高并发系统性能测试:JMeter_Gatling 压测实战,测试场景设计与结果分析
高并发系统性能测试:JMeter/Gatling 压测实战,测试场景设计与结果分析
在高并发系统的生命周期中,性能测试是验证架构设计有效性、提前暴露性能瓶颈的关键环节。无论是电商大促前的容量验证,还是核心服务上线后的性能兜底,一份科学的性能测试报告能直接指导架构优化方向。作为架构师,掌握主流压测工具的实战技巧、精准的场景设计方法以及深度的结果分析能力,是保障系统在高并发场景下稳定运行的核心能力之一。本文将从高并发性能测试的基础认知切入,结合 JMeter 与 Gatling 两大工具的实战操作,拆解测试场景设计逻辑与结果分析维度,为入门者提供完整的高并发性能测试落地指南。
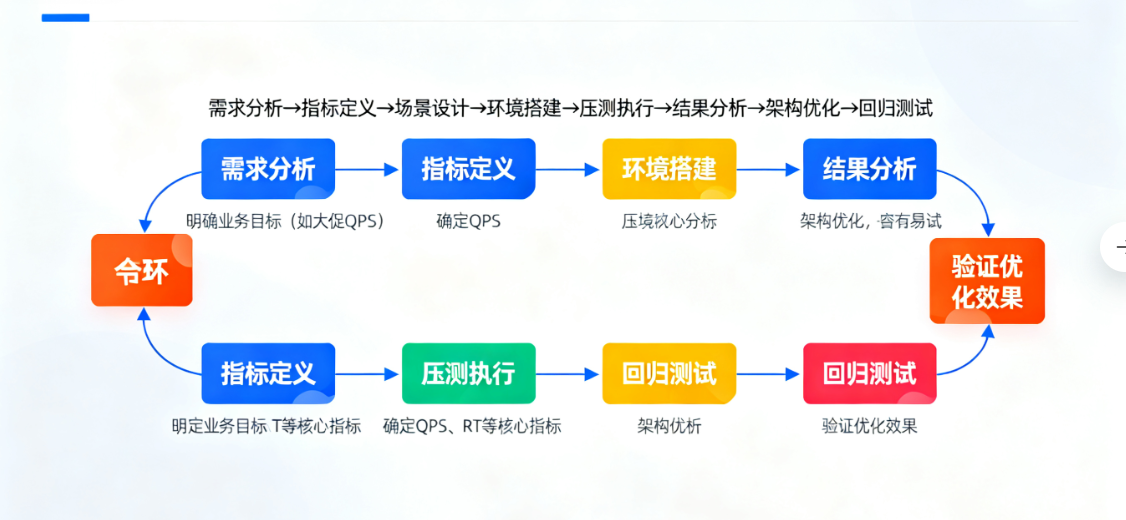
(图 1:高并发性能测试从需求分析到结果优化的全流程示意图)
一、高并发性能测试基础认知:先搞懂 “为什么测” 和 “测什么”
在动手搭建压测环境前,首先需要明确高并发性能测试的核心目标与关键指标,避免陷入 “为了压测而压测” 的误区。
1. 为什么要做高并发性能测试?—— 从业务价值反推测试意义
高并发性能测试的本质,是模拟真实业务场景下的流量压力,验证系统是否能满足预期的性能指标,同时定位潜在的性能瓶颈。其核心价值体现在三个维度:
-
容量验证:确认系统在目标并发量下(如电商大促 10 万 QPS)是否能稳定运行,避免线上因流量超预期导致服务崩溃;
-
瓶颈定位:提前发现系统中的性能短板,如数据库慢查询、缓存未命中、线程池参数不合理等,为架构优化提供依据;
-
成本优化:通过性能测试确定系统的最优资源配置(如服务器数量、数据库实例规格),避免过度扩容导致的资源浪费。
举个典型案例:某社交平台在热点事件爆发前未做性能测试,导致用户发布内容的接口 QPS 从日常 1 万飙升至 5 万时,出现大量请求超时,最终通过紧急扩容服务器才恢复服务 —— 若提前通过压测定位到 “消息队列消费能力不足” 的瓶颈,只需优化队列参数即可避免线上故障。
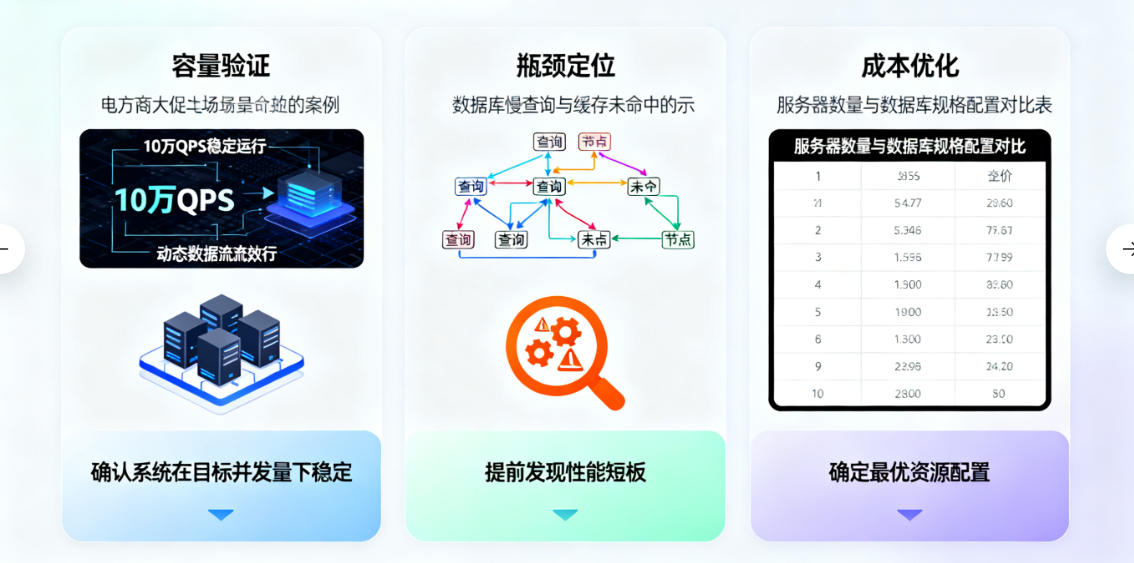
(图 2:高并发性能测试在容量验证、瓶颈定位、成本优化三大维度的业务价值)
2. 高并发性能测试核心指标:4 个关键维度评估系统性能
性能测试不是只看 “并发数”,而是需要通过多维度指标综合判断系统表现。以下 4 个核心指标是架构师必须关注的重点:
| 指标名称 | 定义与含义 | 行业参考标准(高并发场景) |
|---|---|---|
| 吞吐量(QPS/TPS) | 单位时间内系统处理的请求数(QPS:查询请求,TPS:事务请求),反映系统处理能力 | 核心接口 QPS 需满足业务峰值 120% 以上 |
| 响应时间(RT) | 从请求发起至接收响应的总时间,直接影响用户体验 | P99 响应时间≤500ms(99% 请求达标) |
| 错误率 | 失败请求占总请求的比例,反映系统稳定性 | 错误率≤0.1%(核心接口需≤0.01%) |
| 资源利用率 | 服务器 CPU、内存、磁盘 IO、网络带宽的使用占比,反映资源瓶颈 | CPU≤80%,内存≤85%,磁盘 IO≤70% |
需要注意的是,指标标准需结合业务场景调整:例如金融支付接口的错误率要求远高于普通资讯接口,而短视频推荐接口的响应时间容忍度可适当放宽。
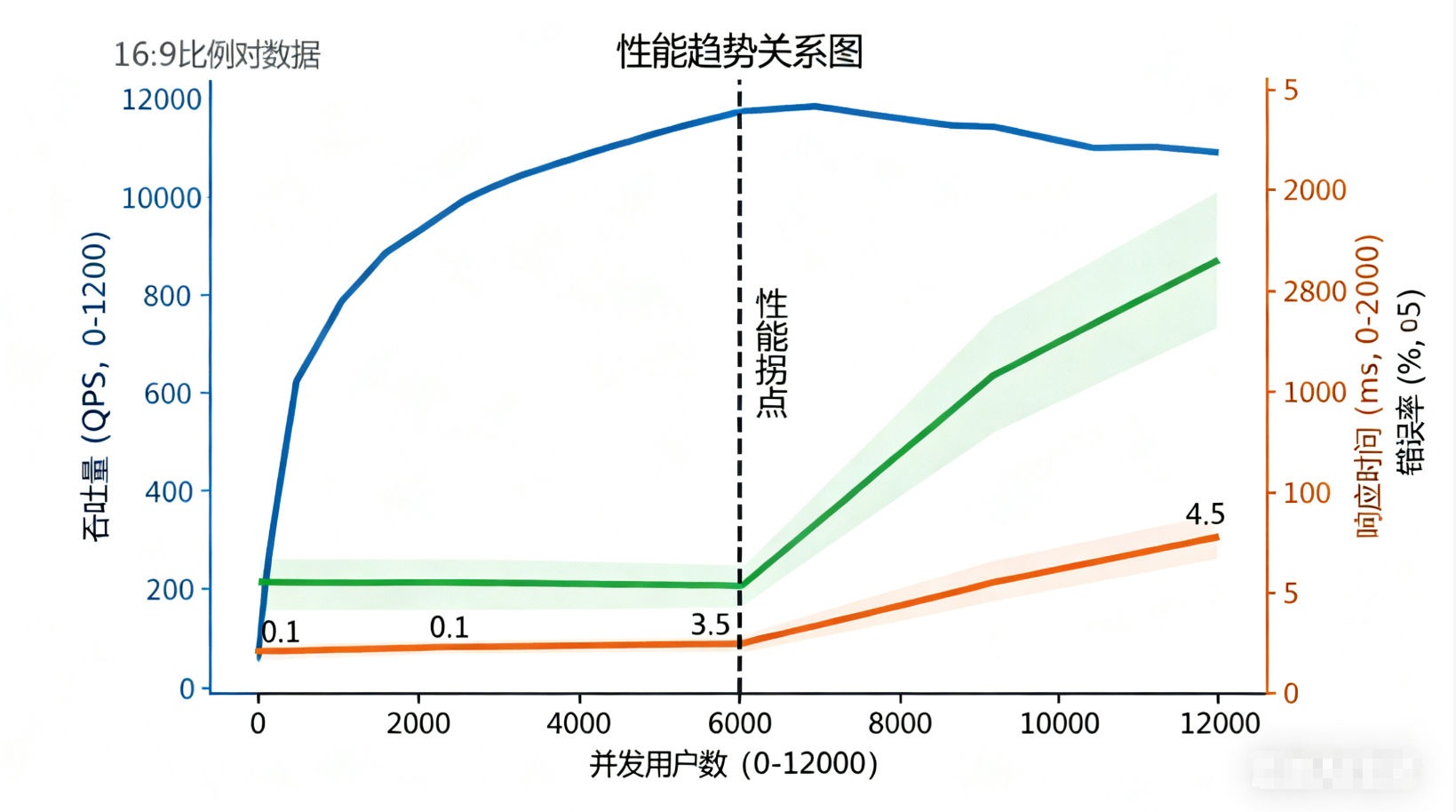
(图 3:吞吐量、响应时间、错误率随并发用户数变化的趋势关系图,当并发超过阈值后,响应时间飙升、错误率上升)
3. 高并发性能测试常见误区:避免这些 “踩坑” 行为
新手在做性能测试时,容易陷入以下误区,导致测试结果失真或无法指导实践:
-
误区 1:用 “单接口压测” 替代 “全链路压测”
只压测 “商品详情页” 接口,忽略 “用户登录→购物车→下单” 的全链路依赖,导致线上全链路调用时出现瓶颈(如购物车缓存未生效)。
-
误区 2:压测数据与真实业务不一致
用随机生成的无效数据压测,而非真实用户的商品 ID、用户 ID,导致缓存命中率、数据库索引利用率与线上差异大,测试结果无参考价值。
-
误区 3:忽略 “长时间稳定性测试”
仅压测 5 分钟的峰值流量,未做 24 小时稳定性测试,导致线上运行 10 小时后因内存泄漏出现服务崩溃。
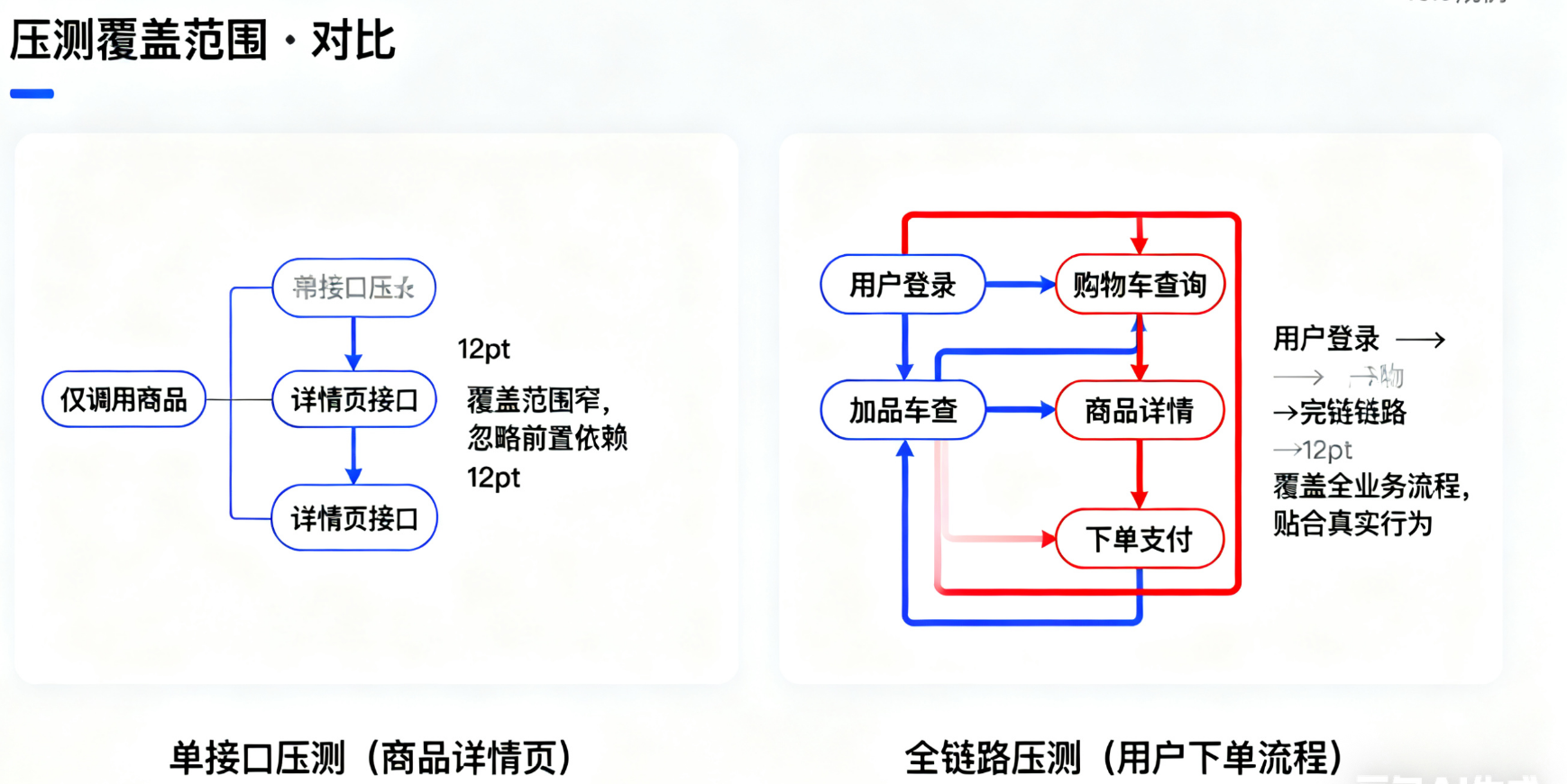
(图 4:单接口压测与全链路压测的覆盖范围对比,全链路压测更贴近真实业务场景)
二、主流压测工具实战:JMeter vs Gatling 操作指南
目前行业内最常用的高并发压测工具是 JMeter(Apache 开源)和 Gatling(Scala 语言开发,开源商业双版本)。两者各有优势:JMeter 生态完善、支持场景多,适合入门;Gatling 性能更高、脚本更简洁,适合高并发场景。以下分别介绍两者的核心实战步骤。
1. JMeter 实战:从环境搭建到压测执行(以 “电商商品详情页接口” 为例)
(1)环境准备
-
安装 JMeter:下载 Apache JMeter(推荐 5.x 版本),解压后通过
bin/jmeter.bat(Windows)或bin/jmeter.sh(Linux)启动。 -
配置 Java 环境:JMeter 依赖 JDK 8+,需提前配置
JAVA_HOME环境变量。 -
压测机器建议:若压测 10 万 QPS,需至少 2 台 8 核 16G 的压测机(避免单台机器资源不足成为瓶颈)。
(2)核心脚本设计(3 步完成)
Step 1:创建测试计划与线程组
-
打开 JMeter,右键 “测试计划”→“添加”→“Threads (Users)”→“线程组”。
-
配置线程组参数(关键参数说明):
-
线程数:模拟的并发用户数(如 1000 代表 1000 个并发用户);
-
Ramp-Up 时间:线程数全部启动的耗时(如 10 秒启动 1000 线程,即每秒启动 100 线程,避免瞬间压垮系统);
-
循环次数:压测持续轮次(若勾选 “永远”,则需手动停止压测)。
-
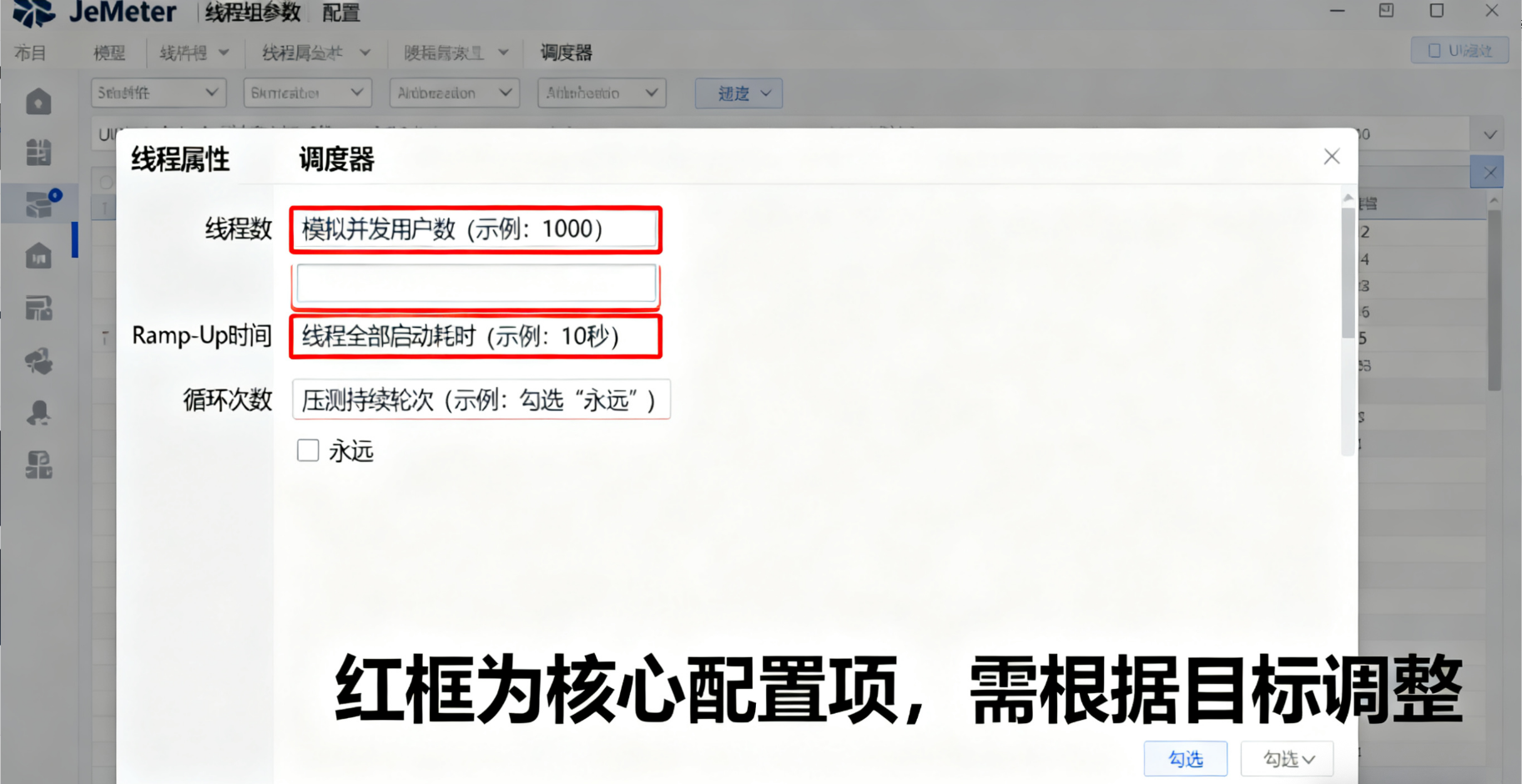
(图 5:JMeter 线程组参数配置界面,红框标注核心配置项)
Step 2:添加 HTTP 请求(商品详情页接口)
-
右键线程组→“添加”→“Sampler”→“HTTP 请求”。
-
配置接口参数:
-
协议:HTTP/HTTPS;
-
服务器名称或 IP:目标接口域名(如
api.xxx.com); -
端口号:默认 80(HTTP)或 443(HTTPS);
-
路径:接口路径(如
/product/detail); -
参数:添加
productId(真实商品 ID,如1001,1002,1003,避免用随机值)。
-
Step 3:添加监听器(查看压测结果)
-
右键线程组→“添加”→“Listener”,推荐添加以下 3 个监听器:
-
聚合报告:查看平均响应时间、QPS、错误率等核心指标;
-
查看结果树:查看每个请求的详细响应(用于排查错误);
-
响应时间曲线:查看响应时间随压测时间的变化趋势(判断是否存在性能衰减)。
-
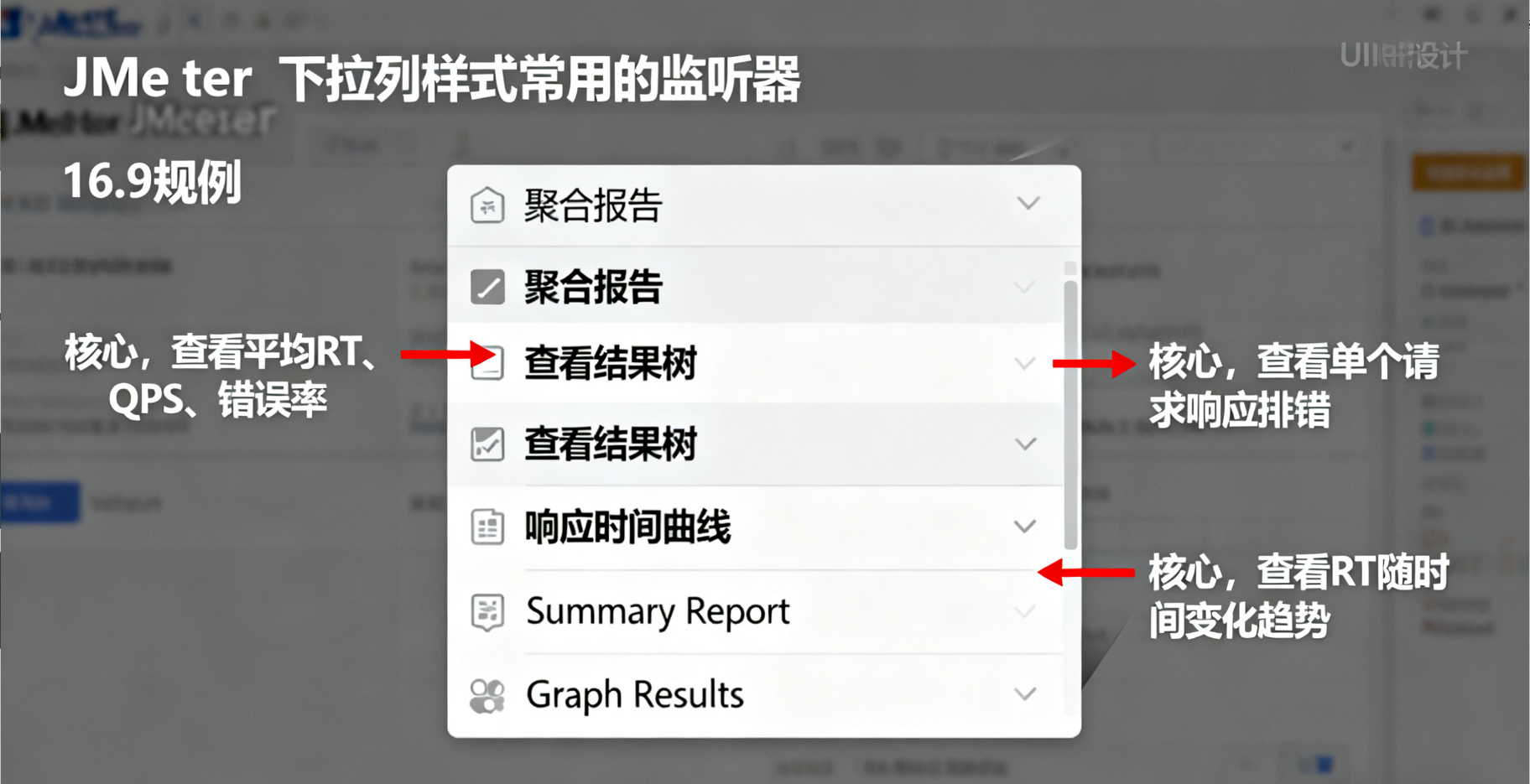
(图 6:JMeter 常用监听器列表,箭头指向核心监听器)
(3)压测执行与优化
-
执行压测:点击 JMeter 工具栏 “启动” 按钮,开始压测(建议先以 50 线程试运行,确认脚本无错误后再逐步提升线程数)。
-
性能优化:若 JMeter 压测时出现 “自身 CPU 利用率过高”,可做以下优化:
-
关闭 GUI 界面,用命令行执行(
jmeter -n -t testplan.jmx -l result.jtl),减少 GUI 资源占用; -
调整 JMeter 堆内存(
bin/jmeter.bat中修改HEAP="-Xms2g -Xmx4g",根据压测机内存调整); -
禁用 “查看结果树” 等实时监听器,仅在排查问题时启用。
-
2. Gatling 实战:Scala 脚本编写与高并发压测
Gatling 的优势在于高性能(相同硬件下 QPS 比 JMeter 高 30%+)和脚本化(用 Scala 编写脚本,支持灵活的业务逻辑),适合需要高并发压测的场景(如 10 万 QPS 以上)。
(1)环境准备
-
下载 Gatling:从 Gatling 官网下载开源版(推荐 3.x 版本),解压后无需安装,直接使用。
-
脚本编写工具:推荐用 IntelliJ IDEA(安装 Scala 插件),或直接在 Gatling 的
user-files/simulations目录下编写 Scala 脚本。
(图 7:Gatling 核心目录结构,红框标注脚本存放与结果输出目录)
(2)核心脚本设计(以 “商品详情页接口” 为例)
Gatling 的脚本核心是 “Simulation” 类,包含 “场景定义”“用户行为”“压测配置” 三部分。以下是完整脚本示例:
import io.gatling.core.Predef.\_import io.gatling.http.Predef.\_import scala.concurrent.duration.\_// 压测脚本主类,继承Simulationclass ProductDetailSimulation extends Simulation {  // 1. 配置HTTP请求(基础参数)  val httpProtocol = http  .baseUrl("https://api.xxx.com") // 基础域名  .acceptHeader("application/json") // 请求头  .userAgentHeader("Gatling/PerformanceTest")  // 2. 定义用户行为(场景)  val productDetailScenario = scenario("商品详情页压测场景")  .exec(  http("获取商品详情") // 请求名称(用于结果展示)  .get("/product/detail") // 接口路径  .queryParam("productId", "\${productId}") // 动态参数(从 feeder 读取)  .check(status().is(200)) // 断言:响应状态码为200  .check(jsonPath("\$.code").is("0")) // 断言:业务码为0(成功)  )  // 3. 配置压测数据(真实商品ID列表)  val productIdFeeder = csv("product\_ids.csv").random // 从CSV文件读取商品ID,随机分配  // 4. 配置压测计划(用户数、持续时间)  setUp(  productDetailScenario  .feed(productIdFeeder) // 关联数据 feeder  .inject(  rampUsers(10000) during (60 seconds), // 60秒内启动10000个用户  constantUsersPerSec(1000) during (5 minutes) // 之后以每秒1000用户的速率持续5分钟  )  .protocols(httpProtocol)  )}
(3)压测执行与结果查看
-
执行压测:在 Gatling 的
bin目录下执行命令(Windows):gatling.bat -s ProductDetailSimulation(-s指定脚本类名)。 -
查看结果:压测结束后,Gatling 会自动生成 HTML 报告(路径:
results/日期_时间/index.html),报告包含:-
响应时间分布(P50/P90/P99);
-
每秒请求数(RPS)趋势;
-
错误请求详情(含响应内容);
-
服务器响应时间 breakdown(如 DNS 解析、TCP 连接耗时)。
-
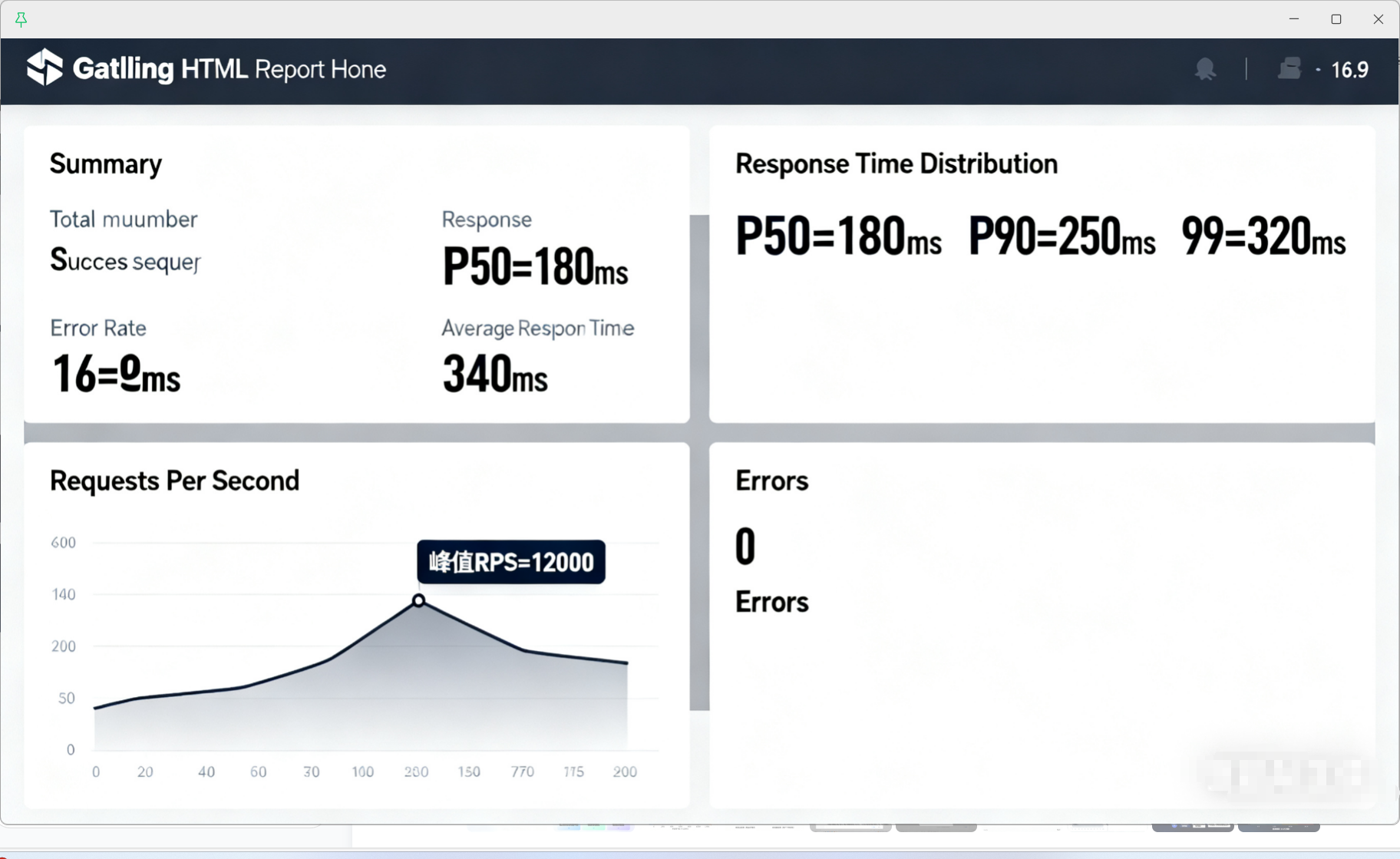
(图 8:Gatling 自动生成的 HTML 报告首页,展示核心性能指标与趋势图)
3. JMeter vs Gatling 选型建议
| 对比维度 | JMeter | Gatling |
|---|---|---|
| 性能 | 中(单台机器支持 1-5 万 QPS) | 高(单台机器支持 5-10 万 QPS) |
| 易用性 | 高(GUI 界面,无需编程) | 中(需掌握 Scala 基础,脚本化) |
| 生态支持 | 丰富(支持 HTTP、MQ、数据库等多种协议) | 较丰富(以 HTTP 为主,其他协议需扩展) |
| 报告展示 | 基础(需手动配置监听器) | 专业(自动生成 HTML 报告,含趋势分析) |
| 适用场景 | 中小并发(1 万 QPS 以下)、多协议场景 | 高并发(1 万 QPS 以上)、性能要求高的场景 |
选型建议:
-
若团队无 Scala 基础,或需压测 MQ、数据库等非 HTTP 协议,优先选 JMeter;
-
若需压测 10 万 QPS 以上的高并发场景,或需要更精准的性能趋势分析,优先选 Gatling。
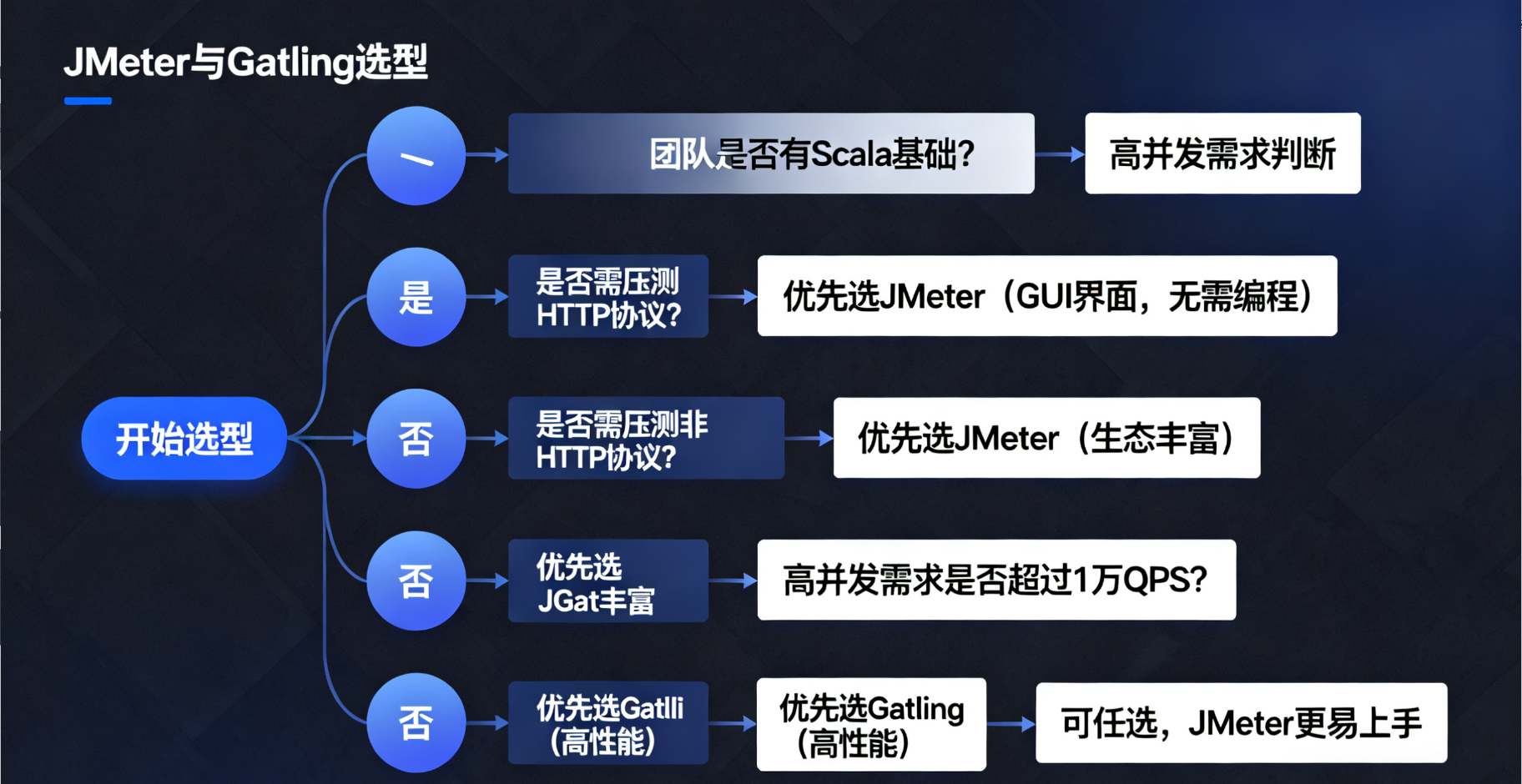
(图 9:JMeter 与 Gatling 的选型决策树,根据团队基础、并发需求等快速选择工具)
三、高并发测试场景设计:从 “单一场景” 到 “全链路闭环”
场景设计是性能测试的核心 —— 若场景与线上真实业务脱节,即使工具用得再熟练,测试结果也毫无价值。以下从 “基础场景” 到 “复杂场景”,拆解高并发场景设计的方法论。
1. 基础场景设计:覆盖核心接口的 “三要素”
基础场景针对单个核心接口(如商品详情、用户登录),设计时需满足 “三要素”:真实数据、梯度压测、边界验证。
(1)真实数据:用线上数据复刻业务场景
-
数据来源:从线上数据库导出真实的商品 ID、用户 ID(脱敏处理),避免用随机生成的无效数据;
-
数据量级:压测数据量需与线上一致(如商品 ID 列表包含 10 万条数据,模拟线上商品库规模);
-
示例:压测 “商品详情页” 接口时,从线上导出 10 万条真实商品 ID,存入 CSV 文件,通过 JMeter/Gatling 的 “数据 feeder” 动态分配。
(2)梯度压测:模拟流量从 “日常” 到 “峰值” 的变化
梯度压测的目的是找到系统的性能拐点(即 QPS 增长到某一值后,响应时间突然飙升的点)。以电商大促为例,设计梯度如下:
| 压测阶段 | 并发用户数 | 持续时间 | 目标 |
|---|---|---|---|
| 日常流量 | 1000 用户 | 5 分钟 | 验证日常场景下系统稳定性 |
| 增长流量 | 3000 用户 | 5 分钟 | 观察 QPS 与响应时间变化 |
| 峰值流量 | 10000 用户 | 10 分钟 | 验证是否满足大促峰值需求 |
| 超峰流量 | 12000 用户 | 5 分钟 | 验证系统过载保护能力(如熔断、限流是否生效) |
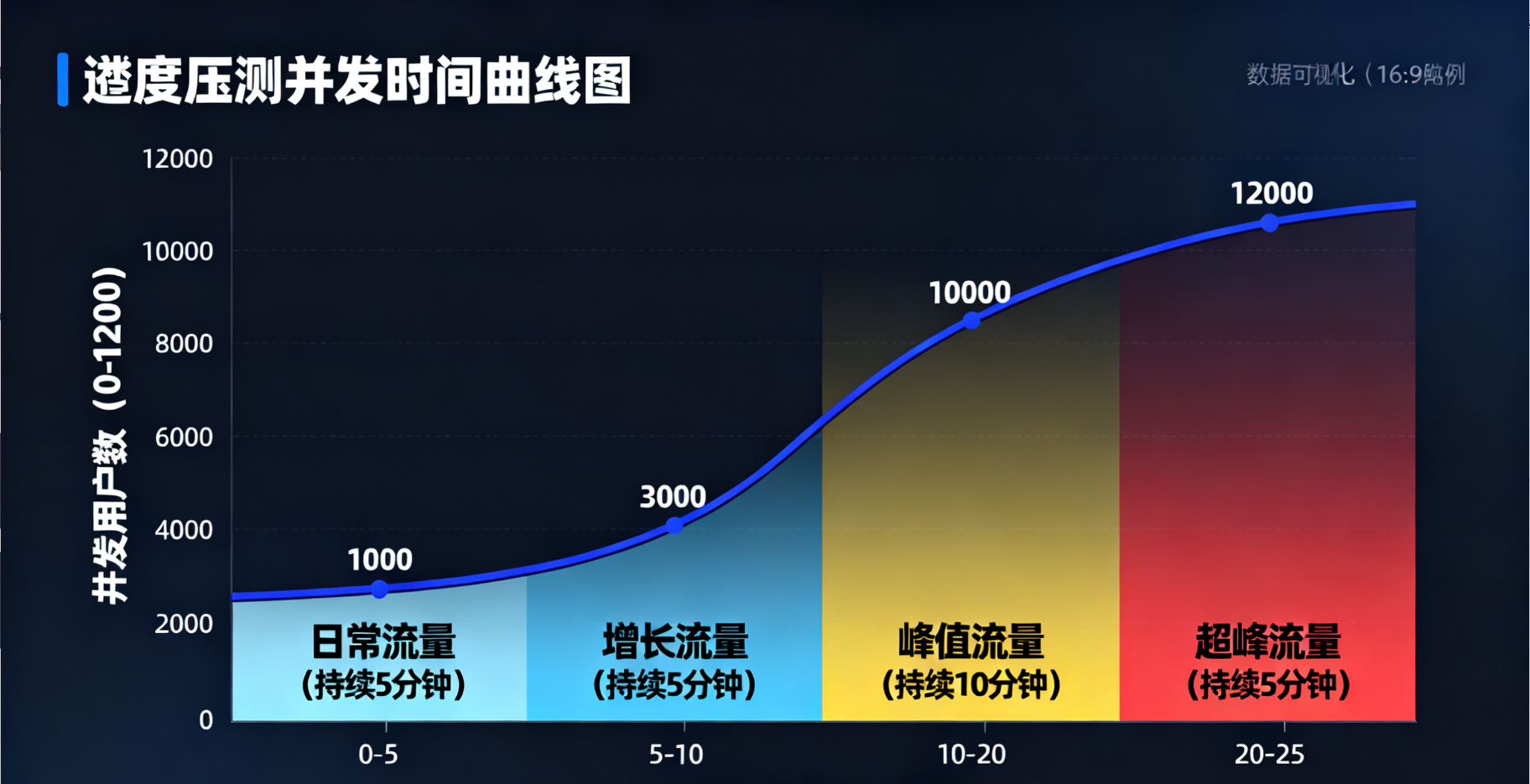
(图 10:梯度压测中并发用户数与时间的关系曲线,模拟流量从日常到超峰的变化)
(3)边界验证:覆盖 “异常场景” 与 “资源瓶颈”
-
异常场景:模拟接口返回 500 错误、数据库超时等情况,验证系统的容错能力;
-
资源瓶颈:压测时监控服务器 CPU