AI大事记12:Transformer 架构——重塑 NLP 的革命性技术(下)
4 从 Transformer 到现代大模型的演进
4.1 Transformer:大模型的基石架构
在当今的大模型时代,Transformer 架构已经成为了所有主流大语言模型的基础。无论是 OpenAI 的 GPT 系列、Google 的 PaLM 系列、Anthropic 的 Claude,还是中国的文心一言、通义千问,无一不是基于 Transformer 架构构建的。
GPT 系列的发展历程充分展示了 Transformer 的强大生命力。从 2018 年的 GPT-1(1.17 亿参数)开始, 2019 年的 GPT-2(15 亿参数),2020 年的 GPT-3(1750 亿参数),2023 年的 GPT-4,2025年的GPT-5(被描述为 OpenAI “迄今为止最强大的大模型)。每一代模型都在 Transformer 架构的基础上不断扩大规模,提升能力。
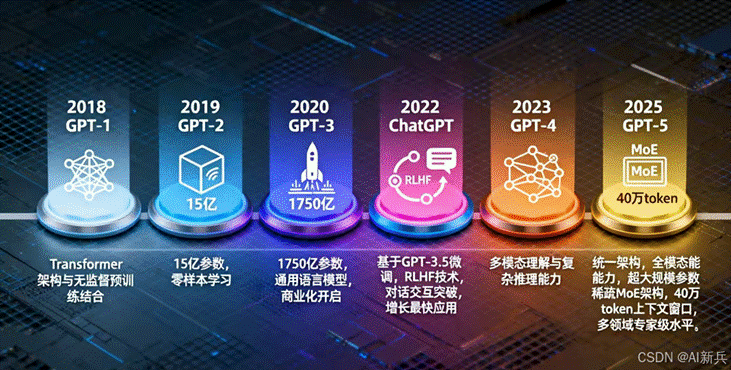
图 5 GPT 系列
Google 的 PaLM 系列同样基于 Transformer 架构。PaLM 2 拥有 5400 亿参数,在推理能力上有了显著提升。而最新的 Gemini 系列更是采用了多模态 Transformer 架构,能够同时处理文本、图像、音频等多种信息。
这些大模型的成功都离不开 Transformer 架构的三大优势:高效的并行计算能力使得训练万亿参数模型成为可能;强大的长距离依赖建模能力让模型能够理解复杂的上下文关系;灵活的架构设计支持各种改进和扩展,如稀疏注意力、混合专家模型等。
4.2 技术创新:从 BERT 到 GPT-4 的突破
尽管 Transformer 架构已经非常强大,但研究者们仍在不断探索新的技术创新,以进一步提升模型性能和效率。
混合专家模型(MoE)是近年来的一个重要创新。这种架构将多个专门化的 "专家" 模型组合在一起,根据输入内容动态选择最合适的专家进行处理。DeepSeek-V3.1-Terminus 采用了深度优化的混合专家系统 DeepSeekMoE,通过动态更新每个专家的偏置来维持专家的负载均衡,使专家利用率从传统 MoE 的 12% 提升至 89%,且无损模型效果。
稀疏注意力机制是另一个重要方向。标准 Transformer 的注意力机制计算复杂度为 O (n²),这在处理超长序列时是一个巨大的瓶颈。研究者们提出了多种稀疏注意力方案,如 Longformer 的滑动窗口注意力、BigBird 的全局 + 局部 + 随机注意力等,通过限制每个位置的关注范围来降低计算复杂度。
线性注意力机制则通过数学变换将注意力计算的复杂度从 O (n²) 降至 O (n)。Linformer 通过低秩投影实现线性化,Performer 通过核函数近似实现线性计算,这些方法在保持性能的同时大大提高了效率。
位置编码的改进也在持续进行。RoPE(旋转位置编码)通过对查询和键向量进行旋转来注入位置信息,在处理长序列时表现优于传统的正弦余弦位置编码。Alibi 等相对位置编码方法则通过注意力偏差来表示位置关系,进一步提升了模型性能。
4.3 多模态 AI 的新机遇
Transformer 架构的一个重要发展方向是多模态 AI。传统的 Transformer 主要处理文本序列,但随着技术的发展,研究者们开始将 Transformer 应用于图像、音频、视频等多种模态的处理。
在计算机视觉领域,Vision Transformer(ViT)将图像分割成固定大小的块(patches),将这些块线性嵌入后,添加位置编码,然后输入到标准的 Transformer 编码器中。ViT 在 ImageNet 等图像分类任务上取得了与 CNN 相当甚至更好的性能,证明了 Transformer 在视觉领域的潜力。
在语音识别领域,研究者们提出了基于 Transformer 的语音识别模型,直接将语音信号转换为文本,跳过了传统的特征提取步骤。这种端到端的方法不仅简化了系统架构,还提高了识别准确率。
在多模态理解方面,研究者们正在探索如何让 Transformer 同时理解文本、图像、音频等多种信息。例如,CLIP 模型通过对比学习训练文本编码器和图像编码器,能够理解图像和文本之间的语义关联;DALL-E 系列模型则能够根据文本描述生成相应的图像。
5 Transformer:智能时代的基石
回顾 Transformer 架构从 2017 年诞生到现在的发展历程,我们看到了一项技术如何改变整个产业。从最初的机器翻译需求出发,Transformer 不仅解决了传统架构的技术瓶颈,更开启了人工智能的新纪元。它让机器能够理解和生成人类语言,能够处理多种模态的信息,能够在各种复杂任务上超越人类水平。
Transformer 的成功告诉我们,创新往往来自于对传统思维的突破。当所有人都在 RNN 和 CNN 的框架内修修补补时,Google 的研究者们大胆地提出了完全基于注意力机制的架构,这种颠覆性的创新带来了革命性的影响。
展望未来,虽然我们可能会开发出比 Transformer 更好的架构,但 Transformer 所奠定的基础 ——并行计算、全局建模、预训练范式—— 将继续影响 AI 的发展。它不仅是一个技术成就,更是一种思维方式,推动着我们不断探索智能的边界。
随着 Transformer 模型规模的不断增大,如何在资源受限的边缘设备上部署这些模型成为了一个重要挑战。研究者们提出了多种技术来解决这个问题。
模型压缩技术包括剪枝、量化、知识蒸馏等方法。通过去除不重要的参数、降低参数精度、将大模型的知识迁移到小模型等方式,可以在保持模型性能的同时大幅减少模型大小和计算需求。例如,DistilBERT 是 BERT 的蒸馏版本,参数减少了 40%,但保留了 97% 的性能,推理速度提升了 60%。
硬件加速技术则通过专用芯片或优化的计算库来提高 Transformer 模型的推理效率。例如,Google 的 TPU 专门为 Transformer 设计,能够高效执行矩阵运算;NVIDIA 的 GPU 通过 CUDA 和 cuDNN 库提供了优化的 Transformer 推理支持;一些公司还开发了专门的 AI 芯片来加速 Transformer 模型的部署。
算法优化方面,研究者们提出了多种高效的推理算法。例如,FlashAttention 通过优化内存访问模式来提高 GPU 利用率;FasterTransformer 通过融合多个操作、优化内存布局等方式来提高推理速度。