【具身智能】Gemini Robotics 1.5 深度解析:当机器人学会“思考”与“技能迁移”
Gemini Robotics 1.5 深度解析:当机器人学会“思考”与“技能迁移”
摘要
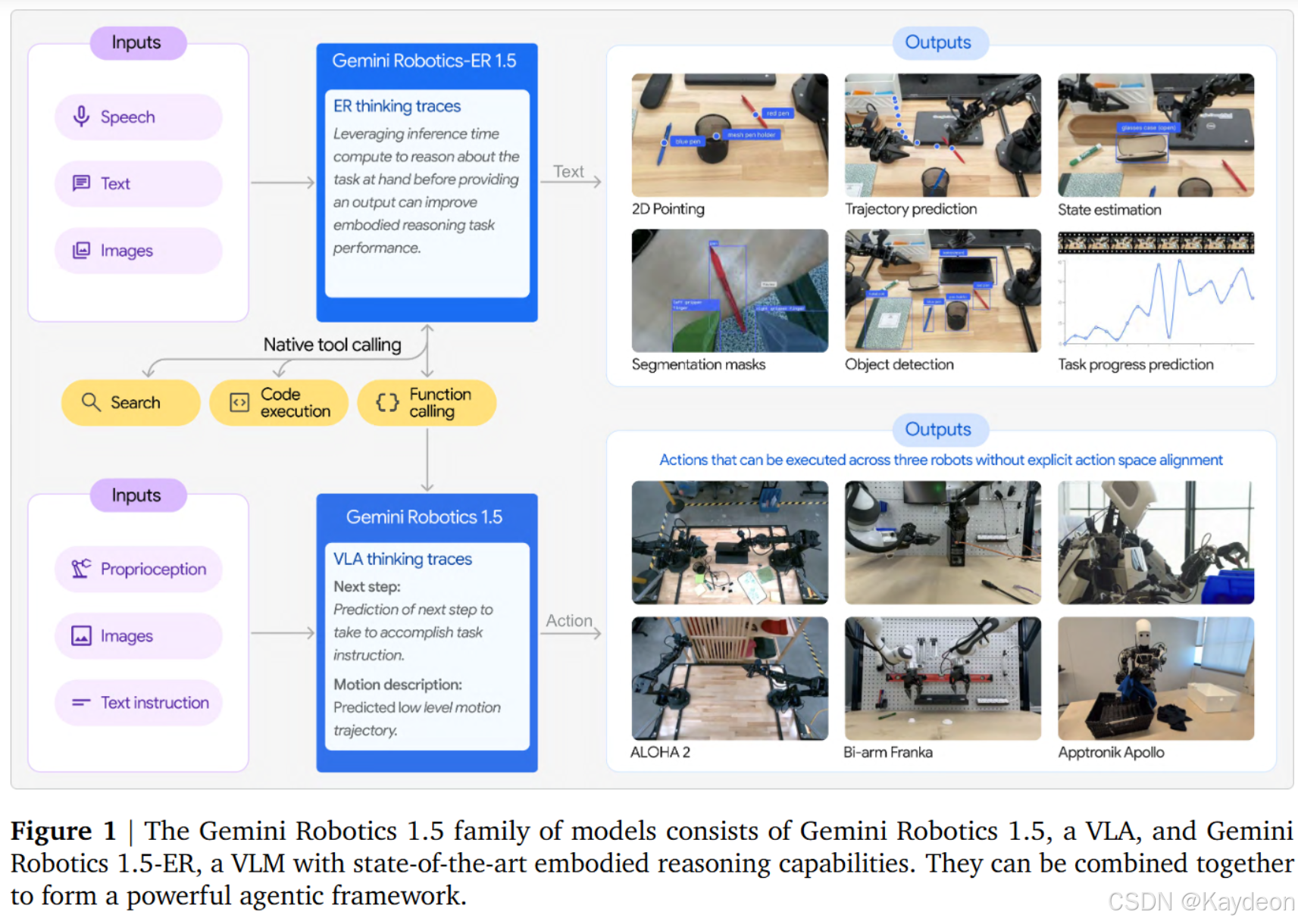
Gemini Robotics 1.5 系列包含两个模型:
- GR 1.5:多形态视觉-语言-动作(VLA)模型。
- GR-ER 1.5:通用具身推理(VLM)模型。
三大创新:
- 运动迁移(MT):在共享潜空间 z∈R64z\in\mathbb{R}^{64}z∈R64 里统一异构机器人动作,实现零样本跨本体迁移。
- 思考-再-行动:在动作前插入自然语言思考痕迹 τt\tau_tτt,把“高阶指令→低阶动作”拆成两步。
- SOTA 具身推理:15 项基准全部霸榜,空间推理平均提升 8 个点。
第一章 引言

- 通用机器人必须“懂物理”。
- 前作 Gemini Robotics 只能单本体+短指令。
- 本文目标:把 Gemini 的“高层推理”搬到物理世界,并解决三大痛点:
① 数据稀缺;② 跨本体迁移难;③ 长任务规划弱。
第二章 方法概述

2.1 模型与架构
GR 1.5(VLA)
输入:
- 图像 ot∈RH×W×3o_t\in\mathbb{R}^{H\times W\times 3}ot∈RH×W×3
- 语言指令 l∈Σ∗l\in\Sigma^*l∈Σ∗
- 本体感受 pt∈RPp_t\in\mathbb{R}^{P}pt∈RP(维度随机器人变化)
内部流程:
vt=Φenc(ot)∈RDvel=Ψenc(l)∈RDlτt=Θthink(vt,el,pt,ht−1)∈Σ∗(思考痕迹)at=Θact(vt,el,pt,τt)∈RA(连续动作)\begin{aligned} v_t &= \Phi_{\text{enc}}(o_t) \in\mathbb{R}^{D_v} \\ e_l &= \Psi_{\text{enc}}(l) \in\mathbb{R}^{D_l} \\ \tau_t &= \Theta_{\text{think}}(v_t,e_l,p_t,h_{t-1}) \in\Sigma^* \quad \text{(思考痕迹)} \\ a_t &= \Theta_{\text{act}}(v_t,e_l,p_t,\tau_t) \in\mathbb{R}^{A} \quad \text{(连续动作)} \end{aligned} vtelτtat=Φenc(ot)∈RDv=Ψenc(l)∈RDl=Θthink(vt,el,pt,ht−1)∈Σ∗(思考痕迹)=Θact(vt,el,pt,τt)∈RA(连续动作)
训练目标:
minθ∑i∑t[∥at(i)−a^t(i)∥2+λLlang(τt(i),τ^t(i))],λ=0.1\min_\theta \sum_i\sum_t \Bigl[\bigl\|a_t^{(i)}-\hat a_t^{(i)}\bigr\|^2 + \lambda\,\mathcal{L}_{\text{lang}}(\tau_t^{(i)},\hat\tau_t^{(i)})\Bigr], \quad \lambda=0.1 θmini∑t∑[at(i)−a^t(i)2+λLlang(τt(i),τ^t(i))],λ=0.1
GR-ER 1.5(VLM)
标准 next-token 交叉熵,但在 50% 数据里加入空间推理提示,例如:
“输出 10 个二维点,顺序组成无碰撞轨迹。”
2.2 运动迁移(MT)机制
设本体 A 动作空间 RAA\mathbb{R}^{A_A}RAA,本体 B 动作空间 RAB\mathbb{R}^{A_B}RAB,且 AA≠ABA_A\neq A_BAA=AB。引入共享潜空间 z∈RKz\in\mathbb{R}^{K}z∈RK,K=64K=64K=64。
对每个本体 iii 学习:
z=Ei(a(i))a~(i)=Di(z)\begin{aligned} z &= E_i(a^{(i)}) \\ \tilde a^{(i)} &= D_i(z) \end{aligned} za~(i)=Ei(a(i))=Di(z)
训练目标:
minEi,Di∑i∑t[∥at(i)−Di(Ei(at(i)))∥2+β∥zt∥2],β=0.01\min_{E_i,D_i} \sum_i\sum_t \Bigl[\bigl\|a_t^{(i)}-D_i(E_i(a_t^{(i)}))\bigr\|^2 + \beta\|z_t\|^2\Bigr], \quad \beta=0.01 Ei,Dimini∑t∑[at(i)−Di(Ei(at(i)))2+β∥zt∥2],β=0.01
VLA 主干在潜空间 zzz 上操作,同一条 zzz 序列可被任意 DiD_iDi 还原为对应本体的真实动作,实现零样本迁移。
2.3 数据
- 机器人数据:ALOHA 2、Franka Bi-arm、Apollo 人形,共 3.2 M 轨迹。
- 互联网数据:LAION-5B 图文对 + Something-Something v2 视频字幕 1.8 M 小时。
- 合成数据:Gemini 2.5 生成 12 M 条“伪动作”字幕,用于预训练视觉-语言对齐。
2.4 评估协议
- 真机 A/B/n:同一工作台交替运行,消除环境漂移。
- 模拟对齐:MuJoCo 场景与真机 RGB/深度/摩擦系数逐参数标定,Pearson r>0.95r>0.95r>0.95。
- 进度指标:
progress=∑kwk⋅1[subtaskk完成]\text{progress}=\sum_k w_k\cdot\mathbb{1}[\text{subtask}_k~\text{完成}] progress=k∑wk⋅1[subtaskk 完成]
成功率:
SR=1[progress=1]\text{SR}=\mathbb{1}[\text{progress}=1] SR=1[progress=1]
第三章 GR 1.5 通用多形态 VLA 实验
3.1 泛化四维评测
| 维度 | 扰动示例 | GR 1.5 相对增益 |
|---|---|---|
| 视觉 | 换桌布、加光照、换纹理 | +18% |
| 指令 | 同义句、错别字、西班牙语 | +22% |
| 动作 | 初始位置随机、新形状 | +15% |
| 任务 | 全新“把雨伞挂到墙上” | +12% |
3.2 跨本体迁移
零样本任务:Franka 数据 → ALOHA 真机测试。
成功率定义:
SR=成功次数30\text{SR}=\frac{\text{成功次数}}{30} SR=30成功次数
结果:
- 单本体训练:7%
- 多本体无 MT:21%
- 多本体+MT:39%
公式化:
SRA→B=Eπ∼GR1.5[1[TB完成]∣仅在DA训练]\text{SR}_{A\to B}=\mathbb{E}_{\pi\sim\text{GR1.5}}\Bigl[\mathbb{1}[T_B~\text{完成}]\Bigm| \text{仅在}D_A~\text{训练}\Bigr] SRA→B=Eπ∼GR1.5[1[TB 完成]仅在DA 训练]
MT 通过共享 zzz 空间使 SR\text{SR}SR 提升 18 个百分点。
3.3 思考模式消融
- 关闭思考:τt≡∅\tau_t\equiv\varnothingτt≡∅
- 开启思考:τt\tau_tτt 平均 32 tokens
多步任务进度分数:
- 关思考:0.44
- 开思考:0.67(+52%)
思考痕迹示例:
下一步:用左手拿水瓶;运动描述:左臂前移,手腕逆时针旋转 30°…
第四章 GR-ER 1.5 通用具身推理模型
4.1 通用-专用帕累托前沿
定义:
x轴 Generality=MMMU+GPQA+Aider3y轴 ER=空间推理×0.5+VQA×0.51\begin{aligned} x~\text{轴}~\text{Generality} &= \frac{\text{MMMU}+\text{GPQA}+\text{Aider}}{3} \\ y~\text{轴}~\text{ER} &= \frac{\text{空间推理}\times 0.5 + \text{VQA}\times 0.5}{1} \end{aligned} x 轴 Generalityy 轴 ER=3MMMU+GPQA+Aider=1空间推理×0.5+VQA×0.5
GR-ER 1.5 坐标 (73.8, 59.6),比 Gemini 2.5 Pro (83.5, 51.7) 在 y 轴高 8 个点,同时保持 x 轴 70%+ 通用能力。
4.2 复杂指向
基准公式:
给定图像 III 与文本查询 qqq,模型输出点集 {pi}i=1n\{p_i\}_{i=1}^n{pi}i=1n,pi∈[0,1]2p_i\in[0,1]^2pi∈[0,1]2。
精度:
Acc=1n∑i=1n1[pi∈GTi]\text{Acc}=\frac{1}{n}\sum_{i=1}^n \mathbb{1}[p_i\in\text{GT}_i] Acc=n1i=1∑n1[pi∈GTi]
GR-ER 1.5 在 Point-Bench-Spatial 得 71.0,超 GPT-5(35.4)一倍。
4.3 思考缩放律
令思考 token 预算 T∈[0,1024]T\in[0,1024]T∈[0,1024]。
拟合曲线:
ER(T)=ER0+αlog(1+T/T0),α=2.3\text{ER}(T)=\text{ER}_0+\alpha\log(1+T/T_0), \quad \alpha=2.3 ER(T)=ER0+αlog(1+T/T0),α=2.3
远大于 Gemini 2.5 Flash 的 0.7,说明 GR-ER 1.5 更会把额外算力转化为具身推理性能。
第五章 完整智能体系统
任务示例:Pack Suitcase
高层规划(GR-ER 1.5):
- 查天气 API → “伦敦未来 3 天有雨”
- 生成计划:
- 把雨衣从衣架取下 → GR 1.5 执行
- 折叠雨衣 → GR 1.5 执行
- 放入行李箱 → GR 1.5 执行
进度分数:
progress=∑k=140.25⋅1[subtaskk完成]\text{progress}=\sum_{k=1}^4 0.25\cdot\mathbb{1}[\text{subtask}_k~\text{完成}] progress=k=1∑40.25⋅1[subtaskk 完成]
实验结果:
- 纯 VLA(思考开):0.40
- Gemini 2.5 Flash + VLA:0.60
- GR-ER 1.5 + VLA:0.88
失败分析:
规划错误率从 25.5% 降到 9%,主要因为 ER 模型能正确理解“雨衣”与“折叠”之间的物理前提。
第六章 安全与责任
6.1 语义安全
ASIMOV-2.0 基准风险分数:
R=∑jwj⋅1[模型输出违反约束 j]R=\sum_j w_j\cdot\mathbb{1}[\text{模型输出违反约束}~j] R=j∑wj⋅1[模型输出违反约束 j]
约束示例:单臂最大负载 10 kg,若输出指向 15 kg 物体,则 R+=1R\mathrel{+}=1R+=1。
GR-ER 1.5 经过安全微调后 RRR 从 0.31 降到 0.08。
6.2 自动红队
三模型博弈:
- 攻击者 AAA:给定场景 SSS,生成对抗指令 qadvq_{\text{adv}}qadv 使目标模型 TTT 犯错。
- 目标 TTT:输出响应 yyy。
- 评分器 CCC:若 yyy 不安全,返回奖励 +1+1+1 给 AAA,否则 −1-1−1。
用强化训练迭代 AAA,发现 TTT 的漏洞并加入黑名单数据。
第七章 讨论与未来方向
- 数据扩展:下一步用人类日常视频(Ego4D 等)+ 合成 VEO 视频,无需动作标注,直接做自监督预训练。
- 灵巧度提升:当前夹爪成功率 92%,但“单手系鞋带”类任务仅 11%。未来引入 RL 微调阶段,奖励函数:
r=1[task 成功]−0.01×能耗−0.1×时间r=\mathbb{1}[\text{task 成功}]-0.01\times\text{能耗}-0.1\times\text{时间} r=1[task 成功]−0.01×能耗−0.1×时间
在共享 zzz 空间上做策略梯度,保持通用表示不变。
附录关键公式速查
- 进度分数(通用定义):
progress=∑k=1Kwk⋅1[subtaskk完成]\text{progress}=\sum_{k=1}^K w_k\cdot\mathbb{1}[\text{subtask}_k~\text{完成}] progress=k=1∑Kwk⋅1[subtaskk 完成] - 跨本体迁移成功率:
SRA→B=Eπ[1[TB完成]∣仅在DA训练]\text{SR}_{A\to B}=\mathbb{E}_{\pi}\Bigl[\mathbb{1}[T_B~\text{完成}]\Bigm| \text{仅在}D_A~\text{训练}\Bigr] SRA→B=Eπ[1[TB 完成]仅在DA 训练] - 思考痕迹生成概率:
P(τt∣ht)=softmax(Wthink⋅[vt;el;pt;ht−1]+bthink)P(\tau_t\mid h_t)=\text{softmax}(W_{\text{think}}\cdot[v_t;e_l;p_t;h_{t-1}]+b_{\text{think}}) P(τt∣ht)=softmax(Wthink⋅[vt;el;pt;ht−1]+bthink)