面试_场景_分布式调度系统设计
问题:设计个分布式调度系统。
回答时,切忌一上来就陷入技术细节。一个好的策略是采用 “自上而下、由广至深” 的方法,先勾勒出宏观蓝图,再深入关键模块。
第一步:理解业务,梳理用户动线,明确业务诉求
(澄清需求,设定目标)
先,你需要向面试官确认需求,这展示了你的沟通能力和业务思维。
“在设计之前,我想先明确一下这个分布式调度系统的核心需求和目标。我想确认几点:
任务类型:主要是定时任务(Cron),还是有依赖关系的DAG工作流,或是即时任务?
业务规模:预期的任务数量、触发频率(秒级、分钟级?)和执行时长大概是怎样的?
可靠性要求:对任务执行的准确性 和 不丢失不重复的要求有多高?比如是财务对账任务,还是普通的日志清理任务?
其他特性:是否需要支持 手动触发、暂停、重试、优先级、故障转移等?”
基于这些信息,我们可以定义出系统的设计目标:
-
高可用:不能有单点故障。
-
高性能:能快速调度和执行大量任务。
-
可扩展:能通过增加机器来应对任务量的增长。
-
高可靠:任务不丢、不重复(或至少一次/恰好一次交付)。
-
易运维:有良好的控制台和监控。
核心挑战:因为我们这是个中间件系统设计, 目标也是我们的核心挑战。
第二步:架构设计
1. 微服务模块的拆分
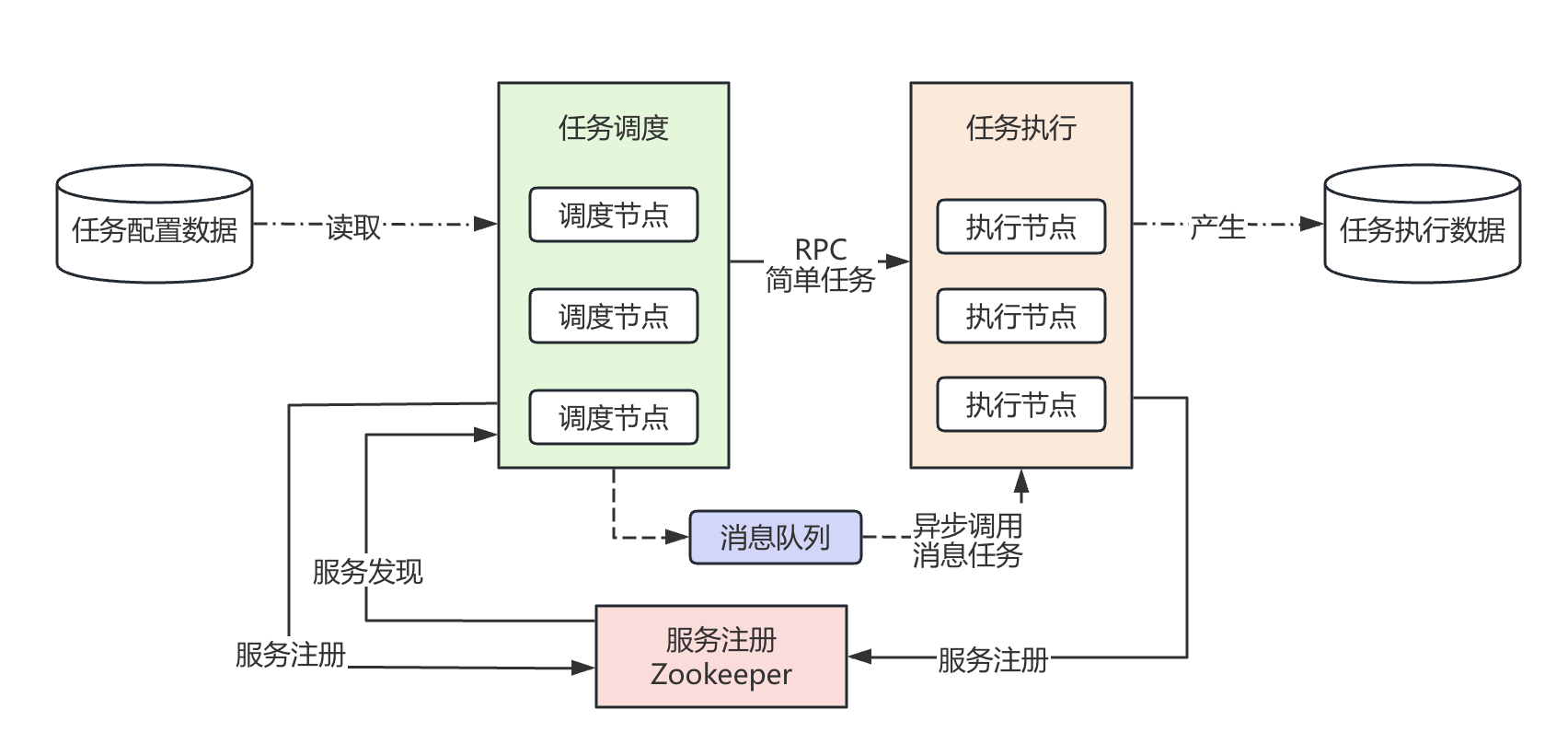
架构的解释:
1. 调度集群
-
职责:负责管理任务时间线,到点触发任务,但不负责执行。
-
高可用与选主:通过 ZooKeeper实现集群选主,只有一个 Leader 节点在运行调度逻辑,其他 Follower 作为热备。Leader挂掉后,Follower能迅速接管。
-
时间轮/优先级队列:Leader在内存中使用时间轮或优先级队列来高效管理大量定时任务。
-
触发与解耦:到点后,调度器将任务信息放入消息队列,这样就完成了“触发”,实现了调度与执行的解耦。
2. 执行集群
-
职责:从消息队列中获取任务并执行业务逻辑。
-
弹性伸缩:执行节点是无状态的,可以轻松水平扩展。通过增加执行器实例,就能提高系统的任务处理能力。
-
负载均衡:所有执行器都订阅同一个消息主题,消息队列天然提供了负载均衡。
-
结果上报:执行完毕后,将执行结果和日志记录到数据库。
3. 存储与协调
-
元数据存储:使用 关系数据库MySQL 存储任务本身的定义、配置、依赖关系等。
-
协调中心:使用 ZooKeeper/Etcd 负责集群选主、服务注册发现,存储系统的运行时状态。
-
消息队列:使用 RocketMQ 或 Kafka。它的作用是:
-
解耦:将调度和执行彻底分离。
-
削峰填谷:应对任务洪峰。
-
持久化:保证触发信号不丢失。
-
保证可靠性:提供At-least-once的投递语义。
-
2. 技术架构的选型
1. spring cloud alibaba 微服务框架, Nocas作为服务注册中心、配置中心; 负载均衡Ribbon
2. RocketMq / Kafka 消息队列
3. 关系数据库Mysql 数据库, 非关系数据库ES/Lindorm等
第三部:核心细节/核心挑战
-
幂等性
-
问题:网络抖动可能导致执行器收到重复任务。
-
方案:执行器必须具备幂等性。可以为每个任务生成全局唯一ID,执行前在数据库检查该ID是否已被处理过。
-
-
故障转移与容错
-
调度器故障:通过ZK选主,新的Leader会接管工作。
-
执行器故障:利用消息队列的重试机制。当执行器消费失败且未ACK时,消息会被重新投递给其他执行器。
-
-
分片与大数据量任务
-
问题:如果一个任务要处理1亿条数据,单机执行太慢。
-
方案:支持任务分片。调度器将“处理1亿条数据”的任务,拆分成10个“每个处理1000万条数据”的子任务,分发给不同的执行器并行处理。这极大提升了处理效率。
-
第四步:系统运维/延展设计
“总结一下,我的设计核心是 ‘调度与执行分离’ 和 ‘基于消息队列解耦’ 的架构。通过选主实现高可用,通过无状态执行器实现可扩展,通过消息持久化和幂等设计保证可靠性。
1.其他非功能设计
运维:监控、灰度、回滚
安全性:
数据规划: 执行结果超过3个月的做数据归档
容灾演进:同城双活、异地多活
2. 延展设计
如果未来有更复杂的需求,我们还可以考虑:
-
可视化控制台:用于任务管理、监控告警和日志查看。
-
资源隔离:引入容器技术,为任务提供沙箱环境。
-
更丰富的调度策略:如支持基于资源利用率的调度。”
追问环节
1. 注册中心为什么选择Zookeeper
分布式调度系统的协调中心,常用的技术选型包括Zookeeper、Nocas、Eureka. ZooKeeper 是为强一致性协调而生的,而 Nacos/Eureka 的首要目标是高可用服务发现。
-
ZooKeeper:侧重 CP。它保证在网络分区发生时,牺牲部分可用性,也要保证集群内数据的一致性。
-
Nacos / Eureka:侧重 AP。它们保证在网络分区发生时,牺牲数据的强一致性,也要保证系统的最大可用性。Nacos也支持CP.
a) 协调中心的能力
1. 数据模型与功能定位
-
ZooKeeper:它本质上是一个分布式的、强一致的小文件系统(树形结构)。它的
ephemeral节点和sequence节点是为分布式锁、选主、集群管理等协调任务而量身定做的原语。这正是调度系统选主所需要的。 -
Nacos/Eureka:核心数据模型是 服务-实例列表。它们是为微服务架构中的服务发现而设计的,功能非常专注。
2. 一致性模型与选主可靠性
-
ZooKeeper:基于 ZAB 协议,提供强一致性。在选主成功后,所有节点都会立即知道谁是唯一的 Leader,没有歧义。这对于调度系统至关重要,可以避免“脑裂”(即出现多个领导者,导致任务被重复触发)。
-
Nacos/Eureka:默认采用 最终一致性。服务实例的注册信息通过 心跳异步复制,这意味着在某个时刻,不同节点看到的服务实例列表可能是不一致的。如果用它们来选主,可能会出现短时间内多个节点都认为自己是Leader的混乱情况。
3. 会话与生命周期管理
-
ZooKeeper:通过 Session 和 Ephemeral Node 绑定。当调度器节点与ZK断开连接后,其创建的临时节点会自动消失,从而立即触发重新选主。反应迅速、准确。
-
Nacos/Eureka:通过 心跳 来维持实例的健康状态。如果一个节点假死(如GC停顿),但心跳仍在发送,系统就无法及时感知其异常,可能导致一个不健康的节点仍被当作Leader,造成任务堆积或延迟。
b) 调度系统偏爱Zookeeper
分布式调度系统(如 ElasticJob、Apache DolphinScheduler)普遍选择 ZooKeeper,是因为:
-
强一致性是刚需:调度系统的核心——选主,必须保证全局只有一个生效的调度器。这是典型的CP场景,ZooKeeper是天然契合的。
-
原生支持分布式锁和选主:ZK的
Ephemeral+Sequence节点可以非常轻松、可靠地实现这些功能,而无需额外开发。 -
实时性高:基于会话的临时节点机制,对节点上下线的感知比基于心跳的模型更快、更确定。
-
数据量小但结构性强:调度系统需要存储的元数据(如任务分配、节点状态)量不大,但需要结构化的存储和监听,ZK的树形结构非常适合。
2. 调度集群如何触发任务调度
我们的核心设计是 ‘基于数据库的任务持久化’ + ‘通过ZooKeeper选主保证唯一调度器’ + ‘使用时间轮进行高效定时’ + ‘通过消息队列触发以实现解耦’
-
任务持久化
-
所有任务的定义(如
cron表达式、处理器信息、参数)都保存在数据库中, 有字段表示任务是否上线。 -
当管理员创建或修改一个任务时,其实只是在更新数据库中的一条记录。
-
-
调度器的集群选主
-
所有调度器节点启动后,通过 ZooKeeper 竞争创建一个临时节点。创建成功的节点成为 Leader,其余的成为 Follower。
-
只有 Leader 节点承担实际的 调度触发职责。Follower 节点作为热备,随时准备在 Leader 宕机时接管工作。这避免了“脑裂”(即多个调度器同时触发同一个任务)。
-
-
核心引擎:时间轮
-
Leader 节点启动后,会从数据库加载所有"已上线"的任务。
-
它并不会为每个任务创建一个
Timer或ScheduledThreadPool,而是使用一个高效的 时间轮 来管理所有这些任务的触发时间。 -
计算任务的第一次执行时间, 包装任务信息放入时间轮中
-
工作原理:想象一个时钟,每个刻度代表一个时间间隔。调度器将任务 按触发时间放到对应的刻度槽里。一个指针按固定频率前进,每到一个刻度,就触发该槽内所有到期的任务。这在海量任务场景下,性能远高于传统的定时器。
-
触发与解耦
当时间轮指示某个任务需要触发时:-
计算任务的下一次执行时间, 重新包装任务信息放入时间轮中。
-
然后,Leader 并不会直接调用执行器,而是向 消息队列 发送一条任务消息。消息体中包含任务ID、执行参数等。
-
Leader 会先更新数据库中的任务状态,例如变为 “已触发”。这是一个防止重复触发的安全措施。
-
这一步是解耦的关键:它将“调度”这个轻量级动作和“执行”这个可能重量级且耗时的动作分离开来。调度器快速发出指令后就可以继续处理下一个任务,无需等待执行结果。
3. 如何组织多实例任务
cron类型的任务, 如何将多个(甚至是无限个)任务实例放入时间轮呢?
它触及了时间轮这类调度算法在处理周期性任务时的核心机制。
核心思想是:在本次任务被触发执行的那一刻,当场计算出它的下一次触发时间,并把它自己重新放回时间轮。
实例任务计算的详细过程:
-
首次加载:
-
系统启动时,从数据库加载任务
ScheduleTask(已上线的任务)。 -
根据Cron表达式,计算出第一次触发时间
nextTriggerTime_1。 -
用这个任务和
nextTriggerTime_1创建一个CronTimerTask,并添加到时间轮。
-
-
首次触发:
-
时间轮指针转动,
CronTimerTask到期,被取出并提交到线程池执行。 -
开始执行
run()方法。
-
-
递归注册的关键步骤(在
run()方法中):-
a. 执行业务逻辑:调用
doBusinessLogic(),向MQ发送消息等。 -
b. 计算下次时间:以当前时刻为基准,再次调用
CronUtils.nextExecutionTime,计算出第二次触发时间nextTriggerTime_2。 -
c. 自我重新注册:调用
timingWheel.add(this),将这个相同的CronTimerTask对象再次放入时间轮。此时,getDelayMs()方法将基于新的nextTriggerTime_2返回延迟时间。
-
-
循环往复:
-
当时间再次走到
nextTriggerTime_2时,同样的过程会重复:执行业务 -> 计算nextTriggerTime_3-> 重新注册。 -
这个循环会一直持续,直到任务被禁用或从数据库删除。
-
为什么不一次性计算出所有的执行时间?
1. 内存:周期任务,执行时间点是无限的,会导致内存耗尽
2. 灵活性:任务配置可能被修改,导致之前计算的被清除,处理这些变更会非常复杂, “逐次调用”的方式更加及时。
3. 效率:计算下一次触发时间是一个非常轻量的操作
4. 单次任务执行时间过长
某次任务执行时间特别长,超过了它的执行周期,会怎么样?
-
调度是准时的:时间轮会准时触发
CronTimerTask的run方法。 -
执行是异步的:
run方法的核心工作是发送MQ消息和重新注册下一次任务。这两个操作都非常快。 -
因此,即使上一次任务的业务逻辑在执行器端运行了很久,也不会影响调度器端为它计算和注册下一次触发时间。它们互不阻塞。当然,这可能导致任务在执行器端重叠,这就需要执行器自己根据业务情况考虑做 幂等 或 排队控制。
当然也可以最一些调整,调度器调度任务时,判断任务上一次的执行状态,如果未结束,放弃本次执行。
5. 哪些关键数据表
| 表名 | 核心字段 | 主要作用 |
|---|---|---|
任务信息表 (如 pg_job, XXJOB_STATUS) | job_id (任务ID), job_name (任务名), job_status/isopen (状态), job_type(任务类型),interval/interval_text (时间间隔), next_run_date (下次执行时间),cron(cron表达式) | 任务的"身份证"和"日程本"。存储所有定时任务的基本信息、调度规则和下次触发时间,是调度器决定"什么时候该触发哪个任务"的根本依据。 |
| 任务实例表 | instance_id (实例ID), job_id (关联任务ID), trigger_time (触发时间), status (实例状态), execute_info (执行信息) | 每一次任务执行的"档案"。每次任务被触发都会生成一条记录,用于追踪具体某一次任务执行的完整生命周期和结果。 |
| 执行日志表 | log_id (日志ID), job_id (任务ID), instance_id (实例ID), log_time (日志时间), log_level (日志级别), content (详细内容) | 任务的"黑匣子"。详细记录任务执行过程中的关键事件、输出和错误信息,是排查问题的重要依据。 |
🎯 核心表详解与设计要点
-
任务信息表 (
pg_job/XXJOB_STATUS):这是系统中最核心的表。job_status或isopen字段用于启停任务。interval字段存储cron表达式或间隔时间,调度器据此计算next_run_date。一些系统还会记录last_suc_date(上次成功时间)等信息。设计时可考虑添加executor_handler字段存储任务执行器的标识,方便路由。 -
任务实例表:此表与任务信息表解耦,专门用于记录每次触发的现场情况。
status字段跟踪实例的整个生命周期(如触发成功、执行中、成功、失败)。execute_info可存储执行器地址、运行时参数等。这张表是实现任务重试、失败告警和最终一致性的关键。 -
执行日志表:此表以高吞吐量写入,记录任务执行的详细流水。设计时需要注意日志分级(如INFO, ERROR),并考虑历史日志的归档和清理策略,避免数据无限增长影响性能。
6. 谁操作任务实例表
它触及了分布式调度系统中职责边界和数据一致性的核心设计。
准确的答案是:任务实例记录应由调度器在触发任务时生成。
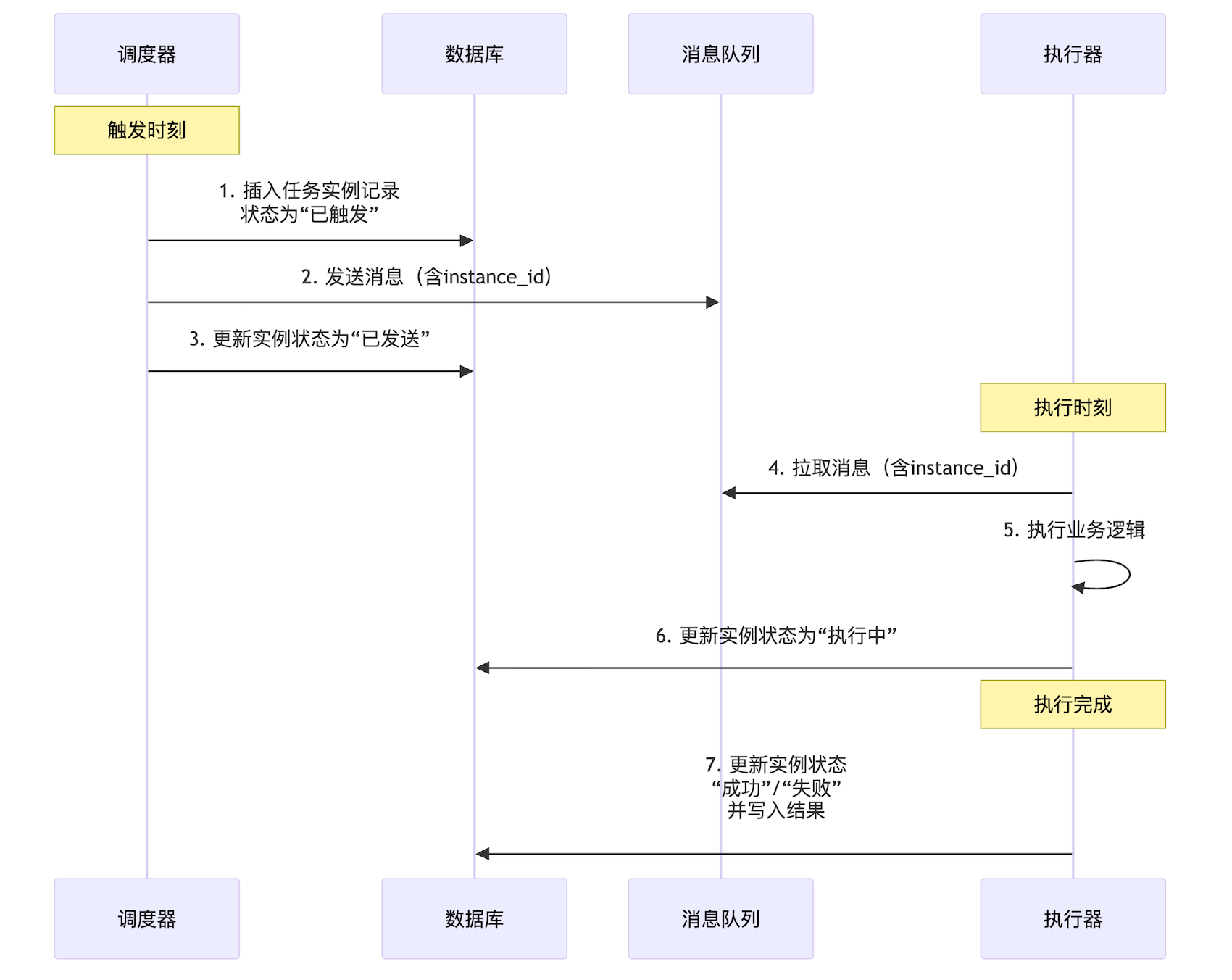
关键点:
1. 触发器生成任务实例,这是生成一个唯一实例id, 贯穿实例的整个生命周期,这也是执行器实现幂等的关键
2. 保证可追溯,从任务被触发就有了记录,可以完整的追踪实例执行过程。
3. 职责清晰
7. 执行器如何交互调度器
上一步中可以看到,执行器需要更新任务实例的状态,那么执行器如何修改状态呢?
这个问题涉及到微服务架构中如何优雅地处理 状态同步。
直接让执行器去调用调度器的API来更新状态,虽然直接,但是一种紧耦合的、不推荐的做法。正确的设计原则是:通过中间媒介进行异步解耦,让每个服务只关心自己的核心状态,并通过事件驱动来更新最终一致性视图。
1. 事件驱动模式(首选推荐)
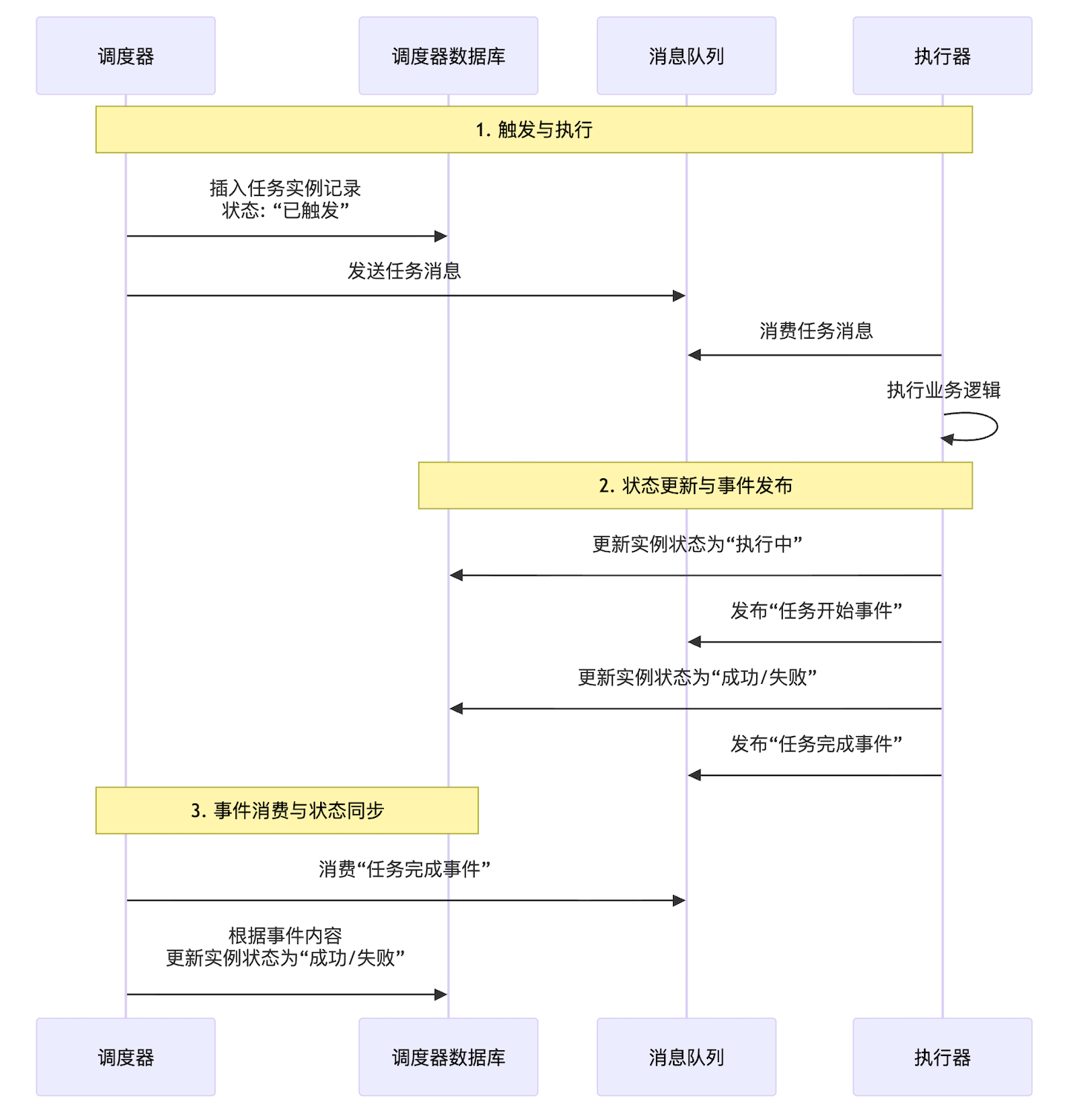
特点:
1. 解耦
2. 职责清晰, 执行器 就是执行本地任务+汇报执行结果, 调度器 就是触发任务和维护一个用于查询的“任务实例状态视图”。它通过监听事件来异步地、最终一致地更新这个视图。
3. 可扩展性,如果有其他的系统也关心任务执行结果,监听这个事件就可以。
2. 回调方案
-
调度器在发送给执行器的任务消息中,携带一个
callback_url字段(例如:http://scheduler-service/api/task/callback)。 -
执行器在任务状态变更时(如开始、成功、失败),向这个
callback_url发送一个HTTP POST请求,请求体中包含任务实例ID和最新状态。 -
调度器提供一个专用的回调接口,接收请求并更新自己数据库中的任务实例状态。
优点:简单、直接
缺点:
-
耦合:执行器需要知道调度器的网络地址(至少是域名或网关地址)。
-
可靠性:如果回调时调度器暂时不可用,执行器需要自己实现重试机制,增加了执行器的复杂性。
-
性能(阻塞):同步HTTP调用会阻塞执行器的线程。
3. 共享数据库
-
劣势:
-
紧耦合:这是最严重的问题。两个服务被数据库紧紧绑在一起,无法独立演进、独立部署和独立选择技术栈。
-
单点故障:数据库成为单点瓶颈。
-
技术栈锁定:执行器必须能用某种语言操作这个特定的数据库。
-
-
适用场景:仅适用于非常小的、初期的系统,或者本身就是作为一个单体应用部署的。