【三维分割】LangSplatV2:高维的语言3DGS,快到450+FPS
标题:<LangSplatV2: High-dimensional 3D Language Gaussian Splatting with 450+ FPS>
来源:哈佛;中科院大学;清华;约翰霍普金斯大学;MIT-IBM Watson AI Lab;UMass Amhers(马萨诸塞大学阿默斯特分校)
项目主页:https://langsplat-v2.github.io
文章目录
- 摘要
- 一、LangSplat: 3D Language Gaussian Splatting(CVPR 2024 highlight)
- 1.1 使用SAM学习层次结构语义
- 1.2 Language Fields 的 3DGS
- 1.3 开放词汇查询(Open-vocabulary Querying)
- 二、Bottleneck Analysis(瓶颈分析)
- 三、3D Sparse Coefficient Field (3D稀疏系数场)
- 四、Efficient Sparse Coefficient Splatting(高效的稀疏离散系数溅射 )
- 五、实验
摘要
LangSplatV2,在高分辨率图像上实现了476.2帧/秒的高维feature splating和384.6帧/秒的三维开放词汇文本查询,相比原版LangSplat分别获得42×倍加速和47×倍性能提升,同时显著提高查询准确率。该模型采用3DGS将二维CLIP语言特征嵌入三维空间,不仅大幅提升运算速度,还能精准学习符合SAM语义的三维语言场。
LangSplat V1 即使使用先进的A100 GPU,仍无法实现实时推理(8.2帧/秒),严重制约其广泛应用。我们首先通过时间分析发现,高维 decoder是主要瓶颈。改进方案LangSplatV2创新性地将每个GS视为全局字典中的稀疏 code,从而构建出完全无需高维 decoder的三维稀疏系数场。基于这种稀疏性,我们进一步提出了一种具有CUDA优化的高效稀疏系数splatting方法,在仅产生超低维特征的计算时间成本的同时,渲染出高质量的高维特征图。
实验结果表明,LangSplatV2不仅实现了更好的或有竞争力的查询准确性,而且速度也显著更快。
一、LangSplat: 3D Language Gaussian Splatting(CVPR 2024 highlight)
Tsinghua University;Harvard University
1.1 使用SAM学习层次结构语义

SAM 可以准确地将一个像素与周围属于同一对象的像素进行分组,从而将图像分割成多个边界清晰的对象掩模。具体来说,使用32×32的规则网格进行point 提示,获得三个不同语义级别 mask: M0s、M0p、M0wM_0^s、M_0^p、M_0^wM0s、M0p、M0w,分别代表子部分、部分和整个物体。然后根据IoU评分、stability评分和mask之间的重叠率,去除集合的冗余mask。过滤后的mask 集合为: Ms、Mp、MwM^s、M^p、M^wMs、Mp、Mw,将场景划分为语义上有意义的区域,用于提取区域CLIP特征。在数学上,所获得的像素对齐的语言嵌入为(Ml(v)M^l (v)Ml(v)表示在语义级别lll上,像素vvv属于的mask):

1.2 Language Fields 的 3DGS
3D language GS,它用三个language embedding {fs,fp,fwf^s,f^p,f^wfs,fp,fw}来增强每个3DGS。这些嵌入来自于CLIP特征。增强的高斯函数被称为三维语言高斯,采用基于tile的光栅化器来保持渲染效率:

Fl(v)F^l(v)Fl(v)表示语义级别lll在像素vvv处渲染的语言嵌入。通过将语言信息直接合并到3DGS中,3DLanguage Fields 能够响应基于语言的查询。
由于CLIP嵌入是高维特征,直接在CLIP潜在空间上学习flf^lfl显著增加了内存和时间成本。与学习没有球谐系数的RGB颜色相比,学习512维CLIP特征使存储3D高斯数据的内存需求增加了35倍以上,很容易导致L1 cache内存耗尽。为了降低内存成本和提高效率,我们 引入了一种场景级别的 language autoencoder,将场景中的CLIP嵌入映射到一个较低维的潜在空间,从而减少了内存需求。CLIP模型使用4亿对(图像、文本)对进行训练,它的d维潜在空间可能非常紧凑,因为它需要在这个空间中对齐任意的文本和图像。然而,Language Fields ΦΦΦ 是特定于场景的,可以利用场景先验来压缩CLIP特征。事实上,对于每个输入图像,我们将得到数百个被SAM mask,明显小于CLIP训练中使用的图像数量。因此,一个场景中所有的mask都稀疏地分布在CLIP潜在空间中,允许我们使用一个场景特定的 Autoencoder进一步压缩这些CLIP特征
编码器EEE将DDD维CLIP特征Ltl(v)∈RDL^l_t(v)∈R^DLtl(v)∈RD映射到Htl(v)=E(Ltl(v))∈RDH_t^l(v) = E(L^l_t (v))∈R^DHtl(v)=E(Ltl(v))∈RD,其中d≪D。解码器ΨΨΨ从压缩表示重构原始CLIP嵌入。Autoencoder 在CLIP嵌入上重建目标为 (daed_{ae}dae表示距离函数,具体采用l1l_1l1和余弦距离损失):

让Language Gaussian 在特定场景的latent space 中学习 language embedding,而不是CLIP潜在空间,有fl∈Rdf^l∈R^dfl∈Rd。实验取d = 3(模型效率和准确性的均衡)。与直接建模D维CLIP嵌入相比,我们的方法通过合并场景先验显著降低了内存成本。语言嵌入的优化目标:

推理遵循等式(4),将language embedding 从3D渲染到2D,并使用场景特定解码器ΨΨΨ恢复CLIP图像嵌入 Ψ(Ftl)∈RD×H×WΨ(F_t^l)∈R^{D×H×W}Ψ(Ftl)∈RD×H×W,这允许使用CLIP文本编码器进行开放词汇表查询。
1.3 开放词汇查询(Open-vocabulary Querying)
由于CLIP模型提供的图像和文本之间的对齐空间,学到的3D language field 支持开放词汇表3D查询,包括开放词汇表3D对象定位和开放词汇表3D语义分割。许多现有的开放词汇表三维语义分割方法[24]通常从一个类别列表中选择类别,其中包括图像中出现的类别。然而,获得一个全面的野外场景类别列表是具有挑战性的。与它们不同的是,我们的方法在给定任意文本查询时生成精确的对象mask。
按照LERF计算language embeddinig ϕimgϕ_{img}ϕimg 与每个文本查询ϕqryϕ_{qry}ϕqry的相关性得分(其中,ϕcanoniϕ^i_{canon}ϕcanoni是从“object”, “things”, “stuff”,
和“texture”中选择的预定义规范短语的CLIP嵌入):

每个文本查询可以得到三个相关性映射,表示在特定的语义级别上的结果。
二、Bottleneck Analysis(瓶颈分析)
LangSplat相比其他方法实现了显著提速,但其仍无法实现高分辨率的实时开放词汇3D查询。然而,增强现实(AR)[58]、智能机器人[13]等众多应用领域对实时3D查询有着强烈需求。
给定的文本查询,LangSplat的推理过程可分为三个阶段:渲染、解码和后处理。在渲染阶段,我们将学习到的三维语言高斯转换为二维,得到渲染后的潜在特征图F∈RH×W×dF∈R^{ H×W×d}F∈RH×W×d(其中H、W分别表示二维图像的高度和宽度)。由于渲染特征图仅在低维潜在空间中编码语言特征,因此需要通过解码器 gd(F)∈RH×W×Dg_d(F)∈R^{H×W×D}gd(F)∈RH×W×D(采用MLP实现)将特征映射转换到CLIP空间。最后的后处理阶段根据LERF [13]算法计算D维特征的相关性得分,并对相关性得分图进行降噪处理,具体采用均值滤波器处理相关性得分图(二维的相关性得分图 S∈RH×WS∈R^{H×W}S∈RH×W ,每个像素值在[-1, 1]之间,值越高代表该像素与查询文本在语义上越相关)。LangSplat采用了SAM [59]提出的三个语义层级结构,因此上述操作需针对三个SAM语义层级重复三次,而后处理阶段则需通过特定策略选择一个语义层级进行预测。

我们在LERF数据集上使用一台A100显卡测试了LangSplat的分阶段推理耗时。表1数据显示,渲染阶段耗时6.0毫秒,解码阶段耗时83.1毫秒,后处理阶段耗时33.0毫秒。虽然所有阶段耗时较长,但通过两项简单改进可显著优化:首先, LangSplat将后处理阶段部署在CPU上,当涉及均值滤波操作时速度较慢。我们将后处理阶段迁移至GPU,其耗时已远低于其他阶段。 第二项改进是尺度并行化。LangSplat原本需在三个语义层级依次执行文本查询,导致渲染阶段需重复三次。而我们实现了三个语义尺度的并行推理 。例如,无需三次对d维特征进行分层处理,而是直接一次性处理三维特征。我们用LangSplat*表示经过这些改进的版本,结果显示其渲染阶段耗时2.0毫秒,后处理阶段耗时0.5毫秒。在这三个阶段中,解码阶段占总查询时间的97.1%,成为实现实时3D查询的主要瓶颈。

三、3D Sparse Coefficient Field (3D稀疏系数场)
与渲染RGB的3DGS,三维语言场需要 splat 高维特征,如图1所示,这会显著降低渲染速度。为解决这一问题,现有方法通常会在三维空间中建模d维(d << D)的潜在特征,随后通过在线解码器[44]或离线解码器[12]将这些潜在特征解码回二维图像空间中的D维特征。由于潜在特征与解码特征之间存在高维鸿沟,需要使用权重较大的MLP来确保解码阶段的准确性,这成为主要的性能瓶颈。
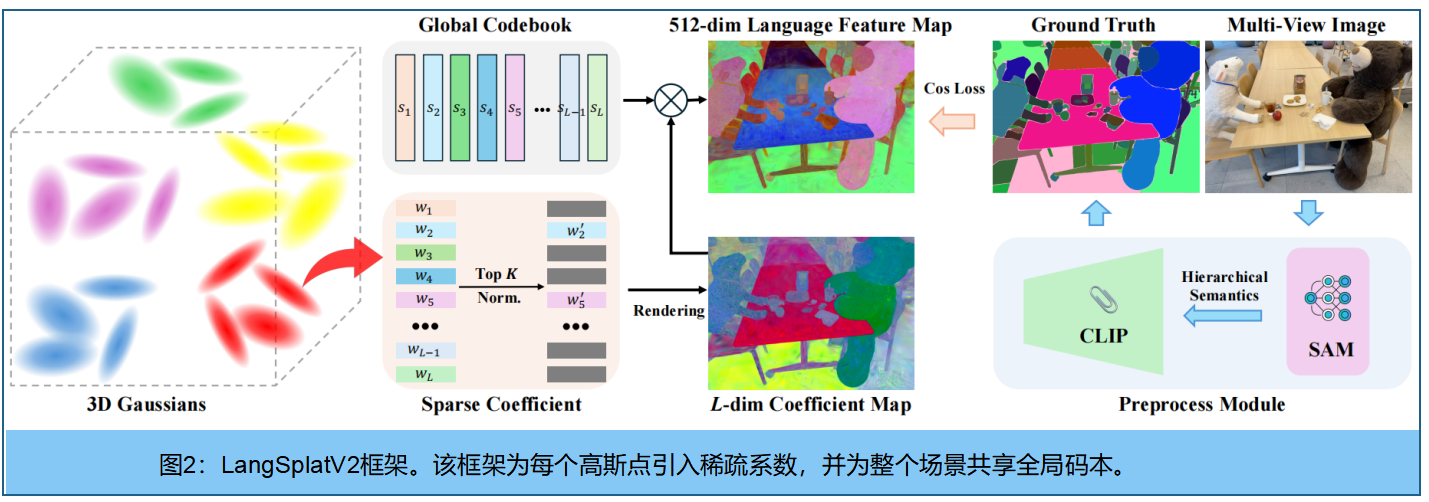
LangSplatV2摒弃了splating d维潜在语言特征,转而提出构建三维稀疏系数场。如公式4所示,该模型为每个高斯点分配一个语言特征 fif_ifi,用以表征其语义属性。由于LangSplat能够生成数百万个高斯点,理论上可产生数百万种独特的语言特征。然而这种设计效率低下,因为场景中的独特语义特征数量有限且远少于高斯点总数。实际上,许多高斯点共享相似语义特征。为此, 我们假设场景中每个高斯点的语言嵌入均可表示为LLL个全局基向量S=[s1,s2,...,sL]⊤∈RL×DS=[s_1,s_2,...,s_L]^⊤∈R^{L×D}S=[s1,s2,...,sL]⊤∈RL×D的稀疏编码。这L个基向量构成全局码本,每个高斯点通过线性组合少量局部基向量即可生成 。我们假设仅使用LLL个全局码本中的KKK个基向量(K<<LK << LK<<L)来表示高斯点的语言嵌入。接着定义第iii个高斯点的关联稀疏系数为wi=[wi,1,wi,2,...,wi,L]⊤∈R1×Lwi = [w_{i,1},w_{i,2},...,w_{i,L}]^⊤∈R^{1×L}wi=[wi,1,wi,2,...,wi,L]⊤∈R1×L,其中 ∑l=1Lwi,l\sum _{l=1}^L{w_{i,l}}∑l=1Lwi,l= 1,仅有K个元素为非零值而其余均为零。 第iii个高斯点的语言嵌入fi∈R D可表示为:

如果我们直接渲染D维语言场,而不压缩CLIP特征,得到渲染的D维CLIP特征:

也可以写成:

公式7表明,D维CLIP特征的渲染过程可等效理解为:先渲染稀疏系数 w(i)w(i)w(i),再与全局字典S进行矩阵乘法运算。
为学习系数wiw_iwi的稀疏分布,我们首先应用softmax函数对LLL维参数进行归一化处理,保留前K个非零元素并将其余元素设为零。随后通过重新归一化前KKK个元素的总和,确保系数之和等于1。LLL维三维稀疏系数场与LLL个基向量实现联合学习。图2展示了该框架的可视化呈现。
相较于LangSplat,LangSplatV2在渲染权重图后仅需进行简单的矩阵乘法运算,无需依赖复杂的解码器,从而突破了LangSplat在推理速度上的主要瓶颈。此外,D维全局码本消除了维度缩减带来的重建损失,使得CLIP空间中的高维特征建模更加精准,显著提升了查询准确率。
四、Efficient Sparse Coefficient Splatting(高效的稀疏离散系数溅射 )
通过学习三维稀疏系数场,MLP解码器被完全移除,消除了MLP相关的计算开销。然而,我们仍需执行三维特征渲染和矩阵乘法运算。实验表明,矩阵乘法耗时(表1中列为LangSplatV2的解码阶段)与渲染过程相比几乎可以忽略不计。不过,处理高维特征(维度为L)的渲染仍具有计算密集性。针对这一问题,我们 提出了一种基于CUDA优化的高效稀疏系数splating方法。通过利用系数场的稀疏特性,仅需进行K维渲染即可实现L维特征渲染,其中K≪L。
在CUDA架构实现的 3DGS 和LangSplat算法中,每个线程需对一个tile内的∣N∣|N|∣N∣个有序高斯点进行alpha混合。在L维渲染场景下,线程需依次计算L个通道,导致计算复杂度达到 O(∣N∣L)O(|N|L)O(∣N∣L)。当L值足够大时,alpha混合计算会成为关键瓶颈,随着L值增大,整体计算开销显著增加,如图1所示。
为解决这一问题,测试时利用学习到的系数场稀疏特性,即只对非零元素进行alpha混合,将计算复杂度从O(|N|L)有效降低到O(|N|K),如图3,其中K远小于L。实际应用中我们设定K=4,这样可以在CUDA中仅用12个有效特征渲染维度同时渲染三个语义尺度,最终生成1536维的高质量特征图。这种设计既保证了渲染效率,又不会影响特征质量。

具体而言,每个高斯的LLL维稀疏系数wiw_iwi都可以完全由前KKK个非零元素表示。我们将这些元素存储为两个K维数组:前K个索引和前K个系数。渲染过程中,对于tile内的每个高斯点,CUDA线程会访问前K个元素的索引和系数,并仅对这K维索引进行加权求和运算。通过这种方式,LangSplatV2能够在仅消耗超低维(K)特征点分布的情况下,获得高维(D)特征点分布结果。
五、实验
数据集。LERF(iPhone应用Polycam采集真实场景)、3D-OVS(包含多种姿态和背景下的长尾物体采集图像)和Mip-NeRF360数据集(多视角室内外场景图像组成,并配有GAGS[15]标注的分割标签)。
实施细节。基于LangSplat[12],采用OpenCLIP ViT-B/16模型提取CLIP特征。SAM[59]使用ViT-H模型进行图像分割并生成包含三个层级语义的mask。codebook LLL设为64,K值设为4。测试时我们同时渲染三个语义尺度,实际渲染维度达到12维。首先通过RGB监督训练3D高斯模型30,000次以重建RGB场景,随后固定其他3D高斯参数,再训练10,000次生成3D稀疏系数场。所有实验均在单块A100 GPU上完成。
与其他算法在LERF数据集上的 3D object localization 和 3D semantic segmentation指标对比:

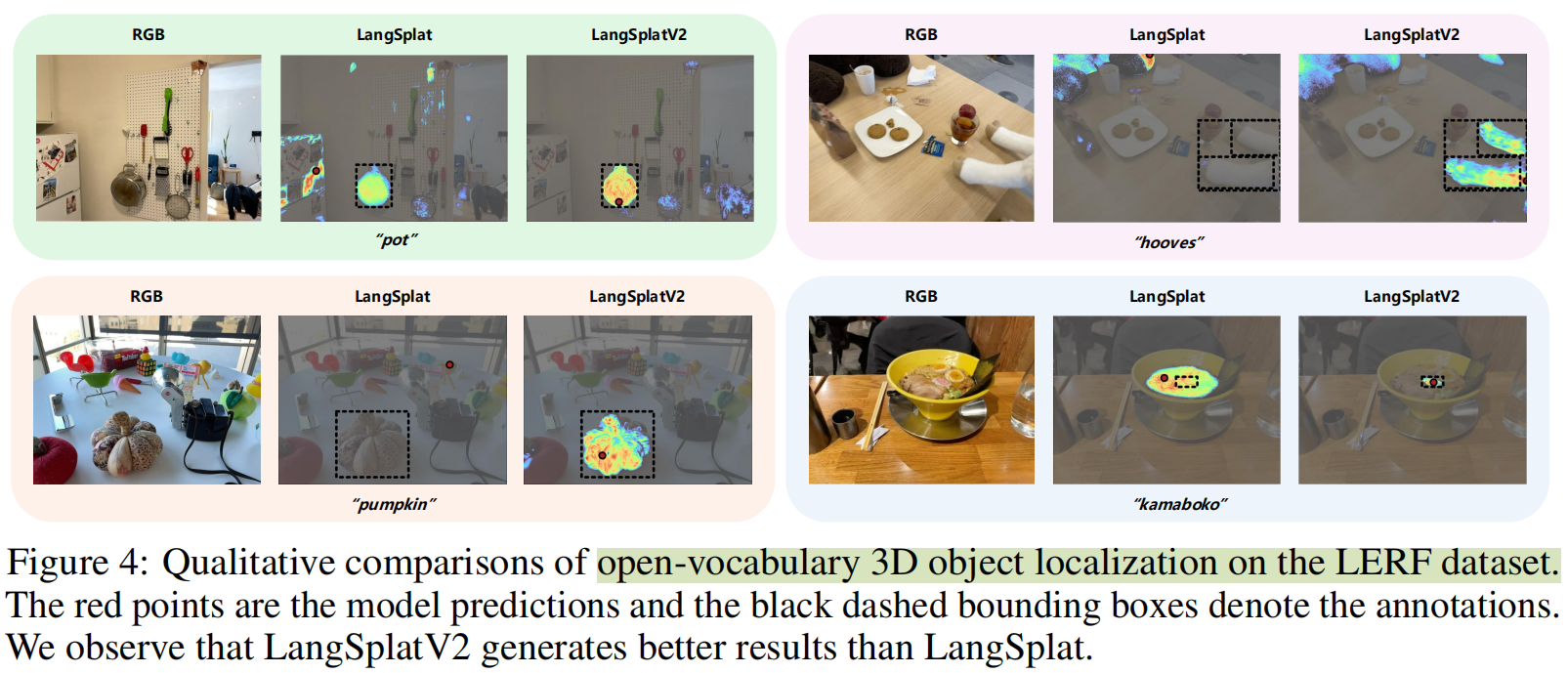
可视化结果:
其他数据集结果:

消融实验:

其他可视化结果:

其他指标对比(运行速度与显存占用):

#pic_center =60%x80%
d\sqrt{d}d 18\frac {1}{8}81 xˉ\bar{x}xˉ D^\hat{D}D^ I~\tilde{I}I~ ϵ\epsilonϵ
ϕ\phiϕ ∏\prod∏ abc\sqrt{abc}abc ∑abc\sum{abc}∑abc
/ $$