基于微服务的在线判题系统重点总结
项目核心技术
1.B端
1.1管理员登录功能
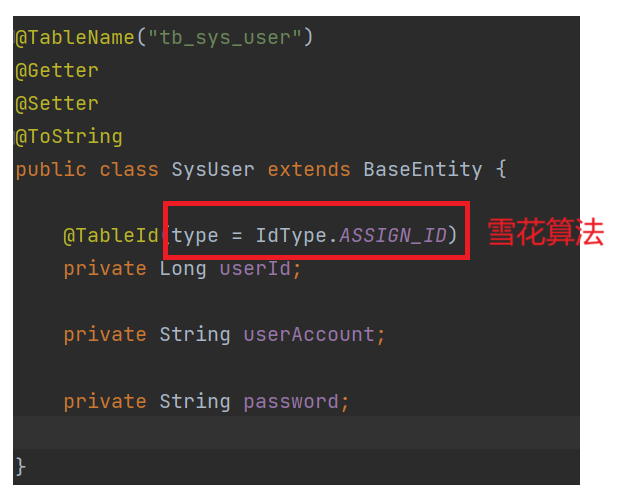
1.实体类的设计---LoginUser
对于实体类的设计,主要部分是表结构的设计,在这个项目中,不在采用自增Id的形式去设计主键,而是采用雪花算法的方式来作为主键
1.2 管理员登录功能
登录功能的实现逻辑是在用户输入用户名和密码之后,后端根据用户输入的用户名去数据库查找对应的用户信息(包含密码),最后在去判断用户输入的密码与数据查到的密码是否一致即可
1.2 SpringCloud Gateway的引入
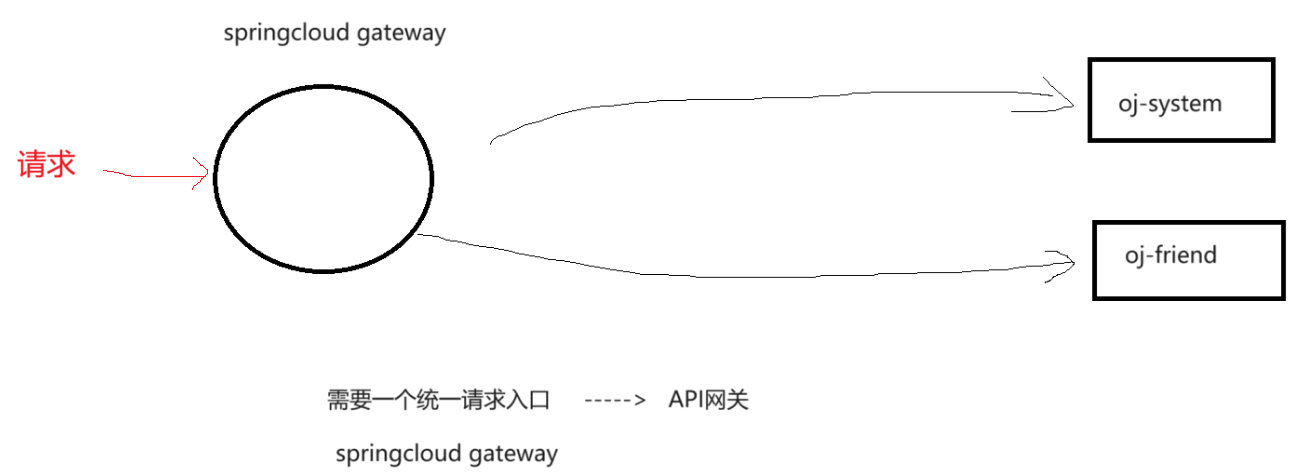
在oj挑战项目中,用户会分为管理员用户和普通成员用户,此时就需要根据不同类型用户的请求将请求达到对应的服务上,此时就需要引入SpringCloud Gateway,如下图
则此时就涉及到了一个身份验证的问题,如何实现身份的验证呢?
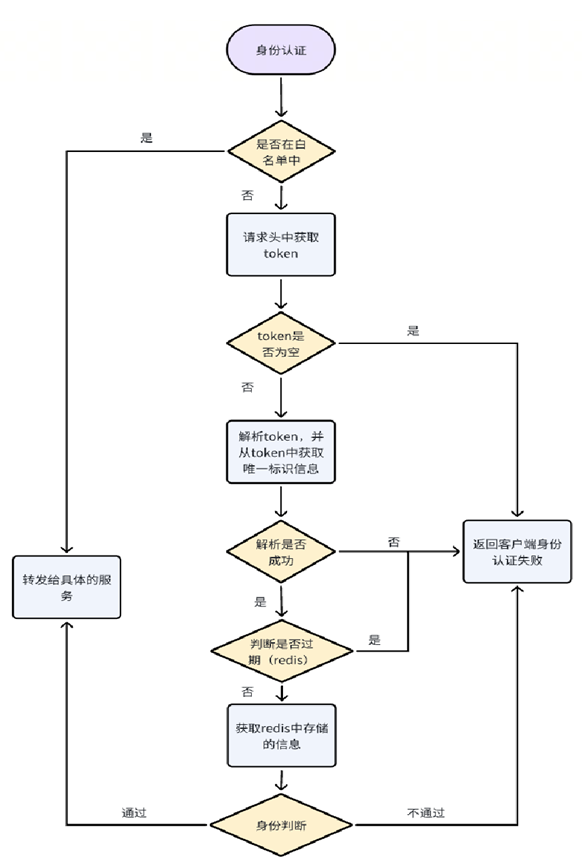
1.3 身份验证的实现---Jwt+Redis
对于身份的验证,按照功能的方面来说,仅仅依靠一个token就可以实现身份验证的功能,用户在第一次登录时,后端根据该用户的用户类别信息去生成一个token,并将该token返回给客户管,该token可以被客户端存储在Cookie或者Local Storage中,后续每次发起请求时都会携带这个token,此时服务端就可以解析token,获得用户是管理员用户还是成员用户
1.仅仅依靠Jwt会出现的问题
但是此时仅仅依靠Jwt去实现身份验证的功能时会有几个问题
第一个问题:因为Jwt中的payload是包含用户的信息的,但是并没有进行加密,而是采用了Base64编码的格式对payload中的用户信息进行编码,由于没有加密就导致了payload中无法存储一些用户的敏刚信息
第二个问题:Jwt是无状态的,这就意味着,如果Jwt中存储了用户的信息,此时如果用户修改了个人信息,就会导致重新登录的现象,这就会导致用户的体验感很差
第三个问题:无法延长Jwt的过期时间,这就会导致用户正在操作,而此时Jwt过期了,此时就会出现用户正在操作,却出现了身份验证失败的问题
2.解决方案---引入redis
1.第一个问题和第二个问题的解决方案
针对于第一个问题,因为payload没有加密而导致无法存储敏感信息的问题,那很好解决,不往Jwt中去存储用户的敏感信息即可,此时就可以引入redis,将用户的敏感信息存储到redis就行了。
但是此时还是有一个问题:token是没有过期时间的,为redis中存储的信息是有过期时间的,如何判断此时这个token是否过期了呢?
此时redis中存的信息算是与token对应的,此时可以根据通过token中解析得到的信息(也就是key)尝试去从redis中去获取对应的数据,如果获取到对应的数据,说明此时的token没有过期,如果没有从redis中获取到数据,则此时代表token已经过期,此时就需要重新登录
还有一个问题,必须要保证redis存储对应的用户信息的key是唯一的,这个很好解决,统一key的前缀并且加上一个userId作为key,就可以解决redis的key唯一性的问题
以上就是第一个问题的解决方案,很显然,这个方案同时也解决了第二个问题
这一步是通过在网关实现一个过滤器来实现的,具体代码如下
@Slf4j
@Component
public class AuthFilter implements GlobalFilter, Ordered {// 排除过滤的 uri 白名单地址,在nacos自行添加@Autowiredprivate IgnoreWhiteProperties ignoreWhite;@Value("${jwt.secret}")private String secret;@Autowiredprivate RedisService redisService;@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {ServerHttpRequest request = exchange.getRequest();String url = request.getURI().getPath(); //请求的接口地址 登录接口是否需要进行身份认证? 否// 跳过不需要验证的路径 接口白名单中的所有接口均不需要进行身份的认证if (matches(url, ignoreWhite.getWhites())) {//判断如果当前的接口在白名单中则不需要进行身份认证 ignoreWhite.getWhites(): 拿到nacos上配置的接口地址的白名单return chain.filter(exchange);}//执行到这 说明接口不再白名单中 接着进行身份认证逻辑 通过token进行身份认证 首先要把token获取出来//从http请求头中获取tokenString token = getToken(request);if (StrUtil.isEmpty(token)) {
// throw new RuntimeException("令牌不能为空");return unauthorizedResponse(exchange, "令牌不能为空");}Claims claims;try {claims = JwtUtils.parseToken(token, secret); //获取令牌中信息 解析payload中信息 存储着用户唯一标识信息if (claims == null) {//springcloud gateway 基于webfluxreturn unauthorizedResponse(exchange, "令牌已过期或验证不正确!");}} catch (Exception e) {return unauthorizedResponse(exchange, "令牌已过期或验证不正确!");}// String userId = JwtUtils.getUserId(claims);
// boolean isLogin = redisService.hasKey(getTokenKey(userId));//通过redis中存储的数据,来控制jwt的过期时间String userKey = JwtUtils.getUserKey(claims); //获取jwt中的keyboolean isLogin = redisService.hasKey(getTokenKey(userKey)); //7c114ab4-e4d7-4392-8630-3e248a9cb335 //42752c9a-009a-47bb-8a9c-1d34f4287944if (!isLogin) {return unauthorizedResponse(exchange, "登录状态已过期");}String userId = JwtUtils.getUserId(claims); //判断jwt中的信息是否完整if (StrUtil.isEmpty(userId)) {return unauthorizedResponse(exchange, "令牌验证失败");}//token 是正确的 并且没有过期//判断redis存储 关于用户身份认证的信息是否是对的//判断当前请求 请求的是C端功能(只有C端用户可以请求) 还是B端功能 (只有管路员可以请求)LoginUser user = redisService.getCacheObject(getTokenKey(userKey), LoginUser.class);if (url.contains(HttpConstants.SYSTEM_URL_PREFIX) && !UserIdentity.ADMIN.getValue().equals(user.getIdentity())) {return unauthorizedResponse(exchange, "令牌验证失败");}if (url.contains(HttpConstants.FRIEND_URL_PREFIX) && !UserIdentity.ORDINARY.getValue().equals(user.getIdentity())) {return unauthorizedResponse(exchange, "令牌验证失败");}return chain.filter(exchange);}/*** 查找指定url是否匹配指定匹配规则链表中的任意一个字符串** @param url 指定url* @param patternList 需要检查的匹配规则链表* @return 是否匹配*/private boolean matches(String url, List<String> patternList) {if (StrUtil.isEmpty(url) || CollectionUtils.isEmpty(patternList)) {return false;}//接口地址如果和白名单中其中一个地址匹配就返回true。 如果便利完白名单中所有的地址都没有匹配的返回falsefor (String pattern : patternList) {if (isMatch(pattern, url)) {return true;}}return false;}/*** 判断url是否与规则匹配* 匹配规则中:* pattern 中可以写一些特殊字符* ? 表示单个任意字符;* * 表示一层路径内的任意字符串,不可跨层级;* ** 表示任意层路径;** @param pattern 匹配规则* @param url 需要匹配的url* @return 是否匹配*/private boolean isMatch(String pattern, String url) {AntPathMatcher matcher = new AntPathMatcher();return matcher.match(pattern, url);}/*** 获取缓存key*/private String getTokenKey(String token) {return CacheConstants.LOGIN_TOKEN_KEY + token;}/*** 从请求头中获取请求token*/private String getToken(ServerHttpRequest request) {String token = request.getHeaders().getFirst(HttpConstants.AUTHENTICATION);// 如果前端设置了令牌前缀,则裁剪掉前缀if (StrUtil.isNotEmpty(token) && token.startsWith(HttpConstants.PREFIX)) {token = token.replaceFirst(HttpConstants.PREFIX, StrUtil.EMPTY);}return token;}private Mono<Void> unauthorizedResponse(ServerWebExchange exchange, String msg) {log.error("[鉴权异常处理]请求路径:{}", exchange.getRequest().getPath());return webFluxResponseWriter(exchange.getResponse(), msg, ResultCode.FAILED_UNAUTHORIZED.getCode());}//拼装webflux模型响应private Mono<Void> webFluxResponseWriter(ServerHttpResponse response, String msg, int code) {response.setStatusCode(HttpStatus.OK);response.getHeaders().add(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE);R<?> result = R.fail(code, msg);DataBuffer dataBuffer = response.bufferFactory().wrap(JSON.toJSONString(result).getBytes());return response.writeWith(Mono.just(dataBuffer));}
}2.第三个问题的解决方案---如何解决无法延长token过期时间的问题
因为通过引入redis,此时token是否过期是根据能否从redis获取到数据来决定的,此时解决方案就很简单了,只需在特定的时段去延长redis中对应数据的过期时间即可
那么应该在什么时候去延长时间呢?
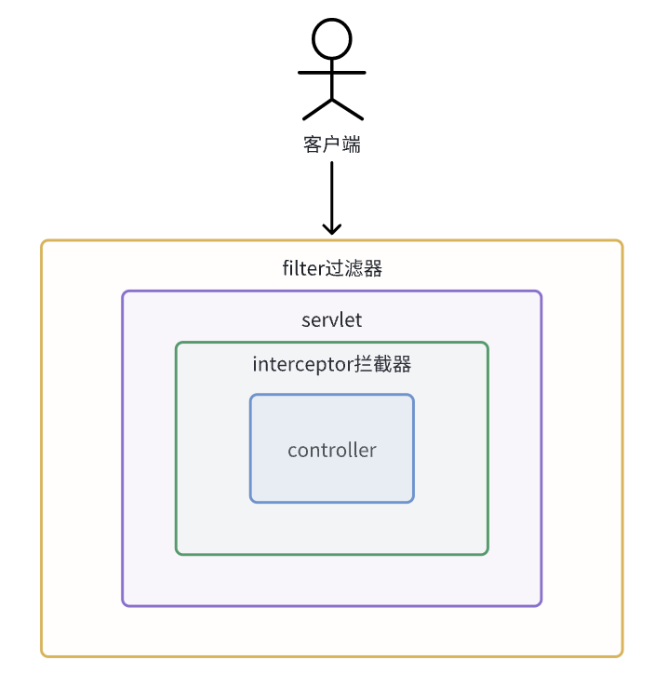
肯定是在身份验证之后,且请求转发到controller之前,此时有的同学就可能直接在网关的过滤器中身份验证逻辑的后面继续编写延长时间的代码,但是从代码功能层面来说,网关的主要职责是进行身份验证的,如果写在过滤那里,不是很好,接着就是如果写在网关层的话,代码的耦合度就很大了
此时我们就可以通过拦截器实现,如下图
但是我们也不能盲目的去延长过期时间,可以设计一个临界值,如果达到了这个临界值,就要去延长时间了
1.4身份验证总结图
2.题库管理
2.1 获取题目列表
在获取题目列表这块,引入PageHelper插件实现了分页查询,主要是注意下面的理解
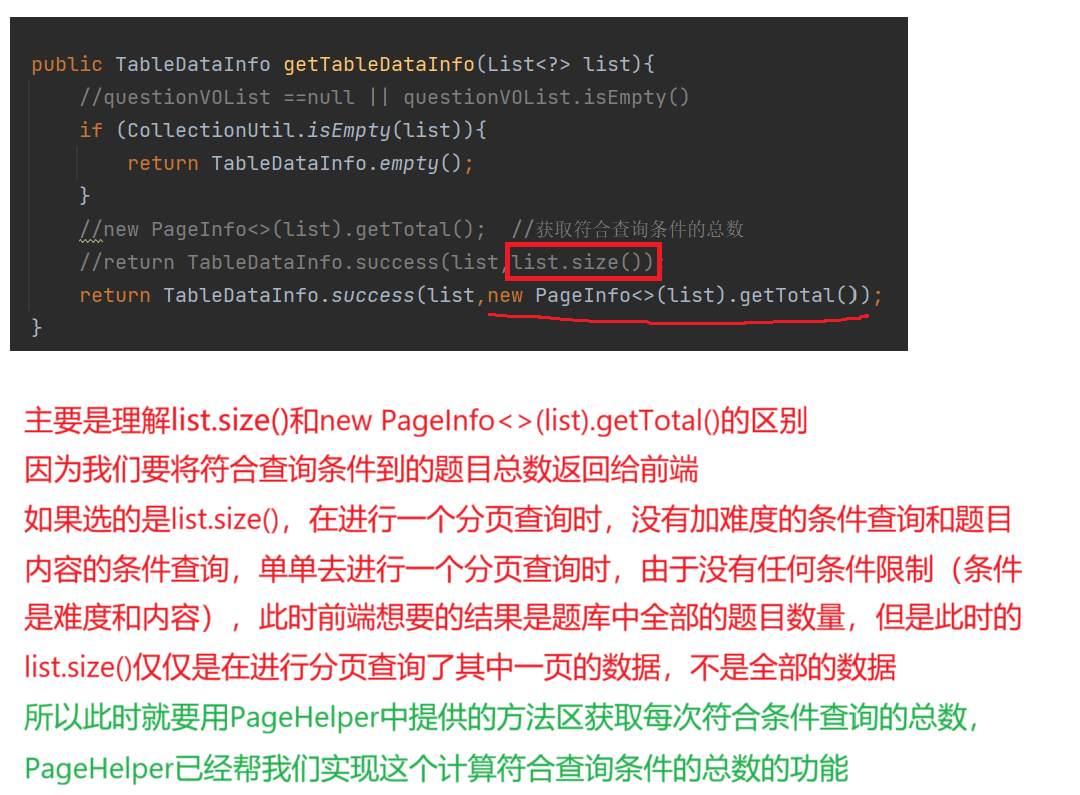
2.2解决的一个小bug
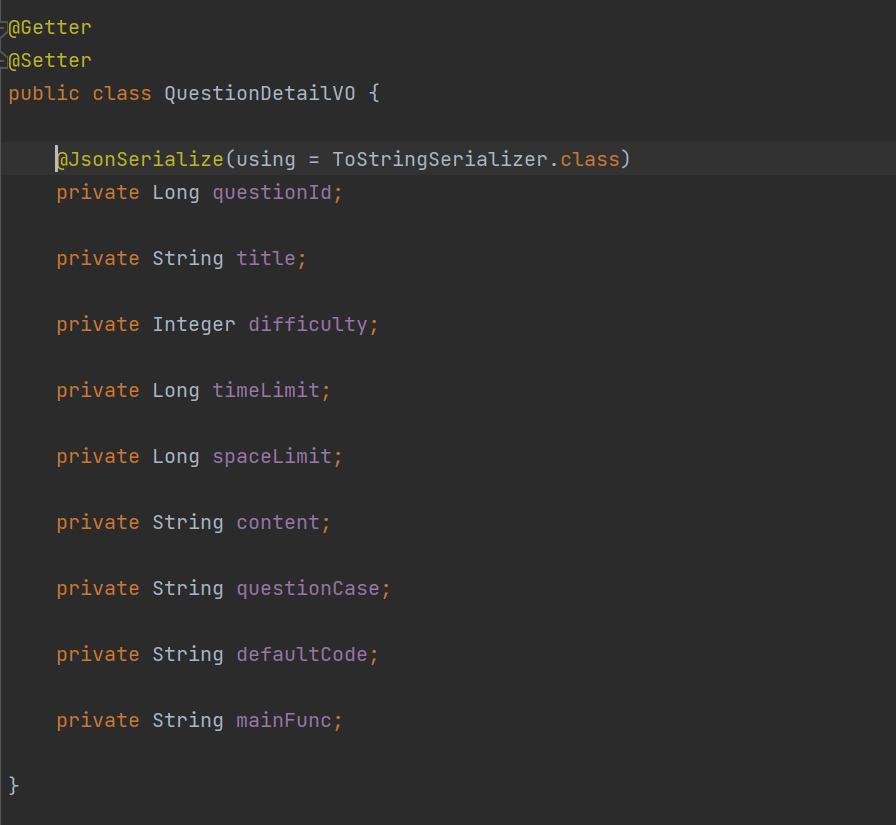
因为在返回数据给前端时,questionId是Long类型的,太长了,返回给前端会发生截断,会导致前端获得的数据不正确,此时只要在数据返回给前端之前将questionId转换为String类型即可,可以用一个注解来解决,如下图
3.引入redis优化代码
在实现C端用户获取竞赛列表的时候,由于我们是直接查询数据库来获取竞赛数据的,但是查数据库的速度是在是太慢了,所以在这里引入redis来优化一下代码
3.1 什么时候往redis中添加竞赛数据呢?
首先,用户能在主页能看到的竞赛数据都有一个共同的特点,那就是都是已经发布的数据,所以,我们可以在管理员发布竞赛的时候将发布的竞赛添加到redis中
3.2 如何设计缓存结构
首先,要清楚选择哪一个数据结构来存储C端的竞赛数据
C端竞赛数据有分页、有序的特点,所以选择list作为存储竞赛,选择两个list结构,一个用来存储未完赛的竞赛的竞赛列表,另一个用来存储历史竞赛列表
接着如何设计key和value呢?
对于未完赛的竞赛列表的key设计为:e:t:l
对于历史竞赛列表的key设计为:e:h:l
那么如何设计value呢?
此时可能就很快就想到了将竞赛信息以json的形式将作为value,但是以长久的眼光来看,未来可能还会有其他功能会我们会将竞赛数据存储到redis中,这部分功能会往redis中存储竞赛数据,另一个功能可能也会往redis中存储竞赛数据,这就导致redis中会存储了重复的数据,此时也会浪费一部分空间
此时的解决方法就是用一个String的数据结构来存储竞赛的基本信息,此时的key就是examId,value就是竞赛的基本信息
通过这样的方案,针对存储重复数据的问题,此时就以examId为value来存储即可,通过list的key找到examId,在通过examId去String中寻找对应的竞赛信息
3.3实现思路
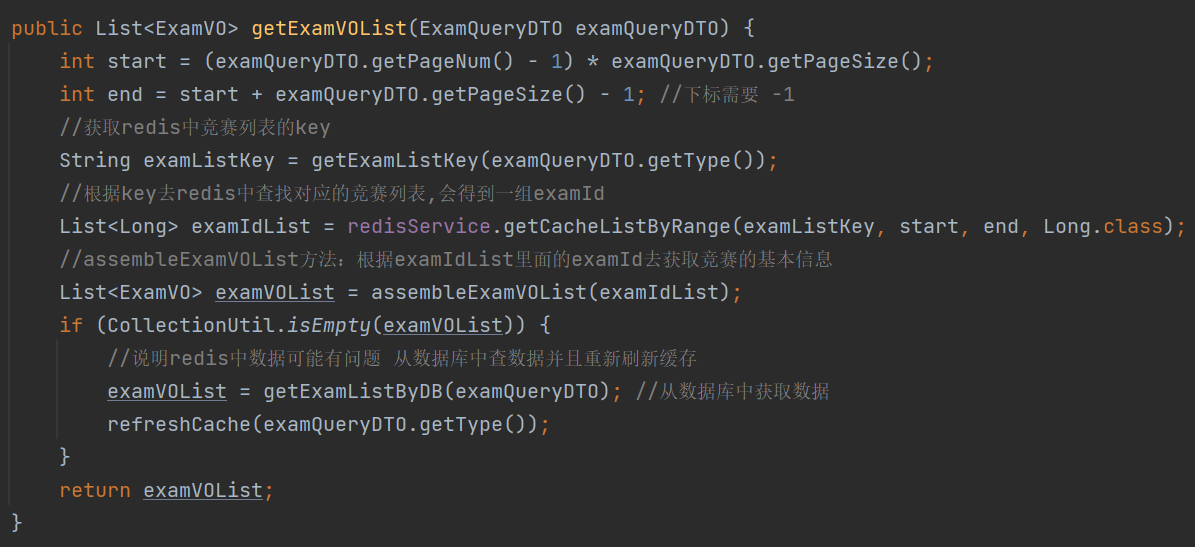
C端用户在获取竞赛列表的时候,我们先从redis中去获取竞赛列表,如果没有从redis中获取到竞赛列表或者从从redis中获取的数据有问题,此时我们在去数据库中获取竞赛列表
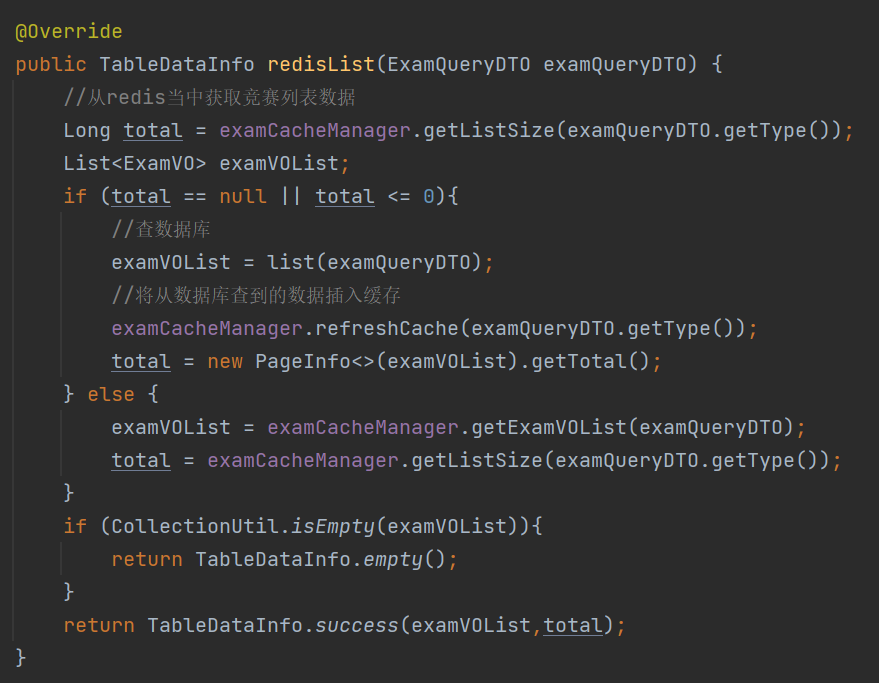
refreshCache方法的代码,这个方法是用来往redis中插入数据的
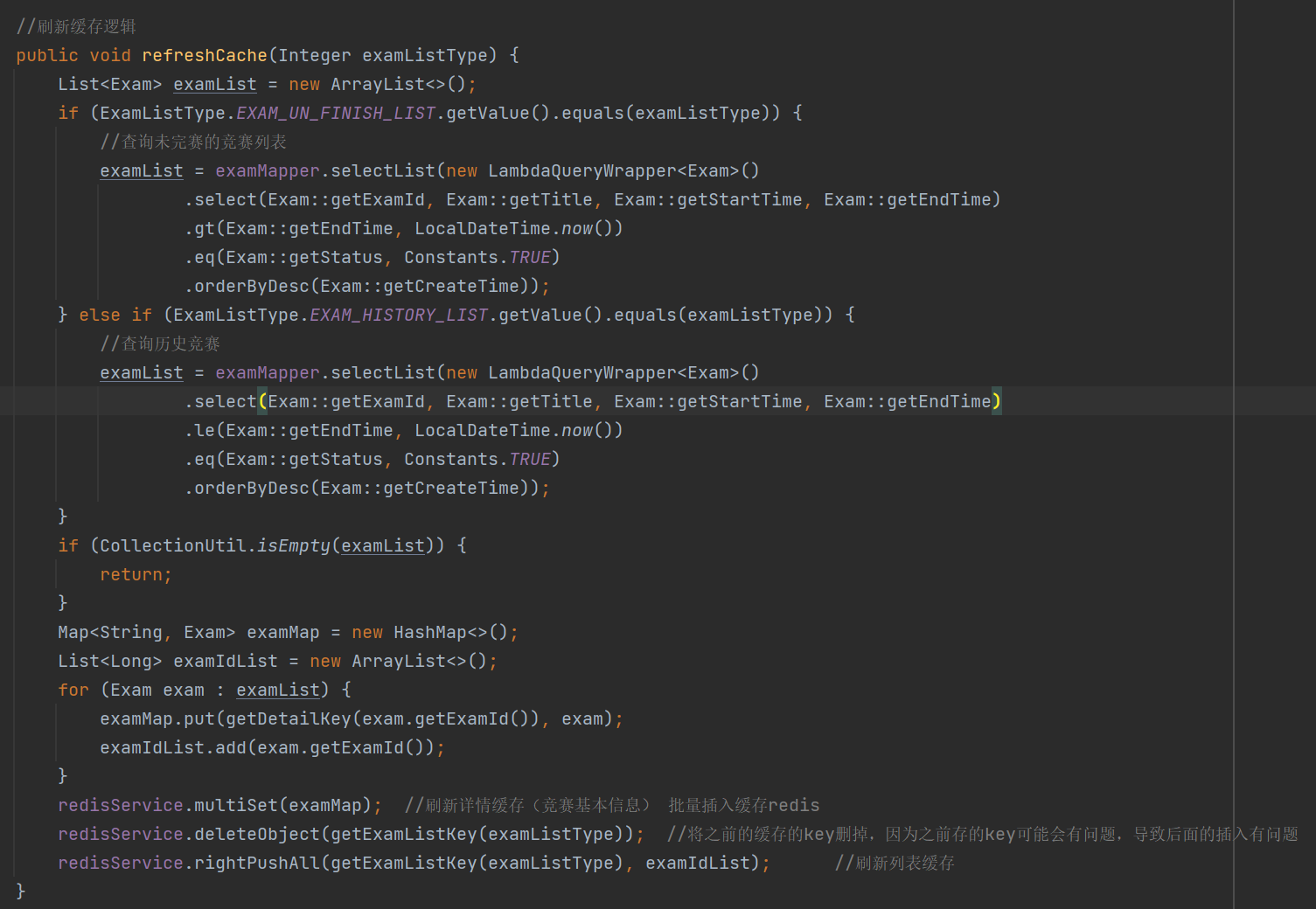
此时在查询完数据库获取到竞赛列表的时候,在往redis中插入数据的时候,为什么要将之前缓存的exanId先删除一遍之后,在往redis中插入数据呢?
这样是为了防止之前存的key出现了问题,导致后面向redis中插入的examId出现问题,从而导致根据有问题的examId获取竞赛基本信息时会出现问题
getExamVOList方法是用来从redis中获取竞赛列表的
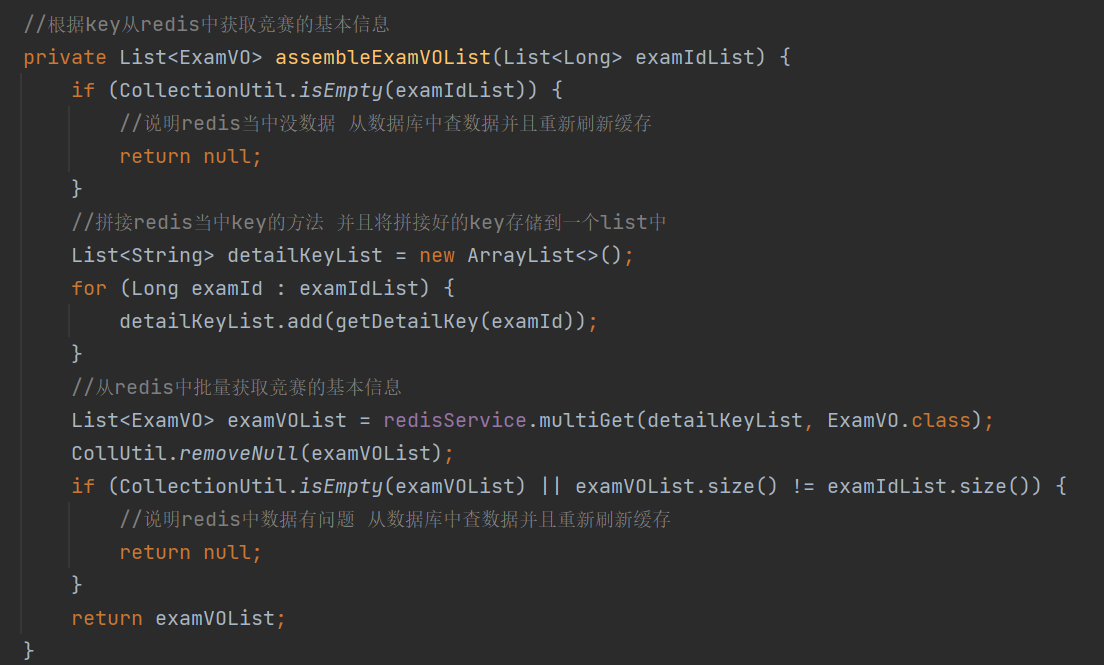
assembleExamVOList方法,即使从redis中查找出了竞赛的基本信息之后,还是有对从redis中获取到的数据是否有问题进行一个判断,其中removeNull方法是将examVOList中为null的数据去除掉
3.4 遗留的问题
此时就完成了优化,但是此时还是存在一个问题,就是历史竞赛是会增加的
假如前一次的查询结束之后,已经向redis中存储了数据,但此时有一个竞赛就结束了,由于已经往redis中插入数据了,下次查询历史竞赛列表的时候,因为从redis中获取的数据不为空,此时就会直接将之前存到redis中竞赛列表数据返回,此时并没有将新结束的竞赛返回,这就是存在的一个问题
4.引入XXL-JOB
为了让未完赛的竞赛到了过期时间变成了历史竞赛,让新的历史竞赛重新刷经缓存中,引入了XXL-JOB,通过实现一个定时任务,每天凌晨1点将数据中的数据同步到缓存中
5.引入TransmittableThreadlocal
由于在OJ挑战项目中,我将登录用户的userId中存到了token里面,由于OJ项目中很多功能都设计到userId,导致我在每次实现一些接口的过程中,每次都要从请求头中获取token,并解析token从中得到userId,所以通过引入TransmittableThreadlocal,TransmittableThreadlocal相当于是加强版的ThreadLocal,ThreadLocal变量就是会为每一个线程提供一个该变量的副本,且每个线程的这个副本变量之间是相互隔离的,所以可以安全的使用
由于在拦截器那部分有解析token的逻辑,所以就在拦截器那里将从token中解析得到的userId保存到ThreadLocal变量
6.引入ES
在做C端的题目列表时,由于涉及到一个搜索功能,支持题目的模糊搜索和内容的模糊搜索,但是为了提高效率,我们是不能直接从数据库中去查询数据的,所以一开始可能想到会先将数据存入redis中
但是存入redis有一个问题,就是关于这个题目的模糊搜索和内容的模糊搜索,如果想要在redis中实现模糊查询,此时在设计key的时候有一个问题,就是如果想要实现模糊搜索,此时就要将题目或者内容的每一个字的组合都要设计成一个key对应一个valule来存储在redis中,但是这样的组合的数量会十分的巨大,此时这样就不适合存储在redis中了
此时就引入ES,ES是一个实现高效实时搜索的中间件,类似与MySQL的中间件,此时通过引入ES就可以很好的解决模糊搜索的问题
7.项目阶段性总结
最近好多涉及到的功能都涉及到了redis,为了提高效率,每次涉及到查询时的操作时,都要先从redis中获取数据,如果从redis中获取到了数据,此时就可以直接返回得到的数据
但是如果没有从redis中获取到对应的数据或者从Redis中获取到的数据有误,此时就要去数据库查询对应的数据,此时并将从数据库得到的数据同步到redis中
由于这个项目有B端和C端功能,由于我已经实现B端功能再实现的C端功能,此时C端在涉及到redis的操作时,此时还要考虑之前的B端代码中是否要调整
举个例子,我在C端实现了一个获取竞赛第一个题目的功能,此时在C端会先从redis中获取这个竞赛的所有题目,如果从redis获取到对应的信息,此时就通过数据库查询并同步到redis中,以后不出异常的情况,此时就会直接返回Redsi中存储的数据
但是此时有一个问题,C端是可以对竞赛的题目信息进行编辑的,如果此时C端对竞赛题目信息进行了编辑,此时数据库中存的是新的数据,而redis中还没有同步新的数据,此时如果在去获取该竞赛的题目信息的话,由于redis中是存储了对应的数据的,不过是旧的,此时就会直接返回旧的数据
为了解决这个问题,就要对B端的一些进行一些代码上的挑战,是数据库和redis中的数据同步
例如上面的例子,由于在对竞赛信息进行操作时,是要先撤销竞赛才能操作的,此时就可以直接在撤销竞赛功能时,同时也把对应的缓存信息删除掉。
此时也可以在C端发布竞赛功能时,也可以将对应的竞赛题目存储到redis中,但是也可以不用这么做,因为B端如果没有从redis中获取到数据,会从数据库中查询并同步到redis中
所以没必要再发布竞赛时存储一部分到redis中,因为发布竞赛的时候,用户可能还没想参与竞赛刷题,可以等用户刷竞赛题时,才存到redis中
8.判题功能的实现
挑战项目的判题功能分为两部分:
第一部分是oj--friend微服务接受到前端提交代码的请求,接收到前端提交的代码,也就是一个submitDTO
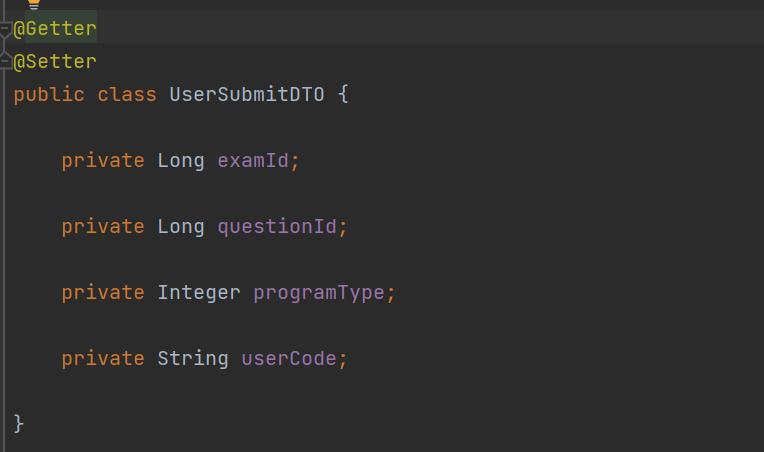
先根据programTye去判断提交的代码是什么语言类型的代码,根据不同语言类型的代码去进行不同的处理,然后根据submitDTO中的examId,先从es中去查询相关的题目的信息,相关信息包括对应的main函数、测试用例(测试用例会有多个,是一个列表,测试用例就包括了输入和输出)、该题的时间限制和空间限制和难易程度
如果没有从es中查询到,再去数据库中查询,在将从数据库中查询到的数据同步到es中即可
注意:对于测试用例的处理,因为是将测试用例以JSON的形式存到数据库和es里的,所以,要将查询到的测试用例进行反序列化成对象
此时oj--friend微服务根据submitDTO形成了一个JudgeSubmit类型的参数,JudgeSubmit类型的参数是给oj-judege服务进行判题的参数
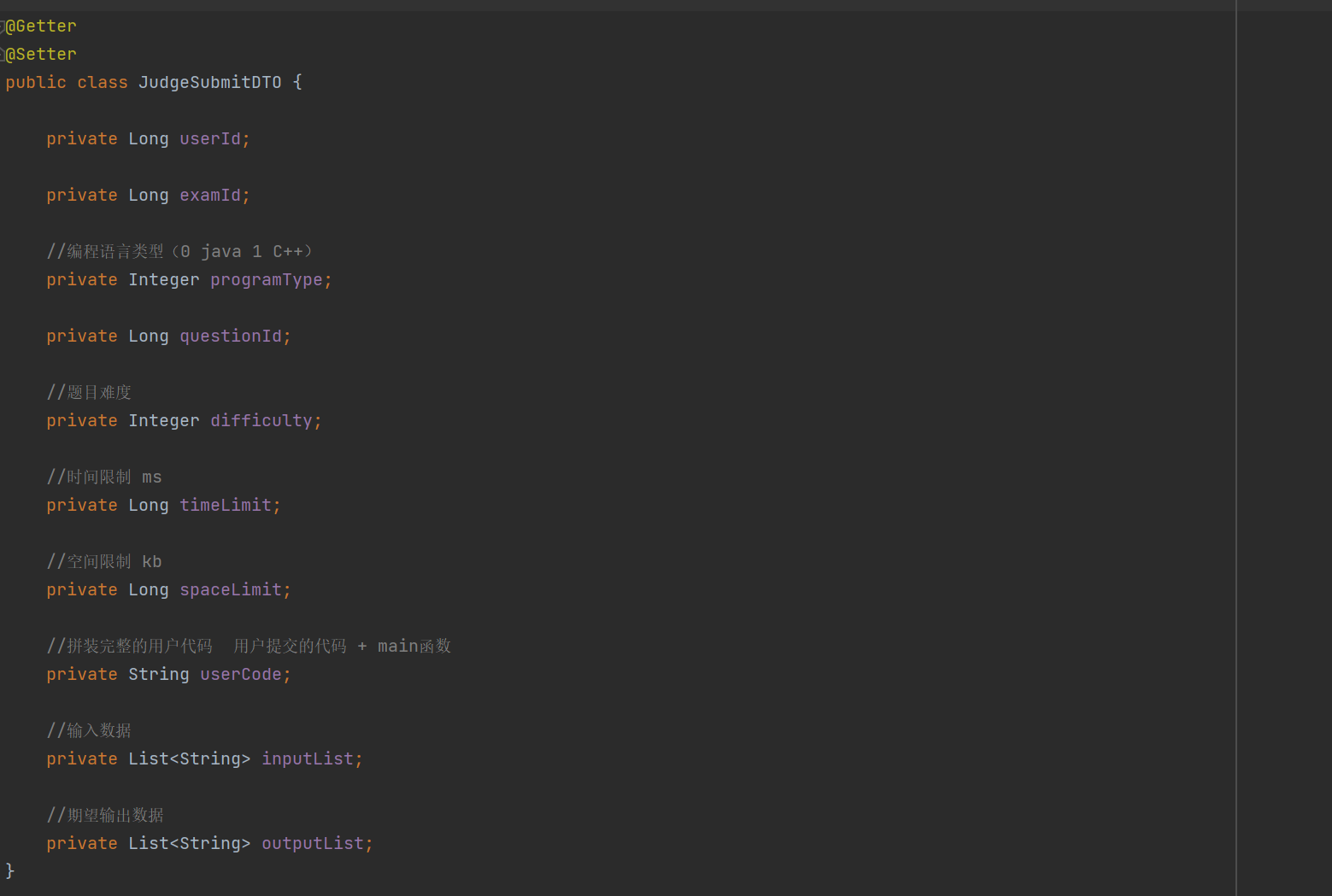
public R<UserQuestionResultVO> submit(UserSubmitDTO submitDTO) {Integer programType = submitDTO.getProgramType();if(ProgramType.JAVA.getValue().equals(programType)){//按照Java的逻辑进行后续处理JudgeSubmitDTO judgeSubmitDTO = assembleJudgeSubmitDTO(submitDTO);return remoteJudgeService.doJudgeJavaCode(judgeSubmitDTO);}throw new ServiceException(ResultCode.FAILED_NOT_SUPPORTED_PROGRAM);}
//
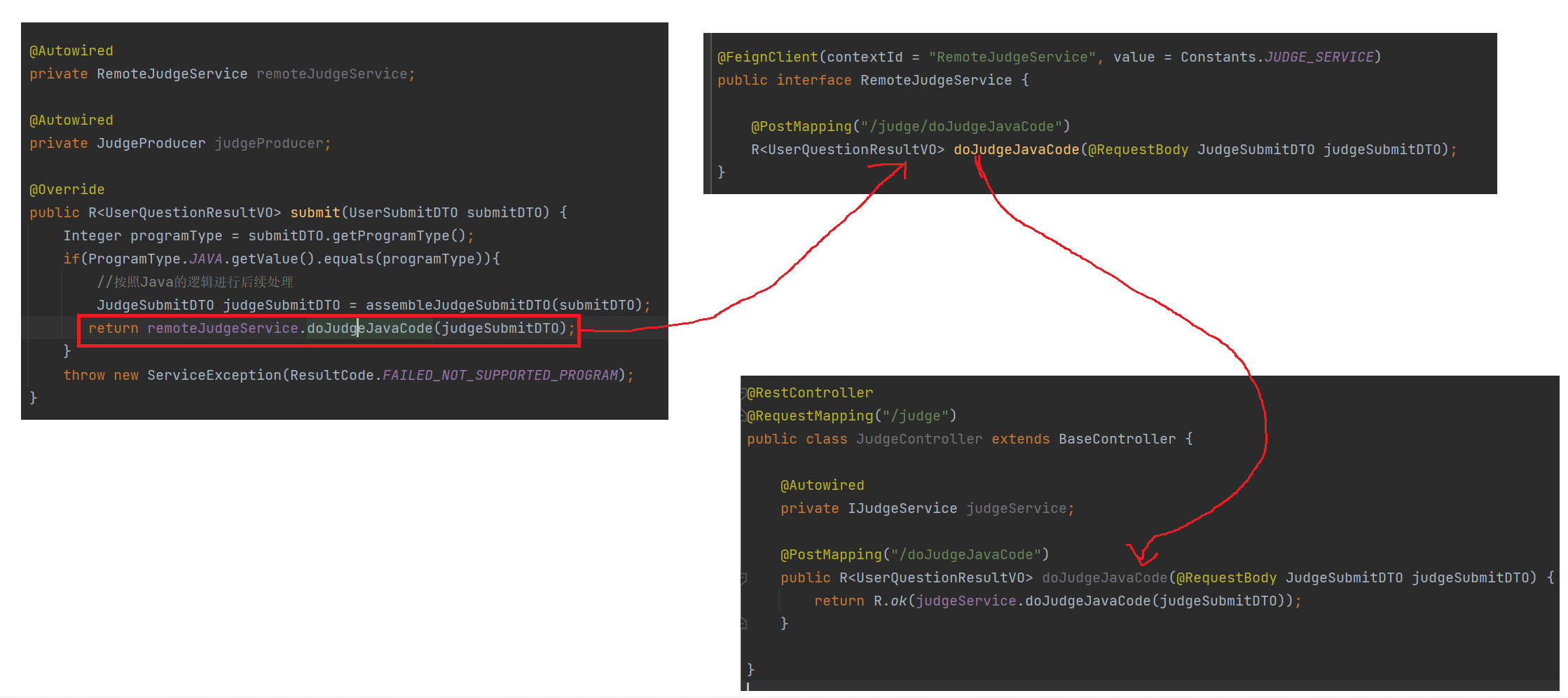
private JudgeSubmitDTO assembleJudgeSubmitDTO(UserSubmitDTO submitDTO) {Long questionId = submitDTO.getQuestionId();QuestionES questionES = questionRepository.findById(questionId).orElse(null);JudgeSubmitDTO judgeSubmitDTO = new JudgeSubmitDTO();if (questionES != null){BeanUtil.copyProperties(questionES,judgeSubmitDTO);} else {Question question = questionMapper.selectById(questionId);BeanUtil.copyProperties(question,judgeSubmitDTO);questionES = new QuestionES();BeanUtil.copyProperties(question,questionES);questionRepository.save(questionES);}judgeSubmitDTO.setUserId(ThreadLocalUtil.get(Constants.USER_ID,Long.class));judgeSubmitDTO.setExamId(submitDTO.getExamId());judgeSubmitDTO.setProgramType(submitDTO.getProgramType());judgeSubmitDTO.setUserCode(codeConnect(submitDTO.getUserCode(),questionES.getMainFunc()));//对测试用例进行反序列化List<QuestionCase> questionCaseList = JSONUtil.toList(questionES.getQuestionCase(), QuestionCase.class);List<String> inputList = questionCaseList.stream().map(QuestionCase::getInput).toList();judgeSubmitDTO.setInputList(inputList);List<String> outputList = questionCaseList.stream().map(QuestionCase::getOutput).toList();judgeSubmitDTO.setOutputList(outputList);return judgeSubmitDTO;}//拼接代码private String codeConnect(String userCode, String mainFunc) {String targetCharacter = "}";int targetLastIndex = userCode.lastIndexOf(targetCharacter);if (targetLastIndex != -1) {return userCode.substring(0, targetLastIndex) + "\n" + mainFunc + "\n" + userCode.substring(targetLastIndex);}throw new ServiceException(ResultCode.FAILED);}第二部分就是oj-judge服务了,此时是在oj-friend服务中调用了oj-judge服务,此时就用到了OpenFeign,此时也会将OpenFeign单独抽出来作为一个微服务
@FeignClient(contextId = "RemoteJudgeService", value = Constants.JUDGE_SERVICE)
public interface RemoteJudgeService {@PostMapping("/judge/doJudgeJavaCode")R<UserQuestionResultVO> doJudgeJavaCode(@RequestBody JudgeSubmitDTO judgeSubmitDTO);
}
在oj-judge的主要功能就是运行代码,判断代码是否编译成功和运行成功,如果失败,也要将失败的信息返回给前端
如果代码运行成功,此时还要去判断代码的运行结果是否正确,如果结果正确,在这之后还要判断代码的空间限制和时间限制是否符合题目的要求
一个一个来,首先要解决的是如果运行用户提交的代码,在这个oj挑战项目中,采用的是Docker沙箱的形式来运行代码
为什么采用Docker沙箱的形式来运行代码呢?
因为此时用户提交的代码会有几个问题
第一个问题就是用户的代码会用到很多系统的资源,例如cpu、内存、网络等资源,如果用户提交的代码都把资源都占用完了,此时系统运行就很难保证稳定性和性能
第二个问题就是用户提交的代码可能存在病毒,可能会导致我们的系统瘫痪
第三个问题就是数据泄漏,如果用户提交的代码具有很高的权限,那么将可以访问我们系统的文件,这样可能会导致重要信息泄露出去,或者借机往往我们的一些文件中写入一些非法的内容,这也会导致一些严重的后果
第四个问题就是相互干扰,如果多个用户同时提交代码执行,同一个环境下有可能会相互影响
针对上面这些问题,使用Docker的容器就可以很好的解决问题
第一个问题的解决方案:在创建一个沙箱容器时,只给这个容器分配的资源,限制cpu、内存等资源的使用
第二个问题通过Docker的容器就可以很好的解决,如果代码提交的代码中有病毒的,由于代码是在容器中运行的,即使病毒导致该容器挂了,也不会影响主系统的安全性
第三个问题的解决方案就是如果发现恶意攻击的用户,将其拉黑即可
第四个问题通过Docker的容器也就解决了,由于代码实在容器中运行的,而容器间是相互不影响的,这就很好的解决了不同用户提交的的代码之间会相互影响的问题
8.1 判题功能代码---初版代码
首先通过Java代码来操作Docker,如一下代码
@Service
public class SandboxServiceImpl implements ISandboxService {@Value("${sandbox.docker.host:tcp://localhost:2375}")private String dockerHost;@Value("${sandbox.limit.memory:100000000}")private Long memoryLimit;@Value("${sandbox.limit.memory-swap:100000000}")private Long memorySwapLimit;@Value("${sandbox.limit.cpu:1}")private Long cpuLimit;@Value("${sandbox.limit.time:5}")private Long timeLimit;private DockerClient dockerClient;private String containerId;private String userCodeDir;private String userCodeFileName;@Overridepublic SandBoxExecuteResult exeJavaCode(Long userId,String userCode, List<String> inputList) {//创建对应文件createUserCodeFile(userId,userCode);//初始化Docker容器initDockerSanBox();//编译代码CompileResult compileResult = compileCodeByDocker();if (!compileResult.isCompiled()){deleteContainer();deleteUserCodeFile();return SandBoxExecuteResult.fail(CodeRunStatus.COMPILE_FAILED,compileResult.getExeMessage());}//执行代码return executeJavaCodeByDocker(inputList);}//创建并返回用户代码的文件private void createUserCodeFile(Long userId, String userCode) {String examCodeDir = System.getProperty("user.dir") + File.separator + JudgeConstants.EXAM_CODE_DIR;if (!FileUtil.exist(examCodeDir)) {FileUtil.mkdir(examCodeDir); //创建存放用户代码的目录}String time = LocalDateTimeUtil.format(LocalDateTime.now(), DateTimeFormatter.ofPattern("yyyyMMddHHmmss"));//拼接用户代码文件格式userCodeDir = examCodeDir + File.separator + userId + Constants.UNDERLINE_SEPARATOR + time;userCodeFileName = userCodeDir + File.separator + JudgeConstants.USER_CODE_JAVA_CLASS_NAME;FileUtil.writeString(userCode, userCodeFileName, Constants.UTF8);}private void initDockerSanBox() {DefaultDockerClientConfig clientConfig = DefaultDockerClientConfig.createDefaultConfigBuilder().withDockerHost(dockerHost).build();dockerClient = DockerClientBuilder.getInstance(clientConfig).withDockerCmdExecFactory(new NettyDockerCmdExecFactory()).build();//拉取镜像pullJavaEnvImage();//创建容器 限制资源 控制权限HostConfig hostConfig = getHostConfig();CreateContainerCmd containerCmd = dockerClient.createContainerCmd(JudgeConstants.JAVA_ENV_IMAGE).withName(JudgeConstants.JAVA_CONTAINER_NAME);CreateContainerResponse createContainerResponse = containerCmd.withHostConfig(hostConfig).withAttachStderr(true).withAttachStdout(true).withTty(true).exec();//记录容器idcontainerId = createContainerResponse.getId();//启动容器dockerClient.startContainerCmd(containerId).exec();}//拉取java执行环境镜像 需要控制只拉取一次private void pullJavaEnvImage() {ListImagesCmd listImagesCmd = dockerClient.listImagesCmd();List<Image> imageList = listImagesCmd.exec();for (Image image : imageList) {String[] repoTags = image.getRepoTags();if (repoTags != null && repoTags.length > 0 && JudgeConstants.JAVA_ENV_IMAGE.equals(repoTags[0])) {return;}}PullImageCmd pullImageCmd = dockerClient.pullImageCmd(JudgeConstants.JAVA_ENV_IMAGE);try {pullImageCmd.exec(new PullImageResultCallback()).awaitCompletion();} catch (InterruptedException e) {throw new RuntimeException(e);}}//限制资源 控制权限private HostConfig getHostConfig() {HostConfig hostConfig = new HostConfig();//设置挂载目录,指定用户代码路径hostConfig.setBinds(new Bind(userCodeDir, new Volume(JudgeConstants.DOCKER_USER_CODE_DIR)));//限制docker容器使用资源hostConfig.withMemory(memoryLimit);hostConfig.withMemorySwap(memorySwapLimit);hostConfig.withCpuCount(cpuLimit);hostConfig.withNetworkMode("none"); //禁用网络hostConfig.withReadonlyRootfs(true); //禁止在root目录写文件return hostConfig;}//编译//的使用docker编译private CompileResult compileCodeByDocker() {String cmdId = createExecCmd(JudgeConstants.DOCKER_JAVAC_CMD, null, containerId);DockerStartResultCallback resultCallback = new DockerStartResultCallback();CompileResult compileResult = new CompileResult();try {dockerClient.execStartCmd(cmdId).exec(resultCallback).awaitCompletion();if (CodeRunStatus.FAILED.equals(resultCallback.getCodeRunStatus())) {compileResult.setCompiled(false);compileResult.setExeMessage(resultCallback.getErrorMessage());} else {compileResult.setCompiled(true);}return compileResult;} catch (InterruptedException e) {//此处可以直接抛出 已做统一异常处理 也可再做定制化处理throw new RuntimeException(e);}}private SandBoxExecuteResult executeJavaCodeByDocker(List<String> inputList) {List<String> outList = new ArrayList<>(); //记录输出结果long maxMemory = 0L; //最大占用内存long maxUseTime = 0L; //最大运行时间//执行用户代码for (String inputArgs : inputList) {String cmdId = createExecCmd(JudgeConstants.DOCKER_JAVA_EXEC_CMD, inputArgs, containerId);//执行代码StopWatch stopWatch = new StopWatch(); //执行代码后开始计时//执行情况监控StatsCmd statsCmd = dockerClient.statsCmd(containerId); //启动监控StatisticsCallback statisticsCallback = statsCmd.exec(new StatisticsCallback());stopWatch.start();DockerStartResultCallback resultCallback = new DockerStartResultCallback();try {dockerClient.execStartCmd(cmdId).exec(resultCallback).awaitCompletion(timeLimit, TimeUnit.SECONDS);if (CodeRunStatus.FAILED.equals(resultCallback.getCodeRunStatus())) {//未通过所有用例返回结果return SandBoxExecuteResult.fail(CodeRunStatus.NOT_ALL_PASSED);}} catch (InterruptedException e) {throw new RuntimeException(e);}stopWatch.stop(); //结束时间统计statsCmd.close(); //结束docker容器执行统计long userTime = stopWatch.getLastTaskTimeMillis(); //执行耗时maxUseTime = Math.max(userTime, maxUseTime); //记录最大的执行用例耗时Long memory = statisticsCallback.getMaxMemory();if (memory != null) {maxMemory = Math.max(maxMemory, statisticsCallback.getMaxMemory()); //记录最大的执行用例占用内存}outList.add(resultCallback.getMessage().trim()); //记录正确的输出结果}deleteContainer();//删除容器deleteUserCodeFile(); //清理文件return getSanBoxResult(inputList, outList, maxMemory, maxUseTime); //封装结果}private String createExecCmd(String[] javaCmdArr, String inputArgs, String containerId) {if (!StrUtil.isEmpty(inputArgs)) {//当入参不为空时拼接入参String[] inputArray = inputArgs.split(" "); //入参javaCmdArr = ArrayUtil.append(JudgeConstants.DOCKER_JAVA_EXEC_CMD, inputArray);}ExecCreateCmdResponse cmdResponse = dockerClient.execCreateCmd(containerId).withCmd(javaCmdArr).withAttachStderr(true).withAttachStdin(true).withAttachStdout(true).exec();return cmdResponse.getId();}private SandBoxExecuteResult getSanBoxResult(List<String> inputList, List<String> outList,long maxMemory, long maxUseTime) {if (inputList.size() != outList.size()) {//输入用例数量 不等于 输出用例数量 属于执行异常return SandBoxExecuteResult.fail(CodeRunStatus.NOT_ALL_PASSED, outList, maxMemory, maxUseTime);}return SandBoxExecuteResult.success(CodeRunStatus.SUCCEED, outList, maxMemory, maxUseTime);}private void deleteContainer() {//执行完成之后删除容器dockerClient.stopContainerCmd(containerId).exec();dockerClient.removeContainerCmd(containerId).exec();//断开和docker连接try {dockerClient.close();} catch (IOException e) {throw new RuntimeException(e);}}private void deleteUserCodeFile() {FileUtil.del(userCodeDir);}
}
8.2判题功能代码---容器池实现
在判题功能的初版代码中,由于只有当用户点击提交代码按钮时,才会开启一个代码沙箱容器去运行代码,这样会导致每次判题都临时启动一个全新的Docker容器且判题功能完成后,这样会导致频繁的创建容器、启动容器,这些创建和启动容器的操作都是会有一定的开销的,这样就会导致延迟高,也会导致用户提交代码后需要等待很久才能获取到判题结果,从而导致整体运行效率低下
为了解决这个问题,我采用Bean的模式和阻塞队列让创建了一个容器池,则此时的运行流程变为:
1.由于采用了Bean模式创建了一个容器池,系统在启动时,会根据我们手动定义的容器池的大小来预先启动多个容器,并将这些容器放入容器池中
2.用户在提交代码时,此时直接从容器池中取出一个空闲的容器,此因为容器池中的容器是启动的状态,此时用户提交的代码就可以得到立即运行,就可以很快得到了判题结果,因为判题结束后,并不会销毁容器,而是将容器放回容器池中,这样整个的过程就可以避免频繁的创建和销毁容器,这样就可以大大提高代码的运行效率了
8.3容器池的大小如何确定呢?
在我看来,容器池的大小的定义一般有以下这些指标
第一个就是系统的并发请求量,我认为这是最核心的指标,假设同时有N个用户提交代码,想可以同时判题,那么此时至少要预先启动N个可用的容器,但是通常不会出现所有用户同时提交代码的情况,且如果在系统用户非常多的情况下,开启那么多容器也是要很大开销的,并有可能会导致一些容器长期被闲置,这样就会占据大部分的资源和开销,所以我们可以统计一个平均并发判题数或者统计一个最大峰值的并发判题数,根据平均并发判题数或者最大峰值并发判题数来确定容器池的大小。比如,假设我们的判题系统平均同时有10~20个容器在判题,此时容器池的大小就可以设置为20~30,提高容错。还有一种情况就是在竞赛的情况下,此时有可能更多的并发,假设有100+的并发,此时就可以将容器池的大小设置为100~200,甚至要更高
第二个指标就是容器池中的容器的运行效率,如果用户提交的代码执行很快,那么单个容器就可以在短时间内就能处理多个任务,此时容器池的大小就不需要特别的大,但是也有可能会出现用户提交的代码运行的很难的现象,此时一些容器被占用的时间就会变长,此时就需要更多的容器来保证并发能力,所以可以根据这两种情况计算一个单个判题任务的平均执行时间,根据这个平均执行时间来确定容器池的大小
还有一个指标就是还要根据主机的硬件资源来确定容器池的大小,虽然每个Docker容器是轻量级的,但是任然会占据一些CPU资源、内存资源和磁盘IO,如果我们脱离主机的资源来无脑的确定容器池的初始容量,这样也是不可行的,所以,最终还要根据主机的硬件资源来确定容器池的大小
容器池配置代码
容器池类:
@Configuration
public class DockerSandBoxPoolConfig {@Value("${sandbox.docker.host:tcp://localhost:2375}")private String dockerHost;@Value("${sandbox.docker.image:openjdk:8-jdk-alpine}")private String sandboxImage;@Value("${sandbox.docker.volume:/usr/share/java}")private String volumeDir;@Value("${sandbox.limit.memory:100000000}")private Long memoryLimit;@Value("${sandbox.limit.memory-swap:100000000}")private Long memorySwapLimit;@Value("${sandbox.limit.cpu:1}")private Long cpuLimit;@Value("${sandbox.docker.pool.size:4}")private int poolSize;@Value("${sandbox.docker.name-prefix:oj-sandbox-jdk}")private String containerNamePrefix;@Beanpublic DockerClient createDockerClient(){DefaultDockerClientConfig clientConfig = DefaultDockerClientConfig.createDefaultConfigBuilder().withDockerHost(dockerHost).build();return DockerClientBuilder.getInstance(clientConfig).withDockerCmdExecFactory(new NettyDockerCmdExecFactory()).build();}@Beanpublic DockerSandBoxPool createDockerSandBoxPool(DockerClient dockerClient) {DockerSandBoxPool dockerSandBoxPool = new DockerSandBoxPool(dockerClient, sandboxImage, volumeDir, memoryLimit,memorySwapLimit, cpuLimit, poolSize, containerNamePrefix);dockerSandBoxPool.initDockerPool();return dockerSandBoxPool;}}
具体实现
@Service
public class SandboxPoolServiceImpl implements ISandboxPoolService {@Autowiredprivate DockerSandBoxPool sandBoxPool;@Autowiredprivate DockerClient dockerClient;private String containerId;private String userCodeFileName;@Value("${sandbox.limit.time:5}")private Long timeLimit;@Overridepublic SandBoxExecuteResult exeJavaCode(Long userId,String userCode, List<String> inputList) {containerId = sandBoxPool.getContainer();//创建对应文件createUserCodeFile(userCode);//编译代码CompileResult compileResult = compileCodeByDocker();//编译失败if (!compileResult.isCompiled()){//向容器池返回对应的容器sandBoxPool.returnContainer(containerId);deleteUserCodeFile();return SandBoxExecuteResult.fail(CodeRunStatus.COMPILE_FAILED,compileResult.getExeMessage());}//执行代码return executeJavaCodeByDocker(inputList);}//创建并返回用户代码的文件private void createUserCodeFile(String userCode) {//获取用户代码文件的路径String codeDir = sandBoxPool.getCodeDir(containerId);userCodeFileName = codeDir + File.separator + JudgeConstants.USER_CODE_JAVA_CLASS_NAME;//如果文件之前存在,将之前的文件删除掉if (FileUtil.exist(userCodeFileName)) {FileUtil.del(userCodeFileName);}FileUtil.writeString(userCode, userCodeFileName, Constants.UTF8);}//编译//的使用docker编译private CompileResult compileCodeByDocker() {String cmdId = createExecCmd(JudgeConstants.DOCKER_JAVAC_CMD, null, containerId);DockerStartResultCallback resultCallback = new DockerStartResultCallback();CompileResult compileResult = new CompileResult();try {dockerClient.execStartCmd(cmdId).exec(resultCallback).awaitCompletion();if (CodeRunStatus.FAILED.equals(resultCallback.getCodeRunStatus())) {compileResult.setCompiled(false);compileResult.setExeMessage(resultCallback.getErrorMessage());} else {compileResult.setCompiled(true);}return compileResult;} catch (InterruptedException e) {//此处可以直接抛出 已做统一异常处理 也可再做定制化处理throw new RuntimeException(e);}}private SandBoxExecuteResult executeJavaCodeByDocker(List<String> inputList) {List<String> outList = new ArrayList<>(); //记录输出结果long maxMemory = 0L; //最大占用内存long maxUseTime = 0L; //最大运行时间//执行用户代码for (String inputArgs : inputList) {String cmdId = createExecCmd(JudgeConstants.DOCKER_JAVA_EXEC_CMD, inputArgs, containerId);//执行代码StopWatch stopWatch = new StopWatch(); //执行代码后开始计时//执行情况监控StatsCmd statsCmd = dockerClient.statsCmd(containerId); //启动监控StatisticsCallback statisticsCallback = statsCmd.exec(new StatisticsCallback());stopWatch.start();DockerStartResultCallback resultCallback = new DockerStartResultCallback();try {dockerClient.execStartCmd(cmdId).exec(resultCallback).awaitCompletion(timeLimit, TimeUnit.SECONDS);if (CodeRunStatus.FAILED.equals(resultCallback.getCodeRunStatus())) {//未通过所有用例返回结果return SandBoxExecuteResult.fail(CodeRunStatus.NOT_ALL_PASSED);}} catch (InterruptedException e) {throw new RuntimeException(e);}stopWatch.stop(); //结束时间统计statsCmd.close(); //结束docker容器执行统计long userTime = stopWatch.getLastTaskTimeMillis(); //执行耗时maxUseTime = Math.max(userTime, maxUseTime); //记录最大的执行用例耗时Long memory = statisticsCallback.getMaxMemory();if (memory != null) {maxMemory = Math.max(maxMemory, statisticsCallback.getMaxMemory()); //记录最大的执行用例占用内存}outList.add(resultCallback.getMessage().trim()); //记录正确的输出结果}sandBoxPool.returnContainer(containerId);deleteUserCodeFile(); //清理文件return getSanBoxResult(inputList, outList, maxMemory, maxUseTime); //封装结果}private String createExecCmd(String[] javaCmdArr, String inputArgs, String containerId) {if (!StrUtil.isEmpty(inputArgs)) {//当入参不为空时拼接入参String[] inputArray = inputArgs.split(" "); //入参javaCmdArr = ArrayUtil.append(JudgeConstants.DOCKER_JAVA_EXEC_CMD, inputArray);}ExecCreateCmdResponse cmdResponse = dockerClient.execCreateCmd(containerId).withCmd(javaCmdArr).withAttachStderr(true).withAttachStdin(true).withAttachStdout(true).exec();return cmdResponse.getId();}private SandBoxExecuteResult getSanBoxResult(List<String> inputList, List<String> outList,long maxMemory, long maxUseTime) {if (inputList.size() != outList.size()) {//输入用例数量 不等于 输出用例数量 属于执行异常return SandBoxExecuteResult.fail(CodeRunStatus.NOT_ALL_PASSED, outList, maxMemory, maxUseTime);}return SandBoxExecuteResult.success(CodeRunStatus.SUCCEED, outList, maxMemory, maxUseTime);}private void deleteUserCodeFile() {FileUtil.del(userCodeFileName);}
}
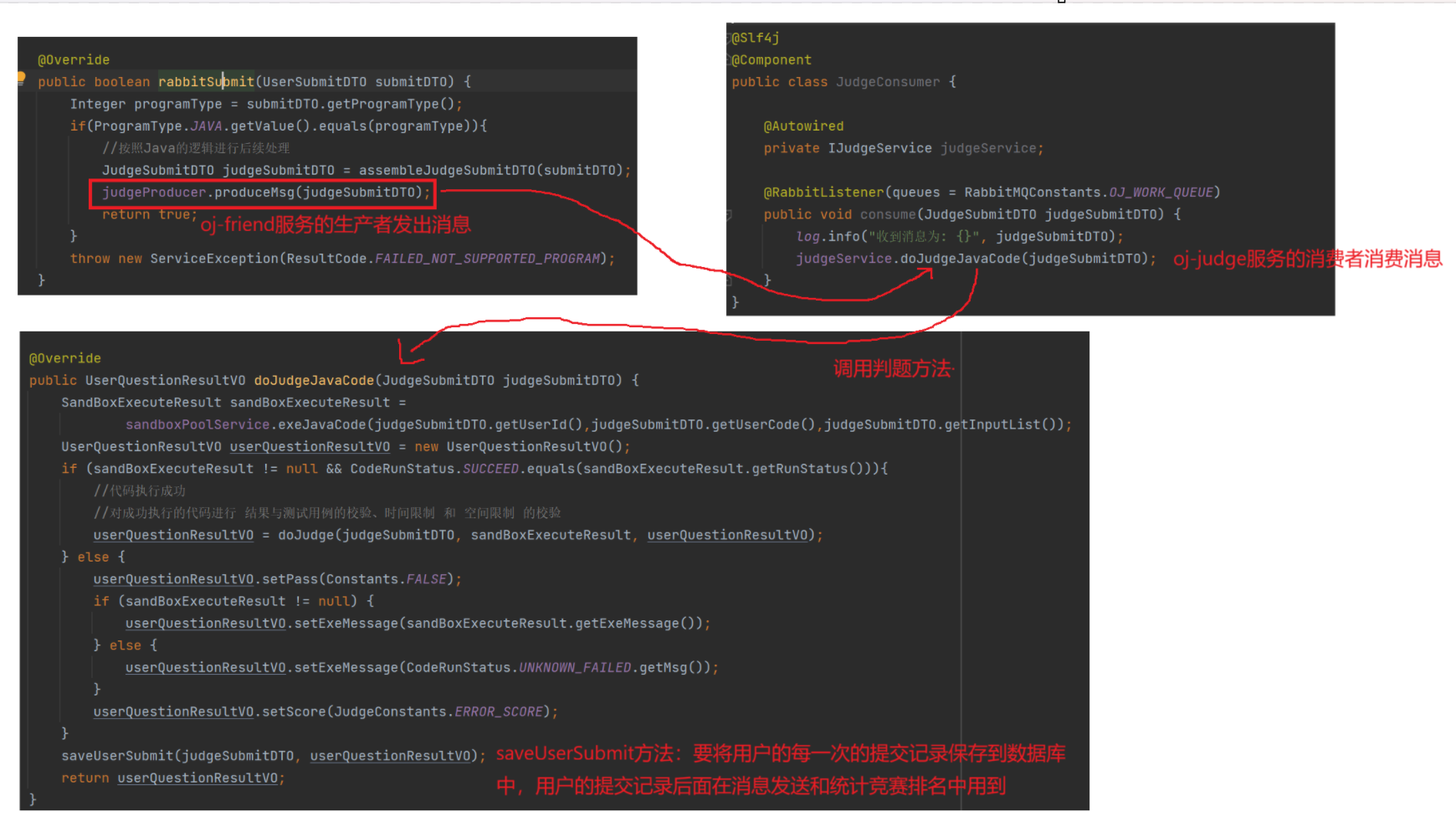
8.4判题功能代码---mq版本
为了应对高并发,在判题功能这快也引入了rabbitmq来实现削峰填谷,用户点击提交代码的按钮,oj-friend微服务的生产者生产消息,oj-judge服务的消费者消费队列中的任务,调用判题服务
9.用户拉黑功能---用户行为限制
由于我的项目写到这里的时候,大部分的功能就已经实现了,如果用户被拉黑了,此时用户的行为就要收到限制,所以此时为了实现这个功能,就需要在每一个B端功能实现时加上一些判断用户状态的代码,但是为了避免重复写同样的代码,且为了以后功能的扩展更加的顺利,此时就使用了AOP切面,通过一个自定义注解来解决这个问题,此时只需要在一些controller层的接口加上这个注解就可以实现用户状态判断的功能
首先,创建一个自定义注解
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface CheckUserStatus {}接着创建一个类,加上@Aspect注解,实现该注解的逻辑
@Aspect
@Component
public class UserStatusCheckAspect {@Autowiredprivate UserCacheManager userCacheManager;@Before(value = "@annotation(com.bite.friend.aspect.CheckUserStatus)")public void before(JoinPoint point){Long userId = ThreadLocalUtil.get(Constants.USER_ID, Long.class);UserVO user = userCacheManager.getUserById(userId);if (user == null) {throw new ServiceException(ResultCode.FAILED_USER_NOT_EXISTS);}if (Objects.equals(user.getStatus(), Constants.FALSE)) {throw new ServiceException(ResultCode.FAILED_USER_BANNED);}}
}然后就是在对应的controller层接口加上这个自定义注解

10.竞赛结果消息通知
10.1 数据表结构设计
竞赛结果消息通知功能的实现涉及到站内信。
站内信:网站内部的一种通信方式,一般有三种形式
第一种:用户与用户之间的通信(点对点)
第二种:管理员/系统 和 某个用户之间的通信(点对点)
第三种:管理员/系统 和 某个用户群(指的是满足某一条件的用户群体)之间的通信(点对面)
那么竞赛结果消息通知属于那种站内信呢?
可能一开始我们会觉得竞赛消息结果通知就是系统向参加竞赛的一些群体用户发送消息,自然而然是点对面的站内信了,但是有一点需要注意的是:对与参加竞赛的用户来说,每一个参加竞赛的用户最终的竞赛排名是不同的,也就是每个用户接受到的竞赛结果消息是不一样的,所以竞赛结果消息通知是系统要向每一位参加竞赛的用户发送一个不同排名的消息,所以此时竞赛结果消息结果通知属于第二种站内信
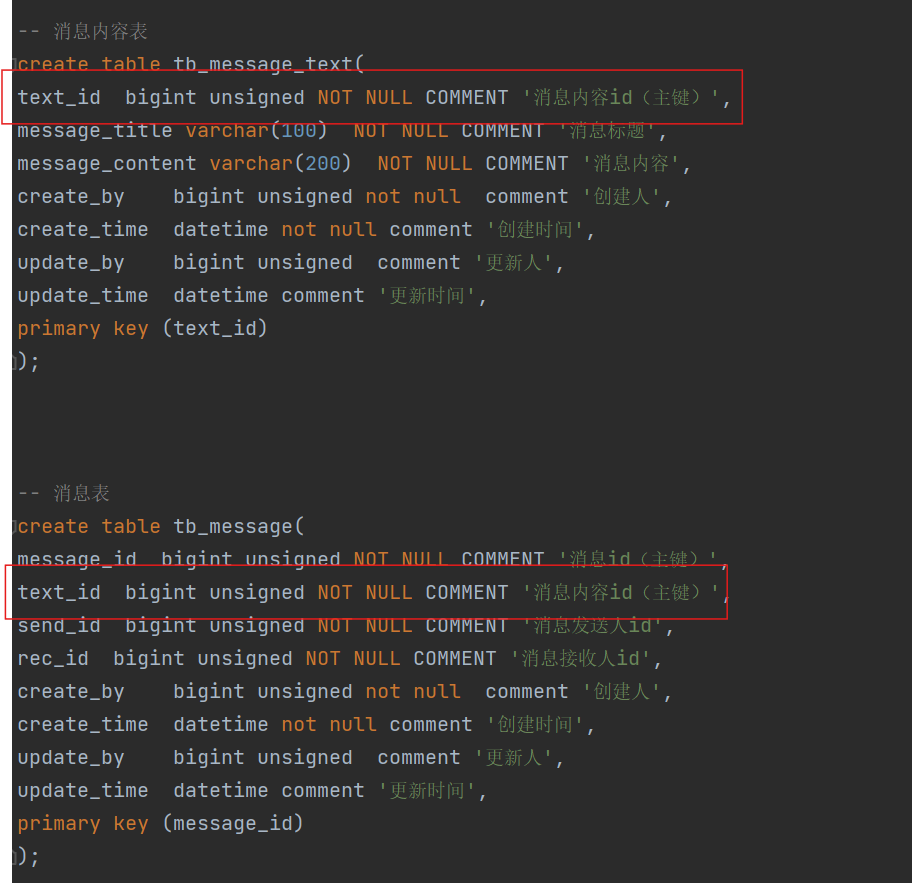
知道属于是哪一种站内信后,开始设计数据库表结构,可能一开始会这样来设计数据库表结构,会有这几个字段,分别为主键id,消息标题,消息内容,消息接受方和消息发送方
但是这样设计会有一个问题,如果以后我们系统的功能还要加上第一种站内信和第三种站内信,此时的数据库表结构是可以符合的,但是对于第三种站内信来说,可能会造成数据冗余的问题,因为第三种站内信中用户接收到的消息是一样的,此时数据库表中的消息内容就会存储大量的相同内容,就会造成了数据冗余
如何解决呢?
可以通过设计两张表来解决,一张message_text表用来记录消息标题和消息内容,另一种message表记录message_text表的消息发送方和消息接受方
10.2 我的消息功能开发
我的消息功能分为两步:消息的发送和消息的展示
消息的发送,我们只要通过定时任务生成消息,将生成的消息存储到数据库和缓存中即可
消息的展示,就是从数据库或者缓存中获取生成的消息即可
代码实现:
生成消息的定时任务代码
@XxlJob("examResultHandler")public void examResultHandler() {//先将前一天结束的竞赛统计出来log.info("*** examResultHandler ***");LocalDateTime now = LocalDateTime.now();LocalDateTime minusDatetime = now.minusDays(1);List<Exam> examList = examMapper.selectList(new LambdaQueryWrapper<Exam>().select(Exam::getExamId,Exam::getTitle).eq(Exam::getStatus, Constants.TRUE).ge(Exam::getEndTime, minusDatetime).le(Exam::getEndTime, now));if (CollectionUtil.isEmpty(examList)){return;}//统计总分和排名Set<Long> examIdSet = examList.stream().map(Exam::getExamId).collect(Collectors.toSet());List<UserScore> userScoreList = userSubmitMapper.selectUserScoreList(examIdSet);//以竞赛为单位划分userScoreList,将每一个竞赛的排名情况都单独划分出来Map<Long, List<UserScore>> userScoreMap = userScoreList.stream().collect(Collectors.groupingBy(UserScore::getExamId));createMessage(examList,userScoreMap);}private void createMessage(List<Exam> examList, Map<Long, List<UserScore>> userScoreMap) {List<MessageText> messageTextList = new ArrayList<>();List<Message> messageList = new ArrayList<>();for (Exam exam : examList){Long examId = exam.getExamId();List<UserScore> userScoreList = userScoreMap.get(examId);if (userScoreList == null){continue;}int totalUser = userScoreList.size();int examRank=1;for (UserScore userScore : userScoreList){String msgTitle = exam.getTitle()+"——排名情况";String msgContent = "您所参加的竞赛:"+exam.getTitle()+"本次参与竞赛一共"+totalUser+"人,您排名第"+examRank+"名!";userScore.setExamRank(examRank);MessageText messageText = new MessageText();messageText.setMessageTitle(msgTitle);messageText.setMessageContent(msgContent);messageText.setCreateBy(Constants.SYSTEM_USER_ID);messageTextList.add(messageText);Message message = new Message();message.setSendId(Constants.SYSTEM_USER_ID);message.setCreateBy(Constants.SYSTEM_USER_ID);message.setRecId(userScore.getUserId());messageList.add(message);examRank++;}userExamMapper.updateUserScoreAndRank(userScoreList);String examRankListKey = getExamRankListKey(examId);redisService.rightPushAll(examRankListKey,userScoreList);}//批量插入,提高效率messageTextService.batchInsert(messageTextList);Map<String,MessageTextVO> messageTextVOMap = new HashMap<>();for (int i = 0; i < messageTextList.size(); i++) {MessageText messageText = messageTextList.get(i);MessageTextVO messageTextVO = new MessageTextVO();BeanUtil.copyProperties(messageText,messageTextVO);String msgDetailKey = getMsgDetailKey(messageText.getTextId());messageTextVOMap.put(msgDetailKey,messageTextVO);Message message = messageList.get(i);message.setTextId(messageText.getTextId());}//批量插入,提高效率messageService.batchInsert(messageList);//根据用户的id对messageList中的数据分组Map<Long, List<Message>> userMsgMap = messageList.stream().collect(Collectors.groupingBy(Message::getRecId));Iterator<Map.Entry<Long, List<Message>>> iterator = userMsgMap.entrySet().iterator();while (iterator.hasNext()){Map.Entry<Long, List<Message>> entry = iterator.next();Long recId = entry.getKey();String userMagListKey = getUserMsgListKey(recId);List<Long> userMsgTextIdList = entry.getValue().stream().map(Message::getTextId).toList();//同步到redis中redisService.rightPushAll(userMagListKey,userMsgTextIdList);}//批量插入,提高效率redisService.multiSet(messageTextVOMap);}public void refreshCache(List<Exam> examList,String examListLey) {if (CollectionUtil.isEmpty(examList)) {return;}Map<String, Exam> examMap = new HashMap<>();List<Long> examIdList = new ArrayList<>();for (Exam exam : examList) {examMap.put(getDetailKey(exam.getExamId()), exam);examIdList.add(exam.getExamId());}redisService.multiSet(examMap); //刷新详情缓存(竞赛基本信息) 批量插入缓存redisredisService.deleteObject(examListLey); //将之前的缓存的key删掉,因为之前存的key可能会有问题,导致后面的插入有问题redisService.rightPushAll(examListLey, examIdList); //刷新列表缓存}