Kafka服务端处理producer请求原理解析
Kafka系列文章
基于Kafka2.1解读Producer原理
基于Kafka2.1解读Consumer原理
Kafka服务端NIO操作原理解析(一)
Kafka服务端NIO操作原理解析(二)
kafka服务端架构总览
文章目录
- Kafka系列文章
- 前言
- 1. dataPlaneRequestHandlerPool是什么?
- 1.1 KafkaRequestHandler
- 2. KafkaApis#handleProduceRequest
- 3. ReplicaManager#appendRecords
- 4. Partition#appendRecordsToLeader
- 5. UnifiedLog#appendAsLeader
- 6. LocalLog.append
- 7. LogSegment#append
- 总结
前言
书接上文,我们在kafka服务端架构总览结尾提出了问题,Processor放入到RequestChannel里的request被谁处理了?
当然我们也在结尾稍微提了一下:dataPlaneRequestHandlerPool
1. dataPlaneRequestHandlerPool是什么?
从变量名就可以看出来,这是一个Handler的池,实际,dataPlaneRquestHandlerPool也是KafkaServer的一个变量。在kafkaServer#startup方法中进行初始化:
// 初始化 requestHandlerPool
dataPlaneRequestHandlerPool = new KafkaRequestHandlerPool(config.brokerId, socketServer.dataPlaneRequestChannel, dataPlaneRequestProcessor, time,config.numIoThreads, s"${DataPlaneAcceptor.MetricPrefix}RequestHandlerAvgIdlePercent", DataPlaneAcceptor.ThreadPrefix)
可以看到入参会把RequestChannel作为参数传进去(socketServer.dataPlaneRequestChannel)。
而这个方法里最主要的创建了一个KafkaRequestHandlerPool,并初始化,往里面放了很多KafkaRequestHandler,同时调用了这些Handler的start方法
1.1 KafkaRequestHandler
点进去一看,原来KafkaRequestHandler继承了Runnable接口,所以,此时我们就要看KafkaRequestHandler的run()方法干了啥。
1. val req = requestChannel.receiveRequest(300):从RequestChannel里获取request
2. 根据request的类型,调用不同的方法进行handle
我们的client发过来的request,会调用KafkaApis#handle方法来进行处理。在KafkaApis#handle方法内部,又会基于request.header.apiKey调用不同的方法,而producer在封装produceRequest的时候,会将apiKey设置成ApiKeys.PRODUCE,因此producer发送过来的消息,会调用handleProduceRequest方法
2. KafkaApis#handleProduceRequest
按照咱们朴素的情感,因为producer发送过来的ProduceRequest是以node为单位的,也就是broker,实际上一个broker上可能放了好几个topicPartition的leader replica。所以是不是该基于tp维度进行循环处理?
别着急,其实这部分实际工作是ReplicaManager来实现的。kafkaApis更像是DDD服务里接口层服务+应用层服务。
1. 对发送过来的消息进行完整性校验+鉴权
2. 调用ReplicaManager#appendRecords来处理校验通过的数据
3. 把produceRequest上的数据清掉,防止一直占用内存
3. ReplicaManager#appendRecords
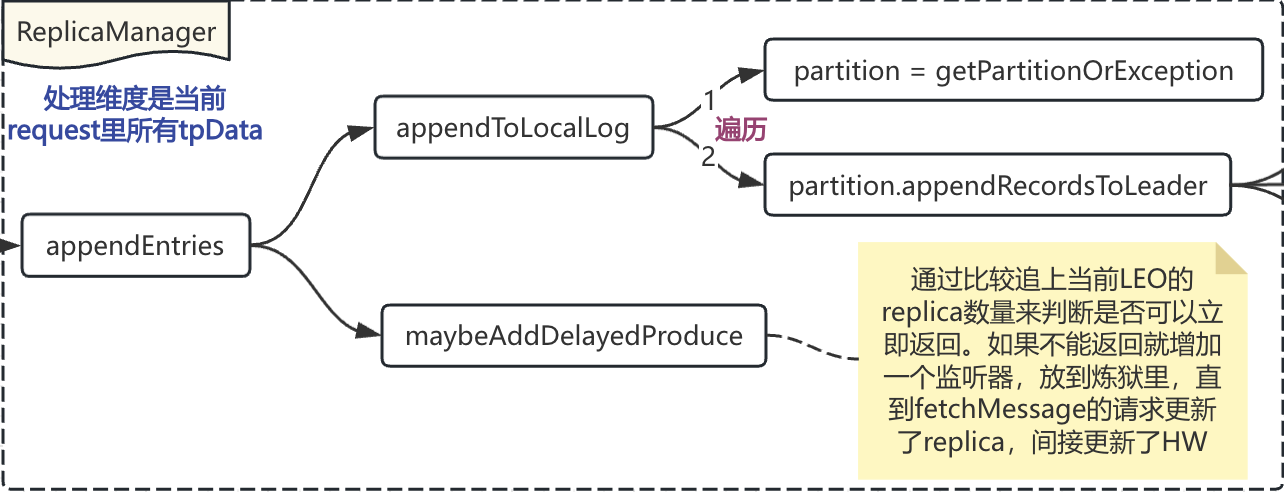
可以从示意图里看到ReplicaManager一共做了两件事:
1. 遍历tpData,将数据写入到localLog里
2. 判断是否需要立马返回response(因为producer的acks可以设置的是-1,需要等待所有的replica赶上进度)
在appendToLocalLog方法中,需要对tp维度数据进行遍历,找到当前tp维度的partition对象,调用该对象的appendRecordsToLeader方法,一般情况下,producer或者consumer在发送消息之前就已经确认了broker就是当前partition的leader,但是服务端有可能机器宕机重启,或者服务端进行了重新配置等,所以会有一些校验
4. Partition#appendRecordsToLeader
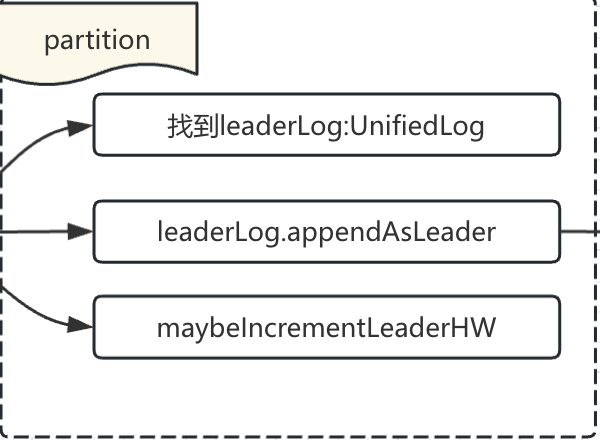
1. 找到leaderLog:其实主要是校验当前tp的leaderLog是不是在本broker
2. 通过leaderLog.appendAsLeader进行数据的真实写入
3. 写入数据之后,判断下partition的HW是否需要增长(ISR也是一直在从leader replica进行数据同步的)
5. UnifiedLog#appendAsLeader
主要逻辑是调用UnifiedLog#append完成的。
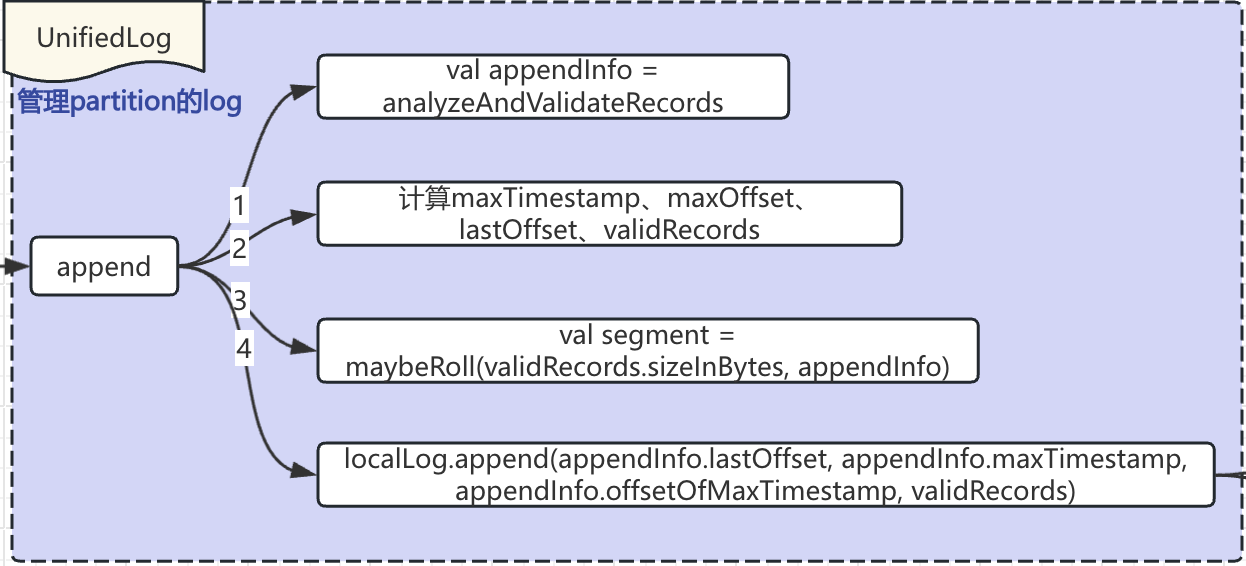
1. 分析遍历了当前tp,获得record维度数据,计算得到maxTimestamp、maxOffset、lastOffset、validRecords
2. 获取当前可以写入的segment(需要根据前面算出来的值判断是否需要roll一个新的segment文件)
3. 调用localLog.append方法,进行数据写入。localLog.append的底层还是调用的是segment.append方法
具体有哪几种情况需要roll一个Segment呢?
a. 当前Segment文件超过1G
b. 发送过来的消息时间距离现在超过7天
c. index文件超过10MB了
6. LocalLog.append
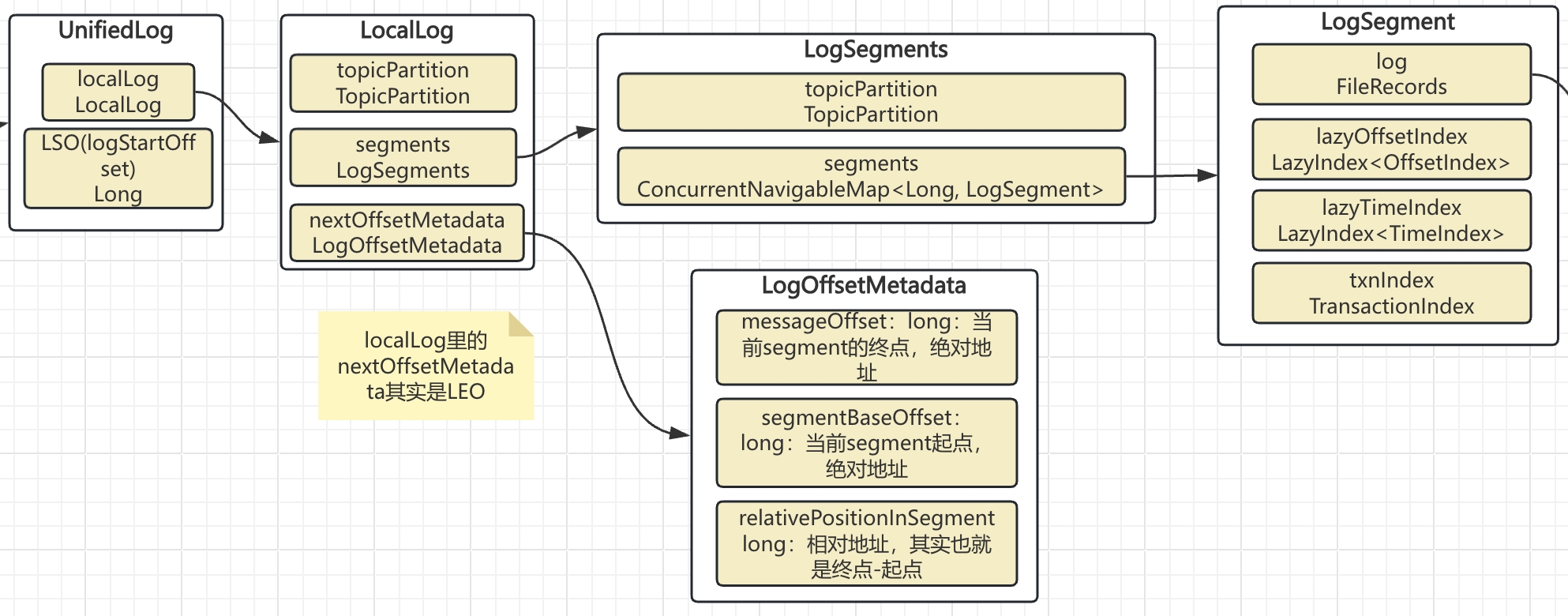
可以看到UnifiedLog和LocalLog是一对一的关系,所以UnifiedLog的作用更像是一个LocalLogManager。
LocalLog里保存了当前tp的所有的segments信息,以及当前的activeSegment的起点绝对offset、终点绝对offset、终点距离起点的offset里实际存放的字节数。相信大家已经有感觉了,这不就是保存Segment索引需要的信息么?
LocalLog主要做了两件事:
1. 当前正在使用的Segment写入数据
2. 更新当前partition的LEO
7. LogSegment#append
根据上面的示意图可以看到LogSegment里有log、lazyOffsetIndex、lazyTimeIndex、txIndex
实际该append方法也就是执行这几个文件的写入:
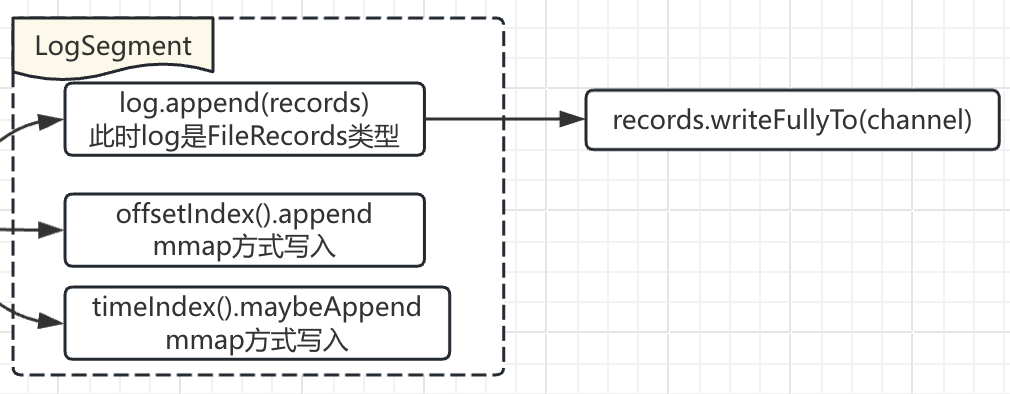
需要注意的是:
log的写入并不会进行flush,是为了性能考虑,完全靠操作系统的脏页处理机制来进行page cache到磁盘的flush
几个index通过mmap方式写入。
offsetIndex().append(largestOffset, physicalPosition);
timeIndex().maybeAppend(maxTimestampSoFar(), offsetOfMaxTimestampSoFar());

注意此处的physicalPosition,取的是当前FileRecords.file里已写入的字节数;同时index文件存储相对index的逻辑是在方法内部实现的
总结
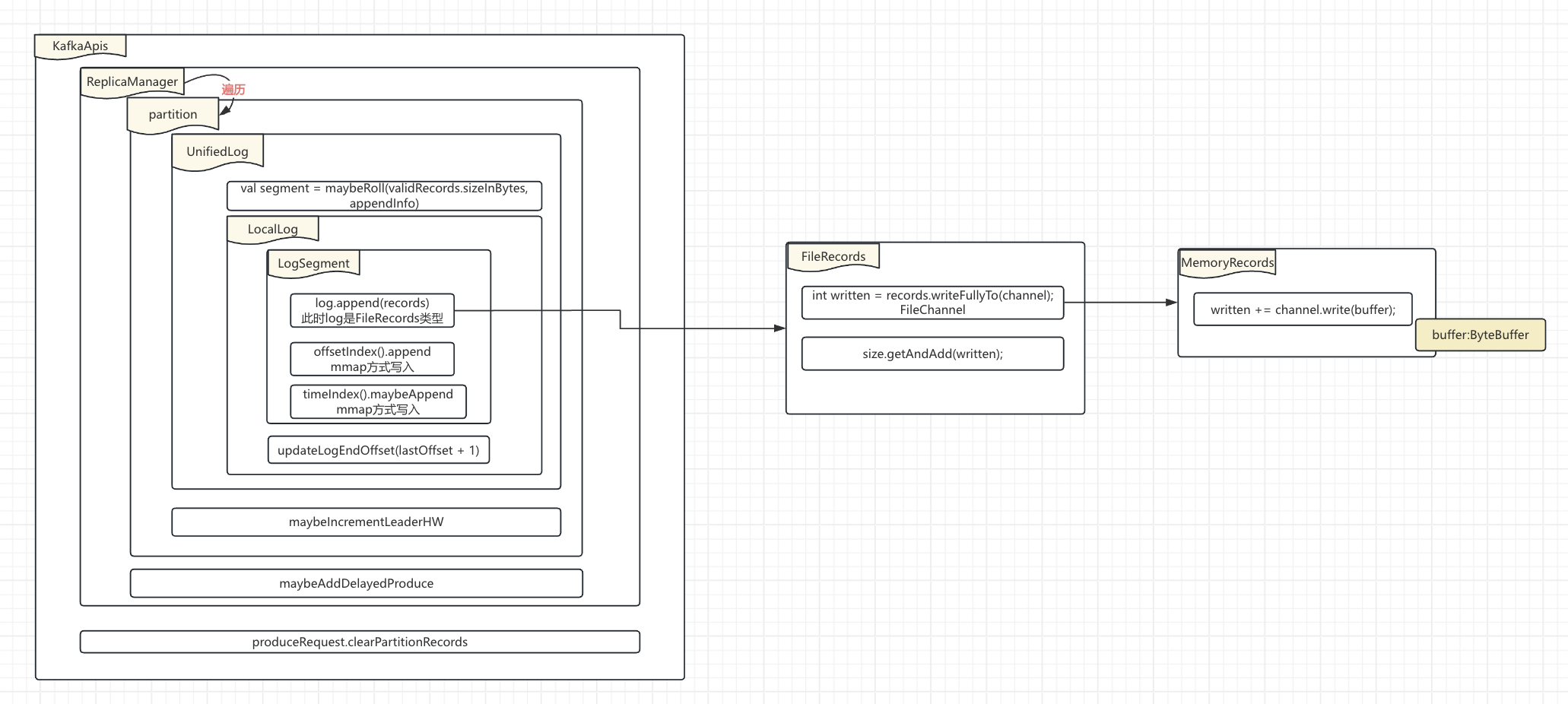
以上便是kafka服务端针对producer发过来的produceRequest的处理流程示意图。其实复杂之处在于里面类太多,每个类处理一部分信息,直至最后调用fileChannel.write进行数据写入。