RAG长上下文加速解码策略-meta基于RAG的解决思路浅尝(REFRAG)
前文在RAG常见13种分块策略大总结(一览表)提到,分块策略在RAG中至关重要,目的是提高效率、相关性和上下文保持。但也会带来冗余。引发长上下文 RAG 应用的效率痛点:
在 RAG 等依赖外部知识的任务(如多轮对话、长文档总结)中,LLMs 需要将检索到的大量段落拼接为长上下文输入,但这会引发两大问题:
- 高延迟与高内存消耗:长上下文需占用大量键值缓存(KV Cache),且生成第一个token的时间(TTFT,Time-to-First-Token)随上下文长度呈二次方增长,后续token生成时间(TTIT)呈线性增长,导致系统吞吐量显著下降,难以满足Web级检索等低延迟场景需求。
- 冗余计算严重:RAG 上下文由多个检索段落拼接而成,但其中仅小部分与查询直接相关;且检索段落因多样性或去重处理,语义相似度极低,形成“块对角注意力模式”(即不同段落间的交叉注意力几乎为零)。现有 LLM 解码时会对整个上下文进行全量计算,而这些与查询无关的段落计算大多是不必要的。
下面看下meta的解决思路/目标:在不损失 RAG 任务性能(如回答准确性、困惑度)的前提下,通过针对性优化 RAG 解码过程,大幅降低延迟(尤其是 TTFT)和内存消耗,同时扩展 LLM 的有效上下文窗口。
模型架构
该模型由一个仅解码器的LLM(LLaMA)和一个轻量级编码器模型(Roberta )组成。
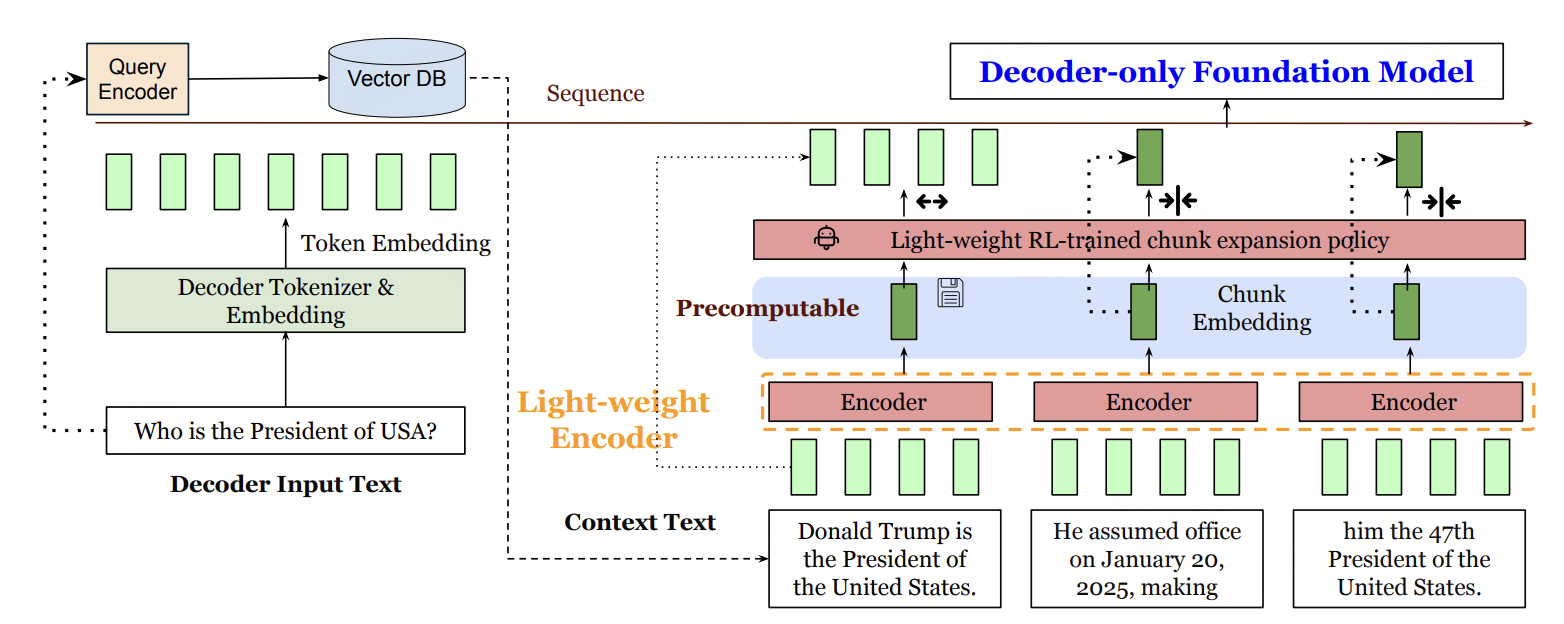
REFRAG的解码过程分为预处理(离线/在线) 和生成(在线) 两个阶段,完整流程如上。
阶段1:上下文预处理
针对RAG检索到的长上下文(占输入序列的绝大部分,即s≫qs \gg qs≫q),通过“分块→编码→投影”三步完成压缩,减少解码器输入长度:
-
上下文分块(Chunking)
将RAG检索到的上下文 tokens(xq+1,...,xTx_{q+1},...,x_Txq+1,...,xT)按固定大小kkk拆分为L=skL=\frac{s}{k}L=ks个不重叠块:Ci={xq+k∗(i−1),...,xq+k∗i−1}C_i = \{x_{q+k*(i-1)}, ..., x_{q+k*i -1}\}Ci={xq+k∗(i−1),...,xq+k∗i−1}(i=1,2,...,L(i=1,2,...,L(i=1,2,...,L)。如:若上下文长度s=16384s=16384s=16384,分块大小k=16k=16k=16,则拆分为L=1024L=1024L=1024个块,每个块含16个tokens。
-
块编码
轻量级编码器MencM_{enc}Menc(如RoBERTa-Large)对每个块CiC_iCi独立编码,输出低维块嵌入ci=Menc(Ci)c_i = M_{enc}(C_i)ci=Menc(Ci)。这么做的好处:编码器处理块时无需跨块注意力(因RAG段落语义稀疏,跨块相关性低),可并行计算,大幅降低预处理耗时。
-
维度适配
由于编码器输出的cic_ici维度(如RoBERTa-Large为1024维)与解码器的token嵌入维度(如LLaMA-2-7B为4096维)不匹配,通过投影层ϕ\phiϕ将cic_ici映射为eicnk=ϕ(ci)e_i^{cnk} = \phi(c_i)eicnk=ϕ(ci),确保与解码器输入格式兼容。
阶段2:解码器生成(带动态扩展)
将“主输入token嵌入((用户的核心输入,如查询q)) + 压缩块嵌入(RAG 检索到的长上下文)”作为解码器输入,生成答案;同时通过RL策略动态扩展关键块,避免压缩导致的信息丢失:
-
解码器输入构造
解码器接收两类输入的拼接序列:- 主输入token嵌入:e1,e2,...,eqe_1, e_2, ..., e_qe1,e2,...,eq(eie_iei为xix_ixi的原生token嵌入);
- 压缩块嵌入:e1cnk,e2cnk,...,eLcnke_1^{cnk}, e_2^{cnk}, ..., e_L^{cnk}e1cnk,e2cnk,...,eLcnk(投影后的块嵌入)。
最终解码器输入长度从T=q+sT=q+sT=q+s缩短至q+Lq+Lq+L,压缩比约为k1\frac{k}{1}1k(因L=skL=\frac{s}{k}L=ks,s≫qs \gg qs≫q时总输入长度近似从sss变为sk\frac{s}{k}ks)。
-
RL动态块扩展
并非所有块都适合压缩(如与查询强相关的块压缩后可能丢失关键信息)。REFRAG通过轻量级RL策略,在解码前或解码中决定:- 对低信息块:保留压缩嵌入eicnke_i^{cnk}eicnk,减少计算;
- 对高信息块:替换为原始块的token嵌入(即“扩展”),确保信息完整。
RL策略以“下一段预测的困惑度(Perplexity)”为负奖励,学习选择最优扩展块,且扩展不破坏解码器的自回归特性(可在上下文任意位置进行)。
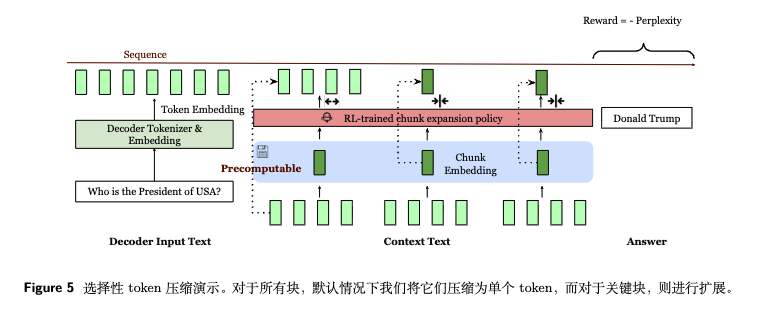
- 答案生成
解码器基于处理后的输入序列生成答案:y∼Mdec({e1,...,eq,e1cnk,...,eLcnk})y \sim M_{dec}(\{e_1,...,e_q, e_1^{cnk},...,e_L^{cnk}\})y∼Mdec({e1,...,eq,e1cnk,...,eLcnk}),生成过程与原生LLM完全一致,无需修改解码器架构。
训练方法逻辑概述
REFRAG 不修改基础 LLM 解码器架构,通过 “预训练 + 微调” 让解码器学会理解和利用编码器生成的压缩块嵌入。
- 对齐阶段:通过 “重建任务” 让编码器生成的块嵌入能准确还原原始上下文,同时让投影层将块嵌入映射到解码器兼容的维度(解决 “压缩后信息丢失” 问题)。
- 优化阶段:通过 “课程学习” 降低训练难度,让模型从单块重建逐步过渡到多块处理,避免直接训练长序列导致的优化困难(解决 “多块压缩难以收敛” 问题)。
- 适配阶段:通过 “RL 选择性压缩” 动态决定哪些块保留原始 token(扩展)、哪些用压缩嵌入(压缩),在保证性能的前提下最大化效率(解决 “全量压缩可能损失关键信息” 问题)。
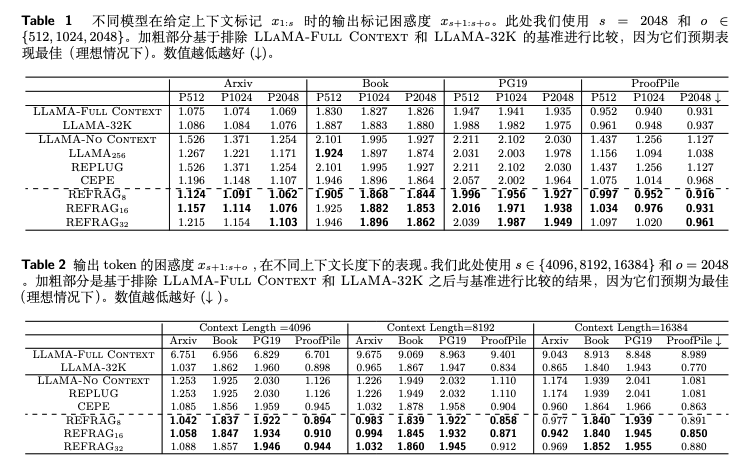
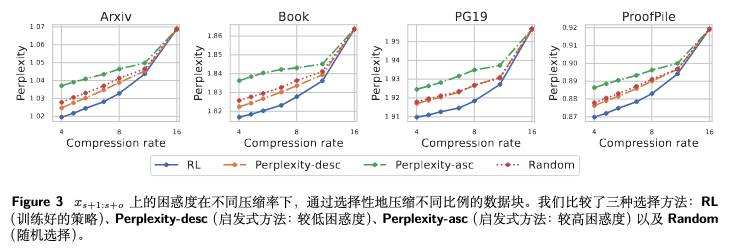
实验
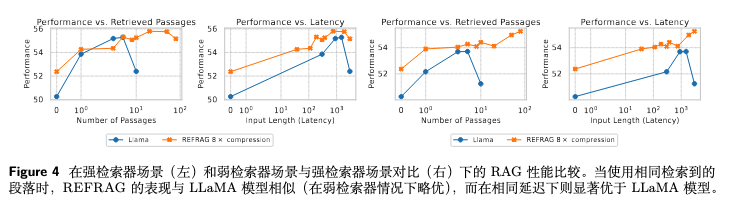
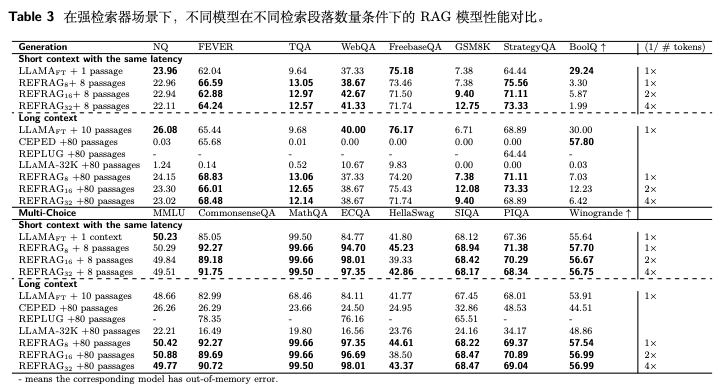
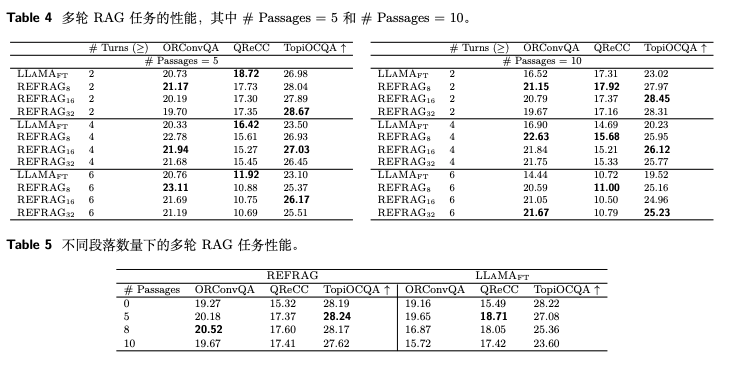
REFRAG: Rethinking RAG based Decoding,https://arxiv.org/pdf/2509.01092