MySQL实战篇08:MySQL主从复制环境修复记录---3个真实问题的排查过程
MySQL主从复制环境修复记录:3个真实问题的排查过程
📅 2025年10月15日
💻 环境:Docker MySQL 8.0(1主2从)
⏰ 用时:约1.5小时(调试主从复制问题)
作者:进击的圆儿
之前搭好了Docker的MySQL主从集群,本来想直接做延迟压测,结果Docker一重启,主从复制全废了。
花了1个多小时调试,遇到3个问题:server_id冲突、SQL线程报错、配置失败。记录一下完整的排查过程,因为这种问题生产环境也会遇到。

目录
- 背景
- 🔌 第一部分:Docker环境检查
- 步骤1:检查Docker容器状态
- 步骤2:启动MySQL容器
- 🔍 第二部分:主从复制状态检查
- 问题1:IO线程未运行
- 问题2:server_id冲突
- 问题3:SQL线程执行失败
- 🛠️ 第三部分:问题解决方案对比
- 测试环境 vs 生产环境
- 最终解决方案
- 总结
- 遇到的3个问题
- 学到的东西
- 遇到的错误
背景
上次做完主从复制实战后,Docker主从环境一直正常工作。但这次打开电脑准备做压测,发现容器都停了。
启动容器后,发现主从复制断了。需要先修复环境。
🔌 第一部分:Docker环境检查
步骤1:检查Docker容器状态
首先检查容器是否在运行:
PS D:\pythontest\c++_learn> docker ps -a

发现问题:
- 三个MySQL容器的状态都是
Exited(255) - 说明容器已停止运行
步骤2:启动MySQL容器
依次启动三个容器:
PS D:\pythontest\c++_learn> docker start mysql-master
mysql-masterPS D:\pythontest\c++_learn> docker start mysql-slave1
mysql-slave1PS D:\pythontest\c++_learn> docker start mysql-slave2
mysql-slave2
验证启动状态:
PS D:\pythontest\c++_learn> docker ps

✅ 三个容器的STATUS都变成了 Up xxx seconds
🔍 第二部分:主从复制状态检查
问题1:IO线程未运行
连接到slave1检查主从状态:
PS D:\pythontest\c++_learn> docker exec -it mysql-slave1 mysql -uroot -proot123
执行检查命令:
mysql> SHOW SLAVE STATUS\G
关键字段:
Slave_IO_Running: No ← ❌ IO线程停止了!
Slave_SQL_Running: Yes
Seconds_Behind_Master: 0
思考:为什么IO线程会停止?
我回顾了课时07学习的主从复制三大线程:
- Binlog Dump线程(Master):发送binlog
- IO线程(Slave):接收binlog,写入relay log
- SQL线程(Slave):执行relay log中的SQL
IO线程停止 = Slave无法从Master接收binlog!
问题2:server_id冲突
查看错误信息:
mysql> SHOW SLAVE STATUS\GLast_IO_Errno: 13117
Last_IO_Error: Fatal error: The replica I/O thread stops because
source and replica have equal MySQL server ids; these ids must be
different for replication to work
错误翻译:
- Master和Slave的
server_id相同了! - 主从复制要求它们的ID必须不同
为什么server_id必须不同?
我的理解:
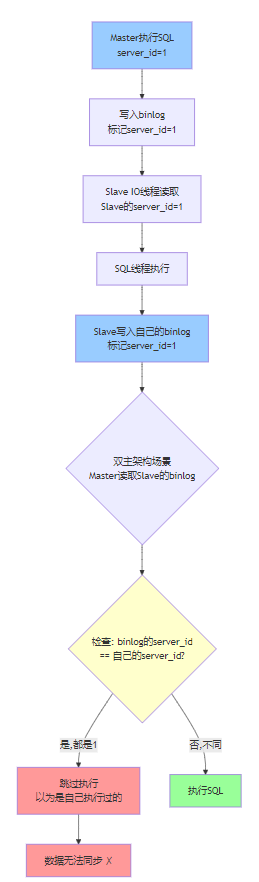
MySQL通过server_id来判断:
- 如果binlog的server_id和自己相同 → 跳过(防止循环复制)
- 如果不同 → 执行
验证server_id冲突
查看Master的server_id:
PS D:\pythontest\c++_learn> docker exec mysql-master mysql -uroot -proot123 -e "SHOW VARIABLES LIKE 'server_id';"
Variable_name Value
server_id 1
查看Slave1的server_id:
PS D:\pythontest\c++_learn> docker exec mysql-slave1 mysql -uroot -proot123 -e "SHOW VARIABLES LIKE 'server_id';"
Variable_name Value
server_id 1 ← ❌ 和Master相同了!

问题确认:
- Master:server_id = 1
- Slave1:server_id = 1
- 冲突!
修复server_id
修改Slave1的server_id为2:
PS D:\pythontest\c++_learn> docker exec mysql-slave1 mysql -uroot -proot123 -e "SET GLOBAL server_id=2;"
验证修改成功:
PS D:\pythontest\c++_learn> docker exec mysql-slave1 mysql -uroot -proot123 -e "SHOW VARIABLES LIKE 'server_id';"
Variable_name Value
server_id 2 ← ✅ 修改成功!
重启IO线程
连接到slave1:
PS D:\pythontest\c++_learn> docker exec -it mysql-slave1 mysql -uroot -proot123
重启IO线程:
mysql> STOP SLAVE IO_THREAD;
Query OK, 0 rows affected (0.00 sec)mysql> START SLAVE IO_THREAD;
Query OK, 0 rows affected (0.01 sec)mysql> SHOW SLAVE STATUS\G
检查结果:
Slave_IO_Running: Yes ← ✅ IO线程恢复了!
Slave_SQL_Running: No ← ❌ SQL线程停止了!
新问题出现:SQL线程停止了!
问题3:SQL线程执行失败
查看SQL线程错误:
mysql> SHOW SLAVE STATUS\GLast_SQL_Errno: 1007
Last_SQL_Error: Coordinator stopped because there were error(s) in the worker(s).
The most recent failure being: Worker 1 failed executing transaction 'ANONYMOUS'
at source log binlog.000002, end_log_pos 1192.
错误码1007的意思:
- 数据库已存在(Can’t create database; database exists)
问题分析
为什么会出现这个错误?
之前课时07的情况:
1. 主从复制正常工作
2. Master创建了test_replication数据库
3. Slave通过binlog同步,也创建了test_replication
4. 数据完全同步Docker重启后的情况:
1. 容器重启,主从复制关系断开
2. 我们重新配置主从复制
3. Slave的IO线程从Master的binlog开头开始读取
4. 读到:CREATE DATABASE test_replication;
5. SQL线程执行:CREATE DATABASE test_replication;
6. Slave上已经有这个数据库了!
7. 报错:1007 数据库已存在!❌
核心问题:
- Slave上有旧数据
- 但relay log要重新执行旧的SQL
- 冲突!
🛠️ 第三部分:问题解决方案对比
测试环境 vs 生产环境
我的第一反应(错误的方案)
我一开始想删除Slave上的旧数据:
-- ❌ 错误方案
STOP SLAVE;
DROP DATABASE IF EXISTS test_replication;
START SLAVE;
但这个方案有问题:
如果删除数据,那跟直接删库重来有什么区别?
数据会丢失!
生产环境绝对不能这么做!
重新思考:
- 删数据 = 数据丢失
- 应该从Master当前位置开始同步
- 不要重新执行旧SQL
正确方案:从Master当前位置开始同步
步骤1:查看Master当前binlog位置
PS D:\pythontest\c++_learn> docker exec mysql-master mysql -uroot -proot123 -e "SHOW MASTER STATUS;"
File Position
binlog.000004 157 ← Master当前位置

步骤2:配置Slave从这个位置开始同步
mysql> STOP SLAVE;
mysql> RESET SLAVE;
mysql> CHANGE MASTER TO-> MASTER_HOST='mysql-master',-> MASTER_USER='repl',-> MASTER_PASSWORD='repl123',-> MASTER_LOG_FILE='binlog.000004',-> MASTER_LOG_POS=157;
mysql> START SLAVE;
思路:
- 指定从
binlog.000004的位置157开始读取 - 跳过所有旧的binlog(binlog.000001, binlog.000002等)
- 不会重新执行
CREATE DATABASE等旧SQL - 数据不丢失! ✅
遇到的新问题
执行 CHANGE MASTER TO 时报错:
mysql> CHANGE MASTER TO ...
ERROR 3021 (HY000): This operation cannot be performed with a running replica io thread;
run STOP REPLICA IO_THREAD FOR CHANNEL '' first.
解决:
- 需要先
STOP SLAVE;才能修改配置
再次报错:
mysql> CHANGE MASTER TO ...
ERROR 1802 (HY000): CHANGE REPLICATION SOURCE cannot be executed when the replica was
stopped with an error or killed in MTA mode. Consider using RESET REPLICA.
原因:
- Slave之前是因为SQL错误停止的
- MySQL需要先清理错误状态
解决:
- 先执行
RESET SLAVE;清理错误状态 - 再配置主从复制
又遇到SQL线程报错
即使指定了从 binlog.000004 位置157开始,SQL线程还是报错:
Last_SQL_Error: Worker 1 failed executing transaction 'ANONYMOUS'
at source log binlog.000002, end_log_pos 469.
问题分析:
虽然我指定了从 binlog.000004 开始,但Master在157-469之间仍然有一些SQL要执行。
比如可能有:
157位置:INSERT INTO test_replication.users ...
469位置:某个事务结束
而Slave上已经有这些数据了 → 冲突!
真实生产环境会这样吗?
疑问:
真实生产环境也需要这样跳过好几个错误事务吗?
答案:正常的生产环境不会出现这种情况!
正常情况:
Master和Slave持续运行↓
主从复制一直工作↓
即使重启,也是从上次停止的位置继续↓
不会重复执行旧SQL↓
不需要跳过错误!✅
什么时候需要跳过错误?
| 场景 | 原因 | 解决方案 |
|---|---|---|
| 主从数据不一致 | 之前同步失败,数据已经不一致了 | 跳过1-2个错误事务 |
| 人为误操作 | 直接在Slave上执行了写操作 | 跳过冲突事务 |
| 灾难恢复 | Master宕机,重新配置主从 | 重新搭建主从(不跳过) |
我们现在的情况(测试环境特有):
Docker容器重启 → 主从复制关系完全断开↓
重新配置 → 但Slave已经有旧数据↓
Master的binlog又要重新执行旧SQL↓
冲突!需要跳过多个错误事务
这在生产环境中不会发生!
最终解决方案
经过多次尝试,最终采用的方案:
# 彻底清除Slave配置和状态
docker exec mysql-slave1 mysql -uroot -proot123 -e "STOP SLAVE; RESET SLAVE ALL;"# 确保server_id正确
docker exec mysql-slave1 mysql -uroot -proot123 -e "SET GLOBAL server_id=2;"# 配置从Master当前位置开始同步
docker exec mysql-slave1 mysql -uroot -proot123 -e "
CHANGE MASTER TOMASTER_HOST='mysql-master',MASTER_USER='repl',MASTER_PASSWORD='repl123',MASTER_LOG_FILE='binlog.000004',MASTER_LOG_POS=157;
START SLAVE;
"
验证结果:
PS D:\pythontest\c++_learn> docker exec mysql-slave1 mysql -uroot -proot123 -e "SHOW SLAVE STATUS\G" | Select-String "Slave_IO_Running|Slave_SQL_Running|Seconds_Behind_Master"Slave_IO_Running: Yes ← ✅
Slave_SQL_Running: Yes ← ✅
Seconds_Behind_Master: 0 ← ✅

成功!✅
总结
调了1个半小时,把主从复制环境修好了。
遇到的3个问题
- server_id冲突 - Master和Slave的server_id都是1,导致IO线程停止
- SQL线程报错 - relay log要重新执行旧SQL,但Slave已经有数据了
- 配置报错 - 各种ERROR 3021、ERROR 1802
学到的东西
server_id的作用:
MySQL通过server_id判断binlog是不是自己的。如果相同就跳过,不同就执行。这是防止循环复制的。
测试环境 vs 生产环境:
- 测试环境:可以删库重来,快速解决
- 生产环境:绝对不能删数据,要从Master当前位置同步
从当前位置同步的方法:
-- 先在Master查位置
SHOW MASTER STATUS;-- 在Slave指定位置
CHANGE MASTER TOMASTER_LOG_FILE='binlog.000004',MASTER_LOG_POS=157;
这样不会重新执行旧SQL,数据不丢失。
遇到的错误
| 错误 | 原因 | 解决 |
|---|---|---|
| IO线程No | server_id冲突 | 改server_id |
| SQL线程No | 数据库已存在 | 从当前位置同步 |
| ERROR 3021 | IO线程还在跑 | 先STOP SLAVE |
| ERROR 1802 | Slave有错误状态 | 先RESET SLAVE |
调试过程挺折腾的,但理解了主从复制的问题排查流程。生产环境应该也是这样排查的。