
背景需求
开学周,为了看护托、小班新生安全,总园中大班老师会到分园各班“大带小”。
放学时孩子走光了,总部中班组长看到我就说:“我还想要你以前做的那个破译电话号码,就是家长号码都不同的”
我很高兴她提出的需求:“那我去闵豆家园上把中3班的家长手机号提取出来”。
数据提取
上一次批量用UIBOT批量提取闵豆手机号,但是最后发现识别起来有错误(9变成0,6变成b)所以这次复制整个页面上的幼儿姓名、几个手机号码到Deepseek,让它做出学号、姓名、爸妈手机号。
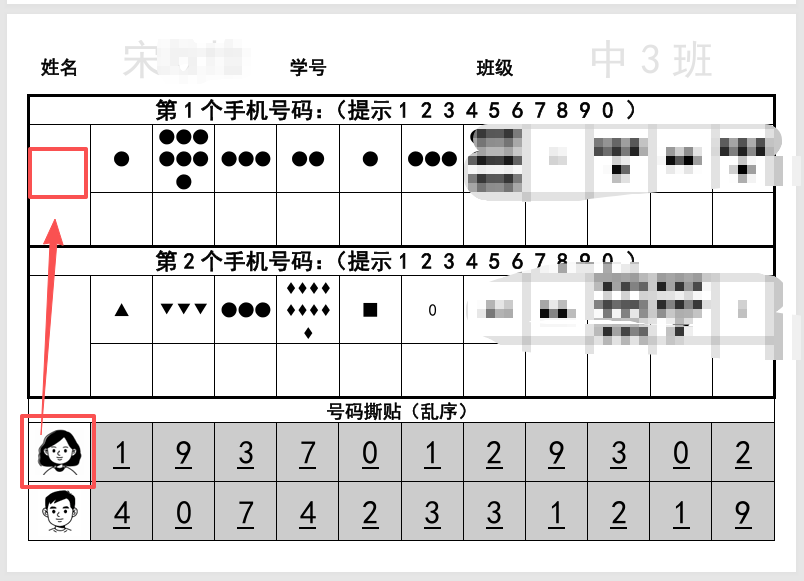
做出来的格式和闵豆家园网页上的一样
但是我只要两个电话,而且希望一个孩子一行(爸妈号码放在一行上)
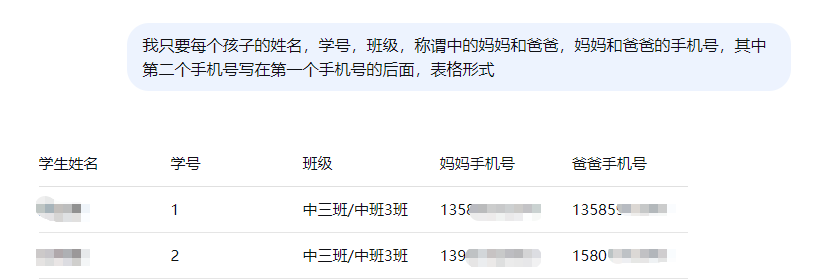
它快速写出了我想要的样式(但是不太安全,所以还是要想办法非网络提取)
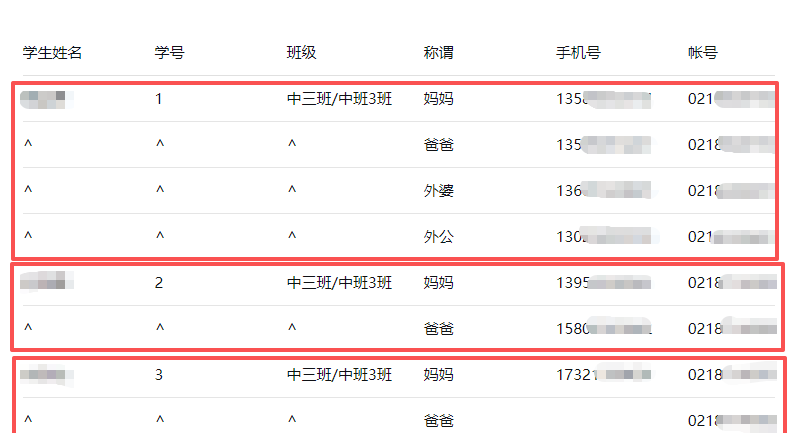
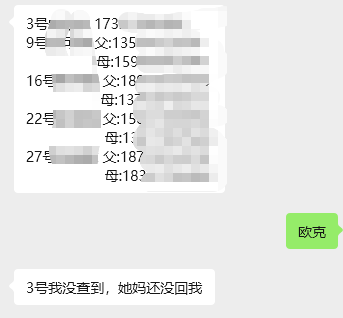
一个班级的家长的表格
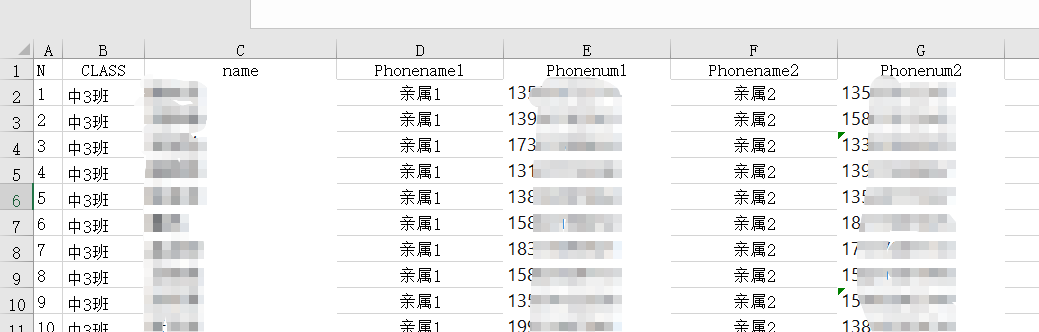
部分家长只留了一个手机号码,我就复制了一份变成第二个号码
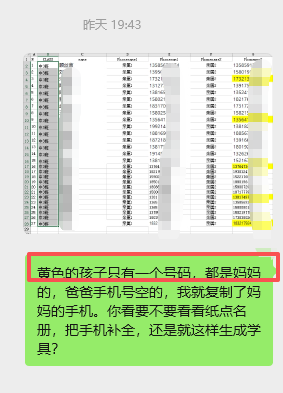
组长很认真,当晚就把两个号码收集到了
看来她很需要这份学具,所以我也用心把代码找出来重新修正。
分类代码
考虑中班幼儿年龄特点,我把这四个代码进行制作



一、破译电话号码——手写数字+图案+设计题目__名字和班级
'''
作者:阿夏
时间:2024年10月10日 破译电话号码-图形版-名字和班级(不需要分列,直接导入word)
'''
import openpyxl
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
import os,timeclassroom=input('班级名称(如大1)\n')path=r'C:\Users\jg2yXRZ\OneDrive\桌面\20250908破译电话号码'
print('----------第2步:新建一个临时文件夹------------')
# 新建一个”装N份word和PDF“的文件夹
ten_path=path+r'\零时Word'
os.makedirs(ten_path,exist_ok=True)print('------------读取excle表单--------------')
wb = openpyxl.load_workbook(path+r'\家长电话号码.xlsx')# wb=用openpyxl打开存有号码的ExcelEx
phone = wb.active #phone=获取wb里面的数据print('------------读取 爸爸的手机号--------------')
symbol_1=['●','●','●', '●', '●', '●','●', '●','●','●','●']
father=[]
for i in list(phone.columns)[4][1:]:# 第3列是爸爸的手机号 phonestr = str(i.value)# 电话字符串 = 第二列的数字的值的字符串形式print(phonestr)# 打印电话字符串
# # Phonenum1
# # 13512345678
# # 16556345690
# # 13724680156
# print('------------ 爸爸的手机号的数字全部写在一起--------------')# for i in phonestr:col = 0 # for _ in phonestr:# 在电话字符串里面循环遍历 取各种数字if i.value!= 'Phonenum1':# 如果电话号码的值不等于'dad' 不要第一行C1if int(_) != 0:# 如果取出的数字不等于0 等于1-9str_temp = int(_) * symbol_1[col] # 结果等于 取出的数字的整数 乘以 符号列表的相应列数的符号(批量几个符号)else:# 如果取出的数字=于0str_temp = '0'# 0=零# print( str_temp)father.append(str_temp) col +=1
print(father)
# # ['●', '●●●', '●●●●●', '●', '●●', '●●●', '●●●●', '●●●●●', '●●●●●●', '●●●●●●●', '●●●●●●●●', '●', '●●●●●●', '●●●●●', '●●●●●', '●●●●●●', '●●●', '●●●●', '●●●●●', '●●●●●●', '●●●●●●●●●', '零', '●', '●●●', '●●●●●●●', '●●', '●●●●', '●●●●●●', '●●●●●●●●', '零', '●', '●●●●●', '●●●●●●']print('------------读取 妈妈的手机号--------------')
mother=[]
symbol_2 = ['▲','▼','●','♦','■','▶','◀','◣','◥','◤','◢']#
for j in list(phone.columns)[6][1:]:phonestr = str(j.value)print(phonestr)# Phonenum2# 13214562358# 15615617891# 13123568210print('------------ 妈妈的手机号的数字全部写在一起--------------')col = 0 # 第一个字符串的起始列 123数下去 mum电话的第一位数在第O列=15列for _ in phonestr:if j.value != 'Phonenum2':if int(_) != 0:str_temp = int(_) * symbol_2[col] else:str_temp = '0'mother.append(str_temp) col +=1
print(mother)
# ['▲', '▼▼▼', '●●', '♦', '■■■■', '▶▶▶▶▶', '◀◀◀◀◀◀', '◣◣', '◥◥◥', '◤◤◤◤◤', '◢◢◢◢◢◢◢◢', '▲', '▼▼▼▼▼', '●●●●●●', '♦', '■■■■■', '▶▶▶▶▶▶', '◀', '◣◣◣◣◣◣◣', '◥◥◥◥◥◥◥◥', '◤◤◤◤◤◤◤◤◤', '◢', '▲', '▼▼▼', '●', '♦♦', '■■■', '▶▶▶▶▶', '◀◀◀◀◀◀', '◣◣◣◣◣◣◣◣', '◥◥', '◤', '零']print('------------ 爸爸的手机号拆开成11个一组的列表--------------')
father_all=[]
for i in range(0,int(len(father)/11)):b=father[i*11:i*11+11]father_all.append(b)
print(father_all)
# [['●', '●●●', '●●●●●', '●', '●●', '●●●', '●●●●', '●●●●●', '●●●●●●', '●●●●●●●', '●●●●●●●●'], # ['●', '●●●●●●', '●●●●●', '●●●●●', '●●●●●●', '●●●', '●●●●', '●●●●●', '●●●●●●', '●●●●●●●●●', '零'],['●', '●●●', '●●●●●●●', '●●', '●●●●', '●●●●●●', '●●●●●●●●', '零', '●', '●●●●●', '●●●●●●']]print('------------ 妈妈的手机号拆开成11个一组的列表--------------')
mother_all=[]
for i in range(0,int(len(mother)/11)):b=mother[i*11:i*11+11]mother_all.append(b)
print(mother_all)
# [['▲', '▼▼▼', '●●', '♦', '■■■■', '▶▶▶▶▶', '◀◀◀◀◀◀', '◣◣', '◥◥◥', '◤◤◤◤◤', '◢◢◢◢◢◢◢◢'],
# ['▲', '▼▼▼▼▼', '●●●●●●', '♦', '■■■■■', '▶▶▶▶▶▶', '◀', '◣◣◣◣◣◣◣', '◥◥◥◥◥◥◥◥', '◤◤◤◤◤◤◤◤◤', '◢'],
# ['▲', '▼▼▼', '●', '♦♦', '■■■', '▶▶▶▶▶', '◀◀◀◀◀◀', '◣◣◣◣◣◣◣◣', '◥◥', '◤', '零']]print('------------读取 学号或者姓名--------------')
N=[]
for i in list(phone.columns)[2]:# 学号-0 班级1 姓名2 phonestr = str(i.value)# 电话字符串 = 第二列的数字的值的字符串形式N.append(phonestr)
print(N)# ['N', '1', '11', '24']print('------------读取 班级--------------')
C=[]
for i in list(phone.columns)[1]:# 班级 phonestr = str(i.value)# C.append(phonestr)
print(C)#['CLASS', '大七班', '大七班', '大七班'] print('------------ 数据导入word,字体设置--------------')
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColorfor y in range(0,int(len(father)/11)): doc = Document(path+r'\破译电话号码模板(图案).docx') wb = pd.read_excel(path+r'\家长电话号码.xlsx') table = doc.tables[0] print('------------学号\班级写入,字体设置--------------')n=N[y+1]run=table.cell(0,2).paragraphs[0].add_run(n) # 这里的可以代表学号或者名字,把上面连接的数字改掉 姓名02 学号06 班级08run.font.name = '黑体'#输入时默认华文琥珀字体run.font.color.rgb = RGBColor(220,220,220) #设置颜色