta_j \\ 0, & \text{if } S_j < \theta_j \end{cases} Xj=f(Sj)={1,0,if Sj≥θjif Sj<θj
这里, S j S_j Sj是输出单元 j j j的加权输入总和, θ j θ_j θj是阈值。
输出层中所有单元的即时输出集合 X = { X 0 , X 1 , … , X n } X=\{X_0 ,X_1 ,…,X_n\} X={X0,X1,…,Xn}构成了网络的输出向量。
输出层中第 j j j个单元的即时输出构成了输出向量的第 j j j个分量。
根据感知器学习规则,两层之间的连接权重 w j i w_{ji} wji会被改变,这样网络就更有可能对某些输入产生期望的输出。
权重调整的过程被称为感知器学习(或训练)。
每个处理单元根据其状态和阈值计算输出。 S j = ∑ i = 0 n w j i a i S_j = \sum_{i=0}^{n} w_{ji} a_i Sj=∑i=0nwjiai。
输出值 X j X_j Xj由单元的阈值激活函数定义: X j = f ( S j ) = { 1 , if S j ≥ θ j 0 , if S j < θ j X_j = f(S_j) = \begin{cases} 1, & \text{if } S_j \geq \theta_j \\ 0, & \text{if } S_j < \theta_j \end{cases} Xj=f(Sj)={1,0,if Sj≥θjif Sj<θj
接着,我们计算输出单元的误差,输出单元的误差是目标输出和即时输出之间的差异,误差的计算公式为: e j = ( t j − X j ) e_j = (t_j - X_j) ej=(tj−Xj)。这里 t j t_j tj是输出单元 j j j的目标值,即我们希望网络输出的值。 X j X_j Xj是输出单元 j 实际产生的即时输出值,即网络当前状态下的输出。
误差 e j e_j ej被计算出来,并用来重新调整连接权重的值。
权重的调整方式是使网络整体上更有可能在下次给出期望的响应。
1.3.4 感知器在权重更新过程中的步骤
训练的目标是找到一组权重,使得网络能够成功地完成训练集中的每一个映射。、
- 计算每个输出单元的误差。误差的计算公式为: e j = ( t j − X j ) e_j = (t_j - X_j) ej=(tj−Xj)。
- 新的权重 w j i new w_{ji}^{\text{new}} wjinew由旧的权重 w j i old w_{ji}^{\text{old}} wjiold加上权重变化量 Δ w j i \Delta w_{ji} Δwji计算得出:
w j i new = w j i old + Δ w j i w_{ji}^{\text{new}} = w_{ji}^{\text{old}} + \Delta w_{ji} wjinew=wjiold+Δwji
权重变化量 Δ w j i \Delta w_{ji} Δwji由感知器学习规则决定:
Δ w j i = C e j a i = C ( t j − X j ) a i \Delta w_{ji} = C e_j a_i = C (t_j - X_j) a_i Δwji=Cejai=C(tj−Xj)ai
这里, C C C是学习率,一个正的常数,用于控制权重更新的步长。
e j e_j ej是输出单元 j j j的误差。
a i a_i ai是第 i i i个输入单元的输入值。
在感知器训练中,权重的更新是逐个样本进行的,即每次使用一个训练样本来更新权重,然后移动到下一个样本。
感知器训练算法(Delta 规则),公式为: Δ w = l e a r n i n g r a t e × ( t e a c h e r − o u t p u t ) × i n p u t Δw=learning \ rate×(teacher−output)×input Δw=learning rate×(teacher−output)×input
这里 t e a c h e r − o u t p u t = e r r o r teacher−output=error teacher−output=error,也就是误差的计算公式。
下图展示了这个工作流程。
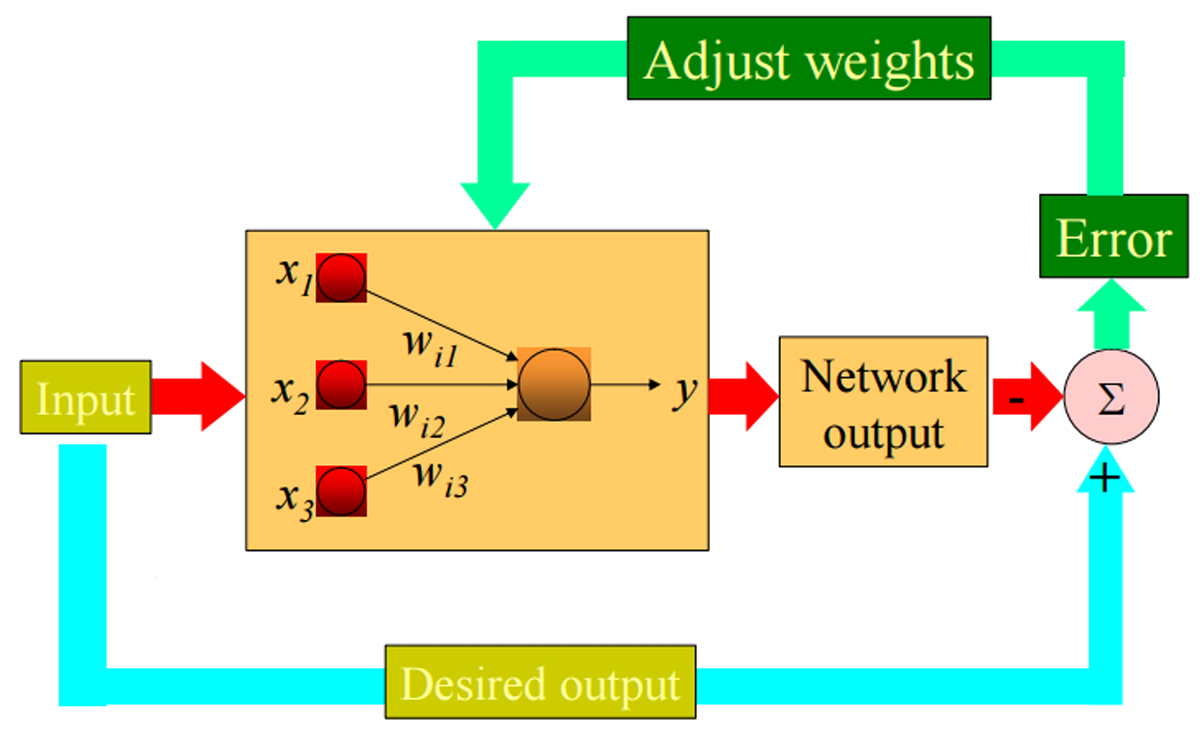
输入层接收外部数据,这些数据是模型的输入特征。每个输入特征 x 1 x_1 x1, x 2 x_2 x2, x 3 x_3 x3通过各自的权重 w i 1 w_{i1} wi1, w i 2 w_{i2} wi2, w i 3 w_{i3} wi3连接到输出单元。权重是模型中的可调参数,用于调整输入特征对输出的影响。
输出单元 y y y计算其输入的加权和,然后根据阈值函数决定输出值。这个输出是模型对当前输入的预测结果。
期望模型达到的输出结果与实际输出进行比较,计算得到误差。
根据计算出的误差,模型会调整权重。权重的调整遵循感知器学习规则,目的是减少误差,提高模型的预测准确性。
1.3.5 示例
我们现在给出一个例子。
我们现在需要用一个模型去判断水果是否为"好水果“。
我们先定义特征:
Taste(味道):分为“Sweet(甜)”和“Not_Sweet(不甜)”。
Seeds(种子):分为“Edible(可食用)”和“Not_Edible(不可食用)”。
Skin(果皮):分为“Edible(可食用)”和“Not_Edible(不可食用)”。
每个特征都被编码为二进制值:
“Sweet” = 1, “Not_Sweet” = 0
“Edible” = 1, “Not_Edible” = 0
输出是一个二进制值,用于表示水果是否为“好水果”,同样被编码为二进制值:
“Good_Fruit” = 1
“Not_Good_Fruit” = 0
我们从一个没有知识的状态开始,如下图所示。
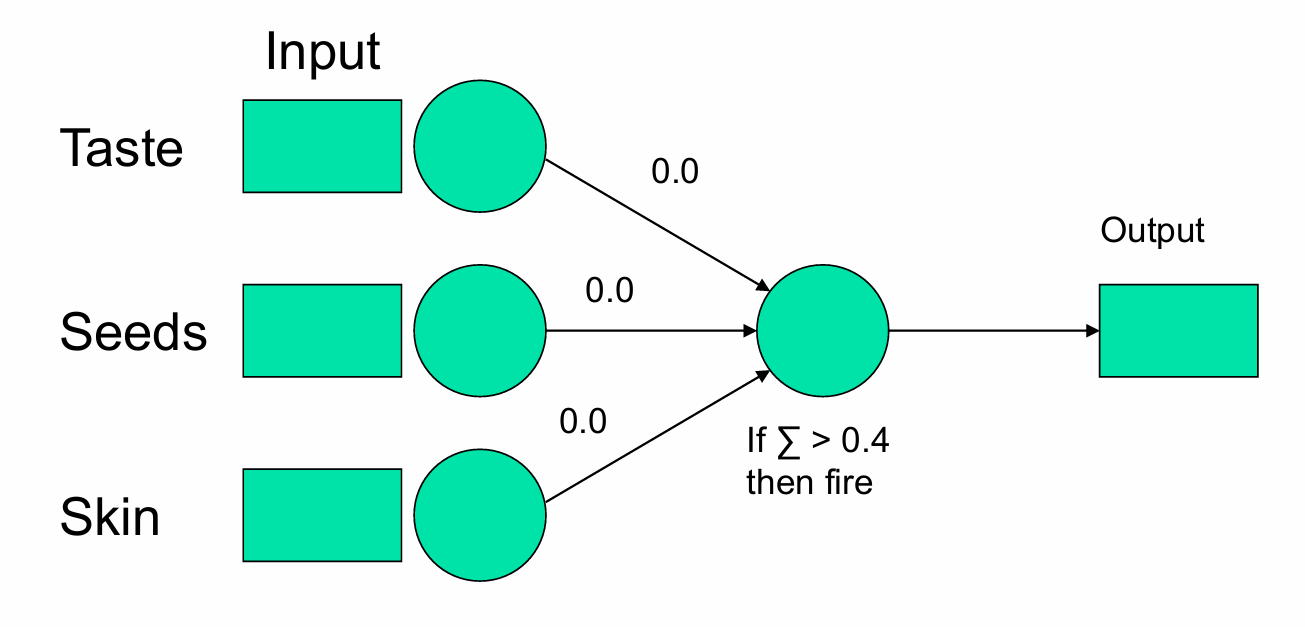
输入层包含三个输入单元,分别对应三个特征:Taste(味道)、Seeds(种子)、Skin(果皮)。
每个输入单元都连接到输出单元,初始权重为0.0。
输出层包含一个输出单元,用于产生最终的输出。
如果加权和 Σ 大于0.4,则输出单元激活(即“fire”),输出1。否则,输出单元不激活,输出0。
在训练感知器时,我们将每个示例(或训练样本)展示给模型,并让它对每个示例进行分类。
由于感知器从没有知识的状态开始,即所有权重都初始化为0,它在开始时会犯错误。
当模型在某个示例上犯了错误(即其预测输出与期望输出不一致),我们需要调整权重以减少未来犯同样错误的可能性。
当我们调整权重时,我们将采取相对较小的步骤,以确保我们不会过度纠正并产生新的问题。
我们将学习“好水果”这一类别,这一类别被定义为任何甜的水果。
Good fruit = 1:如果模型判断某个水果是甜的,即属于“好水果”类别,则输出1。
Not good fruit = 0:如果模型判断某个水果不是甜的,即不属于“好水果”类别,则输出0。
我们输入一个香蕉。
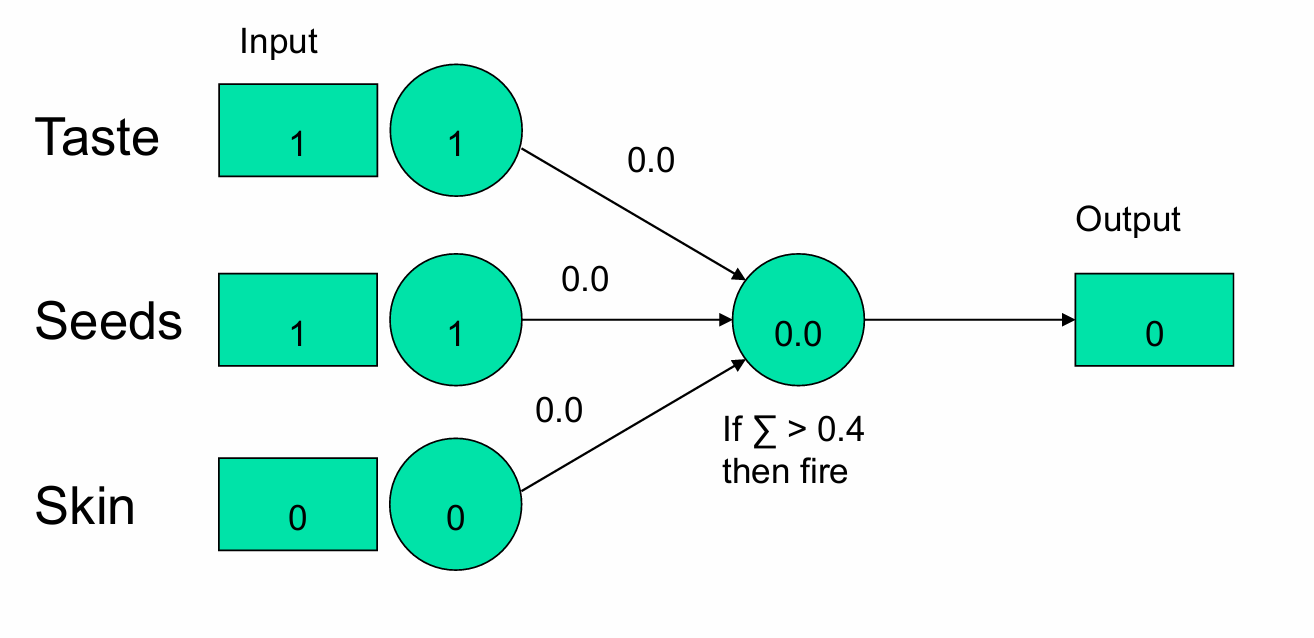
Taste(味道):输入值为1(表示香蕉是甜的)。
Seeds(种子):输入值为1(表示香蕉有种子,尽管实际上香蕉的种子通常不可食用,这里当作可食用)。
Skin(果皮):输入值为0(表示香蕉的果皮不可食用)。
每个输入特征通过权重连接到输出单元,初始权重都设置为0.0。
在这个例子中,输出单元的加权和为0.0(因为所有权重都是0,(1×0)=0+(1×0)=0+(0×0)=0),所以模型输出0,即判断香蕉不是“好水果”,但这与实际情况不符,因为香蕉应该是“好水果”。
由于模型预测错误,我们需要改变权重。使用 delta 规则调整权重: Δ w = l e a r n i n g r a t e × ( t e a c h e r − o u t p u t ) × i n p u t Δw=learning \ rate×(teacher−output)×input Δw=learning rate×(teacher−output)×input
学习率是我们自己设定的参数。它需要足够大,以便学习过程能在合理的时间内发生;同时,它也需要足够小,以避免学习过程过快。这里选择0.25。
teacher(教师)知道正确的答案(例如,香蕉应该是好水果)。在这个例子中,教师说1(表示好水果),输出是0,所以误差是 (1 - 0) = 1。
我们正在调整权重的节点的输入值。对于第一个节点,输入值是1。
使用delta规则来更新权重:
学习率(C)= 0.25
误差(e)= (teacher - output) = (1 - 0) = 1
输入值(a_i)= 1
将给定的值代入公式: Δ w = 0.25 × 1 × 1 = 0.25 Δw=0.25×1×1=0.25 Δw=0.25×1×1=0.25
由于 Δ w Δw Δw是正值,这意味着我们需要在当前权重的基础上增加这个值。
我们现在聚焦于delta规则,先看误差:
如果我们正确地进行了分类,那么(teacher - output)将会是零(正确答案减去它自己)。
换句话说,如果我们预测正确,我们不会改变任何权重。也就是我们有一个好解决方案,为什么要改变它呢?
如果我们分类错误,(teacher - output) 将会是 -1 或 +1。
如果我们在答案应该是“no”时说“yes”,我们的权重太高了,我们将得到一个 (teacher - output) 的值为 -1,这将导致权重减少。
如果我们在答案应该是“yes”时说“no”,我们的权重太低了,这将导致权重增加。
再看输入值:
如果我们正在调整权重的节点发送了0(如果某个输入单元的值为0),那么它没有参与决策过程。在这种情况下,它不应该被调整。乘以零将实现这一点。
如果我们正在调整权重的节点发送了1,那么它确实参与了决策过程,我们应该在相应的输出错误时改变权重(根据需要增加或减少)。
我们再看下面例子给出的一些值。我们可以按照下面的结果进行权重更新。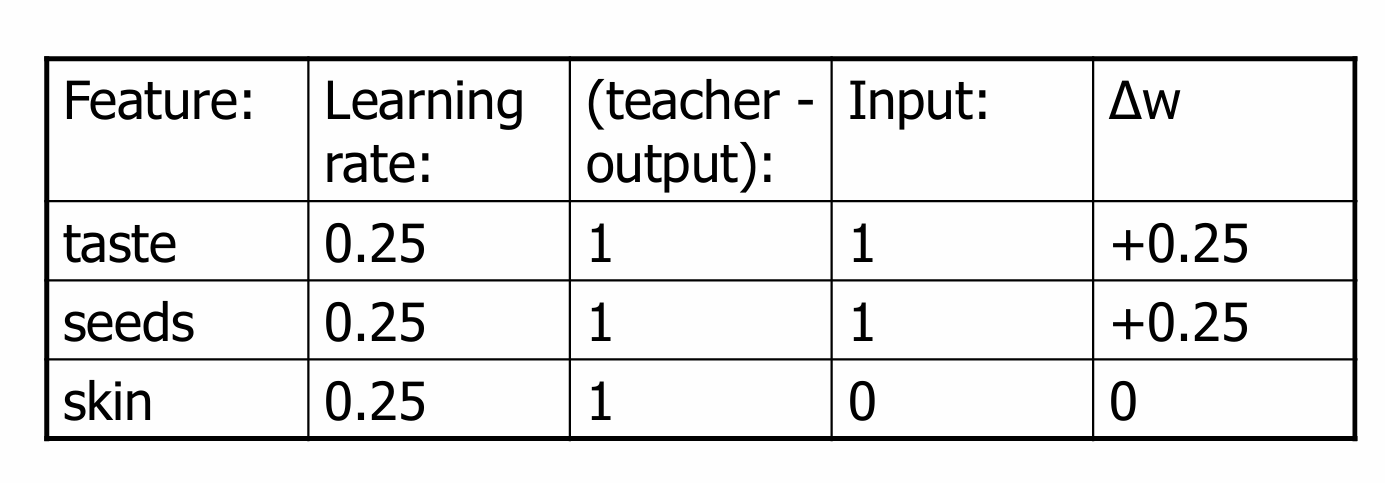
更新后的结果如下:
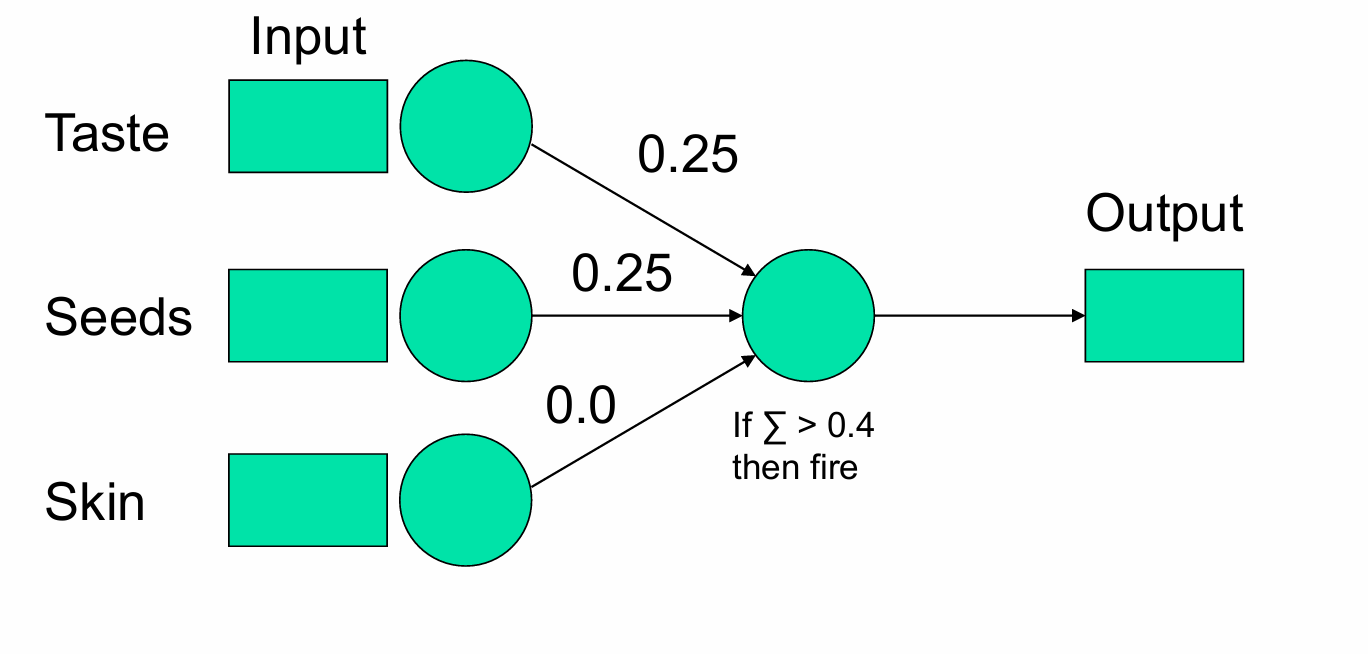
为了继续训练,我们将下一个示例展示给模型,并根据模型的表现调整权重。
我们将不断循环遍历这些示例,直到我们能够完整地遍历一次而不对权重进行任何更改。
当模型能够在整个训练集上正确分类所有样本,而不需要进一步调整权重时,我们可以认为模型已经学会了如何根据输入特征来区分不同的类别。
展示给模型一个梨。
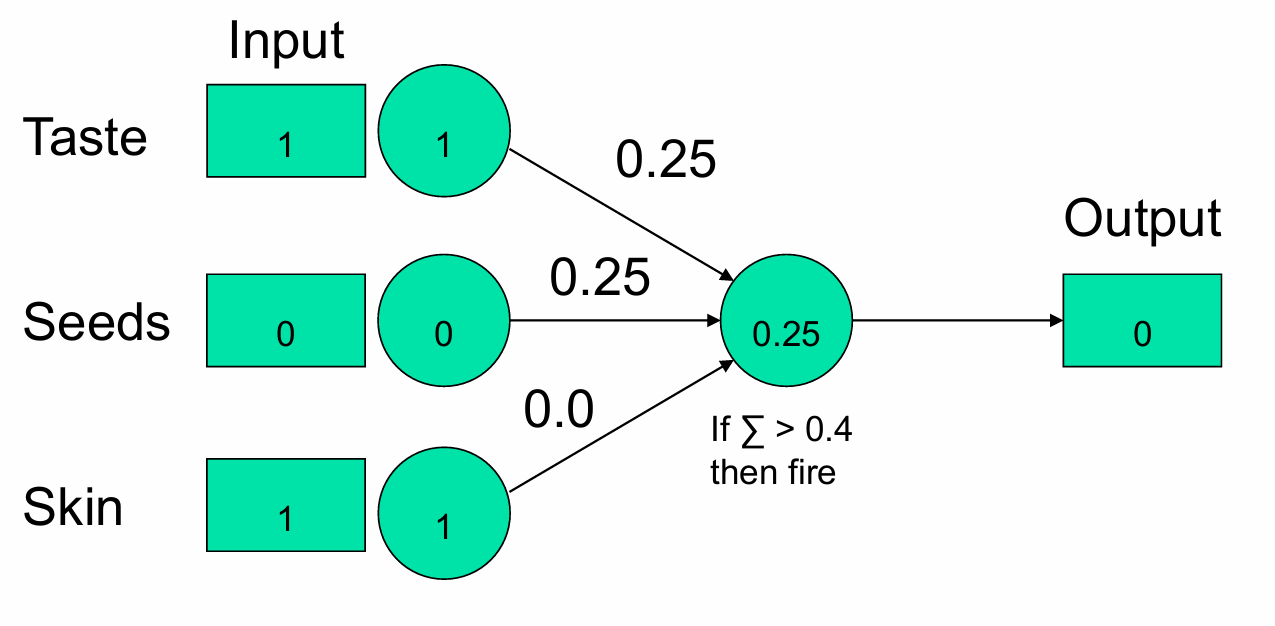
Taste(味道):输入值为1(表示梨是甜的)。
Seeds(种子):输入值为0(表示梨种子不可食用)。
Skin(果皮):输入值为1(表示梨的果皮可食用)。
在这个例子中,输出单元的加权和为0.25(1×0.25+0×0.25+1×0.0=0.25),所以模型输出0,即判断梨不是“好水果”。
因此我们如下进行更新。
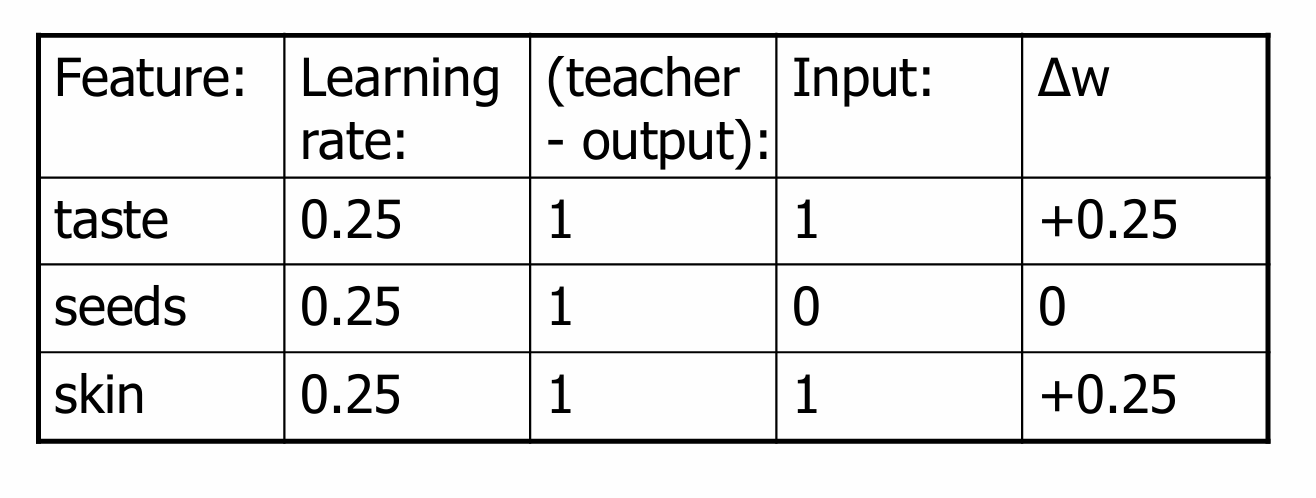
获得新的模型。
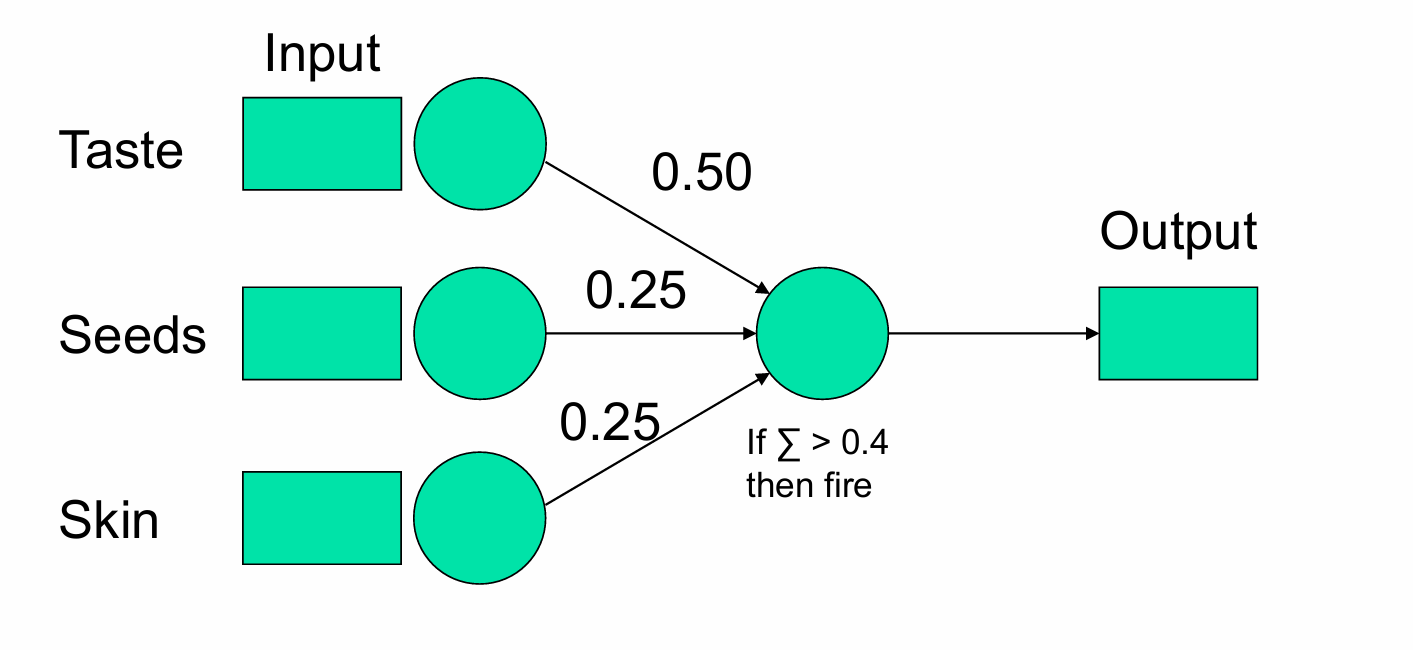
我们再展示给模型一个柠檬。
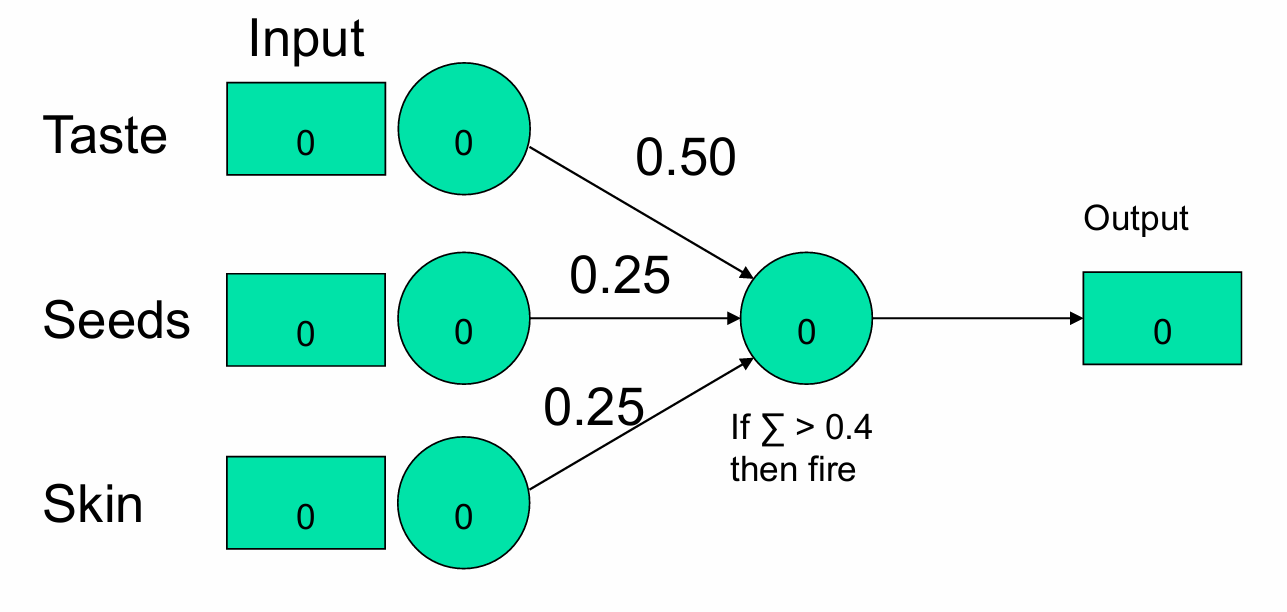
Taste(味道):输入值为0(表示柠檬不甜)。
Seeds(种子):输入值为0(表示柠檬的种子不可食用)。
Skin(果皮):输入值为0(表示柠檬的果皮不可食用)。
在这个例子中,输出单元的加权和为0(即 0×0.50+0×0.25+0×0.25=0),所以模型输出0,即判断柠檬不是“好水果”。
那这里我们如何调整权重吗?在这个例子中,模型正确地将柠檬分类为“非好水果”,因此不需要调整权重。
我们再展示给模型一个草莓。
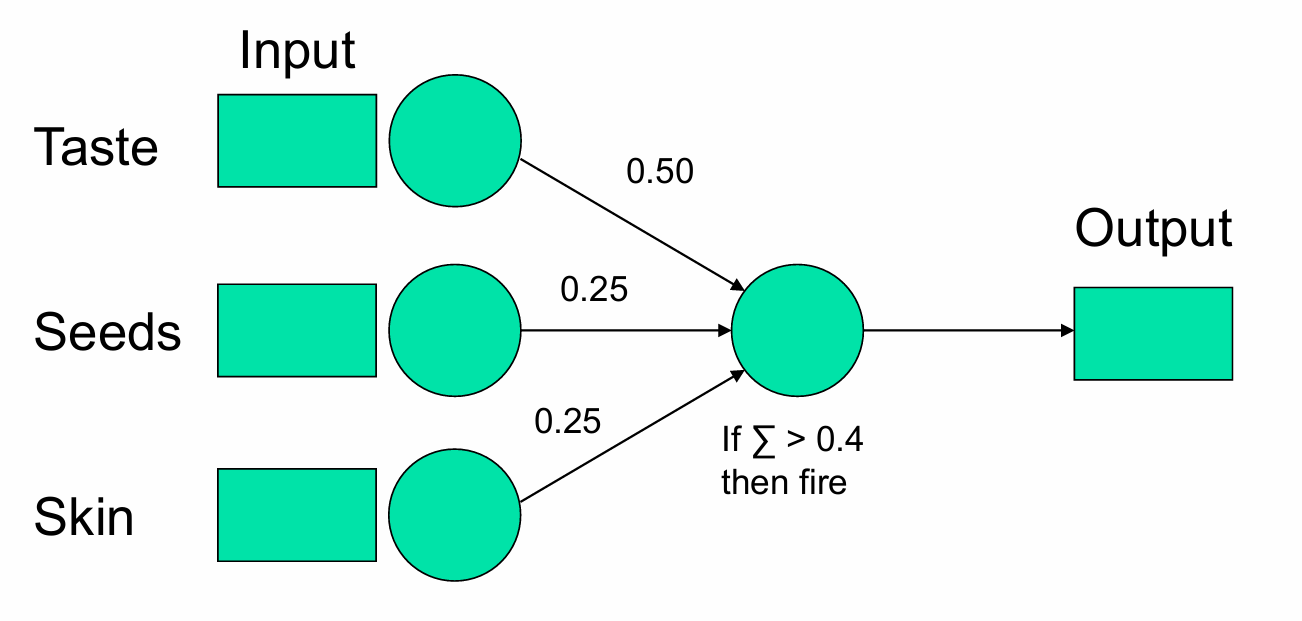
Taste(味道):输入值为1(表示草莓是甜的)。
Seeds(种子):输入值为1(表示草莓的种子可食用)。
Skin(果皮):输入值为1(表示草莓的果皮可食用)。
在这个例子中,输出单元的加权和为1(即 1×0.50+1×0.25+1×0.25=1),所以模型输出1,即判断草莓是“好水果”。
在这个例子中,模型正确地将草莓分类为“好水果”,因此也不需要调整权重。
我们再展示给模型一个青苹果。
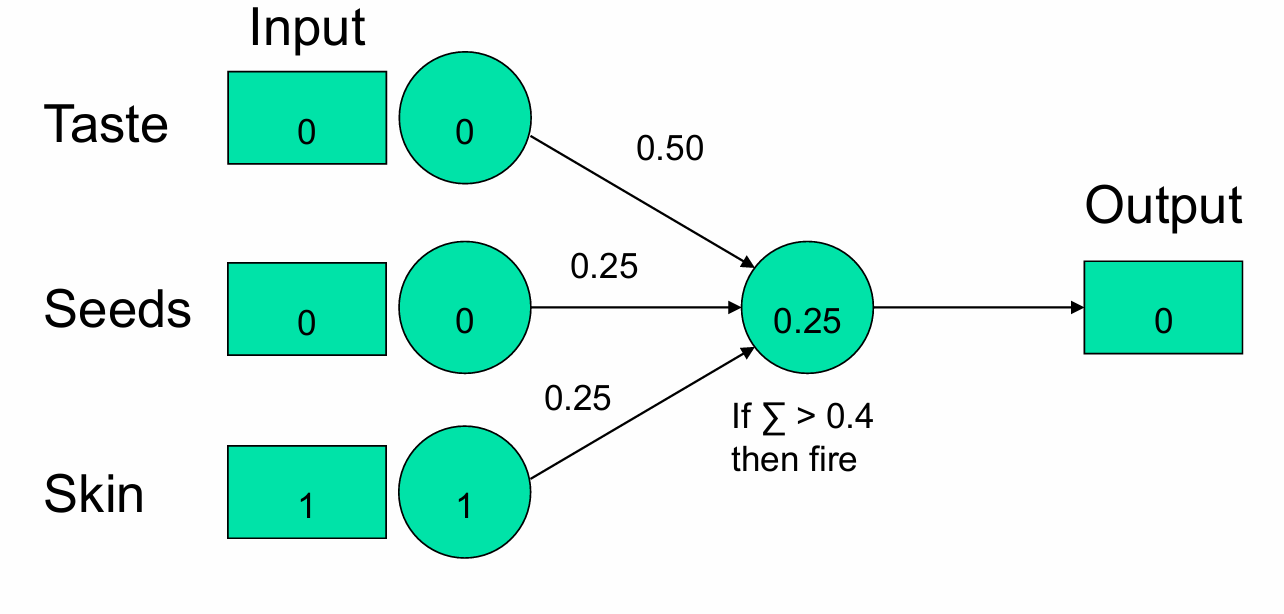
Taste(味道):输入值为0(表示青苹果不甜)。
Seeds(种子):输入值为0(表示青苹果的种子不可食用)。
Skin(果皮):输入值为1(表示青苹果的果皮不可食用)。
在这个例子中,输出单元的加权和为0.25(即 0×0.50+0×0.25+1×0.25=0.25),所以模型输出0,即判断青苹果不是“好水果”。再一次符合结果。
如果我们继续训练感知器模型,我们会发现这个模型能够正确地对我们已经提供给它的示例进行分类。
1.3.6 总结
权重只有在输入值和输出单元的误差都不为0时才会改变。
如果输出是正确的(即期望输出 y e y_e ye等于模型输出 o e o_e oe),则权重 w i w_i wi不会改变。
如果输出是错误的(即期望输出 y e y_e ye不等于模型输出 o e o_e oe),则权重 w i w_i wi会改变,以便在新权重下感知器的输出更接近于期望输出 y e y_e ye。
感知器算法能够收敛到正确的分类,如果满足以下条件:
- 训练数据是线性可分的(即存在一个超平面可以将不同类别的数据点分开);
- 学习率足够小,通常设置在1以下,这决定了在单次迭代中进行的修正量。
1.3.6.1 感知器收敛定理(Perceptron Convergence Theorem)
定理内容:对于任何线性可分的数据集,感知器的学习规则保证在有限的步骤内找到一个解决方案。
这里需要三个假设:
- 至少存在至少一组权重 w ∗ w^* w∗,,使得数据集线性可分。
- 训练样本的数量是有限的。
- 阈值函数是单极的(即输出是0或1)。
1.3.7 衡量感知器
在训练过程中,可以通过均方根(Root Mean Square,RMS)误差值来衡量网络性能。
RMS = ∑ i = 1 N ( x i − x ^ i ) 2 N \text{RMS} = \sqrt{\frac{\sum_{i=1}^{N} (x_i - \hat{x}_i)^2}{N}} RMS=N∑i=1N(xi−x^i)2,这里 N N N是数据点的数量, x i x_i xi是目标输出(期望输出), x ^ i \hat{x}_i x^i是实际输出(模型的预测输出)。
RMS误差仅依赖于即时输出值。
即时输出( x i x_i xi)是输入值和连接权重( w i j w_{ij} wij)的函数。
由于即时输出依赖于权重,因此网络的性能(通过RMS误差来衡量)也仅是权重的函数。
RMS误差越小,表示模型的预测结果与实际值(目标输出)之间的差异越小,模型的性能越好。
所以网络的最佳性能对应于RMS误差的最小值。
因此为了达到最佳性能,我们需要调整连接权重,以使RMS误差最小化。
下图中展示了学习曲线,即RMS误差随训练集迭代次数的变化关系。
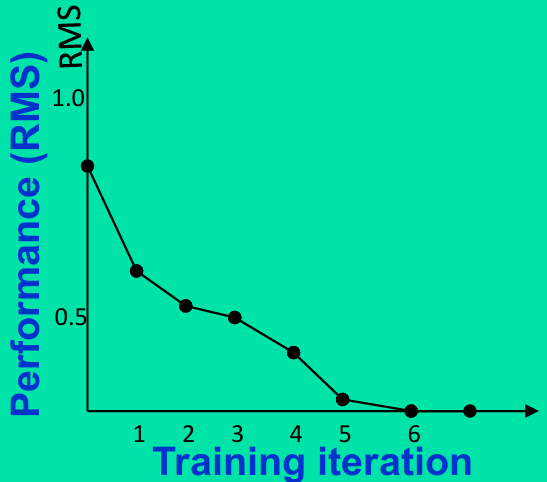
在初始阶段(第1次迭代),RMS误差较高,表明模型性能不佳。
随着迭代次数的增加,RMS误差逐渐降低,表明模型性能在提升。
在第6次迭代后,RMS误差趋于稳定,表明模型性能达到一个较好的水平。
当误差率足够低时,训练停止,网络被认为已经收敛。
1.3.7.1 感知器收敛定理(Perceptron Convergence Theorem)
因此我们可以将感知器收敛定理(Perceptron Convergence Theorem)重新理解为:如果存在一组权重,使得感知器能够正确响应所有的训练模式,那么感知器的学习方法将找到这组权重,并且它会在有限次迭代中完成这一过程。
在训练过程中,可能会发生性能停止改善的情况,即无论进行多少次迭代,RMS误差都不会变得更小。
如果发生上述情况,即性能不再提升,RMS误差不再减小,这意味着网络未能学会正确分类所有的训练样本。
如果训练是成功的,感知器被认为已经完成了监督学习过程。
完成监督学习后,感知器能够对与训练集中相似的模式进行分类。
1.3.8 感知器作为分类器
对于d维数据,感知器由d个权重、一个偏置(bias)和一个阈值激活函数组成。
对于二维数据的例子,我们有:
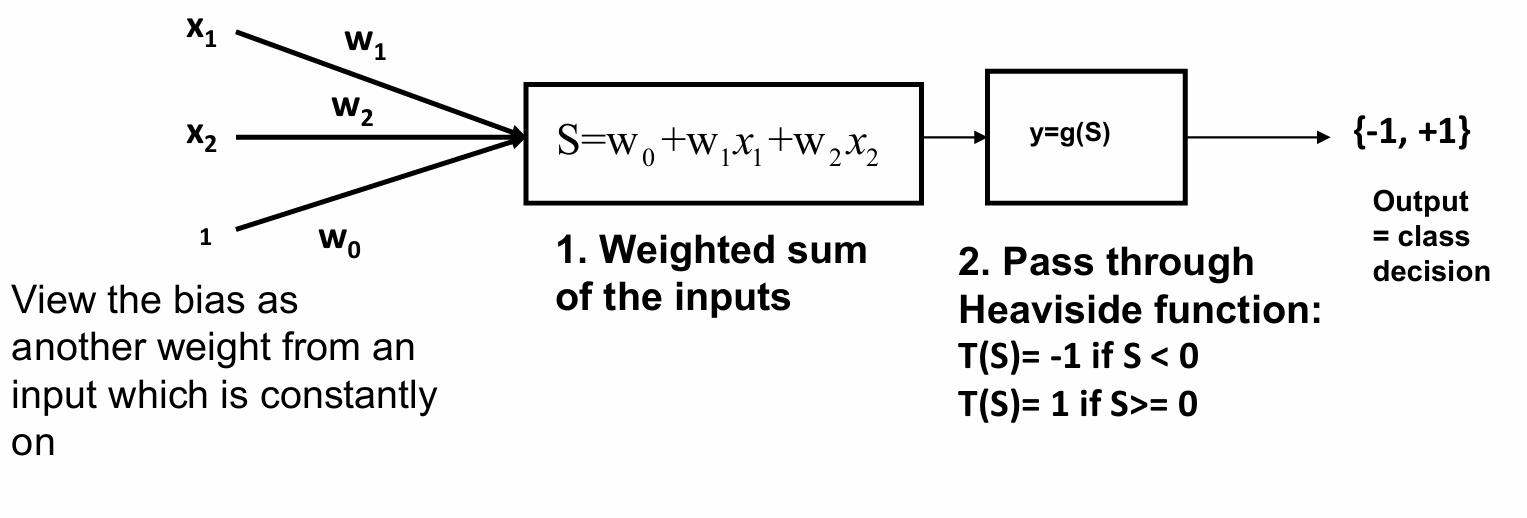
输入特征 x 1 x_1 x1和 x 2 x_2 x2通过权重 w 1 w_1 w1和 w 2 w_2 w2连接到输出单元。还有一个偏置权重 w 0 w_0 w0,可以看作是来自一个始终为1的输入(即偏置输入)。
首先计算输入特征的加权和 S = w 0 + w 1 ⋅ x 1 + w 2 ⋅ x 2 S = w_0 + w_1 \cdot x_1 + w_2 \cdot x_2 S=w0+w1⋅x1+w2⋅x2。
然后将加权和 S S S通过Heaviside函数 g ( S ) g(S) g(S)来决定最终的输出 y = g ( S ) = { − 1 , if S < 0 1 , if S ≥ 0 。 y = g(S) = \begin{cases} -1, & \text{if } S < 0 \\ 1, & \text{if } S \geq 0 \end{cases}。 y=g(S)={−1,1,if S<0if S≥0。
如果我们将权重组合成一个向量 w w w,则网络的输出 y y y可以表示为: y = g ( w ⋅ x + w 0 ) y = g(\mathbf{w} \cdot \mathbf{x} + w_0) y=g(w⋅x+w0)
感知器训练的目标是计算权重向量 W = [ w 0 , w 1 , w 2 , … , w p ] W = [w_0, w_1, w_2, \ldots, w_p] W=[w0,w1,w2,…,wp]。
例如,考虑当 p = 2 p=2 p=2时,下图展示了一个二维空间,其中 x 1 x_1 x1和 x 2 x_2 x2是两个输入特征。
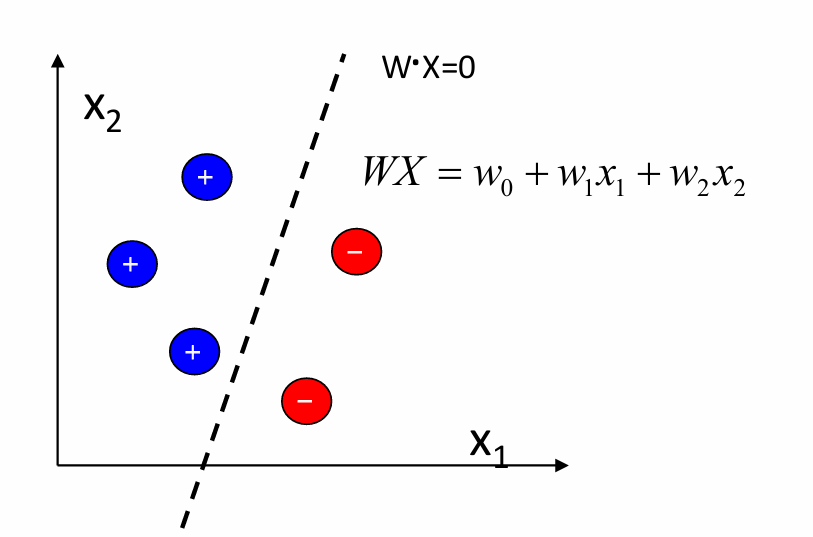
虚线 w x \mathbf{w}\mathbf{x} wx是一条直线,这个是决策边界,它将两类数据分开。
感知器通过调整权重向量来找到一个决策边界(超平面),将不同类别的数据点分开。
在二维空间中,这个决策边界是一条直线。
对于两个类别,将网络输出视为一个判别函数 y ( x , w ) y(x,w) y(x,w),其中:
y ( x , w ) = { 1 , if x is in class 1 (C1) − 1 , if x is in class 2 (C2) y(x, w) = \begin{cases} 1, & \text{if } x \text{ is in class 1 (C1)} \\ -1, & \text{if } x \text{ is in class 2 (C2)} \end{cases} y(x,w)={1,−1,if x is in class 1 (C1)if x is in class 2 (C2)
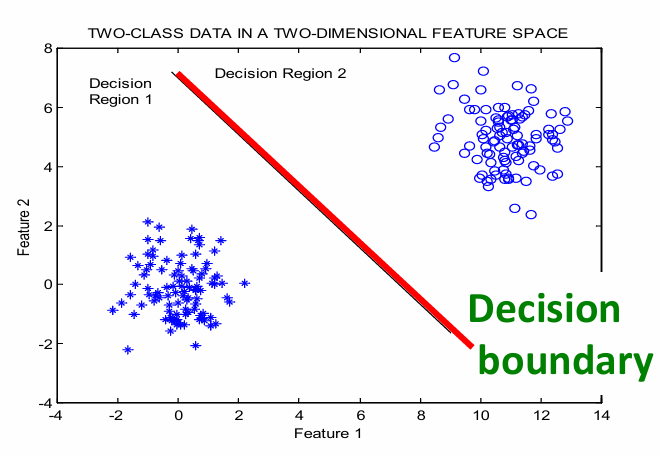
对于m个类别,分类器应该将特征空间划分为m个决策区域。
在超过2维的情况下,决策边界是一个超平面(hyperplane)。
感知器在d维空间中表示一个超平面决策表面,例如,在2维空间中是一条直线,在3维空间中是一个平面,等等。
超平面方程为: w ⋅ x T = 0 \mathbf{w} \cdot \mathbf{x}^T = 0 w⋅xT=0这是x空间中位于边界上的点的方程。
1.3.8.1 决策边界
下图展示了一个二维空间中线性可分的情况。
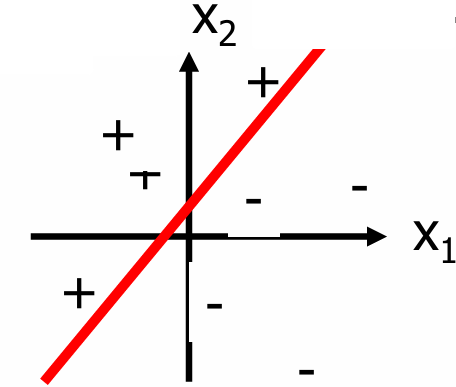
图中的红色直线是决策边界,它将数据分为两类(用“+”和“-”表示)。
下图展示了一个二维空间中线性不可分的情况。
这时数据点无法通过一条直线分开。
感知器能够表示一些有用的函数。
但是,不能表示非线性可分的函数(例如,XOR函数)。
下面给出一个感知器决策边界的例子。
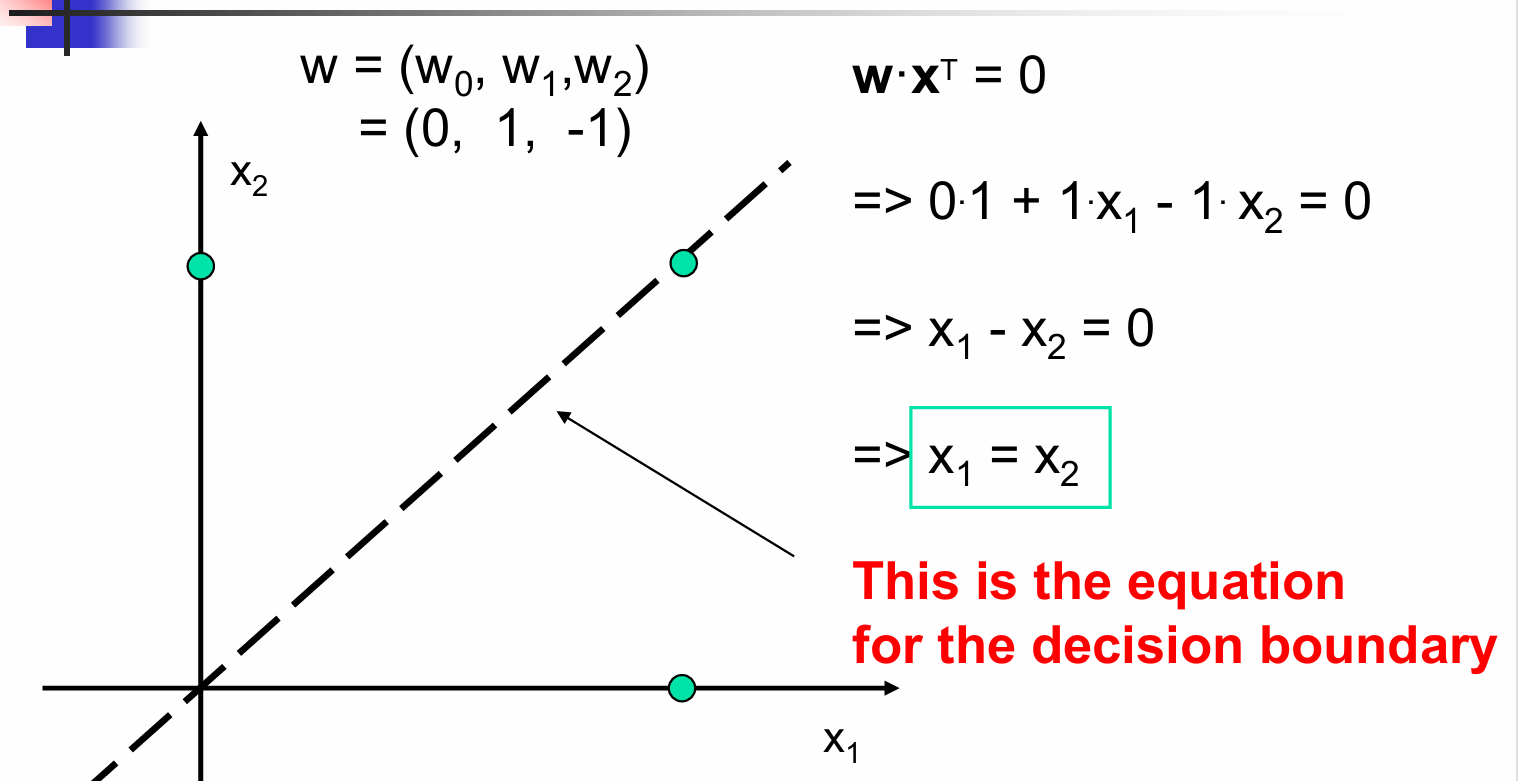
决策表面是单位输出恰好等于阈值的表面,即 ∑ w i x i = 0 \sum w_i x_i = 0 ∑wixi=0
决策边界方程: w ⋅ x T = 0 \mathbf{w} \cdot \mathbf{x}^T = 0 w⋅xT=0
展开后得到: 0 ⋅ 1 + 1 ⋅ x 1 − 1 ⋅ x 2 = 0 0 \cdot 1 + 1 \cdot x_1 - 1 \cdot x_2 = 0 0⋅1+1⋅x1−1⋅x2=0
简化后得到决策边界方程: x 1 − x 2 = 0 x_1 - x_2 = 0 x1−x2=0
进一步简化得到: x 1 = x 2 x_1 = x_2 x1=x2
在这个例子中,决策边界是 x 1 = x 2 x_1 = x_2 x1=x2,这意味着当两个输入特征相等时,输出恰好等于阈值。
当然如果 w ⋅ x T < 0 \mathbf{w} \cdot \mathbf{x}^T < 0 w⋅xT<0表示决策区域 -1,即 x 1 < x 2 x_1 < x_2 x1<x2。
同样的, w ⋅ x T > 0 \mathbf{w} \cdot \mathbf{x}^T > 0 w⋅xT>0表示决策区域 -1,即 x 1 > x 2 x_1 > x_2 x1>x2。
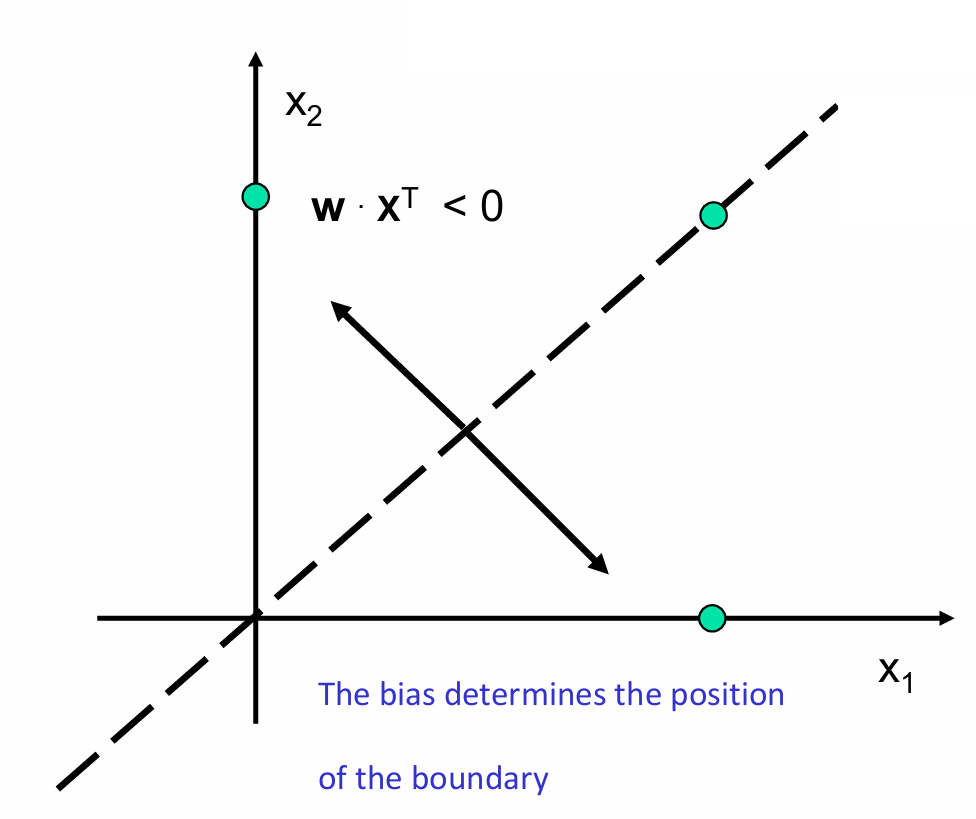
我们需要知道权重向量定义了决策边界的方向,因为权重向量 w \mathbf{w} w与决策边界垂直。而偏置决定了边界的位置。
1.3.9 线性可分问题(Linear Separability Problem)
如果两类模式可以通过一个决策边界(decision boundary)分开,这个边界可以用线性方程表示: b + ∑ i = 1 n x i w i = 0 b + \sum_{i=1}^{n} x_i w_i = 0 b+∑i=1nxiwi=0
如果数据是线性可分的,那么感知器可以正确地对任何模式进行分类。
注意:如果没有偏置项,超平面将被迫经过原点。
对于线性可分的类别,其决策边界(即权重 W W W和偏置 b b b)可以通过某些学习过程或者基于每个类别的代表性模式来解线性方程组来确定。
如果这样的决策边界不存在,那么这两类就被认为是线性不可分的。
线性不可分的问题不能通过简单的感知器网络解决,需要更复杂的架构。
我们前面给出了一个线性不可分的例子:逻辑异或(XOR)函数
我们现在具体看这个例子,其输出为1当且仅当输入变量中有一个为1,否则输出为-1。
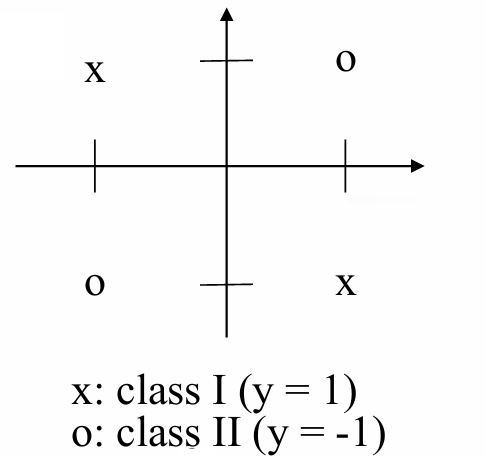
我们试图找到能够将两类数据分开的权重 w 1 w_1 w1和 w 2 w_2 w2以及偏置 b b b。
{ b − w 1 − w 2 < 0 ( 1 ) b − w 1 + w 2 ≥ 0 ( 2 ) b + w 1 − w 2 ≥ 0 ( 3 ) b + w 1 + w 2 < 0 ( 4 ) \begin{cases} b - w_1 - w_2 < 0 & (1) \\ b - w_1 + w_2 \geq 0 & (2) \\ b + w_1 - w_2 \geq 0 & (3) \\ b + w_1 + w_2 < 0 & (4) \end{cases} ⎩ ⎨ ⎧b−w1−w2<0b−w1+w2≥0b+w1−w2≥0b+w1+w2<0(1)(2)(3)(4)
从方程(1)和(4)得出 b < 0 b<0 b<0,而从方程(2)和(3)得出 b ≥ 0 b≥0 b≥0,这导致了一个矛盾,因此该线性方程组无解。
这便是线性不可分。
我们再看两个线性可分的例子:逻辑与(AND)函数和逻辑或(OR)函数。
逻辑与(AND)函数:
对于逻辑与函数,输出为1(真)当且仅当两个输入都为1时。
权重 w 1 w_1 w1和 w 2 w_2 w2都为1,偏置 b = − 1 b=-1 b=−1,阈值 θ = 0 θ=0 θ=0。
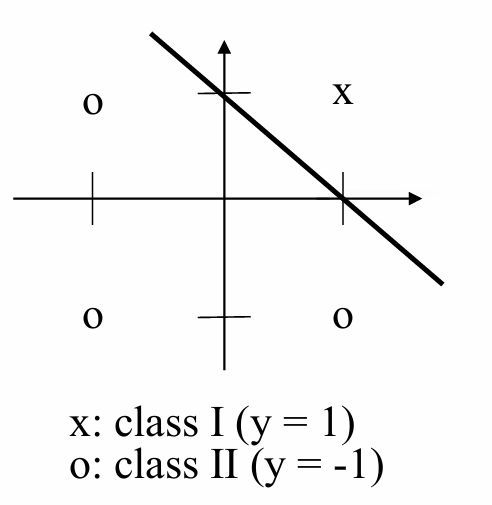
逻辑或(OR)函数:
对于逻辑或函数,输出为1(真)只要至少有一个输入为1。
权重 w 1 w_1 w1和 w 2 w_2 w2都为1,偏置 b = 1 b=1 b=1,阈值 θ = 0 θ=0 θ=0。
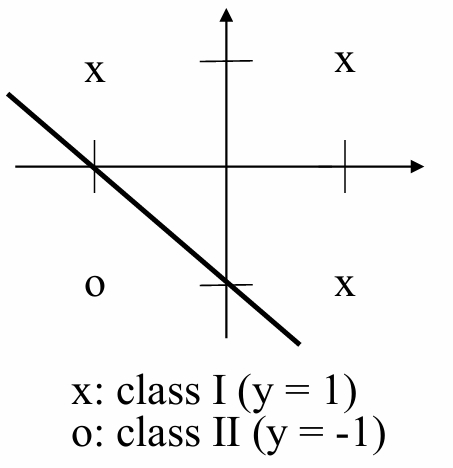
这些权重和偏置的选择是为了直观地展示如何使用感知器模型来实现基本的逻辑运算。在实际应用中,权重和偏置通常是通过训练数据来学习得到的,例如通过感知器学习规则或其他优化算法。在这两个例子中,权重和偏置是手动设置的,以直接反映逻辑与和逻辑或的数学定义,不需要掌握计算。