【GUI自动化测试】Python 自动化测试框架 pytest 全面指南:基础语法、核心特性(参数化 / Fixture)及项目实操

文章目录
- 一、关于窗口
- 二、菜单栏
- 2.1 fixture嵌套
- 2.2 请求多个fixture
- 2.3 yield fixture
- 2.3 带参数的fixture
- 2.4 指定⽤例执⾏顺序
- 🚩总结
一、关于窗口
⽀持Python语⾔的⾃动化框架有很多,以下是⽀持Python的⾃动化主流框架对⽐分析:
| 应用场景类型 | 典型应用示例 | 说明 |
|---|---|---|
| 办公软件自动化 | Microsoft Office(Word、Excel、PPT) | Word的文档结构(段落、表格嵌套)、Excel的单元格区域与菜单层级、PPT的幻灯片元素层级等,需逐层定位控件。 |
| 即时通讯工具 | QQ、钉钉、企业微信 | 聊天窗口、联系人列表、设置面板等模块存在多层控件嵌套,自动化交互需穿透层级。 |
| 设计类软件 | Photoshop、AutoCAD、Figma(桌面端) | 画布图层嵌套、工具栏子菜单、属性面板多级控件等,需精准逐层查找目标控件。 |
| 系统工具与资源管理 | 文件资源管理器、系统设置面板、任务管理器 | 文件资源管理器的目录树与文件列表嵌套在不同Pane中;系统设置的选项卡及子控件存在深层级。 |
| 企业级业务应用 | ERP系统(如SAP)、CRM系统、财务软件 | 复杂业务表单、报表模块、导航栏等存在深控件嵌套,自动化操作(如提交表单、查询数据)需处理层级。 |
| 游戏客户端(自动化/测试) | 大型网游客户端、单机游戏 | 游戏内UI(背包、技能栏、任务面板)多为多层嵌套控件,自动化交互(如点击技能、打开背包)需定位深层控件。 |
| 开发工具 | PyCharm、VS Code、Xcode | IDE的代码编辑区、侧边栏(如项目结构树)、调试面板等,控件分布在不同层级的容器中。 |
| 多媒体软件 | PotPlayer、VLC、Audacity | 播放控制栏、播放列表、参数设置菜单等存在控件嵌套,自动化操作(如切换播放、调整参数)需穿透层级。 |
-
pytest介绍
pytest官⽅⽂档:https://docs.pytest.org/en/stable/getting-started.html
pytest是一个非常流行且高效的Python测试框架,它提供了丰富的功能和灵活的用法,使得编写和运行测试用例变得简单而高效。
为什么选择pytest:
简单易用: pytest的语法简洁清晰,对于编写测试用例非常友好,几乎可以在几分钟内上手。·强大的断言库: pytest内置了丰富的断言库,可以轻松地进行测试结果的判断。
·支持参数化测试: pytest支持参数化测试,允许使用不同的参数多次运行同一个测试函数
这
大大提高了测试效率。
丰富的插件生态系统: pytest有着丰富的插件生态系统,可以通过插件扩展各种功能,比如覆盖率测试、测试报告生成(如pytest-html/插件可以生成完美的HTML测试报告)、失败用例重复执行(如pytest-rerunfailures 插件)等。此外,pytest还支持与selenium、
requests、appinum等结合,实现Web自动化、接口自动化、App自动化测试。
·灵活的测试控制: pytest允许跳过指定用例,或对某些预期失败的case标记成失败,并支持重
复执行失败的caseo -
安装
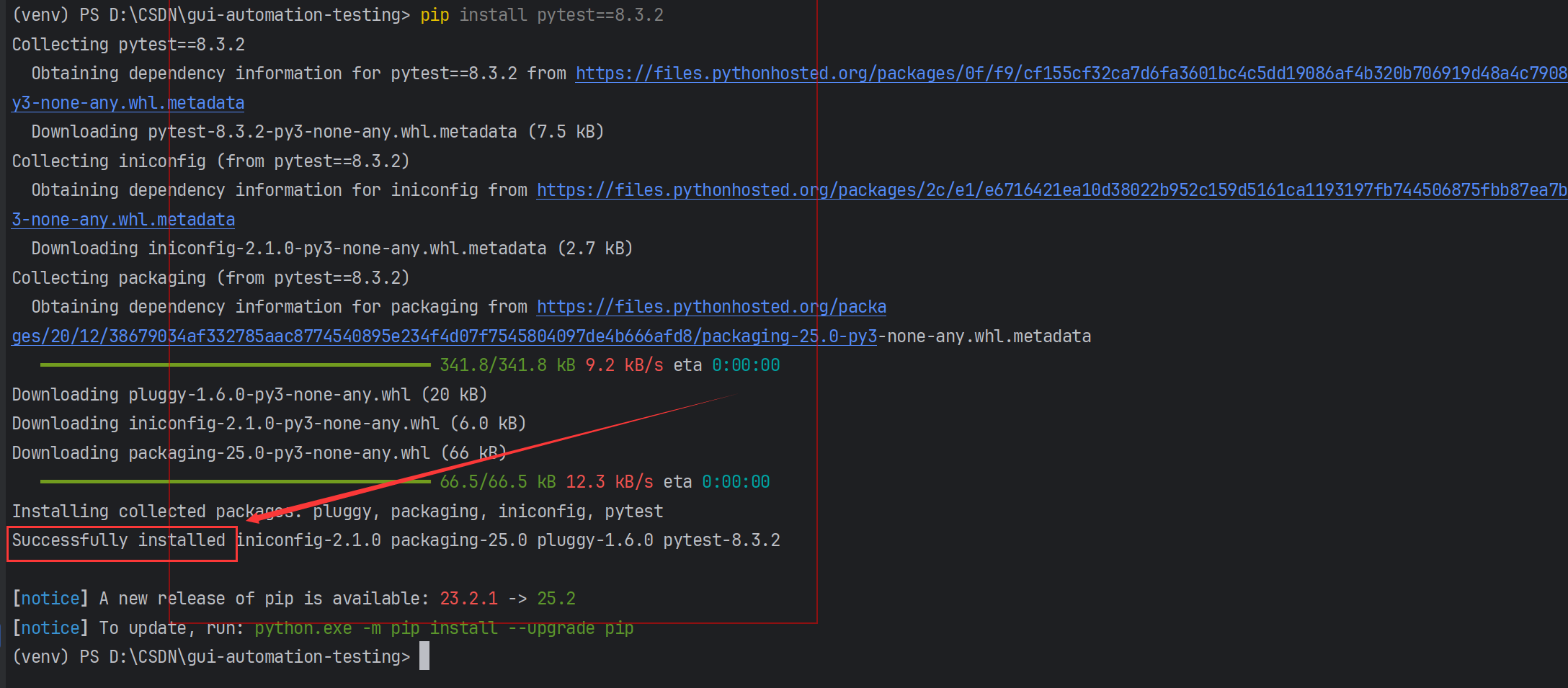
安装pytest8.3.2要求python版本在3.8及以上。
pip install pytest==8.3.2
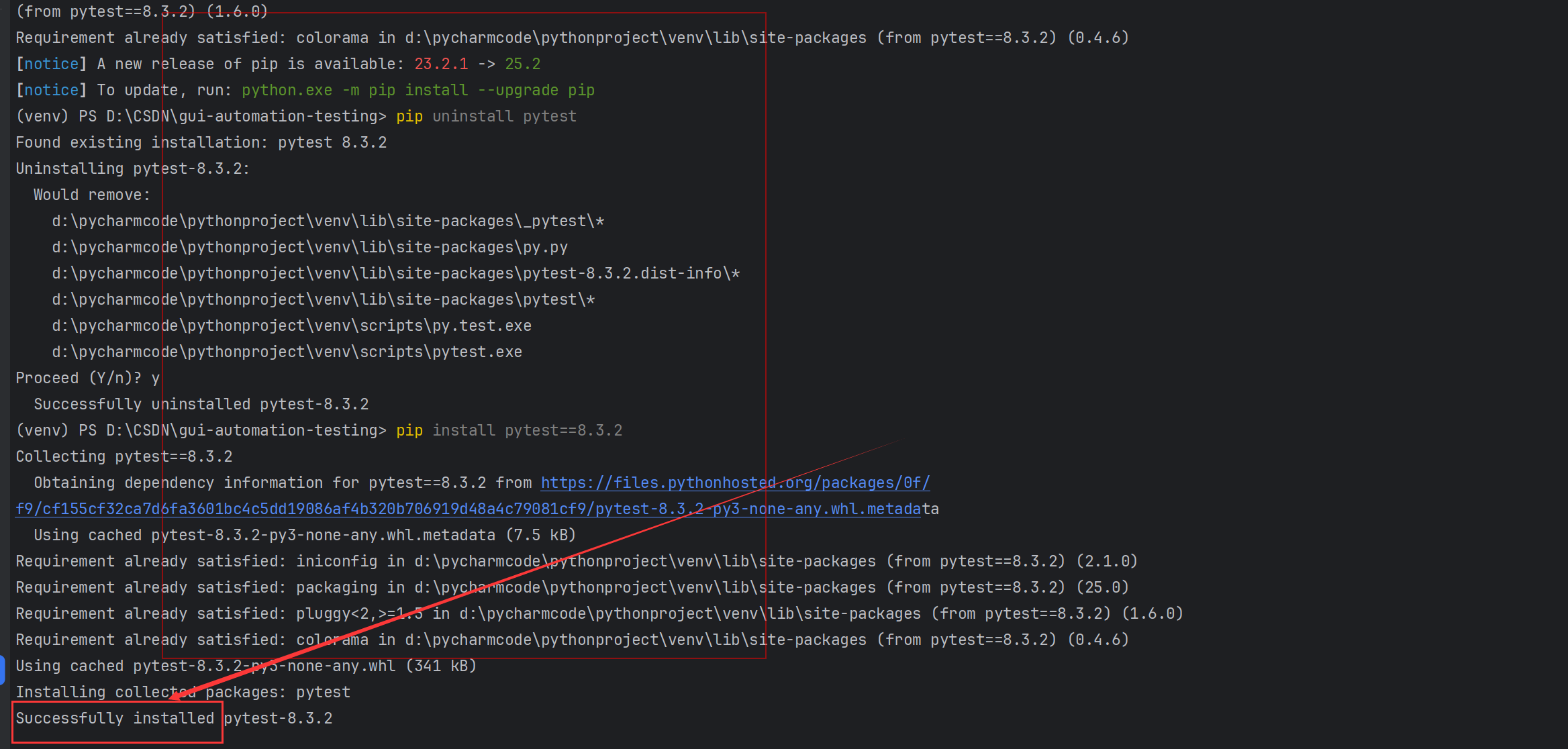
若python版本低于3.8,可参考表格不同的pytest版本⽀持的python版本:
| pytest 版本 | 最低 Python 版本 |
|---|---|
| 8.0+ | 3.8+ |
| 7.1+ | 3.7+ |
| 6.2 - 7.0 | 3.6+ |
| 5.0 - 6.1 | 3.5+ |
| 3.3 - 4.6 | 2.7, 3.4+ |
 |
安装好 pytest后,确认pycharm中python解释器已经更新,来看一下有 pytest框架和没有pytest框架编写代码的区别:
安装pytest:


未安装pytest框架的情况下需要编写main函数,在main函数中手动调用测试用例test01;安装了pytest框架后方法名前有直接运行标志。
然而并不是所有的方法都可以直接运行,需要遵循pytest中的用例命名规则。
- ⽤例运⾏规则

1.文件名必须以test_开头或者_test结尾
2.测试类必须以Test开头,并且不能有__init__方法。
3.测试方法必须以test开头
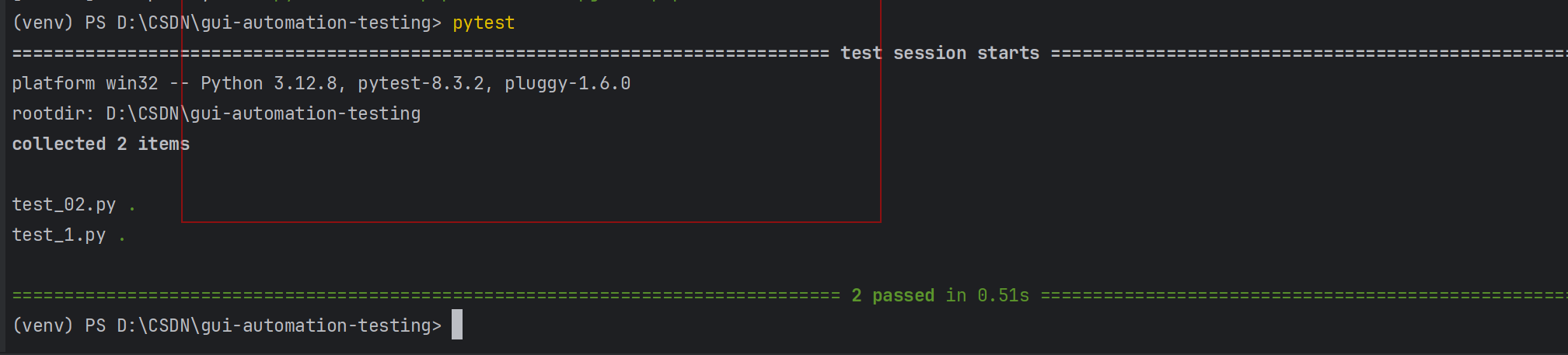
当满⾜以上要求后,可通过命令⾏参数pytest 直接运⾏符合条件的⽤例:
注意:Python类中不可以添加init⽅法
class Test():def __init__(self):print("-----init-------")def test_a(self):print("-----test_a----")
由于 pytest的测试收集机制,测试类中不可以定义__init__方法。pytest 采用自动发现机制来收集测试用例。它会自动实例化测试类并调用其所有以test结尾的方法作为测试用例。如果测试类中定义了__init__方法,那么当pytest实例化该类时,__init__方法会被调用,这可能会掩盖测试类的实际测试逻辑,并引入额外的副作用,影响测试结果的准确性。
若测试类中存在初始化操作该采取什么方案?
为了避免使用__init__方法,建议在pytest中使用其他替代方案,如使用setup()和tearDown()方法、使用类属性、使用fixture函数(具体使用后续会讲解)
- pytest命令参数
pytest提供了丰富的命令行选项来控制测试的执行。以下是一些常用的pytest命令行参数及其使用说明。
| 命令 | 描述 | 备注 |
|---------------------|----------------------------------------|------|
|pytest| 在当前目录及其子目录中搜索并运行测试 | |
|pytest -v| 增加输出的详细程度 | |
|pytest -s| 显示测试中的print语句 | |
|pytest test_module.py| 运行指定的测试模块 | |
|pytest test_dir/| 运行指定目录下的所有测试 | |
|pytest -k <keyword>| 只运行测试名包含指定关键字的测试 | |
|---------------------------|------------------------------|--------------------------|
|pytest -m <marker>| 只运行标记为指定标记的测试 | |
|pytest -q| 减少输出的详细程度 | |
|pytest --html=report.html| 生成 HTML 格式的测试报告 | 需要安装pytest-html插件 |
|pytest --cov| 测量测试覆盖率 | 需要安装pytest-cov插件 |
⽰例1:运⾏符合运⾏规则的⽤例
pytest

注意,这⾥不会输出测试⽤例中print内容
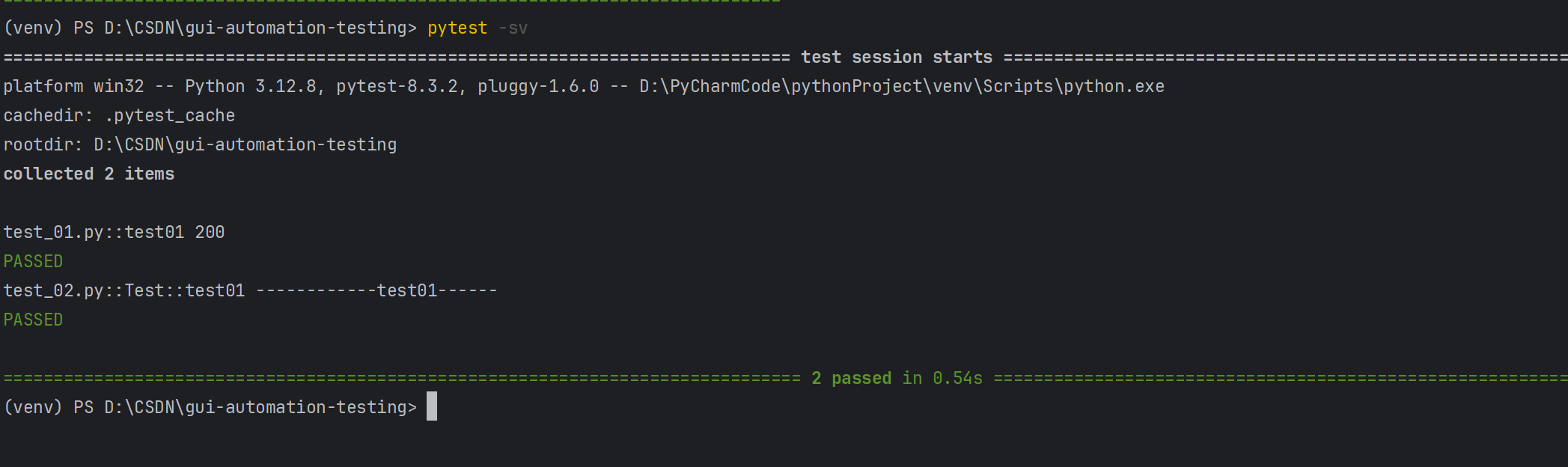
⽰例2:详细打印,并输⼊print内容
pytest -s -v或者pytest -sv(可以连写)
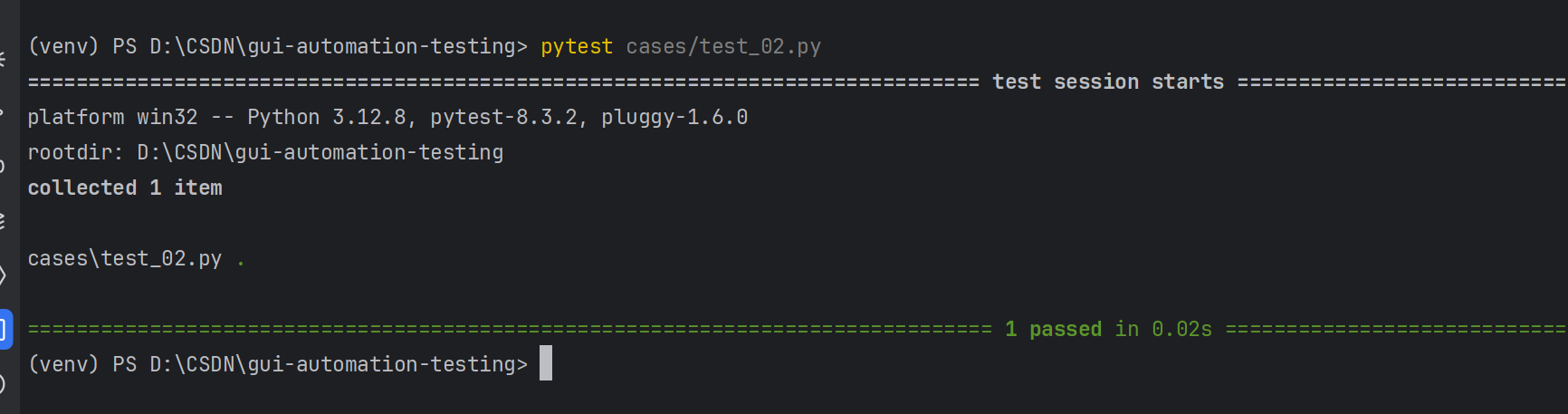
⽰例3:指定⽂件/测试⽤例
#指定文件: pytest包名/文件名
pytest cases/test_01.py
#指定测试用例: pytest包名/文件名: :类名::方法名
pytest cases/test_01.py ::Test: :test_a

问题:当我们既要详细输出,⼜要指定⽂件时,命令会⼜臭⼜⻓,⽽且每次运⾏都需要⼿动输⼊命
令,如何解决?
将需要的相关配置参数统⼀放到 pytest 配置⽂件中。
- pytest配置⽂件
在当前项⽬下创建pytest.ini⽂件,该⽂件为pytest的配置文件,以下为常见的配置选项:
| 参数 | 解释 |
|-------------------|--------------------------------------------|
|addopts| 指定在命令行中默认包含的选项。|
|testpaths| 指定搜索测试的目录。|
|python_files| 指定发现测试模块时使用的文件匹配模式。|
|python_classes| 指定发现测试类时使用的类名前缀或模式。|
|python_functions| 指定发现测试函数和方法时使用的函数名前缀或模式。 |
|norecursedirs| 指定在搜索测试时应该避免递归进入的目录模式。|
|markers| 定义测试标记,用于标记测试用例。|
配置好pytest.ini文件后,命令行执行pytest命令即可,无需再额外指定其他参数:
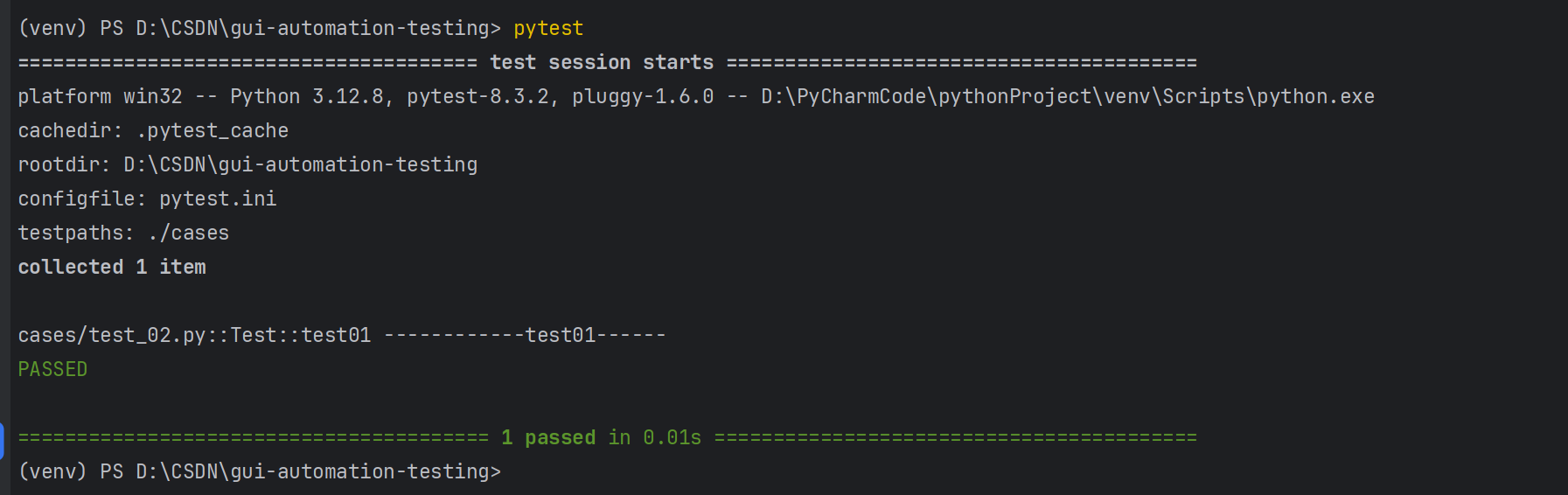
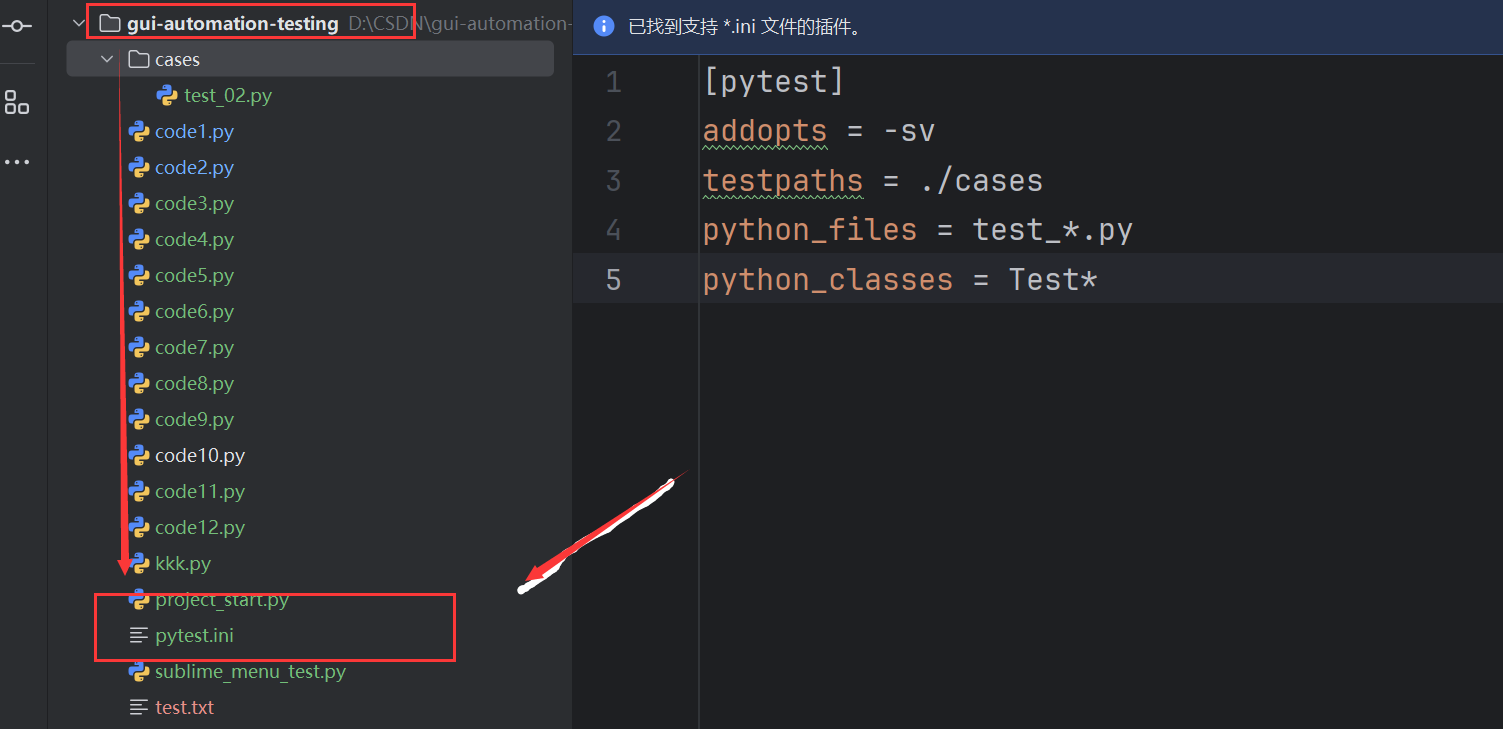
pytest.ini文件通常位于项目的根目录下。通过在 pytest.ini中定义配置项,可以覆盖pytest的默认行为,以满足项目的需求。
6.前后置
遗留问题:使用pytest框架,测试类中不可以添加init()方法,如何进行数据的初始化?
在测试框架中,前后置是指在执行测试用例前和测试用例后执行一些额外的操作,这些操作可以用于设置测试环境、准备测试数据等,以确保测试的可靠性
pytest框架提供三种方法做前后置的操作:
setup_method 和teardown_method:这两个方法用于类中的每个测试方法的前置和后置操作。
setup_class和teardown_class:这两个方法用于整个测试类的前置和后置操作。fixture:这是 pytest推荐的方式来实现测试用例的前置和后置操作。fixture提供了更灵活的控制和更强大的功能。(该内容后续在fixture章节中详细讲解)
示例1:setup_method和teardown_method
import pytestclass TestExample:def setup_method(self):print("Setup: Before each test")def teardown_method(self):print("Teardown: Before each test")def test_emample1(self):print("Running test_example1")def test_emample2(self):print("Running test_example2")
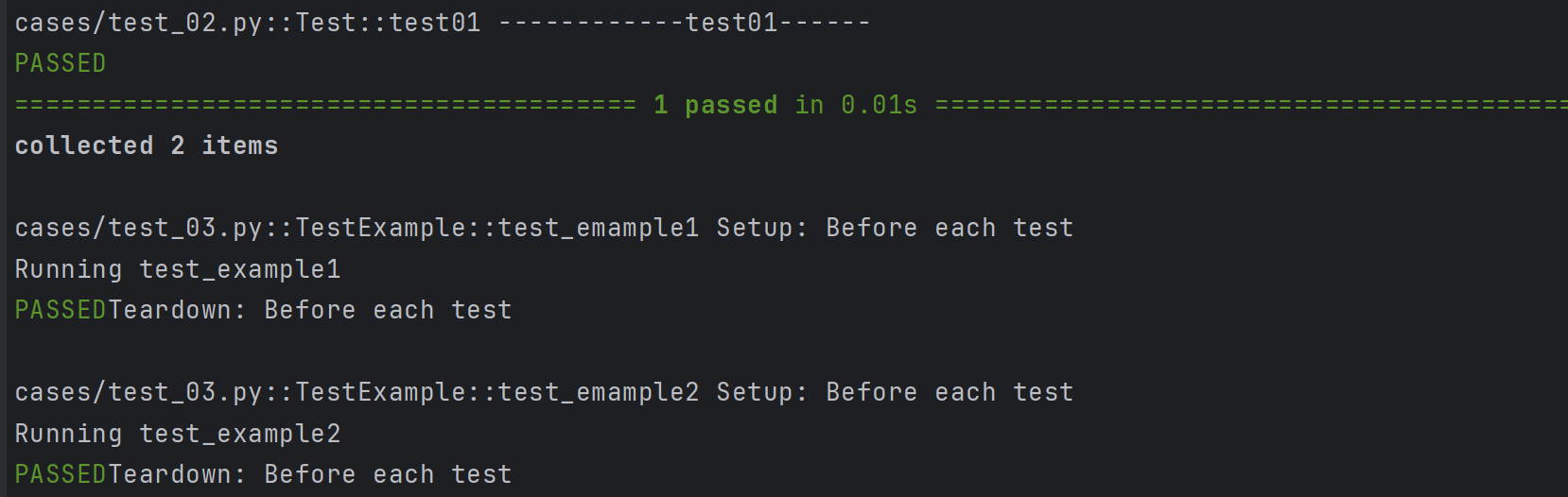
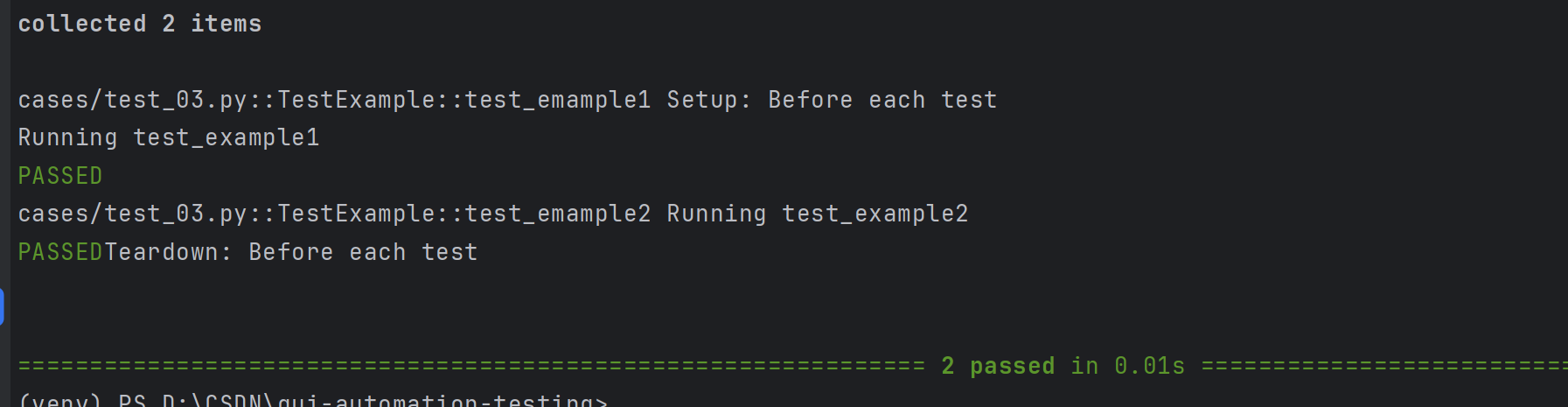
示例2: setup_class和teardown_class
class TestExample:def setup_class(self):print("Setup: Before each test")def teardown_class(self):print("Teardown: Before each test")def test_emample1(self):print("Running test_example1")def test_emample2(self):print("Running test_example2")
7.断言
断言( assert)是一种调试辅助工具,用于检查程序的状态是否符合预期。如果断言失败(即条件为假),Python解释器将抛出一个AssertionError异常。断言通常用于检测程序中的逻辑错误。pytest|允许你在Python测试中使用标准的Python assert语句来验证预期和值。
基本语法:
assert条件,错误信息
条件:必须是一个布尔表达式。
错误信息︰当条件为假时显示的错误信息,可选。示例1:基本数据类型的断言
#断言整数
a = 1
b = 2
assert a == b#断言字符串
str = "hello"
assert "hello" == str
⽰例2:数据结构断⾔
- 列表(
list) vs C++std::vector
-
Python
list:- 动态数组,元素可任意类型(因为 Python 是动态类型);
- 支持增删改查、自动扩容;
- 示例:
[1, "apple", 3.14](整数、字符串、浮点数混合)。
-
C++
std::vector:- 动态数组,元素必须同类型(C++ 是静态类型,编译期检查);
- 同样支持增删改查、自动扩容;
- 示例:
std::vector<int> vec = {1, 2, 3};(仅存整数)。
-
关联记忆:
list是“更灵活的vector”(允许不同类型元素)。
- 元组(
tuple) vs C++std::tuple/const std::vector
-
Python
tuple:- 不可变的序列(创建后元素不能修改);
- 元素可任意类型;
- 示例:
(1, "apple", 3.14)。
-
C++ 替代方案:
std::tuple(C++11+):固定大小的异质集合(不同类型元素,如std::tuple<int, std::string, double>),但大小编译期固定,更接近 Python tuple 的“异质+不可变”特性。const std::vector:不可变的同类型数组(如const std::vector<int> vec = {1, 2, 3};),但仅支持同类型。
-
关联记忆:
tuple是“不可变的list”,和std::tuple都强调“不可变+异质元素”。
- 字典(
dict) vs C++std::unordered_map
-
Python
dict:- 键值对(key-value)容器,基于哈希表实现;
- 键必须是“可哈希”类型(如不可变类型:int、str、tuple 等),值任意类型;
- 无序(Python 3.7+ 因实现细节变为插入有序,但逻辑上仍视为无序哈希表);
- 示例:
{"name": "Alice", "age": 25}。
-
C++
std::unordered_map:- 键值对容器,基于哈希表实现;
- 键必须是“可哈希/可比较”类型(需自定义哈希函数或用内置类型),值同类型;
- 无序;
- 示例:
std::unordered_map<std::string, int> map = {{"name", "Alice"}, {"age", 25}};。
-
关联记忆:
dict和std::unordered_map是“异曲同工的哈希表键值对”。
- 集合(
set) vs C++std::unordered_set
-
Python
set:- 唯一元素的集合(自动去重),基于哈希表实现;
- 元素必须是“可哈希”类型;
- 无序;
- 示例:
{1, 2, 3, "apple"}。
-
C++
std::unordered_set:- 唯一元素的集合(自动去重),基于哈希表实现;
- 元素必须是“可哈希/可比较”类型;
- 无序;
- 示例:
std::unordered_set<int> set = {1, 2, 3};。
-
关联记忆:
set和std::unordered_set是“哈希表实现的自动去重集合”。
总结:核心关联逻辑
| Python 数据结构 | C++ 对应/替代容器 | 核心共性 | 关键差异(Python → C++) |
|---|---|---|---|
list | std::vector | 动态数组、自动扩容 | Python 支持异质元素,C++ 仅同类型 |
tuple | std::tuple / const std::vector | 不可变(或编译期固定) | Python 更灵活,C++ 类型更严格 |
dict | std::unordered_map | 哈希表键值对、无序 | Python 支持异质值,C++ 需同类型值 |
set | std::unordered_set | 哈希表去重集合、无序 | Python 支持异质元素,C++ 仅同类型 |
#数据结构
def test():#断言列表expect_list = [1, "apple", 3.14]actual_list = [1, "apple", 3.14]#断言元组expect_tuple = (1, "apple", 3.14)actual_tuple = (1, "apple", 3.14)#断言字典expect_dict = {"name": "Alice", "age" : 25}actual_dict = {"name": "Alice", "age" : 25}#断言集合expect_set = {1, 2, 3, "appple"}actual_set = {1, 2, 3, "apple"}assert expect_list == actual_listassert expect_tuple == actual_tupleassert expect_dict == actual_dictassert expect_set == actual_set
⽰例3:函数断⾔
def divide(a, b):assert b != 0, "除数不能为0"return a / b# 正常情况
print(divide(10, 2))#触发断言
print(divide(10, 0)) #抛出AssertionError:除数不能为0
8.参数化
参数化设计是自动化设计中的一个重要组成部分,它通过定义设计参数和规则,使得设计过程更加灵活和可控。pytest中内置的pytest.mark.parametrize装饰器允许对测试函数的参数进行参数化。示例1:在用例上使用参数化
⽰例1:在⽤例上使⽤参数化
import pytest@pytest.mark.parametrize("test_input, expected",[("3+5", 8),("2+4", 6),("6*9", 42)])
def test_eval(test_input, expected):assert eval(test_input) == expected
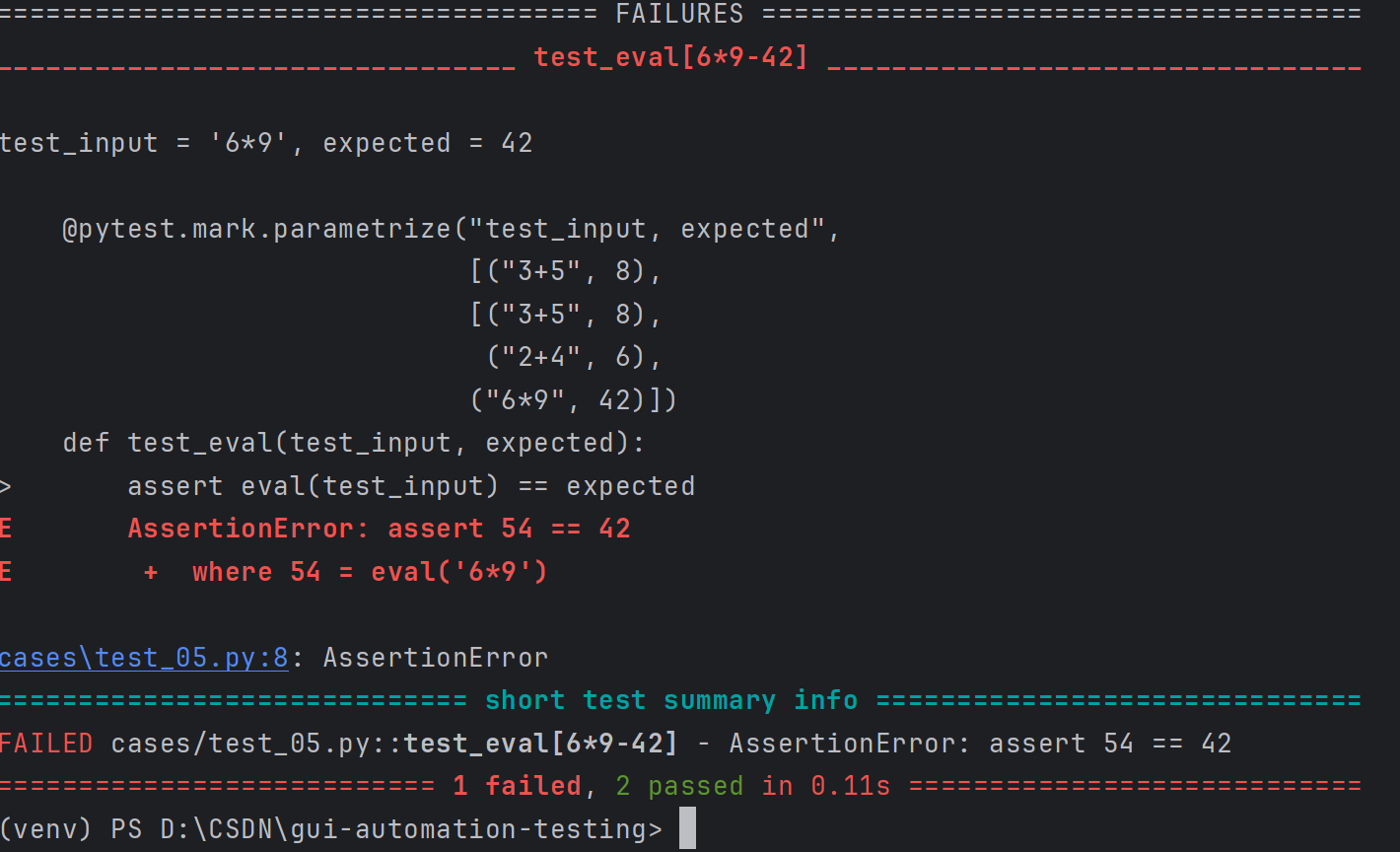
这里,@parametrize装饰器定义了三个不同的(test_input, expected)元组,以便test_eval函数将依次使用它们运行三次。
也可以在类或模块上使用parametrize标记,这将使用参数集调用多个函数
示例2:在类上使用参数化
@pytest.mark.parametrize("n, expected", [(1,2), (3, 4)])
class TestClass:def test_simple_case(self, n, expected):assert n+1 == expecteddef test_weird_simple_case(self, n, expected):assert (n*1) + 1 == expected
要对模块中的所有测试进行参数化,你可以将pytestmark 全局变量赋值:
除了使用@parametrize添加参数化外,pytest.fixture()允许对fixture函数进行参数化。
示例3:自定义参数化数据源
class TestClass02:def test_simple_case(self, n, expected):assert n + 1 == expecteddef test_weird_simple_case(self, n, expected):assert (n * 1) + 1 == expecteddef data_provider():return ["a", "b"]#定义一个测试函数,他依赖于上面函数的返回值
@pytest.mark.parametrize("data", data_provider())def test_data(data):assert data != Noneprint(f"Testing with data provider: {data}")
pytest中的fixture是一种强大的机制,用于提供测试函数所需的资源或上下文。它可以用于设置测试环境、准备数据等。以下是fixture的一些核心概念和使用场景.
9.1 基本使⽤
⽰例1:使⽤与不使⽤fixture标记
未标记fixture⽅法的调⽤
def fixture_01():print("第一个fixture")
def test_01():fixture_01()print("第一个测试用例")
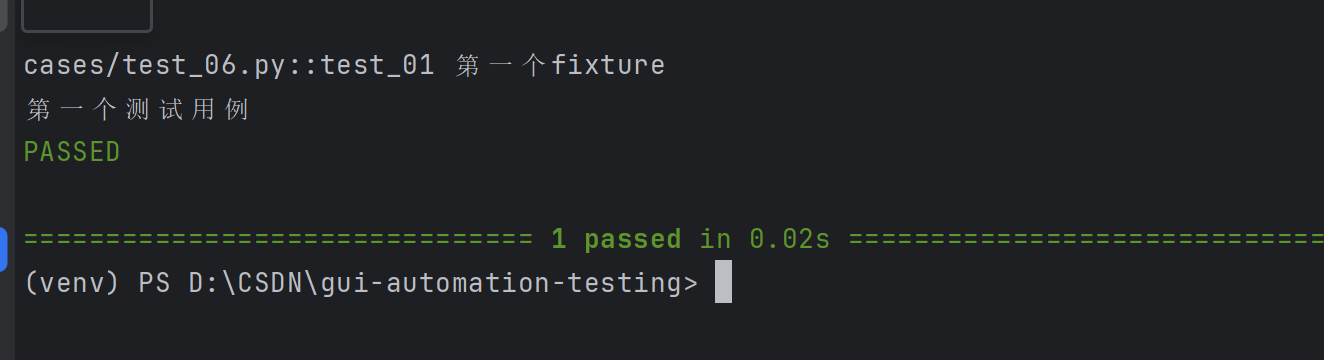
@pytest.fixture
def fixture_01():print("第一个fixture")def test_01(fixture_01):print("第一个测试用例")
未标记fixture方法的调用与fixture标记的方法调用完全不一样,前者需要在方法体中调用,而后者可以将函数名作为参数进行调用。
测试脚本中存在的很多重复的代码、公共的数据对象时,使用fixture最为合适
示例2:访问列表页和详情页之前都需要执行登录操作
@pytest.fixture
def login():print("------执行登录操作-------")
def test_list(login):print("----访问列表页")
def test_detail(login):print("---访问详情页")
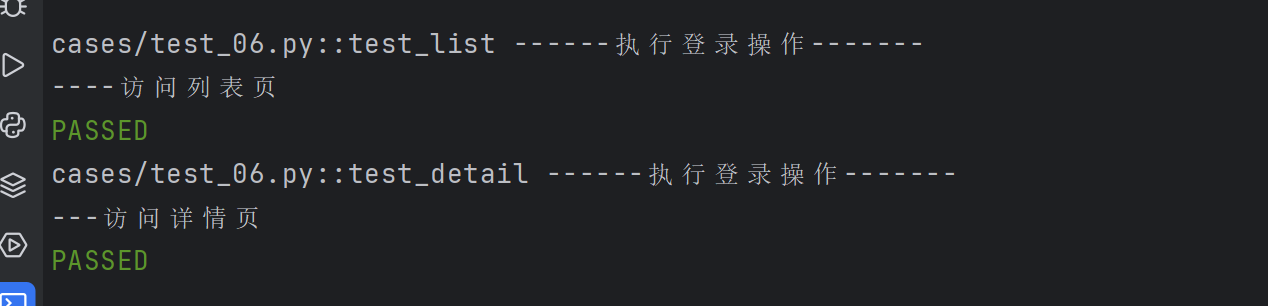
通过使用@pytest.fixture装饰器来告诉pytest一个特定函数是一个fixture,通过运行结果可见,在执行列表页和详情页之前都会先执行login方法。
二、菜单栏
2.1 fixture嵌套
#安排
@pytest.fixture
def first_entry():return "a"@pytest.fixture
def order(first_entry):return [first_entry]def test_string(order):#行动order.append("b")#断言assert order == ["a", "b"]
2.2 请求多个fixture
import pytestclass Fruit:def __init__(self, name):self.name = namedef __eq__(self, other):self.name == other.name@pytest.fixture
def my_fruit():return Fruit("apple")@pytest.fixture
def fruit_basket(my_fruit):return [Fruit("banana"), my_fruit]def test_my_fruit_in_basket(my_fruit, fruit_basket):assert my_fruit in fruit_basket
测试和fixture不仅限于一次请求单个fixture,它们可以请求任意多个。
2.3 yield fixture
当我们运行测试时,我们希望确保它们能够自我清理,以便它们不会干扰其他测试(同时也避免留下大量测试数据来膨胀系统)。plytest中的fixture提供了一个非常有用拆卸系统,它允许我们为每个fixture定义具体的清理步骤。
Yield” fixture使用yield而不是return。有了这些fixture,我们可以运行一些代码,并将对象返回给请求的fixture/test,就像其他fixture]一样。唯一的不同是:
- return被替换为yield。
- 该fixture的任何拆卸代码放置在yield之后。
一旦pytest确定了fixture的线性顺序,它将运行每个fixture直到它返回或yield,然后继续执行列表中的下一个fixture做同样的事情。
测试完成后,pytest将逆向遍历fixture列表,对于每个yield的fixture,运行yield语句之后的代码。
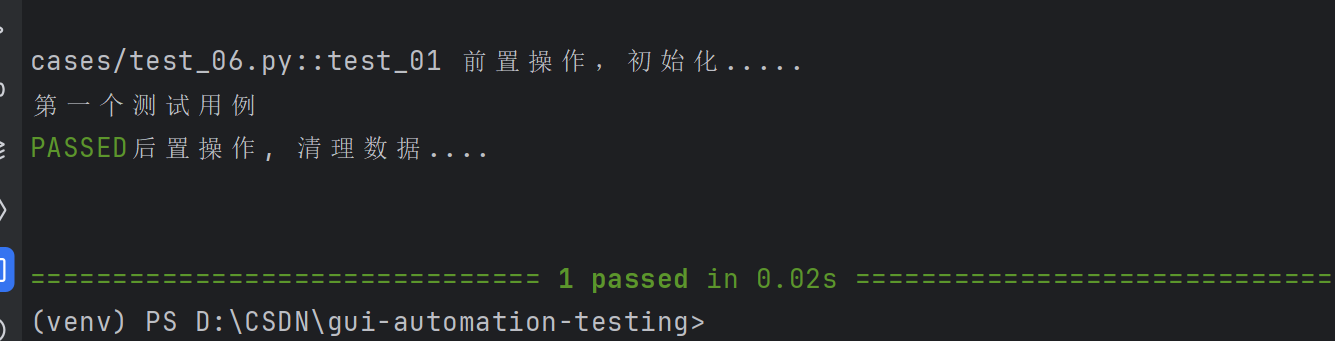
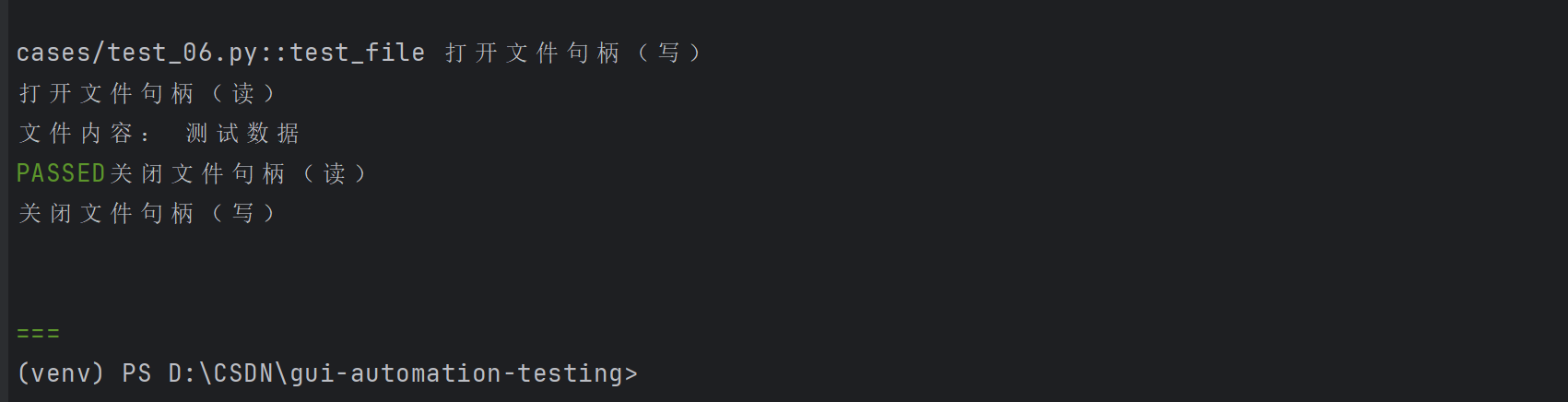
⽰例2:创建⽂件句柄与关闭⽂件
# ⽰例2:创建⽂件句柄与关闭⽂件
import pytest# 使用 yield 管理资源
@pytest.fixture
def file_read():print("打开文件句柄(读)")fo = open("test.txt", "r", encoding="utf-8") # 读取 test.txtyield fo # 提供文件句柄给测试用例print("关闭文件句柄(读)")fo.close() # 确保关闭@pytest.fixture
def file_write():print("打开文件句柄(写)")fo = open("test.txt", "w", encoding="utf-8") # 写入 test.txt(与读取的文件名一致)yield fo # 提供文件句柄给测试用例print("关闭文件句柄(写)")fo.close() # 自动关闭,无需测试用例手动调用def test_file(file_write, file_read):# 写入数据(使用 file_write 的句柄)file_write.write("测试数据")# 注意:写入后需刷新缓冲区(或在 fixture 中用 yield 确保关闭后再读取)# 因为 file_write 的 yield 会在测试用例执行后才关闭文件,这里需要手动刷新file_write.flush() # 刷新缓冲区,确保数据写入磁盘# 读取数据(使用 file_read 的句柄)content = file_read.read(10)print("文件内容:", content)assert content == "测试数据" # 验证内容正确
2.3 带参数的fixture
pytest.fixture(scope='', params='', autouse='', ids='', name='')
参数详解:
scope参数用于控制fixture的作用范围,决定了fixture的生命周期。可选值有:。
-
function(默认)︰每个测试函数都会调用一次fixture。
-
class:在同一个测试类中共享这个fixture。
-
module:在同一个测试模块中共享这个fixture。(一个文件里)。
-
session:整个测试会话中共享这个fixture。
autouse参数默认为False]。如果设置为(True,则每个测试函数都会自动调用该fixture,无需显式传入
params参数用于参数化fixture,支持列表传入。每个参数值都会使fixture执行一次,类似于for循环
ids参数与params 配合使用,为每个参数化实例指定可读的标识符(给参数取名字)
.name参数用于为fixture显式设置一个名称。如果使用了name,则在测试函数中需要使用这个名称来引用fixture(给fixture取名字) -
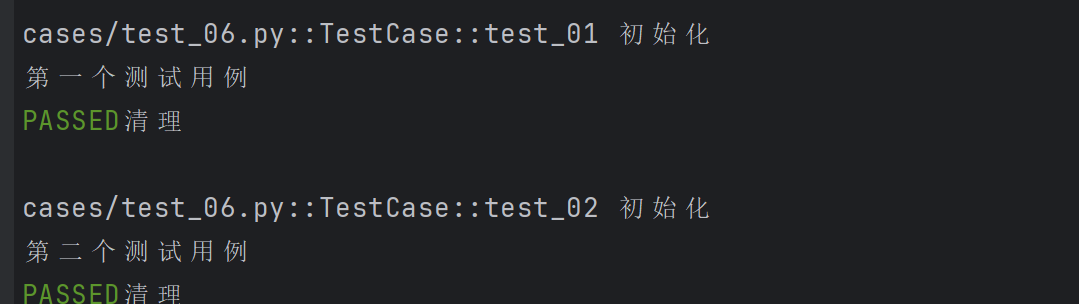
scope=“function”
import pytest@pytest.fixture(scope="function")
def fixture_01():print("初始化")yieldprint("清理")class TestCase():def test_01(self, fixture_01):print("第一个测试用例")def test_02(self, fixture_01):print("第二个测试用例")
- scope=“class”
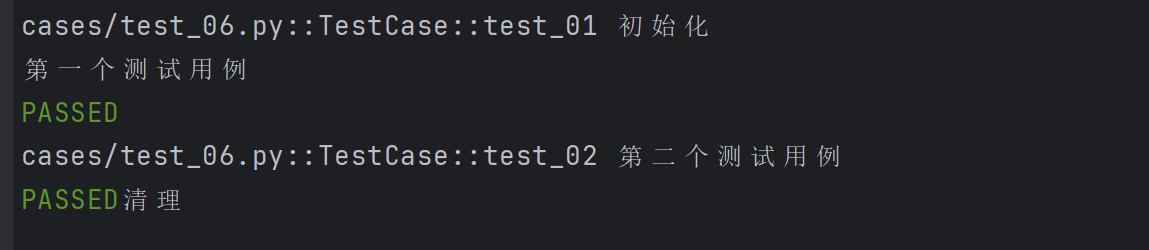
@pytest.fixture(scope="class")
def fixture_01():print("初始化")yieldprint("清理")class TestCase():def test_01(self, fixture_01):print("第一个测试用例")def test_02(self, fixture_01):print("第二个测试用例")
没错他们的正和前面的这四个对应效果一样:setup_method和teardown_method,setup_class和teardown_class
结论:
- scope默认为function ,这里的function可以省略不写,当scope=“function”)时,每个测试函数都会调用一次fixture 。scope=“class”)时,在同一个测试类中,fixture只会在类中的第一个测试函数开始前执行一次,并在类中的最后一个测试函数结束后执行清理。
- 当scope=“moudle” 、scope="session"时可用于实现全局的前后置应用,这里需要多个文件的配合
conftest.py和epytest.fixture结合使用实现全局的前后置应用
@pytest.fixture 与conftest.py文件结合使用,可以实现在多个测试模块(.py)文件中共享前后置操作,这种结合的方式使得可以在整个测试项目中定义和维护通用的前后置逻辑,使测试代码更加模块化和可维护。
规则:
conftest.py是一个单独存放的夹具配置文件,名称是固定的不能修改
你可以在项目中的不同目录下创建多个conftest.py文件,每个conftest.py文件都会对其所在目录及其子目录下的测试模块生效
在不同模块的测试中需要用到conftest.py的前后置功能时,不需要做任何的import导入操作
·作用:可以在不同的.py文件中使用同一个fixture函数
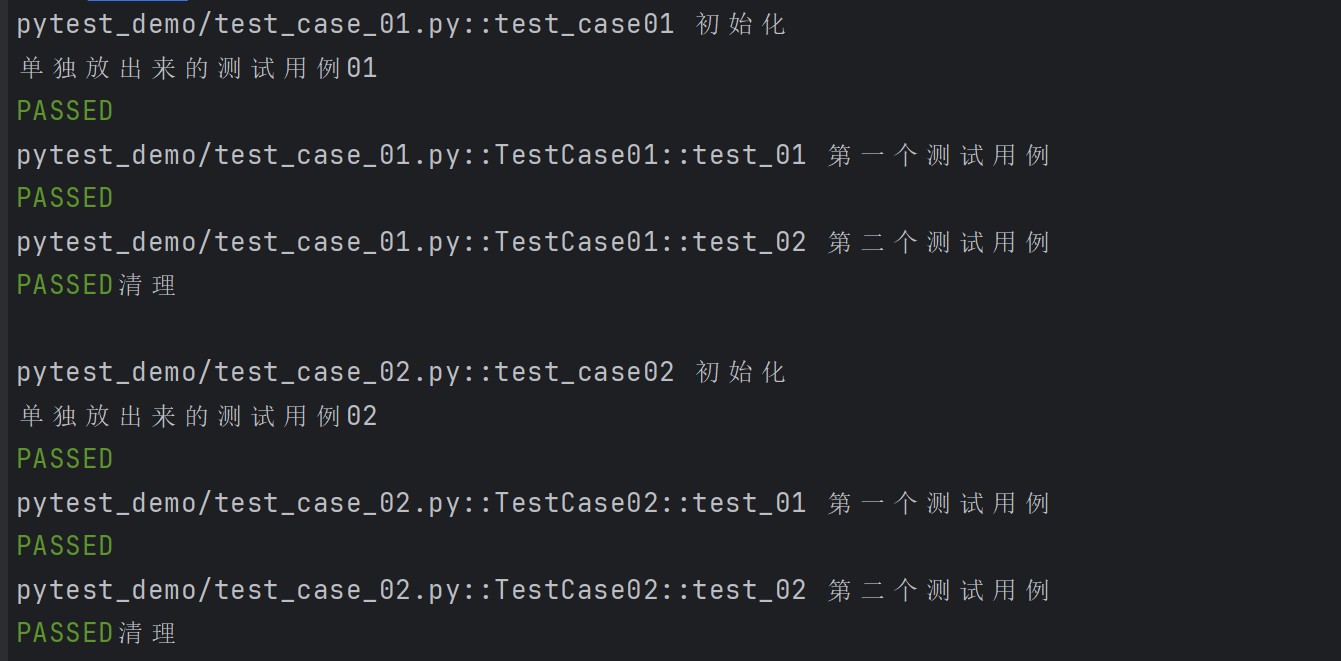
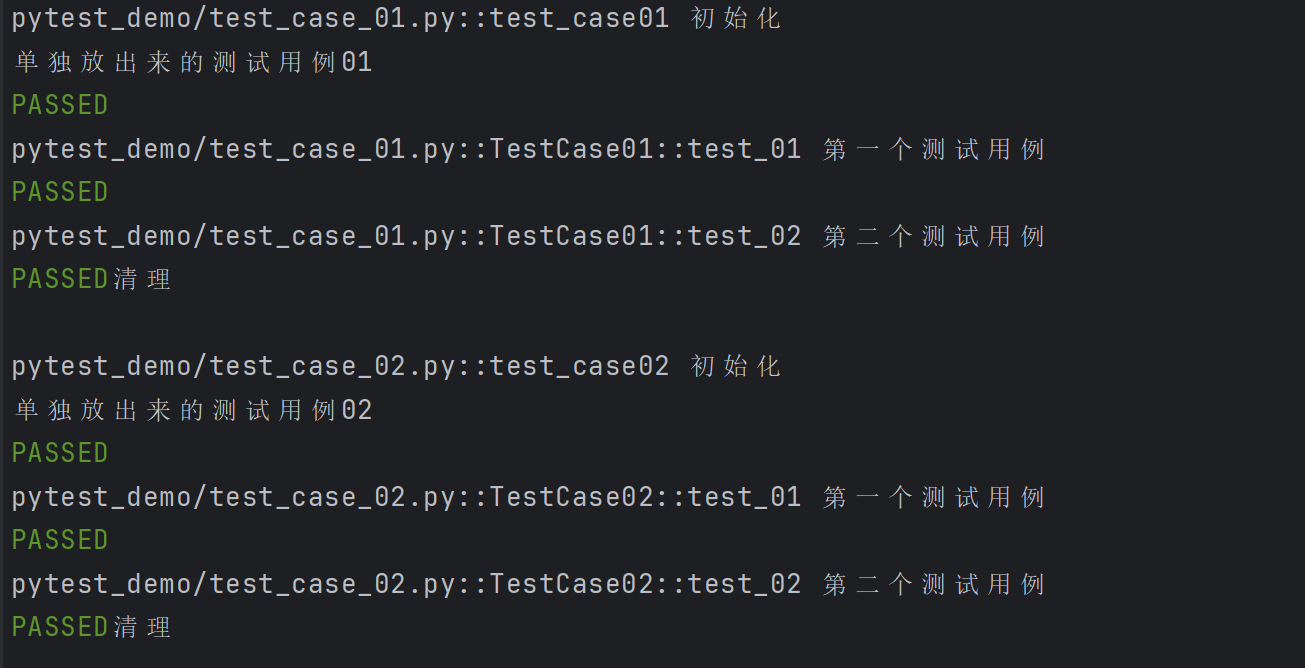
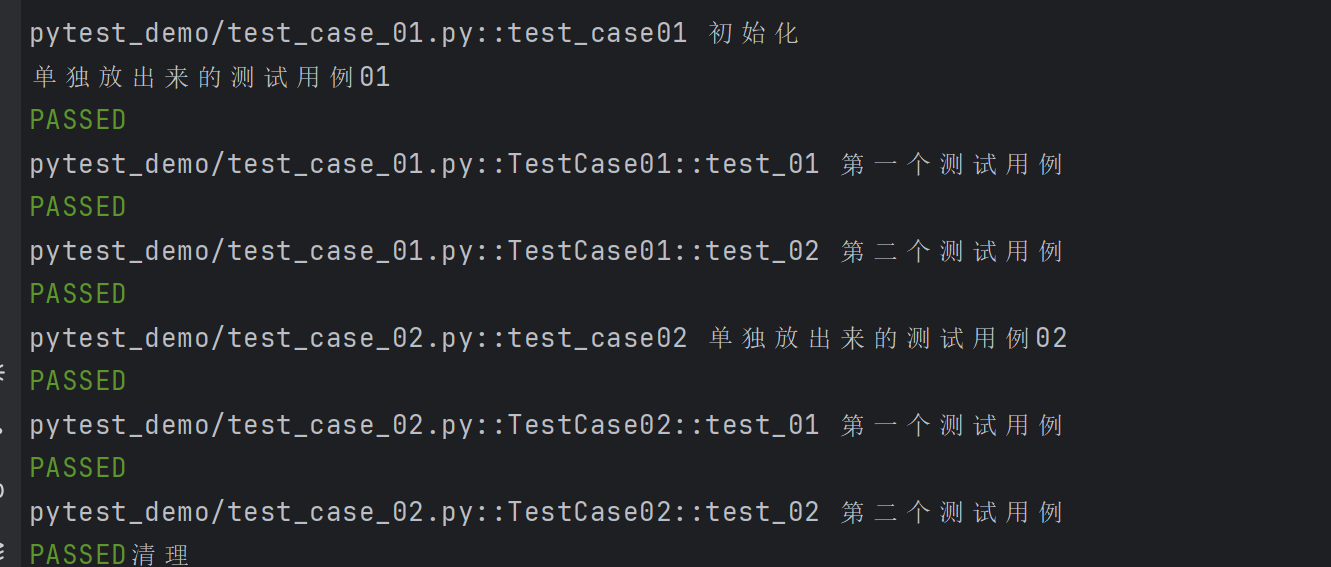
示例2: scope=“moudle” 、scope="session"实现全局的前后置应用
test_case_01.py
def test_case01():print("单独放出来的测试用例01")class TestCase01():def test_01(self):print("第一个测试用例")def test_02(self):print("第二个测试用例")
test_case_02.py
def test_case02():print("单独放出来的测试用例02")class TestCase02():def test_01(self):print("第一个测试用例")def test_02(self):print("第二个测试用例")
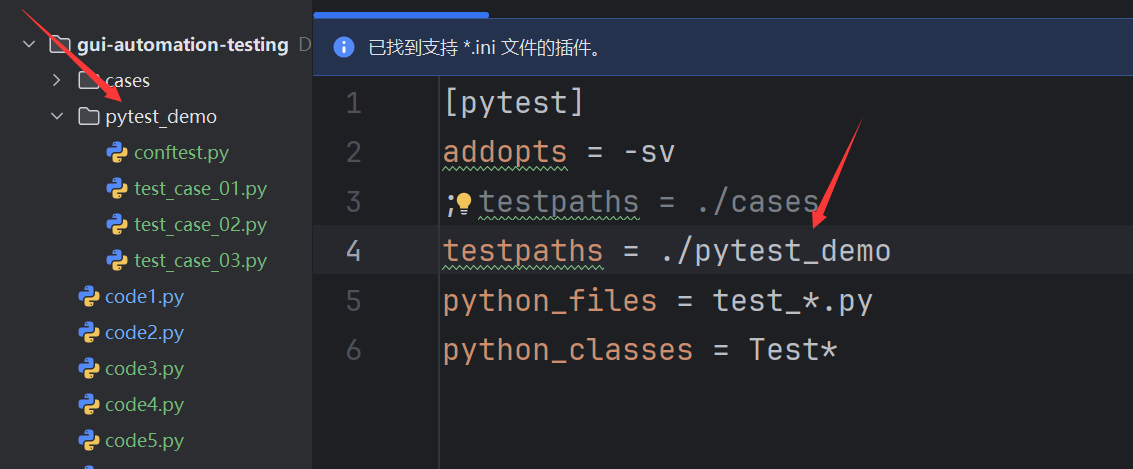
conftest.py 文件
@pytest.fixture(scope="module", autouse=True)
def fixture_01():print("初始化")yieldprint("清理")
@pytest.fixture(scope="session", autouse=True)
def fixture_01():print("初始化")yieldprint("清理")
 ⽰例3:autouse 的使⽤
⽰例3:autouse 的使⽤
import pytest
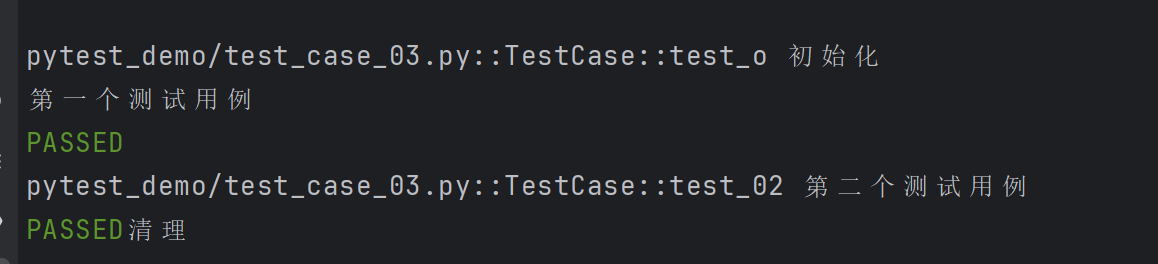
@pytest.fixture(scope="class", autouse=True)
def fixture_o1():print( "初始化")yieldprint("清理")class TestCase( ):def test_o(self):print("第一个测试用例")def test_02(self):print("第二个测试用例")
autouse 默认为False ,即当前的fixture需要手动显示调用,在该案例之前我们默认使用的都是autouse=False
当autouse=True时,fixture 会在所有测试函数执行之前自动调用,无论这些测试函数是否显式地引用了该fixture
示例4:通过params实现参数化
import pytest@pytest.fixture(params=["a", "b"])
def data_provider(request):return request.param#定义一个测试函数,它依赖于上面的参数化 fixture
def test_data(data_provider):assert data_provider != Noneprint(f"Testing with data provider: {data_provider}")
前面我们已经学过pytest中通过@pytest.mark.parametrize实现参数化,通过 fixture也可以实现参数化,那么到底哪一种更好呢?
如果测试场景主要涉及简单的参数传递,且不需要复杂的资源管理,建议使用parametrize,因为它更简单直接;如果测试需要动态加载外部数据,或者需要管理复杂的测试资源〈如数据库连接、文件操作等),建议使用fixture,在某些情况下,也可以结合使用parametrize和 fixture,以充分利用两者的优点。总结来说,parametrize更适合简单场景,而fixture更适合需要动态数据和资源管理的复杂场景。
2.4 指定⽤例执⾏顺序
在使⽤pytest进⾏测试时,有时候我们需要按照特定的顺序来运⾏测试⽤例,尤其是在涉及到测试⽤例之间的依赖关系时。pytest本⾝并不直接⽀持通过配置来改变测试⽤例的默认运⾏顺序,pytest-order是⼀个第三⽅插件,专⻔⽤于控制测试⽤例的执⾏顺序。⾸先,你需要安装这个插件:
pip install pytest-order==1.3.0
既可以⽤在测试类上,也可以⽤在测试⽅法上,以测试类为例:
import pytest@pytest.mark.order(1)
def test_one():assert True@pytest.mark.order(2)
def test_two():assert True

🚩总结
