数据结构1:顺序表
目录
前言
一、数据结构
二、顺序表
1、顺序表的概念
2、顺序表的分类
2.1顺序表和数组的区别
2.2静态顺序表
2.3动态顺序表
三、动态顺序表的实现
3.1初始化和销毁、打印
3.2头插和尾插
3.3头删和尾删
3.4指定位置插入/删除数据
3.5顺序表的查找
四、通讯录
4.1结构体的定义
4.2通讯录的初始化和销毁
4.3添加通讯录数据
4.4删除数据
4.5展示通讯录数据
4.6修改通讯录数据
4.7查找通讯录数据
最后
前言
本文介绍了数据结构中的顺序表及其在通讯录项目中的应用。主要内容包括:1.数据结构概念,将数据组织成特定结构以便高效存储和访问;2.顺序表原理,作为数组的封装提供增删改查接口,分为静态和动态两种;3.动态顺序表实现,详述初始化、扩容、头尾操作等核心功能;4.通讯录项目开发,通过修改顺序表数据类型实现联系人管理功能,包括添加、删除、查找等操作。文章通过生活化比喻(如羊圈与数据)帮助理解技术概念,并附完整代码示例。
一、数据结构
数据结构是数据和结构两个词组合。数据,简单理解就是一些信息,比如通讯录里保存的用户信息、姓名、年龄等等和一些网页里可以看到的文字、图片、视频等等。结构,就是当我们想要大量使用同⼀类型的数据时,通过手动定义大量的独立的变量对于程序来说,可读性非常差,我们可以借助数组这样的数据结构将大量的数据组织在一起,结构也可以理解为组织数据的方式。
我们可以把数据理解成很多只在草原上随意奔跑的小羊,当你想找一只叫”cc”的羊的时候,会无从下手,但是从羊圈里找到cc羊就很简单,羊圈这样的结构有效将羊群组织起来。
二、顺序表
1、顺序表的概念
我们在数组中想要修改数据,可以直接arr[i] = x,插入一个数据可以找到数组中已有的元素个数再插入数据,删除一个数据可以找到数组中已有的元素个数再删除数据。顺序表就是在数组的底层逻辑下提供了很多现成的方法,直接可以使用,于是就成了一个很厉害的数据结构
就像我们在普通饭店里喝粥就很简答就叫做白粥,但如果你去米其林里吃饭,也是白粥,但它可能就叫做超级无敌白粥,它们没有什么大的区别,超级无敌白粥只是比白粥多了个摆盘而已。数组就像白粥,顺序表就是超级无敌白粥。
顺序表也是线性表的一种,线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的,线性表在物理上存储时,通常以数组和链式结构的形式存储。顺序表在物理和逻辑上都是连续的。我们可以通俗一点去理解,物理结构上连续,就是一种踏实的连续,arr[0]后面一定是arr[1],它们在内存中就排成规规矩矩的一排。逻辑结构上的连续像是你知道它在你前面,就像吃饭排队一样,不一定是很规矩的站成一排,但你知道你是6号前面就一定是5号。
2、顺序表的分类
2.1顺序表和数组的区别
2.2静态顺序表
使用定长数组储存元素,但有缺点是空间给少了不够用,给多了造成空间浪费。
//静态顺序表
typedef struct SeqList
{int arr[100];int size;
}SL;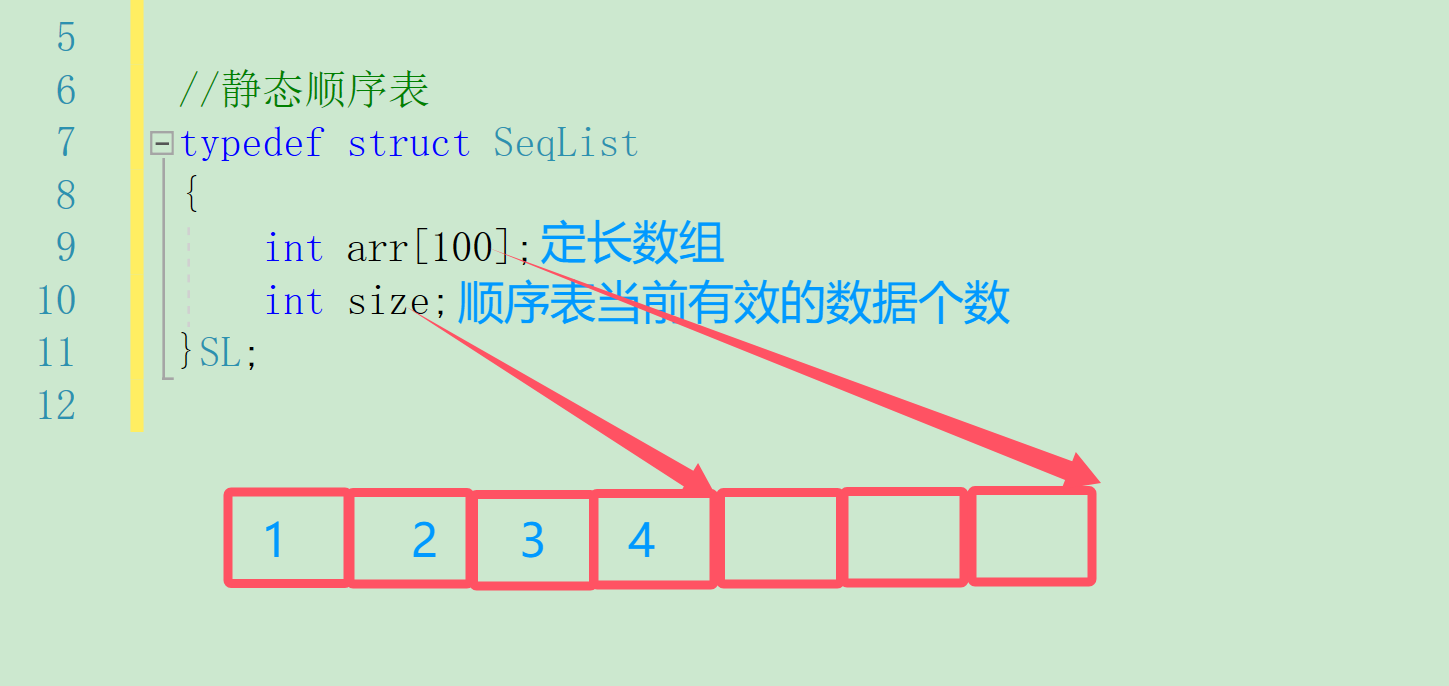
2.3动态顺序表
按需申请空间储存数据,所以我们使用一般都是用动态顺序表
//动态顺序表
typedef struct SeqList
{int* arr;int size;int capacity;
}SL;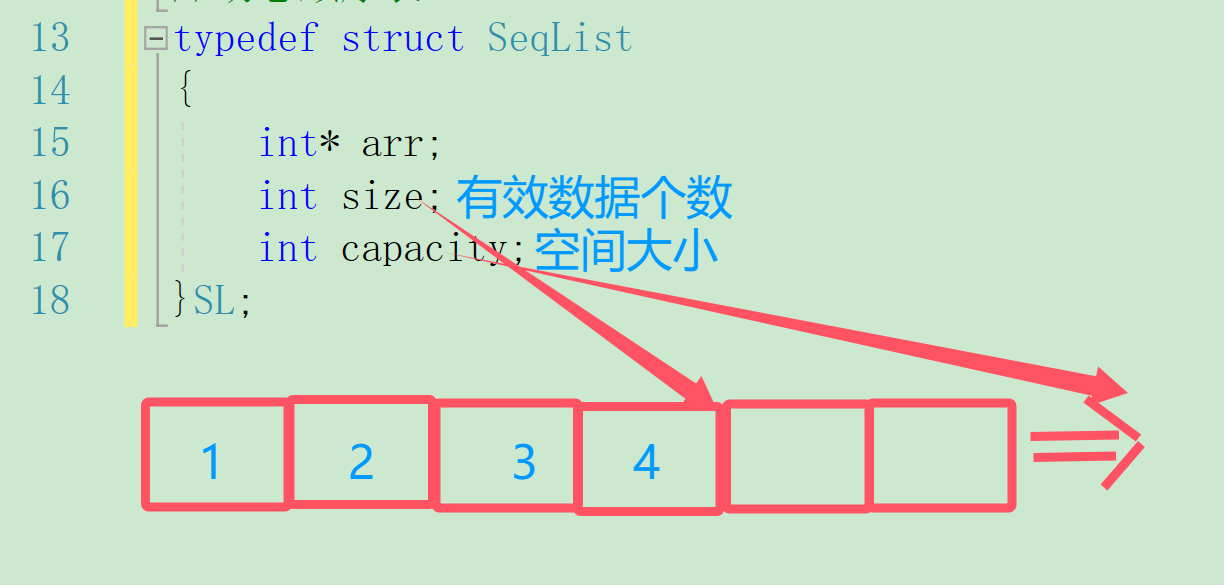
三、动态顺序表的实现
我们在实现动态顺序表的时候会发现把数组的类型定义很奇怪,这是因为数组所能保存的不只是int型,也许以后我们要把这个顺序表拿出来用的时候,是储存别的类型的数据,如果一个一个去改变的话,实在是太麻烦了。因此,我们可以直接用typedef定义一下,后续要用的时候直接改就好了。(注意:不要把size和capacity也改了,有效数据个数和空间大小是int型)
typedef int SLDataType;
//动态顺序表
typedef struct SeqList
{SLDataType* arr;int size;int capacity;
}SL;想要完成顺序表的实现需要初始化、销毁、扩容、头部插入删除,尾部插入删除等,我们要学会边写边调试。
3.1初始化和销毁、打印
我们在初始化的时候可能会直接想要通过传值的方法传递,但这个方法不可行,因为传值是属于值拷贝,我们所定义的s1里都没有数值怎么可能传递数据,所以报错如下
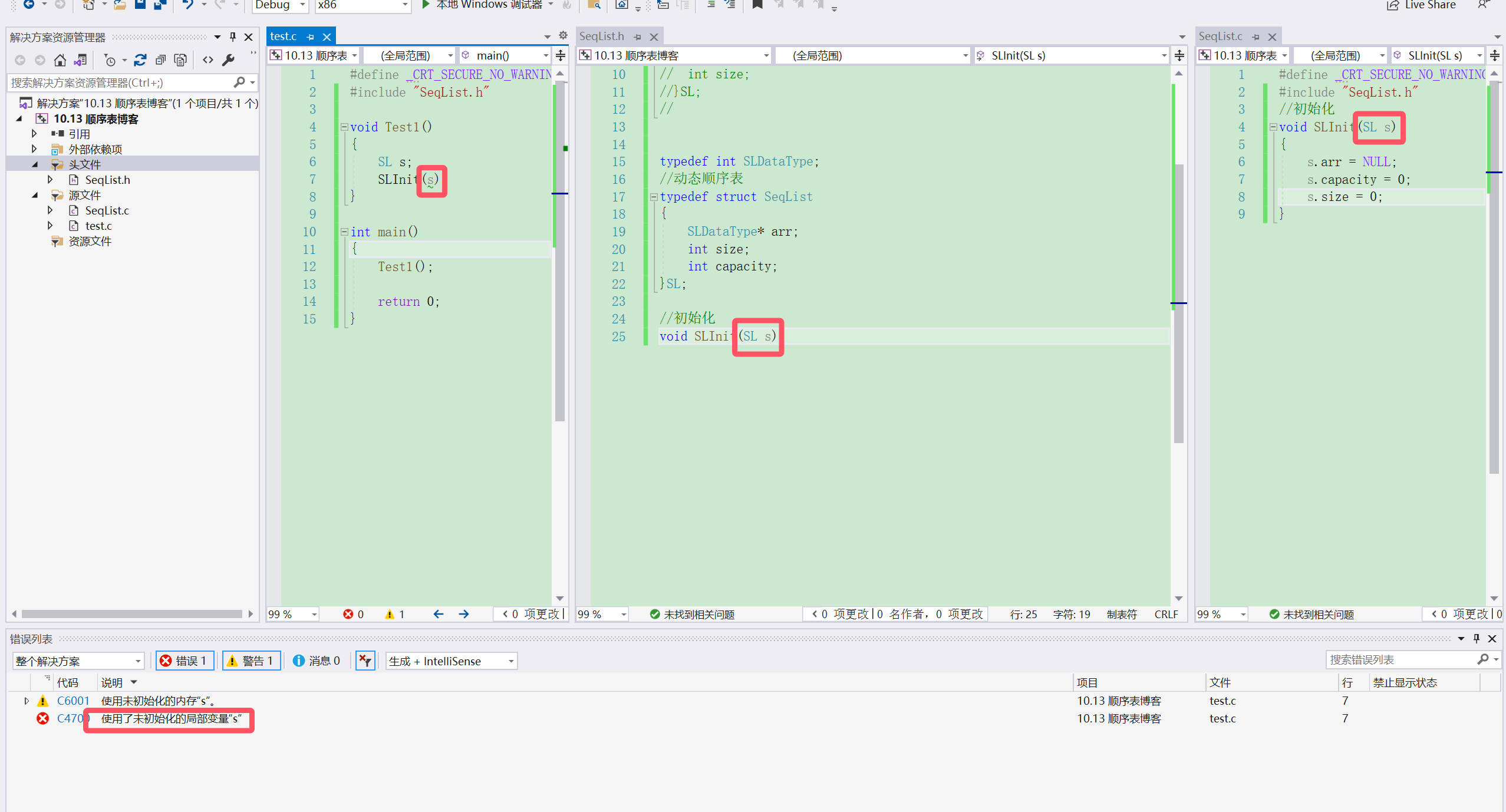
我们还要注意的是我们通过指针传值,需要把指针操作符"."改成"->",因为”.“ 操作对象是“对象本身”,直接通过对象名访问其成员,” ->“ 操作对象是“指向对象的指针”,通过指针间接访问它所指向对象的成员。若把对象看作“房子”,. 是直接用钥匙开门(钥匙=对象名),-> 是先找到持有钥匙的人(人=指针),再让他用钥匙开门。
//初始化
void SLInit(SL* s)
{s->arr = NULL;s->capacity = 0;s->size = 0;
}销毁就需要释放空间,然后把指针置为空指针,把变量置为0
//销毁
void SLDestroy(SL* s)
{if (s->arr){free(s->arr);}s->arr = NULL;s->size = 0;s->capacity = 0;
}打印
//打印
void SLPrint(SL s)
{for (int i = 0; i < s.size; i++){printf("%d ", s.arr[i]);}printf("\n");
}
3.2头插和尾插
尾插顾名思义就是在尾部插入数据,在插入数据前我们要先判断内存够不够,然后才能插入数据,插入数据时我们可以注意到数组中下标是size的位置就是应该插入的位置
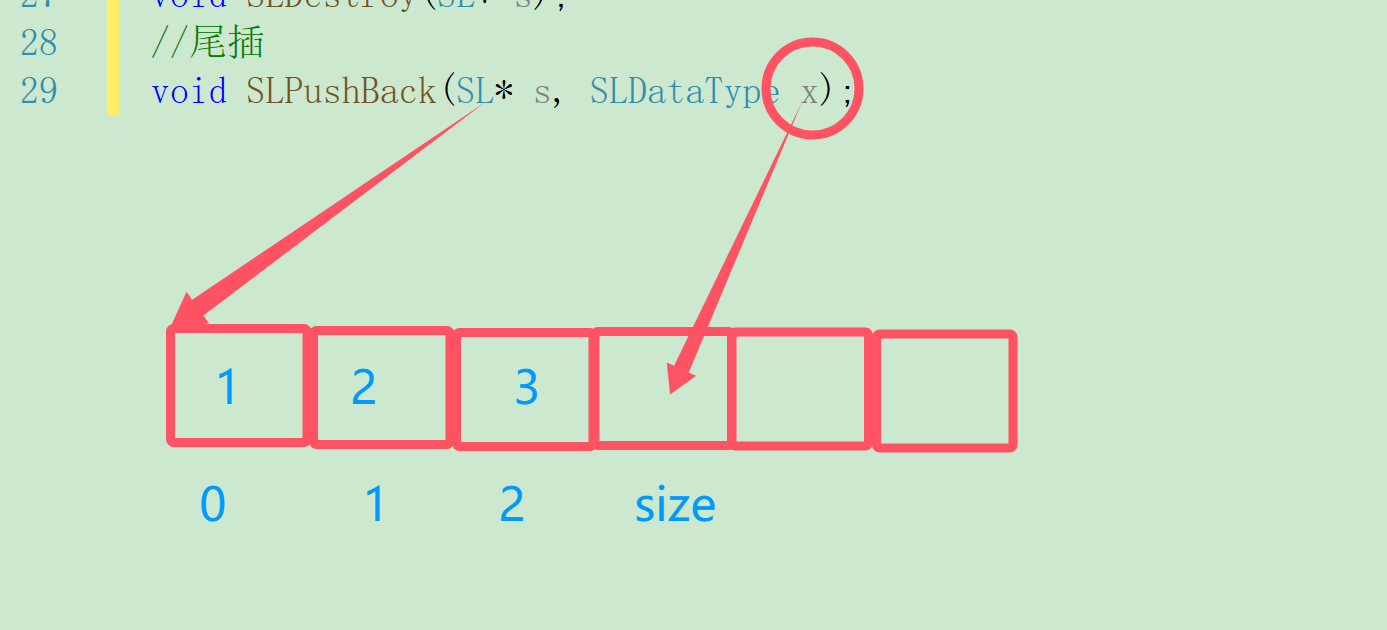
判断内存并扩容
在一开始我们是没有定义内存空间大小,所以在判断内存的时候要用三目操作符,如果为0的话需要赋值,如果已经赋值则让它成倍数增加。
我们扩容内存的时候要成倍数扩容,这是因为1. 降低增容频率:若每次只增容固定大小(如每次加10),频繁插入数据会不断触发增容,每次增容需拷贝所有数据,总时间复杂度会从O(n)飙升到O(n²);而倍数增容能让增容次数大幅减少,整体趋近于O(n)。 2. 控制空间浪费:倍数增容虽会预留部分空间,但相比“一次性分配极大空间”更灵活,且通过数学证明(如2倍增容),累计浪费的空间不会超过当前总容量,处于可接受范围。就像给杯子加水,每次把杯子换成2倍大的(倍数增容),比每次只加10毫升水(固定增容)更省事,且不会浪费过多桌面空间。
void SLCheckCapacity(SL* s)
{if (s->capacity == s->size){//判断capacity是否为0int newCapacity = s->capacity == 0 ? 4 : 2 * s->capacity;SLDataType* tmp = (SLDataType*)realloc(s->arr, newCapacity * sizeof(SLDataType));if (tmp == NULL){perror("realloc fail");exit(1);}s->arr = tmp;s->capacity = newCapacity;}}//尾插
void SLPushBack(SL* s, SLDataType x)
{SLCheckCapacity(&s);s->arr[s->size] = x;s->size++;
}我们可以通过打印判断代码是否正确
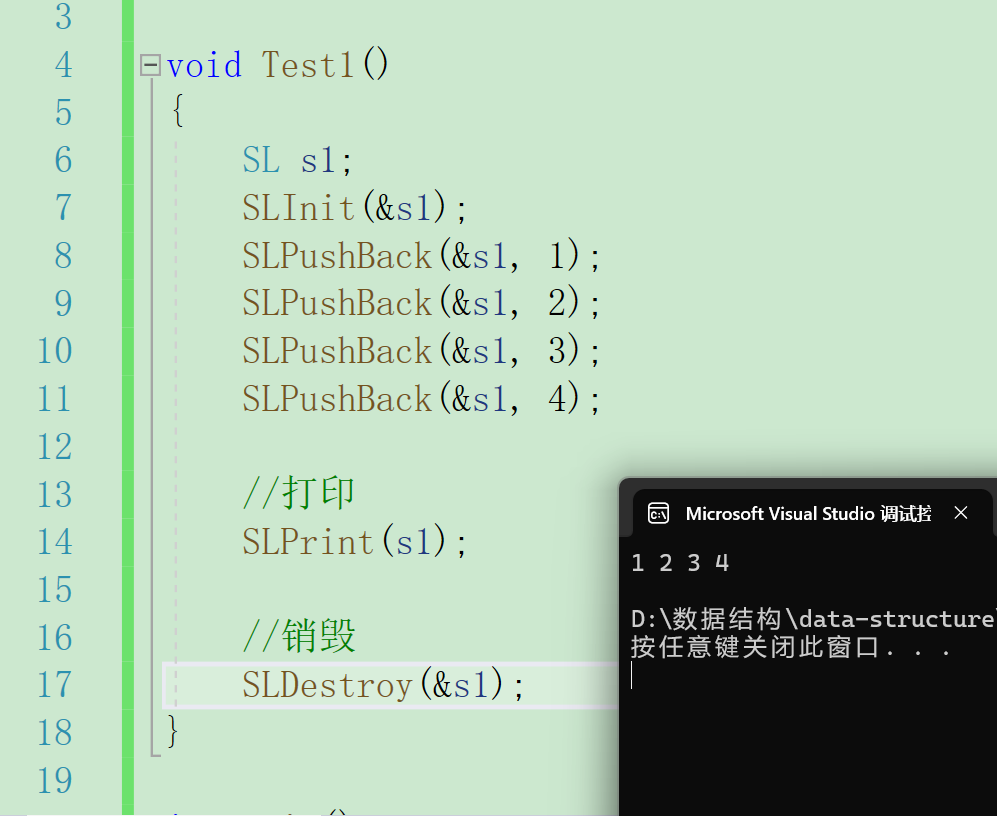
头插顾名思义就是在尾部插入数据,在插入数据前我们要先判断内存够不够,所有数据都要向后移一位然后才能插入数据。向后移动的时候我们发现第一个移动的是下标为size的位置,移动时的循环就从arr[size]开始。最后一次移动应该是arr[0]= arr[1]
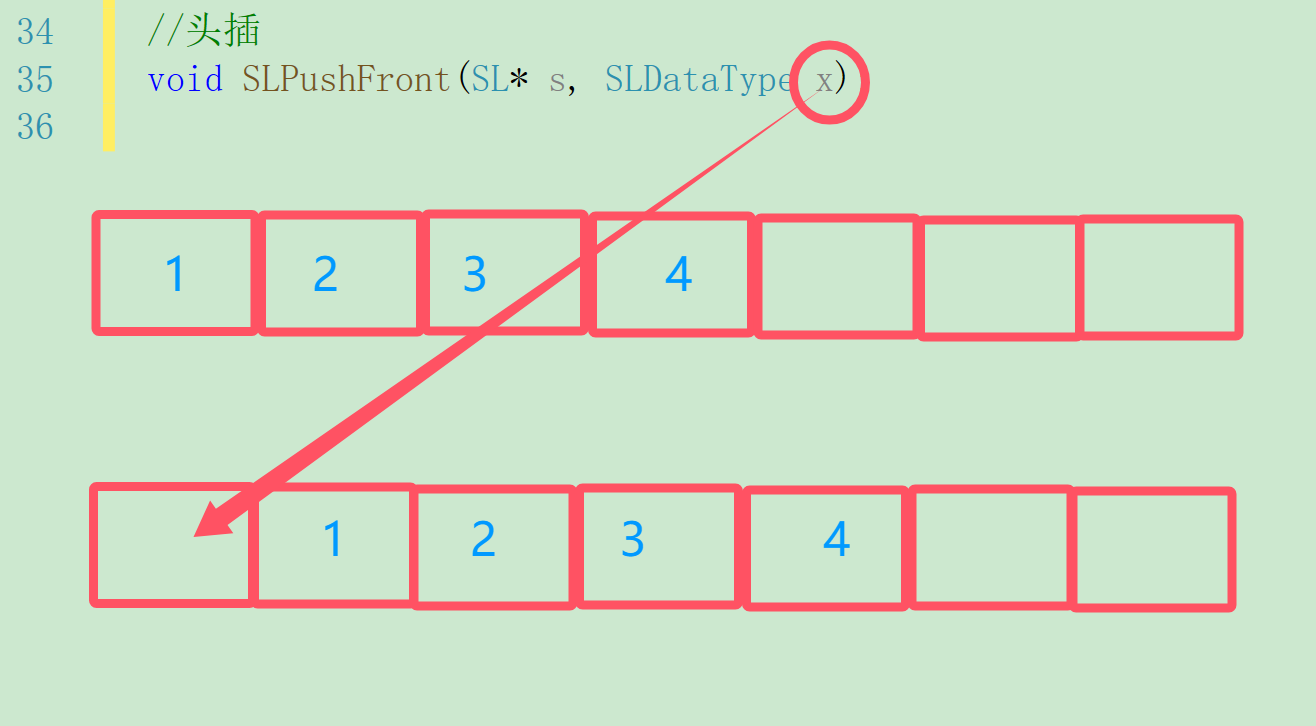
//头插
void SLPushFront(SL* s, SLDataType x)
{assert(s);SLCheckCapacity(s);//让顺序表的数据整体往后移动一位for (int i = s->size; i > 0; i--){s->arr[i] = s->arr[i - 1];}s->arr[0] = x;s->size++;
}我们可以通过打印判断代码是否正确
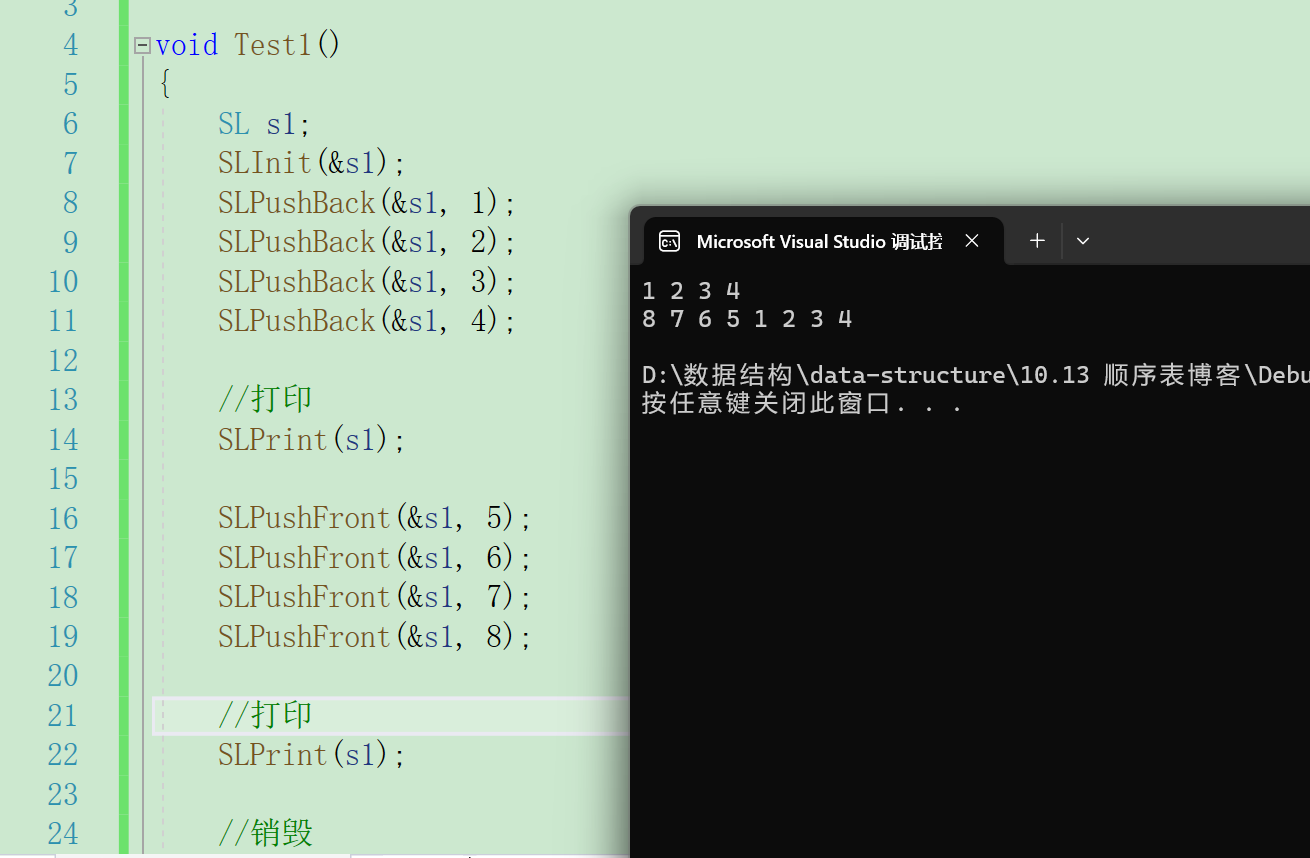
3.3头删和尾删
尾删顾名思义就是删除最后一个数据,s->arr[s->size - 1] = -1就是删除最后一个数据是因为选择-1是因为它是一个**“特殊值”**(通常业务场景中不会用-1表示有效数据),用来标识“这个位置的元素已经被删除,不再是有效数据”。实际开发中,也可以用其他特殊值(比如0xFFFFFF等),核心是和有效数据做区分。本质是“标记无效”:真正的“删除”是通过size--实现的——后续操作会以size作为有效元素的边界,不再访问size之后的位置(即使该位置还有旧数据)。而赋值-1只是让“已删除位置”的数据更直观地体现“无效”。就比如如果顺序表存的是学生成绩(成绩都是非负数),用-1标记“已删除”就很合理,后续遍历数据时,看到-1就知道这是无效项。
//尾删
void SLPopBack(SL* s)
{assert(s);assert(s->size);//顺序表不为空s->arr[s->size - 1] = -1;
}真正的删除应该是
//尾删
void SLPopBack(SL* s)
{assert(s);assert(s->size);//顺序表不为空//s->arr[s->size - 1] = -1;--s->size;
}我们可以通过打印判断代码是否正确
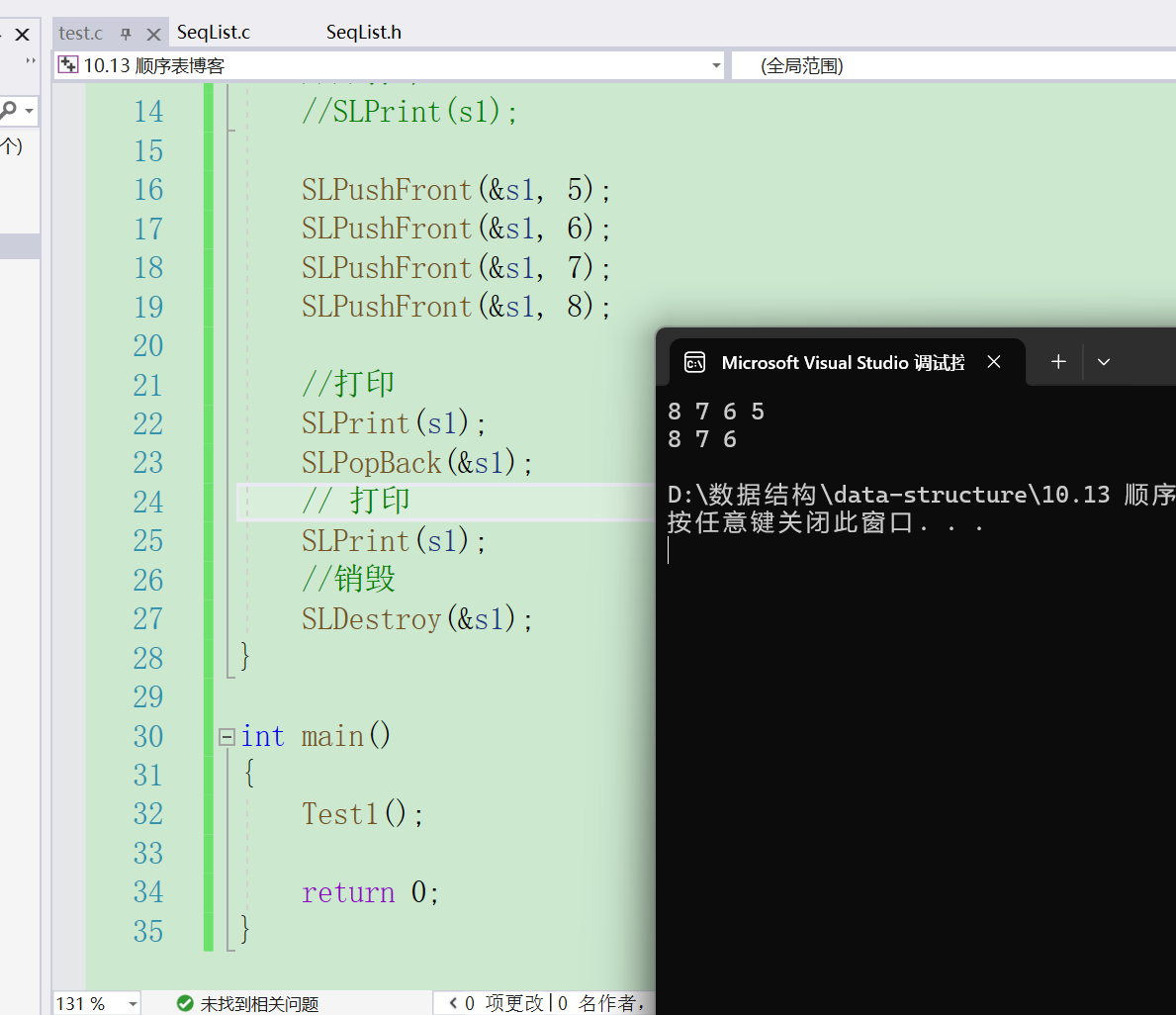
头删顾名思义就是删除第一个数据,所有数据要向前移动一位,最后一次应该是arr[size-1] = arr[size-2]。
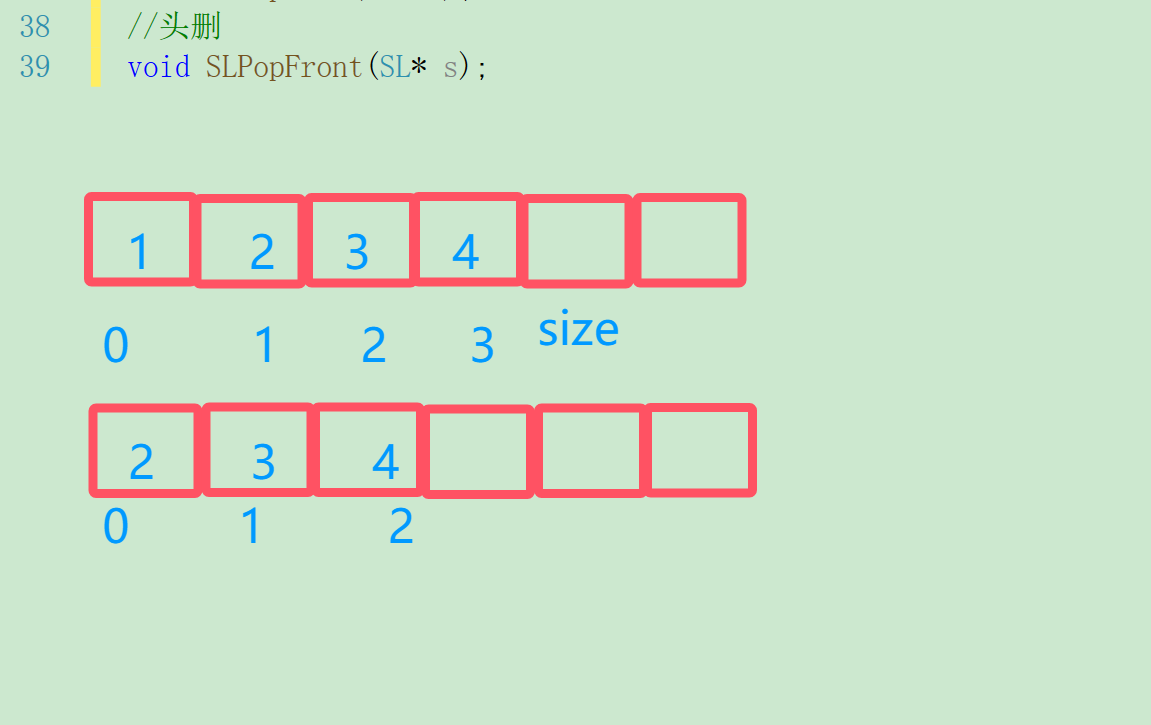
//头删
void SLPopFront(SL* s)
{assert(s);assert(s->size);//让顺序表的数据整体往前移动一位for (int i = 0; i < s->size - 1; i++){s->arr[i] = s->arr[i + 1];}s->size--;
}我们可以通过打印判断代码是否正确
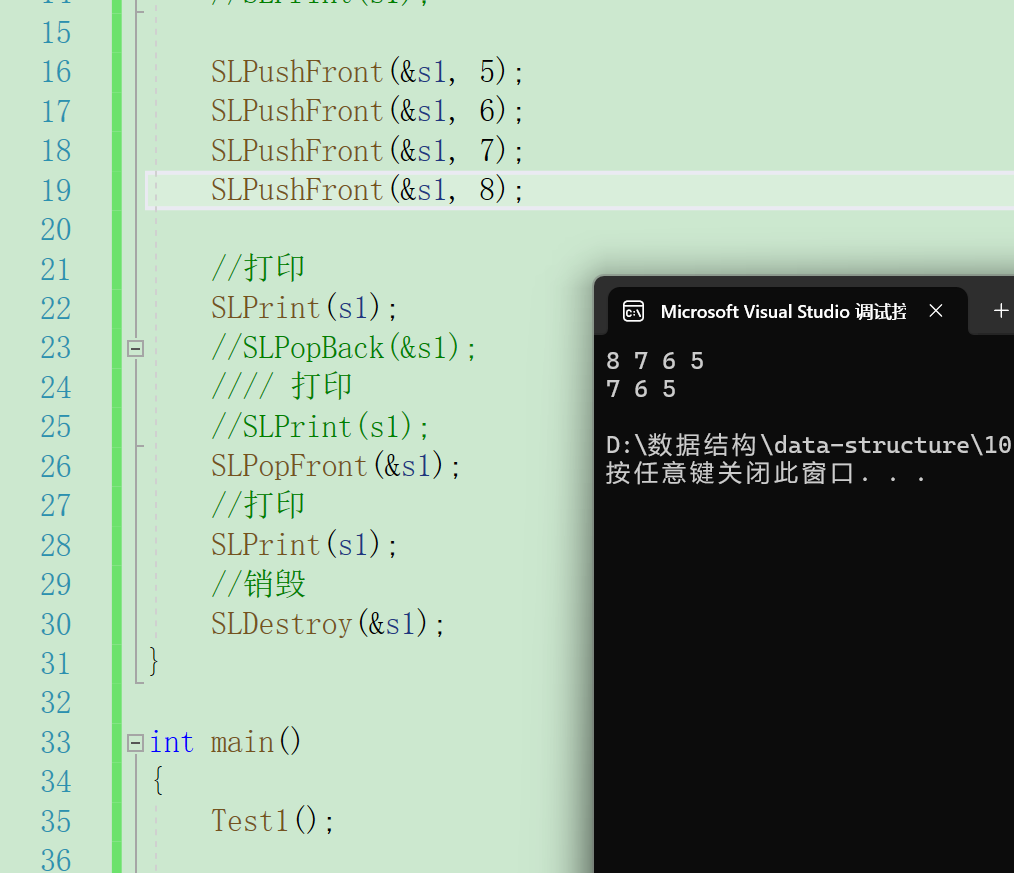
3.4指定位置插入/删除数据
指定位置插入数据要把指定位置之后的数据向后移动一位,再在那个位置插入数据。
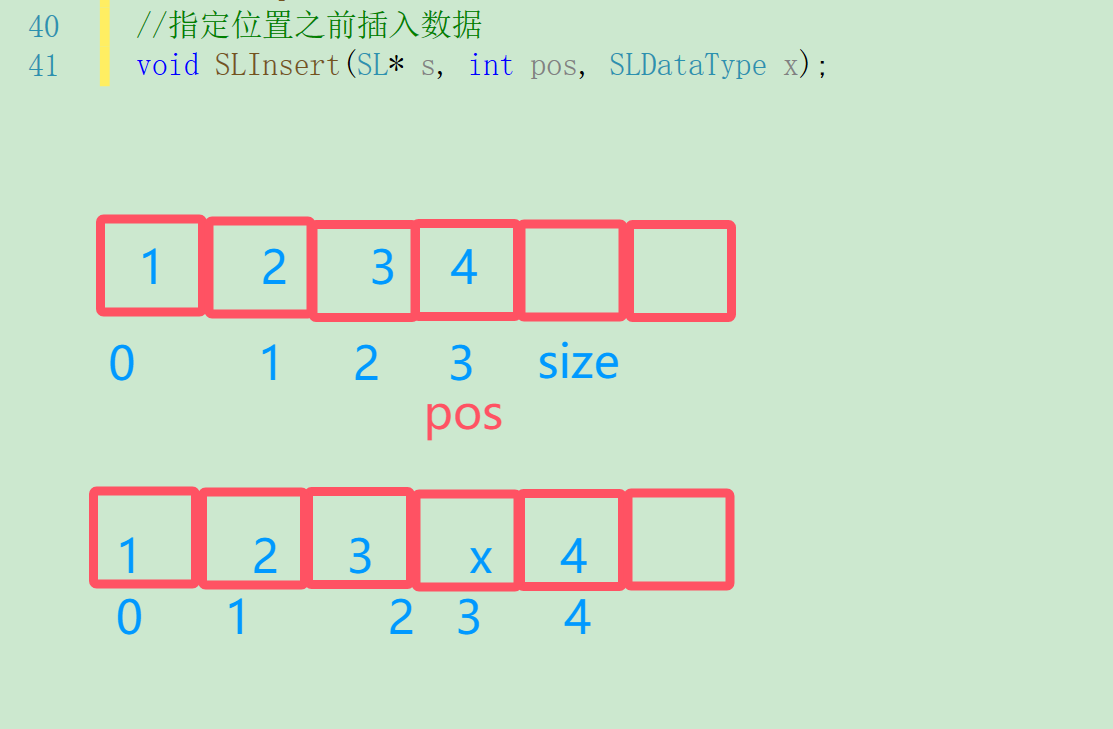
//指定位置之前插入数据
void SLInsert(SL* s, int pos, SLDataType x)
{assert(s);assert(pos >= 0 && pos <= s->size);SLCheckCapacity(s);for (int i = s->size; i > pos; i--){s->arr[i] = s->arr[i - 1];}s->arr[pos] = x;s->size++;
}我们可以通过打印判断代码是否正确
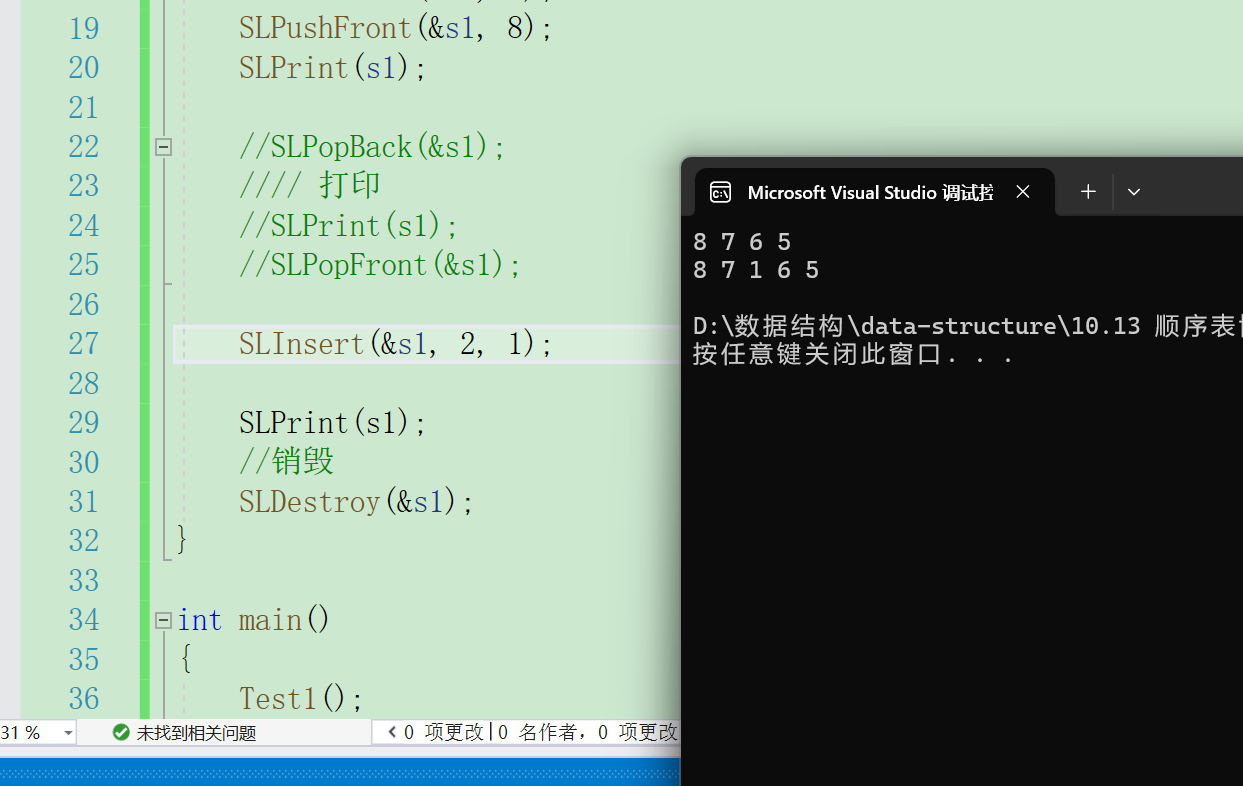
指定位置删除数据要把指定位置之后的数据向前移动一位,这里pos不能取到s->size,因为pos取那个位置就是在那个位置上进行操作,s->size都没有数据。
//删除指定位置的数据
void SLErase(SL* s, int pos)
{assert(s);assert(pos >= 0 && pos < s->size);for (int i = pos; i < s->size - 1; i++){s->arr[i] = s->arr[i + 1];}s->size--;
}我们可以通过打印判断代码是否正确
3.5顺序表的查找
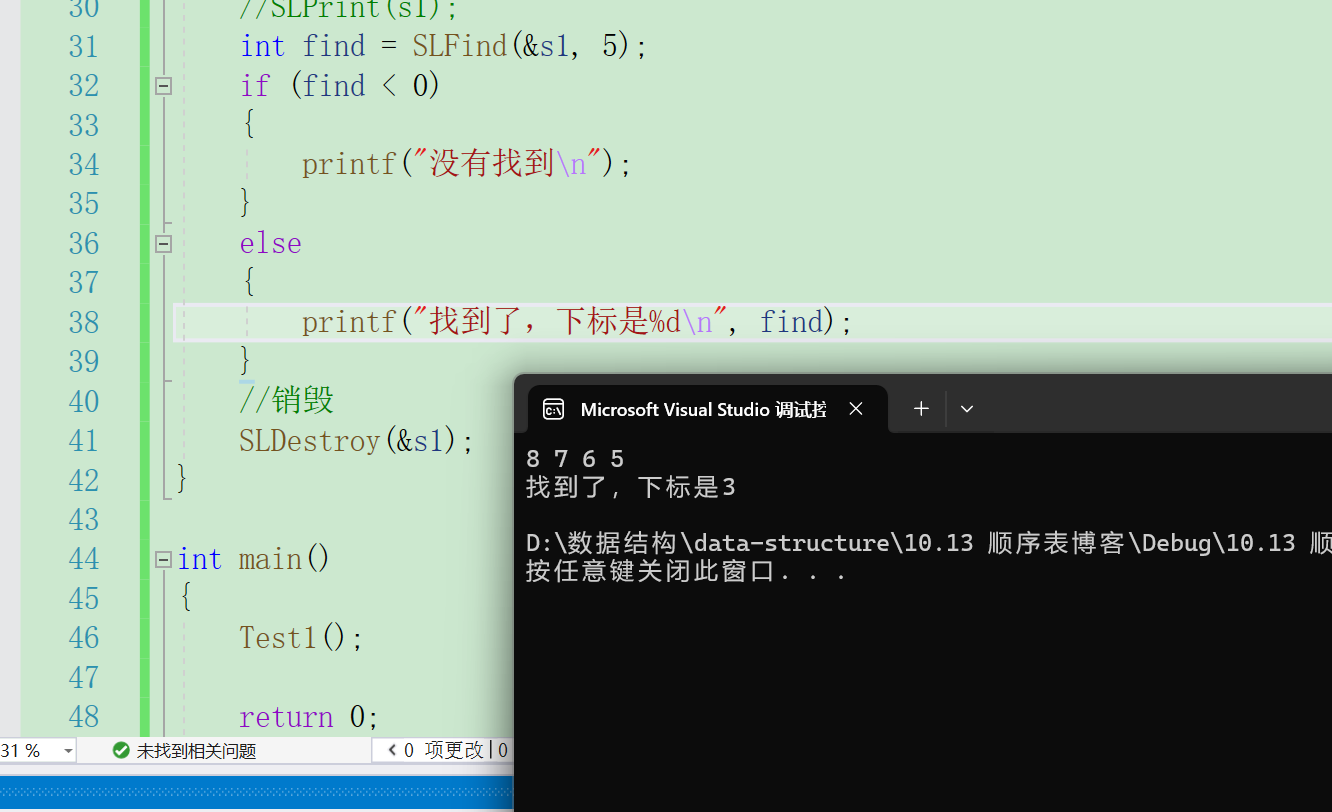
顺序表的查找就是会输出查找数据的下标。
int SLFind(SL* s, SLDataType x)
{assert(s);for (int i = 0; i < s->size; i++){if (s->arr[i] == x){//找到return i;}}//没有找到return -1;
}我们可以通过打印判断代码是否正确
四、通讯录
到这里我们已经完成了顺序表,接下来我们要完成的通讯录便是基于顺序表实现的项目。我们的逻辑是一步一步由数组到顺序表再到通讯录,顺序表可以储存很多种类型的数据,上面我们用它存储了int型的数据,现在我们想让它存储自定义的结构体类型的数据,这个结构体类型包括姓名,性别,年龄,电话,地址等,于是就被叫做通讯录。
我们写通讯录项目肯定是需要用到顺序表,因为我们刚刚写的顺序标中是int类型的数据,所以我们在写通讯录项目之前要先把int改成我们的自定义的结构体类型,一些只能与int有关的代码需要注销。
4.1结构体的定义
在初始化的时候我们要先定义一下结构体,再初始化。定义的时候我们要注意它们的几个文件之间有点绕,我们可以通过下图理解一下,我们可以看到特别是SeqList.h和Contact.h之间需要相互包含一样,但这是不允许的。所以我们前向声明(struct SeqList)先告诉编译器“存在一个名为SeqList的结构体类型”,但暂时不定义它的具体内容。
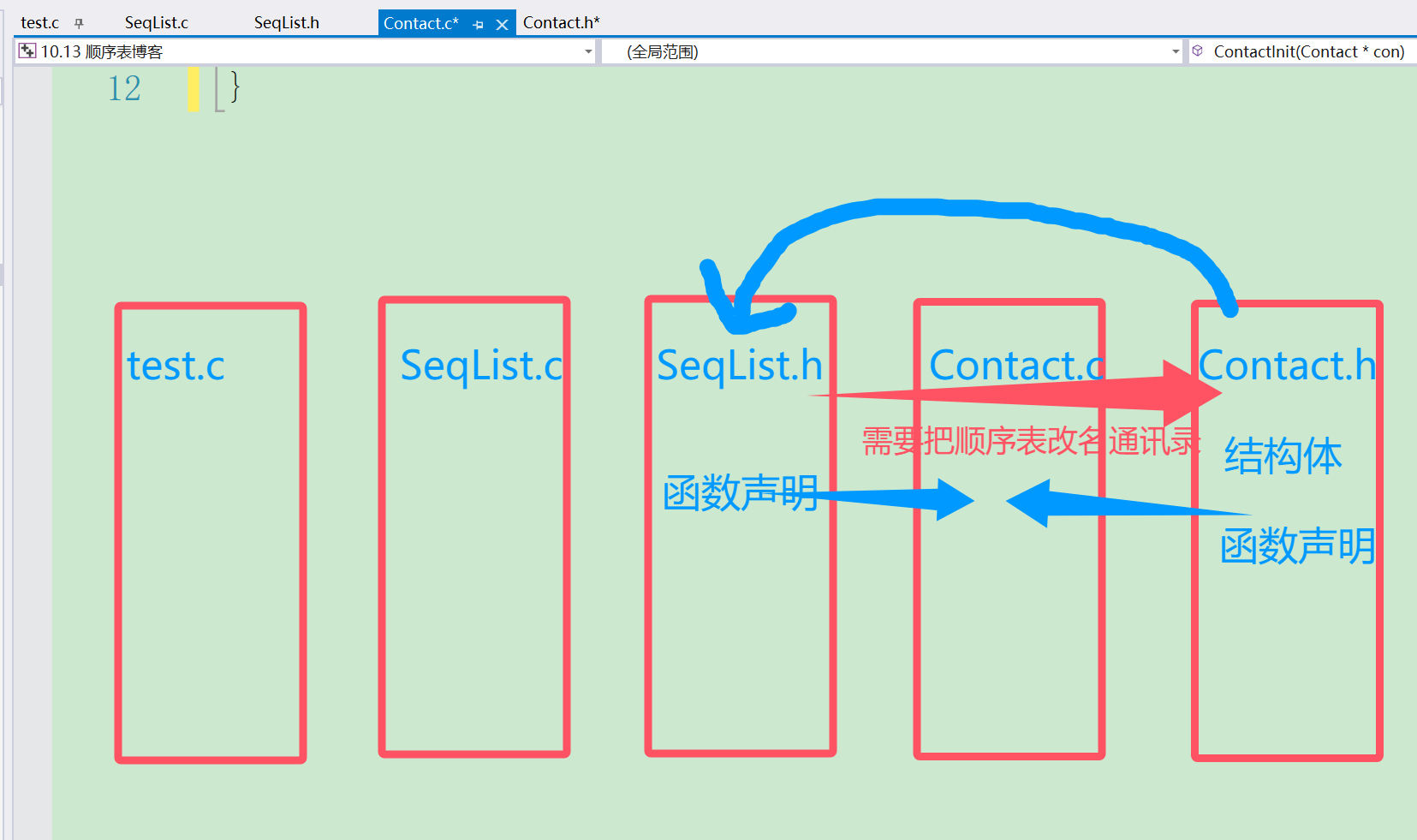
#pragma once#define NAME_MAX 20
#define GENDER_MAX 10
#define TEL_MAX 20
#define ADDR_MAX 100//定义联系人数据结构
//姓名 性别 年龄 电话 地址typedef struct personInfo
{char name[NAME_MAX];char gender[GENDER_MAX];int age;char tel[TEL_MAX];char addr[ADDR_MAX];
}peoInfo;struct SeqList;//要到顺序表相关方法,对通讯录操作就是对顺序表操作
//给顺序表改个名字,叫做通讯录
typedef struct SeqList Contact;并且不要忘记把顺序表中的int类型改成结构体peoInfo
//typedef int SLDataType;
typedef peoInfo SLDataType;4.2通讯录的初始化和销毁
顺序表已经有初始化和销毁功能了,我们直接使用就好。
// 初始化
void ContactInit(Contact* con)//s1
{//实际上是顺序表的初始化//顺序表已经初始化好了SLInit(con);
}
//销毁
void ContactDesTroy(Contact* con)
{SLDestroy(con);
}4.3添加通讯录数据
顺序表已经有添加数据功能了,我们直接使用就好。
//添加数据
void ContactAdd(Contact* con)
{//获取用户输入的内容//姓名 性别 年龄 电话 地址peoInfo info;printf("请输入姓名\n");scanf("%s", info.name);printf("请输入性别\n");scanf("%s", info.gender);printf("请输入年龄\n");scanf("%d", &info.age);printf("请输入电话\n");scanf("%s", info.tel);printf("请输入地址\n");scanf("%s", info.addr);SLPushBack(con, info);
}4.4删除数据
删除数据需要先找到数据存在才能进行删除,删除功能我们可以直接通过顺序表实现。这里我们实现的是通讯录项目,所以一般使用姓名来找到数据,然后使用strcpm函数来判断是否找到。
int FindByName(Contact* con, char name[])
{for (int i = 0; i < con->size; i++){if (0 == strcmp(con->arr[i].name,name)){//找到return i;}}//没找到return -1;
}//删除数据
void ContactDel(Contact* con)
{//存在才能删除//查找char name[NAME_MAX];printf("请输入联系人姓名\n");scanf("%s", name);int find = FindByName(con, name);if (find < 0){printf("要删除的联系人数据不存在\n");return;}//顺序表中删除指定位置的数据SLErase(con, find);printf("删除成功\n");
}4.5展示通讯录数据
//展示通讯录数据
void ContactShow(Contact* con)
{//表头:姓名 性别 年龄 电话 地址printf("%s %s %s %s %s\n", "姓名", "性别", "年龄", "电话", "地址");for (int i = 0; i < con->size; i++){printf("%4s %4s %4d %4s %4s\n",con->arr[i].name,con->arr[i].gender,con->arr[i].age,con->arr[i].tel,con->arr[i].addr);}}4.6修改通讯录数据
修改数据需要先找到数据存在才能直接进行修改。这里我们实现的是通讯录项目,所以一般使用姓名来找到数据,然后使用strcpm函数来判断是否找到。
int FindByName(Contact* con, char name[])
{for (int i = 0; i < con->size; i++){if (0 == strcmp(con->arr[i].name, name)){//找到return i;}}//没找到return -1;
}
//修改
void ContactModify(Contact* con)
{//存在char name[NAME_MAX];printf("请输入联系人姓名\n");scanf("%s", name);int find = FindByName(con, name);if (find < 0){printf("要修改的联系人数据不存在\n");return;}//直接修改printf("请输入新的姓名:\n");scanf("%s", con->arr[find].name);printf("请输入新的性别:\n");scanf("%s", con->arr[find].gender);printf("请输入新的年龄:\n");scanf("%d", &(con->arr[find].age));printf("请输入新的电话:\n");scanf("%s", con->arr[find].tel);printf("请输入新的地址:\n");scanf("%s", con->arr[find].addr);printf("修改成功\n");
}4.7查找通讯录数据
查找数据需要先找到数据存在才能直接进行打印。
int FindByName(Contact* con, char name[])
{for (int i = 0; i < con->size; i++){if (0 == strcmp(con->arr[i].name, name)){//找到return i;}}//没找到return -1;
}
//查找
void ContactFind(Contact* con)
{//存在char name[NAME_MAX];printf("请输入联系人姓名\n");scanf("%s", name);int find = FindByName(con, name);if (find < 0){printf("要查找的联系人数据不存在\n");return;}printf("%s %s %s %s %s\n", "姓名", "性别", "年龄", "电话", "地址");printf("%4s %4s %4d %4s %4s\n",con->arr[find].name,con->arr[find].gender,con->arr[find].age,con->arr[find].tel,con->arr[find].addr);
}最后
我们这里只是对实现通讯录项目的几个功能进行了编译,具体项目的完整逻辑放在了我的仓库里。如果有需要可以自行去查看。链接:顺序表2(通讯录) · 63fb0ca · 陈陈陈陈/数据结构 - Gitee.com