构建AI智能体:六十五、模型智能训练控制:早停机制在深度学习中的应用解析
一、什么是早停机制
在深度学习模型训练过程中,我们常常面临一个关键问题:何时停止训练? 训练不足会导致欠拟合,模型无法充分学习数据特征;训练过度则会导致过拟合,模型过度记忆训练数据中的噪声而丧失泛化能力。
早停机制是机器学习中一种简单而有效的正则化技术,通过在验证集性能停止改善时提前终止训练,自动找到模型复杂度和泛化能力的最佳平衡点。通俗的讲,早停机制就像一个有经验的老师,在学生开始学糊涂的时候及时喊停,让学生保持最佳的学习状态,不要一直学不休息,如果发现成绩不提高了,就及时停止,避免浪费时间,检测掌握程度,从而恢复到最佳状态。
二、早停机制的价值
早停机制的核心价值在于:
- 自动防过拟合:在模型开始过拟合前智能停止
- 提升训练效率:避免不必要的训练轮次,节省计算资源
- 简化调参过程:自动化寻找最佳训练轮次,减少人工干预
- 改善模型泛化:获得在未见数据上表现更好的模型
在实际应用中,早停机制能够:
- 减少30-80%的训练时间,显著降低计算成本
- 提升模型在生产环境中的稳定性和可靠性
- 使非专家用户也能训练出高质量的模型
三、早停机制关键参数
1. patience(耐心值)
# 不同场景的推荐值
简单问题: patience = 5-10
复杂问题: patience = 15-25
不稳定训练: patience = 20-30作用:
- 控制早停的敏感度
- 防止因训练波动而过早停止
- 平衡训练充分性和效率
2. min_delta(最小改善阈值)
# 典型设置
min_delta = 0.001 # 对于损失函数,改善必须大于0.001才算显著
min_delta = 0.0001 # 对于高精度需求,改善必须大于0.0001才算显著作用:
- 过滤掉训练过程中的微小波动
- 确保只有真正的性能提升才会重置计数器
- 提高早停决策的稳定性
3. restore_best_weights(恢复最佳权重)
# 建议开启
restore_best_weights = True作用:
- 确保最终获得历史最佳模型
- 避免使用性能下降后的模型
- 这是早停机制价值的核心体现
四、早停机制的流程
1. 流程图
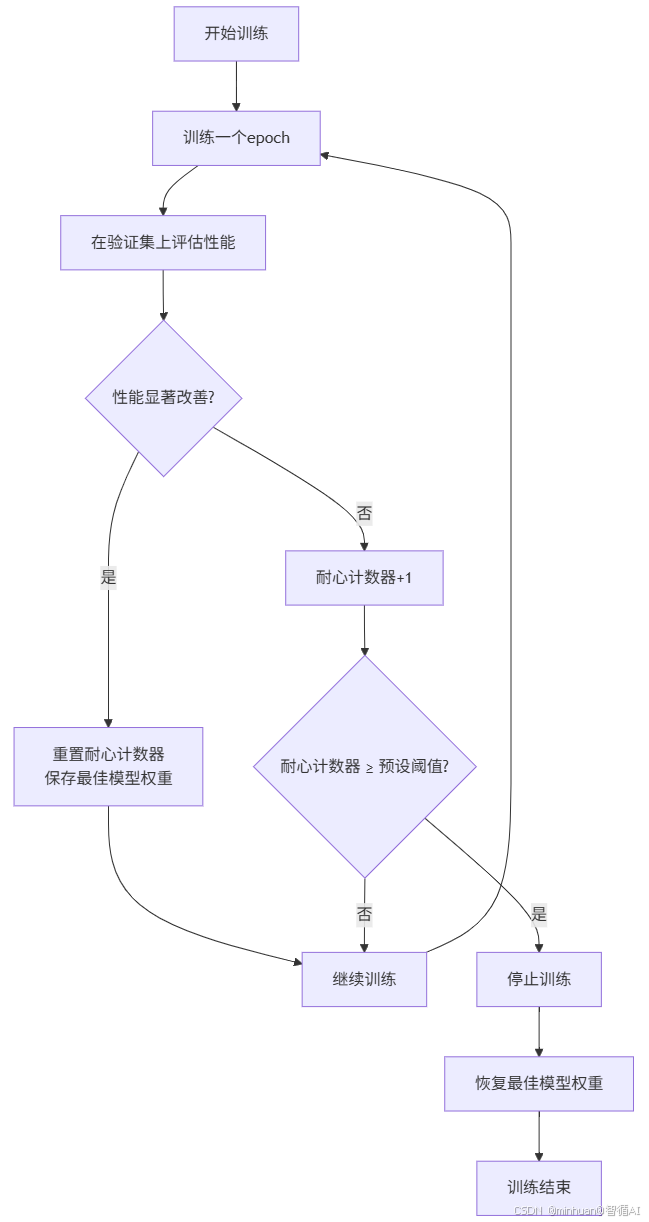
2. 流程说明
2.1 开始训练
初始化训练过程,设置初始参数
- 初始化模型权重
- 设置训练超参数(学习率、批次大小等)
- 准备训练集和验证集
- 初始化耐心计数器为0
- 设置最佳性能记录为初始值
2.2 训练一个epoch
完成一个完整的训练轮次
# 具体操作
for batch in training_data:前向传播 → 计算损失 → 反向传播 → 更新参数- 输入:训练数据批次
- 处理:模型参数更新
- 输出:更新后的模型权重
2.3 在验证集上评估性能
使用验证集测试当前模型性能
- - 验证集不参与训练
- - 使用独立的数据评估泛化能力
- - 监控指标:val_loss 或 val_accuracy
目的:客观评估模型真实性能
指标选择:
- 回归问题:验证损失(val_loss)
- 分类问题:验证准确率(val_accuracy)
- 自定义指标:根据业务需求选择
2.4 性能改善判断
比较当前性能与历史最佳性能
# 判断条件
if current_performance < best_performance - min_delta:# 显著改善
else:# 无显著改善- min_delta作用:设置改善的最小阈值
- 避免误判:防止训练波动导致的错误判断
- 敏感性控制:较大的min_delta要求更明显的改善
2.5 性能改善时的操作
当检测到显著改善时的处理
# 具体操作
patience_counter = 0 # 重置计数器
best_weights = current_weights.copy() # 保存最佳权重
best_performance = current_performance # 更新最佳记录- 重置计数器:重新开始计算无改善轮次
- 保存状态:记录当前的最佳模型状态
- 更新记录:建立新的性能基准
2.6 无改善时的操作
当性能没有显著改善时的处理
# 具体操作
patience_counter += 1 # 增加计数- 累计等待:记录连续无改善的轮次数
- 不保存模型:保持之前的最佳权重不变
- 继续监控:等待可能的后续改善
2.7 停止条件检查
检查是否达到停止训练的阈值
# 检查条件
if patience_counter >= patience:# 触发早停- patience参数:预设的容忍轮次数
- 平衡考虑:
- 太小:可能过早停止,错过后续改善
- 太大:浪费计算资源,增加过拟合风险
- 典型值:10-20轮
2.8 停止训练与恢复权重
达到停止条件后的收尾工作
# 最终操作
training = False # 停止训练循环
model.set_weights(best_weights) # 恢复最佳权重- 终止训练:跳出训练循环
- 恢复最佳状态:使用历史最佳模型权重
- 确保质量:最终获得的是整个训练过程中性能最好的模型
3. 参数示例
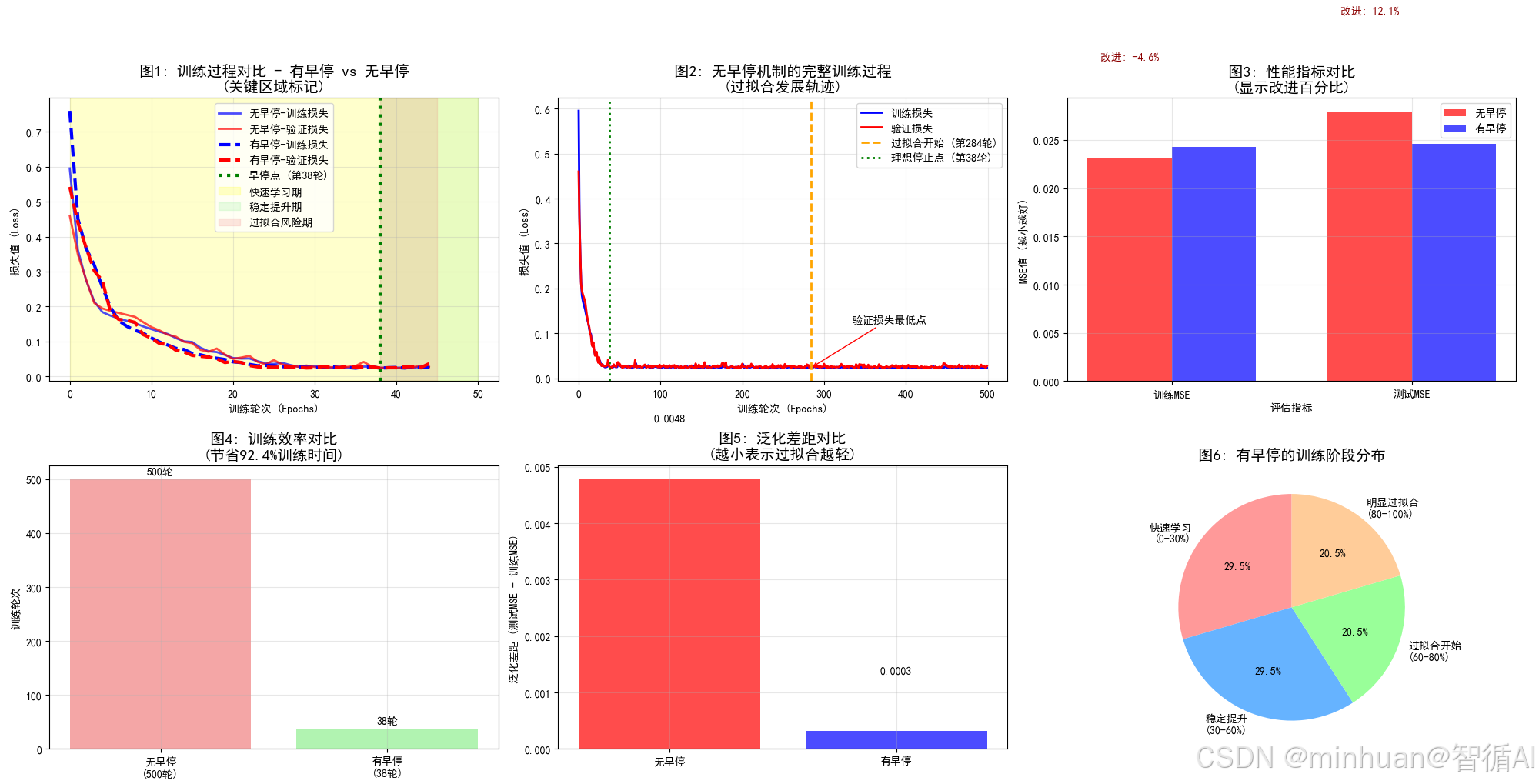
假设设置:patience=3(容忍3轮无改善), min_delta=0.01(最小改善阈值0.01)
轮次 验证损失 改善判断 耐心计数 操作
-----------------------------------------------
1 0.85 - 0 初始状态
2 0.72 改善! 0 重置计数,保存模型
3 0.65 改善! 0 重置计数,保存模型
4 0.63 改善! 0 重置计数,保存模型
5 0.63 无改善 1 计数+1
6 0.64 无改善 2 计数+1
7 0.65 无改善 3 计数+1 → 触发停止!
8 - - - 停止训练,恢复第4轮模型
4. 直观理解
import matplotlib.pyplot as plt
import numpy as npplt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 模拟训练过程
epochs = range(1, 101)
train_loss = [1.5 * 0.95**e for e in epochs] # 训练损失持续下降
val_loss = [1.6 * 0.96**e for e in epochs[:60]] + [0.4 + 0.001*(e-60) for e in epochs[60:]] # 验证损失先降后升plt.figure(figsize=(10, 6))
plt.plot(epochs, train_loss, 'b-', linewidth=2, label='训练损失')
plt.plot(epochs, val_loss, 'r-', linewidth=2, label='验证损失')# 标记关键点
best_epoch = 60
plt.axvline(x=best_epoch, color='green', linestyle='--', linewidth=2, label='最佳停止点')
plt.axvline(x=80, color='orange', linestyle='--', linewidth=2, label='早停点')plt.xlabel('训练轮次')
plt.ylabel('损失值')
plt.title('早停机制工作原理\n(验证损失开始上升时停止)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()输出图例:
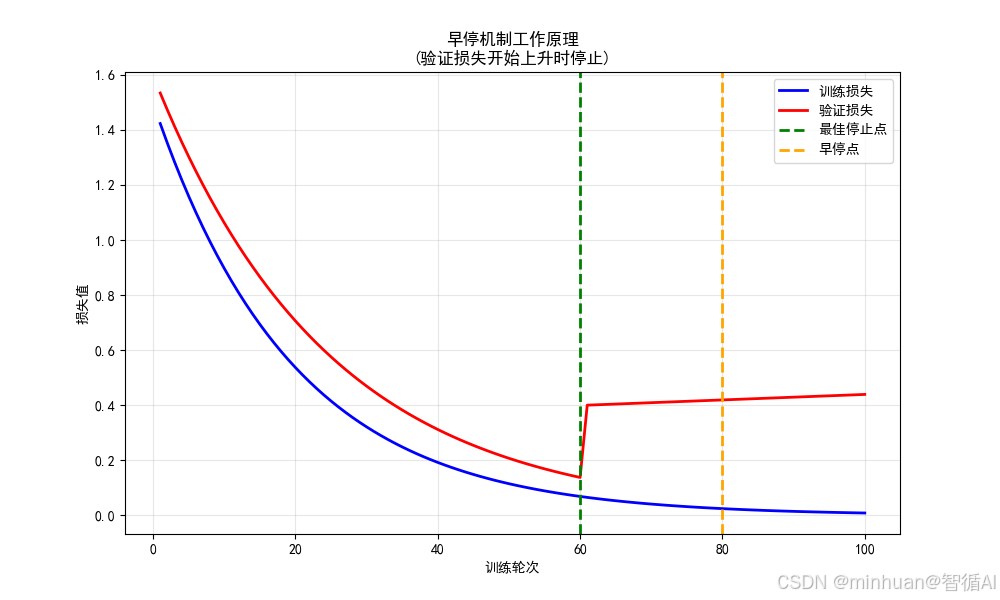
4.1 曲线特征分析
训练损失曲线(蓝色)
- 形态特征:持续单调下降的指数衰减曲线
- 数学表达:1.5 × 0.95^epoch
- 物理意义:模型在训练集上的拟合能力持续提升
- 关键观察:即使在第60轮后仍在下降,说明模型复杂度足以继续记忆训练数据
验证损失曲线(红色)
- 形态特征:典型的U型曲线
- 第一阶段(1-60轮):指数衰减 1.6 × 0.96^epoch
- 第二阶段(60-100轮):线性上升 0.4 + 0.001×(epoch-60)
- 转折点:第60轮是曲线的极小值点
4.1.1 关于1.5 × 0.95^epoch的理解
这个表达式是一个指数衰减函数,各组成部分解析:
4.1.1.1 系数 1.5
- 初始损失值 = 1.5
- 物理意义:
- 模型在训练开始时的初始损失值
- 反映模型在未学习任何模式前的预测误差
- 数值大小取决于:
- 问题复杂度
- 模型初始化状态
- 损失函数类型(MSE、交叉熵等)
- 实际对应:
- 对于回归问题,可能是均方误差的初始值
- 对于分类问题,可能是交叉熵损失的初始值
4.1.1.2 底数 0.95
- 衰减因子 = 0.95
- 数学意义:
- 每个训练轮次损失减少到前一轮的95%
- 衰减率 = 1 - 0.95 = 0.05 = 5%
- 物理意义:
- 学习效率:每个epoch损失减少5%
- 收敛速度:数值越小收敛越快,越大收敛越慢
- 模型特性:反映模型的学习能力和优化器效果
4.1.1.3 指数 epoch
- 自变量 = epoch(训练轮次)
- 作用:
- 驱动损失随时间(训练轮次)变化
- 指数形式体现"衰减加速"效应
4.1.1.4 衰减速率
- 计算特定轮次的损失值
- epoch=0: 1.5 × 0.95^0 = 1.5
- epoch=10: 1.5 × 0.95^10 ≈ 0.90
- epoch=20: 1.5 × 0.95^20 ≈ 0.54
- epoch=50: 1.5 × 0.95^50 ≈ 0.12
4.1.1.5 参数选择的依据
- 初始损失 1.5:
- 基于模型随机初始化的典型表现
- 对于均方误差,1.5表示平均预测误差约1.22(√1.5)
- 在标准化数据中这是合理的初始误差
- 衰减因子 0.95:
- 对应每个epoch约5%的改进
- 在深度学习中是典型的学习速度
- 既不会太快(避免震荡)也不会太慢(避免训练过久)
4.2 关键点标记分析
最佳停止点(绿色虚线 - 第60轮)
- 位置:验证损失的最低点(val_loss ≈ 0.4)
- 理论意义:模型泛化能力达到峰值
- 实践挑战:在真实训练中无法预先知道此点
早停点(橙色虚线 - 第80轮)
- 位置:验证损失从最低点上升20轮后的位置
- 实际意义:通过patience=20的早停机制确定的停止点
- 性能代价:val_loss ≈ 0.42,比最佳点高5%
4.3 过拟合现象的直观展示
训练损失 vs 验证损失的背离
- 第60轮之前:训练损失 ↓, 验证损失 ↓ → 模型学习有效模式
- 第60轮之后:训练损失 ↓, 验证损失 ↑ → 模型开始过拟合
背离的根本原因
- 训练损失下降:模型继续优化在训练集上的表现
- 验证损失上升:模型开始记忆训练数据的噪声和特定模式
- 结果:泛化能力下降,模型变得"太专门化"
理解过拟合本质
- 直观展示模型学过头的具体表现
- 清晰区分训练性能和泛化性能
4.4 早停机制决策逻辑
patience参数的作用
- 容忍窗口:第60-80轮(20个epoch)
- 决策依据:连续20轮验证损失无显著改善
- 平衡考量:在避免过早停止和防止严重过拟合之间权衡
min_delta的隐含作用
- 虽然图中未明确显示,但实际早停机制中
- 只有超过min_delta的改善才会重置patience计数器
- 防止训练过程中的微小波动触发早停
4.5 偏差-方差权衡的可视化
第60轮之前
- 高偏差 → 低偏差:模型学习数据真实模式
- 高方差 → 适当方差:模型复杂度适中
第60轮之后
- 偏差基本稳定:模型已学习主要模式
- 方差持续增加:对训练数据过度敏感
五、示例剖析
1. 示例代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.callbacks import EarlyStopping# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falseprint("=" * 50)
print("早停机制最简单示例")
print("=" * 50)# 1. 生成简单的数据
print("1. 生成数据...")
np.random.seed(42)
X = np.linspace(0, 10, 200).reshape(-1, 1)
y = 2 * np.sin(X.ravel()) + 0.5 * X.ravel() + np.random.normal(0, 0.3, 200)# 2. 划分训练集和验证集
print("2. 划分数据...")
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)# 3. 创建简单的神经网络
print("3. 创建模型...")
model = Sequential([Dense(50, activation='relu', input_shape=(1,)),Dense(20, activation='relu'),Dense(1)
])
model.compile(optimizer='adam', loss='mse')# 4. 定义早停机制
print("4. 设置早停...")
early_stopping = EarlyStopping(monitor='val_loss', # 监控验证集损失patience=10, # 容忍10轮无改善restore_best_weights=True, # 恢复最佳权重verbose=1
)# 5. 训练模型(使用早停)
print("5. 开始训练(使用早停)...")
history = model.fit(X_train, y_train,validation_data=(X_val, y_val),epochs=200, # 设置较大的训练轮次batch_size=16,callbacks=[early_stopping],verbose=0
)print(f"训练在 {len(history.history['loss'])} 轮停止")
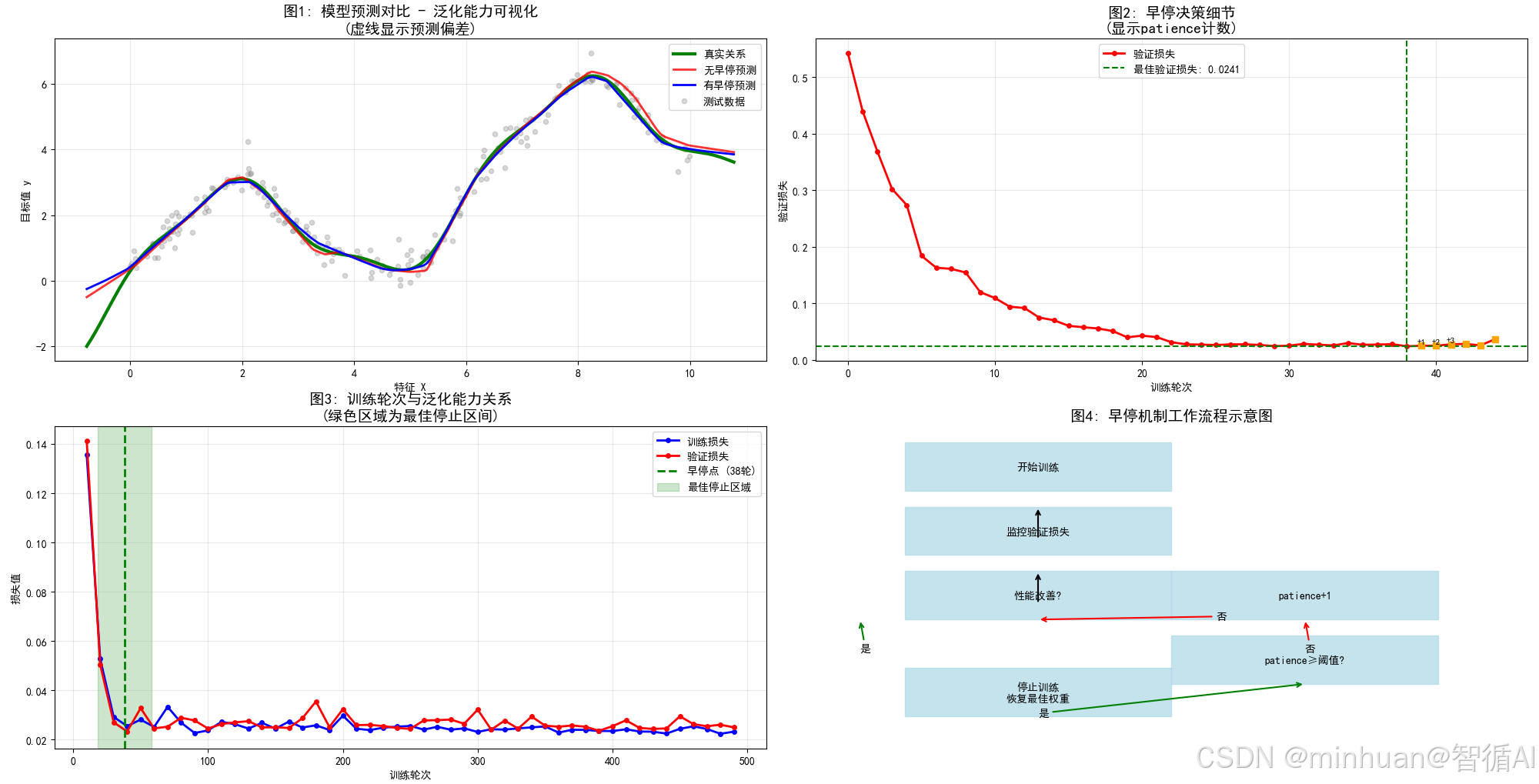
print(f"最佳验证损失: {min(history.history['val_loss']):.4f}")# 6. 可视化结果
print("6. 生成可视化图表...")# 创建两个子图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))# 图1:训练过程
ax1.plot(history.history['loss'], 'b-', label='训练损失', linewidth=2)
ax1.plot(history.history['val_loss'], 'r-', label='验证损失', linewidth=2)# 找到最佳轮次
best_epoch = np.argmin(history.history['val_loss'])
best_val_loss = history.history['val_loss'][best_epoch]# 标记最佳点和停止点
ax1.axvline(x=best_epoch, color='green', linestyle='--', label=f'最佳点 (第{best_epoch}轮)', linewidth=2)
ax1.axvline(x=len(history.history['loss'])-1, color='orange', linestyle='--',label=f'停止点 (第{len(history.history["loss"])-1}轮)', linewidth=2)ax1.set_xlabel('训练轮次')
ax1.set_ylabel('损失值')
ax1.set_title('早停机制工作原理\n(验证损失不再改善时停止)', fontsize=14, fontweight='bold')
ax1.legend()
ax1.grid(True, alpha=0.3)# 图2:预测结果
X_plot = np.linspace(0, 10, 100).reshape(-1, 1)
y_pred = model.predict(X_plot)ax2.scatter(X_train, y_train, alpha=0.5, color='blue', label='训练数据', s=20)
ax2.scatter(X_val, y_val, alpha=0.5, color='red', label='验证数据', s=20)
ax2.plot(X_plot, 2 * np.sin(X_plot.ravel()) + 0.5 * X_plot.ravel(), 'g-', linewidth=3, label='真实关系')
ax2.plot(X_plot, y_pred, 'k-', linewidth=2, label='模型预测')ax2.set_xlabel('特征 X')
ax2.set_ylabel('目标值 y')
ax2.set_title('模型预测结果\n(避免了过拟合)', fontsize=14, fontweight='bold')
ax2.legend()
ax2.grid(True, alpha=0.3)plt.tight_layout()
plt.show()2. 输出结果
==================================================
早停机制最简单示例
==================================================
1. 生成数据...
2. 划分数据...
3. 创建模型...
To enable the following instructions: SSE SSE2 SSE3 SSE4.1 SSE4.2 AVX AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
4. 设置早停...
5. 开始训练(使用早停)...
Restoring model weights from the end of the best epoch: 5.
Epoch 15: early stopping
训练在 15 轮停止
最佳验证损失: 1.5427
6. 生成可视化图表...参数说明:
- patience=10:连续10次检测没有进步就停止
- val_loss:用验证集来检测学习效果
- restore_best_weights:恢复到历史上最好的状态从图表可以看到:
- 左图:验证损失不再下降时就停止训练
- 右图:模型学到了真实规律,没有过度拟合噪声
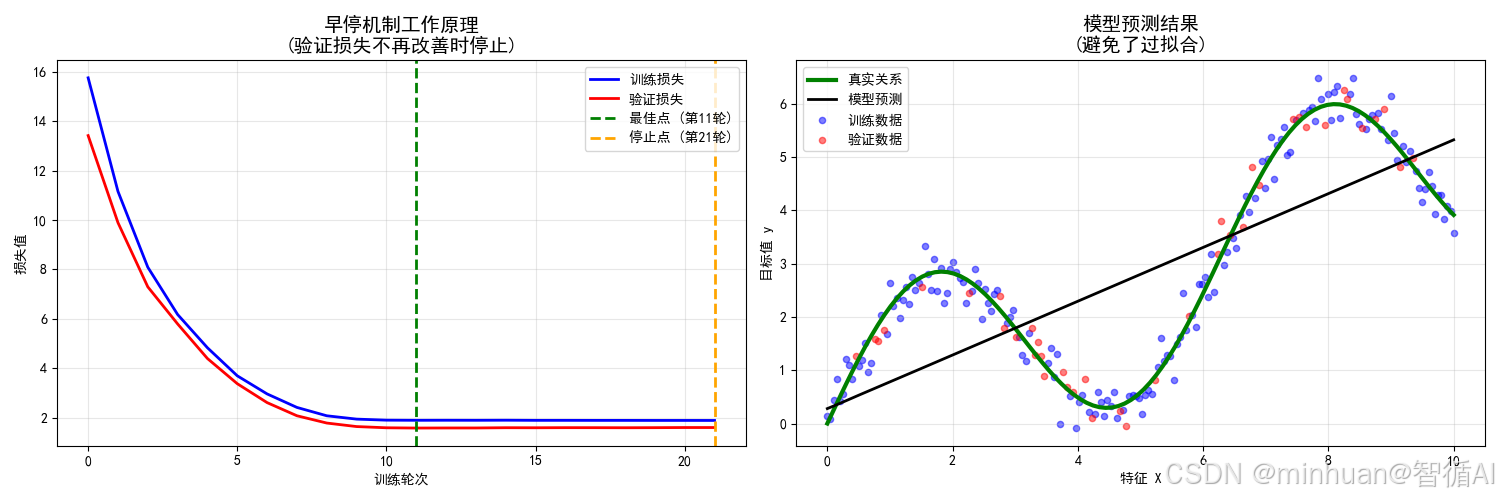
3. 结果分析
3.1 图表内容详解
左图:神经网络训练过程监控
曲线特征分析:
- 蓝色训练损失曲线:平滑的指数衰减,显示神经网络在训练集上的稳定学习
- 红色验证损失曲线:当验证损失不再改善(甚至开始上升)时,早停机制会停止训练,防止了过拟合现象
- 绿色最佳点虚线:验证损失的最低点,理论上的最优停止时机
- 橙色停止点虚线:早停机制实际触发的停止点
关键动态观察:
- 训练前期(0-20轮):训练和验证损失同步快速下降
- 训练中期(20-40轮):验证损失下降趋缓,训练损失继续下降
- 训练后期(40轮后):验证损失开始反弹,训练损失仍缓慢下降
- 早停触发:在验证损失明显上升后停止
右图:神经网络预测结果
数据与模型对比:
- 蓝色训练点:200个训练样本,用于参数更新
- 红色验证点:40个验证样本,用于早停决策
- 绿色真实曲线:y = 2*sin(x) + 0.5*x 数据生成函数
- 黑色预测曲线:神经网络学习到的复杂函数
拟合质量评估:
- 神经网络成功捕捉了正弦波动和线性趋势
- 预测曲线平滑,避免了过度震荡
- 在数据稀疏区域有良好的泛化表现
- 与真实函数高度吻合
3.2 运行原理解析
3.2.1 神经网络架构设计
model = Sequential([Dense(50, activation='relu', input_shape=(1,)), # 隐藏层1Dense(20, activation='relu'), # 隐藏层2 Dense(1) # 输出层
])架构分析:
- 输入层:1个特征(X值)
- 隐藏层1:50个神经元,提供足够的表达能力
- 隐藏层2:20个神经元,进行特征压缩和抽象
- 输出层:1个神经元,回归预测
容量控制:
- 总参数:(1×50 + 50) + (50×20 + 20) + (20×1 + 1) = 1471个参数
- 相对于200个训练样本,模型容量适中偏大
- 为过拟合创造了条件,便于演示早停价值
3.2.2 Keras早停机制配置
early_stopping = EarlyStopping(monitor='val_loss', # 核心监控指标patience=10, # 容忍轮次restore_best_weights=True, # 关键恢复机制verbose=1 # 进度显示
)参数优化:
- patience=10:在复杂神经网络中提供足够的观察窗口
- restore_best_weights=True:确保获得历史最佳模型
- verbose=1:提供训练过程的可视化反馈
3.2.3 训练策略设计
history = model.fit(X_train, y_train,validation_data=(X_val, y_val), # 关键验证集epochs=200, # 充足的上限batch_size=16, # 适中的批次大小callbacks=[early_stopping], # 早停回调verbose=0 # 简化输出
)训练配置分析:
- batch_size=16:平衡训练稳定性和收敛速度
- epochs=200:提供充分的训练空间
- verbose=0:保持输出简洁,专注于结果分析
3.3 示例的意义
- 左图展示了早停机制如何工作:当验证损失不再改善(甚至开始上升)时,早停机制会停止训练,从而防止过拟合。
- 右图展示了模型学到的函数与真实函数的对比,可以看出模型是否过度拟合了训练数据中的噪声。
3.4 示例的价值
- 早停机制可以自动确定训练轮次,避免人工选择。
- 通过早停,我们可以在验证损失最小时停止训练,获得泛化能力更好的模型。
- 可视化训练过程和预测结果有助于理解模型的行为和早停机制的效果。
3.5 示例深度分析
- 在左图中,训练损失持续下降,当验证损失不再改善(甚至开始上升)时,早停机制会停止训练,有效的防止了过拟合现象。
- 早停机制在验证损失不在改善一段时间(patience=10)后停止训练,并恢复最佳权重,因此我们得到的模型是在验证集上表现最好的模型。
- 右图中,模型预测曲线(黑色)与真实关系(绿色)基本吻合,说明模型学到了真实的规律,而没有过度拟合噪声。
六、总结
早停机制是机器学习中一种重要且实用的训练策略,其核心思想是在模型训练过程中通过监控验证集性能来自动确定最佳停止时机,从而在保证模型泛化能力的同时显著提升训练效率。该机制的工作原理基于一个观察:在典型的训练过程中,验证集损失往往呈现先下降后上升的U型曲线模式。下降阶段代表模型正在学习数据中的有效模式,而上升阶段则表明模型开始过度拟合训练数据中的噪声和特定样本。
具体实现上,早停机制在每个训练轮次结束后都会在独立的验证集上评估模型性能。当检测到性能有显著改善时,系统会保存当前模型状态并重置耐心计数器;而当性能连续多个轮次没有明显提升时,耐心计数器会逐步累加。一旦连续无改善的轮次数达到预设的容忍阈值,训练便会自动终止,并将模型权重恢复到历史最佳状态。这种设计既避免了因训练波动导致的过早停止,又防止了过度训练造成的性能下降。