CLIP介绍
文章目录
- 一、CLIP 是什么
- 二、核心思想:对比学习(Contrastive Learning)
- 四、训练数据与规模
- 五、能力与应用
- 零样本分类(Zero-Shot Classification)
- 图文检索
- 视觉问答、图像生成基础模型
- 六、在农业中的应用(结合 Singh 博士研究)
- CLIP 的影响与发展
- 原始论文
- 论文信息
- 官方摘要(简译版)
- Learning Transferable Visual Models From Natural Language Supervision
- 1. 零样本迁移与图像分类
- 2. 图像生成与编辑
- 3. 视频理解
- 4. 开放词汇目标检测与分割
- 5. 多模态检索
- 6. 与其他模态的结合(如音频、深度图)
- 7. 分析与鲁棒性研究
一、CLIP 是什么
CLIP(Contrastive Language–Image Pre-training) 是 OpenAI 于 2021 年提出的一个多模态模型,旨在让计算机同时理解图像与文本。
它能实现“看图识文、以文找图”的能力,是连接**视觉(Vision)和语言(Language)**的桥梁。
简单来说:
CLIP 就像一个“会读图的语言专家”,它能理解一张图片与一句文字描述是否匹配。
二、核心思想:对比学习(Contrastive Learning)
CLIP 通过 对比学习 来训练:
- 输入一批图像和与之对应的文本描述(例如:“一只棕色的狗在草地上”)。
- 目标是让模型学会把匹配的图文向量拉近,把不匹配的图文向量推远。
经过大规模训练后,模型能在**共享的语义空间(embedding space)**中表示图像和文本,使得:
“猫的图片” 与 “a photo of a cat” 的向量距离非常近。
#三、模型结构
CLIP 包含两个主要部分:
-
文本编码器(Text Encoder)
- 通常使用 Transformer(类似BERT)结构。
- 输入自然语言描述,输出文本特征向量。
-
图像编码器(Image Encoder)
- 通常使用 ResNet 或 Vision Transformer(ViT)。
- 输入图像,输出图像特征向量。
两者输出后会被映射到同一个向量空间中,用于进行图文相似度计算。
四、训练数据与规模
CLIP 使用了一个超大规模的开源数据集:
- 4亿(400M)图像–文本对
- 来源:互联网(如网站、社交平台上的图文内容)
- 训练方式:自监督学习(无需人工标注)
这让 CLIP 能够掌握通用的视觉–语言关联知识,而不是仅限于特定任务。
五、能力与应用
零样本分类(Zero-Shot Classification)
CLIP 最大的创新之一是无需再训练,就能直接识别新类别。
例如:
给模型输入图片 + 一组文字标签(“a dog”, “a cat”, “a horse”…)
它计算图像与各标签的相似度,输出最可能的类别。
这种“以文代标签”的方式让 CLIP 具备了强大的零样本识别能力。
图文检索
- 以图找文:给一张图片,找最匹配的文字描述。
- 以文找图:输入一句话(如“a red butterfly on a leaf”),找到匹配的图像。
视觉问答、图像生成基础模型
CLIP 已成为许多多模态模型的底层组件,例如:
- DALL·E / Stable Diffusion:用 CLIP 来理解文本提示(prompt);
- CLIPSeg、CLIP-Adapter:用于图像分割与细粒度识别;
- 农业与生态领域:用于零样本昆虫检测、植物识别等。
六、在农业中的应用(结合 Singh 博士研究)
在 Arti Singh 博士的研究中,CLIP 被用于:
- 实现 零样本昆虫检测(Zero-Shot Detection);
- 模型可通过文字提示(如“寻找一只绿色的蚜虫”)识别图片中未训练过的昆虫;
- 显著降低了对人工标注(特别是边界框标注)的依赖。
CLIP 的影响与发展
CLIP 引发了一系列多模态研究的浪潮,包括:
- ALIGN(Google)、Florence(Microsoft):扩展数据规模;
- OpenCLIP、CLIP-ViT-L/14:开源社区复现与改进;
- CLIP2Text、BLIP、Flamingo、GPT-4V:更复杂的视觉语言理解。
| 项目 | 内容 |
|---|---|
| 模型名称 | CLIP(Contrastive Language–Image Pre-training) |
| 提出机构 | OpenAI(2021) |
| 训练数据 | 4亿 图像–文本对 |
| 核心思想 | 对比学习 + 多模态共享语义空间 |
| 能力 | 零样本分类、图文检索、视觉语言理解 |
| 应用领域 | 图像识别、生成模型、农业智能识别、生态监测等 |
原始论文
论文信息
Title(标题):
“Learning Transferable Visual Models From Natural Language Supervision”
Authors(作者):
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever
Institution(机构):
OpenAI
Publication(发表时间):
2021年(arXiv 预印本)
arXiv 链接:
https://arxiv.org/abs/2103.00020
官方摘要(简译版)
当前的视觉模型通常依赖大量人工标注数据(如 ImageNet),限制了它们的泛化能力。
本文提出使用来自互联网的 自然语言监督(natural language supervision) 来训练图像模型。
我们收集了 4 亿(400M)对图像–文本配对数据,并使用**对比学习(contrastive learning)方法进行训练。
结果表明,这种方法训练的模型(CLIP)能够在零样本(zero-shot)**条件下在多个视觉任务上取得与有监督模型相当甚至更优的性能。
##论文主要内容概览
-
动机
- 传统视觉模型依赖昂贵的人工标签。
- 网络上已有大量“图片 + 描述性文本”的天然监督数据。
-
方法
- 同时训练图像编码器与文本编码器,使匹配的图文对在语义空间中更接近。
- 使用**对比损失(contrastive loss)**优化。
-
数据
- 收集了一个含有 4 亿 图像–文本对的大规模数据集(来自互联网)。
-
结果
- CLIP 可直接执行 零样本图像分类。
- 在 30 多个基准测试上表现与有监督模型(如 ResNet50, ViT)相当或更优。
-
意义
- 开启了**多模态预训练(vision-language pretraining)**的新方向。
- 为后续模型(如 DALL·E, BLIP, GPT-4V)奠定基础。
Learning Transferable Visual Models From Natural Language Supervision
摘要
当前最先进的计算机视觉系统通常被训练来预测一组固定的、预先定义的对象类别。
这种受限的监督方式限制了模型的通用性与可用性,因为若要识别新的视觉概念,就必须额外收集并标注新的数据。
一种有前景的替代方案是直接从关于图像的原始文本中学习,这种方法可以利用更广泛的监督信息来源。
我们证明了一种简单而高效的预训练任务——预测哪条文字说明与哪张图像相匹配——是一种从零开始学习**最先进图像表示(SOTA image representations)**的可扩展方法。
我们在一个包含 4 亿对(图像,文本) 的互联网数据集上进行了这种训练。
在完成预训练后,模型可以使用自然语言来引用已学习的视觉概念(或描述新的概念),
从而实现模型在下游任务中的零样本迁移(zero-shot transfer)。
我们通过在 30 多个现有计算机视觉数据集上的基准测试来评估该方法的性能,
这些任务涵盖光学字符识别(OCR)、视频动作识别(action recognition in videos)、地理定位(geo-localization)以及多种细粒度目标分类。
实验结果表明,模型在大多数任务中都能实现非平凡的迁移(non-trivial transfer),
且在无需针对特定数据集进行训练的情况下,其性能通常可与完全监督的基线模型相媲美。
例如,在 ImageNet 上,我们的模型在零样本条件下达到了原始 ResNet-50 的准确率,
而无需使用该模型训练所需的 128 万张标注图像。
我们公开发布了模型的代码与预训练权重:
🔗 https://github.com/OpenAI/CLIP
- 引言与研究动机(Introduction and Motivating Work)
在过去的几年中,直接从原始文本中进行学习的预训练方法彻底改变了自然语言处理(NLP)领域(Dai & Le, 2015;Peters et al., 2018;Howard & Ruder, 2018;Radford et al., 2018;Devlin et al., 2018;Raffel et al., 2019)。
诸如自回归语言建模和掩码语言建模(masked language modeling)等与任务无关的目标函数,在计算量、模型容量和数据规模上实现了跨数量级的扩展,并稳步提升了模型的能力。
“文本到文本(text-to-text)”这一标准化输入输出接口的提出(McCann et al., 2018;Radford et al., 2019;Raffel et al., 2019)使得任务无关型架构能够实现对下游数据集的零样本迁移(zero-shot transfer),从而无需为每个任务设计专用的输出层或定制化结构。
诸如 GPT-3(Brown et al., 2020) 等代表性系统,如今在多种任务上已能与特定任务定制模型竞争,同时几乎不需要针对具体数据集的额外训练数据。
这些结果表明,现代预训练方法所能获取的网络级文本监督信息的总量,已经超过了传统高质量、人工标注的 NLP 数据集。然而,在其他领域(如计算机视觉)中,当前的主流做法仍是利用人工标注的数据集(如 ImageNet,Deng et al., 2009)对模型进行预训练。
因此,我们提出一个核心问题:
➡️ 能否通过直接从网络文本中进行可扩展的预训练,在计算机视觉领域取得类似于 NLP 的突破?
已有研究为这一设想提供了积极的迹象。
早在 20 多年前,Mori 等人(1999)就尝试通过训练模型预测与图像配对的文本中的名词和形容词,以改进基于内容的图像检索。
Quattoni 等人(2007)展示了通过流形学习(manifold learning)在分类器权重空间中预测图像说明文字中的单词,可以学习到更高效的图像表示。
Srivastava 和 Salakhutdinov(2012)进一步探索了深度表示学习,他们在图像与文本标签特征的基础上训练了多模态深度玻尔兹曼机(Deep Boltzmann Machines)。
随后,Joulin 等人(2016)对这一方向进行了现代化改进,证明了通过训练卷积神经网络(CNN)来预测图像说明中的单词,可以学习出有用的图像表示。他们将 YFCC100M 数据集(Thomee et al., 2016)中的图像标题、描述与标签元数据转换为多标签词袋分类任务(bag-of-words multi-label classification),并展示了用此方法预训练的 AlexNet(Krizhevsky et al., 2012)在迁移任务中可与基于 ImageNet 的预训练相媲美。
Li 等人(2017)进一步将这一方法扩展到短语 n-gram预测,并展示了其模型在零样本条件下向其他图像分类数据集迁移的能力——模型通过比较目标类别在其学习到的视觉 n-gram 字典中的得分,预测得分最高的类别。
在此基础上,更近的研究如 VirTex(Desai & Johnson, 2020)、ICMLM(Bulent Sariyildiz et al., 2020) 和 ConVIRT(Zhang et al., 2020) 利用基于 Transformer 的语言建模、掩码语言建模和对比学习目标,展示了从文本中学习图像表示的潜力。
尽管这些成果令人鼓舞,但利用自然语言监督进行图像表示学习的研究仍然较少,
其主要原因是:在标准基准测试上,该类方法的表现显著低于其他替代方法。
例如,Li 等人(2017)在零样本 ImageNet 分类中仅获得 11.5% 的准确率,
远低于当前最先进模型的 88.4%(Xie et al., 2020),甚至不如经典视觉方法的 50%(Deng et al., 2012)。
相对而言,更狭义但更有针对性的弱监督学习在性能上取得了更大的成功。
Mahajan 等人(2018)证明,在 Instagram 图像上预测与 ImageNet 相关的标签是一种有效的预训练任务。当在 ImageNet 上进行微调时,这种预训练可使准确率提升超过 5%,并刷新当时的 SOTA 结果。
Kolesnikov 等人(2019)和 Dosovitskiy 等人(2020)也通过在噪声标签数据集 JFT-300M 上进行类别预测预训练,在更广泛的迁移基准上实现了显著提升。
这种工作路线代表了当前介于两种极端之间的折中方案:
介于从有限量的“金标准”标注学习与从几乎无限量的原始文本中学习之间。
但这种方法也存在妥协:Mahajan 等人和 Kolesnikov 等人均手动设计并限制了模型监督范围,前者限定在 1000 类,后者为 18291 类。
相比之下,自然语言具有更强的普适性,能够表达并监督更广泛的视觉概念。
此外,这些方法都采用了静态的 softmax 分类器,无法实现动态输出,从而显著限制了模型的灵活性与零样本能力。
这些弱监督模型与直接从自然语言中学习图像表示的最新探索之间的关键区别在于规模(scale)。
Mahajan 等人(2018)和 Kolesnikov 等人(2019)的模型在数百万至数十亿张图像上进行了多年级别的训练,而 VirTex、ICMLM 和 ConVIRT 仅在十几万张图像上进行了几天的训练。
在本研究中,我们弥合了这一差距,系统研究了在大规模自然语言监督下训练图像分类器的行为。
利用互联网上大量公开可用的图像与文本数据,我们构建了一个包含 4 亿对(图像,文本) 的新数据集。
我们在此基础上从零开始训练了一个简化版本的 ConVIRT 模型,并称之为 CLIP(Contrastive Language–Image Pre-training,对比语言–图像预训练)。
结果表明,CLIP 是一种高效的自然语言监督学习方法。
我们通过训练八个不同规模(跨度近两个数量级)的模型研究了 CLIP 的可扩展性,并发现模型的迁移性能是计算量的平滑可预测函数(Hestness et al., 2017;Kaplan et al., 2020)。
CLIP 与 GPT 系列类似,在预训练过程中学会执行包括 OCR、地理定位、动作识别等在内的多种任务。
通过在 30 多个现有数据集上的零样本测试,我们发现 CLIP 在多数任务上能与针对特定任务的监督模型竞争。
进一步的线性探针分析表明,CLIP 在计算效率上超过了当前最优的公开 ImageNet 模型。
我们还发现,零样本 CLIP 模型的鲁棒性显著优于相同准确率的监督模型,这表明零样本评估更能真实反映任务无关模型的总体能力。
这些结果具有重要的政策与伦理意义,我们将在第 7 节中进一步讨论。
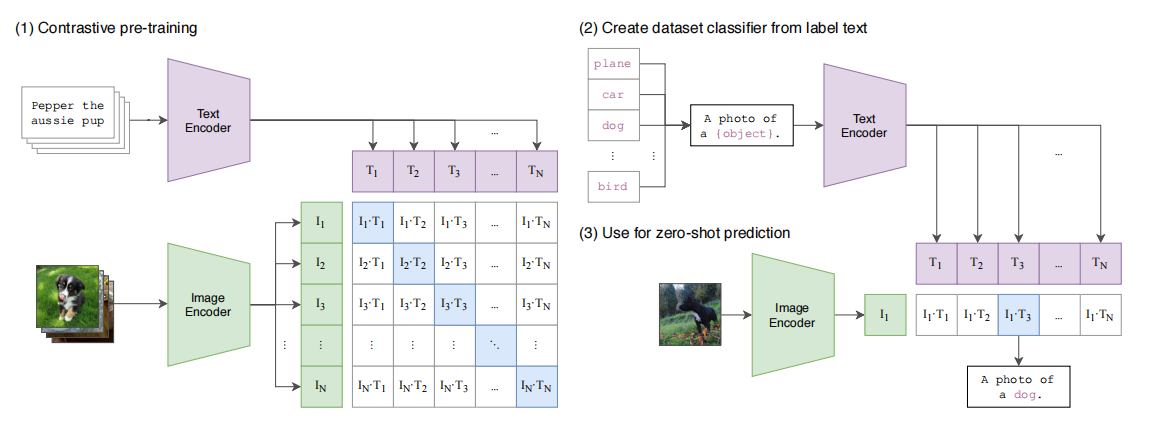
图1. 我们的方法概览。传统图像模型通过联合训练图像特征提取器与线性分类器来预测标签,而CLIP则采用联合训练图像编码器与文本编码器的方式,预测一批(图像,文本)训练样本的正确匹配关系。在测试阶段,经过学习的文本编码器通过嵌入目标数据集各类别的名称或描述,自动合成出零样本线性分类器。
2. 方法(Approach)
2.1 自然语言监督(Natural Language Supervision)
我们方法的核心思想是:从自然语言中蕴含的监督信号中学习感知能力。
正如在引言中所讨论的,这一思路并非全新,但在该领域中,不同研究所使用的术语各异,甚至存在矛盾,而其研究动机也多种多样。
例如,Zhang 等人(2020)、Gomez 等人(2017)、Joulin 等人(2016)以及 Desai 和 Johnson(2020)均提出了从配对的图像与文本中学习视觉表示的方法,但他们分别将自己的方法称为无监督(unsupervised)、自监督(self-supervised)、弱监督(weakly supervised)和监督学习(supervised)。
我们强调,这些工作的共同点并非在于具体算法的实现细节,而在于它们都认识到了自然语言作为训练信号的价值。
早期研究在使用主题模型或 n-gram 表示时受制于语言复杂性,但随着深度上下文表示学习(deep contextual representation learning)的进展(McCann et al., 2017),我们如今具备了充分利用这种丰富监督源的工具。
与其他训练方法相比,从自然语言中学习具有多项潜在优势:
更易扩展。与传统的人工标注图像分类不同,自然语言监督无需将标注转化为“机器学习兼容格式”(如 1-of-N 的多数投票“金标准标签”)。模型可以被动地从互联网上大量现成文本中学习。
语义连接性。与大多数无监督或自监督学习不同,自然语言监督不仅能学习表示,还能将这种表示与语言直接对应,从而支持灵活的零样本迁移(zero-shot transfer)。
以下小节将介绍我们最终采用的具体方法。
2.2 构建大规模数据集(Creating a Sufficiently Large Dataset)
现有研究主要使用三种数据集:MS-COCO(Lin et al., 2014)、Visual Genome(Krishna et al., 2017)和 YFCC100M(Thomee et al., 2016)。
其中 MS-COCO 和 Visual Genome 是高质量的人工标注数据集,但规模较小(约 10 万张训练图像),而现代计算机视觉模型的训练通常使用高达 35 亿张的图像(Mahajan et al., 2018)。
YFCC100M 拥有 1 亿张图像,看似是一个替代方案,但其元数据稀疏且质量参差不齐。许多图像的“标题”只是自动生成的文件名(如 20160716_113957.JPG),或“描述”仅包含相机曝光设置。
在过滤掉这些无效样本并仅保留具有自然语言标题或描述的英文图像后,数据集规模减少了约 6 倍,仅剩 1500 万张图像,与 ImageNet 的规模相当。
自然语言监督的主要动机在于互联网上存在大量此类公开可用数据。
现有数据集并不能充分体现这种潜力,仅基于它们的研究会低估该方向的能力。
为此,我们构建了一个全新的大规模数据集,包含 4 亿对(图像,文本),数据来自多种互联网公开资源。
在构建过程中,我们为尽可能覆盖广泛的视觉概念,从包含 50 万个查询词(queries) 的集合中搜索(图像,文本)对。
该查询词列表包括所有在英文维基百科中出现至少 100 次的词汇,并通过高互信息(PMI)短语、热门维基条目及 WordNet 同义词集(synsets)进行扩充。
为保持类别平衡,我们最多保留每个查询的 2 万对(图像,文本)。
最终得到的数据集总词数与用于训练 GPT-2 的 WebText 数据集相当。
我们将其命名为 WIT(WebImageText)。
2.3 选择高效的预训练方法(Selecting an Efficient Pre-Training Method)
当前的计算机视觉系统通常需要极高的计算量。
例如,Mahajan 等人(2018)的 ResNeXt101-32×48d 模型训练耗费了 19 个 GPU 年,而 Xie 等人(2020)的 Noisy Student EfficientNet-L2 模型耗费了 33 个 TPUv3 核心年。
考虑到它们仅学习了 ImageNet 的 1000 个类别,若要从自然语言中学习开放视觉概念,计算代价将十分巨大。
在我们的研究中,训练效率成为成功扩展自然语言监督的关键,因此我们基于该指标选择了最终方法。
最初,我们采用类似 VirTex 的思路,联合训练一个 CNN 图像编码器与 Transformer 文本编码器,从零开始预测图像的文字说明。
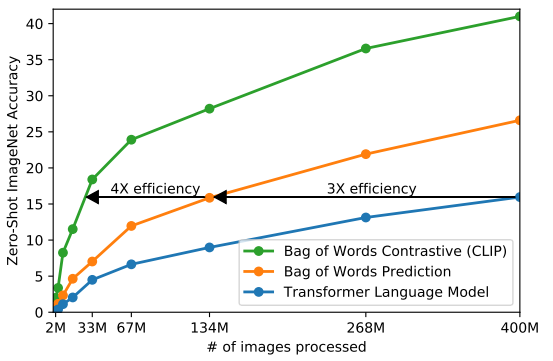
然而,该方法在扩展时效率低下。正如图 2 所示,一个拥有 6300 万参数的 Transformer 语言模型(计算量为 ResNet-50 的两倍),其在 ImageNet 零样本分类中的学习速度比一个简单的词袋(bag-of-words)预测基线慢 3 倍。
这两种方法都尝试预测与每张图像对应的精确文本内容。
由于图像关联文本的多样性(描述、评论、标签等),这是一个困难任务。
对比学习研究发现,对比目标函数(contrastive objectives) 往往比预测目标函数能学得更优的表示(Tian et al., 2019)。
其他研究也表明,生成式图像模型虽然能学习高质量表示,但计算量比对比模型高出一个数量级(Chen et al., 2020a)。
受此启发,我们改为训练系统仅预测哪段文本与哪张图像配对,而不预测文本的精确词汇。
我们将原先的词袋预测任务替换为对比学习目标后,零样本迁移效率提升了 4 倍。
具体而言,给定一个包含 N 对(图像,文本)的批次,CLIP 需要预测这 N² 个可能配对中哪些是真实存在的。
为此,CLIP 通过联合训练图像编码器与文本编码器,学习一个多模态嵌入空间(multi-modal embedding space):
最大化真实配对样本的余弦相似度,最小化错误配对的相似度。
损失函数采用对称交叉熵(symmetric cross entropy loss)。
这一训练目标最早由 Sohn(2016)提出为 N-pair loss,随后被 Oord 等人(2018)推广为 InfoNCE loss,并由 Zhang 等人(2020)首次用于医学影像领域的文本-图像对比学习。
由于我们的预训练数据集规模庞大,过拟合风险较低,因此 CLIP 的训练过程较为简化:
图像编码器未使用 ImageNet 预训练权重,文本编码器也未使用预训练模型;
不使用非线性投影层,仅用线性映射将表示投射到嵌入空间;
不采用 Zhang 等人(2020)的句子采样函数;
图像增强仅使用随机方形裁剪;
softmax 的温度参数 τ 直接在训练中优化,而非作为超参数调节。
2.4 模型选择与扩展(Choosing and Scaling a Model)
我们为图像编码器采用了两种架构:
ResNet 系列(He et al., 2016):
以 ResNet-50 为基础,采用 ResNet-D 改进(He et al., 2019)及 Zhang(2019)的抗混叠模糊池化。
同时,用**注意力池化机制(attention pooling)**取代了全局平均池化,实现了基于多头 QKV 注意力的聚合。
Vision Transformer(ViT, Dosovitskiy et al., 2020):
基于原始实现,添加一层 LayerNorm 并使用稍作修改的初始化方式。
文本编码器采用 Transformer(Vaswani et al., 2017),基于 Radford 等人(2019)的修改:
使用 12 层、512 隐层宽度、8 个注意力头的模型(约 6300 万参数),
词汇采用 49,152 词的 BPE 表示,最大序列长度为 76。
文本以 [SOS] 和 [EOS] 包围,Transformer 最后一层 [EOS] 的激活作为文本表示,经过归一化后线性映射到多模态空间。
为保持可扩展性,图像编码器采用 Tan & Le(2019)的宽度、深度与分辨率共同扩展策略,而非单维度扩展;
文本编码器仅按比例扩宽,不加深层数。
2.5 训练(Training)
我们共训练了 5 个 ResNet 模型 与 3 个 Vision Transformer 模型:
ResNet 系列:ResNet-50、ResNet-101、RN50×4、RN50×16、RN50×64;
ViT 系列:ViT-B/32、ViT-B/16、ViT-L/14。
所有模型均训练 32 个 epoch。优化器为 Adam(Kingma & Ba, 2014),使用解耦权重衰减(Loshchilov & Hutter, 2017),并采用余弦学习率衰减(cosine schedule, Loshchilov & Hutter, 2016)。
温度参数 τ 初始化为 0.07(Wu et al., 2018),并限制最大放缩倍数为 100,以防训练不稳定。
批次大小为 32,768。采用混合精度训练(Micikevicius et al., 2017),同时启用梯度检查点(gradient checkpointing)、半精度 Adam 统计量及文本编码器权重的随机半精度舍入。嵌入相似度计算在多 GPU 上分片并行。
最大的 ResNet 模型 RN50×64 在 592 张 V100 GPU 上训练 18 天;
最大的 Vision Transformer 在 256 张 V100 上训练 12 天。
对于 ViT-L/14 模型,我们额外在 336 像素分辨率上再训练 1 个 epoch,以获得更优性能(类似 FixRes,Touvron et al., 2019)。
我们将该模型记为 ViT-L/14@336px,并将其作为本文所有实验的标准 CLIP 模型。
1. 零样本迁移与图像分类
这是CLIP最直接的应用,即不经过任何训练,直接用于新数据集的分类。
-
论文: 《Learning Transferable Visual Models From Natural Language Supervision》 (CLIP的原论文)
- 核心应用: 展示了CLIP本身在超过30个不同图像分类数据集上的强大零样本性能,无需特定数据集的训练,就能达到甚至超过有监督基线的水平。
- 意义: 为后续所有应用奠定了基础。
-
论文: 《A Cookbook of Self-Supervised Learning》
- 核心应用: 其中对CLIP及其变种进行了系统的评估和总结,提供了如何更好地使用CLIP进行零样本和少样本学习的“食谱”,包括提示工程、集成等技巧。
2. 图像生成与编辑
CLIP的语义对齐能力可以极大地指导和控制生成过程。
-
论文: 《ClipCap: CLIP Prefix for Image Captioning》
- 核心应用: 使用CLIP图像编码器的输出作为前缀,输入给语言模型(如GPT-2)来生成图像的描述文本。展示了如何利用CLIP作为视觉与语言生成的桥梁。
-
论文: 《DiffusionCLIP: Text-Guided Diffusion Models for Robust Image Manipulation》
- 核心应用: 将CLIP的文本-图像相似度损失与扩散模型结合,实现基于文本描述的精准图像编辑。用户输入文本(如“悲伤的表情”),模型就能根据文本来修改图像。
-
工具: VQGAN+CLIP (虽然更多是社区驱动的方法,但影响深远)
- 核心应用: 通过优化VQGAN的生成结果,使其CLIP编码与给定的文本提示的编码尽可能相似,从而实现了“用文字作画”。
3. 视频理解
将CLIP的图像级理解能力扩展到视频时序领域。
-
论文: 《ActionCLIP: A New Paradigm for Video Action Recognition》
- 核心应用: 将CLIP的框架扩展到视频动作识别。它提出将视频视为“图像的一个特定领域”,并设计了时空交互的编码器,利用文本提示(如“一个人在游泳”)来进行零样本或少样本的动作识别。
-
论文: 《X-CLIP: Expanding CLIP for Video and Language Understanding》
- 核心应用: 针对视频的时序特性,引入了跨帧注意力机制和视频特定的提示学习,显著提升了CLIP在视频检索、动作识别等任务上的性能。
4. 开放词汇目标检测与分割
让模型能够检测和分割出在训练集中未曾见过的物体类别。
-
论文: 《OV-DETR: Open-Vocabulary Detection with Transformers》
- 核心应用: 将目标检测问题构建为一个区域-文本匹配问题。使用视觉编码器提取区域特征,然后与CLIP文本编码器生成的类别文本特征进行匹配,从而实现对任意类别名称的检测。
-
论文: 《OpenSeg: Aligning Text and Image Features for Open-Vocabulary Semantic Segmentation》
- 核心应用: 类似思想应用于语义分割。通过将像素级特征与CLIP的文本特征对齐,使得模型能够根据文本描述(如“路牌”、“草坪”)对图像中的每个像素进行分类。
5. 多模态检索
利用CLIP的共享嵌入空间,进行高效的图搜图、文搜图、图搜文。
- 论文: CLIP原论文本身就是一个强大的双塔检索模型。
- 后续研究: 很多工作集中在如何提升CLIP的检索效率、细粒度检索能力以及对长尾分布数据的鲁棒性上。
6. 与其他模态的结合(如音频、深度图)
- 论文: 《ImageBind: One Embedding Space To Bind Them All》
- 核心应用: 一个将CLIP思想扩展到六种模态(图像、文本、音频、深度、热成像、IMU数据)的里程碑式工作。它使用图像作为“纽带”,将其他所有模态对齐到CLIP已经构建好的语义空间中,从而实现跨模态的检索和生成(例如,用声音生成图像)。
7. 分析与鲁棒性研究
理解CLIP的工作原理、偏见和弱点。
-
论文: 《Multimodal Neurons in Artificial Neural Networks》 (OpenAI)
- 核心应用: 分析了CLIP模型中的“多模态神经元”,发现其与大脑中的概念神经元类似,例如存在专门响应“蜘蛛”概念的不同模态输入(文字、图片、素描)的神经元。
-
论文: 《Are CLIP Models Fair? An Analysis of the Fairness of Representations》
- 核心应用: 系统地分析了CLIP在不同人口统计学组(如性别、种族)上的表现差异,揭示了模型可能存在的偏见。