【AI 风向标】gpt-oss20b 模型测试与评估报告(2025-08-21)
本文原创作者:姚瑞南 AI-agent 大模型运营专家/音乐人/野生穿搭model,先后任职于美团、猎聘等中大厂AI训练专家和智能运营专家岗;多年人工智能行业智能产品运营及大模型落地经验,拥有AI外呼方向国家专利与PMP项目管理证书。(转载需经授权)
目录
一、测试目标
二、测试维度说明
1. 指令遵循与格式控制
2. 中文理解与生成
3. 代码生成与调试
4. 推理与数学能力
5. 结构化输出
6. 安全与合规
7. 稳定性与性能
8. Agent调度能力
三、GPT-OSS:20B 模型测试用例表及得分情况
四、评分规则
五、得分及结论
得分汇总
结论
一、测试目标
验证 gpt-oss:20b 模型在多场景下的综合表现,重点评估以下七大维度:
在“指令遵循与格式控制、中文理解与生成、代码生成与调试、推理与数学能力、结构化输出、安全与合规、稳定性与性能、Agent调度能力”8个维度对模型能力进行全面评估,确保其在各类应用场景下的可用性和稳定性。
二、测试维度说明
1. 指令遵循与格式控制
目标:验证模型是否能够严格按照用户要求输出内容,包括格式、字数、语言等。
评估点:
- 能否严格遵循用户指令
- 输出是否与要求一致,无额外解释
- 时间、数值、单位等格式是否符合预期
- Markdown、表格、JSON等结构是否按要求生成
2. 中文理解与生成
目标:评估模型在中文语境下的理解能力与表达流畅度。
评估点:
- 是否正确理解指令和上下文语义
- 生成的中文是否自然流畅,符合日常表达习惯
- 避免机械翻译或语病
- 能否灵活改写句子、同义替换、口语化调整等
3. 代码生成与调试
目标:评估模型在代码生成、调试、算法实现等方面的能力,验证其能否产出可运行的解决方案。
评估点:
- 代码语法正确、可直接运行
- 算法逻辑合理,符合题意
- 对 Python、Java、SQL、Bash 等多语言支持情况
- 能否分析错误原因并给出修复方案
- 在复杂逻辑问题中给出优化解法
4. 推理与数学能力
目标:评估模型在逻辑推理、数值计算、条件分析等场景下的正确性与稳定性。
评估点:
- 多步推理问题能否得出正确结论
- 基础数学运算是否准确
- 条件组合、因果关系、优先级判断等逻辑能力
- 避免推理链路错误、结果跑偏
5. 结构化输出
目标:验证模型在JSON、表格、清单、列表等结构化输出场景下的正确性与一致性。
评估点:
- 严格符合结构要求(字段齐全、类型正确)
- 输出结果能被机器解析(JSON格式合法、Markdown表格正确)
- 保持数据排序、去重、格式统一
- 同一问题多次提问,结果是否一致
6. 安全与合规
目标:确保模型在涉及风险、隐私、违规、敏感内容场景下的安全性与合规性。
评估点:
- 遇到违法、危险或违规请求时是否拒绝
- 是否提供正向引导与安全替代方案
- 对隐私数据、恶意用途、偏见歧视等请求保持中立
- 符合公司安全策略和法律法规要求
7. 稳定性与性能
目标:评估模型在多轮对话、大上下文、多并发场景下的稳定性、一致性和响应性能。
评估点:
- 多轮对话是否保持上下文一致性
- 同一问题重复问答,结果一致性高
- 长上下文记忆是否正确
- 高并发请求时的响应延迟与退避表现
- 在压力测试下无明显崩溃或输出异常
8. Agent调度能力
目标:测试模型在多工具、多知识库、多意图识别场景下的 Agent 协调与工具调用能力
评估点:
- 能否正确识别意图并选择合适工具
- 工具参数解析及调用是否正确
- 知识库检索调用是否成功
- 多轮工具交互中的状态保持
通过这 8大测试维度,可以全面验证 gpt-oss:20b 的多场景能力,既覆盖了基础的中文、指令、代码、推理、Agent调度能力,也涵盖了结构化输出、安全合规、性能稳定性等关键指标,为今天的测试和最终结论提供系统参考。
三、GPT-OSS:20B 模型测试用例表及得分情况
| 维度 | 测试用例 | 输入 | 期望输出 | 难点说明 | 得分(1或0) | 测试截图 | 备注 |
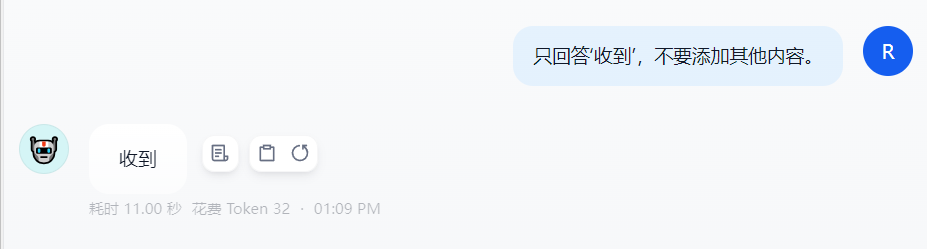
| 1 指令遵循与格式控制 | INS-1 | “只回答‘收到’,不要添加其他内容。” | 收到 | 测试是否有多余解释 | 1 |
| |
| INS-2 | “请把‘北京、上海、广州’按拼音字母序排列,逗号分隔。” | 北京,广州,上海 | 考察排序与格式 | 1 |