MinerU2.5:高分辨率文档解析的解耦式视觉语言模型革命
引言:文档智能的痛点与破局之道
在AI驱动的文档智能时代,如何让机器“看懂”复杂的PDF、扫描文档、科研论文、报表与教材,一直是计算机视觉与自然语言理解交叉领域的重大挑战。传统OCR流水线虽可解释性强但存在“错误传播”与维护成本高的问题,而通用视觉语言模型(VLM)虽具强大的语义理解能力,却常被O(N²)复杂度与幻觉问题束缚。上海人工智能实验室、北大与交大团队联合推出的MinerU2.5,通过“解耦式视觉语言架构”实现了效率与精度的平衡,在多个公开基准上超越Gemini 2.5 Pro、GPT-4o等通用大模型,为文档解析这一老课题注入了新的范式。
一、解耦架构:粗到细的两阶段解析范式
MinerU2.5的核心创新在于“粗到细(coarse-to-fine)”的两阶段解耦架构。第一阶段(全局布局分析)将高分辨率文档缩放为1036×1036缩略图,快速检测文本块、表格、公式等版面元素的位置与类型,捕获全局语义关系。第二阶段(局部内容识别)则根据布局信息回溯原始高分辨率文档,对各区域执行细粒度识别。这种设计带来三大直接收益:计算成本减少一个数量级、解析过程可解释且可独立优化、有效抑制“幻觉”现象。
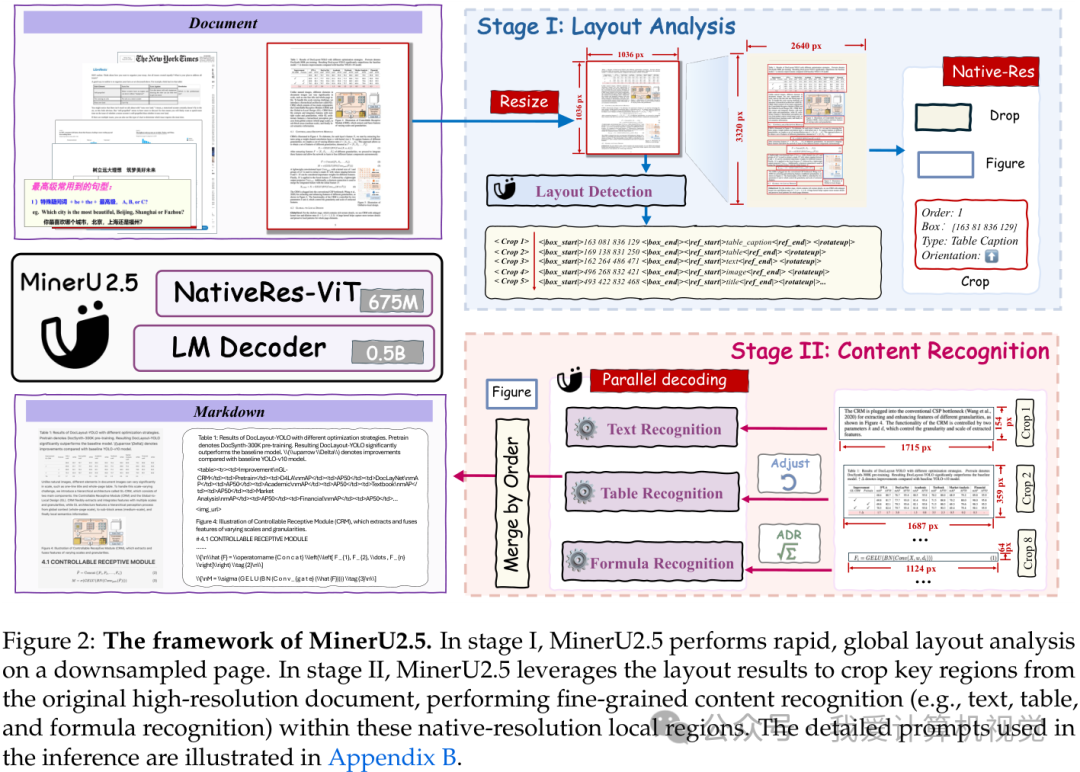
二、模型设计:视觉-语言双引擎的深度融合
视觉编码器:NaViT原生分辨率感知
视觉编码器采用675M参数的NaViT(Native Resolution Vision Transformer)结构,支持动态分辨率输入。其核心机制包括:
动态Patch分块与Batch混合:通过Padding + Masking机制允许每张图以原生分辨率划分patch,实现跨尺寸图像的批处理训练
二维相对位置编码(2D-RoPE):在水平与垂直方向分别编码相对位置,理解表格单元格行列关系等二维结构
P