【具身智能】MolmoAct深度解析:在空间中推理的开放式机器人动作模型
MolmoAct深度解析:首个在空间中推理的开放式机器人动作模型
MolmoAct: Action Reasoning Models that can Reason in Space
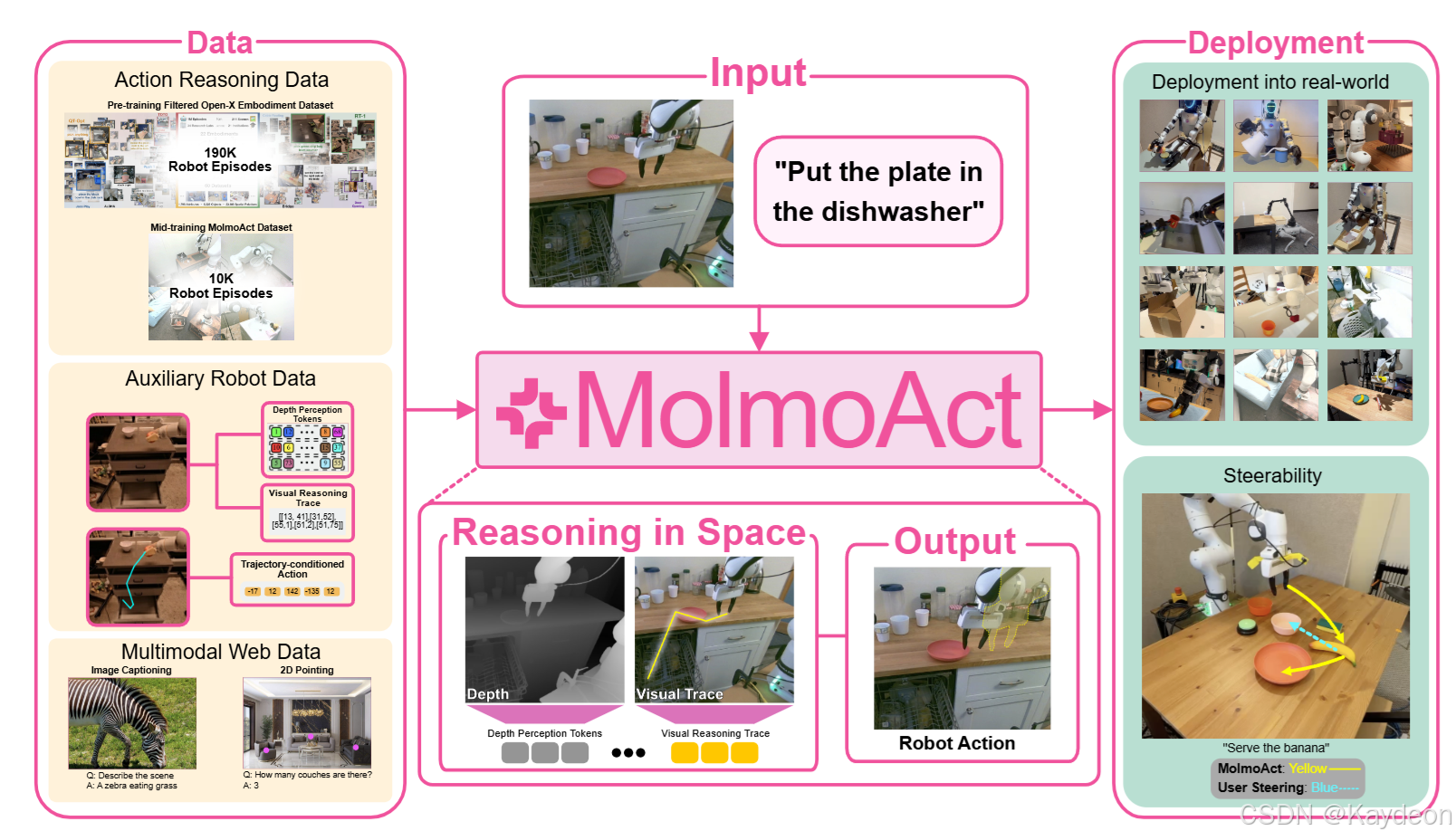
📘 一、摘要解析
研究背景:
传统机器人模型将感知(如图像)和语言指令直接映射为动作,缺乏“思考”过程,导致泛化能力差、适应性弱、不可解释。
核心贡献:
- 提出动作推理模型(ARMs),通过三阶段结构化流程整合感知、规划与控制。
- 实现模型 MolmoAct,具备以下能力:
- 编码图像与指令为深度感知Token;
- 生成**视觉轨迹(轨迹点)**作为中间规划;
- 预测动作Token控制机器人;
- 性能表现:
- 零样本任务成功率达 70.5%(SimplerEnv);
- LIBERO 平均成功率 86.6%;
- 真实世界中微调后任务完成率提升 10%(单臂) 和 22.7%(双臂);
- 开源贡献:
- 发布 MolmoAct 数据集(10,000+ 轨迹);
- 开源模型权重、训练代码、动作推理数据。
🧠 二、引言解析
核心思想:
“思考是具身的、空间的、发生在你头脑之外的。”
机器人要像人类一样“先想后做”,必须引入空间推理机制。
问题指出现状:
- VLA(视觉-语言-动作)模型虽多,但普遍:
- 泛化能力差(跨任务/场景/机器人);
- 不可解释(无法说明为何选择某个动作);
- 数据饥渴(依赖大量昂贵真机数据);
MolmoAct 的解决方案:
- 引入结构化推理流程:
- 感知阶段:生成深度Token(3D理解);
- 规划阶段:生成视觉轨迹(2D路径);
- 控制阶段:生成动作Token(控制命令);
- 所有中间表示均可视化、可编辑、可解释;
- 支持语言指令与视觉轨迹草图双重控制方式。
⚙️ 三、MolmoAct 方法详解
3.1 基础架构:视觉语言模型(VLM)
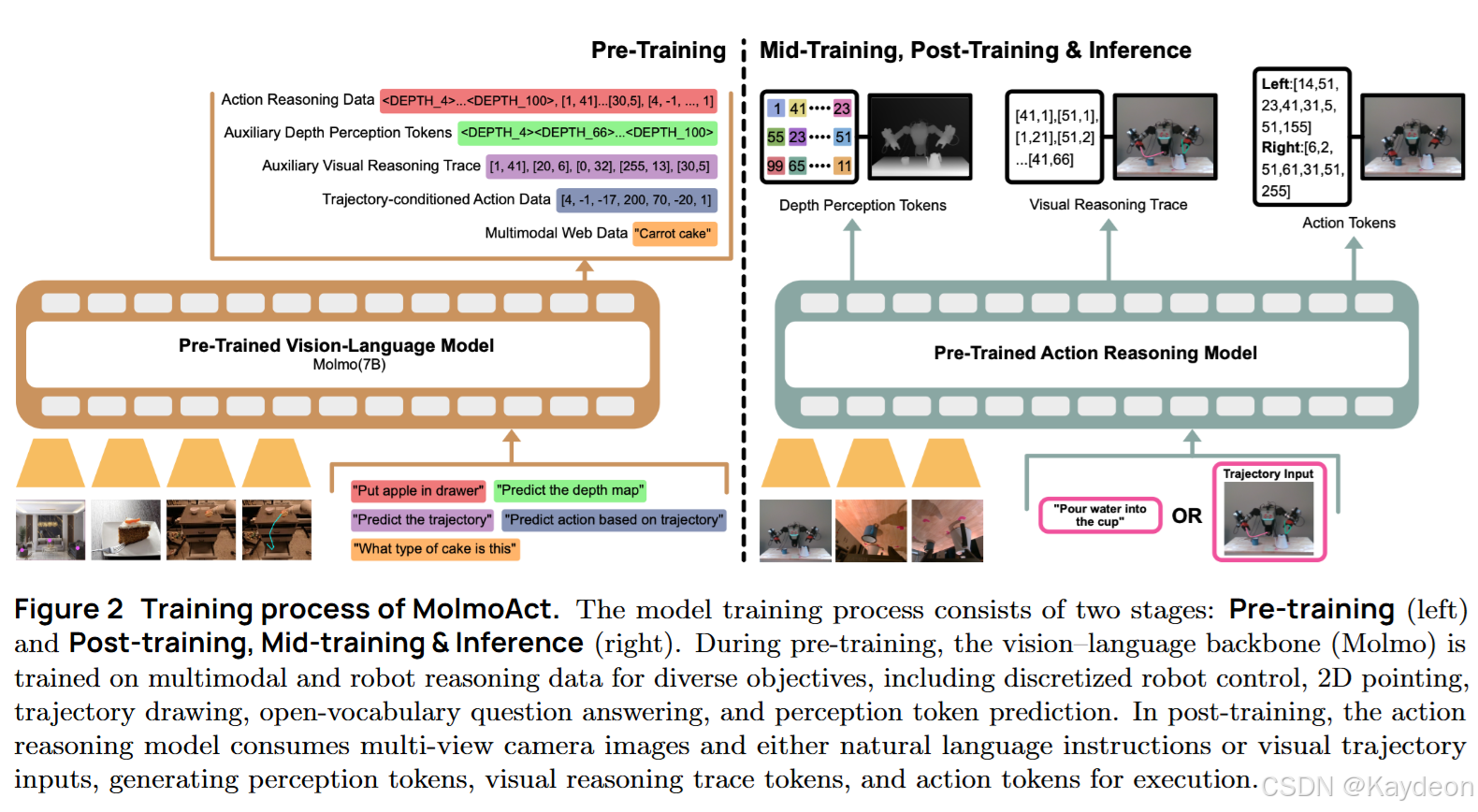
三部分组成:
- 视觉编码器:如 ViT(SigLIP2 / CLIP);
- 视觉-语言连接器:MLP,将图像特征映射到语言空间;
- 大语言模型(LLM):如 Qwen2.5-7B / OLMo2-7B;
两个模型版本:
- MolmoAct-7B-D:SigLIP2 + Qwen2.5(性能最佳);
- MolmoAct-7B-O:CLIP + OLMo2(最开放);
3.2 动作建模:动作Token化
动作表示:
- 每个动作维度(如x, y, z, 旋转、夹爪)被归一化后;
- 离散化为 256个bin(0~255);
- 每个bin映射为一个动作Token;
创新点:
- 不使用随机语言Token,而是:
- 选取 Qwen2 分词器中最后256个Token;
- 这些Token是字节级BPE子词,具有字符相似性;
- 将相邻bin映射为相似Token,保留动作空间的连续性;
- 优势:
- 更好的嵌入初始化;
- 训练更快(GROOT N1 的 1/5 时间);
- 动作预测更平滑、准确;
3.3 动作推理模型(Action Reasoning Model)
✅ 核心思想:在空间中进行推理
不同于语言推理(如“先拿杯子再倒水”),MolmoAct 引入两个空间中间表示:
🔍(1)深度感知Token(Depth Perception Tokens)
目的:让模型理解3D空间结构。
生成方式:
- 使用专家模型(Depth Anything V2)生成深度图;
- 用 VQVAE 将深度图量化为 100个离散Token;
- 每个Token对应一个深度码本索引(128个码本向量);
公式解析:
V depth = { ⟨ DEPTH_START ⟩ , ⟨ DEPTH_END ⟩ } ∪ { ⟨ DEPTH_ k ⟩ } k = 1 N V_{\text{depth}} = \{\langle\text{DEPTH\_START}\rangle, \langle\text{DEPTH\_END}\rangle\} \cup \{\langle\text{DEPTH\_}k\rangle\}_{k=1}^{N} Vdepth={⟨DEPTH_START⟩,⟨DEPTH_END⟩}∪{⟨DEPTH_k⟩}k=1N
- V depth V_{\text{depth}} Vdepth:深度Token词汇表;
- N = 128 N=128 N=128:码本大小;
- ⟨ DEPTH_ k ⟩ \langle\text{DEPTH\_}k\rangle ⟨DEPTH_k⟩:第k个深度Token;
目标深度序列:
d = ( ⟨ DEPTH_START ⟩ , ⟨ DEPTH_ z 1 ⟩ , … , ⟨ DEPTH_ z M ⟩ , ⟨ DEPTH_END ⟩ ) \mathbf{d} = \left( \langle\text{DEPTH\_START}\rangle, \langle\text{DEPTH\_}_{z_1}\rangle, \dots, \langle\text{DEPTH\_}_{z_M}\rangle, \langle\text{DEPTH\_END}\rangle \right) d=(⟨DEPTH_START⟩,⟨DEPTH_z1⟩,…,⟨DEPTH_zM⟩,⟨DEPTH_END⟩)
- M = 100 M=100 M=100:Token序列长度;
- z i ∈ { 1 , … , 128 } z_i \in \{1, \dots, 128\} zi∈{1,…,128}:VQVAE量化后的码本索引;
🧭(2)视觉推理轨迹(Visual Reasoning Trace)
目的:用2D轨迹表示未来运动计划。
定义:
- 在图像平面上,预测末端执行器的轨迹点;
- 最多 5个点(0~4段线段);
- 坐标归一化为 [0, 255];
公式:
τ = ( p 1 , … , p L ) , p i = ( u i , v i ) \tau = (p_1, \dots, p_L), \quad p_i = (u_i, v_i) τ=(p1,…,pL),pi=(ui,vi)
- τ \tau τ:轨迹;
- p i p_i pi:第i个轨迹点;
- ( u i , v i ) (u_i, v_i) (ui,vi):图像坐标;
🧠(3)动作推理流程(Action Reasoning Procedure)
自回归生成顺序:
- 深度Token序列 d \mathbf{d} d;
- 视觉轨迹 τ \tau τ;
- 动作Token序列 a \mathbf{a} a;
联合概率公式:
p ( d , τ , a ∣ I , T ) = ∏ i = 1 M + 2 p ( d i ∣ I , T , d < i ) × ∏ j = 1 L p ( τ j ∣ I , T , d , τ < j ) × ∏ k = 1 D p ( a k ∣ I , T , d , τ , a < k ) p(\mathbf{d}, \tau, \mathbf{a} \mid I, T) = \prod_{i=1}^{M+2} p(d_i \mid I, T, d_{<i}) \times \prod_{j=1}^{L} p(\tau_j \mid I, T, \mathbf{d}, \tau_{<j}) \times \prod_{k=1}^{D} p(a_k \mid I, T, \mathbf{d}, \tau, a_{<k}) p(d,τ,a∣I,T)=i=1∏M+2p(di∣I,T,d<i)×j=1∏Lp(τj∣I,T,d,τ<j)×k=1∏Dp(ak∣I,T,d,τ,a<k)
- 每个阶段的生成都依赖于前面所有阶段;
- 动作为最终输出,受深度与轨迹双重条件约束;
- 实现“先理解3D空间 → 再规划路径 → 再执行动作”的推理链;
3.4 动作可控性(Steerability)
问题:语言指令模糊、不可精确控制;
解决方案:
- 允许用户在图像上手绘轨迹;
- 将轨迹叠加到图像上,形成增强输入 I + I^+ I+;
- 模型直接根据 I + I^+ I+ 生成动作;
公式:
p ( a ∣ I + , T ) = ∏ k = 1 D p ( a k ∣ I + , T , a < k ) p(\mathbf{a} \mid I^+, T) = \prod_{k=1}^{D} p(a_k \mid I^+, T, a_{<k}) p(a∣I+,T)=k=1∏Dp(ak∣I+,T,a<k)
- 不再生成深度与轨迹,而是直接使用用户提供的轨迹;
- 实现视觉草图控制机器人;
- 成功率远高于语言修正(75% vs 42%);
📊 四、数据与训练
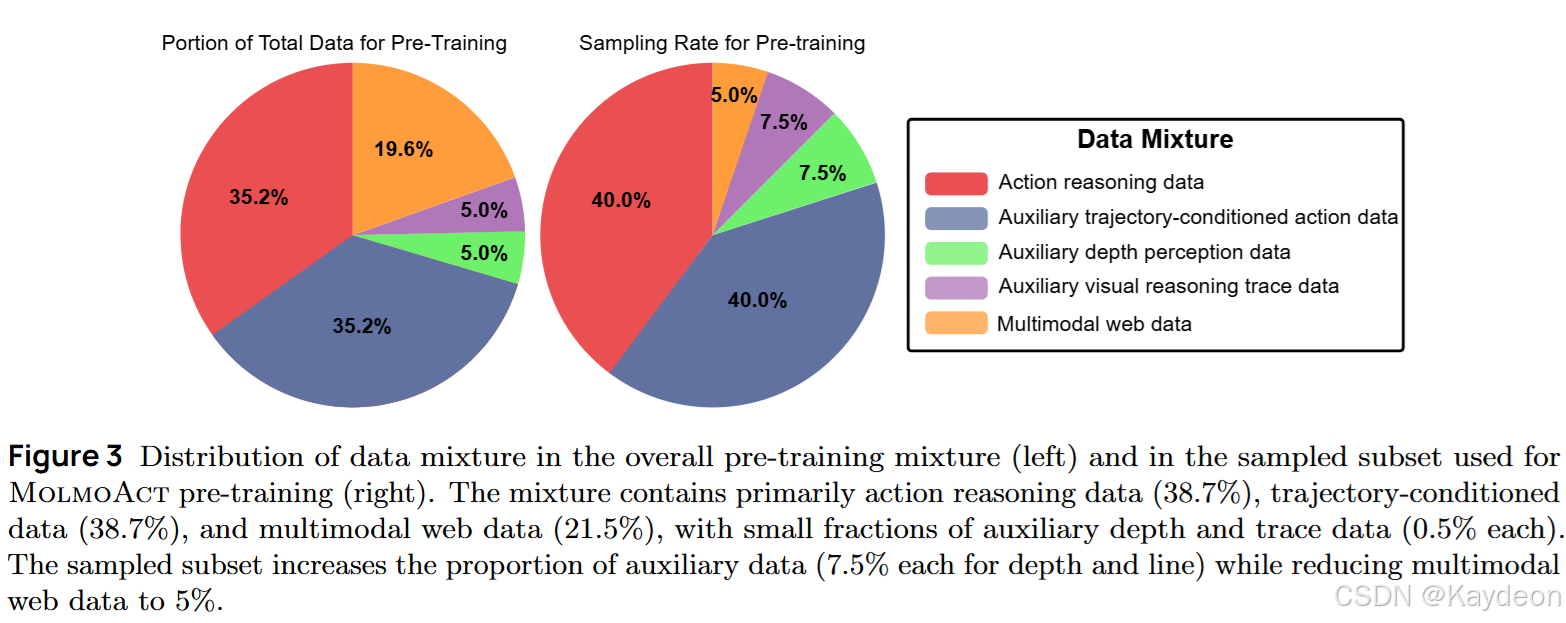
4.1 动作推理数据生成
- 将任意机器人数据集转换为动作推理格式;
- 自动生成:
- 深度Token(VQVAE编码);
- 视觉轨迹(Molmo VLM 标注夹爪位置);
- 支持多种辅助任务(仅预测深度、仅预测轨迹、轨迹条件动作预测);
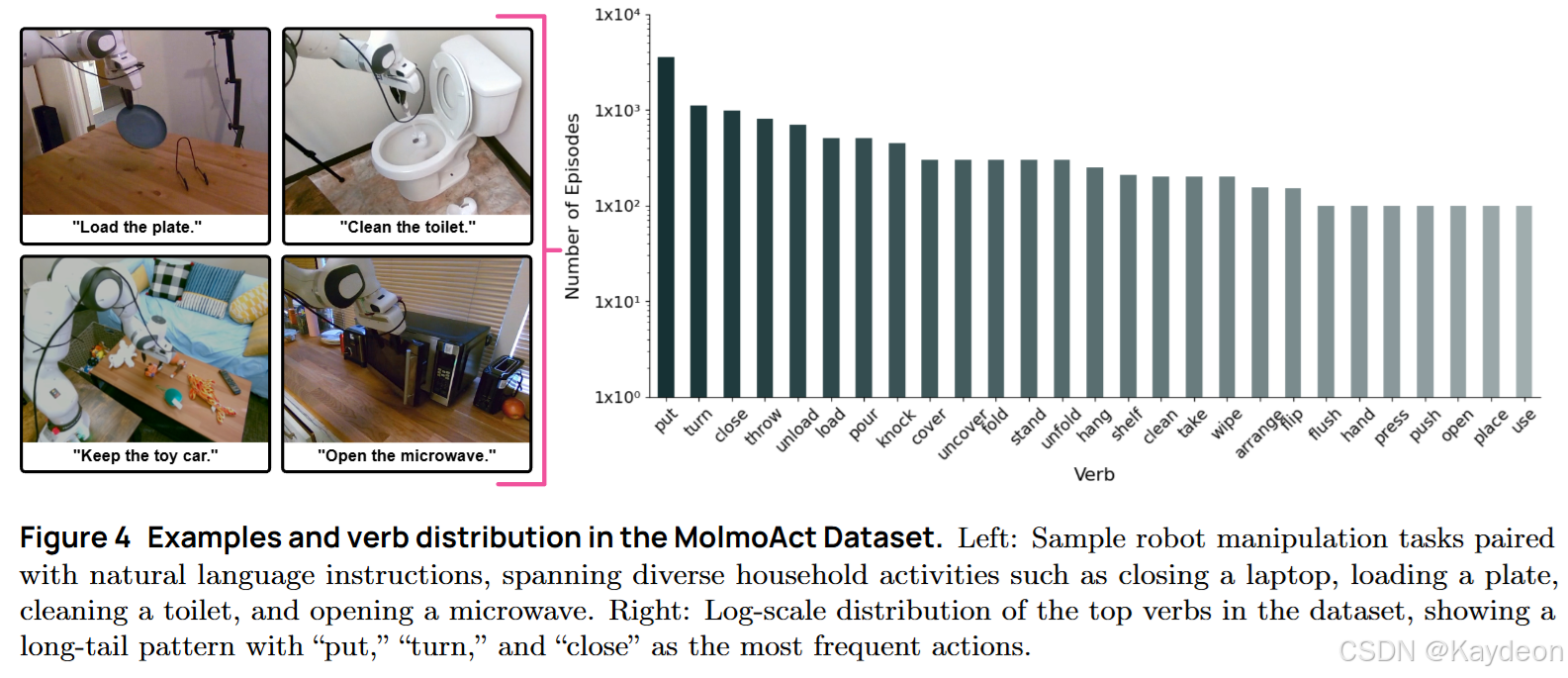
4.2 MolmoAct 数据集
- 10,689条轨迹,93个任务;
- 家庭环境 + 桌面环境;
- 长任务分解为子任务;
- 提升模型泛化与空间理解能力;
🧪 五、实验评估
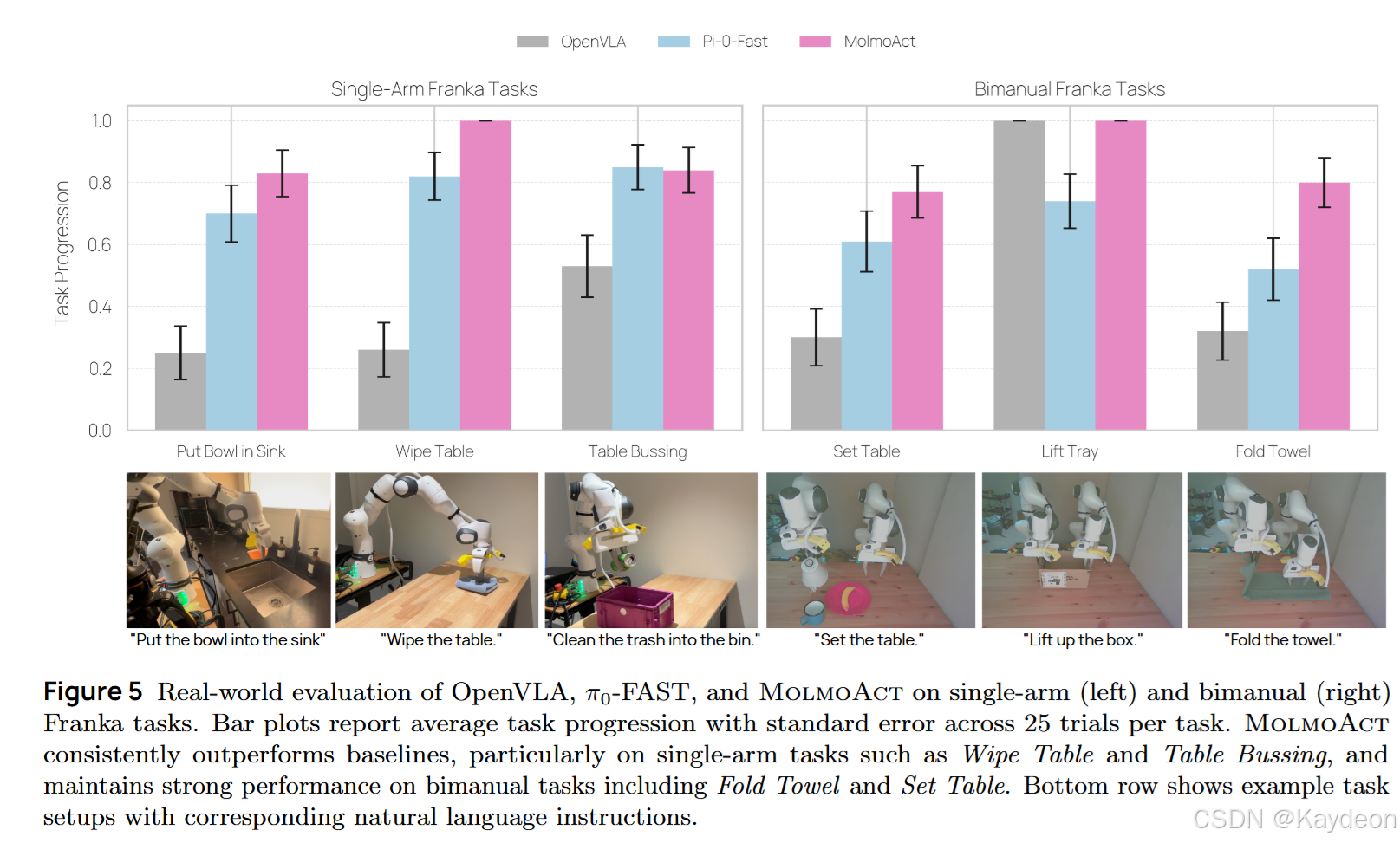
| 实验类型 | 数据集 | 结果 |
|---|---|---|
| 零样本测试 | SimplerEnv | 70.5%(超 π₀、GROOT N1) |
| 微调测试 | LIBERO | 86.6%(第一) |
| 真实世界 | 单臂/双臂 | +10% / +22.7%(优于 π₀-FAST) |
| 泛化测试 | OOD | +23.3%(平均提升) |
| 指令遵循 | 人工评分 | Elo 分最高(语言+轨迹) |
| 可控性测试 | 手绘轨迹 | 成功率 75%(语言仅 42%) |
📚 六、结论
- 提出 MolmoAct:完全开放、可解释、可引导的动作推理模型;
- 引入空间推理机制:深度Token + 视觉轨迹;
- 三阶段推理流程:感知 → 规划 → 控制;
- 在模拟与真实世界中均取得SOTA性能;
- 开源所有模型、数据、代码,推动机器人基础模型发展。