浏览器书签脚本(书签小程序)学习
背景:刷课时发现视频无法自动连播,需要手动调整,很麻烦
发现对于 URL 包含序号参数(如https://xxx.cn/study/0/381/24770992)的视频页面,实现自动连播的核心是识别参数规律并在视频结束时自动跳转。
我的课程是最后一段数字是视频 ID,每次 + 1。
浏览器书签脚本(简单快捷)
外观: 它看起来和普通书签一样,在你的书签栏上有一个标题和一个图标。
本质: 它的网址(URL)不是以
http://或http://开头,而是以javascript:开头。后面跟着一段可执行的JavaScript代码。工作原理: 当你点击这个书签时,浏览器不会跳转到新页面,而是会把你当前正在浏览的网页作为“沙盒”,在这片“沙盒”里运行那段JavaScript代码。
书签脚本的主要用途
书签脚本的用途非常广泛,以下是一些常见的例子:
网页调试与开发:
显示所有元素的边框,方便查看布局。
一键清除页面上的所有Cookie和本地存储。
将页面切换到响应式设计预览模式。
内容提取与处理:
一键去除页面广告和浮动元素,获得干净的阅读视图。
提取页面上的所有链接、图片或电子邮件地址。
将文章内容发送到Kindle或稍后读应用(如Pocket)。
界面增强:
为没有暗色模式的网站强制启用暗色主题。
调整页面的字体和行距,使其更易于阅读。
自动展开被折叠的评论区或“”内容。
实用工具:
生成当前页面的二维码,方便在手机上浏览。
将选中的文本直接翻译成其他语言。
快速进行搜索引擎切换(如在Google和百度之间切换当前搜索关键词)。
如何创建和使用?
在浏览器中打开书签管理器。(通常是按
Ctrl+Shift+O或Cmd+Shift+O)
添加一个新书签。
在“名称”字段中,填写一个你容易识别的名字,例如“视频自动连播”。
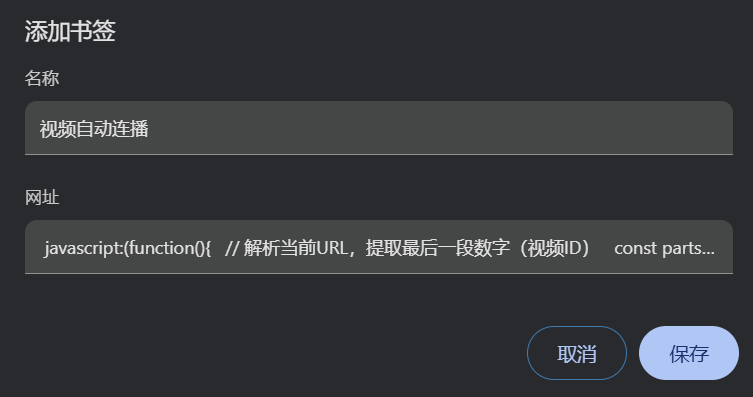
4.在“网址”或“URL”字段中,粘贴完整的以 javascript: 开头的代码。
javascript:(function(){// 解析当前URL,提取最后一段数字(视频ID)const parts = window.location.href.split('/');const lastPart = parts[parts.length - 1];const currentId = parseInt(lastPart);if (!isNaN(currentId)) {// 计算下一个视频ID(根据实际规律调整,这里假设+1)const nextId = currentId + 1;// 替换URL中的ID并跳转parts[parts.length - 1] = nextId;const nextUrl = parts.join('/');// 延迟3秒跳转(预留视频结束缓冲时间,可调整)setTimeout(() => window.location.href = nextUrl, 3000);} else {alert('未识别到视频序号参数');}
})();问题: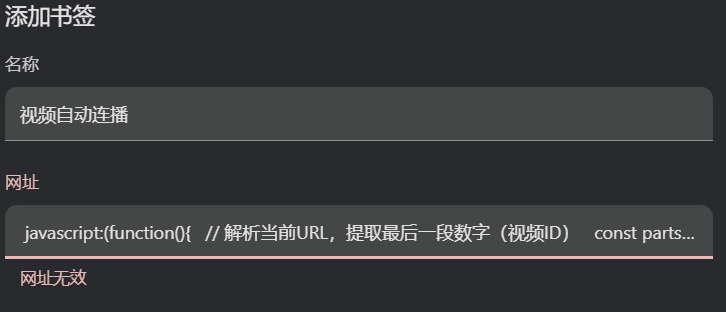
原因:浏览器对书签中 JavaScript 代码的格式要求比较严格,需要确保代码是一个完整、紧凑的 JavaScript 语句,不能有多余的注释、换行等影响格式的内容。
把之前的代码进行压缩,去除不必要的注释和换行,确保代码是连续的。比如将代码修改为:
javascript:(function(){const parts=window.location.href.split('/');const lastPart=parts[parts.length-1];const currentId=parseInt(lastPart);if(!isNaN(currentId)){const nextId=currentId+1;parts[parts.length-1]=nextId;const nextUrl=parts.join('/');setTimeout(()=>window.location.href=nextUrl,3000);}else{alert('未识别到视频序号参数');}})();
5.保存,然后将这个新书签拖到书签栏上方便点击的位置。

bug:
一运行代码就从24770992 跳到本页面第一个视频24770884

问题分析与解决方案
为什么从 24770992 跳到了 24770884?
根本原因在于你的代码逻辑的一个关键假设是错误的。
假设:代码假设视频ID是连续递增的,即下一个视频的ID严格等于当前视频ID + 1。
现实:在你使用的这个网站上,视频ID并不是连续排列的。
从 24770992 到 24770884,ID实际上是减小了,而且跳跃幅度很大。这说明视频ID的生成可能依赖于数据库的自增主键、时间戳或其他复杂逻辑,它们在线性顺序上是不连续的。
因此,当你试图访问一个不存在的 24770993 页面时,网站服务器可能没有返回404错误,而是执行了某种默认的重定向逻辑,比如:
跳转到课程的第一个视频(
24770884)。跳转到课程的介绍页面。
跳转到404页面。
方案:如果网站有播放列表API(进阶)
如果是比较规范的网站,可能会通过API加载播放列表。你可以尝试在开发者工具的 Network(网络)面板中查找包含播放列表的请求,然后编写代码来解析它,找到当前视频在列表中的位置,然后获取下一个视频的URL。这种方法更复杂,但也更强大和精确。
网络请求列表中,寻找包含以下关键词的请求:
listcoursechapterplaylistcurriculummenu
重点关注类型为
XHR或Fetch的请求。点击这些请求,在 Preview 或 Response 标签页中查看返回的数据,确认是否包含视频列表。
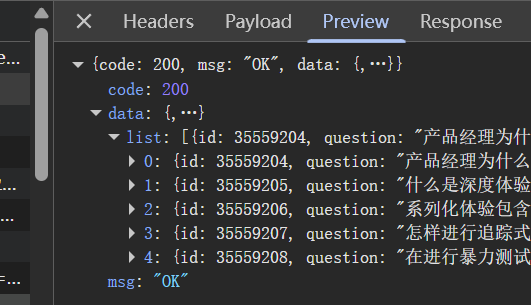
分析API响应:
找到包含视频数组的API,数据结构通常如下:
json
{"data": {"sections": [{"lessons": [{"id": 24770884, "title": "第一章", "url": "/course/0/381/24770884"},{"id": 24770992, "title": "第二章", "url": "/course/0/381/24770992"},{"id": 24771015, "title": "第三章", "url": "/course/0/381/24771015"}]}]}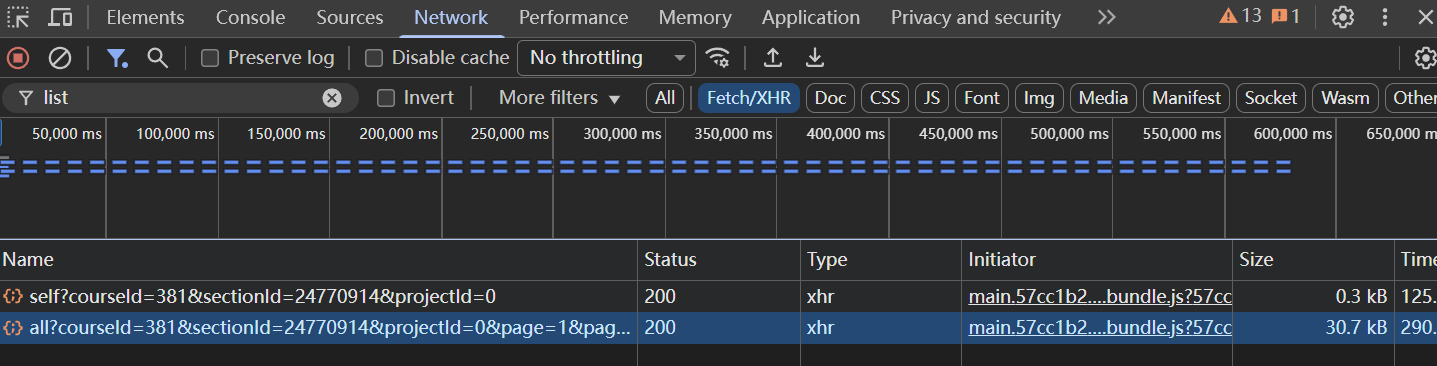
第二步:获取API详细信息
当你找到正确的API后:
复制API地址:
在 Headers 标签页中,找到
Request URL,这就是API端点。
查看请求方法:
通常是
GET或POST。
查看必要的请求头:
有些API需要认证,检查
Headers中的Authorization、Cookie等。
第三步:编写智能连播脚本
基于找到的API信息,这里是一个通用模板:
javascript: (function() {// 配置区:根据你找到的API信息修改这里const API_URL = 'https://api.example.com/course/381/lessons'; // 替换为实际的API URLconst REQUEST_METHOD = 'GET'; // 或 'POST'const NEED_AUTH = true; // 如果API需要认证就设为true// 获取当前页面URL用于匹配const currentUrl = window.location.href;// 显示加载状态const loadingMsg = document.createElement('div');loadingMsg.style.cssText = 'position:fixed; top:20px; right:20px; background:#000; color:#fff; padding:10px; z-index:9999;';loadingMsg.textContent = '📡 获取播放列表中...';document.body.appendChild(loadingMsg);// 准备请求配置const requestConfig = {method: REQUEST_METHOD,headers: {'Content-Type': 'application/json'}};// 如果需要认证,添加认证头if (NEED_AUTH) {// 这里会自动使用当前登录状态的cookie}// 调用API获取播放列表fetch(API_URL, requestConfig).then(response => {if (!response.ok) {throw new Error(`API请求失败: ${response.status}`);}return response.json();}).then(data => {loadingMsg.textContent = '✅ 列表获取成功,解析中...';// 解析函数 - 需要根据实际的API响应结构进行调整function parseVideoList(data) {// 示例1:扁平化结构if (data.data && Array.isArray(data.data.lessons)) {return data.data.lessons;}// 示例2:嵌套章节结构if (data.data && Array.isArray(data.data.sections)) {const allLessons = [];data.data.sections.forEach(section => {if (section.lessons && Array.isArray(section.lessons)) {allLessons.push(...section.lessons);}});return allLessons;}// 示例3:直接数组if (Array.isArray(data.lessons)) {return data.lessons;}throw new Error('无法解析播放列表结构');}const videoList = parseVideoList(data);// 在当前列表中查找当前视频const findCurrentVideo = () => {// 方法1:通过URL匹配for (let i = 0; i < videoList.length; i++) {if (videoList[i].url && currentUrl.includes(videoList[i].url)) {return i;}}// 方法2:通过ID匹配(需要从当前URL提取ID)const currentId = currentUrl.split('/').pop();for (let i = 0; i < videoList.length; i++) {if (videoList[i].id == currentId || (videoList[i].url && videoList[i].url.includes(currentId))) {return i;}}return -1;};const currentIndex = findCurrentVideo();if (currentIndex === -1) {loadingMsg.textContent = '❌ 未在当前课程中找到本视频';setTimeout(() => loadingMsg.remove(), 3000);return;}// 检查是否有下一个视频if (currentIndex < videoList.length - 1) {const nextVideo = videoList[currentIndex + 1];loadingMsg.textContent = `⏭️ 3秒后跳转到: ${nextVideo.title || '下一节'}`;// 3秒后跳转setTimeout(() => {let nextUrl = nextVideo.url || nextVideo.link;// 确保URL是完整的if (nextUrl && !nextUrl.startsWith('http')) {const baseUrl = window.location.origin;nextUrl = baseUrl + (nextUrl.startsWith('/') ? '' : '/') + nextUrl;}if (nextUrl) {window.location.href = nextUrl;} else {loadingMsg.textContent = '❌ 无法获取下一视频链接';setTimeout(() => loadingMsg.remove(), 3000);}}, 3000);} else {loadingMsg.textContent = '🎉 已经是最后一节课程了!';setTimeout(() => loadingMsg.remove(), 3000);}}).catch(error => {console.error('错误:', error);loadingMsg.textContent = `❌ 错误: ${error.message}`;setTimeout(() => loadingMsg.remove(), 5000);});
})();配置说明
修改API_URL:替换成你找到的实际API地址
调整parseVideoList函数:根据API实际返回的数据结构修改解析逻辑
设置NEED_AUTH:如果API需要登录,设为true
调整findCurrentVideo逻辑:确保能准确匹配当前视频
最后:智能探测方案部分视频成功
大部分失败 放弃了