MySQL 主从复制故障排查及解决方案
在 MySQL 运维中,主从复制是实现数据备份、读写分离、高可用的核心架构,但实际部署和运行过程中,常会因配置、网络、数据一致性等问题导致复制中断。本文基于实战场景,梳理了 9 类高频主从复制故障,包含问题模拟、报错分析及分步解决方案,适用于 MySQL 运维人员参考。
1. server_id 重复导致复制中断
问题模拟
MySQL 主从复制要求所有节点的server_id唯一(取值范围 1-4294967295)。若从库server_id与主库一致,会触发复制校验失败。
-
查看主库
server_id:在从库执行show slave status\G,从Master_Server_Id字段获取主库 ID(例:12161); -
故意将从库
server_id改为与主库一致:
set global server_id=12161; -- 与主库ID相同stop slave; -- 重启复制start slave;
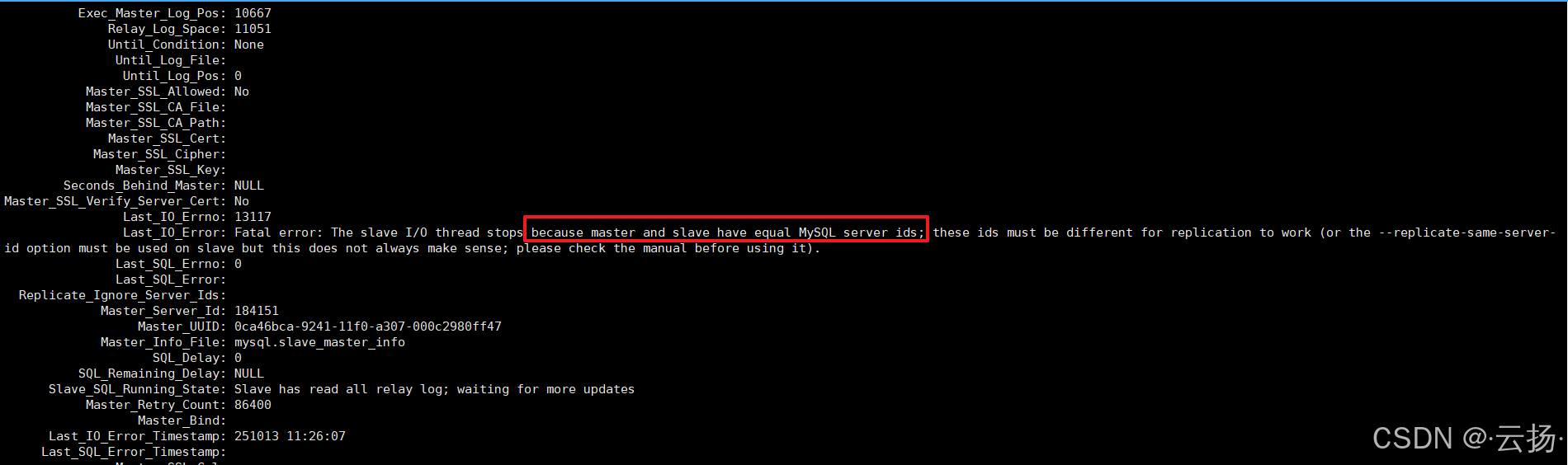
- 查看报错:执行
show slave status\G,会提示 “server_id of slave is equal to server_id of master”。
解决方案
- 修改从库
server_id为唯一值(例:12162):
set global server_id=12162; -- 确保与主库及其他从库不重复
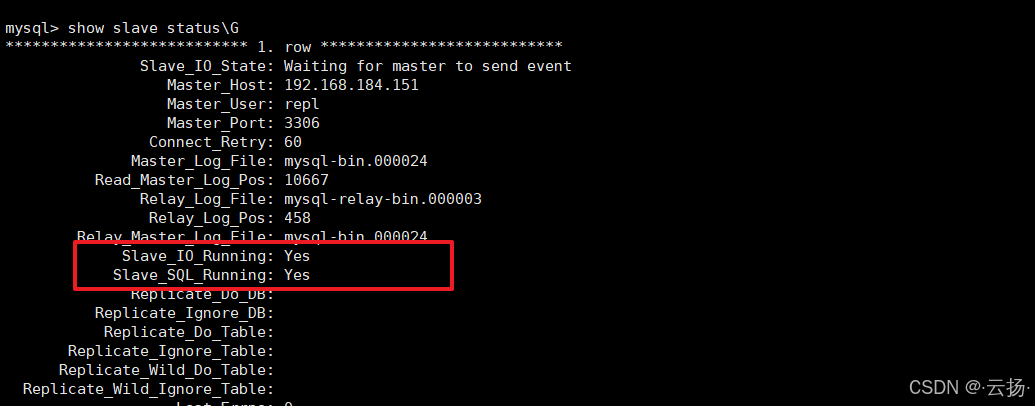
- 重启复制并验证:
stop slave;start slave;show slave status\G -- 观察Slave_IO_Running和Slave_SQL_Running是否均为Yes
2. 主从端口不通(3306 端口被拦截)
问题模拟
主库防火墙拦截从库对 3306 端口的访问,导致从库无法连接主库获取 Binlog。
- 主库添加防火墙规则,禁止从库 IP(例:192.168.12.162)访问 3306:
iptables -A INPUT -s 192.168.12.162 -p tcp --dport 3306 -j DROP
- 从库测试端口连通性:
telnet 192.168.12.161 3306 -- 提示"Connection refused"或超时
- 查看复制状态:
show slave status\G会显示 “Slave_IO_Running: Connecting,Seconds_Behind_Master: NULL”,报错 “Got timeout reading communication packets”。
解决方案
- 主库删除拦截规则(先查看规则行号):
iptables -L -n --line-numbers -- 找到DROP规则的行号(例:1)iptables -D INPUT 1 -- 删除第1条规则;若需清空所有规则,执行iptables -F
- 从库验证端口连通性:
telnet 192.168.12.161 3306 -- 出现"Connected to..."表示通了
- 重启复制并验证:
stop slave;start slave;show slave status\G -- 确认Slave_IO_Running转为Yes
3. 从库磁盘空间满导致复制中断
问题模拟
从库磁盘耗尽后,无法写入 Relay Log 或数据文件,导致复制停止甚至 MySQL 进程崩溃。
- 查看从库磁盘空间:
df -Th -- 显示磁盘使用率100%
- 模拟磁盘占满:创建 15G 临时文件(需确保剩余空间不足 15G):
dd if=/dev/zero of=fill bs=1M count=15000
-
主库写入数据(例:通过存储过程插入 1 万行测试数据),从库执行
show slave status\G会发现:-
复制延迟(Seconds_Behind_Master)持续增加;
-
执行
stop slave时,MySQL 可能因磁盘满而异常中断。

-
解决方案
- 释放从库磁盘空间:
du -sh * -- 查看当前目录大文件/文件夹(例:找到fill临时文件)rm -f fill -- 删除无用大文件;若为日志文件,可清理MySQL慢查询日志、Binlog(需确认安全)df -Th -- 确认磁盘使用率降至合理范围(建议<80%)
- 重启 MySQL 服务(若已崩溃):
/etc/init.d/mysql.server start
- 验证复制状态:
show slave status\G -- 确认复制恢复,延迟逐渐降低
4. 主库新增内容在从库已存在(数据冲突)
问题模拟
从库手动创建了主库后续要新增的对象(如数据库、表),导致主库 SQL 同步到从库时触发 “已存在” 错误。
- 从库手动创建数据库:
create database martin_test;
- 主库执行相同建库语句:
create database martin_test;
- 从库查看报错:
show slave status\G中Last_SQL_Error提示 “Can’t create database ‘martin_test’; database exists”。
解决方案
需根据复制模式(GTID / 位点)跳过冲突事务:
方案 1:GTID 模式
-
查看从库已执行的 GTID:
show slave status\G中Executed_Gtid_Set(例:65c07f5e-1e37-11ed-b657-fa163e0d61f4:1-10139); -
跳过下一个 GTID(冲突事务):
stop slave;-- 设置下一个GTID为Executed_Gtid_Set的下一个值(10139+1=10140)set @@session.gtid_next='65c07f5e-1e37-11ed-b657-fa163e0d61f4:10140';begin; commit; -- 空事务代替冲突事务set session gtid_next='AUTOMATIC'; -- 恢复自动GTID分配start slave;
方案 2:位点模式
stop slave;set GLOBAL SQL_SLAVE_SKIP_COUNTER=1; -- 跳过1个事务(冲突事务)start slave;show slave status\G -- 确认SQL线程恢复
5. 主库要更新的记录从库没有
问题模拟
主库执行更新操作时,若从库对应记录已被手动删除,会导致从库 SQL 线程执行同步事务时触发 “记录不存在” 错误,复制中断。
- 主库准备测试数据:创建表并插入初始数据
use martin_test; -- 沿用前文创建的测试库
-- 创建测试表(指定InnoDB引擎和utf8mb4字符集,确保主从一致)
CREATE TABLE test_repl (
id int NOT NULL AUTO_INCREMENT,
a int NOT NULL,
PRIMARY KEY (id) -- 主键确保数据唯一性
) ENGINE=InnoDB CHARSET=utf8mb4;
-- 插入2条测试数据
insert into test_repl values (1,1),(2,2);
- 从库手动删除记录:模拟数据不一致场景
use martin_test;
delete from test_repl where id=1; -- 删除id=1的记录,主库此记录仍存在
- 主库执行更新操作:触发同步冲突
use martin_test;
update test_repl set a=2 where id=1; -- 更新主库中存在、从库已删除的记录
- 从库查看报错:执行
show slave status\G,Last_SQL_Error会提示 “Could not execute Update_rows event on table martin_test.test_repl; Can’t find record in ‘test_repl’”,明确表示要更新的记录不存在。

解决方案
核心思路:通过解析从库 Relay Log(中继日志)获取主库更新操作的原始条件,在从库补全缺失记录后恢复复制。
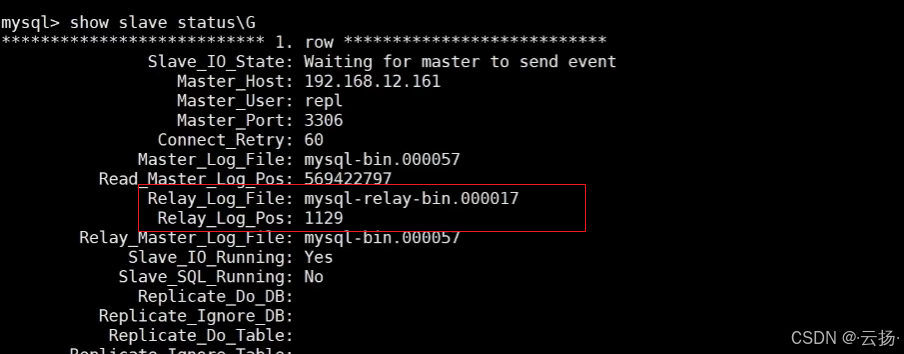
- 定位 Relay Log 位置:从
show slave status\G结果中获取关键信息:Relay_Log_File:当前使用的中继日志文件(例:mysql-relay-bin.000017)Relay_Log_Pos:当前同步位置(例:1129)
- 解析 Relay Log 获取原始数据:使用mysqlbinlog工具解码中继日志,提取更新操作的原始记录值
# 进入Relay Log所在目录(通常与Binlog目录一致)
cd /data/mysql/binlog
# 解析指定位置的日志,输出为可读SQL文件(--base64-output=decode-rows确保行数据解码)
mysqlbinlog mysql-relay-bin.000017 --start-position=1129 --base64-output=decode-rows -v > /tmp/1129.sql
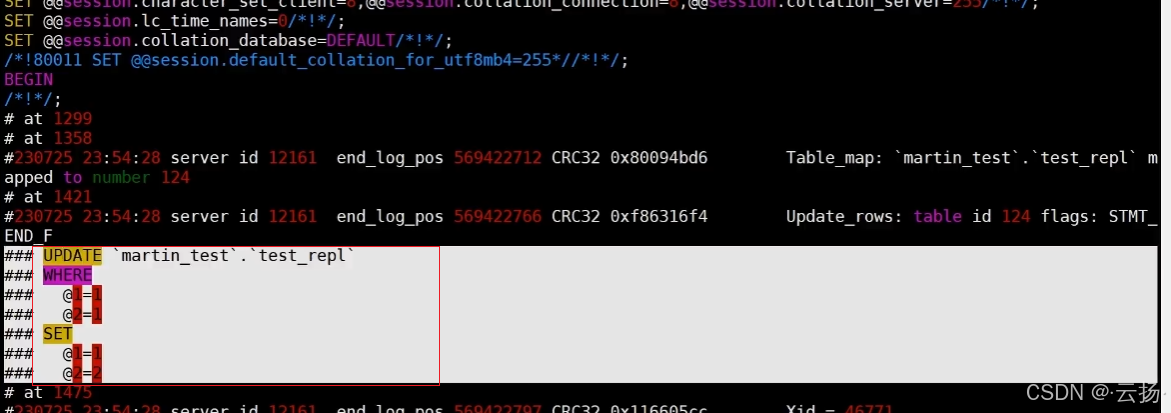
- 查看解析结果:打开/tmp/1129.sql,找到UPDATE语句对应的WHERE条件(即主库更新前的原始数据),可确认缺失记录为id=1, a=1。
- 从库补全缺失记录:根据解析结果插入缺失数据
use martin_test;
insert into test_repl select 1,1; -- 补全id=1的原始记录
- 重启复制并验证:
stop slave; -- 停止复制
start slave; -- 重启复制
show slave status\G -- 查看状态,确认Slave_IO_Running和Slave_SQL_Running均为Yes,无报错
6. 找不到主库的 Binlog 位点(Binlog 被清理)
问题模拟
主库清理了从库未同步的 Binlog 文件(如执行purge binary logs),导致从库启动复制时提示 “Binlog file not found”。
-
从库停止复制:
stop slave;; -
主库刷新并清理 Binlog:
flush logs; -- 生成新Binlog文件(例:mysql-bin.000059)create database a1; -- 写入新事务(Binlog记录在000059)flush logs; -- 再次刷新,生成000060show binary logs;purge binary logs to 'mysql-bin.000059'; -- 清理000059之前的Binlog
- 从库启动复制:
start slave;,执行show slave status\G会报错 “Could not find first log file name in binary log index file”。
解决方案
根据是否有其他正常从库,分两种场景处理:
场景 1:有其他正常从库(推荐)
将故障从库改为 “从从库”,从正常从库同步缺失事务:
stop slave;-- 指向正常从库(例:192.168.152.30),使用GTID自动定位位点change master tomaster_host='192.168.152.30',master_user='repl', -- 复制账号master_password='Uid_dQc63',MASTER_AUTO_POSITION=1;start slave;
场景 2:无其他从库(重建复制)
通过 XtraBackup 备份主库,重建从库复制:
- 主库备份数据:
cd /data/backuprm -rf ./* -- 清空旧备份# 流式备份(适合跨机器传输)xtrabackup --defaults-file=/data/mysql/conf/my.cnf -uroot -p --backup --stream=xbstream --target-dir=./ > extrabackup.xbstream
- 从库恢复数据:
mkdir /data/backup/recover -- 创建恢复目录scp 主库IP:/data/backup/extrabackup.xbstream /data/backup/recover/ -- 传输备份/etc/init.d/mysql.server stop -- 停止从库MySQLrm /data/mysql/data/* -rf && rm /data/mysql/binlog/* -rf -- 清空旧数据cd /data/backup/recoverxbstream -x < extrabackup.xbstream -- 解压备份xtrabackup --prepare --target-dir=./ -- 准备备份(一致性恢复)# 复制备份到数据目录xtrabackup --defaults-file=/data/mysql/conf/my.cnf --copy-back --target-dir=./chown -R mysql.mysql /data/mysql -- 修改权限/etc/init.d/mysql.server start -- 启动从库
- 从库建立主从关系:
cat /data/backup/recover/xtrabackup_binlog_info -- 查看备份对应的主库Binlog位点stop slave;change master tomaster_host='主库IP',master_user='repl',master_password='Uid_dQc63',MASTER_AUTO_POSITION=1; -- 或指定Binlog文件和位点start slave;
7. GTID 空洞的产生场景
GTID(全局事务 ID)是主从复制中唯一标识事务的 ID,若 GTID 序列出现不连续(如 1-2 后直接 5-6),则称为 “GTID 空洞”,可能导致复制异常。
常见产生原因
-
手动跳过事务:如执行
set GLOBAL SQL_SLAVE_SKIP_COUNTER=1(位点模式)或手动指定gtid_next跳过事务; -
主从切换:主库故障切换后,新主库的 GTID 序列与旧主库未衔接;
-
slave-skip-errors=all:配置从库跳过所有 SQL 错误,若某 DDL/DML 事务被跳过,会导致 GTID 缺失。
规避建议
-
禁止在 GTID 模式下使用
SQL_SLAVE_SKIP_COUNTER; -
主从切换前,确保所有从库已同步旧主库的 GTID;
-
避免设置
slave-skip-errors=all,仅针对特定无害错误(如 1062 主键冲突)跳过。
8. 主从 UUID 重复问题
问题现象
从库启动复制时提示 “The server UUIDs are equal”,即主从库 UUID 相同。
根本原因
从库服务器是主库的克隆机,而 MySQL 的 UUID 存储在数据目录的auto.cnf文件中(格式:server-uuid=xxxx-xxxx-xxxx-xxxx),克隆会导致auto.cnf内容一致,UUID 重复。
解决方案
-
停止从库 MySQL:
/etc/init.d/mysql.server stop; -
删除从库的
auto.cnf文件(路径例:/data/mysql/data/auto.cnf); -
重启从库 MySQL:
/etc/init.d/mysql.server start;- 重启后 MySQL 会自动生成新的 UUID,写入新的
auto.cnf;
- 重启后 MySQL 会自动生成新的 UUID,写入新的
-
重新建立主从复制:
change master to ...后启动复制即可。
9. 从库是否可能读到比主库更新的数据?
在 “一主两从” 架构(1 个异步从库 + 1 个半同步从库)中,需结合 MySQL 复制类型和两阶段提交原理分析:
前置知识
-
两阶段提交:InnoDB 事务提交分两步:
-
Prepare 阶段:写入 Redo Log,标记事务为 “准备提交”;
-
Commit 阶段:写入 Binlog,再将 Redo Log 标记为 “已提交”。
-
-
复制类型:
-
异步复制:主库提交事务后立即返回客户端,不等待从库同步;
-
半同步复制(after_commit):主库执行 Commit 阶段后,等待从库确认接收 Binlog 再返回;
-
增强半同步复制(after_sync):主库执行 Prepare 阶段后,先发送 Binlog 给从库,待从库确认后再执行 Commit 阶段。
-
结论:特定场景下可能
-
场景 1:半同步为 after_commit:主库已执行 Commit,Redo Log 标记为 “已提交”,主库客户端可查新数据;此时异步从库即使同步到 Binlog,数据与主库一致,不会 “更新”。
-
场景 2:半同步为 after_sync:主库发送 Binlog 给从库后,从库(含异步从库)已回放 Binlog,但主库尚未执行 Commit 阶段(Redo Log 仍为 Prepare);此时主库客户端查不到新数据,但异步从库已能查到 —— 即异步从库读到比主库更新的数据。
规避建议
若需避免此问题,可将半同步复制模式改为after_commit(需在主库配置rpl_semi_sync_master_wait_point=AFTER_COMMIT),但会牺牲部分性能(主库需等待 Commit 后再返回)。
总结
MySQL 主从复制故障排查的核心思路是:先定位故障环节(IO 线程 / SQL 线程)→ 查看错误日志(/var/log/mysqld.log)→ 结合复制模式(GTID / 位点)选择解决方案。日常运维中,建议:
-
定期检查从库磁盘空间、复制延迟、GTID 完整性;
-
主库 Binlog 保留时间足够长(避免未同步就清理);
-
禁止手动修改从库数据(减少数据冲突);
-
半同步复制优先选择 after_commit 模式(平衡一致性与性能)。
通过本文的实战方案,可快速解决多数主从复制中断问题,保障 MySQL 架构的稳定性。