【C++】list的使用及底层逻辑实现
目录
一 list介绍及使用
1 list介绍
2 list使用
(1)list的构造
(2)list iterator的使用
迭代器从功能角度的分类:
(3)list的sort
二 list 和vector的核心区别
三 list的底层逻辑及部分源代码
四 自己实现List
(1)push_back
(2)iterator
(3)insert
(4)erase
(5)size
(6)头插头删 尾插尾删
(7)链表核心框架实现
a 链表类及核心类型定义
b 迭代器接口
c 初始化函数
d 构造函数(多种初始化方式)
e 析构函数
f 拷贝控制 (深拷贝)
g 私有成员变量
(8)operator** 和operator->
一 list介绍及使用
1 list介绍
在 C++ 中,std::list 是标准模板库(STL)提供的双向链表容器,其底层实现基于双向链表数据结构,每个元素(节点)包含数据域和两个指针域(分别指向前后节点)。
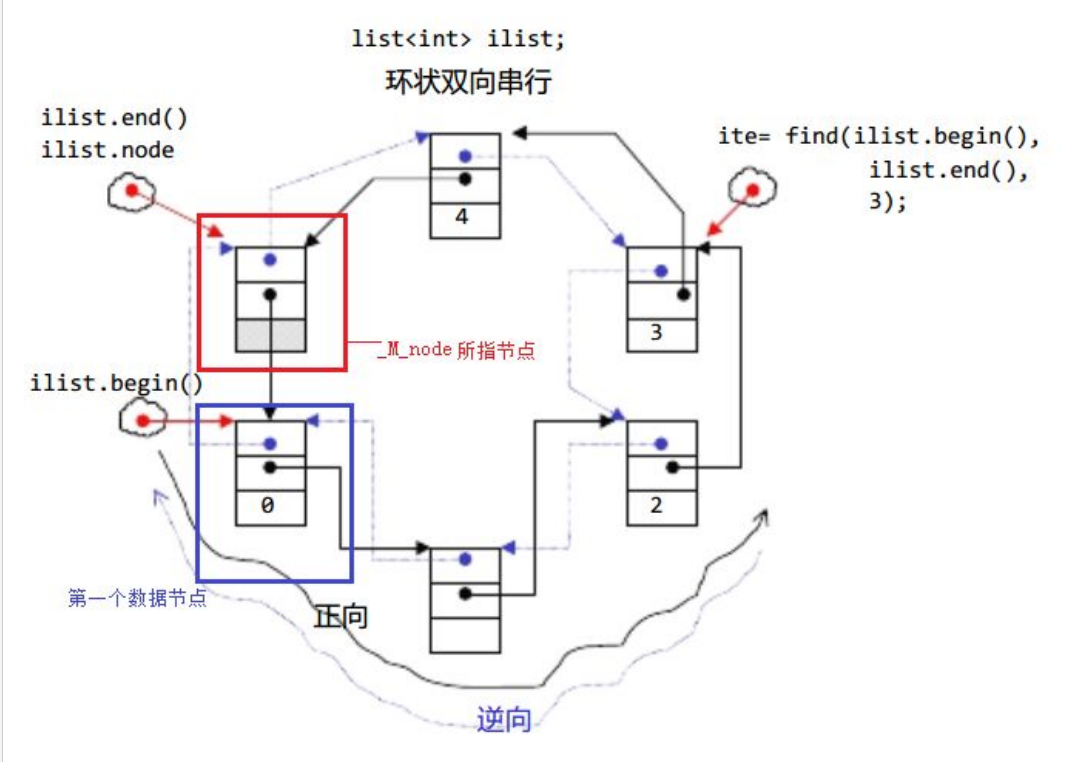
可以将list理解为:带头双向循环链表
list文档介绍:http://www.cplusplus.com/reference/list/list/?kw=list
2 list使用
list中的接口比较多,和string,vector中的类似,只需要掌握如何正确的使用,然后再去深入研究背后的原理,已达到可扩展的能力。以下为list中一些常见的重要接口。
(1)list的构造
| 构造函数(constructor) | 接口说明 |
|---|---|
vector (size_type n, const value_type& val = value_type()) | 构造的 vector 中包含 n 个值为 val 的元素 |
vector() | 构造空的 vector |
vector (const vector& x) | 拷贝构造函数 |
vector (InputIterator first, InputIterator last) | 用 [first, last) 区间中的元素构造 vector |
(2)list iterator的使用
迭代器从功能角度的分类:
迭代器分为:单向迭代器(+ + ) 双向迭代器(++ --) 随机迭代器(++ -- + -)
是由容器的底层结构决定
| 迭代器类型 | 核心功能限制 | 典型容器 | 无法支持的操作 / 算法示例 |
|---|---|---|---|
| 输入迭代器 | 只读、单向移动 | istream_iterator | 写入操作(*it = val)、reverse |
| 输出迭代器 | 只写、单向移动、不可重复写 | ostream_iterator | 读取操作(val = *it)、find |
| 前向迭代器 | 不可反向移动(无 --) | forward_list | 反向遍历(--it)、rbegin() |
| 双向迭代器 | 不可随机访问(无 it + n) | list、map | 下标访问([])、std::sort |
| 随机访问迭代器 | 无核心限制 | vector、array | 无(兼容所有弱迭代器场景) |



(3)list的sort
list不支持算法库里的sort(核心是快速排序),因为sort对迭代器的功能有要求,必须是随机迭代器,而list是双向迭代器
debug不能作为判断性能的标准,尤其是判断递归
虽然list自己实现了一个sort,核心是归并排序,但是不建议使用,因为效率太差
在STL中,vector的sort是随机访问迭代器下的快速排序(平均时间复杂度O(nlogn)),而list的sort是双向迭代器下的归并排序(稳定时间复杂度为O(nlogn));数据量大时不建议用list的sort。
二 list 和vector的核心区别
list的核心缺陷是没有办法做下标随机访问、
| 对比维度 | vector | list |
|---|---|---|
| 底层数据结构 | 动态数组(连续内存空间) | 双向链表(非连续内存,节点含前后指针) |
| 随机访问支持 | 支持(通过 [] 或 at(),时间复杂度 O(1)) | 不支持(需迭代器顺序遍历,时间复杂度 O(n)) |
| 插入 / 删除效率 | 尾部操作高效(O(1));中间 / 头部操作需移动元素(O(n)) | 任意位置操作高效(仅修改指针,O(1)) |
| 内存分配 | 容量不足时重新分配更大连续空间(可能触发元素复制) | 每个节点单独分配 / 释放内存,无整体复制开销 |
| 内存利用率 | 连续空间,缓存友好,但可能存在预留空间浪费 | 非连续空间,节点含指针额外开销(内存利用率较低) |
| 迭代器稳定性 | 插入 / 删除中间元素后,该位置后的迭代器失效 | 插入 / 删除元素后,只有被删除节点的迭代器失效 |
| 适用场景 | 频繁随机访问、尾部增删为主的场景 | 频繁在任意位置插入 / 删除、对随机访问需求低的场景 |
但其实,vector和list是互补的关系,如果需要大量的存储数据,尽量选择用vector去存储数据,因为vector是连续的存储数据,在读取数据的的时候可以快速的读取。 如果需要头插,头删,建议使用list
三 list的底层逻辑及部分源代码
我们在学习源代码的时候:要学会抽丝剥茧,抓住核心,去掉不重要的部分

如果List的成员变量是vecor之类的,那么在销毁时,不仅要调用list的析构函数,还要调用vector的析构函数

四 自己实现List
(1)push_back
习惯上来说,如果类不想让访问限定符限制,就使用struct,例如下面的list_node就不想限制,因为list_node是作为链表的一个子结构,是存储每个数据的最小单元,而链表是需要大量访问数据的,就不需要访问限定符的限制,使用struct更好
这个时候就有人问了,那这样设定不就可以随便访问了吗? 但是我们有迭代器,只能从内部看出节点,外部无法看出。而且不同的平台list_node的名称也不同。
我们先来写定义和初始化部分:
#pragma oncenamespace bit
{template<class T>struct list_node{list_node<T>* _next;list_node<T>* _prev;T _data;list_node(const T& x = T()):_next(nullptr),_prev(nullptr),_data(x){}};
}然后来写push_back
void push_back(const T& x)
{Node* newnode = new Node(x);Node* tail = _head->_prev;tail->_next = newnode;newnode->_prev = tail;newnode->_next = _head;_head->_prev = newnode;
}tail是尾节点
(2)iterator
迭代器的核心使用就是解引用,找到指向的数据,在不暴露底层的情况下去访问你的数据,不管是链表,还是之后的树型结构,都是一样的访问方式,它是一种封装
迭代器的设计是一种封装,封装隐藏底层的结构差异,提供类似统一的方式访问容器
我们在写这部分的完整代码时,用了三个:类一个类封装链表,一个类封装节点。一个类封装迭代器。完整代码将会在结尾展出
在源代码的部分
 类里封装了一个节点的指针,然后重载运算符,这个时候迭代器就是这个类。*it就会调用*operator,*operator中含有节点指针指向的数据,所以迭代器解引用就会访问这个指针。
类里封装了一个节点的指针,然后重载运算符,这个时候迭代器就是这个类。*it就会调用*operator,*operator中含有节点指针指向的数据,所以迭代器解引用就会访问这个指针。
++it就会调用operator++,指向当前节点的下一个地址。
为什么要封装呢?
通过类的成员函数(如重载的 operator*、operator++ 等),可以为迭代器提供统一、简洁的接口。不管底层容器(如 list)的实现多么复杂,用户都可以用相同的方式(如 *it 访问元素、++it 移动迭代器)来操作不同容器的迭代器 通过统一的方式访问容器,不用管底层是怎么样的
那我们来自己实现一下:
//实现双向迭代器,支持前向和后向遍历
template<class T, class Ref>struct list_iterator{using Self = list_iterator<T, Ref>;using Node = list_node<T>;Node* _node;list_iterator(Node* node):_node(node){}// *it = 1Ref operator*(){return _node->_data;}// ++itSelf& operator++(){_node = _node->_next;return *this;}Self operator++(int){Self tmp(*this);_node = _node->_next;return tmp;}// --itSelf& operator--(){_node = _node->_prev;return *this;}Self operator--(int){Self tmp(*this);_node = _node->_prev;return tmp;}bool operator!=(const Self& s) const{return _node != s._node;}bool operator==(const Self& s) const{return _node == s._node;}};
using Self = list_iterator<T, Ref>:简化自身类型的使用(避免重复写
void Print(const bit::list<int>& lt)
{bit::list<int>::const_iterator it = lt.begin();while (it != lt.end()){//*it = 1;cout << *it << " ";++it;}cout << endl;
}void test_list1()
{bit::list<int> lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);lt.push_back(4);bit::list<int>::iterator it = lt.begin();while (it != lt.end()){cout << *it << " ";++it;}cout << endl;for (auto e : lt){cout << e << " ";}cout << endl;
}支持迭代器就支持范围for(范围for的底层就是迭代器)

我们来看右上角:
Node* it1和 bit::list<int>::iterator it2都保存了1这个节点,但是因为类型不一样,所以解引用后的使用也不一样。
迭代器是借助链表的指针,去访问链表的数据,但是迭代器销毁以后不会销毁节点,因为节点是归链表管,迭代器销毁了节点还在,所以迭代器不会实现析构函数
(3)insert
void insert(iterator pos, const T& x){Node* cur = pos._node;Node* prev = cur->_prev;Node* newnode = new Node(x);// prev newnode curprev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;++_size;}(4)erase
iterator erase(iterator pos)
{Node* cur = pos._node;Node* prev = cur->prev;Node* next = cur->next;prev->_next = next;next->_prev = prev;delete[] cur;--_size;return next;
}在 erase 函数中返回 next(被删除节点的下一个节点对应的迭代器),是为了保证迭代器的有效性,避免用户使用已失效的迭代器
(5)size
size_t size() const{/*size_t n = 0;for (auto& e : *this){++n;}return n;*/return _size;}private:Node* _head;size_t _size = 0;};这段代码实现了链表的
size成员函数,用于获取链表中元素的个数,同时定义了链表类的私有成员变量。核心设计思路是通过维护一个_size变量,避免每次获取大小都遍历链表,从而提升效率
这段代码实现了两种方法:
| 实现方式 | 核心逻辑 | 时间复杂度 | 优缺点 |
|---|---|---|---|
| 注释版(遍历计数) | 通过范围 for 循环遍历链表,每访问一个元素就将计数器 n 加 1,最终返回 n | O (N)(N 为链表元素个数) | 优点:无需额外维护变量,逻辑直观;缺点:每次调用 size 都要遍历整个链表,元素越多效率越低。 |
保留版(直接返回 _size) | 直接返回私有成员变量 _size 的值 | O (1)(常数时间) | 优点:无论链表有多少元素,都能瞬间返回结果,效率极高;缺点:需要在链表的增删操作(如 push_back、insert、erase)中手动维护 _size 的值(确保增删时同步 ++_size 或 --_size)。 |
因为遍历计数比较麻烦,所以我们可以直接在私有成员变量中添加一个size变量
(6)头插头删 尾插尾删
因为我们已经完成了insert的函数,所以我们可以利用函数的复用降低函数的代码长度
void push_back(const T& x){insert(end(), x);}void push_front(const T& x){insert(begin(), x);}void pop_back(){erase(--end());}void pop_front(){erase(begin());}
(7)链表核心框架实现
a 链表类及核心类型定义
template<class T>
class list
{// 节点类型定义(链表的基本存储单元)using Node = list_node<T>; // 假设list_node是已定义的节点结构体(含_data, _prev, _next)public:// 迭代器类型定义(通过模板参数控制读写权限)using iterator = list_iterator<T, T&>; // 可读写迭代器(解引用返回T&)using const_iterator = list_iterator<T, const T&>; // 只读迭代器(解引用返回const T&)// 注释:另一种迭代器实现思路(通过两个独立类)// using iterator = list_iterator<T>;// using const_iterator = list_const_iterator<T>;b 迭代器接口
// 获取非const迭代器(指向第一个元素)iterator begin(){// 头节点的_next是第一个数据节点return iterator(_head->_next);}// 获取非const迭代器(指向末尾标记,即头节点)iterator end(){// 尾后迭代器指向头节点(符合[begin, end)左闭右开区间)return iterator(_head);}// 获取const迭代器(指向第一个元素,只读)const_iterator begin() const{return const_iterator(_head->_next);}// 获取const迭代器(指向末尾标记,只读)const_iterator end() const{return const_iterator(_head);}const迭代器不是迭代器不能修改,而是指向的内容不能修改,注意const的位置,不要写错
const迭代器和普通迭代器的区别是:const迭代器不能修改---->核心在于修改是通过解引用,*it调用operator*,而operator*返回const T&,就不能修改了
c 初始化函数
private:// 初始化空链表(创建哨兵头节点,形成双向循环)void empty_init(){_head = new Node; // 创建头节点(不存储实际数据,仅作哨兵)_head->_next = _head; // 头节点的_next指向自身_head->_prev = _head; // 头节点的_prev指向自身(循环结构)}public:d 构造函数(多种初始化方式)
// 默认构造函数(初始化空链表)list(){empty_init();}// 初始化列表构造(支持list<int> l = {1,2,3})list(initializer_list<T> il){empty_init(); // 先初始化空链表// 遍历初始化列表,逐个插入元素for (auto& e : il){push_back(e); // 假设push_back已实现(尾插)}}// 迭代器区间构造(从其他容器迭代器区间初始化)template <class InputIterator>list(InputIterator first, InputIterator last){empty_init(); // 先初始化空链表// 遍历[first, last)区间,逐个插入元素while (first != last){push_back(*first); // 插入当前元素++first; // 移动到下一个元素}}// 构造n个值为val的元素(size_t版本,避免类型歧义)list(size_t n, T val = T()){empty_init();for (size_t i = 0; i < n; ++i){push_back(val);}}// 构造n个值为val的元素(int版本,与size_t重载区分)list(int n, T val = T()){empty_init();for (int i = 0; i < n; ++i){push_back(val);}}e 析构函数
~list(){clear(); // 清空所有数据节点(假设clear已实现)delete _head; // 释放头节点_head = nullptr; // 避免野指针_size = 0; // 重置大小}f 拷贝控制 (深拷贝)
第一个是现代写法,第二个是传统写法
// 拷贝构造函数(深拷贝,从另一个list复制)list(const list<T>& lt){empty_init(); // 先初始化空链表// 遍历被拷贝链表,逐个复制元素for (auto& e : lt){push_back(e);}}// 赋值运算符重载(深拷贝,支持lt1 = lt2)list<T>& operator=(const list<T>& lt){if (this != <) // 避免自我赋值(如lt1 = lt1){clear(); // 先清空当前链表的旧元素// 复制lt中的元素到当前链表for (auto& e : lt){push_back(e);}}return *this; // 支持链式赋值(如lt1 = lt2 = lt3)}g 私有成员变量
private:Node* _head; // 头节点指针(哨兵节点,不存储数据)size_t _size = 0; // 链表元素个数(需在增删操作中维护)
};(8)operator** 和operator->
// 迭代器解引用操作
// *it = 1
// Ref 返回节点数据的引用(可读或可写)
Ref operator*() // 解引用, Ref就是reference,引用的意思
{return _node->_data;
}
// operator*()返回对应数据类型的引用Ptr operator->() // 返回对应数据类型的指针
{return &_node->_data;
}这个时候我们会在模板参数里加入一个新的模板,class Ptr,这也就和源代码里的三个模板一样
template<class T, class Ref, class Ptr> // T 数据类型 <T> 提供 IntelliSense 的示例模板参数
// Ref 引用类型 (T& 或 const T&)
struct list_iterator
{// using还具有typedef没有的功能// 使用类型别名 (C++11新特性)using Self = list_iterator<T, Ref, Ptr>; // 自身类型using Node = list_node<T>; // 节点类型Node* _node; // 当前指向的节点
};// 迭代器类型定义
using iterator = list_iterator<T, T&, T*>; // 普通迭代器
using const_iterator = list_iterator<T, const T&, const T*>; // 常量迭代器
// const T* 只能读取数据,不能修改数据
operator->:返回当前节点数据的指针(Ptr类型,若为T*则可通过指针操作元素,若为const T*则只能读),支持像指针一样用it->member访问元素的成员(比如当元素是自定义结构体或类时,访问其成员变量或成员函数)
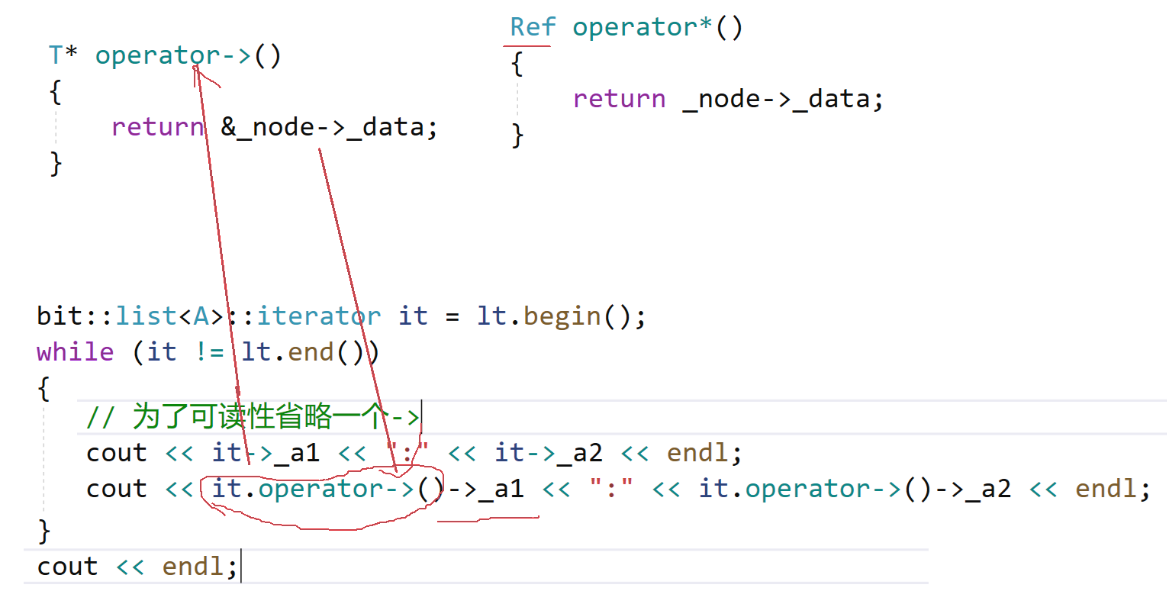
operator->返回的是指针