Python机器学习---3.分类模型评估
分类模型评估是在机器学习中⽤于衡量分类模型性能的⼀种重要⽅法。评估分类模型的性能有助于理解模型对于不同类别的预测表现,为模型选择、调整和⽐较提供依据。以下是分类模型评估的⼀些常⻅⽤途:
-
模型选择和调整:在建⽴机器学习模型时,存在多种算法和模型参数的选择。通过使⽤不同的评估指标,如准确率、精确率、召回率、F1 分数等,可以帮助选择最适合任务的模型,并调整模型参数以提⾼性能。
-
⽐较不同模型:当有多个模型可供选择时,通过对它们的性能进⾏⽐较,可以确定哪个模型更适合解决特定问题。不同的评估指标提供了对模型在不同⽅⾯性能的不同视⻆。
-
发现模型的局限性:模型在某些情况下可能表现得很好,但在其他情况下可能效果差。通过深⼊了解模型的性能,可以识别模型在哪些类别或情境下性能较差,从⽽进⾏改进。
-
调整类别权重:当不同类别的样本数量不平衡时,例如正类别样本远远少于负类别样本,通过调整类别权重或使⽤合适的评估指标(如召回率)可以更好地适应不平衡数据。
-
制定业务决策:在⼀些应⽤中,对于不同类别的错误可能具有不同的代价。通过了解混淆矩阵和相关指标,可以为业务决策提供⽀持,例如在医学诊断中避免漏诊。
-
提⾼模型解释性:分类模型的评估结果可以帮助解释模型的预测,了解模型在不同情况下的表现,以及哪些特征对于模型的决策起到关键作⽤。
常⻅的分类模型评估指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1 分数、ROC 曲线和AUC-ROC 等。选择哪些指标取决于具体问题的要求和关注点。
如下是我们的一个二分类的模型,数据是sklearn包自带的。
# 获取数据
data = datasets.load_breast_cancer()
# print(data)# 确定目标列和特征列
X = data.data
y = data.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, random_state=0)# 模型实例化
lg = LogisticRegression()# 拟合
lg.fit(X_train, y_train)# 预测
Y = lg.predict(X_test)
# print("预测", Y)# 可视化
plt.figure(figsize=(12, 8))
plt.rcParams['font.family'] = 'Microsoft YaHei'
plt.plot(y_test, marker='o', ls='', c='r', label='真实类别')
plt.plot(Y, marker='X', ls='', c='g', label='预测类别')
plt.legend()
plt.xlabel('样本序号')
plt.ylabel('类别')
plt.show()混淆矩阵:混淆矩阵(Confusion Matrix)是在分类问题中⽤于评估模型性能的⼀种表格。它展示了模型在不同类别上的分类结果,包括真正例(True Positive,TP)、假正例(False Positive,FP)、真负例(True Negative,TN)和假负例(FalseNegative,FN)。混淆矩阵的每⼀列代表模型预测的类别,每⼀⾏代表实际的类别。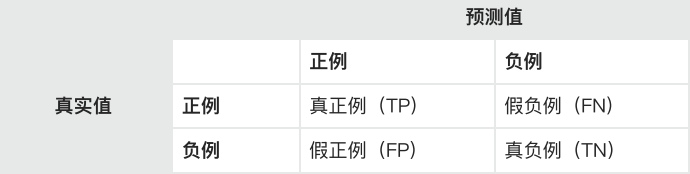
-
True Positive (TP): 正类别实例被正确地预测为正类别。
-
False Positive (FP): 负类别实例被错误地预测为正类别。
-
True Negative (TN): 负类别实例被正确地预测为负类别。
-
False Negative (FN): 正类别实例被错误地预测为负类别。
如下是基于上面二分类模型所制作的混淆函数。
# 获取数据
data = datasets.load_breast_cancer()
# print(data)# 确定目标列和特征列
X = data.data
y = data.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, random_state=0)# 模型实例化
lg = LogisticRegression()# 拟合
lg.fit(X_train, y_train)# 预测
Y = lg.predict(X_test)
# print("预测", Y)# 可视化
plt.figure(figsize=(12, 8))
plt.rcParams['font.family'] = 'Microsoft YaHei'
plt.plot(y_test, marker='o', ls='', c='r', label='真实类别')
plt.plot(Y, marker='X', ls='', c='g', label='预测类别')
plt.legend()
plt.xlabel('样本序号')
plt.ylabel('类别')
# plt.show()# 混淆矩阵
matrix = confusion_matrix(y_test, Y)# 矩阵可视化
plt.figure(figsize=(8,6))
class_name = ['benign', 'malignant']
sns.heatmap(matrix, annot=True, xticklabels=class_name, yticklabels=class_name, cmap=plt.cm.RdYlGn, fmt='d', alpha=0.6)
# plt.show()评估指标:
-
正确率(Accuracy)
-
定义:正确分类的样本数占总样本数的⽐例。
-
计算公式:
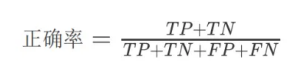
-
适⽤场景:当类别分布均匀或各类别的重要性相近时。
-
-
精确率(Precision)
-
定义:正类别实例被正确地预测为正类别的⽐例。
-
计算公式:

-
适⽤场景:当关注假正例的代价较⾼时,或在不同类别的样本数量不平衡的情况下。
-
-
召回率(Recall)
-
定义:真实的正类别样本中有多少被模型正确地预测为正类别。
-
计算公式:
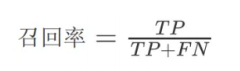
-
适⽤场景:当关注假负例的代价较⾼时,或需要尽量捕获所有正类别样本的情况下。
-
-
F1 分数
-
定义: 精确率和召回率的调和平均数。
-
计算公式:

-
适⽤场景:综合考虑精确率和召回率时使⽤。
-
如下是基于上面二分类模型的评估指标。
# 获取数据
data = datasets.load_breast_cancer()
# print(data)# 确定目标列和特征列
X = data.data
y = data.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, random_state=0)# 模型实例化
lg = LogisticRegression()# 拟合
lg.fit(X_train, y_train)# 预测
Y = lg.predict(X_test)
# print("预测", Y)# 可视化
plt.figure(figsize=(12, 8))
plt.rcParams['font.family'] = 'Microsoft YaHei'
plt.plot(y_test, marker='o', ls='', c='r', label='真实类别')
plt.plot(Y, marker='X', ls='', c='g', label='预测类别')
plt.legend()
plt.xlabel('样本序号')
plt.ylabel('类别')
# plt.show()# 评估指标
print("正确率:", accuracy_score(y_test, Y))
print("精确率:", precision_score(y_test, Y))
print("召回率:", recall_score(y_test, Y))
print("f1调和平均值:", f1_score(y_test, Y))ROC曲线:ROC(Receiver Operating Characteristic)曲线是⼀种⽤于评估⼆分类模型性能的图形⼯具。它显示了在不同阈值下真正例率(True Positive Rate,⼜称为灵敏度或召回率)与假正例率(False Positive Rate,FPR)之间的关系。ROC 曲线的横轴是 FPR,纵轴是 TPR。以下是这些术语的定义:
-
True Positive Rate (TPR): 正类别样本被正确地预测为正类别的⽐例,计算公式为 TP/(TP+FN)。
-
False Positive Rate (FPR): 负类别样本被错误地预测为正类别的⽐例,计算公式为 FP/(FP+TN)。
如下是基于上面二分类模型的绘制的ROC曲线。
# 获取数据
data = datasets.load_breast_cancer()
# print(data)# 确定目标列和特征列
X = data.data
y = data.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, random_state=0)# 模型实例化
lg = LogisticRegression()# 拟合
lg.fit(X_train, y_train)# 预测
Y = lg.predict(X_test)
# print("预测", Y)# 可视化
plt.figure(figsize=(12, 8))
plt.rcParams['font.family'] = 'Microsoft YaHei'
plt.plot(y_test, marker='o', ls='', c='r', label='真实类别')
plt.plot(Y, marker='X', ls='', c='g', label='预测类别')
plt.legend()
plt.xlabel('样本序号')
plt.ylabel('类别')
# plt.show()# 绘制ROC曲线,第一步获取它的概率
y_prob = lg.predict_proba(X_test)[:,1]
fpr, tpr, thresholds = roc_curve(y_test, y_prob)
roc_auc = auc(fpr, tpr)
print(roc_auc)# ROC曲线可视化
plt.figure(figsize=(8, 6))
plt.plot([0, 0, 1], [0, 1, 1], lw=2, ls='-.', label='完美预测')
plt.plot(fpr, tpr, color='orange', lw=2, label='roc_auc')
plt.plot([0, 1], [0, 1], lw=2, ls='-.', label='随机预测', color='green')
plt.xlabel('假正例率(fpr)')
plt.ylabel('真正例率(tpr)')
plt.title('ROC曲线')
plt.legend()
# plt.show()