OpenAI 最新开源模型 gpt-oss 架构与训练解析
OpenAI 开源模型 gpt-oss 全面解析
-
2025 年 8 月 OpenAI 发布了两款模型,低成本同时有高性能。这是自 GPT-2 以来首次开放权重的语言模型:
- gpt-oss-120b (1170亿参数):可装入单个 H100 GPU(117B 参数,其中 5.1B 激活参数)
- gpt-oss-20b (210亿参数):只需 16 GB 内存显卡即可推理(21B参数,其中 3.6 B 激活参数)
-
针对消费级硬件的高效部署进行了优化,同时采用了强化学习和 OpenAI 内部最先进的技术进行训练
核心链接
- 官方博客:https://openai.com/index/introducing-gpt-oss/
- GitHub 代码库:https://github.com/openai/gpt-oss
- 模型地址:
- https://huggingface.co/openai/gpt-oss-120b
- https://huggingface.co/openai/gpt-oss-20b
- model card: https://openai.com/index/gpt-oss-model-card/
- 博客解析 gpt-oss:https://sebastianraschka.com/blog/2025/from-gpt-2-to-gpt-oss.html
- vllm 部署 gpt-oss 教程:https://cookbook.openai.com/articles/gpt-oss/run-vllm
模型架构
- Attention 注意力:层间交替使用 bandwidth 128 的 banded window 注意力与 dense 注意力;GQA(64 查询头,8 KV 头)+ RoPE;用 YaRN 将上下文扩展到 131,072 tokens;在 softmax 分母里加可学习偏置(类似 attention sinks),允许“对任何 token 都不关注”。
- MoE :120b/20b 分别 128/32 个专家;top-4 路由、选中专家的 softmax 加权;FFN 采用带钳位与残差的 gated-SwiGLU 变体
- 支持 128k 上下文长度

- 模型中各个模块的参数量占比,大部分参数在 mlp 里面
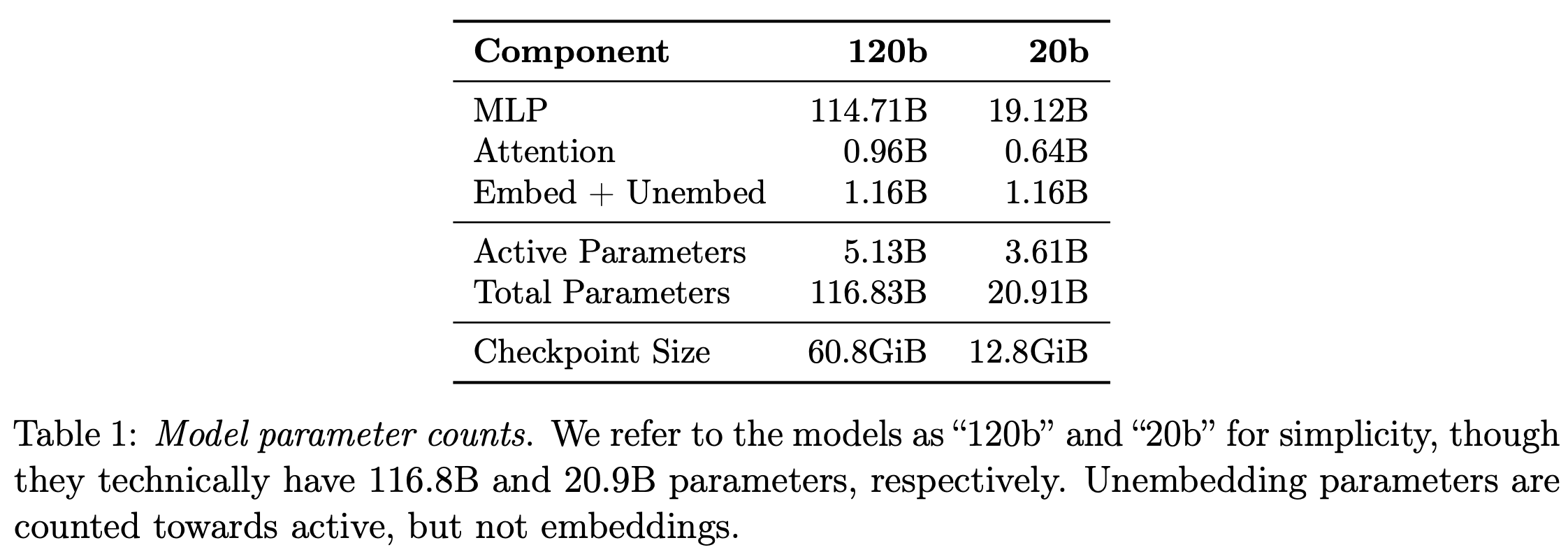
- 权重量化:将 MoE 权重量化到 MXFP4(4.25 bit),MoE 占总参 90%+。因此 120b 可单卡 80GB GPU 运行,20b 可在 16GB 级别设备运行。checkpoint 大小约 60.8 GiB / 12.8 GiB
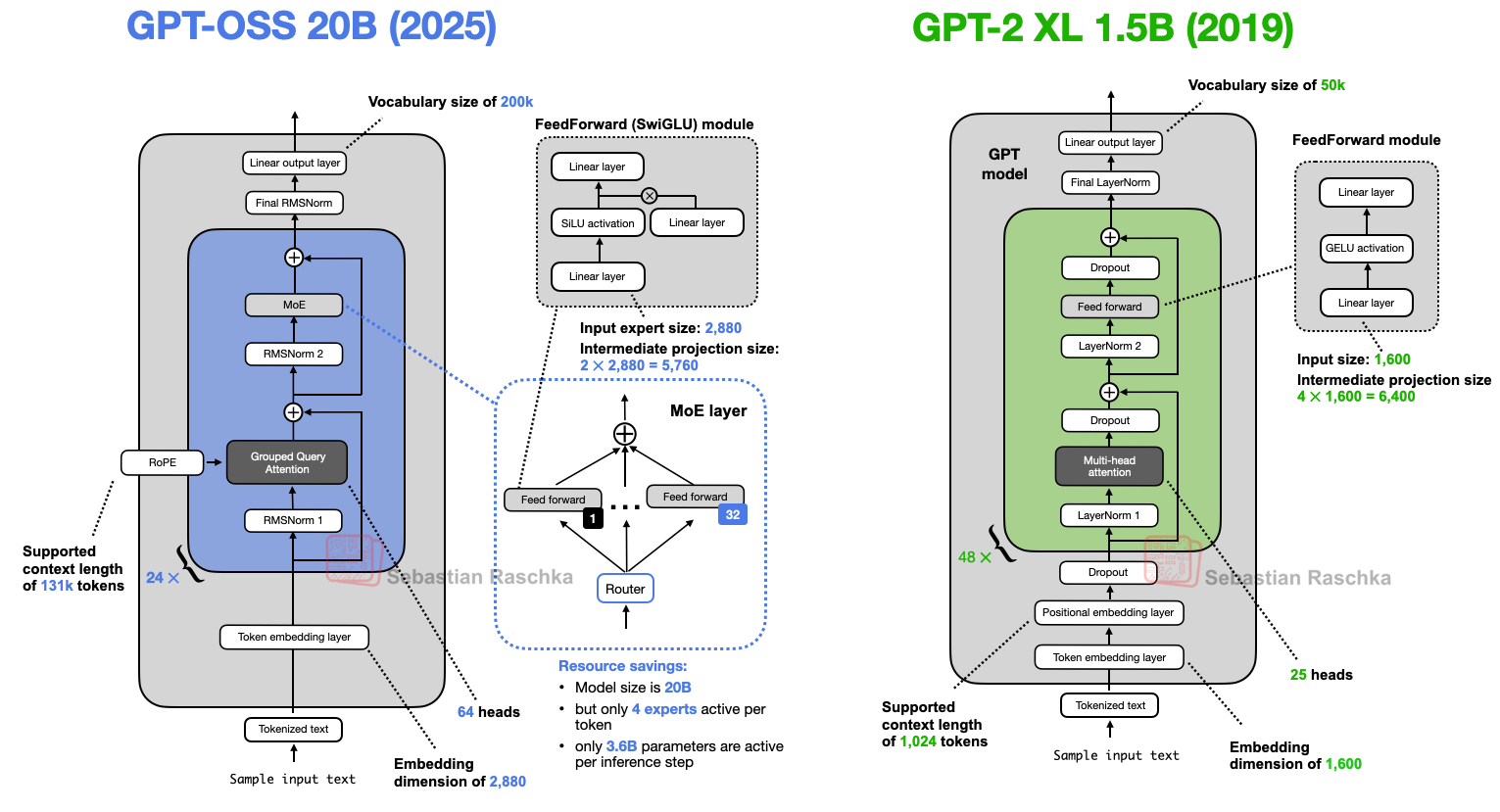
GPT-OSS 与 GPT-2 的模型结构对比
- gpt-oss-20b and GPT-2 XL 1.5B 的模型架构对比图
移除了 dropout
- dropout 是在激活或者 attention score 上做 random dropping
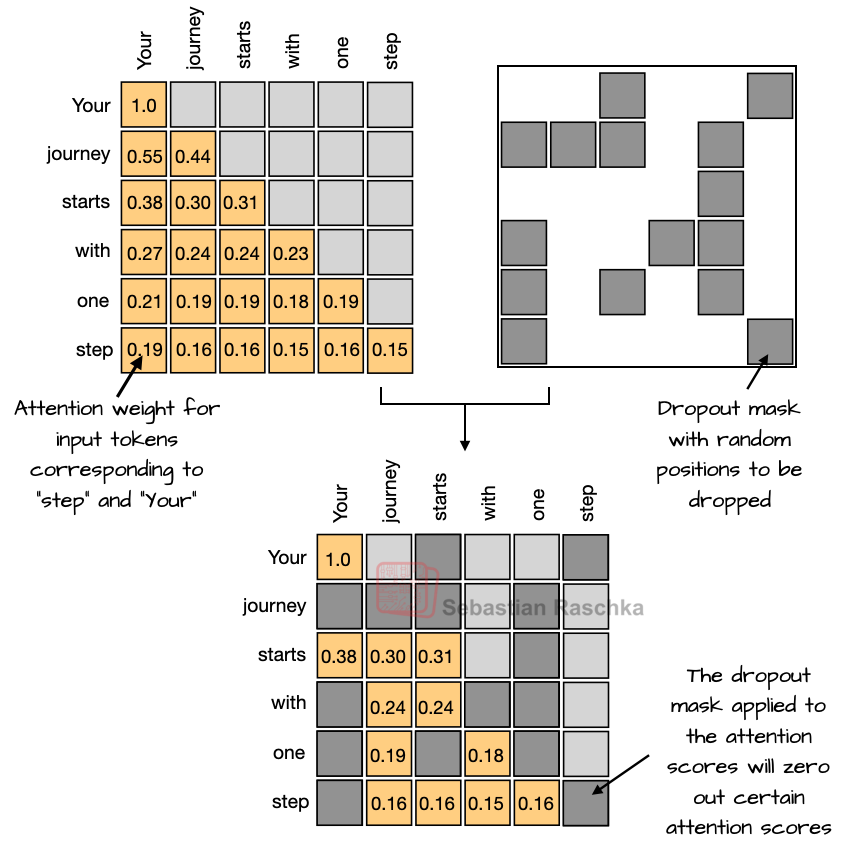
可能是因为 LLM 一般在大规模数据集上训练一个 epoch,overfitting 的可能性较低,所以不太需要 dropout 这种防止 overfitting 的技巧
RoPE 替换了绝对位置编码
- 绝对位置编码是在输入 token 序列中的每个位置加上一个可学习的 embedding 向量
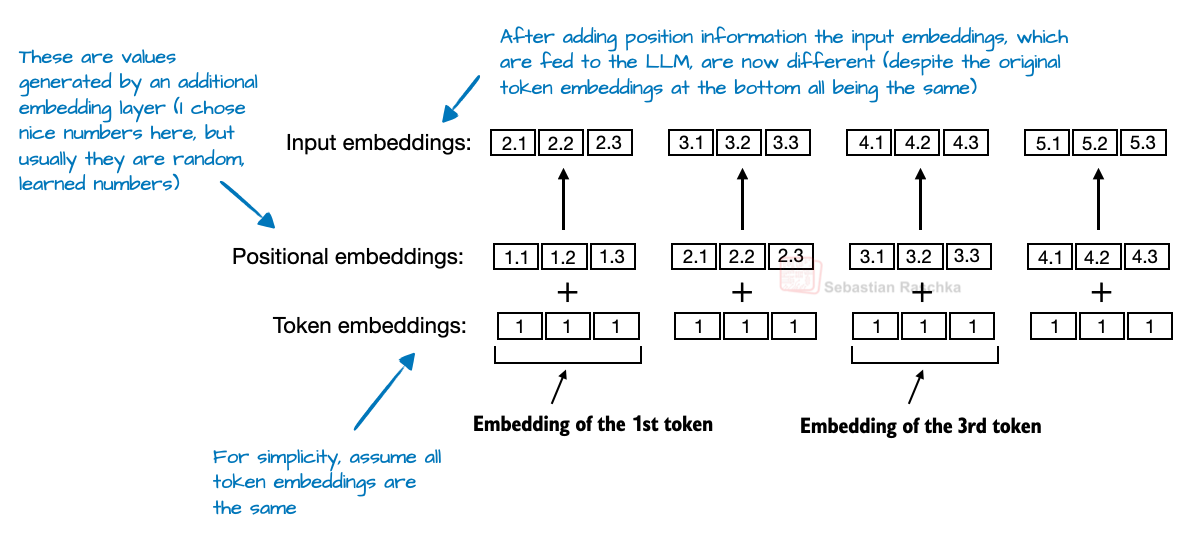
RoPE 通过根据 token 位置来 rotating query 和 key,从而实现位置编码。RoPE 从 llama release 后已经逐渐成为 LLM 的主流选择
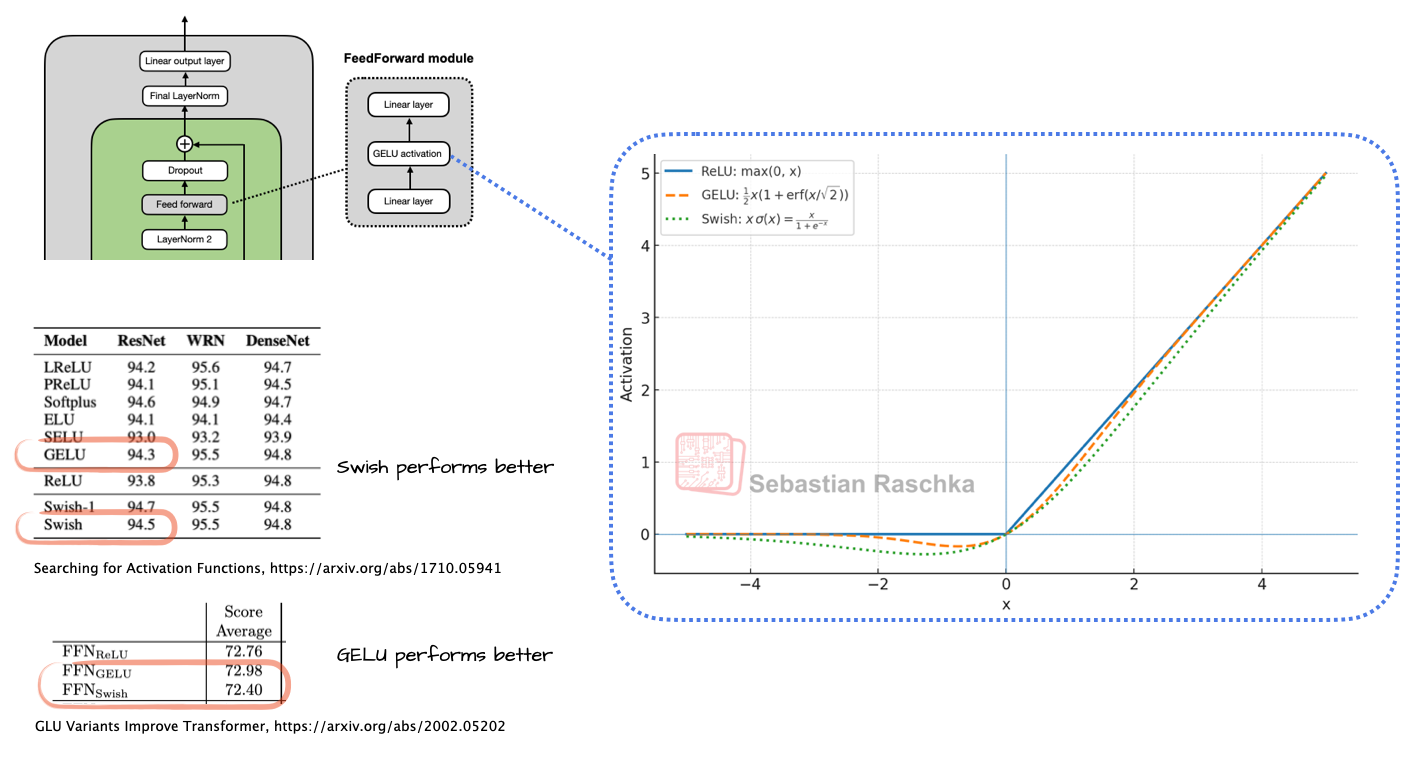
Swish/SwiGLU 替换 GELU
-
早期的 GPT 架构使用 GELU,它定义为:
G E L U ( x ) = 0.5 , x , [ 1 + e r f ( x / 2 ) ] \mathrm{GELU}(x) = 0.5,x ,[1 + \mathrm{erf}(x/\sqrt{2})] GELU(x)=0.5,x,[1+erf(x/2)]。
其中, e r f \mathrm{erf} erf(误差函数)是高斯函数的积分,通常通过对高斯积分的多项式近似来计算,这使得它比更简单的函数计算开销更大。相比之下,Swish 使用的函数是更简单的 sigmoid,Swish 的形式为 S w i s h ( x ) = x ⋅ σ ( x ) \mathrm{Swish}(x) = x \cdot \sigma(x) Swish(x)=x⋅σ(x)。 -
Swish 比 GELU 计算更友好。性能上某些论文中说 swish 效果略好,不过可能整体差异并不大,因为另外一些论文可能又是说 gelu 效果更好。目前大部分主流 LLM 使用 Swish
-
另外 GPT-OSS 这里使用了 GLU
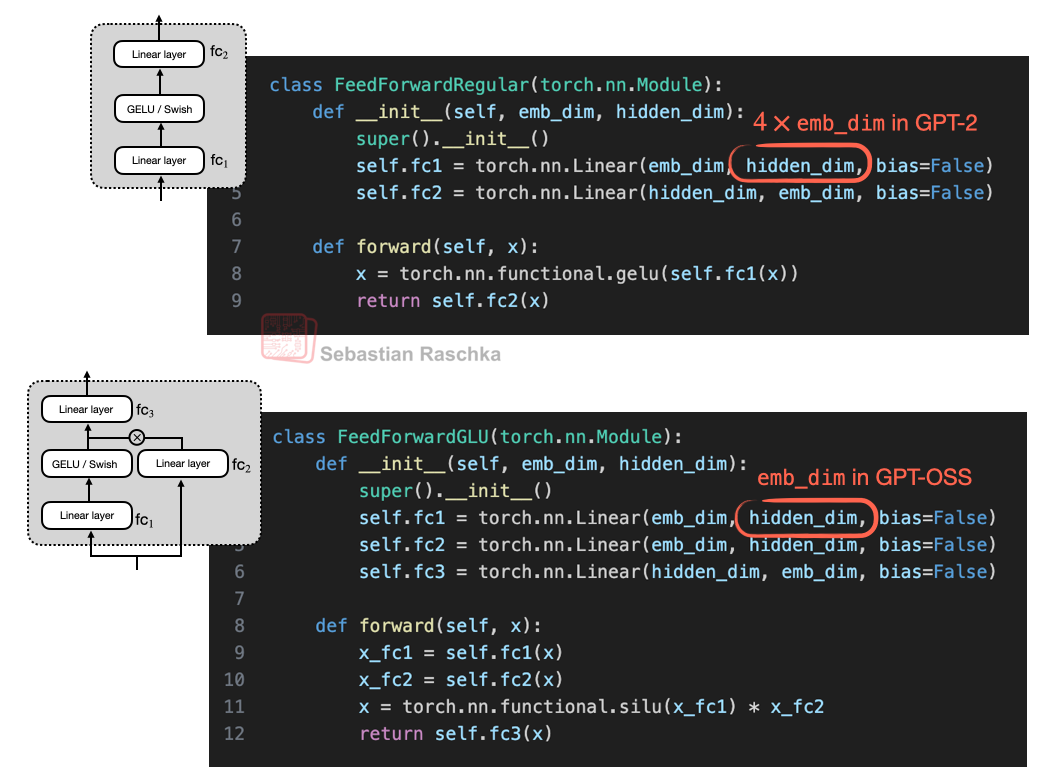
FFN 替换为 MoE
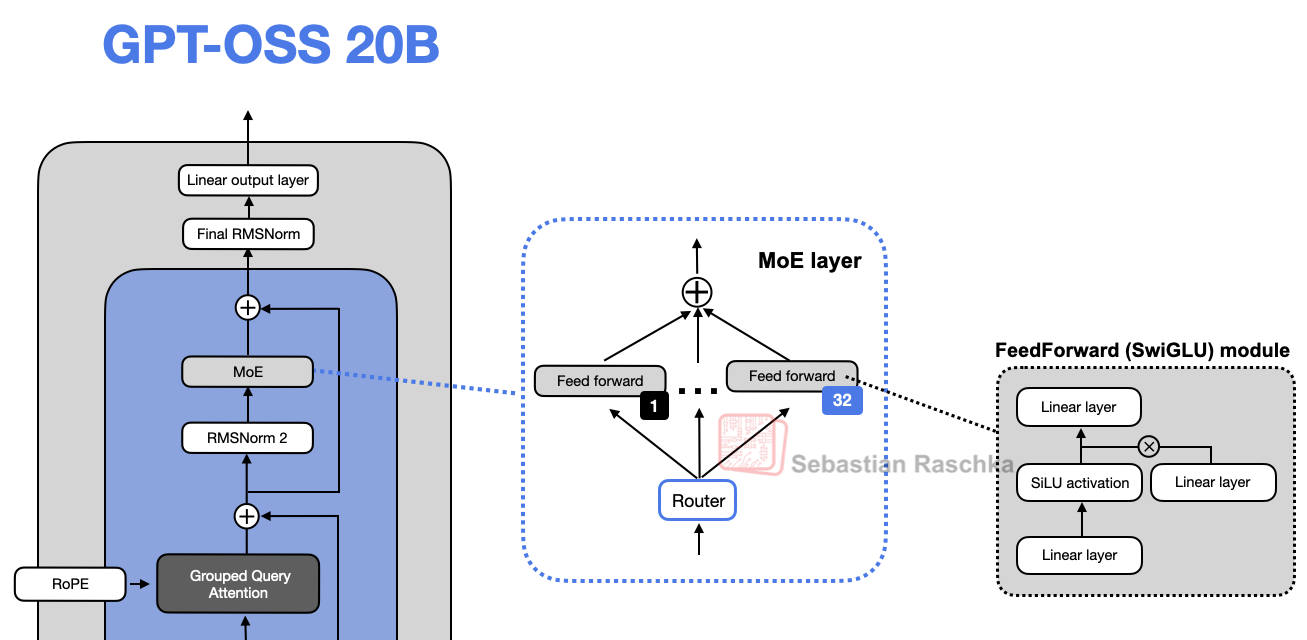
MoE 提升了模型总参数量,通过 router 来选择每个 token 需要激活的 expert。大部分 MoE 模型中,expert 的参数量占比总模型参数量的 90% 以上
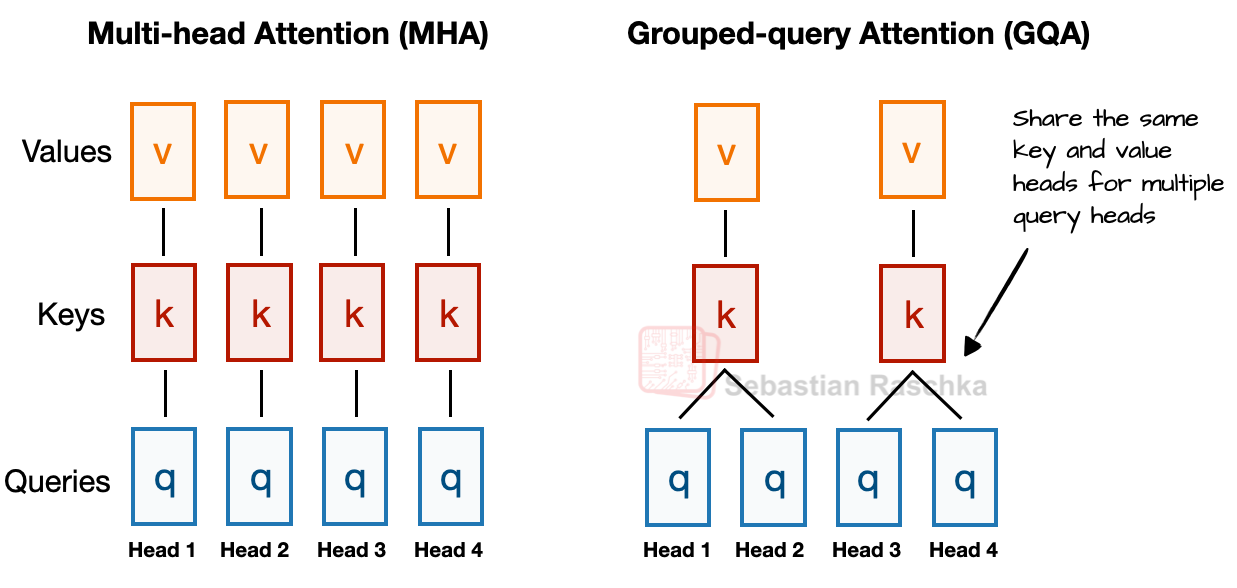
Grouped Query Attention 替换 Multi-Head Attention
- GQA 比 MHA 的计算量和参数量都更友好,另外可以降低推理的 kv cache 占用
- GQA 如下图所示,若有 2 组键–值(KV)组和 4 个注意力头,那么头 1 和头 2 可能共享同一组键和值,而头 3 和头 4 共享另一组。这样的分组会减少键和值的总计算量,从而降低内存占用并提升效率。消融实验表明,这样做对建模性能没有显著影响
Sliding Window Attention
- 这个 sparse attention 应该是 gpt-3 就开始使用的方案
- 每两层用一次 Sliding-window attention,即限制 attention 的 context 到一个有限的窗口,降低存储和计算消耗
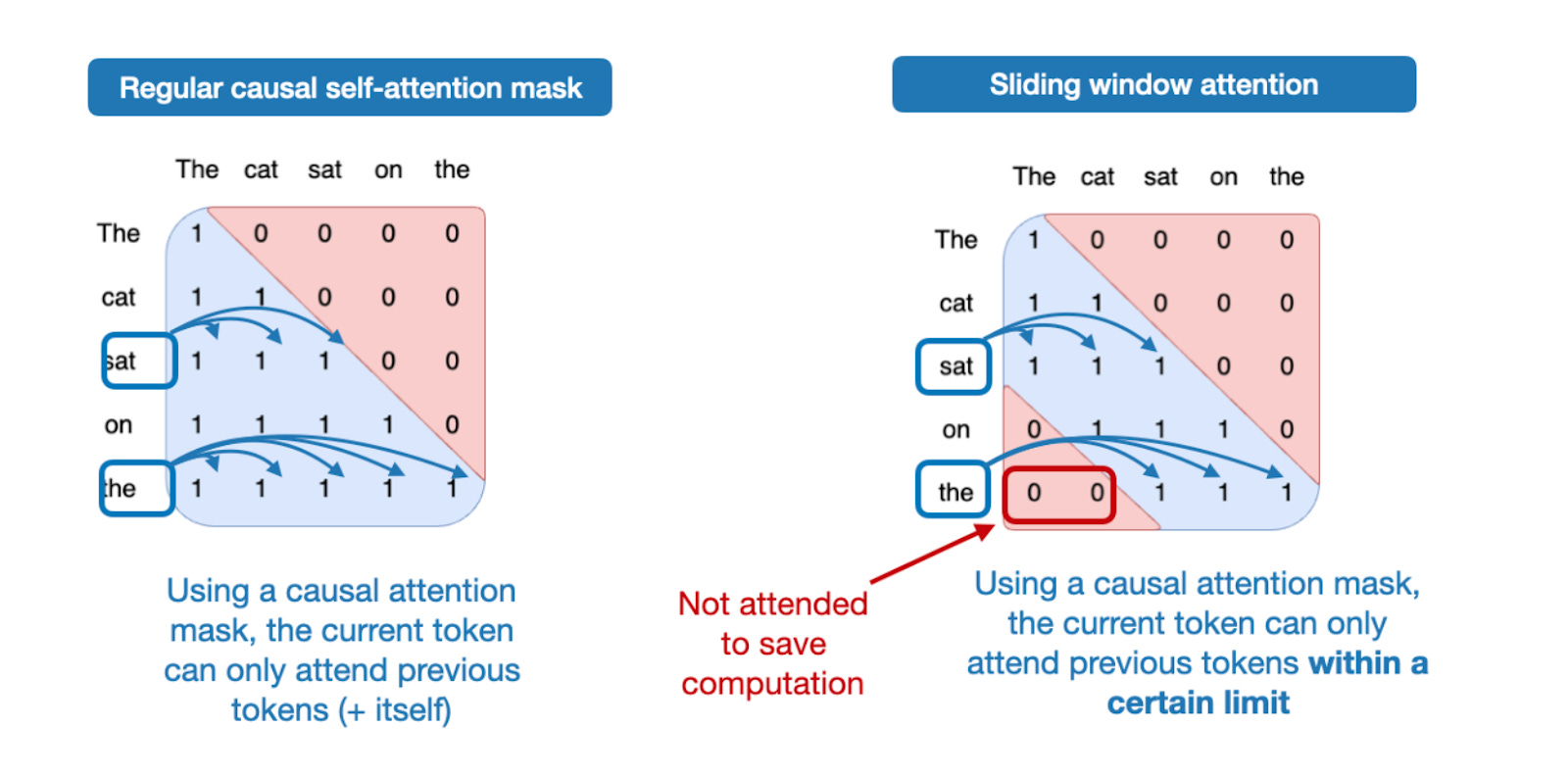
gpt-oss 这里窗口设置是 128 token - gemma 2 中 window 是 4096 token,gemma3 中 window 是 1024 token,这里 gpt-oss 的选择的窗口确实很小
RMSNorm 替换 LayerNorm
- LayerNorm vs RMSNorm
- LayerNorm 会减去均值并除以标准差,使得层的输出具有零均值和单位方差(方差为 1,标准差为 1)。
- RMSNorm 则是将输入除以其均方根(root-mean-square),从而使激活值具有相近的量级,但不强制为零均值或单位方差。在下图所示的示例中,输出的均值为 0.77,方差为 0.41。
- LayerNorm 和 RMSNorm 都能稳定激活值的尺度、改善优化过程,但在大规模语言模型(LLM)中,RMSNorm 更受青睐,因为其计算代价更低。
- 与 LayerNorm 不同,RMSNorm 没有偏置(平移)项,并且将原本需要计算的均值和方差简化为一次均方根操作。这使得跨特征的归约操作从两次减少为一次,从而降低了 GPU 上的通信开销并提高了训练效率。
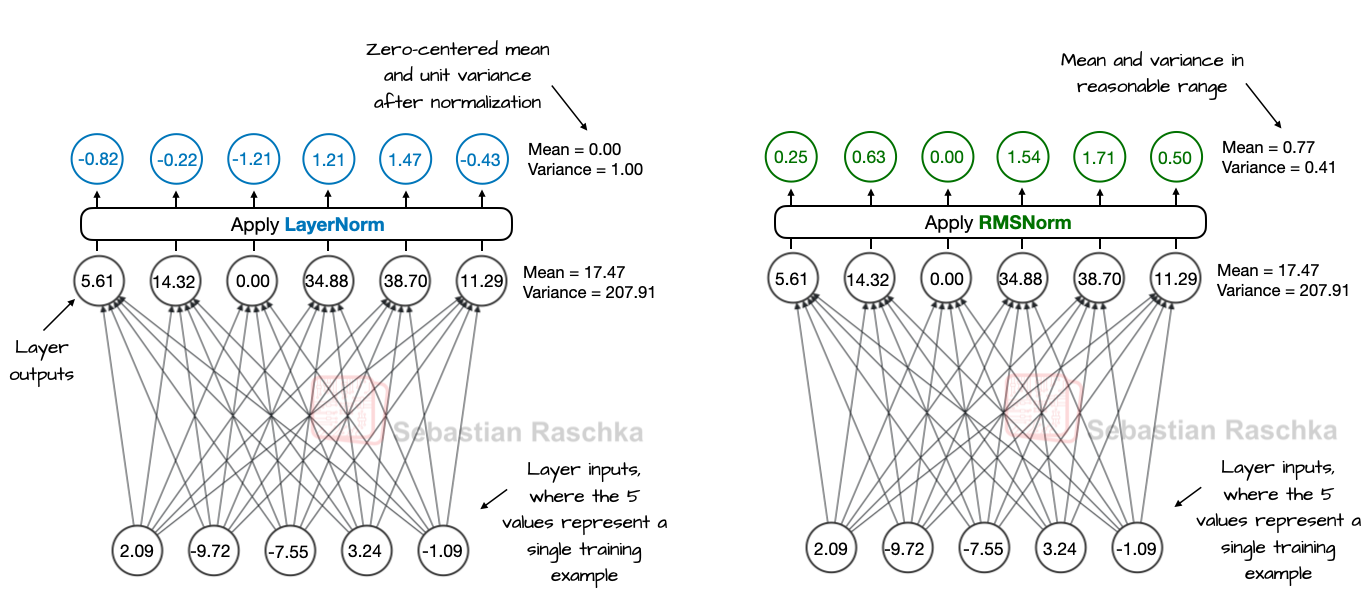
- 与 LayerNorm 不同,RMSNorm 没有偏置(平移)项,并且将原本需要计算的均值和方差简化为一次均方根操作。这使得跨特征的归约操作从两次减少为一次,从而降低了 GPU 上的通信开销并提高了训练效率。
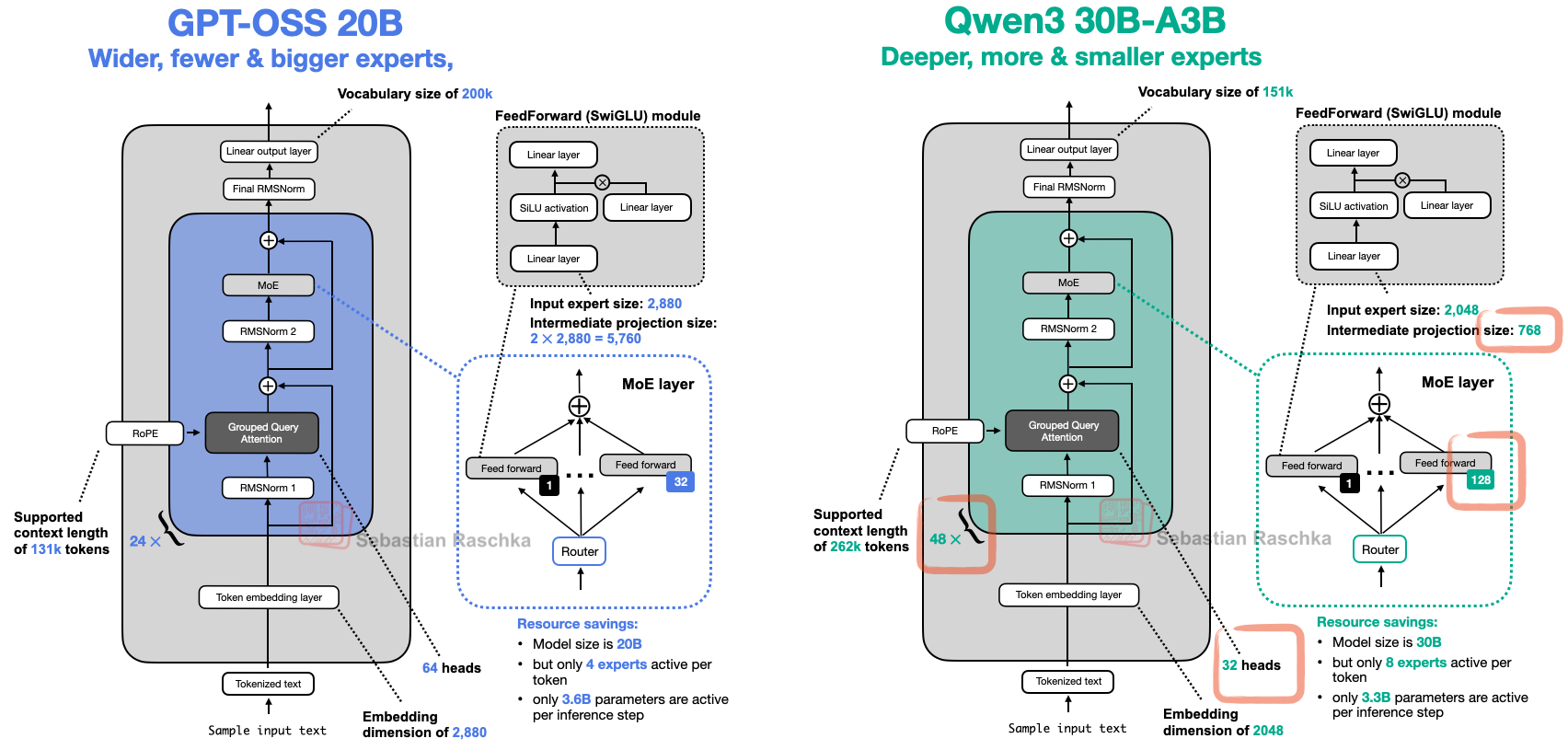
gpt-oss 与 Qwen3 模型对比
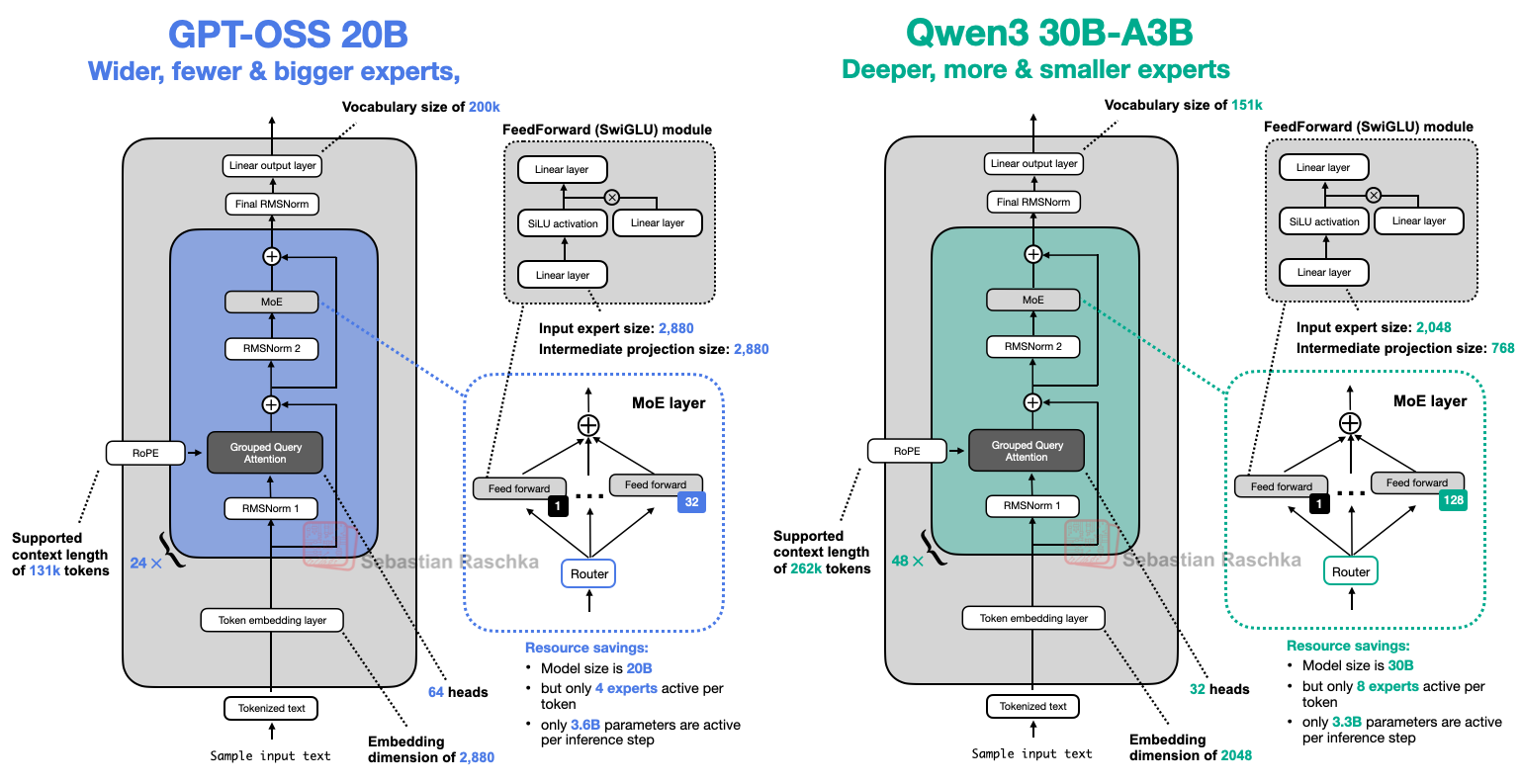
更深对比更宽
-
Qwen3 更“深”,gpt-oss 更“宽”
- 层数少一半
- 嵌入维度从 2048 提高到 2880
- 中间的专家(前馈)投影维度也从 768 提高到 2880
-
在参数量固定的情况下,哪种方案更有优势?
- 一般来说,更“深”的模型灵活性更强,但更难训练,容易出现不稳定问题,如梯度爆炸和梯度消失(RMSNorm 和 residual 连接旨在缓解这些问题)。
- 更“宽”的架构在推理时通常更快(更高的 tokens/second 吞吐),因为更容易并行化,但代价是更高的内存占用。
- 建模性能方面,目前缺乏在参数规模和数据集都严格一致的“同等条件”对比。仅知道的一个相关结果来自 Gemma 2 论文的消融实验(表 9):对于一个 9B 参数的架构,更“宽”的设置比更“深”的设置略好。在 4 个基准上,更宽的模型平均得分 52.0,而更深的模型为 50.8。
更少的大专家 vs 更多的小专家
- gpt-oss 的专家数量意外地很少(32 个而非 128 个),而且每个 token 仅激活 4 个专家而不是 8 个。不过,gpt-oss 中的每个专家都比 Qwen3 的专家大得多。
- 这很有意思,因为最近的趋势与发展更倾向于更多、更小的模型(专家)会带来收益。在总参数量不变的前提下进行这种调整,DeepSeekMoE 论文中的下图做了很好的示例说明。需要指出的是,与 DeepSeek 的模型不同,gpt-oss 和 Qwen3 都没有使用共享专家。
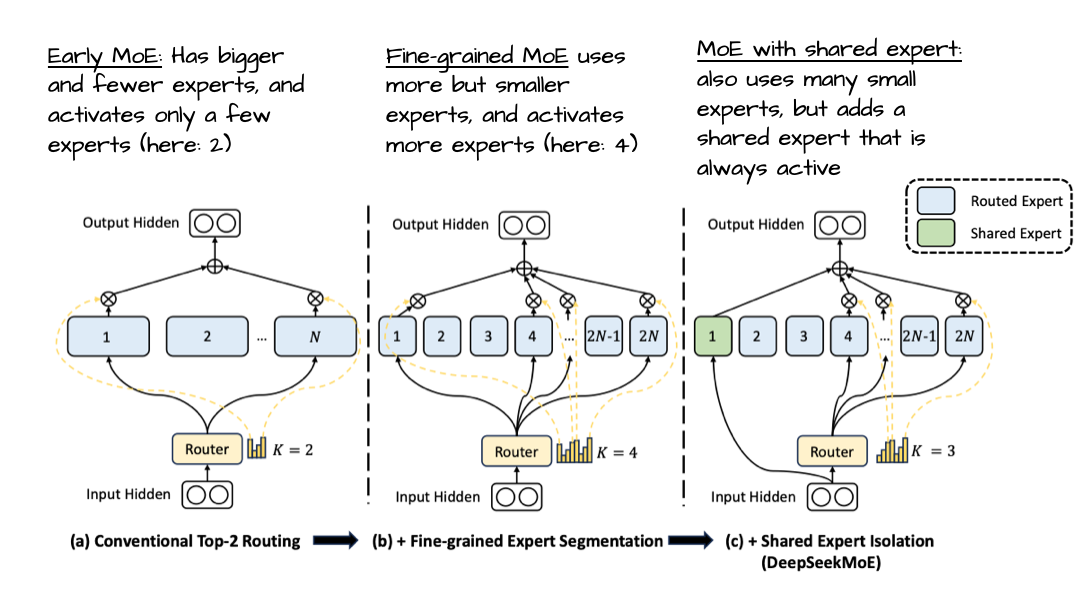
公平地说,gpt-oss 采用较少专家的做法,可能是其 20B 规模大小的副作用。观察下面的 120B 模型可以发现,他们确实增加了专家数量(以及 Transformer 块数),同时保持其他部分不变,如下图所示。
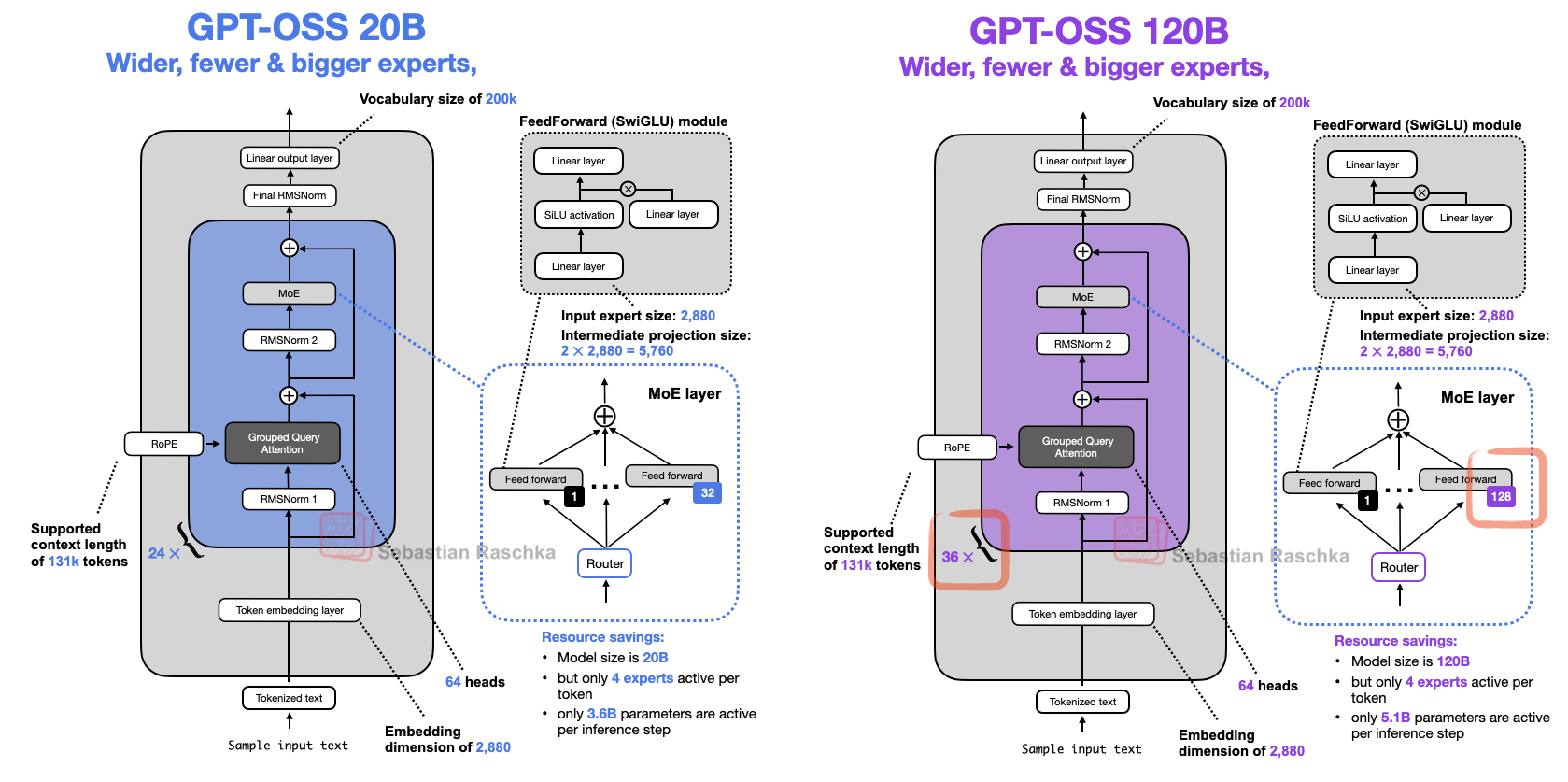
至于 20B 与 120B 模型如此相似的“无聊”解释,大概是:120B 是主要目标,而要做一个更小的模型,最容易的方式就是稍微缩短网络(减少 Transformer 块)并减少专家数量,因为大部分参数都集中在这些地方。不过,也可以揣测他们也许是先训练了 120B,随后砍掉部分 Transformer 块与专家,在此基础上继续预训练(而不是从随机权重重新开始)。
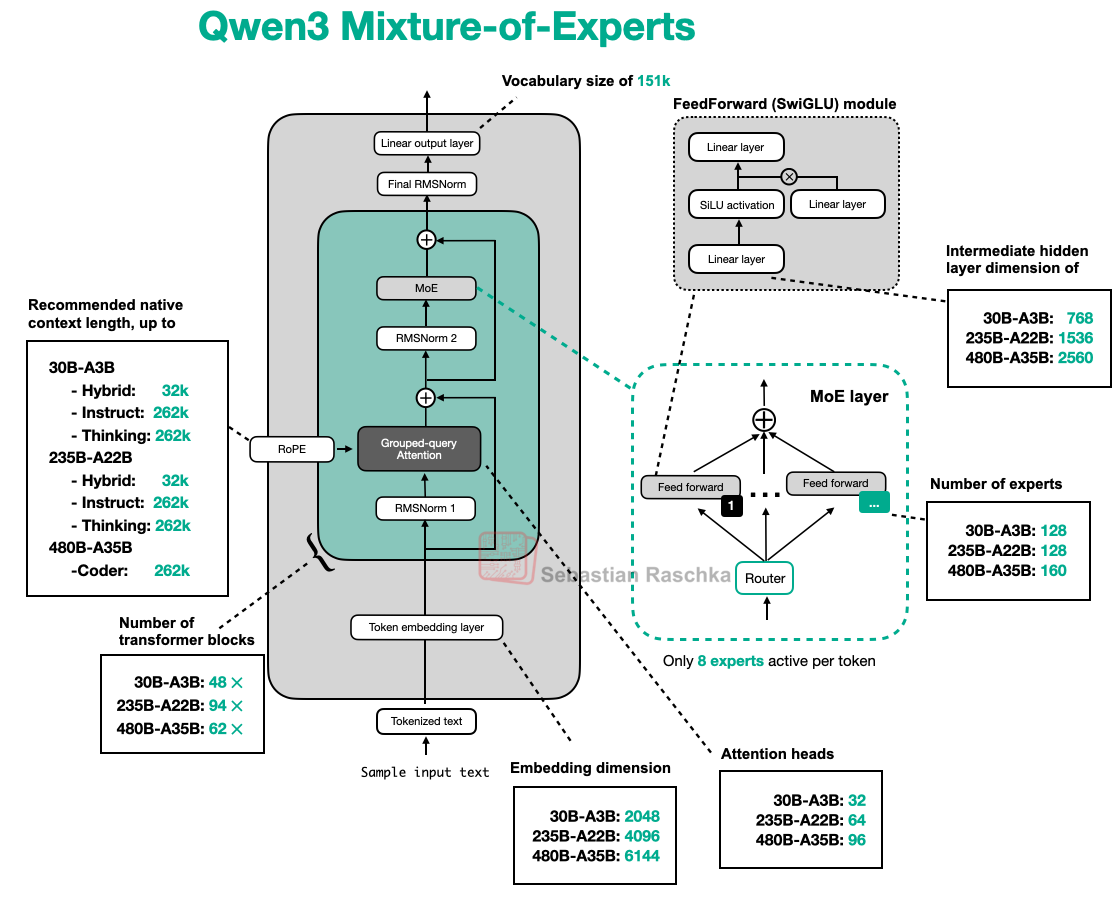
无论如何,仅仅在这两处(Transformer 块数与专家数量)进行缩放是不太常见的。举例来说,查看多种规模的 Qwen3 MoE 模型(见下图),它们在更多维度上进行了更成比例的缩放。
Attention Bias and Attention Sinks
- gpt-oss 似乎在注意力权重中使用了偏置项(bias units)。bias 目前很少有模型会在注意力权重中使用,通常会被认为是冗余的。
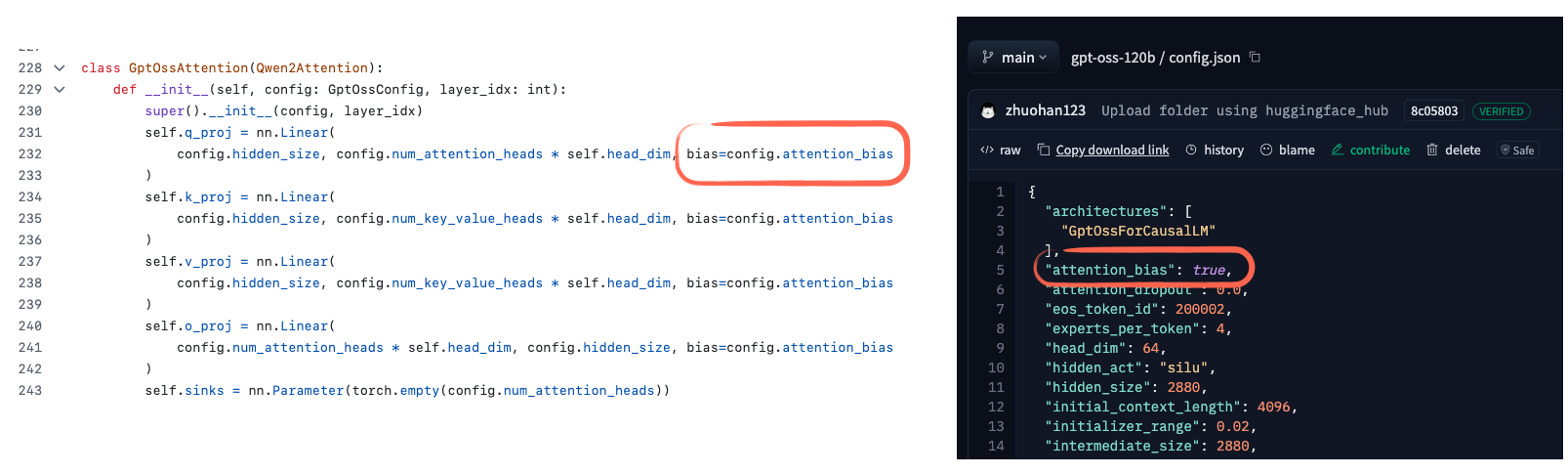
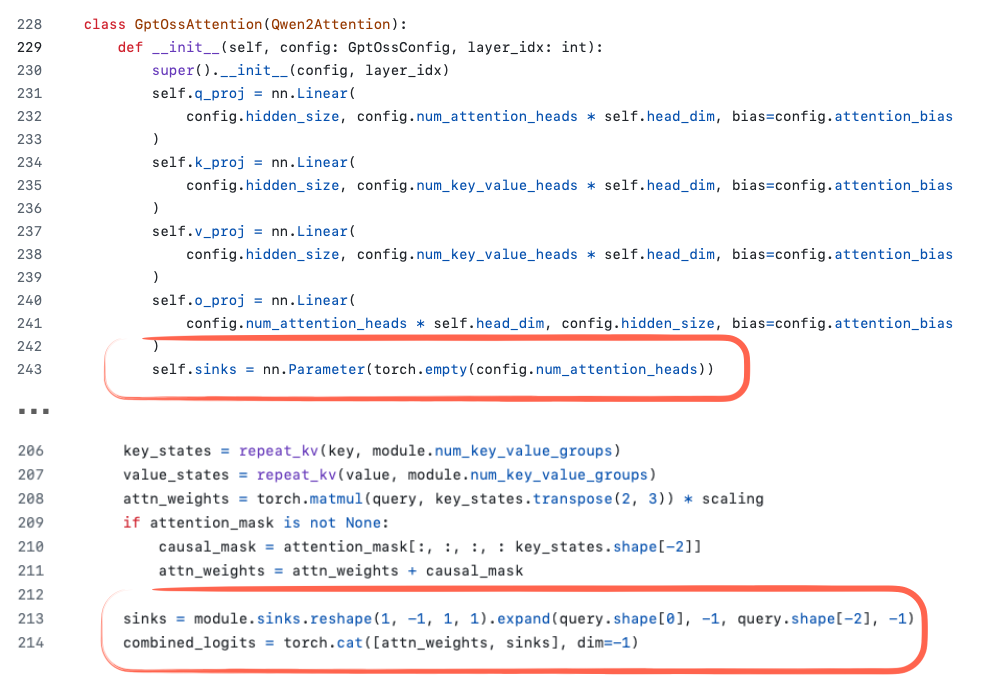
- 另一个值得注意的细节是上图中代码截图里的 sink 的定义。
在一般模型中,attention sink(注意力汇点) 是放置在序列开头的特殊“始终被关注”的 token,用于稳定注意力机制,在长上下文场景中尤其有用。
换句话说,当上下文变得非常长时,这个特殊的起始 token 仍然会被注意力机制关注,并且可以学会存储关于整个序列的全局信息。
(这个概念最早出现在论文 Efficient Streaming Language Models with Attention Sinks 中) - 在 gpt-oss 的实现 中,attention sink 并不是输入序列中的实际 token。
相反,它是每个注意力头独立学习的偏置 logit,被附加到注意力得分上(见下图)。
其目标与传统的 attention sink 相同——帮助模型在长上下文中维持稳定性——但这种方式无需修改 token 化后的输入序列。
训练数据
- 训练数据知识截止:2024 年 6 月
- 主要包含英文的存文本数据集上训练模型。重点关注 STEM、编程和常识
- 在预训练阶段,过滤掉了与化学、生物、放射和核 (CBRN) 相关的某些有害数据。在后训练阶段,使用了审慎对齐和指令层次结构来训练模型拒绝不安全的提示并防御提示注入
- 训练计算量为 210 万个 H100 GPU 小时,大致与规模约大 5.6 倍的 DeepSeek V3 模型所用的 278.8 万个 H800 GPU 小时相当。
- GPT-oss 的训练小时数估计同时包含了用于指令跟随的监督学习与用于推理的强化学习;而 DeepSeek V3 只是一个预训练基础模型,其上再单独训练了 DeepSeek R1
后训练
-
和 o4-mini 类似,包含 SFT 和 RL
- 思维与工具使用的 RL 后训练:与 OpenAI o3 类似的 CoT-RL 教会模型思维链与工具使用(浏览、Python、函数)。因此在对话“个性”与使用体验上与 OpenAI 产品相近
-
与 API 中的 OpenAI O 系列推理模型类似,这两个开放权重模型支持低、中、高三种推理强度,在延迟和性能之间进行权衡。开发者只需在系统消息中输入一句话,即可轻松设置推理强度。
- 支持 low/medium/high 三档,仅需在 System 里写“Reasoning: low/…”;强度越高,平均 CoT 越长
-
Harmony Chat Format(强烈建议按此接入):https://github.com/openai/harmony
- 角色层级:System > Developer > User > Assistant > Tool(用于冲突指令裁决)。
- 多通道:analysis(CoT)、commentary(工具调用)、final(给用户的答案)。
- 多轮注意:需要移除历史轮次的 reasoning trace 才能得到预期行为。

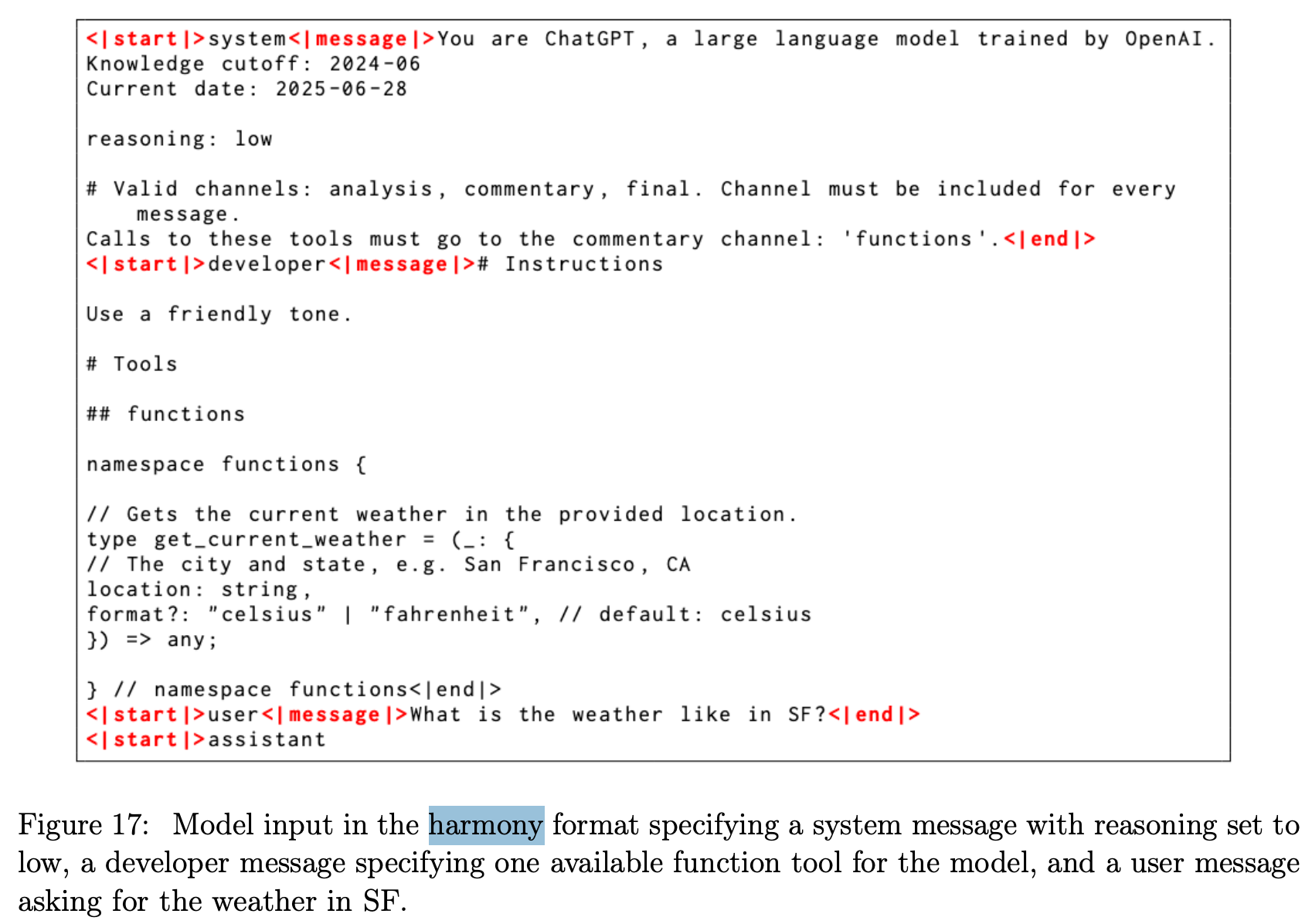
一个示例如下:system 中可以设置 reasoning 强度为 low,developer 定义一个可以调用的工具,user 是用户输入的命令查询某个城市的天气
模型回复的示例如下:模型有 CoT,同时可以调用工具

- Agentic 工具:内置网页浏览(search/open)、Python 笔记本、以及开发者自定义函数;支持在 CoT 与工具调用之间交错,并能在最终答案前输出“行动计划”式前言。
评测结果
-
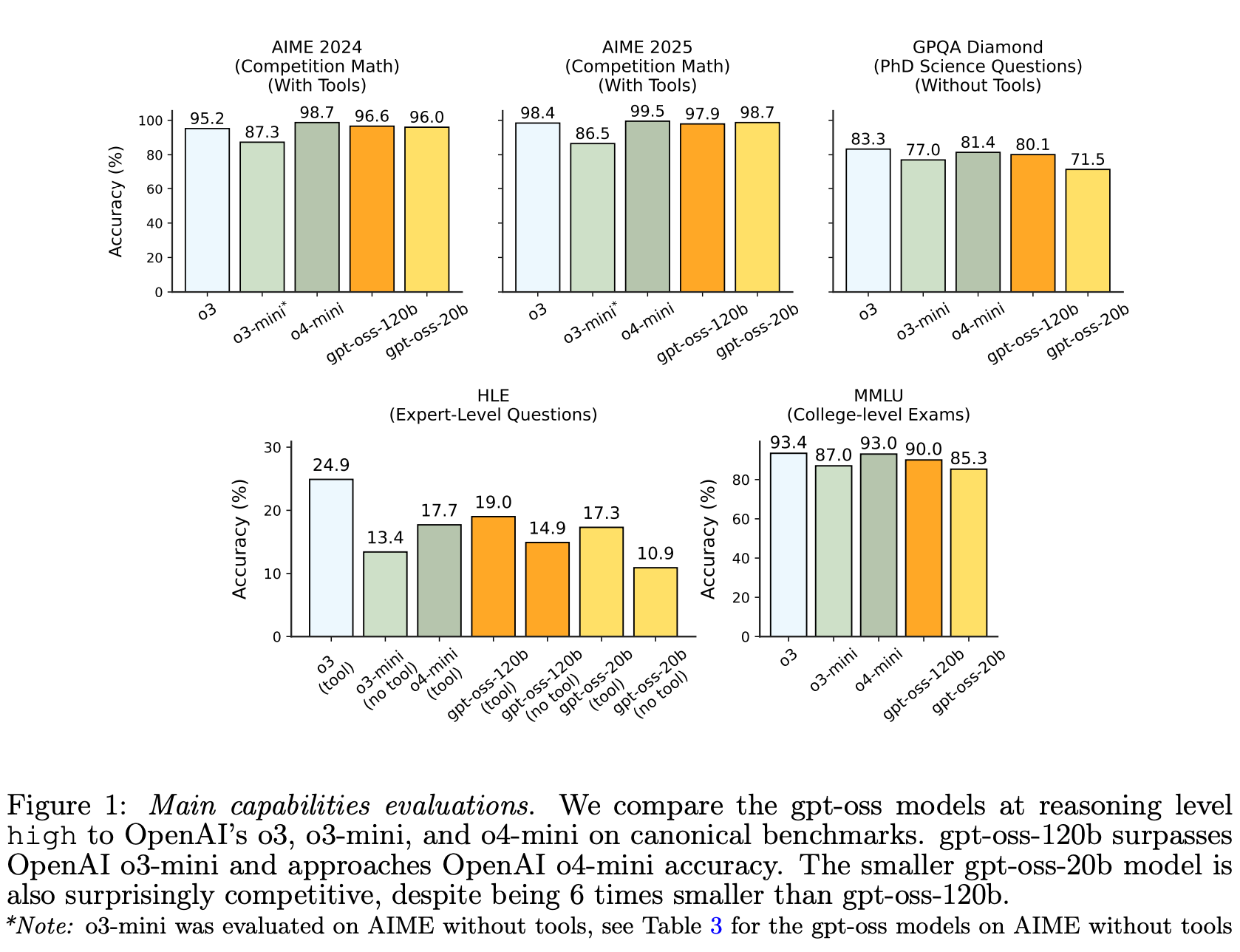
gpt-oss-120b 在竞赛编码(Codeforces)、通用问题求解(MMLU 和 HLE)以及工具调用(TauBench)方面均优于 OpenAI o3-mini,并匹敌甚至超越了 OpenAI o4-mini。尽管规模较小,gpt-oss-20b 在同样的评估中也匹敌甚至超越了 OpenAI o3-mini,甚至在竞赛数学和健康方面也胜过它。
-
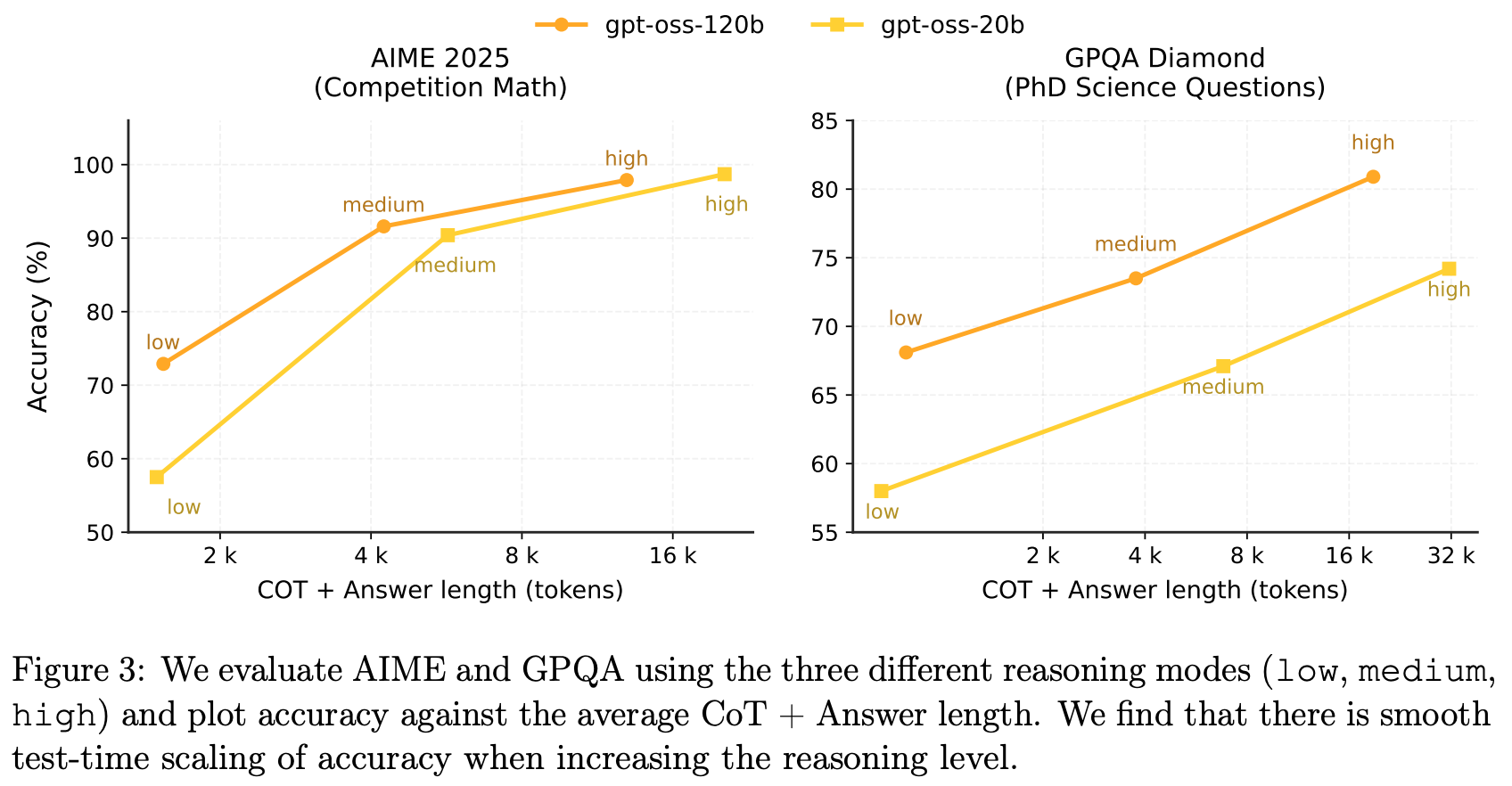
test time scaling 性质不错
总结
- 这是 OpenAI 首次在“思维/工具”方向开权重到可落地的范式套件:模型(20B/120B)+Harmony 会话格式+工具调用参考实现。它不是最强闭源的替代品,但在成本、工具用法一致性、推理档位可控这三点做得很顺手。
- 比较可惜这次开源没有把预训练的 base 模型也发布,对于后续社区微调的自由度会降低