【组队学习】Post-training-of-LLMs TASK02
文章目录
- 语言模型的监督式微调
- SFT的最佳使用场景
- SFT数据策划原则
- Code
- Setting up helper functions
- Load base model & test on simple questions
- SFT results on Qwen3-0.6B model
- Doing SFT on a small model
- Testing training results on small model and small dataset
语言模型的监督式微调
监督式微调(Supervised Fine‑Tuning, SFT)是一种把通用语言模型转换成任务型助手的方法。
通过训练提示与理想回应的成对数据,模型学会模仿示例中的回答,从而能够按照指令行事、展示期望的行为并正确调用工具。
SFT 的核心是让基础模型(只根据提示预测下一个 token)学会生成预期的回答,流程如下:
- 基础模型:未经调整的 LLM 往往会给出泛泛或重复的回应,例如面对“你是谁?”这样的询问,它可能只是反问一句,而不是回答。
- 带标签的数据集:收集并整理用户提示与理想助理回应的配对,例如“请告诉我你的身份——我是 Llama…”、“你最近怎么样?——我很好!”。
- SFT 训练:对这些配对进行微调,通过最小化回应的交叉熵损失来训练模型:
为什么通过交叉损失熵训练模型:
L S F T = − ∑ i = 1 N l o g ( p θ ( R e s p o n s e ( i ) ∣ P r o m p t ( i ) ) ) L_{SFT} = -\sum^{N}_{i=1} log(p_\theta(Response(i) | Prompt(i))) LSFT=−∑i=1Nlog(pθ(Response(i)∣Prompt(i)))
这一损失鼓励模型最大化在每个提示条件下生成目标回应的概率。
- 微调后的模型:完成训练后,模型可以针对新的查询给出合适的回复(例如向用户问好,而不是简单重复问题)
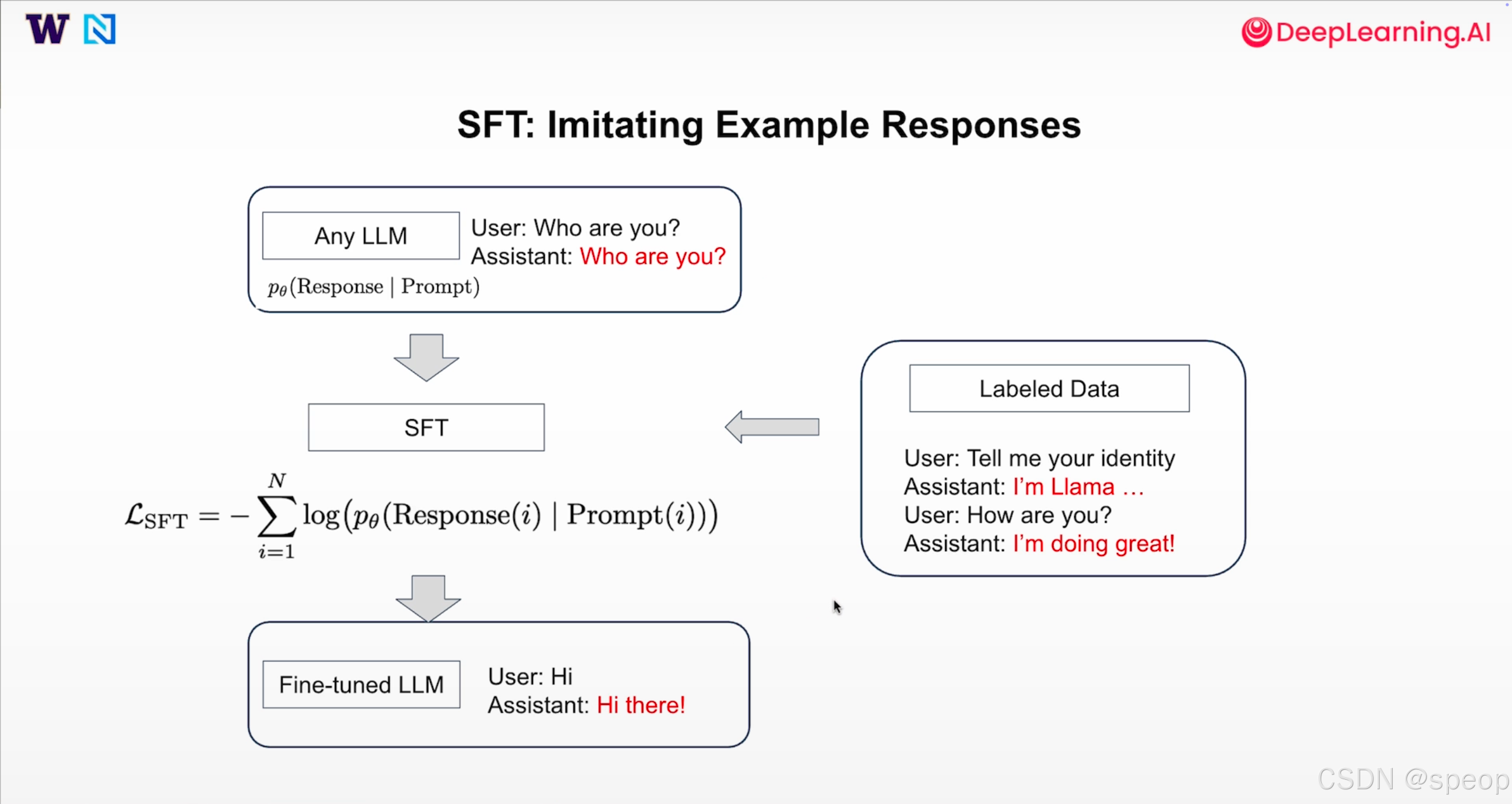
上面的公式也可以理解为最大化在提示条件下回应中所有 token 的联合概率。交叉熵损失会惩罚偏离标签回应的输出,因此 SFT 本质上是在教模型“模仿”。
SFT的最佳使用场景
-
激发新的模型行为:
- 将预训练模型转变为能遵循指令的助理
- 让不具备推理能力的模型学会基本推理
- 让模型在没有明确说明的情况下使用特定的工具
-
提升模型能力
- 利用强大的大模型生成高质量的合成数据,通过训练把这些能力蒸馏到小模型中。

这些例子显示了 SFT 作为预训练和更高级对齐方法之间的桥梁作用。当你需要模型快速适应新行为且有示例数据时,SFT 往往是正确的选择。
SFT数据策划原则
SFT 的效果高度依赖于数据质量。优质且多样的样本能让模型学到有用的行为;劣质样本则会让模型模仿不良习惯。常用的数据策划方法包括:
- 蒸馏:用更强的指令模型生成回复,再训练小模型去模仿这些回复,把强模型的能力迁移到弱模型上。
- Best‑of‑K / 拒绝采样:针对同一提示生成多个候选回复,再用奖励函数选出最好的作为训练数据。
- 过滤:从大型 SFT 数据集中挑选出回应质量高且提示多样性好的样本,形成精简的高质量数据集。
这里的核心是“质量比数量重要”。一千条精心挑选、题材丰富的样本往往比一百万条参差不齐的数据效果更好,因为 SFT 会迫使模型模仿它所见到的一切——包括糟糕的回答。
全参数微调 vs 参数高效微调
在执行 SFT(或其他对齐方法)时,需要决定如何更新模型权重:
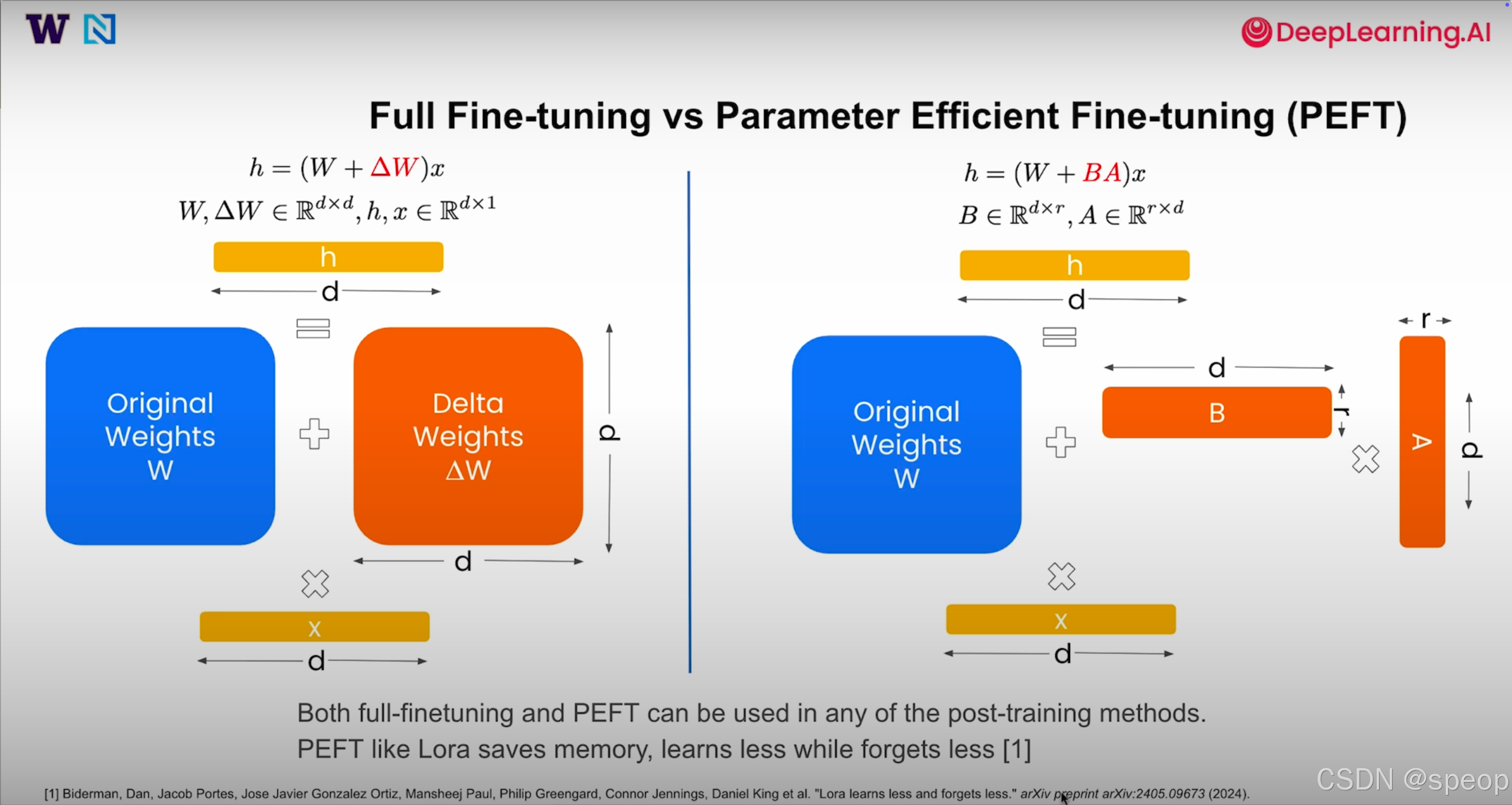
- 全参数微调:对每一层加入一个完整的权重更新矩阵ΔW,即修改所有参数。这可以显著提升性能,但需要大量存储和计算资源。
- 参数高效微调:例如 LoRA(低秩适配)通过在每层引入小的低秩矩阵 A 和 B 来调整模型参数。这减少了可训练参数的数量,节省显存,缺点是学习和遗忘都更有限,因为更新的参数更少。
这两种策略可以与任何训练方法结合。根据资源约束和性能要求,你可以选择全微调或参数高效微调。后者在硬件条件有限的情况下尤为受欢迎。
总结:
监督式微调是语言模型对齐的重要基础方法。
它通过最小化目标回复的负对数似然,使模型学会模仿期望的行为并在面对提示时做出合适回应。
SFT 特别适合用于启动新行为和从大模型向小模型“蒸馏”能力。然而,数据质量至关重要:蒸馏、拒绝采样和过滤等策略能显著胜过简单堆积大量普通数据。全参数与参数高效微调之间的选择则是性能和资源之间的权衡。
Code
import torch
import pandas as pd
from datasets import load_dataset, Dataset
from transformers import TrainingArguments, AutoTokenizer, AutoModelForCausalLM
from trl import SFTTrainer, DataCollatorForCompletionOnlyLM, SFTConfigSetting up helper functions
#生成模型对用户输入信息的响应,通过tokenizer的chat template 格式化输入,调用模型生成回复
def generate_responses(model, tokenizer, user_message, system_message=None, max_new_tokens=100):#model :预训练的语言模型#tokenizer:与模型配套的分词器,用于处理输入和输出文本#user_message:用户输入的消息(字符串)#system_message:可选的系统消息,用于设置模型的上下文或角色(默认None)#max_new_tokens:生成的最大新token数量(默认100)# 返回 模型生成的相应(字符串)——# Format chat using tokenizer's chat templatemessages = []if system_message:messages.append({"role": "system", "content": system_message})# We assume the data are all single-turn conversationmessages.append({"role": "user", "content": user_message})prompt = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=False,)#格式化输入,支持系统消息和用户消息inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
#编码成pytorch张量,并且移动到模型所在的设备
#使用推荐的生成方式(vllm,sglang或TensorRT)这里使用标准PyTorch# Recommended to use vllm, sglang or TensorRT#使用推荐生成方式vllm,sglang,TensorRT,这里使用标准PyTorchwith torch.no_grad():#生成响应,设置最大新token数量,禁用采样、指定填充和结束tokenoutputs = model.generate(**inputs,max_new_tokens=max_new_tokens,do_sample=False,pad_token_id=tokenizer.eos_token_id,eos_token_id=tokenizer.eos_token_id,)#使用model.generate生成响应,设置了do_sample=False禁用采样,使用确定性生成以及填充和结束token#获取输入token的长度,仅解码生成的部分。 input_len = inputs["input_ids"].shape[1]generated_ids = outputs[0][input_len:]#解码生成的token,跳过特殊token并去除多余空格response = tokenizer.decode(generated_ids, skip_special_tokens=True).strip()return responsedef test_model_with_questions(model, tokenizer, questions, system_message=None, title="Model Output"):
#功能:测试模型在给定问题列表上的表现,逐一生成并打印每个问题的响应#输入
#model:预训练或微调后的语言模型
#tokenizer:与模型配套的分词器
#questions:包含测试问题(字符串)的列表
#system_message:可选的系统消息
#title 测试输出的标题#输出
#无返回值,直接打印每个问题的输入和模型生成的响应。#关键点
#遍历问题列表,调用generate_response函数生成每个问题的响应
#格式化输出,清晰展示每个问题的输入输出。print(f"\n=== {title} ===")for i, question in enumerate(questions, 1):response = generate_responses(model, tokenizer, question, system_message)print(f"\nModel Input {i}:\n{question}\nModel Output {i}:\n{response}\n")
def load_model_and_tokenizer(model_name, use_gpu = False):#加载预训练模型和分词器,并进行必要的配置#model_name:模型的路径或huggingface模型名称#use_gpu:是否将模型加载到GPU(默认False,使用CPU)# Load base model and tokenizer#关键点:#使用HuggingFace的AutoTokenizer和AutoModelForCausalLM加载模型和分词器tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name)if use_gpu:model.to("cuda")#如果分词器没有chat_template,设置默认模板if not tokenizer.chat_template:tokenizer.chat_template = """{% for message in messages %}{% if message['role'] == 'system' %}System: {{ message['content'] }}\n{% elif message['role'] == 'user' %}User: {{ message['content'] }}\n{% elif message['role'] == 'assistant' %}Assistant: {{ message['content'] }} <|endoftext|>{% endif %}{% endfor %}"""# Tokenizer config#分词器配置:如果没有pad token,设置为eos tokenif not tokenizer.pad_token:tokenizer.pad_token = tokenizer.eos_tokenreturn model, tokenizerdef display_dataset(dataset):# Visualize the dataset #可视化数据集的前三条记录,展示用户提示和助手响应的表格#dataset: Hugging Face 的 Dataset 对象,包含 messages 字段(每条记录包含系统、用户和助手消息)。#输出#无返回值,使用pandas显示一个表格,包含用户提示和助手响应#关键点#从数据集中提取前三条记录的用户消息和助手消息。 #使用 pandas 创建表格并设置显示选项以避免截断长字符串。#通过 display 函数展示表格(适用于 Jupyter 环境)。rows = []for i in range(3):example = dataset[i]user_msg = next(m['content'] for m in example['messages']if m['role'] == 'user')assistant_msg = next(m['content'] for m in example['messages']if m['role'] == 'assistant')rows.append({'User Prompt': user_msg,'Assistant Response': assistant_msg})# Display as tabledf = pd.DataFrame(rows)pd.set_option('display.max_colwidth', None) # Avoid truncating long stringsdisplay(df)
Load base model & test on simple questions
USE_GPU = False
#设置 USE_GPU=False,默认使用 CPU。
#定义三个测试问题,覆盖不同任务(介绍、计算、概念解释)。
#使用 load_model_and_tokenizer 加载模型和分词器。
#调用 test_model_with_questions 测试并打印结果。
#测试完成后删除模型和分词器以释放内存。# 定义测试问题列表
questions = ["Give me an 1-sentence introduction of LLM.","Calculate 1+1-1","What's the difference between thread and process?"
]
# 加载 Qwen3-0.6B 基础模型和分词器
model, tokenizer = load_model_and_tokenizer("./models/Qwen/Qwen3-0.6B-Base", USE_GPU)
# 测试基础模型在问题列表上的表现
test_model_with_questions(model, tokenizer, questions, title="Base Model (Before SFT) Output")
# 删除模型和分词器以释放内存
del model, tokenizer
SFT results on Qwen3-0.6B model
在小模型上进行SFT
In this section, we’re reviewing the results of a previously completed SFT training. Due to limited resources, we won’t be running the full training on a relatively large model like Qwen3-0.6B. However, in the next section of this notebook, you’ll walk through the full training process
model, tokenizer = load_model_and_tokenizer("./models/banghua/Qwen3-0.6B-SFT", USE_GPU)test_model_with_questions(model, tokenizer, questions, title="Base Model (After SFT) Output")del model, tokenizer
Doing SFT on a small model
using a smaller model and a lightweight dataset.
- 加载小型模型和分词器。
- 加载 banghua/DL-SFT-Dataset 数据集,若不使用 GPU,仅使用前 100 条数据以减少计算需求。
- 调用 display_dataset 可视化数据集前三条记录。
- 配置 SFTConfig 参数,包括学习率、训练轮数、批大小等。
- 使用 SFTTrainer 执行微调训练。
# 加载小型模型 SmolLM2-135M
model_name = "./models/HuggingFaceTB/SmolLM2-135M"
model, tokenizer = load_model_and_tokenizer(model_name, USE_GPU)
# 加载 SFT 训练数据集
train_dataset = load_dataset("banghua/DL-SFT-Dataset")["train"]
# 如果不使用 GPU,仅使用前 100 条数据
if not USE_GPU:train_dataset=train_dataset.select(range(100))
# 可视化数据集前三条记录
display_dataset(train_dataset)
# SFTTrainer config
# 配置 SFTTrainer 参数
sft_config = SFTConfig(learning_rate=8e-5, # 训练学习率num_train_epochs=1, # 训练轮数per_device_train_batch_size=1, # 每设备批大小gradient_accumulation_steps=8,# 梯度累积步数gradient_checkpointing=False, # 是否启用梯度检查点(节省内存)logging_steps=2, # Frequency of logging training progress (log every 2 steps). # 日志记录频率(每 2 步记录一次)
))# 初始化 SFTTrainer 并进行训练
sft_trainer = SFTTrainer(model=model,args=sft_config,train_dataset=train_dataset, processing_class=tokenizer,
)
sft_trainer.train()
Testing training results on small model and small dataset
# 如果不使用 GPU,将模型移动到 CPU
if not USE_GPU: # move model to CPU when GPU isn’t requestedsft_trainer.model.to("cpu")
test_model_with_questions(sft_trainer.model, tokenizer, questions, title="Base Model (After SFT) Output")
# 测试微调后小型模型在问题列表上的表现