【第4篇】InternImage(CVPR2023):探索由可形变卷积构成的纯视觉大模型
论文题目:InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
文献地址:https://arxiv.org/pdf/2211.05778
源码地址:https://github.com/OpenGVLab/InternImage

文章目录
- @[toc]
- 五分钟回顾模型
- 实验结果
- 本文方法
- 一、 理论部分
- A. DCNv3 详解
- B. 整体结构详解
- 二、 Code
- A. 整体结构
- B. StemLayer
- C. InternImageBlock
- DCNv3
文章目录
- @[toc]
- 五分钟回顾模型
- 实验结果
- 本文方法
- 一、 理论部分
- A. DCNv3 详解
- B. 整体结构详解
- 二、 Code
- A. 整体结构
- B. StemLayer
- C. InternImageBlock
- DCNv3
🌠🌠🌠近期准备将近几年工作过程中涉及到的一些还不错的模型结构进行发布。届时,也会把相应用的比较好的模型魔改案例在另一个专栏进行整理发布,帮助大家在跟进最新CV任务的同时,掌握模型魔改的技巧。 可以期待一下! 还希望大家多多关注、留言,你们的支持是我更新的动力~
🌠🌠🌠本篇内容:本文介绍InternImage(CVPR2023, 由上海人工智能实验室、清华大学等机构的研究人员提出的基于卷积神经网络(CNN)的视觉基础模型)。与基于 Transformer 的网络不同,InternImage 以可变形卷积 DCNv3 作为核心算子,使模型不仅具有检测和分割等下游任务所需的动态有效感受野,而且能够进行自适应的空间聚合。
五分钟回顾模型
InternImage是第一个可以有效扩展到大规模参数和数据的CNN基础模型,参数量可以有效扩展到超过10亿,并取得了与最先进的vit模型相当甚至更好的性能。其核心组件为具有动态稀疏性的可形变卷积DCNv3,在只使用常规3x3窗口大小卷积的条件下,可以从给定数据动态学习适当的感受野(提升),同时实现自适应空间聚合,弥补CNN自身与MHSA的不足(MHSA具有长程依赖关系和自适应空间聚合),也避免了大型密集核带来的优化问题和昂贵的计算成本。
具体而言,InternImage的核心动机是打破CNN与Transformer之间的性能鸿沟:传统CNN受固定感受野限制,难以建模全局依赖;而Transformer虽然能捕捉长距离关系,但计算成本高、内存访问效率低。为此,InternImage提出基于可变形卷积的动态感受野机制,通过堆叠带可变形卷积模块,在保持CNN高效特性的同时,实现类似Transformer的全局建模能力。
模型的核心创新点包括:
- 动态可变形卷积(Dynamic Deformable Convolution):卷积核的采样位置随输入内容动态调整,增强对复杂形态特征的捕捉能力。
- 分层结构设计:采用 4 个 stage 的层级结构,通过下采样逐步扩大感受野,每个 stage 包含多个
InternImage Block。 - 高效注意力替代机制:通过可变形卷积的多尺度采样,替代
Transformer的自注意力,在降低计算量的同时保持全局建模能力。
InternImage Block的核心结构为:动态可变形卷积 + 多层感知机(MLP),并引入残差连接和归一化层,形成高效的特征提取单元。

在计算效率方面,InternImage 在 GPU 上的吞吐量(FPS)显著高于同精度的 Transformer 模型,且内存占用更低,更适合大规模部署。
实验结果
InternImage 在多个基准数据集上表现优异,具体如下:
- ImageNet-1K 分类任务:
- InternImage-L 在 Top-1 精度上达到 87.7%,超过 ConvNeXt-L(85.8%)和 Swin-L(86.4%)。
- 同时,在相同精度下,推理速度比 Swin-L 快 2 倍以上。
- COCO 目标检测任务:
- 基于 FPN 框架,InternImage-XL 在 AP 指标上达到 58.3%,超过 Deformable DETR(53.3%)和 Swin-L(55.7%)。

- 基于 FPN 框架,InternImage-XL 在 AP 指标上达到 58.3%,超过 Deformable DETR(53.3%)和 Swin-L(55.7%)。
- ADE20K 语义分割任务:
- 采用 UPerNet 结构,InternImage-XL 的 mIoU 达到 56.1%,优于 ConvNeXt-XL(54.8%)和 Swin-XL(55.2%)。
本文方法
InternImage模型结构主要包含DCNv3和模型整体结构两部分。
一、 理论部分
在介绍DCNv3之前,首先总结常规卷积CNN与MHSA之间的主要区别,进一步理解作者模型修改的动机。
a. 长程依赖关系。具有较大的感受野(长程依赖关系)的模型通常在下游任务中具有更好的性能,但由3x3卷积堆叠的方式有效感受野相对较小,即使比较深的网络结构,也不会获得像vit一样的长程依赖关系,在一定程度限制了CNN结构模型的性能;
b. 自适应空间聚合。MHSA的权重可由输入动态调整,CNN静态权重可能会更快地收敛,但也限制了从规模数据中学习更通用、鲁棒的模式。
图(a)中表示多头注意力机制MHSA具有长程依赖和自适应空间聚合(具有全局注意力机制的同时,查询像素周边的响应像素的动态权重(或者称之为关联性)基本呈现高斯分布),但计算效率较低。
图(b)限制MHSA的范围至一个局部窗口,虽然提升了计算效率,但丧失了长程依赖关系;
图©使用大核卷积的方案,虽然具备长程依赖关系和计算效率的优势,但不具备空间聚合的自适应性,相邻像素的响应(关联性)基本一致。
图(d)则为本篇InterImage的响应效果,在具有长程依赖关系和自适应空间聚合的同时,保持了高效的计算效率。

A. DCNv3 详解
基于CNN的基础模型一般会围绕长程依赖关系和自适应空间聚合两个方面进行设计。
回顾DCNv2,通过可学习的偏移量 Δ p k \Delta p_k Δpk和调制标量 m k m_k mk(通过一个CNN获得),前者可以灵活控制与短或长程特征的交互,提升长程依赖关系;后者可以对于自适应空间聚合,可根据输入 x x x 灵活调整关联程度。可以看出,DCNv2与MHSA具有类似的有利特性。

其中, p 0 p_0 p0为当前像素; K K K为采样点总数, k k k当前采样点的个数; w k w_k wk为当前第k个采样点的权值; m k m_k mk表示第k个采样点的调制标量(可学习),可以简单理解为是对于输入x可学习调整的关联系数; p k p_k pk为预定义的网格采样,即与常规卷积一样的{(-1, 1), (-1, 0), … , (0, +1), … ,(+1, +1)}; Δ p k \Delta p_k Δpk为可学习的偏移量,实际学习过程中是分数,可通过双线性插值。
理解DCNv2后,DCNv3提出动态权重机制,使卷积核权重随输入特征动态生成,进一步增强适应性。主要体现在以下几个方面:
a. 提升模型效率: 卷积权重 w k w_k wk分离为深度可分离卷积的深度部分DW和逐点部分PW;
b. 引入多组机制: 空间聚合过程划分为G组,每组都有单独的采样偏移量 Δ p g k \Delta p_{gk} Δpgk和调制尺度 Δ m g k \Delta m_{gk} Δmgk,因此单个卷积层上的不同组可以具有不同的空间聚合模式,提升提取特征的丰富性,从而为下游任务带来更强的特征。
c. 沿采样点的调制标量归一化: 调制标量归一化由DCNv2(sigmoid)更改为DCNv3(softmax),将调制标量的和约束为1,使得不同尺度模型的训练过程更加稳定。
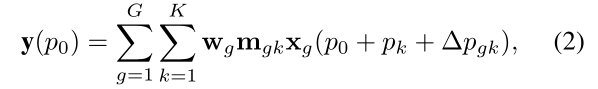
与传统卷积、可形变卷积对比:
- 传统卷积:固定采样位置和权重,感受野受限。
- 可变形卷积:动态调整采样位置,但权重固定。
- 动态可变形卷积:同时动态调整采样位置和权重,适应性更强。
B. 整体结构详解
InternImage的结构如下图所示。整体上来看,共包含4个stage,每个stage前包含一个stem层或者downsampling层,用于空间下采样和通道数量扩展。具体如下:
- 输入嵌入(Input Embedding):
- 通过步长为 4 的 4×4 卷积将输入图像(如 224×224×3)转换为特征图(如 56×56×C1),其中 C1 为第一个 stage 的通道数。
- Stage 结构:
- 每个 stage 由多个
InternImage Block组成,通过步长为 2 的卷积进行下采样,通道数翻倍(C1→C2→C3→C4)。 - 最后两个 stage 包含更多 Block,以捕捉更高层次的语义特征。
- 每个 stage 由多个
- InternImage Block:
- 结构为:
动态可变形卷积 + LayerNorm + MLP + LayerNorm + 残差连接。 - MLP 采用 1×1 卷积实现通道扩展(通常为输入通道的 4 倍),再通过 1×1 卷积压缩回原通道数。
- 结构为:
- 输出层:
- 分类任务中,通过全局平均池化和 1×1 卷积将特征转换为类别概率。
- 检测 / 分割任务中,可直接作为骨干网络输出多尺度特征图。

二、 Code
A. 整体结构
InternImage模型整体结构从代码层面主要包括stemLayer和InternImageBlock两大部分。

B. StemLayer
StemLayer是 InternImage 的输入处理模块,通过两个3x3卷积操作对输入图像进行4倍下采样。如果输入分辨率为224x224,为后续网络层提供的基础特征分辨率为56x56。


C. InternImageBlock
InternImageBlock由多个InternImageLayer堆叠而成,形成网络的一个Stage提取特定尺度的特征。InternImageLayer由dcn+LN,mlp+LN组成,各自通过残差结构相连缓解深层网络训练难题,并在InternImageBlock中添加下采样downsample。

与论文所给结构一致,如下图所示,在网络中的位置:每个 Stage 包含一个InternImageBlock,网络通常包含 4 个这样的 Stage,特征图尺寸依次为 56×56、28×28、14×14 和 7×7。

MLP在InternImage中为包含dropout的两层全连接前馈网络。

DCNv3
代码的核心思想是通过学习偏移量(offset) 和注意力掩码(mask),让卷积核能够自适应地聚焦于图像中具有重要语义信息的区域,从而提升模型对目标变形、尺度变化的适应性。
从DCNv3的forward可以看出,其输入input为NHWC的格式,而Pytorch通常为NCHW的格式,因此,在YOLO等模型添加DCNv3改进时,需要提前将输入x转换为要求的NHWC格式,输出特征再转回NCHW格式。
书归正传,偏移量offset和注意力掩码mask分别通过线性全连接层构成;对输入x进行深度可分离卷积,以减少计算量。
offset:预测每个卷积核位置的偏移量(2 个方向 × 分组数 × 核大小 ²)mask:预测每个采样点的注意力权重(分组数 × 核大小 ²)

DCNv3Function不做进一步解读了,感兴趣的可以深入理解实现的方式。