spiderdemo题解系列——第2篇:请求头检测挑战(第1题)
目录
- 一、分析
- 二、完整代码实现
一、分析
今天继续挑战 spiderdemo:第1题——请求头检测挑战,一起看如何复现并绕过请求头校验。
老规矩,按下 F12 打开 浏览器调试工具,切换到 Network 面板,选择下方的 Fetch/XHR 选项。接着点击页面上的页码,切换不同页的数据。结果发现请求包变红了,返回状态码 400,说明请求出问题了。我们点开数据包看看,究竟返回了什么内容。

原来有检测——它在盯着控制台。第一反应可能是去找 console.table、debugger 等等或考虑用 hook、按堆栈追查检测点,但其实没必要一开始就钻得那么深。既然打开浏览器调试工具就会被触发,不如换个抓包工具试试(Fiddler、Charles、Sunny 等),说不定它们不会被检测,直接抓到包就能分析;如果抓包也被拦,那再回头深入追踪源头也不迟。解决问题时要讲究效率:能用现成工具先省事,感兴趣并有时间再做深入学习。
关闭浏览器开发者工具,按 Ctrl+F5 强制刷新页面,点击页码翻页,查看 Fiddler 是否能抓到正常的请求包;若能,直接在 Fiddler 中分析即可。
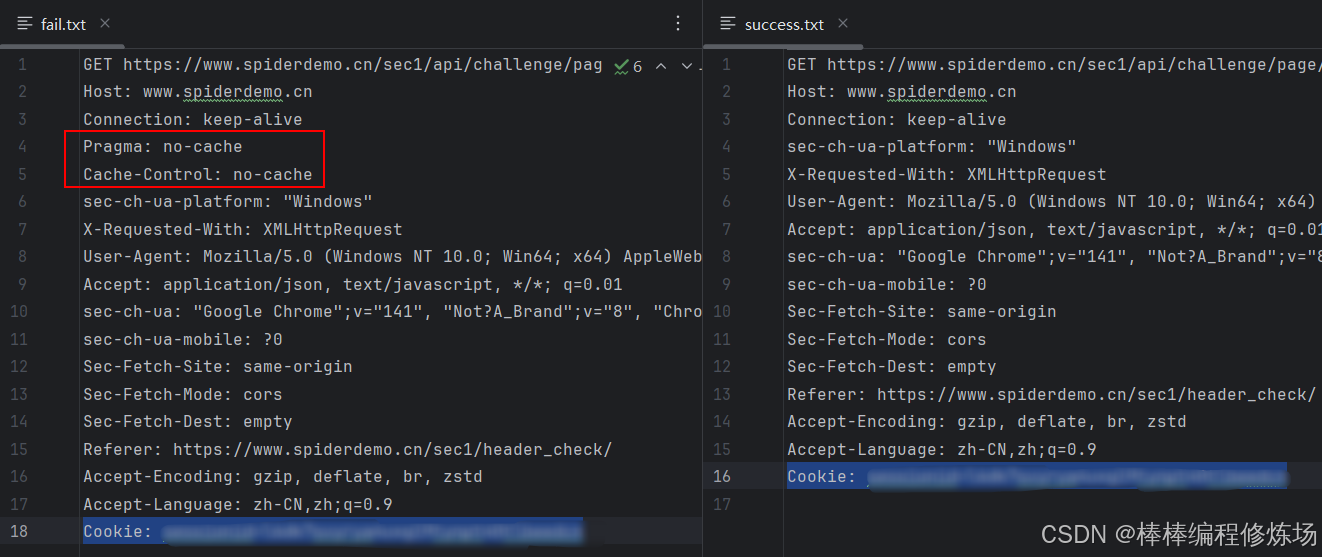
其实到这里我们已经可以直接分析请求了,但为了学习,我们还是来看看为什么一打开浏览器控制台就会被检测。在 Fiddler 中对比正常请求和出错请求后发现,出错的请求头中多了两项:Pragma: no-cache 和 Cache-Control: no-cache。那问题来了——是不是网站就是通过这两个字段来检测我们是否打开了控制台?但这两个请求头和控制台之间到底有什么关联呢?
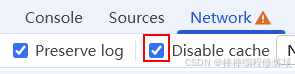
这个其实是一个值得了解的小知识点。不了解也没关系,直接问 AI 就能查到。核心原因在于:禁用缓存会改变请求头和浏览器的行为。当你在 Chrome DevTools 的 Network 面板中勾选 Disable cache 时,浏览器不仅会忽略缓存文件,还会强制在请求头中加入 Pragma: no-cache 和 Cache-Control: no-cache,从而导致请求行为发生变化。
这意味着:每次请求都必须重新从服务器获取资源,浏览器不再使用本地缓存(包括 Cookies、ETag、Service Worker 缓存等)。而某些网站会根据请求头中 Cache-Control 或 Pragma 的变化执行不同逻辑。因此,本题很可能正是因为这一点,当检测到这些请求头被修改后,服务器返回了错误的数据。
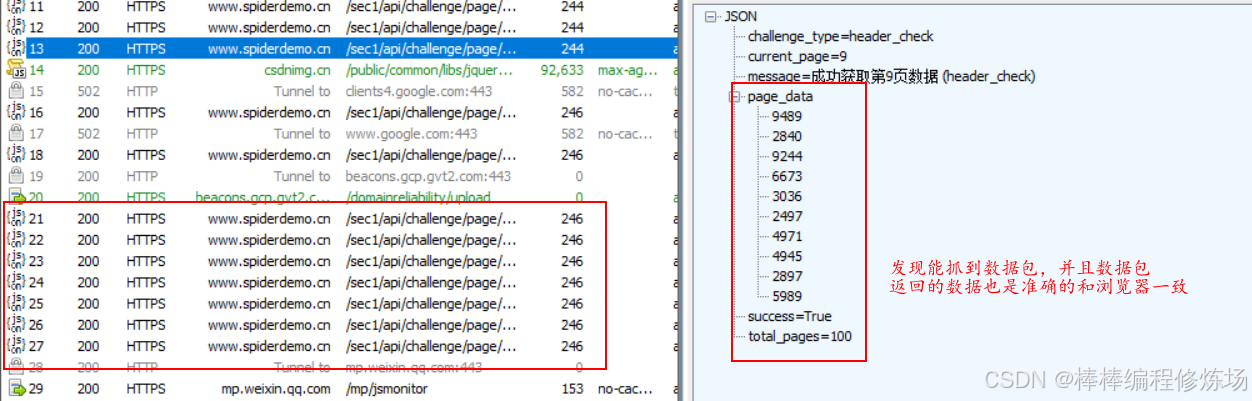
取消勾选 Disable cache,然后按 Ctrl + F5 强制刷新页面。接着打开浏览器调试工具,点击页码切换数据,发现这次能够正常抓到数据包,如下图所示。说明我们的分析是正确的,成功绕过了控制台检测。
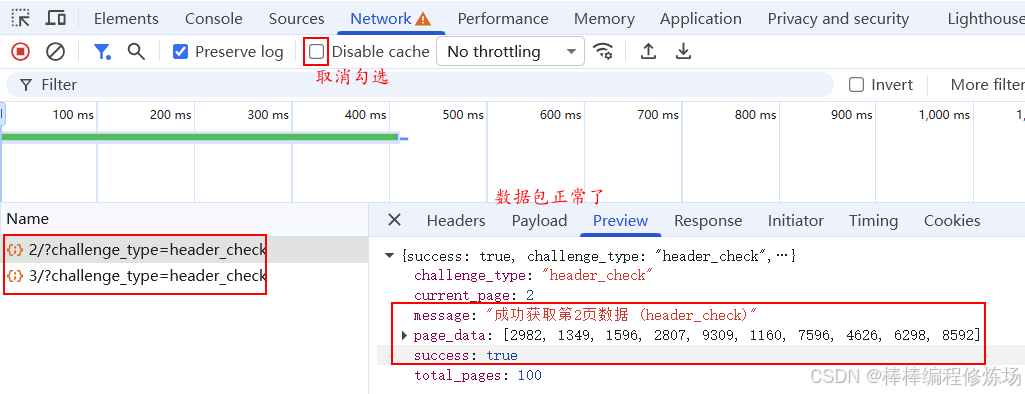
抓包正常后,我们就可以开始仔细分析数据包了。查看请求方式和 URL,发现是 GET 请求,既没有额外的请求参数,也没有加密;再看看请求头,似乎也没有什么特别之处:
GET https://www.spiderdemo.cn/sec1/api/challenge/page/19/?challenge_type=header_check HTTP/1.1
Host: www.spiderdemo.cn
Connection: keep-alive
Pragma: no-cache
Cache-Control: no-cache
sec-ch-ua-platform: "Windows"
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome......
Accept: application/json, text/javascript, */*; q=0.01
sec-ch-ua: "Google Chrome";v="141", "Not?A_Brand";v="8", "Chromium";v="141"
sec-ch-ua-mobile: ?0
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://www.spiderdemo.cn/sec1/header_check/
Accept-Encoding: gzip, deflate, br, zstd
Accept-Language: zh-CN,zh;q=0.9
Cookie: .......
接下来,我们可以右键抓取的数据包,选择 Copy ⇒ Copy as cURL (bash),复制到 https://curlconverter.com/ 转换为 Python 代码,然后在 PyCharm 中进行请求测试。结果发现返回的数据仍然是错误的,如下图所示:
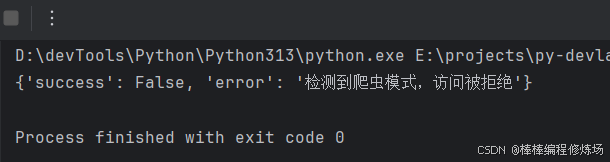
当我们发现请求的 请求头 都与浏览器一致时,也没有加密,但数据仍无法正常返回时,就需要考虑是否存在 TLS 指纹检测,或者当前使用的请求库存在问题。这时可以尝试换一个请求库,看是否能成功获取数据。先换个请求库吧,requests 不行,我们改用 httpx 库试试,结果发现用 httpx 可以正常获取数据,如下图所示:

紧接着我们验证到:使用能伪装/绕过 TLS 指纹的库(如 curl_cffi)也能成功请求并拿到正确数据:

二、完整代码实现
# -*- coding: utf-8 -*-
"""
@File : t1.py
@Author : bb_bcxlc
@Date : 2025-10-19 21:57
@Blog : https://blog.csdn.net/xw1680
@Tool : PyCharm
@Desc :
"""import httpx
from concurrent.futures import ThreadPoolExecutor, as_completed
import threadingclass HeaderCheckClient:def __init__(self, cookies: dict, headers: dict, base_url: str, max_workers: int = 10):self.cookies = cookiesself.headers = headersself.base_url = base_urlself.params = {'challenge_type': 'header_check'}self.result = 0self.lock = threading.Lock() # 保证 result 累加安全self.max_workers = max_workersself.client = httpx.Client(cookies=self.cookies, headers=self.headers) # 单例客户端def fetch_page(self, page_number: int):"""请求单页数据,并安全累加 result"""res = self.client.get(f'{self.base_url}/page/{page_number}/', params=self.params)data = res.json()print(data) # 打印每页返回内容page_sum = sum(data.get('page_data', []))# 使用锁保证累加安全with self.lock:self.result += page_sumdef run_multithread(self, start: int = 1, end: int = 101):"""多线程请求页面"""with ThreadPoolExecutor(max_workers=self.max_workers) as executor:futures = [executor.submit(self.fetch_page, i) for i in range(start, end)]# 等待所有线程完成for _ in as_completed(futures):passprint(f"Total sum: {self.result}")def close(self):self.client.close() # 关闭客户端if __name__ == "__main__":cookies = {'sessionid': '填写你自己的sessionid',}headers = {'accept': 'application/json, text/javascript, */*; q=0.01','accept-language': 'zh-CN,zh;q=0.9','priority': 'u=1, i','referer': 'https://www.spiderdemo.cn/sec1/header_check/','sec-ch-ua': '"Google Chrome";v="141", "Not?A_Brand";v="8", "Chromium";v="141"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"','sec-fetch-dest': 'empty','sec-fetch-mode': 'cors','sec-fetch-site': 'same-origin','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36','x-requested-with': 'XMLHttpRequest',}client = HeaderCheckClient(cookies, headers, "https://www.spiderdemo.cn/sec1/api/challenge")client.run_multithread()client.close()
运行程序并提交结果如下:
